pyspark代码运行报错JDK17环境下
在已经配置好hadoop和JDK之后,运行有警告信息,但是还是能正常运行的。如图: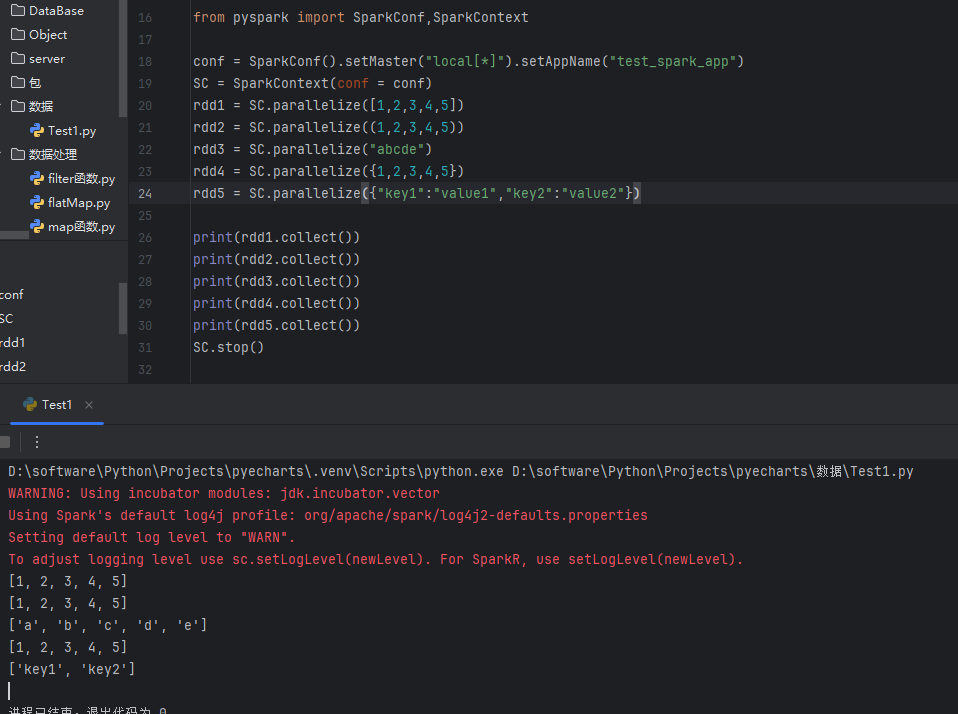
但是换成下面代码就运行报错,什么原因?应该如何解决?
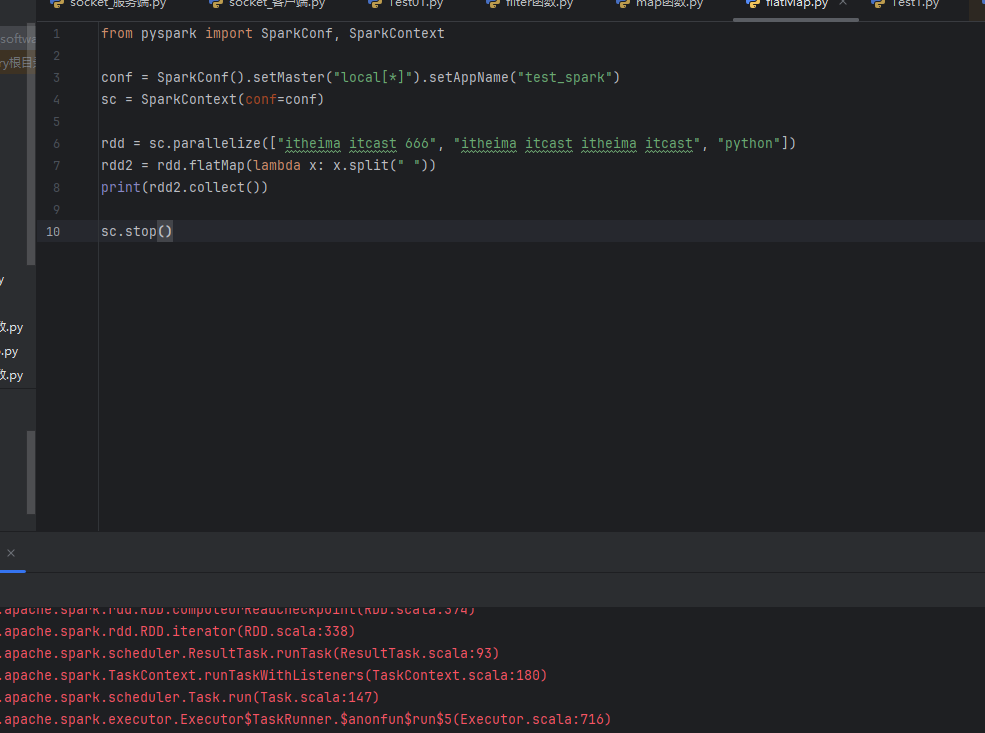
D:\software\Python\Projects\pyecharts\.venv\Scripts\python.exe D:\software\Python\Projects\pyecharts\数据处理\flatMap.py
WARNING: Using incubator modules: jdk.incubator.vector
Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
26/04/06 16:21:44 ERROR Executor: Exception in task 2.0 in stage 0.0 (TID 2)
org.apache.spark.SparkException: Python worker failed to connect back.
