从 RNN 到 LSTM 再到 BiLSTM:循环神经网络的进化与原理详解
NLP-AHU-102
在接触深度学习的过程中,我一直有一个疑问:为什么传统的神经网络无法处理自然语言?直到学习了循环神经网络(RNN)及其变体,我才明白问题的核心在于时序依赖。
我们人类理解一句话,是一个顺序的、上下文关联的过程。比如当你读到 “我昨天去了超市,买了牛奶和面包" 时,你会自动将 "买了" 和前面的 "超市" 联系起来。但传统的全连接神经网络和卷积神经网络,只能处理独立的输入,无法记住之前的信息。
这篇博客是我学习 RNN、LSTM 和 BiLSTM 的笔记整理,我会尽量从设计动机出发,一步步推导每个模型的结构和数学公式,希望能帮助和我一样的初学者理解这些经典的时序模型。
一、RNN:循环神经网络的诞生与局限
1.1 设计灵感:模拟人类的短期记忆
RNN 的全称是 Recurrent Neural Network,直译过来就是 "循环神经网络"。它的设计灵感非常朴素:既然数据是按顺序出现的,那么我们就按顺序处理它,并且让模型记住之前处理过的内容。
这就像我们读书一样,我们不会把每一页都当成独立的内容来读,而是会记住前面的情节,来理解后面的故事。RNN 通过一个循环连接来实现这个 "记忆" 功能。
1.2 网络结构与展开图
RNN 的核心是一个循环单元,它在每个时间步都会接收两个输入:
- 当前时刻的输入
- 上一时刻的隐藏状态
然后输出两个结果:
- 当前时刻的隐藏状态
(传递给下一个时间步)
- 当前时刻的输出
(任务相关的输出)
图 1:RNN 循环结构与展开图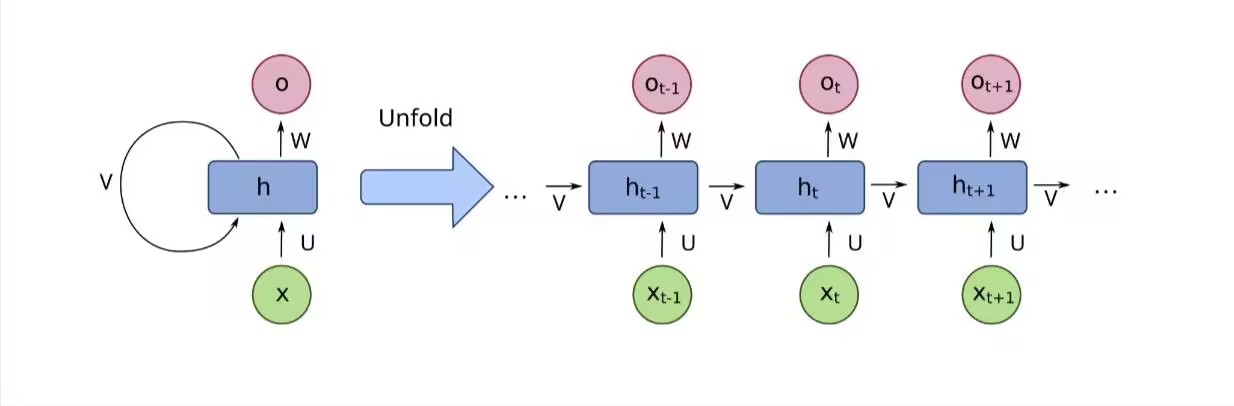
图 1 说明:左边是 RNN 的循环结构示意图,右边是将其按时间步展开后的结构。可以看到,RNN 在所有时间步共享同一套参数,这大大减少了模型的参数量。
1.3 详细数学推导
RNN 的计算过程可以用两个公式来表示:
-
隐藏状态更新公式
