AI coding编程体验之一
1. 工具
关于AI编程工具,我首先尝试了阿里的Qwen Code, 然后尝试Claude Code, 最后尝试Open Code, 阿里自己好像都没怎么推广,Claude对应的服务器模型opus我们又用不上,本着优先使用开源工具原则,最后选择主要使用Open Code, 不放弃尝试对比Claude Code。
由于真实项目所在行业的特殊性,不大可能把源代码上传提供给远程大模型服务器,还是需要自己搭建本地内网大模型服务,原则上使用哪个客户端工具相差不大,主要是选择的开源大模型功能够强大。
2. 方法论
看了很多微信推文,有两种方法论:spec coding和vibe coding。
2.1 Spec Coding 与 Vibe Coding 的定义
Spec Coding(规格编程)指严格遵循预先定义的技术规范、需求文档或设计文档进行开发。开发者需完全按照书面要求实现功能,强调可预测性和可验证性,通常出现在合同制项目或安全关键系统中。
Vibe Coding(氛围编程)更注重开发者的直觉、创意或团队文化,代码风格和实现方式可能随团队习惯或个人偏好调整。常见于初创公司或敏捷环境中,强调快速迭代和灵活性。
2.2 核心区别
目标导向
- Spec Coding:以合规性为核心,确保代码与需求文档100%匹配。
- Vibe Coding:以解决问题为核心,允许灵活调整实现路径。
流程控制
- Spec Coding:依赖严格的代码审查、测试用例和验收标准。
- Vibe Coding:依赖团队共识或主导者的技术决策。
适用场景
- Spec Coding:航空航天、医疗软件、金融系统等高风险领域。
- Vibe Coding:MVP开发、内部工具或文化开放的团队。
2.3 潜在联系
互补性
