FastAPI 部署 NLP 模型实战:从 BERT 文本分类到生产级接口实现
一、 概述
在电商及内容平台中,NLP 模型的应用场景极广,包括商品分类预测、实体抽取、拼写纠错 等。将训练完成的 PyTorch 模型从实验环境迁移至生产环境,需要一个高性能、高并发且易于维护的 Web 框架。FastAPI 凭借其原生支持异步编程(asyncio)和自动生成 OpenAPI 文档的特性,已成为 NLP 工程师部署模型的首选方案。
二、 开发环境与项目结构
在开始部署前,建议使用 Conda 创建独立的虚拟环境,以避免依赖冲突。
1. 环境安装
根据机器的 CUDA 版本安装对应的 PyTorch,并安装 FastAPI 相关依赖:
# 创建并激活环境
conda create -n nlp-deploy python=3.12
conda activate nlp-deploy
# 安装核心依赖
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install transformers datasets fastapi uvicorn pydantic
2. 标准化项目目录
良好的目录结构有助于后期维护,建议参考以下结构组织代码:
./
├── models/ # 存储训练好的 .pt 或 .bin 权重文件
├── pretrained/ # 预训练模型(如 bert-base-chinese)
└── src/
├── model_def.py # 模型类定义
├── web/
│ ├── app.py # FastAPI 实例与入口
│ ├── routers.py # 路由逻辑
│ ├── schemas.py # Pydantic 数据模型
│ └── service.py # 模型加载与推理逻辑
└── config.py # 路径与超参数配置
三、 模型定义与预测函数封装
部署的第一步是确保生产环境能够正确重建模型架构并加载权重。
1. 模型结构定义
以 BERT 多分类模型为例,核心在于提取 [CLS] 向量并接入线性分类头:
# src/model_def.py
import torch
from torch import nn
from transformers import AutoModel
class BertClassifier(nn.Module):
def __init__(self, model_path, num_classes):
super().__init__()
self.bert = AutoModel.from_pretrained(model_path)
self.classifier = nn.Linear(self.bert.config.hidden_size, num_classes)
def forward(self, input_ids, attention_mask=None):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
# 取 [CLS] token 的输出
cls_output = outputs.last_hidden_state[:, 0, :]
logits = self.classifier(cls_output)
return logits
2. 推理函数设计
推理逻辑需要处理分词、设备映射以及结果转换:
# src/runner/predict.py
import torch
def predict_text(text, model, tokenizer, device, label_feature):
# 文本编码
encoded = tokenizer(
[text],
return_tensors='pt',
padding='max_length',
truncation=True,
max_length=128
)
input_ids = encoded['input_ids'].to(device)
attention_mask = encoded['attention_mask'].to(device)
