(综述)当大模型遇上健康管理:PHM-LM的概念、范式与挑战
论文题目:An outline of Prognostics and health management Large Model: Concepts, Paradigms, and challenges(预后和健康管理大模型大纲:概念、范例和挑战)
期刊:Mechanical Systems and Signal Processing(MSSP,机械系统与信号处理,Top)
摘要:预测与健康管理(PHM)是防止复杂系统发生意外故障和确保完成任务的关键技术,广泛应用于航空、航天、制造业、轨道交通、能源等领域。然而,PHM的开发和应用受到诸如泛化、解释和验证能力等瓶颈的严重制约。大型模型(LM)是生成式人工智能(AI)的一个典型和强大的代表,预示着一场技术革命,有可能从根本上重塑传统技术领域。它强大的泛化和推理能力为解决PHM现有的瓶颈提供了机会。为此,我们在系统分析PHM目前面临的挑战和瓶颈以及大模型的优势的基础上,提出了将大模型与PHM相结合的PHM大模型(PHM- lm)的新概念和相应的三种典型范式。此外,在这三种范式的框架内,为PHM- lm提供了一些可行的技术方法,以解决PHM面临的核心问题,并增强PHM的核心能力。并对PHM-LM在整个建设和应用过程中所面临的一系列技术挑战进行了深入探讨,为今后的研究提出建议。本文的综合努力提供了一个全面的PHM- lm技术框架,为PHM的新方法、新技术、新工具、新平台和应用提供了途径,并有可能创新PHM的设计模式、研发模式、验证和应用模式,即:从传统定制到泛化,从判别方法到生成方法,从理想条件到实际应用。
当大模型遇上健康管理:PHM-LM的概念、范式与挑战
一、为什么要写这篇文章?
在航空、航天、制造、轨道交通、新能源等领域,故障预测与健康管理(Prognostics and Health Management,PHM) 是保障复杂系统安全运行、降低维护成本的核心技术。已有数据表明:PHM技术的应用使F-35等先进战斗机的出动率提升了25%,维护人力减少了20%~40%,使用与保障费用降低了50%;波音等大型制造集团也因PHM将故障损失减少了约15%。
然而,随着工程需求的日益提高,传统PHM方法正面临一系列深层次瓶颈——泛化能力弱、可解释性差、验证体系不健全。与此同时,以ChatGPT为代表的大模型(Large Model,LM)技术在近年来引发了全球范围内的技术革命,其强大的推理、泛化和生成能力为突破PHM瓶颈提供了新的可能。
正是在这一背景下,北京航空航天大学陶来发、卢晨等团队发表了这篇综述性论文,首次系统性地提出了PHM大模型(PHM-LM)的概念、三大范式与关键技术挑战,为PHM领域的技术革新提供了全面的框架性参考。
二、PHM当前面临哪些瓶颈?
论文从PHM系统工程全生命周期出发(概念设计→初步设计→详细设计→研制→在役五个阶段),系统梳理了PHM目前面临的9大挑战,分属算法/模型层和系统层两个维度。
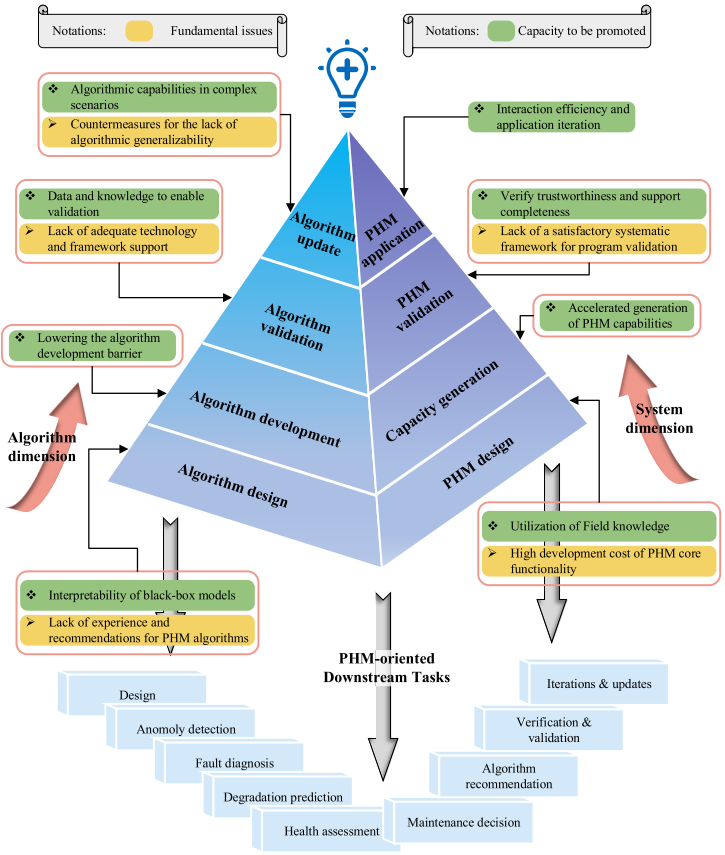
【配图:Fig. 2.2 PHM领域发展瓶颈与挑战示意图】
2.1 算法与模型层面(4个挑战)
挑战1:如何降低算法与模型的开发门槛?
当前PHM算法的开发涉及多模态数据处理设计、算法模型选择、底层代码编写、模型超参数配置与迭代更新等多个高技术门槛环节。随着PHM算法的爆炸式增长,定制化PHM模型的门槛也在不断提高,严重制约了PHM技术的广泛应用。
挑战2:如何有效开展算法与模型验证?
PHM算法与模型的能力验证是确保PHM能力的关键环节。然而,设计开发阶段数据与知识的严重匮乏,极大地制约了验证任务的推进。如何创新验证方式、建立高效可信的PHM算法验证体系,是当前亟待解决的重大挑战。
挑战3:如何增强算法与模型的逻辑性与可信度?
PHM领域广泛使用的黑盒算法(如深度神经网络)存在内部机制不透明、结果难以解释的固有缺陷,其可信度问题是不可回避的短板。在关键工程应用中,不可信的结果可能带来灾难性后果。
挑战4:如何提升算法与模型的泛化性能?
现有PHM算法与模型往往针对特定对象、特定条件定制开发,跨对象、跨工况的迁移能力严重不足。如何挖掘不同对象PHM算法之间的共性知识,开发具有强泛化能力的PHM算法,是该领域广泛应用的核心难题。
2.2 系统层面(5个挑战)
挑战5:如何高效利用PHM领域知识?
