[小结]-Ai技术盘点
·
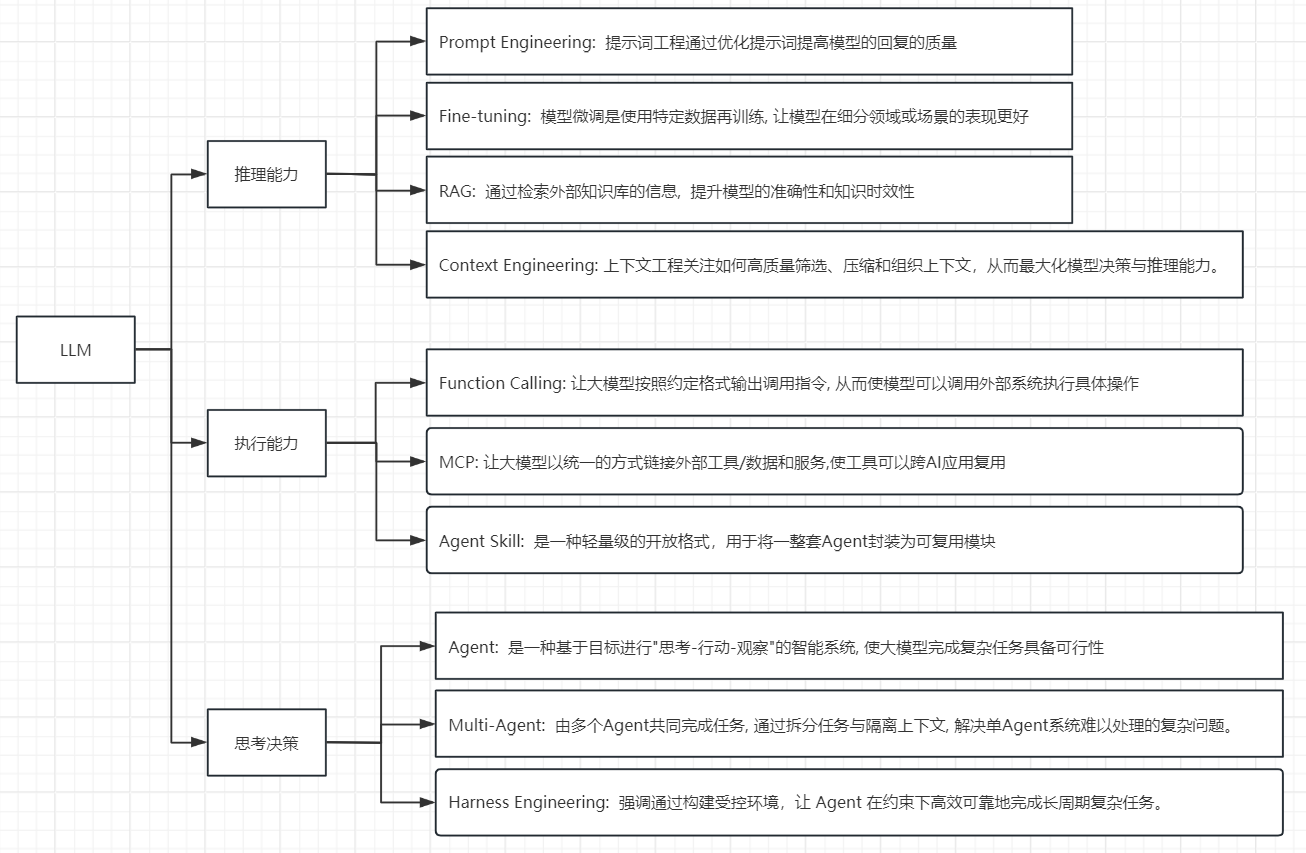
LLM
- LLM就是大语言模型的简称, 旨在理解和生成人类的自然语言
- Transformer架构的提出奠定了大模型时代基础,使基于注意力机制的生成模型成为主流。
- Decoder-Only(仅解码器)的Transformer 架构变体是当下最为主流的架构。
- 整个大模型的训练可以分为预训练和后训练两个个阶段

- LLM的架构图
- 推荐文章: https://arxiv.org/abs/1706.03762
- 在LLM的早期阶段, 最佳的应用就聊天机器人
Prompt Engineering
- Prompt Engineering简称提示词工程
- 有了chat bot这类应用后, 再使用的过程中, 我们发现, 同一个聊天框, 问差不多的问题, 得到的结果的质量有很大的差异, 人们开始关注提示词
- 提示词(Prompt)是用来引导模型按照特定意图生成输出的输入指令
- 主要包含「系统提示词」和「用户提示词」。
- 提示词工程通过设计和优化提示词,使大模型更准确、可控地产生所需输出。
- 是一种提升效果但不改变模型智力(参数)的低成本调优手段。
- 推荐文章 https://www.aneasystone.com/archives/2024/01/prompt-engineering-notes.html
Fine-tuning微调
- 微调是在已有模型基础上,用特定数据再训练,让模型更适合某个具体任务或场景。
