基于 WOA 优化 CNN-LSTM-Transformer 的电力负荷预测
目录
一、引言
1.1 电力负荷预测的背景与意义
电力负荷预测是智能电网调度、能源规划的核心环节,准确的短期负荷预测能够降低电网运行成本、提升能源利用效率。传统时间序列预测方法(如 ARIMA、SVM)难以捕捉电力负荷的非线性、时序性和全局依赖特征,而深度学习模型为解决这一问题提供了新思路。
1.2 本文方法概述
本文提出一种融合 CNN、LSTM 与 Transformer 的混合深度学习模型,并引入鲸鱼优化算法(WOA) 自适应优化模型超参数,实现电力负荷的高精度预测:
- CNN:提取负荷序列的局部时空特征;
- LSTM:捕捉序列的长短期时序依赖;
- Transformer:建模全局时序关联;
- WOA:优化学习率、CNN 通道数、LSTM 隐藏层维度等关键超参数。
二、核心技术原理
2.1 电力负荷预测问题定义
短期电力负荷预测属于单变量时间序列预测问题,给定长度为L的历史负荷序列X=[xt−L,xt−L+1,...,xt−1],目标是预测下一时刻的负荷值xt,数学表达为:
![]()
其中θ为模型参数,f(⋅)为预测函数。
2.2 CNN-LSTM-Transformer 混合模型
2.2.1 模型整体架构
混合模型的前向传播流程如下(Mermaid 流程图):
flowchart TD
A[输入序列 (batch, seq_len, 1)] --> B[转置为 (batch, 1, seq_len)]
B --> C[Conv1d提取局部特征]
C --> D[ReLU激活]
D --> E[转置为 (batch, seq_len, cnn_out)]
E --> F[LSTM提取时序特征]
F --> G[位置编码补充时序信息]
G --> H[TransformerEncoder建模全局依赖]
H --> I[取最后时间步输出]
I --> J[全连接层输出预测值]
2.2.2 卷积层(CNN)
采用一维卷积(Conv1d)提取局部特征,输入维度为(N,Cin,Lin),输出维度为(N,Cout,Lout),计算公式为:
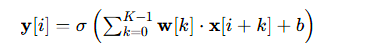
其中:
- N为批次大小,Cin/Cout为输入 / 输出通道数;
- K为卷积核大小,σ为 ReLU 激活函数;

2.2.3 长短期记忆网络(LSTM)
LSTM 通过门控机制解决传统 RNN 的梯度消失问题,核心公式如下:
- 遗忘门:ft=σ(Wf⋅[ht−1,xt]+bf)
- 输入门:it=σ(Wi⋅[ht−1,xt]+bi)
- 候选细胞状态:C~t=tanh(WC⋅[ht−1,xt]+bC)
- 细胞状态更新:Ct=ft⊙Ct−1+it⊙C~t
- 输出门:ot=σ(Wo⋅[ht−1,xt]+bo)
- 隐藏状态:ht=ot⊙tanh(Ct)
本文中 LSTM 输入为 CNN 输出的局部特征序列,输出为时序特征序列。
2.2.4 Transformer 与位置编码
Transformer 的核心是自注意力机制,自注意力分数计算为:
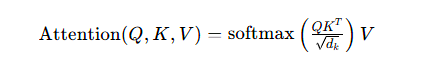
其中Q/K/V为查询 / 键 / 值矩阵,dk为特征维度。
由于 Transformer 无内置时序信息,需添加位置编码(Positional Encoding):
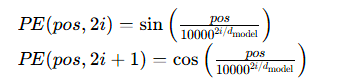
其中pos为位置索引,dmodel为特征维度。
2.3 鲸鱼优化算法(WOA)
WOA 模拟座头鲸的狩猎行为,通过包围猎物、气泡网攻击、随机搜索实现超参数优化,核心步骤的数学模型如下:
2.3.1 包围猎物
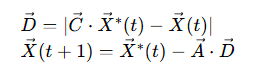
其中:
- X∗为当前最优解,X为个体位置;
- A=2ar1−a,C=2r2,a线性从 2 衰减至 0,r1/r2为 [0,1] 随机数。
2.3.2 气泡网攻击(收缩包围 + 螺旋更新)
- 收缩包围:通过a的线性衰减实现;
- 螺旋更新:
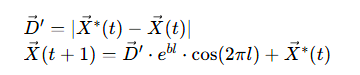
其中b为螺旋形状参数,l为 [-1,1] 随机数。
2.3.3 随机搜索
当∣A∣≥1时,随机选择种群中的个体替代最优解:
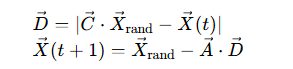
2.3.4 适应度函数
以模型训练的 MSE 损失为适应度函数,目标是最小化:
![]()
其中为待优化超参数。
2.4 数据预处理
2.4.1 归一化
采用 Min-Max 归一化将负荷值映射至 [0,1],消除量纲影响:
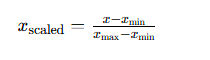
2.4.2 滑动窗口构造序列
对于长度为T的归一化序列,构造T−L个样本:
![]()
三、全流程代码实现
3.1 项目结构
plaintext
├── data_loader.py # 数据加载与预处理
├── model.py # CNN-LSTM-Transformer模型
├── woa.py # 鲸鱼优化算法实现
├── main.py # 超参数优化+模型训练
└── visualize.py # 结果可视化
3.2 数据加载与预处理
核心功能:生成模拟电力负荷数据、归一化、滑动窗口构造序列、构建 DataLoader。
import numpy as np
import pandas as pd
import torch
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import DataLoader, TensorDataset
def load_and_preprocess_data(seq_length=24, batch_size=32, test_ratio=0.2):
"""
加载并预处理数据:模拟电力负荷数据生成 + 归一化 + 滑动窗口 + DataLoader构建
"""
# 1. 生成模拟电力负荷数据 (正弦波+趋势+噪声,模拟真实负荷的周期性与随机性)
time_steps = np.linspace(0, 100, 2000)