这里我选择用 tanh 作为激活函数,这是最常用的选择。tanh 函数的取值范围是(−1,1),可以将输出归一化到这个区间内。
-
输出计算公式
输出层的激活函数取决于具体的任务:
- 如果是分类任务,使用 softmax 激活函数
- 如果是回归任务,不使用激活函数或使用线性激活函数
1.4 致命缺陷:梯度消失与梯度爆炸
RNN 的设计看起来很完美,但在实际应用中却存在一个致命的问题:无法处理长序列。这是由反向传播算法的特性导致的。
在训练 RNN 时,我们使用的是随时间反向传播(BPTT)算法。简单来说,就是将展开后的 RNN 看作一个深度神经网络,然后从最后一个时间步向前传播梯度。
对于第 t 个时间步的隐藏状态ht,它对第 1 个时间步的隐藏状态h1的梯度为:
,
这是一个连乘的形式!如果Whh的最大特征值小于 1,那么多次连乘后梯度会趋近于 0,这就是梯度消失;如果最大特征值大于 1,梯度会趋近于无穷大,这就是梯度爆炸。
图 2:RNN 梯度消失示意图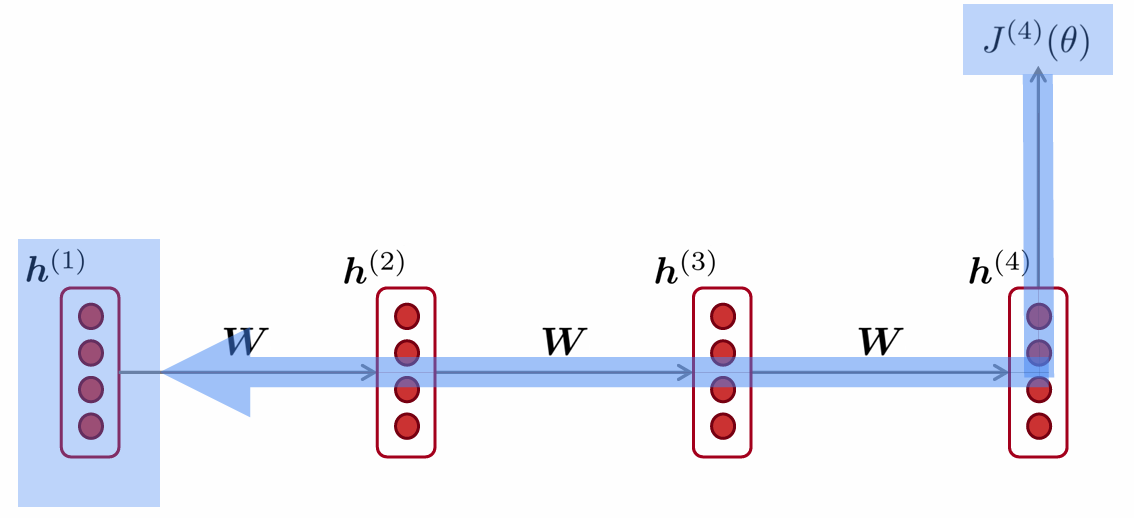
图 2 说明:图中展示了 RNN 按时间步展开后的时间反向传播(BPTT)梯度流:以最后一个时间步的损失为起点,梯度沿时间步从右向左指数级衰减。该现象导致 RNN 无法有效学习序列中的长距离依赖关系,即早期时间步的信息无法通过梯度更新传递到模型参数。
举个例子,如果我们有一句话:"我出生在法国,……(中间隔了 50 个单词),我能流利地说____"。RNN 模型因为梯度消失,无法记住 50 个单词之前的 "法国",因此很难预测出空格处应该填 "法语"。
二、LSTM:长短期记忆网络的突破
2.1 设计动机:解决 RNN 的长距离依赖问题
为了解决 RNN 的梯度消失问题,Hochreiter 和 Schmidhuber 在 1997 年提出了 LSTM(Long Short-Term Memory)网络。