PHM领域积累了海量的多模态知识(技术文档、故障案例、FMECA报告、FTA报告等),但当前的知识利用效率低下,过度依赖个体专家的经验判断,知识碎片化问题严重。
挑战6:如何降低PHM系统设计门槛?
PHM系统设计需要在主系统设计并行开展,受到监测对象、数据传输条件、计算资源等多重约束,设计工作极为复杂。完全依赖专家经验的传统方式已无法满足快速增长的PHM系统开发需求。
挑战7:如何建立PHM验证体系?
同算法验证挑战类似,PHM系统级的验证同样面临数据与知识严重不足的困境,难以形成标准化、高效、可信的验证体系。
挑战8:如何提升PHM系统的泛化性?
传统PHM系统高度定制化,面向不同对象往往需要从零开始研发,开发成本高、效率低。如何设计具有强泛化能力、广泛适用于各类系统的PHM架构,是推动技术普及的关键。
挑战9:如何提升PHM系统的交互效率与性能?
随着智能终端的普及和交互形式的多样化,传统的人机交互模式已不能满足PHM系统的智能化应用需求。同时,如何利用在役阶段产生的海量真实数据实现PHM算法的自适应优化更新,也是重要挑战。
三、大模型有哪些能力能够解决上述问题?
论文在第三章对大模型(LM)及大语言模型(LLM)的技术现状和核心优势进行了系统梳理,这是提出PHM-LM的重要技术基础。
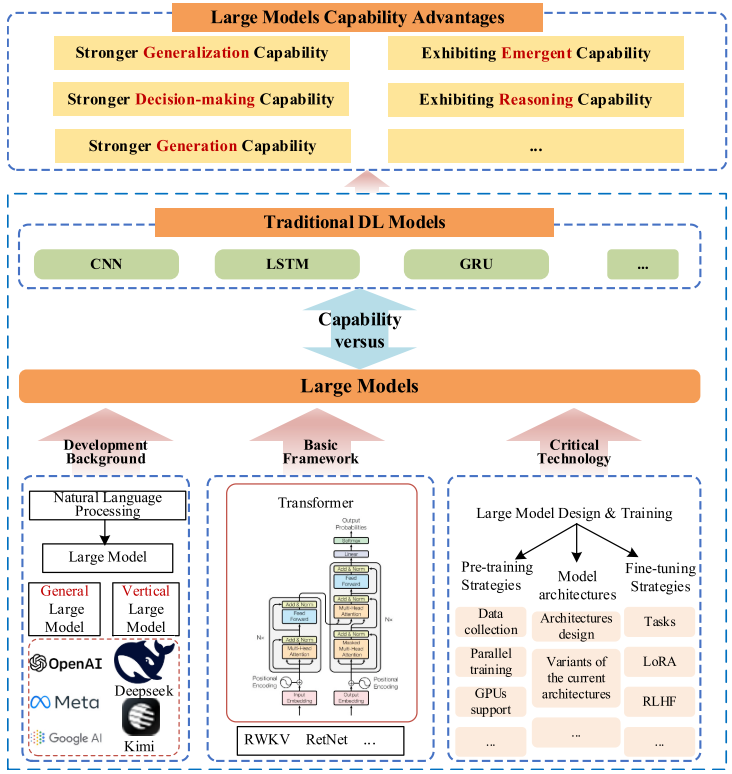
【配图建议:Fig. 3.1 大模型研究现状与优势分析图】
3.1 大模型的基础架构
当前主流大模型采用以下几种架构:
- Transformer:基于自注意力机制,包含编码器(如BERT)和解码器(如GPT)两类典型模型,是当前大模型的主流基础架构;
- RWKV:改进的循环神经网络架构,克服了传统RNN的梯度消失问题,同时避免了Transformer的高显存消耗,支持高效训练与快速推理;
- RetNet(微软研究院与清华大学联合提出):引入多尺度保留机制替代自注意力机制,在长序列建模上表现出色。
3.2 大模型的关键技术
大模型的构建依赖三项关键技术:
- 预训练(Pre-training):在海量无标注文本数据上进行无监督自回归训练,使模型掌握语言的统计规律和上下文关系;
- 微调(Fine-tuning):在预训练基础上,通过有监督数据进行指令微调(Instruction Tuning)和对齐微调(Alignment Tuning,如RLHF),使模型能力适配下游任务并对齐人类价值观;
- 提示策略设计(Prompting):通过上下文学习(ICL)和思维链提示(CoT)等技术,引导大模型进行复杂推理。
3.3 大模型的五大核心能力优势
论文总结了大模型相比传统深度学习模型在PHM应用中的五大差异性优势:
| 能力维度 | 传统DL模型 | 大模型 | 对PHM的价值 |
|---|---|---|---|
| 泛化能力 | 易过拟合,跨任务能力弱 | 预训练+微调后具有强泛化性 | 解决PHM强定制化、弱泛化的痛点 |
| 涌现能力 | 针对特定任务设计 | 参数规模达到阈值后涌现新能力 | 支持PHM新知识发现与能力生成 |
| 推理能力 | 难以完成复杂推理 | 支持逻辑推理、因果推断 | 增强PHM算法可解释性 |
| 决策能力 | 跨任务迁移能力弱 | 具备跨任务快速迁移决策能力 | 支持PHM维修决策、专家系统构建 |