model.eval()
with torch.no_grad():
outputs = model(input_ids, attention_mask)
pred_id = torch.argmax(outputs, dim=1).item()
# 将 ID 转换为可读标签
pred_label = label_feature.int2str(pred_id)
return pred_id, pred_label
四、 FastAPI 服务端实现
FastAPI 的核心在于将推理逻辑解耦为服务层(Service)、路由层(Router)和数据模型层(Schema)。
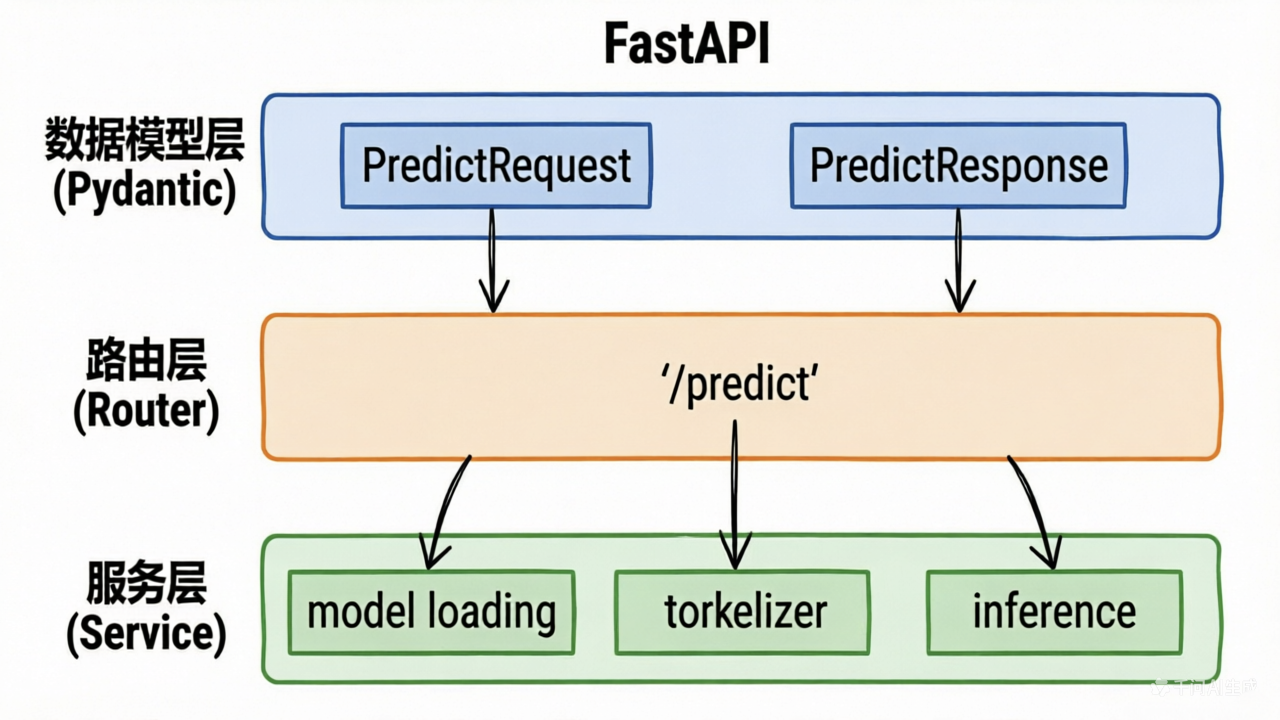
1. 定义数据模型
利用 Pydantic 进行输入校验,确保接口接收到的数据格式正确:
# src/web/schemas.py
from pydantic import BaseModel
class PredictRequest(BaseModel):
text: str
class PredictResponse(BaseModel):
text: str
pred_id: int
pred_label: str
2. 封装推理服务
在服务层完成模型初始化,避免每个请求重复加载模型导致显存溢出:
# src/web/service.py
import torch
from transformers import AutoTokenizer
from datasets import load_from_disk
from model_def import BertClassifier
# 设备初始化
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 全局加载模型与分词器
MODEL_PATH = "models/model.pt"
BERT_DIR = "pretrained/bert-base-chinese"
model = BertClassifier(BERT_DIR, num_classes=15).to(device)
model.load_state_dict(torch.load(MODEL_PATH, map_location=device))
model.eval()
tokenizer = AutoTokenizer.from_pretrained(BERT_DIR)
# 加载标签映射(假设预处理阶段已保存)
label_info = load_from_disk("data/processed/train").features['label']
def get_prediction(text: str):
from runner.predict import predict_text
return predict_text(text, model, tokenizer, device, label_info)
3. 路由与应用启动
定义 API 节点并挂载到主应用:
# src/web/routers.py
from fastapi import APIRouter, HTTPException
from web.schemas import PredictRequest, PredictResponse
from web.service import get_prediction
predict_router = APIRouter(tags=["NLP预测接口"])
@predict_router.post("/predict", response_model=PredictResponse)
async def predict(request: PredictRequest):
try:
content = request.text.strip()
if not content:
raise HTTPException(status_code=400, detail="输入内容不能为空")
id_res, label_res = get_prediction(content)