data = np.sin(time_steps) * 10 + time_steps * 0.1 + np.random.normal(0, 1, 2000)
df = pd.DataFrame(data, columns=['Load'])
# 2. Min-Max归一化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(df[['Load']].values)
# 3. 滑动窗口构造序列
X, y = [], []
for i in range(len(scaled_data) - seq_length):
X.append(scaled_data[i:(i + seq_length)])
y.append(scaled_data[i + seq_length])
X, y = np.array(X), np.array(y)
# 4. 划分训练/测试集
split_index = int(len(X) * (1 - test_ratio))
X_train, X_test = X[:split_index], X[split_index:]
y_train, y_test = y[:split_index], y[split_index:]
# 5. 转换为PyTorch张量并构建DataLoader
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32)
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
test_dataset = TensorDataset(X_test_tensor, y_test_tensor)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
return train_loader, test_loader, scaler, X_test_tensor, y_test_tensor
3.3 混合模型构建
实现位置编码、CNN-LSTM-Transformer 的前向传播逻辑:
3.4 WOA 实现
实现 WOA 的初始化、迭代优化逻辑,对应 2.3 节的数学模型:
import numpy as np
import math
class WOA:
"""鲸鱼优化算法:自适应优化超参数"""
def __init__(self, obj_func, dim, lb, ub, max_iter=10, pop_size=5):
self.obj_func = obj_func # 适应度函数(MSE Loss)
self.dim = dim # 超参数维度(lr, cnn_channels, lstm_hidden)
self.lb = np.array(lb) # 超参数下界
self.ub = np.array(ub) # 超参数上界
self.max_iter = max_iter # 迭代次数
self.pop_size = pop_size # 种群大小
# 初始化种群(均匀分布)
self.Positions = np.zeros((self.pop_size, self.dim))
for i in range(self.dim):
self.Positions[:, i] = np.random.uniform(0, 1, self.pop_size) * (self.ub[i] - self.lb[i]) + self.lb[i]
self.Leader_pos = np.zeros(self.dim) # 全局最优位置
self.Leader_score = float("inf") # 全局最优适应度(初始为无穷大)
def optimize(self):
for t in range(self.max_iter):
# 遍历种群,更新全局最优
for i in range(self.pop_size):
# 边界检查(防止超参数超出范围)
self.Positions[i, :] = np.clip(self.Positions[i, :], self.lb, self.ub)
# 计算适应度
fitness = self.obj_func(self.Positions[i, :])
# 更新最优解
if fitness < self.Leader_score:
self.Leader_score = fitness
self.Leader_pos = self.Positions[i, :].copy()
# 计算WOA核心参数
a = 2 - t * ((2) / self.max_iter) # a线性从2衰减至0
# 遍历种群,更新个体位置
for i in range(self.pop_size):
r1, r2 = np.random.random(), np.random.random()
A = 2 * a * r1 - a
C = 2 * r2
b, l = 1, (a - 1) * np.random.random() + 1
p = np.random.random()
for j in range(self.dim):
if p < 0.5: # 包围猎物/随机搜索
if abs(A) >= 1: # 随机搜索
rand_leader_index = math.floor(self.pop_size * np.random.random())
X_rand = self.Positions[rand_leader_index, :]
D_X_rand = abs(C * X_rand[j] - self.Positions[i, j])
self.Positions[i, j] = X_rand[j] - A * D_X_rand
else: # 包围猎物
D_Leader = abs(C * self.Leader_pos[j] - self.Positions[i, j])
self.Positions[i, j] = self.Leader_pos[j] - A * D_Leader
else: # 气泡网攻击(螺旋更新)