| 生成能力 | 以判别为主,生成能力弱 | 核心优势,高质量内容生成 | 驱动PHM设计方案生成、代码生成、数据生成 |
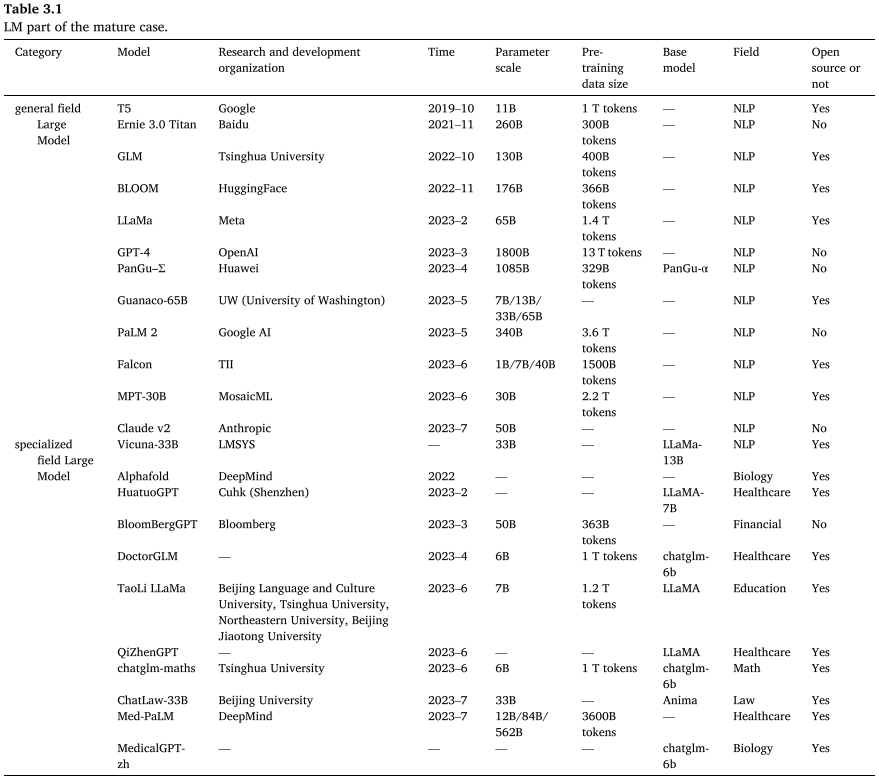
【配图:Table 3.1 大模型成熟案例列表(含通用领域与专业领域分类)】
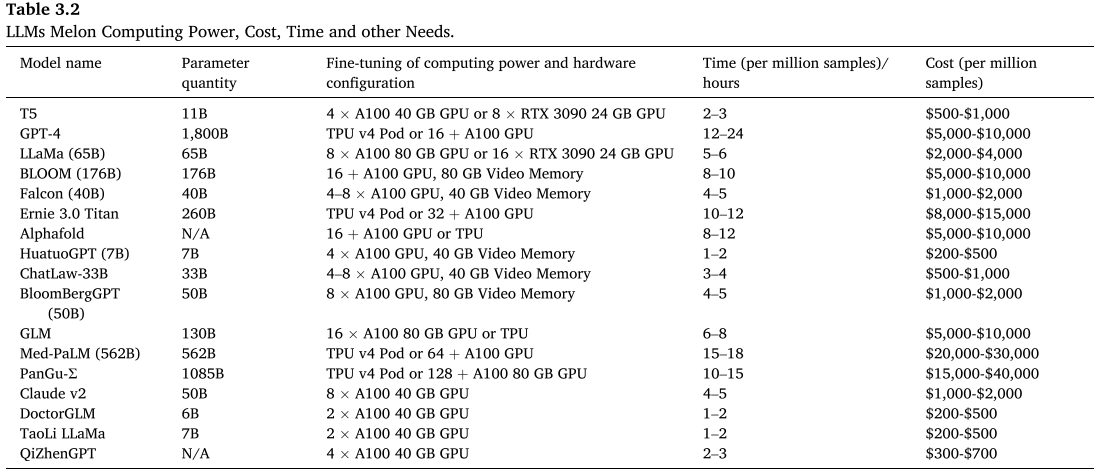
【配图:Table 3.2 典型大模型算力、成本、时间需求对比表】
值得注意的是,论文还列举了包括GPT-4(1800B参数)、LLaMA(65B参数)、BloombergGPT(50B参数,金融领域专用)等大量成熟案例,并给出了对应的微调所需算力配置与成本估算,为PHM-LM的工程实践提供了现实参照。
四、PHM-LM的核心概念与三大范式
4.1 PHM-LM的定义
论文首次正式提出PHM-LM的概念:
PHM-LM 是一种人工智能模型,具有大参数规模和高复杂度,深度融合PHM专业领域的独特特征,能够服务于产品PHM的全生命周期。其设计与应用旨在以更智能、更精准、更通用的方式处理PHM中的各类复杂任务。
PHM-LM可进一步分为三类:
- 面向对象的PHM-LM:如轴承PHM大模型、齿轮PHM大模型、电机PHM大模型;
- 面向任务的PHM-LM:如数据生成大模型、方案生成大模型、验证评估大模型;
- 面向算法的PHM-LM:如故障诊断大模型、故障预测大模型、维修决策大模型。
与传统PHM模型相比,PHM-LM在数据处理(支持多模态)、知识利用(大规模融合)、模型架构(通用+专用协同)和能力覆盖(全生命周期)等方面均有根本性提升。
4.2 三大递进式范式总览
论文提出了从基础到高级递进的三大典型范式,形成一套完整的技术研究路线图:
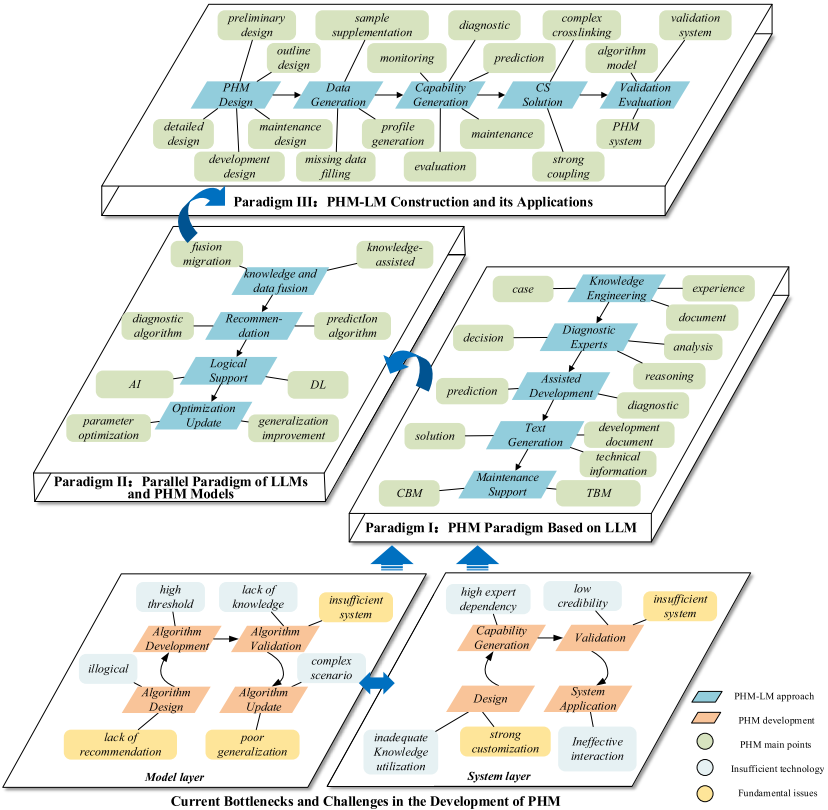
【配图建议:Fig. 1.1 PHM-LM递进式范式设计总览图】
| 范式 | 核心思路 | 主要应用场景 |
|---|---|---|
| 范式一 | 利用基础LLM的语言推理与泛化能力,通过快速微调构建PHM专用LLM | 知识工程、诊断专家、算法辅助开发、文本生成、维修决策 |
| 范式二 | 在成熟LLM基础上,构建LLM与PHM模型的并行协同开发框架 | 知识数据融合、算法智能推荐、可解释性增强、算法优化更新 |
| 范式三 | 针对PHM领域特性,系统性构建PHM-LM,支撑全生命周期下游任务 | 端到端PHM设计、数据生成、能力生成、复杂系统方案生成、验证评估 |
五、范式一:基于LLM的PHM范式(5条技术路径)
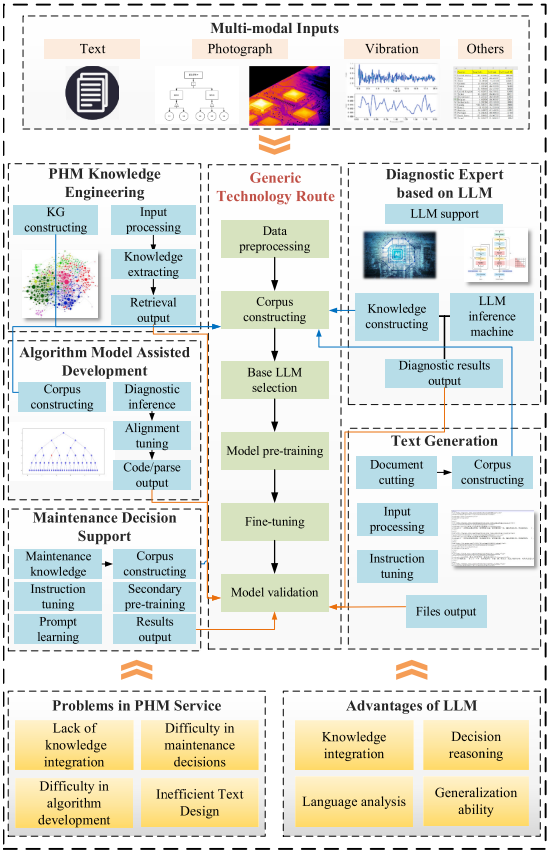
【配图:Fig. 4.1 基于LLM的PHM范式框架图】
范式一的核心逻辑是:直接借用现有成熟的基础LLM(如GPT-4、LLaMA等),通过PHM领域知识的快速微调,构建面向PHM典型场景的专用LLM,从而解决PHM服务中知识整合不足、文本设计重复低效、算法开发门槛高、维修决策效率低等问题。
技术路径1:基于LLM与知识图谱的PHM知识工程
针对问题:知识利用率低、检索效率低、决策可解释性差