两者可结合使用,例如在关键模块采用Spec Coding确保稳定性,非核心模块使用Vibe Coding提升开发速度。
文化影响
团队若过度依赖Vibe Coding可能导致技术债务,而极端Spec Coding可能抑制创新。平衡点需根据项目风险调整。
2.4 实践建议
选择依据
- 评估项目对可靠性、合规性的要求程度。
- 考虑团队的技术成熟度和协作模式。
混合模式案例
- 定义核心接口的Spec标准,允许非核心逻辑自由实现。
- 通过自动化测试保证基础质量,保留局部创新空间。
3. 一个内部使用小项目llmmaster
当我把vLLM服务搭建起来,让产品人员体验开源大模型效果,和互联网大厂家商业功能对比,总不能让他们自己写Python来测试,需要给一个web聊天界面,和平时用的外网一样方便才行,于是刚好用OpenCode来练手体验一下。
手写一份 requirements.md,其实是在互联网某家AI web上生成的,自己修改补充了一下。
# LLM Master - 大模型管理系统
## 1. 项目概述
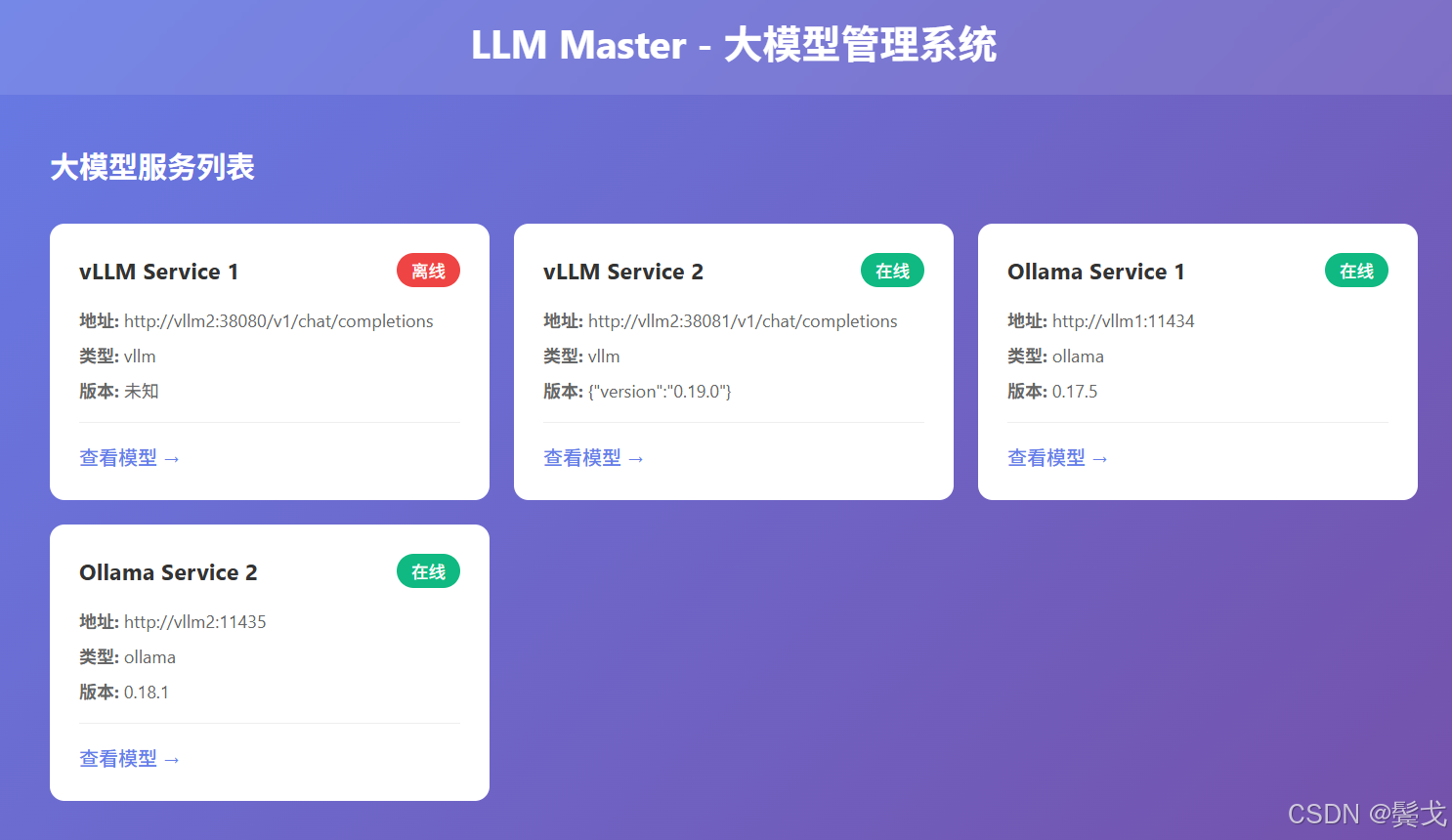
- **目标**:开发一个大模型管理系统,支持连接多个 Ollama 和 多个 vLLM 提供的模型服务, 用户在前端界面上可以选择具体模型进行聊天。
- **核心功能**:
1. 根据配置列出大模型服务列表
2. 列出一个大模型服务中的所有具体模型
3. 选择一个具体的大模型,可以在界面上进行聊天交互
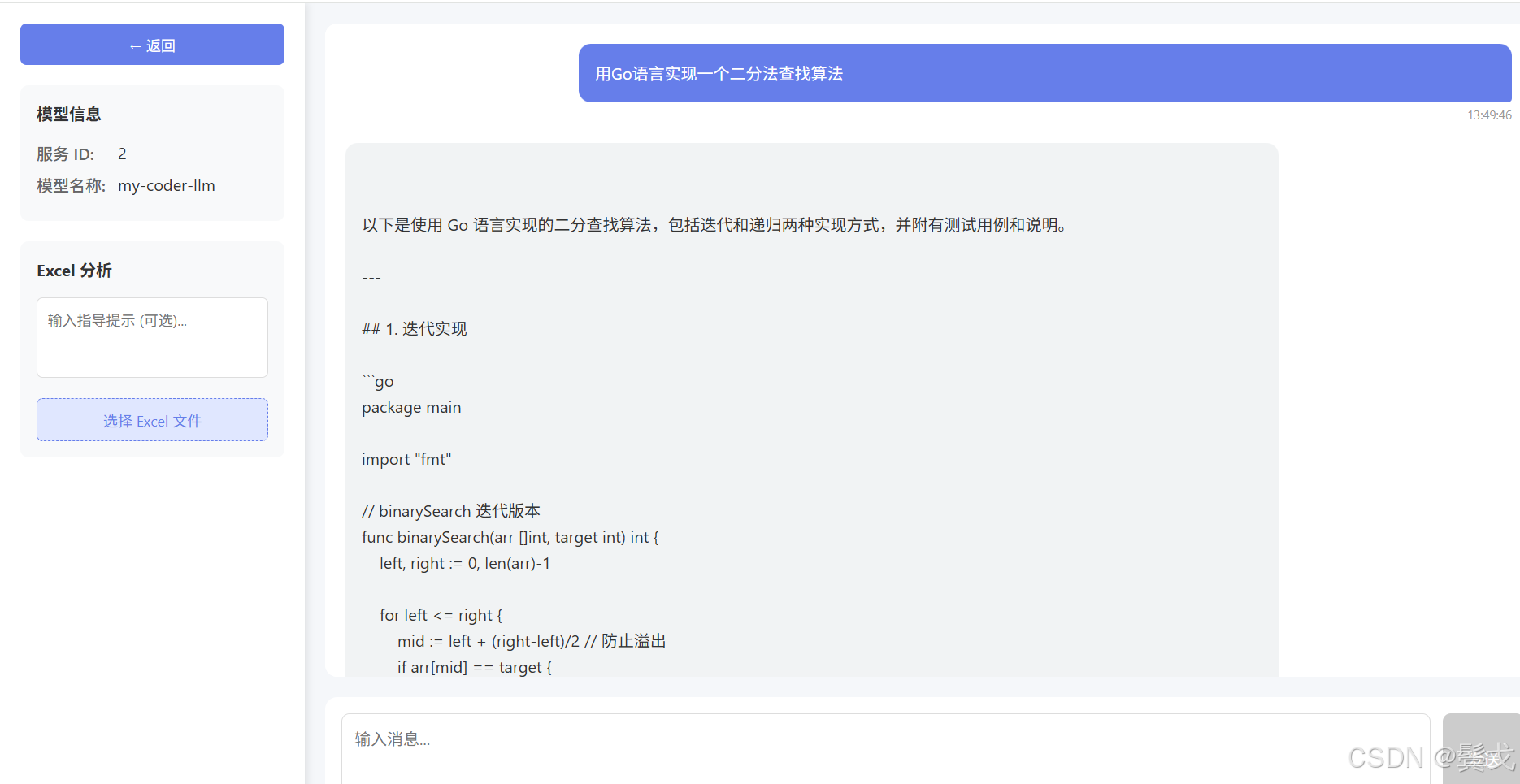
4. 支持上传一个excel表格,让大模型进行统计分析
## 2. 技术栈要求
- **开发语言**:Python 3.10+
- **核心库**:
- Fast API: 提供API接口服务
- requests:访问各个大模型服务,包括Ollama服务和vLLM服务