return PredictResponse(text=content, pred_id=id_res, pred_label=label_res)
except Exception as e:
raise HTTPException(status_code=500, detail=f"推理失败: {str(e)}")
# src/web/app.py
from fastapi import FastAPI
import uvicorn
app = FastAPI(title="NLP Model Service")
app.include_router(predict_router)
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
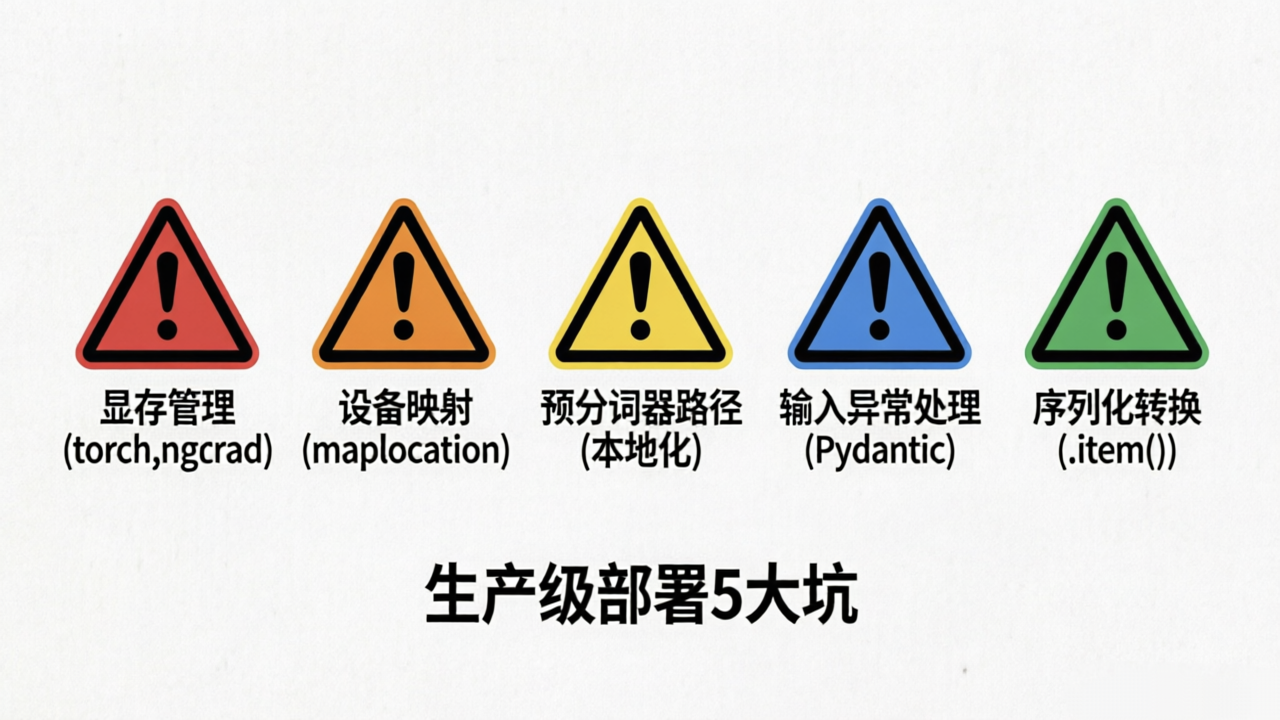
五、 踩坑经验分享
在实际部署 NLP 模型的过程中,容易遇到以下几个关键技术点,处理不当会导致服务不稳定。
1. 显存管理与推理模式
问题: 接口运行一段时间后,GPU 显存持续上涨最终导致 OOM。 对策:
- 必须在推理代码块中使用 with torch.no_grad()。
- 显式调用 model.eval() 以关闭 Dropout 等非推理层。
- 若并发量极高,可考虑引入 torch.autocast 混合精度推理以减少显存占用。
2. 设备映射(Device Mapping)
问题: 在训练环境(GPU)导出的权重,在只有 CPU 的预测服务器上加载报错。 对策: 在 torch.load 时显式指定 map_location 参数。这样无论保存时是在哪个设备,加载时都会自动对齐到当前环境配置的设备。
3. 预分词器的路径依赖
问题: AutoTokenizer.from_pretrained 默认会从 Hugging Face 下载模型,在内网生产环境下会连接超时。 对策: 提前将预训练模型下载到本地,路径通过 Pathlib 或 os.path 转换为绝对路径,并在生产配置中固定该路径。
4. 输入异常处理
问题: 用户输入特殊字符、空字符串或超长文本导致模型崩溃。 对策:
- 在 Pydantic Schema 层限制文本长度。
- 在 tokenizer 中开启 truncation=True 和 padding='max_length',确保输入到模型的 Tensor 维度始终一致。
- 增加空字符串校验逻辑,避免进入推理层。
5. 序列化转换
问题: 模型输出的 pred_id 通常是 torch.Tensor 类型,直接返回会导致 FastAPI 序列化 JSON 失败。 对策: 务必使用 .item() 方法将单元素 Tensor 转换为 Python 原生 int 或 float 类型。
六、 进阶:多任务模型部署
在更复杂的场景中,如电商知识图谱构建,可能需要同时部署拼写纠错和实体抽取模型。
对于 UIE(通用信息抽取)模型的部署,由于其 Prompt 机制较为灵活,建议在 Service 层预设好 schema。通过 FastAPI 的单一实例管理多个模型,要注意通过不同路由(Router)进行区分,并合理分配显存:
# 示例:多模型加载逻辑
class MultiModelService:
def __init__(self):
self.cls_model = load_cls_model()
self.uie_model = load_uie_model() # UIE 实体抽取
self.spell_model = load_spell_model() # 拼写纠错
七、 总结
FastAPI 为 NLP 模型提供了一个标准化且高性能的接口外壳。通过 Pydantic 强化类型约束、合理配置全局模型加载、严控推理模式的梯度计算,可以构建出高可用的生产级 API。在部署过程中,开发者应重点关注模型在不同硬件环境下的路径兼容性与显存回收机制。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)