核心思路:融合LLM的语言分析、知识推理与泛化能力,以及知识图谱在数据挖掘和知识整合方面的优势,构建PHM知识工程框架。系统接收多模态PHM输入(产品结构信息、功能信息、故障模式、故障现象、案例记录、技术报告等),经向量化处理后搜索知识图谱,利用LLM的NLP模块生成查询输出,并通过意图泛化模块增强LLM的泛化能力。
典型应用:知识检索、交互式问答、智能推理
技术路径2:基于LLM的诊断专家系统
针对问题:故障排查效率低,专家系统知识库更新困难
核心思路:利用LLM的知识推理和决策推荐能力,构建生成式LLM诊断专家系统。系统需要信号处理模块将多模态输入(故障描述文本、振动音频、故障图像、FMECA表格等)转化为LLM可处理的格式;推理引擎利用LLM的上下文学习和微调能力分析故障模式,并与语料库中的知识数据进行交叉比对,生成逻辑连贯的诊断结论。
典型应用:基于专家经验的故障诊断推理
技术路径3:LLM辅助PHM算法与模型开发
针对问题:PHM算法开发对专业知识和编程能力要求极高
核心思路:充分利用LLM的代码生成与分析能力,基于历史PHM算法代码构建预训练语料,使LLM具备高质量的PHM模型知识推理和模型生成能力。利用微调方法,使LLM能够分析现有模型、自动提供含功能分析说明的补全代码,并检测代码中的警告或错误,显著降低PHM模型开发的复杂度。
典型应用:代码补全、代码功能分析
技术路径4:PHM文本生成
针对问题:PHM设计文本重复性高、设计效率低
核心思路:利用LLM的语言分析、知识推理、决策能力和泛化能力,设计生成式PHM文本方案设计模型。通过历史PHM知识与方案文档构建预训练语料,结合提示工程技术,以及指令微调与对齐微调,使LLM生成满足要求且逻辑清晰的PHM文本方案。论文指出,LLM在金融、医疗、法律等专业领域辅助专业任务的准确率已高达93.3%,证明了其在专业领域方案生成方面的巨大潜力。
典型应用:文本方案设计、测试大纲生成
技术路径5:基于LLM的维修决策支持
针对问题:维修知识利用率低、决策效率差
核心思路:利用LLM的知识整合与决策推理能力,以FMECA表格等结构化数据和故障描述等非结构化数据为输入,生成可参考的维修决策或检索知识。通过对维修手册等资源进行预训练,并利用用户私有的历史维修记录进行二次预训练和微调,使模型精准对齐用户需求,解决维修人员知识经验不足、知识检索效率低等问题。
典型应用:维修知识检索、维修决策推荐
六、范式二:LLM与PHM模型并行范式(4条技术路径)
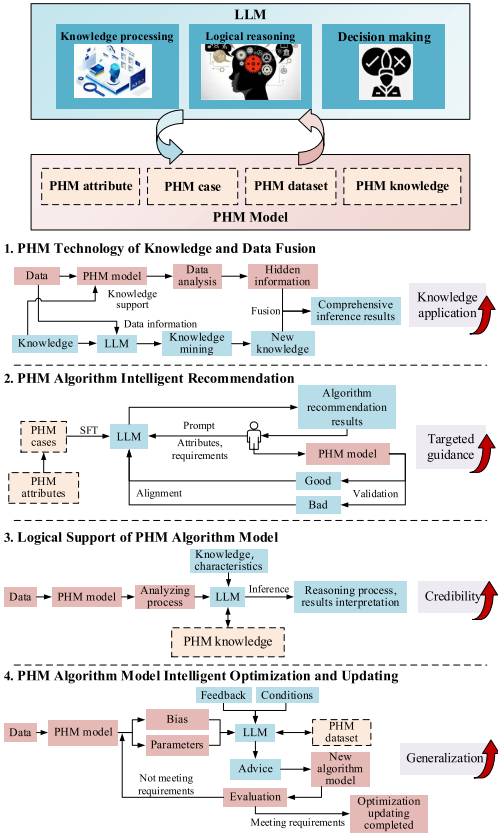
【配图:Fig. 4.7 LLM与PHM模型并行范式框架图】
范式二的核心逻辑在于:PHM领域的数据以多类型传感器采集的时序信号为主(振动、声音、电信号、温度、压力等),这是传统PHM模型的优势所在;而LLM在知识处理、逻辑推理、决策能力方面具有显著优势。因此,构建LLM与PHM模型并行协同的开发框架,可以将两者的能力互补融合,实现1+1>2的效果。
技术路径1:LLM与PHM模型的知识与数据融合
针对问题:现有知识利用不足,数据与知识融合不充分
核心思路:PHM模型处理数据以挖掘隐藏的规律和相关性,并将结果传递给LLM进行进一步处理;同时,LLM积累的大量领域知识反过来辅助PHM模型的数据分析过程,增强其全面性和准确性。这种双向协同既能弥补纯数据驱动方法在知识整合上的不足,又能通过PHM模型产生的数据丰富LLM的知识库。
