RNN、LSTM 与 BiLSTM 算法详解
NLP-AHU-(学号开头D)010
在处理序列数据(如文本、语音、时间序列)时,循环神经网络(RNN)及其改进版本 LSTM 和 BiLSTM 是深度学习中的重要模型。本文将系统介绍它们的设计启发、核心结构、算法细节及数学表达。
一、RNN(循环神经网络)
1.1 设计启发
RNN 的出现是为了解决传统前馈神经网络在序列建模中的固有缺陷,其设计灵感源于人类认知中的“记忆”机制。传统全连接网络或 CNN 在处理序列数据时存在以下局限:
- 输入长度固定:无法处理不同长度的句子或音频。
- 无法捕捉时序依赖:假设输入彼此独立,无法理解诸如“我吃了一个蛋挞,它很甜”中代词“它”的指代关系。
- 参数无法共享:若为每个序列位置设置独立参数,参数量会急剧增加。
RNN 的核心思想是通过循环结构和权重共享机制,使网络在每一步都拥有可以传递历史信息的“隐藏状态”,从而可以处理任意长度序列并捕捉时序依赖。
1.2 核心结构
- 循环单元:RNN 的基本单元会在时间维度上被“展开”,每个时间步使用相同的循环单元。
- 权重共享:所有时间步共享同一套权重
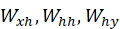 ,保证参数量不会随序列长度增加而爆炸。
,保证参数量不会随序列长度增加而爆炸。 - 隐藏状态 ht
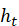 :作为“记忆”载体,每个时间步的隐藏状态会传递到下一步,实现信息在时间上的流动。
:作为“记忆”载体,每个时间步的隐藏状态会传递到下一步,实现信息在时间上的流动。
1.3 算法细节与数学表达
(1) 前向传播
对于时间步 t![]() :
:
- 隐藏状态更新(记忆更新):
![]()
- 输出计算:
![]()
说明: ![]() :当前输入
:当前输入 ![]() :上一时间步的隐藏状态
:上一时间步的隐藏状态 ![]() :权重矩阵
:权重矩阵 ![]() :偏置项 - 激活函数
:偏置项 - 激活函数 ![]() 将隐藏状态映射到
将隐藏状态映射到![]() ,softmax 用于分类任务
,softmax 用于分类任务
(2) 反向传播(BPTT)
RNN 的训练依赖时间反向传播(Backpropagation Through Time, BPTT)。其核心思想是将 RNN 按时间展开为一个深层前馈网络,然后应用标准反向传播算法。
挑战: - 梯度消失:若 ![]() 的特征值小于 1,梯度随时间指数衰减,导致模型无法学习长期依赖。 - 梯度爆炸:若特征值大于 1,梯度指数增长。
的特征值小于 1,梯度随时间指数衰减,导致模型无法学习长期依赖。 - 梯度爆炸:若特征值大于 1,梯度指数增长。
二、LSTM(长短期记忆网络)
2.1 设计启发
LSTM 是 RNN 的改进版本,专门解决长期依赖问题和梯度消失问题。灵感来源于计算机逻辑门和人类信息筛选机制。
核心思想: - 在 RNN 隐藏状态之外引入记忆元(Cell State) - 通过遗忘门、输入门和输出门控制信息的读写和遗忘 - 选择性记忆重要信息,忽略无关信息
2.2 核心结构
- 记忆元
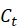 :长期记忆,缓解梯度消失问题
:长期记忆,缓解梯度消失问题 - 隐藏状态
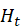 :短期记忆,用于输出和传递
:短期记忆,用于输出和传递 - 三个门控:
- 遗忘门(Forget Gate)
- 输入门(Input Gate)
- 输出门(Output Gate)
每个门由 Sigmoid 层和逐点乘法操作构成,Sigmoid 输出![]() ,表示门的开闭程度。
,表示门的开闭程度。
2.3 算法细节与数学表达
对于时间步![]() :
:
- 遗忘门:
![]()
- 输入门与候选记忆元:
![]()
![]()
- 记忆元更新:
![]()
- 输出门与隐藏状态:
![]()
![]()
注:⊙![]() 表示逐元素乘法。LSTM 的加法结构让梯度在反向传播时顺畅流动,有效缓解梯度消失。
表示逐元素乘法。LSTM 的加法结构让梯度在反向传播时顺畅流动,有效缓解梯度消失。
三、BiLSTM(双向长短期记忆网络)
3.1 设计启发
尽管 LSTM 强大,但它是单向的,仅能利用过去信息。在 NLP 等任务中,一个词的语义受前后上下文共同影响。BiLSTM 希望在任意时间步同时看到过去和未来的信息。
3.2 核心结构
- 前向 LSTM:从
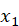 到
到 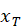 顺序读取输入
顺序读取输入 - 后向 LSTM:从
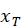 到
到 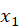 逆序读取输入
逆序读取输入 - 最终输出由两个 LSTM 隐藏状态拼接而成
3.3 算法细节与数学表达
对于时间步 ![]() :
:
![]()
拼接后的 ![]() 同时包含该时间步前后(整个序列)的上下文信息,显著提升模型性能。
同时包含该时间步前后(整个序列)的上下文信息,显著提升模型性能。
计算量和参数量大约是单向 LSTM 的两倍,且不适用于需要严格因果关系的任务(如实时语音识别)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)