- vuejs:前端框架
- **大模型服务**:
- vLLM提供的服务1, 地址:http://vllm:38080/v1/chat/completions, 模型: my-qwen3.5-9b-sft, 不需要API key.
- vLLM提供的服务2, 地址:http://vllm:38081/v1/chat/completions, 模型: my-coder-llm, apiKey: (略)
- Ollam提供的服务1,地址:http://vllm1:11434
- Ollam提供的服务2,地址:http://vllm2:11434
- **依赖管理**:requirements.txt 或 pyproject.toml
## 3. 详细功能需求
### 3.1 根据配置列出大模型服务列表
- **功能描述**:用户访问系统首页,默认看到系统配置的所有大模型服务
- **输入**:
- **预期字段**:
- 按上面大模型服务的描述,系统在代码或配置文件中首先配置好上面4个服务地址和名称
- **处理逻辑**:
1. 读取配置,获取4个服务地址和名称
2. 各个大模型服务提供ping接口或版本查询接口,探测服务是否可用
3. 如果服务不可用,要处理执行异常,打印错误日志,程序不能崩溃
4. 在界面上显示服务名称、地址、状态(是否可用)、版本(可选)
- **异常处理**:打印日志,不能导致程序崩溃.
### 3.2 查看一个大模型服务的所有具体模型
- **功能描述**:用户在界面上选择一个大模型服务,点击之后进入具体大模型列表
- **处理逻辑**:
1. 调用Ollama或vLLM相关models查询接口,获取model的详细信息
2. 在界面上以表格形式显示model列表
- **界面输出**: 以表格形式显示model信息,字段名:ID、名称、尺寸等.