典型应用:知识辅助数据分析、基于数据信息的知识挖掘
技术路径2:PHM算法智能推荐
针对问题:PHM算法选择与设计困难
核心思路:构建PHM算法案例库,利用LLM的知识提取与内化能力,将案例中的算法配置要素、诊断知识要素、工程条件要素转化为PHM工程经验(通过SFT、RLHF等技术)。用户在交互中提供使用对象类型、PHM任务维度(故障诊断/寿命预测/健康评估/维修决策)、可用数据与计算资源、预期结果等需求,LLM据此智能推荐最适合当前需求的算法与配置要素,并通过PHM模型实际运行反馈持续校准推荐质量。
典型应用:故障诊断算法推荐、故障预测算法推荐
技术路径3:PHM算法与模型可解释性增强
针对问题:黑盒算法缺乏逻辑推理,可信度差
核心思路:结合数据驱动算法的数据处理能力(特征提取、特征工程、可视化)和LLM的知识推理能力(逻辑分析、推理链建立、类比推理),为PHM算法的输出提供逻辑支撑。例如,在故障树模型场景中,LLM可从底层单元逐级推理至顶层故障状态,并通过与现有知识库的类比推理增强算法泛化性和逻辑连贯性,确保PHM模型的结果具有过程导向性和可解释性。
典型应用:黑盒算法逻辑补充、高可信PHM算法研发
技术路径4:PHM算法与模型智能优化与更新
针对问题:算法模型精度因对象变化、工况变化而下降
核心思路:当PHM模型的计算精度与实际结果偏差超过阈值时,将偏差值和算法参数输入LLM,由LLM结合PHM模型数据集中同类算法的参数设置提供优化建议,PHM模型据此更新参数并重新评估。若更新后仍不满足要求,则将当前优化状态反馈给LLM生成新的参数优化建议,如此迭代直至满足PHM要求。结合微调和RLHF技术,LLM可实现基于不同新数据条件的模型参数智能优化。
典型应用:新研产品PHM算法开发、在役期间算法自适应更新
七、范式三:PHM-LM构建与应用(5条技术路径)
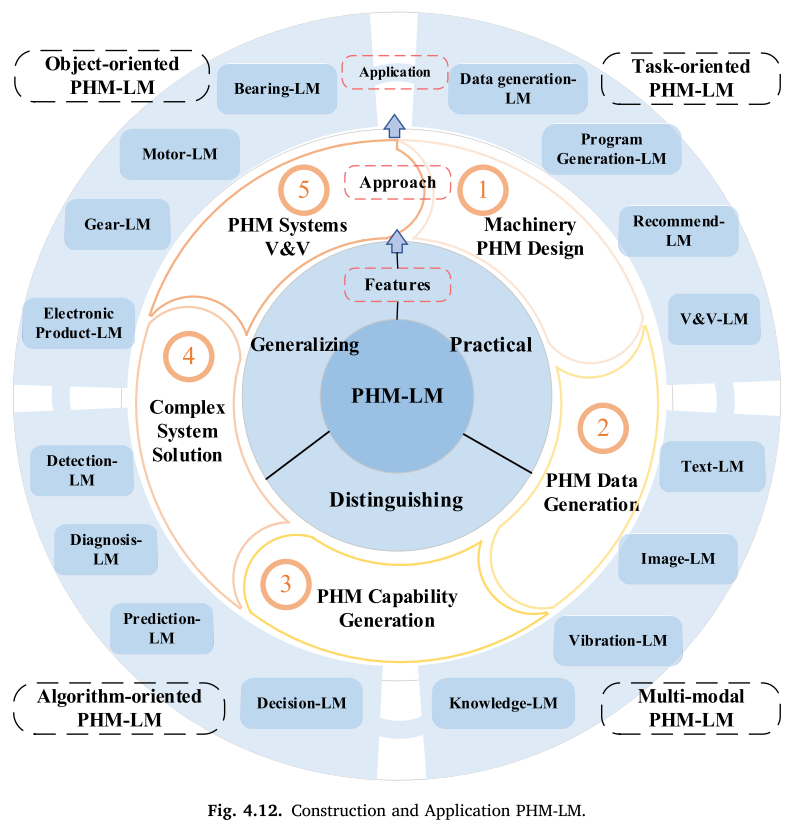
【配图:Fig. 4.12 PHM-LM构建与应用体系图】
范式三是最高层次的范式,旨在结合PHM领域特性,参考经典大模型框架,从对象维度、任务维度、算法维度、模态维度四个层面系统性地构建PHM-LM。
构建要点:
- 数据规模须达到7B级别以上,涵盖多模态、跨学科数据
- 需采用质量过滤、去重、隐私移除、标注等预处理策略
- 训练涉及超参数搜索、大规模分布式训练(多机多卡并行)
- 对象维度涵盖轴承、电机、齿轮、电子产品等;模态维度涵盖振动、知识、文本、图像
技术路径1:端到端PHM智能设计
针对问题:传统PHM设计消耗大量人力,高度依赖专家经验
核心思路:基于PHM-LM的推理能力与多模态融合能力,以任务信息和历史PHM设计案例为输入,智能生成涵盖PHM全过程的设计方案,包括状态监测方案、数据处理方案、算法模型方案、集成耦合方案、验证评估方案等。通过在PHM全过程多个节点设置评估接口,确保大模型推理结果与实际场景的有效对齐。
典型应用:全流程PHM方案的自动设计与生成
技术路径2:PHM数据智能生成
针对问题:PHM算法模型对高质量数据的需求难以满足