LSTM 的核心思想是:既然梯度消失是因为连乘导致的,那么我们就用加法来代替乘法。LSTM 引入了一个细胞状态(Cell State),它像一条传送带一样,在整个序列中线性地传递信息,只有少量的线性交互,从而避免了梯度的指数级衰减。同时,LSTM 设计了三个门控结构来控制细胞状态的信息流动:
- 遗忘门:决定从细胞状态中丢弃哪些信息。
- 输入门:决定哪些新信息存入细胞状态。
- 输出门:决定细胞状态中哪些信息输出到隐藏状态。
2.2 LSTM 单元的详细结构
图 3:LSTM 单元内部结构图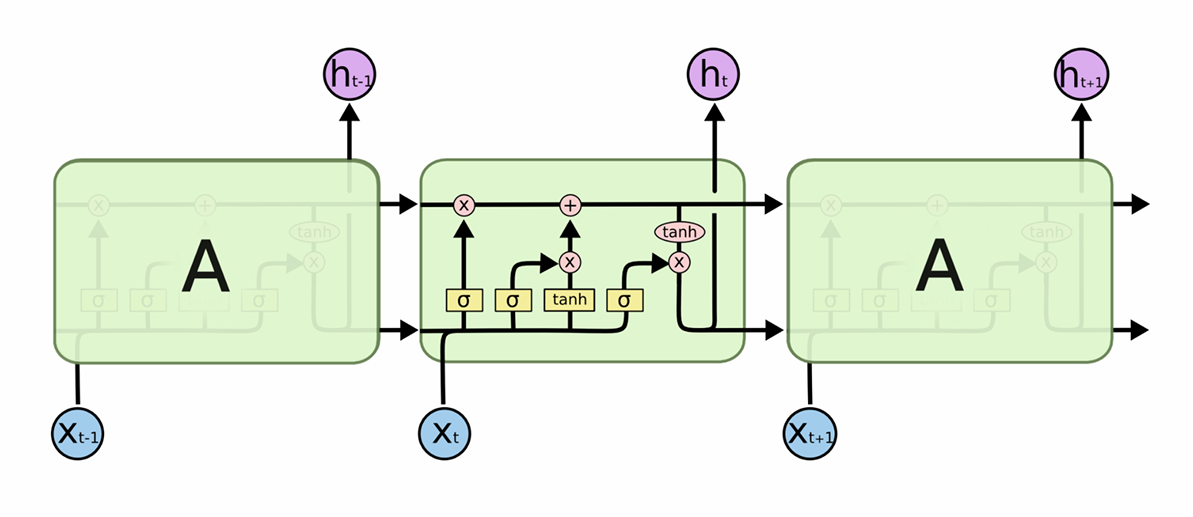
图 3 说明:这是 LSTM 单元的标准内部结构图,清晰地展示了三个门和细胞状态的信息流动。这张图是理解 LSTM 的关键,建议大家多看几遍。
2.3 逐门数学推导
下面我将一步步推导 LSTM 每个门的计算过程,所有的公式都基于图 3 的结构。
2.3.1 遗忘门(Forget Gate)
遗忘门的作用是决定从细胞状态中丢弃哪些信息。它接收上一时刻的隐藏状态 和当前时刻的输入
,输出一个 0 到 1 之间的值ft。
,
其中:
- σ是 sigmoid 激活函数,它将输出压缩到 [0,1] 区间。
表示将两个向量拼接在一起。
- ft的每个元素对应细胞状态
的一个元素,1 表示 "完全保留",0 表示 "完全丢弃"。
2.3.2 输入门(Input Gate)
输入门的作用是决定哪些新信息存入细胞状态。它分为两步:
- 首先,用一个 sigmoid 层生成输入门的值
,决定哪些信息需要更新
。
- 然后,用一个 tanh 层生成候选细胞状态
,这是待存入的新信息
。
2.3.3 细胞状态更新(Cell State Update)
这是 LSTM 最核心的一步,也是解决梯度消失问题的关键。我们用加法来更新细胞状态:
,
其中⊙表示哈达玛积(对应元素相乘)。
2.3.4 输出门(Output Gate)
输出门的作用是决定细胞状态中哪些信息输出到隐藏状态。它也分为两步:
- 首先,用一个 sigmoid 层生成输出门的值
。
- 然后,将细胞状态通过 tanh 函数处理后,与输出门的值相乘,得到当前时刻的隐藏状态
。
2.4 LSTM 为什么能解决梯度消失?
很多教程只是说 LSTM 能解决梯度消失,但没有解释为什么。其实原因很简单。在反向传播时,细胞状态的梯度为:
,
遗忘门 的值通常接近 1,所以
的值也接近 1。这样,梯度在细胞状态这条路径上传播时,不会出现指数级衰减,从而可以学习到长距离的依赖关系。
三、BiLSTM:双向长短期记忆网络
3.1 设计动机:利用上下文双向信息
无论是 RNN 还是 LSTM,都是单向模型。它们只能从左到右处理序列,只能利用 "前文信息",无法利用 "后文信息"。但在很多自然语言处理任务中,语义是双向依赖的。比如下面这个例子:
"他____了一个苹果。"
如果只看前文 "他",我们无法预测空格处应该填什么。但如果看后文 "一个苹果",我们就可以推断出空格处可能是 "吃"、"买"、"拿" 等动词。再比如命名实体识别任务:
"乔布斯是苹果公司的创始人。"
要识别 "苹果" 是一个公司名,不仅需要看前文 "乔布斯是",还需要看后文 "公司的创始人"。为了解决这个问题,人们提出了 BiLSTM(Bidirectional LSTM),即双向长短期记忆网络。
3.2 BiLSTM 的结构与原理
BiLSTM 的结构非常简单:它由两个独立的 LSTM 层组成,一个正向 LSTM和一个反向 LSTM。
图 4:BiLSTM 结构示意图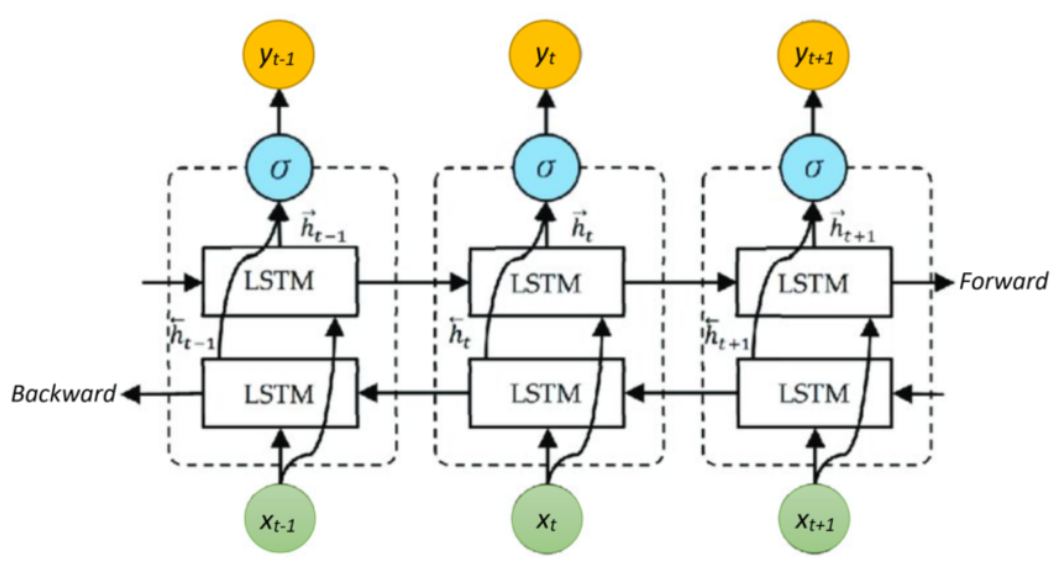
图 4 说明:展示了 BiLSTM 的结构。正向 LSTM 从左到右处理序列,反向 LSTM 从右到左处理序列,最后将两个方向的隐藏状态拼接在一起。
- 正向 LSTM:按时间步1→t处理序列,学习前文到当前的依赖关系。
- 反向 LSTM:按时间步t→1处理序列,学习后文到当前的依赖关系。
对于每个时间步 t ,BiLSTM 的最终隐藏状态ht是正向 LSTM 的隐藏状态htf和反向 LSTM 的隐藏状态htb的拼接:
,
这样, 就同时包含了前文信息和后文信息,能够更全面地表示当前词的语义。
3.3 BiLSTM 的数学表达
BiLSTM 的数学表达非常简洁:
,
其中LSTMf和LSTMb是两个独立的 LSTM 层,它们有各自的参数,互不共享。
四、三者深度对比与应用场景
为了更清晰地对比这三个模型,我整理了下面的表格:
| 模型 | 核心机制 | 记忆能力 | 上下文利用 | 计算复杂度 | 典型应用场景 |
|---|---|---|---|---|---|
| RNN | 简单循环连接 | 只能记住最近几个时间步 | 只能利用前文 | 低 | 短序列预测、简单时序回归 |
| LSTM | 门控机制 + 细胞状态 | 可以记住几百个时间步 | 只能利用前文 | 中 | 长序列预测、语音识别、机器翻译 |