### 3.3 选择一个具体模型进行聊天
- **功能描述**:用户在界面上选择一个具体模型,进入聊天界面,可以发送消息进行交互
- **处理逻辑**:
- 进入一个聊天界面,左侧显示模型信息,右侧显示聊天区域,整个区域要占满,能最大限度展示交互信息
- 支持上传一个excel文件,后台服务提取excel表格数据提交给大模型服务进行统计分析
## 4. 非功能需求
- **错误处理**:所有异常需捕获并返回友好提示
- **代码规范**:遵循PEP8,函数职责单一,添加类型注解
- **日志记录**:关键步骤添加日志,便于调试
- **可配置性**:vLLM服务地址、模型参数通过配置文件管理
- **前端程序端口号要求**:端口号默认设置为3001
- **后台程序端口号要求**:端口号默认设置为8000
4. OpenCode安装
安装很简单,按照https://opencode.ai/官网上安装即可,当然我的本地早就安装好nvm、node、npm, 好几个版本管理。
还需要一个命令行终端软件,我选择Alacritty,opencode.ai首推WezTerm, 安装之后却不喜欢,因为它默认没带Linux基本命令,用习惯了Ubantu系统的人对Linux命令很依赖,当然Alacritty里的命令也不纯粹。
> cd ./llmmaster
> opencode
默认使用是opencode自带免费模型: Big Pickle, 配置我们自己的自建模型:访问C:\Users\你的用户名\.config\opencode\opencode.json,添加模型配置:
{
"$schema": "https://opencode.ai/config.json",
"default_agent": "build",
"provider": {
"vllm": {
"npm": "@ai-sdk/openai-compatible",
"name": "vLLM-local",
"options": {
"baseURL": "http://vllm:38081/v1",
"apiKey": "我的Key不告诉你"
},
"models": {
"my-coder-llm": {
"name": "my-coder-llm",
"limit": {
"context": 24576,
"output": 4096