核心思路:在PHM-LM框架内,利用大模型的生成能力和泛化性能,训练生成式预训练模型,以设备对象信息和数据特性知识为输入,输出预定工况和状态下的仿真数据。数据生成过程以一致性、多样性、任务特异性三个维度为指导,确保生成数据与真实数据的相似性和正确性。论文指出,现有数据增强技术(生成对抗网络、数据迁移、变分编码等)在考虑对象特性、工况条件和未来应用需求方面仍有明显不足,PHM-LM将从这些维度全面优化数据生成任务。
典型应用:典型故障模式数据生成、验证数据剖面构建
技术路径3:PHM核心能力生成
针对问题:PHM能力开发门槛高、智能化程度低
核心思路:基于PHM-LM实现PHM能力智能生成,主要包含两个功能:一是底层代码智能生成(以历史PHM算法代码为训练基础,综合考虑对象特性、工况条件、环境和数据格式,快速生成满足任务需求的底层代码);二是PHM算法模型参数配置信息智能生成(通过分析算法模型特性和数据信息,确定最优参数配置)。这将从根本上降低PHM开发门槛,缩短能力生成周期,最小化算法开发资源投入。
典型应用:诊断能力智能生成、预测能力智能生成
技术路径4:复杂系统PHM方案生成
针对问题:传统PHM设计对多模态信息处理能力不足
核心思路:利用PHM-LM的多模态信息处理、逻辑推理和自然语言生成能力,以多模态故障信息、结构信息、对象特性、应用场景、工况条件、参数指标、能力需求为输入,生成综合PHM方案。大模型不仅能处理文本、声音、图像、结构化传感器数据等多模态信息,还能通过逻辑推理追踪复杂系统中各部件变化引起的连锁反应,并将复杂分析结果转化为清晰简洁的文本描述。
典型应用:装备系统PHM方案生成
技术路径5:PHM验证与评估
针对问题:传统PHM验证缺乏统一评价标准,对稀有故障数据的验证困难
核心思路:利用PHM-LM强大的逻辑推理能力,以系统结构信息、输入信息和故障模式为输入,快速理解装置工作原理和故障潜在原因,通过仿真装置运行来进行预测和诊断,并与实际数据对比验证PHM结果的准确性。同时,大模型可基于评估指标对PHM方法的性能进行评价,帮助识别PHM方法的优缺点,推动进一步优化。
典型应用:PHM验证与评估
八、三个实验案例验证
论文最后通过三个实际案例验证了所提范式的有效性。
案例1:基于LLM的轴承故障诊断框架(对应范式一)
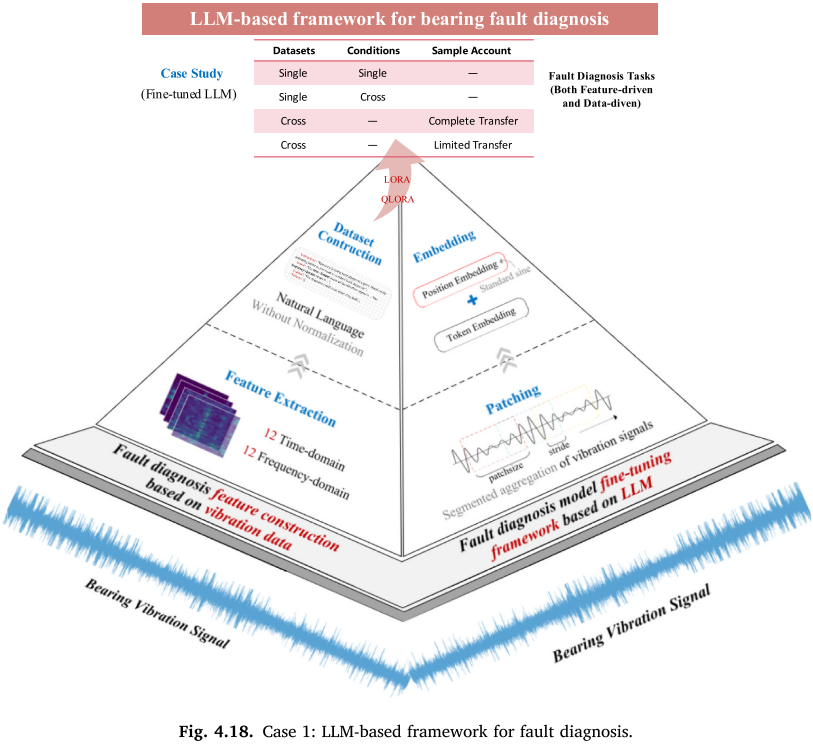
【配图:Fig. 4.18 案例1:基于LLM的轴承故障诊断框架图】
背景:传统轴承诊断方法面临跨工况适应性差、小样本学习困难、跨数据集泛化不足三大挑战。
方法:
- 提出信号特征量化方法,融合时域和频域特征提取(基于统计分析框架)
- 构建故障诊断特征体系
- 提出基于LoRA和QLoRA的振动数据模型微调框架(平衡时间效率与预测精度)
- 开展单数据集、跨工况、跨数据集三类诊断实验,对比完整数据迁移与限量数据迁移的效果
结果:跨数据集学习后精度提升约 10%,在跨工况、小样本、跨数据集三类实际工程需求中均表现出优异的泛化能力。
案例2:基于LLM的轴承剩余寿命预测(对应范式一)
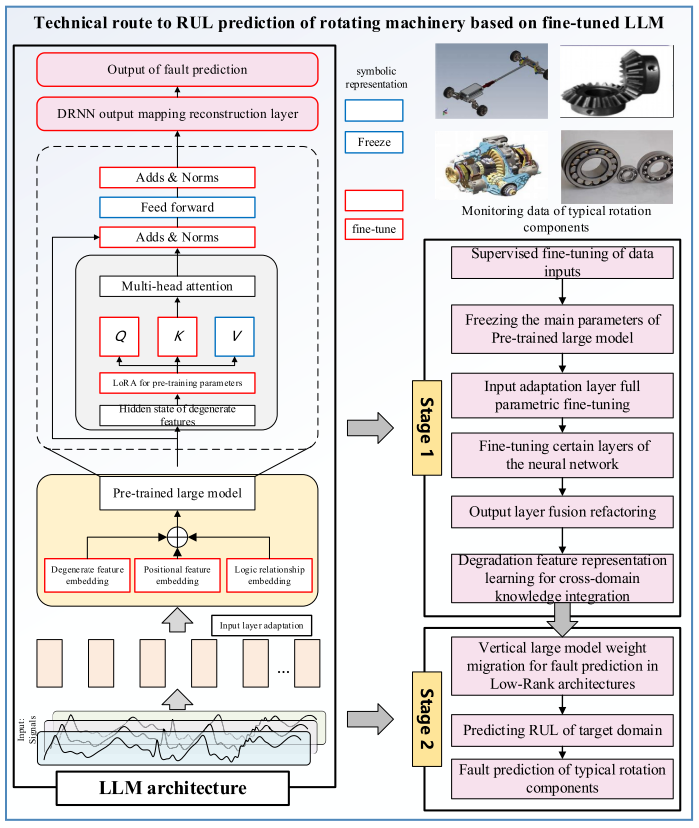
【配图:Fig. 4.19 案例2:基于LLM的轴承剩余寿命预测技术路线图】
背景:旋转机械的剩余寿命(RUL)预测对于设备维护和故障预防至关重要。
方法(LM4RUL),引入三项关键创新:
- 输入层适配:融合信号分析、处理技术、位置编码和基于振动信号特性的分词方法,优化LLM对振动信号的处理