- 微调要训练的是模型的参数。早期模型微调是非常耗费时间和高成本的事情, 属于富人的游戏
- 大概的微调流程: 先准备数据集, 清洗数据, 再准备GPU, 运行模型, 最后微调模型
- LoRA算法通过只训练少量低秩参数来进行微调,大幅降低了训练成本。
- LORA介绍:
- 随着基座大模型的快速进度, 现在模型的微调也面临挑战, 比如你微调了几个月, 让模型再某个细分领域的理解能力获取了一些提升, 但是大模型的一个版本迭代, 你的优势瞬间被抹平, 所以模型微调是一个成本确定而价值不确定的技术
RAG
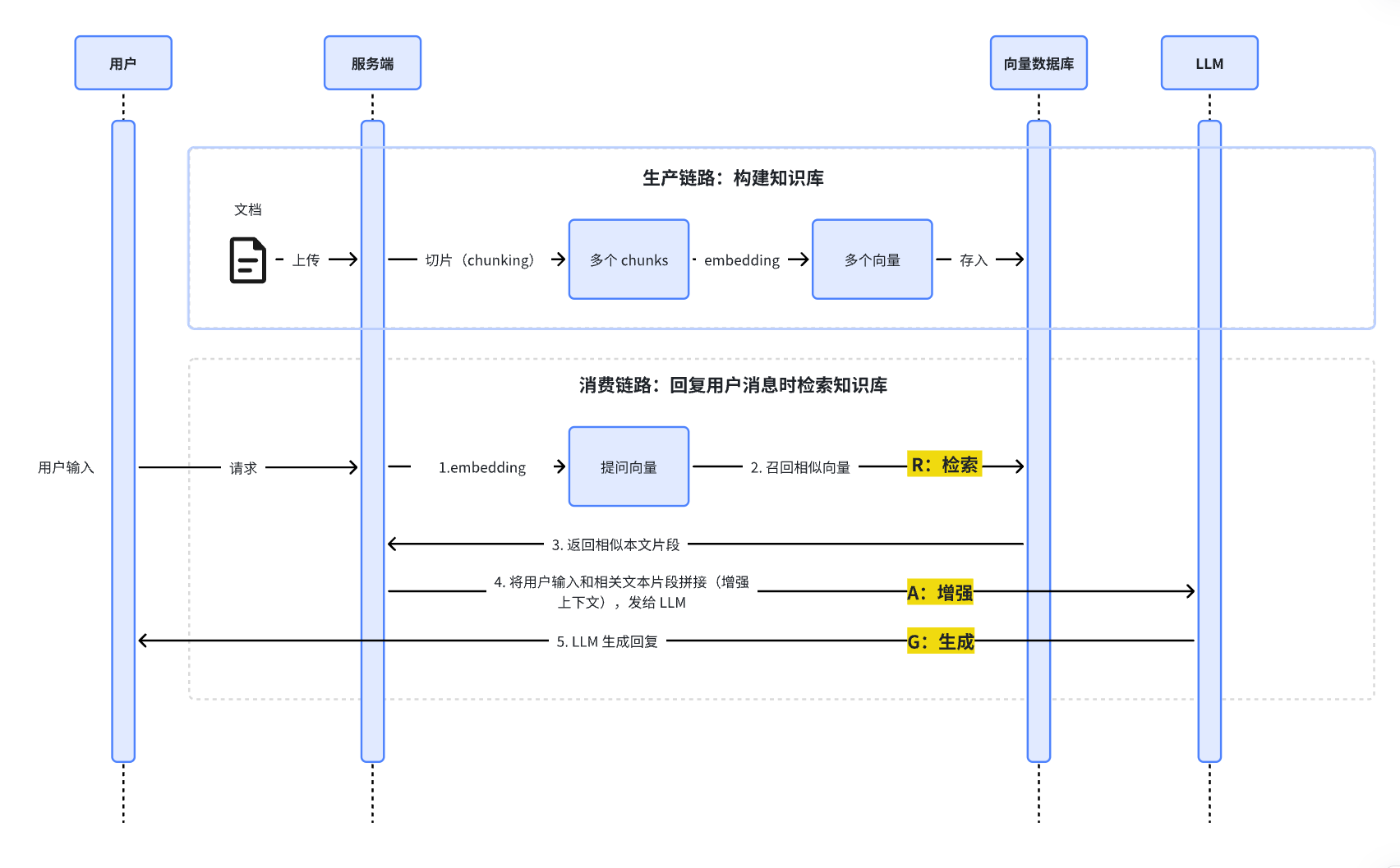
- RAG简称检索增强技术, 可以理解为本地知识库
- RAG架构
- 上面说的模型微调, 成本还是比较高的, 因为本质还是通过训练改变模型的能力
- 大模型的训练依赖网上的公开数据, 在细分领域和缺乏公开资料的领域, 大模型就容易出现幻觉和失效问题
- 知识库就是一种成本比较低的优化手段, 本质是把本地知识和用户提示词一起扔给大模型, 因为有了一些本地知识的补充, 再依靠大模型的强大推理能力, 使大模型在细分领域的表现更靠谱
- 大体流程: 先从外部知识库检索相关信息,再结合这些信息一起生成回答,从而提升模型的准确性和知识时效性。
- 相关文章: https://arxiv.org/abs/2005.11401
Function call
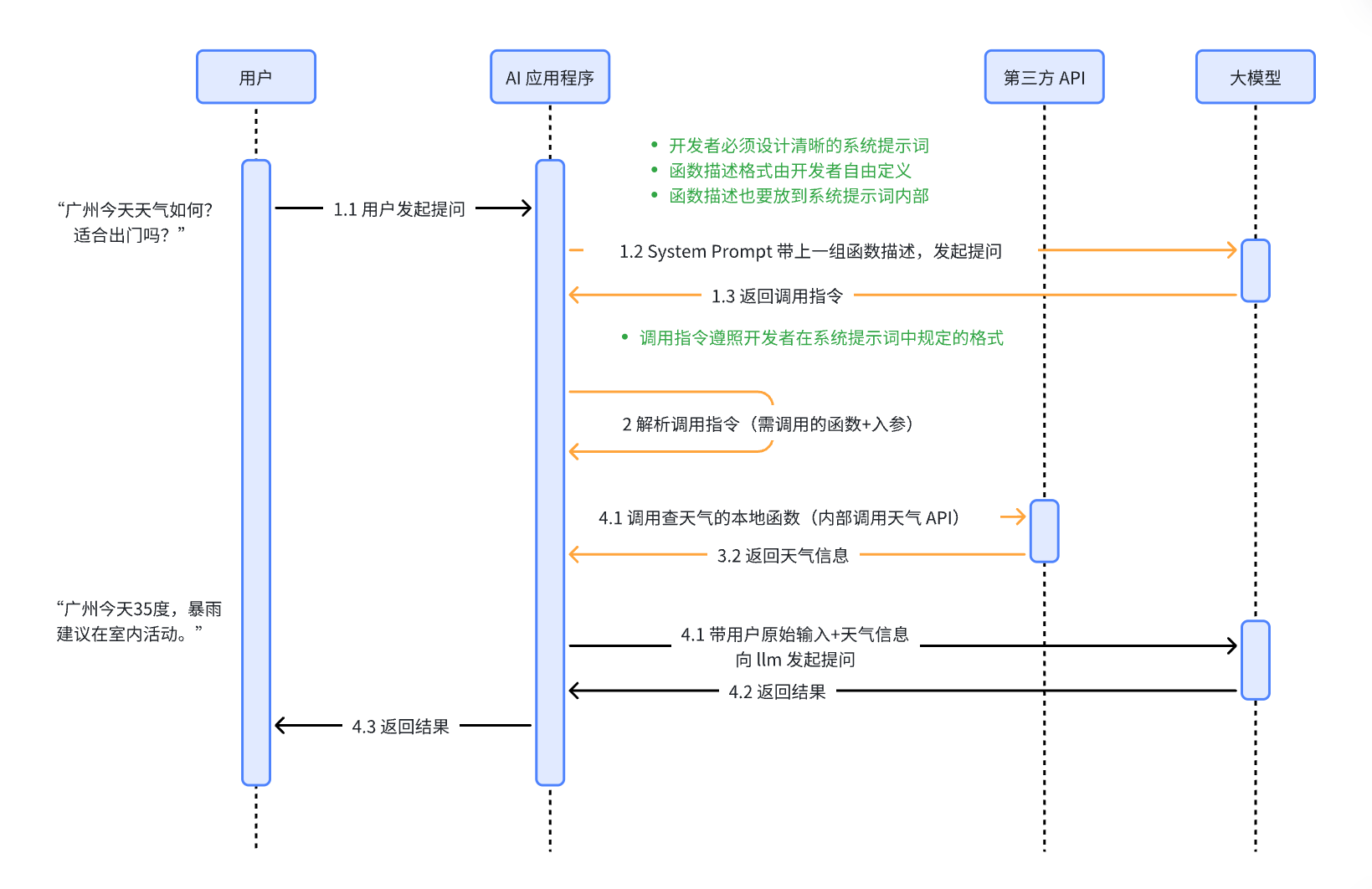
