python-langchain框架(3-7-提取pdf中的图片 )
一、适用场景全覆盖
这个方法能轻松应对绝大多数工作、学习中的 PDF 图片提取需求:
- 文档整理:提取 PDF 报告、白皮书、合同中的插图、图表、logo 等素材;
- 学习办公:导出课件、教材、论文里的高清图片,方便二次编辑使用;
- 素材收集:批量保存 PDF 画册、说明书、手册中的图片资源;
- 高效处理:几十页、上百页的 PDF,几秒内完成所有图片提取,告别手动操作。
二、核心优势:简单、高效、无损
相比截图、在线工具等传统方式,这个方案的优势非常突出:✅ 无损提取:直接提取 PDF 内嵌的原始图片,分辨率 100% 保留,无压缩、无模糊;✅ 批量处理:自动遍历 PDF 每一页,一次性提取所有图片,无需逐页操作;✅ 智能命名:图片文件自动按「页码 + 序号」命名,清晰对应原 PDF 位置,方便查找;✅ 自动归档:自动创建专属文件夹,所有提取的图片统一保存,整洁有序;✅ 格式兼容:支持 PNG、JPG、JPEG 等所有常见图片格式,无需额外转换;✅ 轻量无依赖:本地运行,无需上传文件到第三方平台,保护文档隐私安全。
三、实现方式:极简高效,零基础可上手
整个实现基于轻量的 PDF 处理工具,核心逻辑简洁清晰,全程无需复杂配置:
- 环境准备:仅需安装一个轻量的 PDF 处理依赖库,占用空间极小,安装秒完成;
- 路径配置:只需指定需要处理的 PDF 文件路径,无需修改其他参数;
- 自动执行:运行后工具会自动打开 PDF,逐页扫描识别内嵌图片;
- 批量导出:自动提取每一张图片的原始数据,按规则命名并保存到指定文件夹;
- 结果反馈:实时显示提取进度,最终统计总图片数量,清晰直观。
整个过程无需编写复杂代码、无需理解专业原理,三步即可完成:准备环境→指定文件→执行导出,零基础用户也能轻松上手。
四、实际效果展示
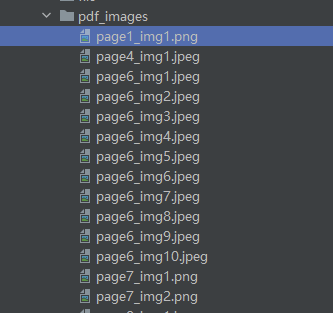
- 运行后自动创建
pdf_images文件夹,所有图片规整存放; - 文件名格式:
page页码_img序号.格式,一眼就能找到对应页面的图片; - 无论 PDF 有多少页、多少张图片,都能快速完成提取,大文件也不卡顿;
- 导出的图片和 PDF 中原图完全一致,可直接用于编辑、打印、展示。
五、总结
这款 PDF 图片提取方案,完美解决了日常办公学习中批量、无损、高效提取 PDF 图片的痛点,摒弃了截图的模糊和在线工具的隐私风险,本地运行、自动处理、结果清晰。
无论是少量图片提取,还是大批量文档处理,都能轻松胜任,是提升工作学习效率的实用小工具,强烈推荐大家收藏使用!
实现代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
|
结果输出:
📄 第 1 页 找到 1 张图片
✅ 已保存:第 1 页 第 1 张图片 → pdf_images/page1_img1.png
📄 第 4 页 找到 1 张图片
✅ 已保存:第 4 页 第 1 张图片 → pdf_images/page4_img1.jpeg
📄 第 6 页 找到 10 张图片
✅ 已保存:第 6 页 第 1 张图片 → pdf_images/page6_img1.jpeg
✅ 已保存:第 6 页 第 2 张图片 → pdf_images/page6_img2.jpeg
✅ 已保存:第 6 页 第 3 张图片 → pdf_images/page6_img3.jpeg
✅ 已保存:第 6 页 第 4 张图片 → pdf_images/page6_img4.jpeg
✅ 已保存:第 6 页 第 5 张图片 → pdf_images/page6_img5.jpeg
✅ 已保存:第 6 页 第 6 张图片 → pdf_images/page6_img6.jpeg
✅ 已保存:第 6 页 第 7 张图片 → pdf_images/page6_img7.jpeg
✅ 已保存:第 6 页 第 8 张图片 → pdf_images/page6_img8.jpeg
✅ 已保存:第 6 页 第 9 张图片 → pdf_images/page6_img9.jpeg
✅ 已保存:第 6 页 第 10 张图片 → pdf_images/page6_img10.jpeg
📄 第 7 页 找到 2 张图片
✅ 已保存:第 7 页 第 1 张图片 → pdf_images/page7_img1.png
✅ 已保存:第 7 页 第 2 张图片 → pdf_images/page7_img2.png
📄 第 8 页 找到 1 张图片
✅ 已保存:第 8 页 第 1 张图片 → pdf_images/page8_img1.jpeg
📄 第 10 页 找到 1 张图片
✅ 已保存:第 10 页 第 1 张图片 → pdf_images/page10_img1.jpeg
📄 第 13 页 找到 1 张图片
✅ 已保存:第 13 页 第 1 张图片 → pdf_images/page13_img1.jpeg
📄 第 14 页 找到 1 张图片
✅ 已保存:第 14 页 第 1 张图片 → pdf_images/page14_img1.jpeg
......
图片存储情况路径:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)