- 中间层选择性微调:针对不同神经网络层的能力差异,仅对特定层进行微调,在保留LLM本征能力的同时实现向RUL预测任务的灵活迁移
- 输出层结构适配:将输出层修改为生成序列化长期数值,而非自然语言形式的概率分布建模
结果:LM4RUL在长期RUL预测精度上显著优于常见深度学习模型和针对性迁移学习模型,展现出更强的泛化能力。
案例3:基于LLM的领域自适应维修方案生成(LLM-R,对应范式一)
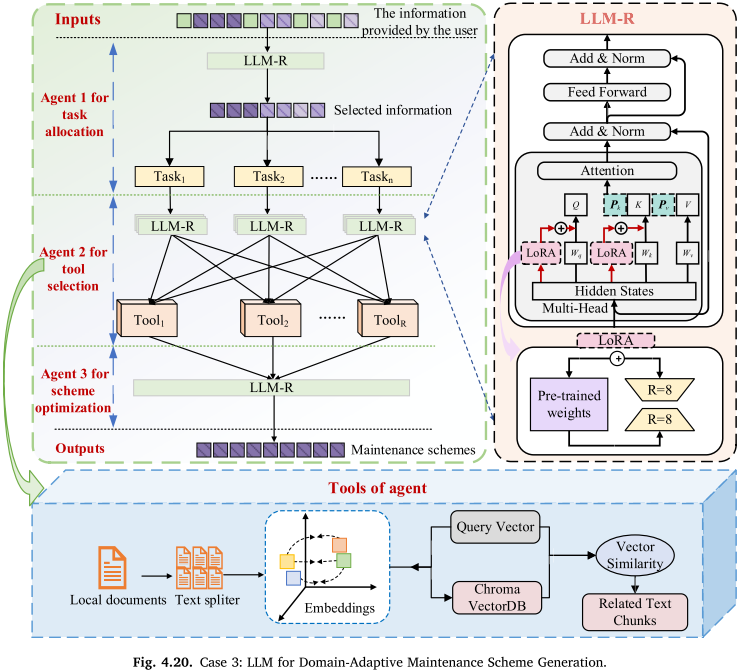
【配图:Fig. 4.20 案例3:LLM-R维修方案生成框架图】
背景:传统交互式电子技术手册(IETM)存在信息检索效率低、逻辑复杂等问题,难以满足智能系统需求。
方法(LLM-R):
- 通过混合数据比例的监督微调(SFT),增强LLM在垂直维修领域的适应性(微调秩 R=8)
- 引入任务级Agent(3个Agent分别负责任务分配、工具调用与信息检索、方案优化)
- 引入指令级RAG(检索增强生成)技术,优化维修方案生成流程,减少幻觉现象
- 以航空和船舶维修典型场景为测试用例构建维修方案数据集
结果:
- 复杂维修任务方案生成准确率达 91.59%
- 航空场景验证:当某机型发动机无法启动时,维修人员仅需用自然语言描述问题,即可快速获取故障排除步骤和解决方案,显著提升效率和准确性
- 船舶场景验证:在限量样本数据条件下,仍能生成高效可靠的维修方案,展现出强泛化能力
九、PHM-LM面临的七大技术挑战
论文在第五章系统梳理了PHM-LM从构建到应用全过程中面临的技术挑战,并对挑战的优先级进行了分析。
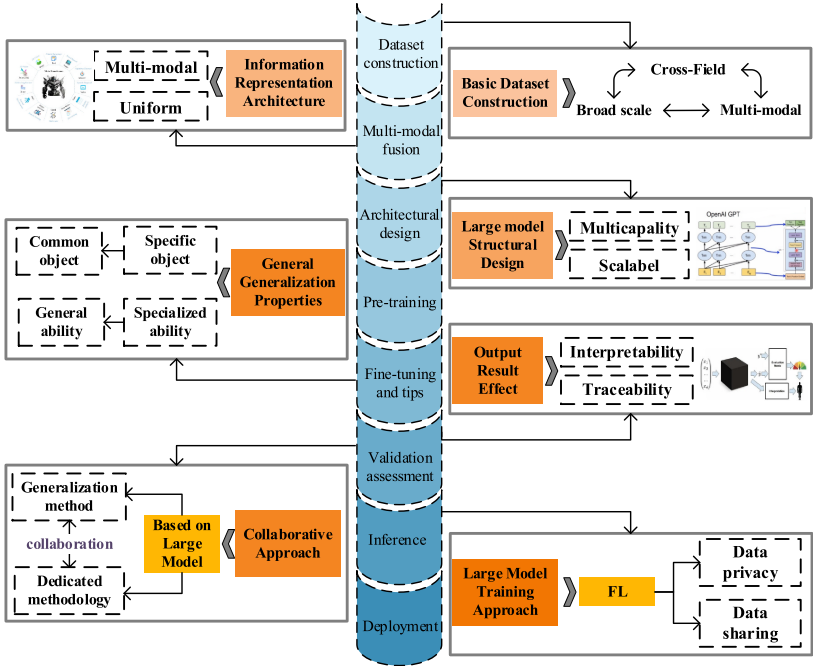
【配图:Fig. 5.1 PHM-LM技术挑战梳理图】
挑战1:跨领域、多模态PHM-LM基础数据集构建
PHM数据涵盖多模态传感器信号(温度、压力、振动、声音等)、多类型知识(FMECA、FTA、技术报告、法规标准等)及领域案例,具有跨学科、多模态、大规模的显著特征。根据模型规模-数据量-总计算量的参照比例,PHM-LM所需数据量理想情况下应达到7B级别以上。然而,隐私顾虑、行业壁垒、对象数据差异巨大等因素使大规模PHM数据集的获取面临重重困难。
挑战2:多模态健康信息统一表征架构
PHM健康信息的多模态特性要求将振动信号、知识文本、图像、结构化传感器数据等异构信息统一编码进入大模型。当前多模态处理研究仍处于探索阶段(主要策略是将非文本模态适配为文本模态,或引入扩展降维向量化层),PHM-LM是沿用现有策略还是创新专用统一表征架构,仍是亟待解决的关键问题。
挑战3:多能力可扩展的PHM-LM结构设计
理想的PHM-LM架构应能同时支持诊断、预测、评估等多种能力需求,并具备良好的可扩展性,能够随技术进步持续演化。在设计时需综合考虑多模态数据表征、模型利用、训练推理、指令微调、人机提示等多能力生成需求,追求底层架构的通用性、模态理解的广泛性、推理应用算法的模块化和输入输出接口的标准化。同时,模型中不合理的偏差设计可能对模型性能产生不可逆的严重影响。
挑战4:从特定目标专属能力到通用实践通用能力的转化