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:281)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:154)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:158)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:309)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:72)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:374)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:338)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:93)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:180)
at org.apache.spark.scheduler.Task.run(Task.scala:147)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$5(Executor.scala:716)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally(SparkErrorUtils.scala:86)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally$(SparkErrorUtils.scala:83)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:97)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:719)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635)
at java.base/java.lang.Thread.run(Thread.java:840)
Caused by: java.net.SocketTimeoutException: Timed out while waiting for the Python worker to connect back
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:263)
... 17 more
26/04/06 16:21:44 WARN TaskSetManager: Lost task 2.0 in stage 0.0 (TID 2) (CHINAMI-G8GC0PN executor driver): org.apache.spark.SparkException: Python worker failed to connect back.
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:281)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:154)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:158)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:309)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:72)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:374)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:338)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:93)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:180)
at org.apache.spark.scheduler.Task.run(Task.scala:147)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$5(Executor.scala:716)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally(SparkErrorUtils.scala:86)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally$(SparkErrorUtils.scala:83)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:97)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:719)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635)
at java.base/java.lang.Thread.run(Thread.java:840)
Caused by: java.net.SocketTimeoutException: Timed out while waiting for the Python worker to connect back
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:263)
... 17 more
26/04/06 16:21:44 ERROR TaskSetManager: Task 2 in stage 0.0 failed 1 times; aborting job
Traceback (most recent call last):
File "D:\software\Python\Projects\pyecharts\数据处理\flatMap.py", line 8, in <module>
print(rdd2.collect())
~~~~~~~~~~~~^^
File "D:\software\Python\Projects\pyecharts\.venv\Lib\site-packages\pyspark\core\rdd.py", line 1700, in collect
sock_info = self.ctx._jvm.PythonRDD.collectAndServe(self._jrdd.rdd())
File "D:\software\Python\Projects\pyecharts\.venv\Lib\site-packages\py4j\java_gateway.py", line 1362, in __call__
return_value = get_return_value(
answer, self.gateway_client, self.target_id, self.name)
File "D:\software\Python\Projects\pyecharts\.venv\Lib\site-packages\py4j\protocol.py", line 327, in get_return_value
raise Py4JJavaError(
"An error occurred while calling {0}{1}{2}.\n".
format(target_id, ".", name), value)
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 2 in stage 0.0 failed 1 times, most recent failure: Lost task 2.0 in stage 0.0 (TID 2) (CHINAMI-G8GC0PN executor driver): org.apache.spark.SparkException: Python worker failed to connect back.
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:281)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:154)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:158)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:309)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:72)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:374)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:338)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:93)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:180)
at org.apache.spark.scheduler.Task.run(Task.scala:147)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$5(Executor.scala:716)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally(SparkErrorUtils.scala:86)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally$(SparkErrorUtils.scala:83)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:97)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:719)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635)
at java.base/java.lang.Thread.run(Thread.java:840)
Caused by: java.net.SocketTimeoutException: Timed out while waiting for the Python worker to connect back
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:263)
... 17 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$3(DAGScheduler.scala:3122)
at scala.Option.getOrElse(Option.scala:201)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:3122)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:3114)
at scala.collection.immutable.List.foreach(List.scala:323)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:3114)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1303)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1303)
at scala.Option.foreach(Option.scala:437)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1303)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:3397)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:3328)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:3317)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:50)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:1017)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2496)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2517)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2536)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2561)
at org.apache.spark.rdd.RDD.$anonfun$collect$1(RDD.scala:1057)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:417)
at org.apache.spark.rdd.RDD.collect(RDD.scala:1056)
at org.apache.spark.api.python.PythonRDD$.collectAndServe(PythonRDD.scala:205)
at org.apache.spark.api.python.PythonRDD.collectAndServe(PythonRDD.scala)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:77)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:569)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:374)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:184)
at py4j.ClientServerConnection.run(ClientServerConnection.java:108)
at java.base/java.lang.Thread.run(Thread.java:840)
Caused by: org.apache.spark.SparkException: Python worker failed to connect back.
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:281)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:154)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:158)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:309)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:72)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:374)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:338)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:93)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:180)
at org.apache.spark.scheduler.Task.run(Task.scala:147)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$5(Executor.scala:716)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally(SparkErrorUtils.scala:86)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally$(SparkErrorUtils.scala:83)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:97)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:719)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635)
... 1 more
Caused by: java.net.SocketTimeoutException: Timed out while waiting for the Python worker to connect back
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:263)
... 17 more
进程已结束,退出代码为 1

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)