- Function Call是让大模型按照约定格式输出调用旨令,从而由外部系统真正去执行具体操作的一种机制。
- Function Calling让模型从“只会说话”变为“会调用工具”
- Function Call的本质是想通过工程手段, 让模型可以调用工具, 简单来讲就是模型只负责思考, 具体做事还是依赖各家自己提供能力
- 交互时序图
MCP
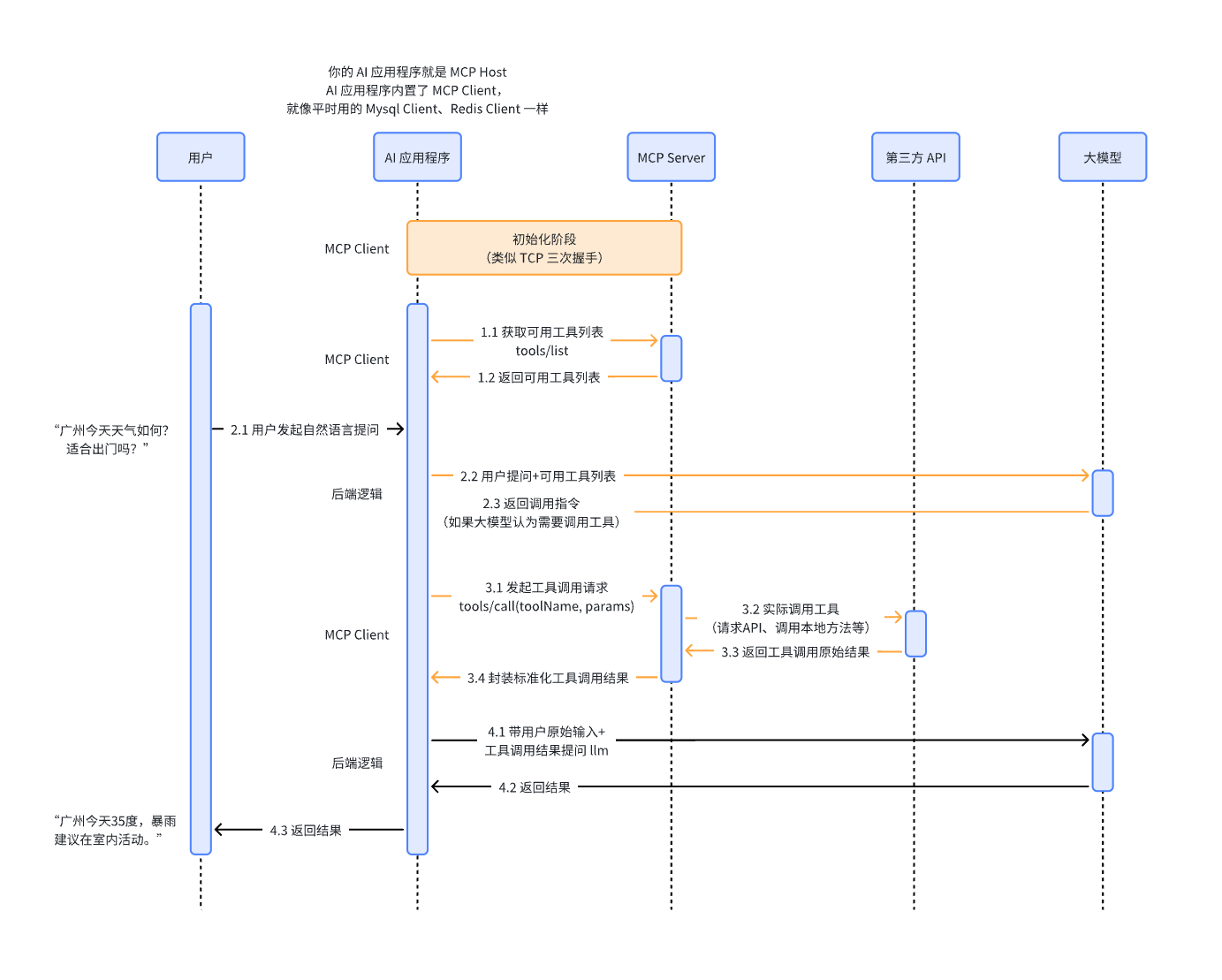
- Model Context Protocol简称模型上下文协议
- 是一种标准化协议,用来让大模型以统一的方式连接外部工具、数据源和服务,从而获取上下文信息并执行操作。
- MCP最重要的贡献之一是使工具可以跨AI应用复用,推动社区生态发展。
- 交互时序图
Agent
- Agent是一种能够基于目标进行"思考-行动-观察"盾环、能够自主调用工具来完成复杂任务的智能系统。
- Agent本质是对人类的模拟,
- 提示词 + LLM + Tools就可以构成一个最简单的Agent
- Agent Loop:思考 → 行动 → 观察
- 相关文章
- https://arxiv.org/abs/2210.03629?utm_source=chatgpt.com
- https://x.com/HiTw93/status/2034627967926825175
- https://x.com/HiTw93/status/2034627967926825175(https://tw93.fun/2026-03-21/agent.html)