PHM-LM的构建和能力生成过程将不可避免地从针对特定产品(如轴承、机电系统)的专属能力出发,逐步扩展至跨多层级对象的全任务能力。如何利用大模型的涌现和泛化特性,在预训练和微调阶段实现从轴承诊断能力向轴承评估、预测、以及其他相似级别对象乃至复杂系统PHM能力的推广,是需要在每个建模步骤都需攻克的技术难题。
挑战5:PHM-LM输出的可解释性与可追溯性
即便是OpenAI也在GPT-4技术报告中承认,研究界尚未深入揭示大模型卓越能力背后的关键因素。黑盒方式产生的结果在关键系统中的可信度仍存疑问。更严峻的是,大模型存在**"幻觉"现象**(生成与现有信息相矛盾或无法被现有信息验证的内容),一旦PHM-LM生成看似可信但与系统特性完全不符的结论,后果可能是灾难性的。
挑战6:基于大模型的通用PHM方法与现有专用方法的协同
PHM-LM在智能化、泛化和生成能力方面具有明显优势,但研究表明当大模型在某些方面表现突出时,可能在其他方面面临挑战。NLP中的灾难性遗忘问题(新旧知识冲突时旧知识被覆盖),以及幻觉现象在PHM场景下(如错误的寿命评估、错误的故障定位)可能带来实际危害。因此,即便引入通用PHM方法,现有专用方法仍应保留,两者应协同运行——在训练侧持续用专业知识微调大模型,在应用侧不能仅依赖大模型输出而必须经过充分验证。
挑战7:PHM-LM的分布式隐私训练——数据隐私与共享的平衡
PHM数据具有隐私性强、分布分散的特点,需要整合大量资源才能满足大模型训练需求,这必然涉及分布式训练和数据隐私问题。联邦学习(Federated Learning,FL) 是目前最有前景的解决方案,但在PHM-LM的实际应用中仍面临客户端存储/计算/通信能力异构、本地数据非独立同分布、基于不同应用场景的模型异构、黑客攻击导致隐私泄露等多重技术挑战。
挑战优先级分析
论文对上述挑战的优先级进行了分析:
- 最优先:数据可用性与质量——是PHM-LM发展的基础前提
- 次优先:可解释性与可追溯性——直接关系应用安全,是安全应用的底线
- 第三优先:通用方法与专用方法的融合——决定模型在实际场景中的适用性
- 第四优先:可扩展架构设计——影响长期竞争力,但效果更偏长远
十、总结与展望
这篇论文构建了一个完整的PHM-LM技术框架,其核心贡献可以概括为:
理论贡献:
- 首次系统性提出PHM-LM的概念定义与分类体系
- 提出从基础到高级的三大递进式创新范式,打通了大模型技术与PHM领域融合的技术路径
- 在三大范式下归纳了14条具体可行的技术路径
实践贡献:
- 通过轴承故障诊断(跨数据集精度提升约10%)、轴承RUL预测(显著优于基线深度学习模型)、维修方案生成(准确率91.59%)三个案例,验证了所提范式的实际有效性
- 深入剖析了7大技术挑战,为后续研究提供了清晰的问题导向
范式转变的愿景:
论文最终呼吁推动PHM技术实现三大根本性转变:
- 从传统定制化走向泛化通用
- 从判别式方法走向生成式方法
- 从理想化条件走向真实应用场景
PHM-LM不仅是一种新的技术工具,更代表着PHM技术的设计模式、研发模式、验证模式和应用模式的全面革新。随着大模型技术的持续演进和PHM领域数据的不断积累,我们有理由相信,PHM-LM将成为推动复杂系统健康管理迈向真正智能化、通用化新时代的核心引擎。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)