}
}
}
},
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"name": "Ollama",
"options": {
"baseURL": "http://vllm2:11435/v1"
},
"models": {
"glm-4.7-flash": {
"name": "glm-4.7-flash"
},
"qwen3.5:35b": {
"name": "qwen3.5:35b"
},
"qwen3.5:35b-262k": {
"name": "qwen3.5:35b-262k"
},
"deepseek-coder:6.7b": {
"name": "deepseek-coder:6.7b"
}
}
}
},
"model": "glm-4.7-flash",
"agent": {
"build": {
"maxContextFiles": 15,
"includeDependencies": true
}
},
"compaction": {
"auto": true,
"reserved": 20000
}
}退出opencode界面,然后再访问,选择模型:
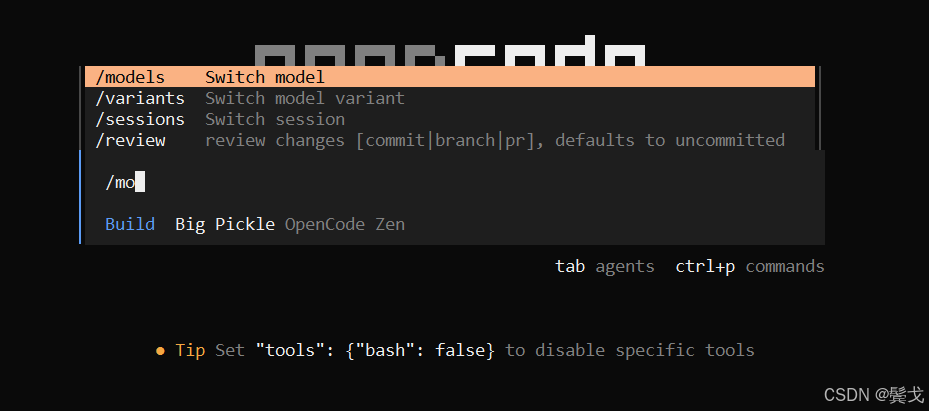
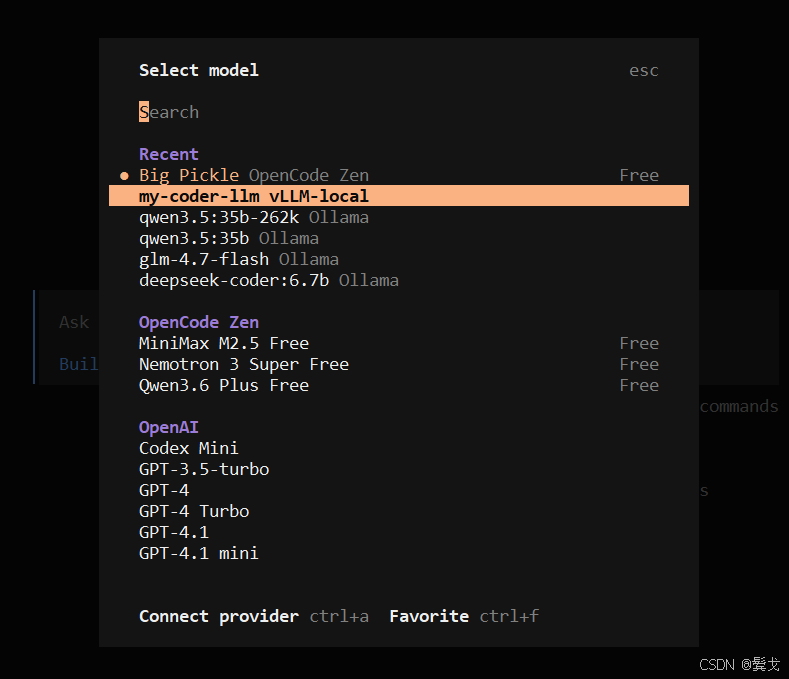
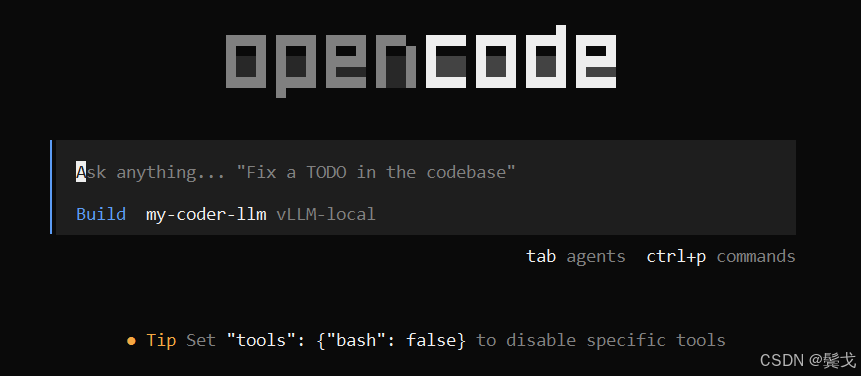
初始化项目环境:
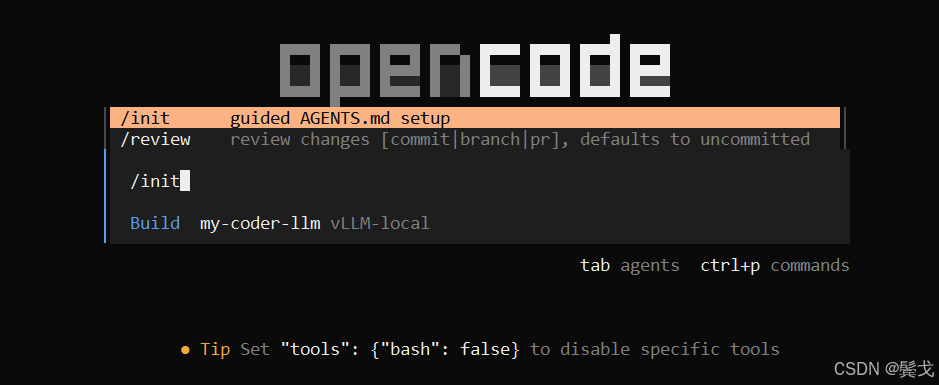
5. Coding
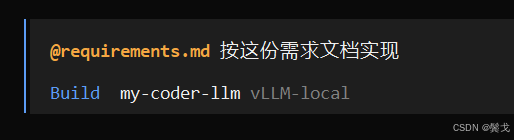
就这么一句话,opencode就会跑起来,最后还真出了一个前后端系统,有一个web界面:

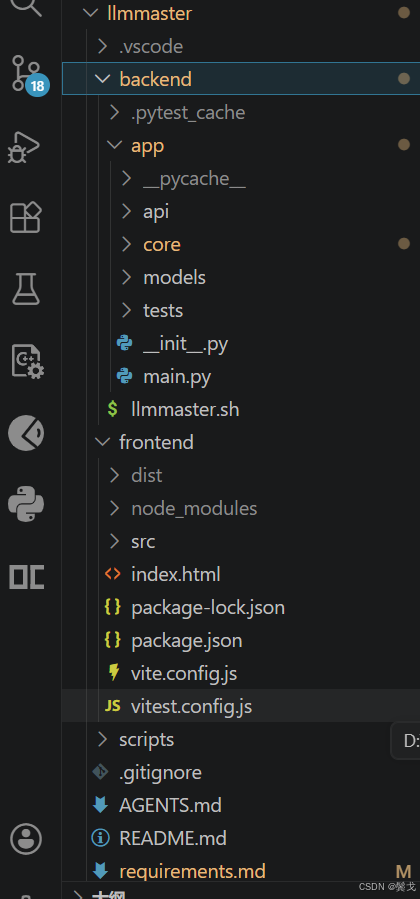
看看工程结构,还有点层次结构:
7. 结束语
是不是很容易很惊喜,对于不会前端开发的我来说,竟然不用求前端开发同事来做界面了,内部使用足够了。程序员都要被取代了,焦虑,恐慌,失业大潮很快卷到我们头上来啦,实际是不是这样呢,请听下回分解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)