- Agent 设计模式
-
- https://medium.com/binome/ai-agent-workflow-design-patterns-an-overview-cf9e1f609696
- https://mp.weixin.qq.com/s/7CZ6cHWQ-T9bmaWoJFwdwA
Multi-Agent
- Multi-Agent 是一种多智能体技术
- 由多个分工协作的Agent共同完成任务,通过拆分任务与隔离上下文解决单Agent系统难以处理的复杂问题。
- 需要谨慎使用以避免Token消耗量大、协作效率低、系统复杂度过高等问题。
- 单Agent和多Agenr不是竞争关系, 而是合作关系, 多Agent的出现是因为早期单个Agent的能力实在有限, 所以通过分工的形式来解决复杂问题, 随着发展, 单Agent已经可以解决很多问题了且成本低
- 相关文章:
- https://claude.com/blog/building-multi-agent-systems-when-and-how-to-use-them
Context Engineering
- Agent运行中需要提供给LLM的一切相关信息(如对话历史、用户输入、背景知识、工具结果等)都是上下文。
- 上下文工程关注如何高质量筛选、压缩和组织上下文,从而最大化模型决策与推理能力。
- 相关文章
- 【Lanchain】Context Engineering(lanchain)
- Effective context engineering for AI agents(Anthropic)
- https://mp.weixin.qq.com/s/KbviOJ6q-K4ik_wzsUs2dw?open_in_browser=true
Agent Skill
- 可以理解为Agent安装包, 别人写好的Agent打包发给我, 我安装在工程中, 就能复用能力
- Agent Skills是一种轻量级的开放格式,用于将一整套Agent 能力(prompt、工具脚本、知识文件等)封装为可复用模块,从而实现低门槛分享与复用。
- Agent Skill本质上约等于一个子Agent。
- Agent Skill特别适合SOP的沉淀和复用(离职的同事终将化作温暖的SkilI)
- Agent会在运行过程中按需激活不同 Skills、按需读取和使用 Skills文件包里的内容(渐进式披露)
- 相关文章
- https://claude.com/blog/equipping-agents-for-the-real-world-with-agent-skills
- https://platform.claude.com/docs/en/agents-and-tools/agent-skills/overview
- https://agentskills.io/home
OpenClaw
- OpenClaw 是一款开源、高可扩展的AI Agent框架,基于TypeScript开发,核心用途是构建可自定义的私人AI助手。
- 创新之一是拓展了Agent的交互入口(飞书等)