| BiLSTM | 双向 LSTM 拼接 | 强 | 同时利用前文和后文 | 是 LSTM 的 2 倍 | 命名实体识别、情感分析、文本分类、问答系统 |
4.1 为什么现在 Transformer 更流行?
虽然 LSTM 和 BiLSTM 在很长一段时间内都是 NLP 任务的主流模型,但现在它们已经逐渐被 Transformer 架构所取代。主要原因有两个:
- 并行计算能力:LSTM 是顺序计算的,必须等前一个时间步计算完成后才能计算下一个时间步,无法并行。而 Transformer 的自注意力机制可以并行计算整个序列,大大提高了训练速度。
- 长距离依赖建模能力:虽然 LSTM 比 RNN 强,但它的长距离依赖能力仍然有限。而 Transformer 的自注意力机制可以直接计算序列中任意两个位置的依赖关系,建模能力更强。
不过,LSTM 和 BiLSTM 依然是非常重要的基础模型。它们的设计思想(门控机制、记忆机制)对后来的深度学习模型产生了深远的影响。而且在一些小数据集、低资源的场景下,LSTM 和 BiLSTM 的表现依然很好。
五、学习感悟与总结
通过这次学习,我深刻体会到了深度学习模型的进化逻辑:发现问题→分析问题根源→针对性地改进模型。
- RNN 发现了传统神经网络无法处理时序数据的问题,提出了循环结构来模拟记忆。
- LSTM 发现了 RNN 梯度消失的问题,提出了细胞状态和门控机制来解决。
- BiLSTM 发现了单向模型无法利用后文信息的问题,提出了双向拼接的结构。
这三个模型层层递进,每一个都解决了前一个模型的核心缺陷。这种 "问题驱动" 的研究思路,值得我们每一个学习者学习。当然,这篇博客只是对 RNN、LSTM 和 BiLSTM 的基础介绍。如果想要更深入地理解它们,还需要动手实现代码,在实际任务中体验它们的效果。
六、参考文献
[1] Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural computation, 1997, 9(8): 1735-1780.
[2] Graves A, Mohamed A R, Hinton G. Speech recognition with deep recurrent neural networks[C]//2013 IEEE international conference on acoustics, speech and signal processing. IEEE, 2013: 6645-6649.
[3] Schuster M, Paliwal K K. Bidirectional recurrent neural networks[J]. IEEE transactions on Signal Processing, 1997, 45(11): 2673-2681.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)