- openclaw 代码太长了,可以看精简版 nanobot:https://github.com/HKUDS/nanobot
Harness Engineering
- Harness Engineering 强调通过构建受控环境,让 Agent 在约束下高效可靠地完成长周期复杂任务。
- 包含围绕Agent构建约束机制、反馈回路、可靠上下文等等一系列工程实践。
- 相关文章:
- https://openai.com/zh-Hans-CN/index/harness-engineering/
Claude Code源码
- https://github.com/instructkr/claw-code
- https://github.com/hesreallyhim/claude-code-fork
- https://www.youtube.com/watch?v=DXTS82fJO9A
结语:
现在AI还处于大基建时代, 所以先技术层出不穷, 一样一样的学透还是很难的, 但是理清楚他们的来龙去脉比较容易, 也能让我们面对新技术时不再那么迷茫和头疼
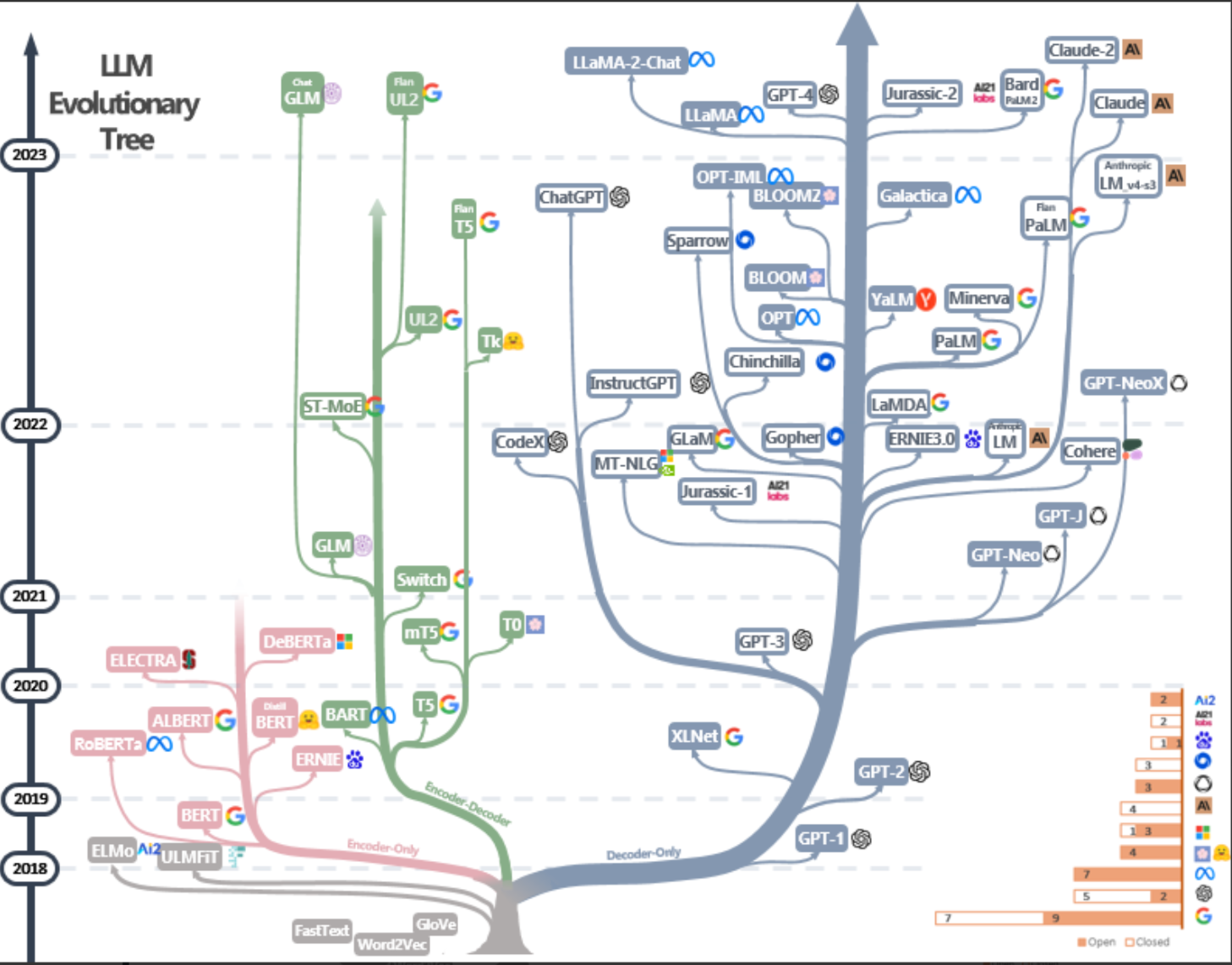
- 整个大模型的发展可以看作三条路径

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 42
42 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)