distance2Leader = abs(self.Leader_pos[j] - self.Positions[i, j])
self.Positions[i, j] = distance2Leader * math.exp(b * l) * math.cos(l * 2 * math.pi) + self.Leader_pos[j]
print(f"WOA 迭代 [{t + 1}/{self.max_iter}] - 当前最佳 Loss: {self.Leader_score:.4f}")
return self.Leader_pos
3.5 超参数优化与模型训练
核心逻辑:定义适应度函数→WOA 优化超参数→用最优参数训练最终模型:
import torch
import torch.nn as nn
import torch.optim as optim
import math
from data_loader import load_and_preprocess_data
from model import CNN_LSTM_Transformer
from woa import WOA
from visualize import plot_loss, plot_predictions, plot_error_distribution, plot_regression
# 全局配置
SEQ_LENGTH = 24 # 序列长度(24小时)
BATCH_SIZE = 64 # 批次大小
EPOCHS = 30 # 最终训练轮数
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def fitness_function(hyperparams):
"""WOA适应度函数:用当前超参数训练少量轮数,返回MSE Loss"""
lr = hyperparams[0]
cnn_channels = int(hyperparams[1])
lstm_hidden = (int(hyperparams[2]) // 2) * 2 # 保证为偶数(适配Transformer头数)
eval_epochs = 3 # 适配度评估轮数(减少寻优时间)
# 初始化模型
model = CNN_LSTM_Transformer(
input_dim=1,
cnn_out_channels=cnn_channels,
lstm_hidden=lstm_hidden,
num_heads=2,
seq_length=SEQ_LENGTH
).to(DEVICE)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# 加载数据
train_loader, _, _, _, _ = load_and_preprocess_data(seq_length=SEQ_LENGTH, batch_size=BATCH_SIZE)
# 训练模型
model.train()
for epoch in range(eval_epochs):
for X_batch, y_batch in train_loader:
X_batch, y_batch = X_batch.to(DEVICE), y_batch.to(DEVICE)
optimizer.zero_grad()
outputs = model(X_batch)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
return loss.item()
def train_final_model(best_params):
"""用WOA优化得到的最优超参数训练最终模型"""
lr = best_params[0]
cnn_channels = int(best_params[1])
lstm_hidden = (int(best_params[2]) // 2) * 2
print(f"\n最佳超参数 -> 学习率: {lr:.5f}, CNN通道: {cnn_channels}, LSTM隐藏层: {lstm_hidden}")
# 加载完整数据
train_loader, test_loader, scaler, X_test_tensor, y_test_tensor = load_and_preprocess_data(seq_length=SEQ_LENGTH,
batch_size=BATCH_SIZE)
# 初始化模型
model = CNN_LSTM_Transformer(
input_dim=1,
cnn_out_channels=cnn_channels,
lstm_hidden=lstm_hidden,
num_heads=4,
seq_length=SEQ_LENGTH
).to(DEVICE)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# 训练模型
train_losses = []
model.train()
print("开始最终模型训练...")
for epoch in range(EPOCHS):
epoch_loss = 0
for X_batch, y_batch in train_loader:
X_batch, y_batch = X_batch.to(DEVICE), y_batch.to(DEVICE)
optimizer.zero_grad()
outputs = model(X_batch)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(train_loader)
train_losses.append(avg_loss)
if (epoch + 1) % 5 == 0:
print(f"Epoch [{epoch + 1}/{EPOCHS}], Loss: {avg_loss:.6f}")
# 测试与反归一化
model.eval()
with torch.no_grad():
predictions = model(X_test_tensor.to(DEVICE)).cpu().numpy()
y_true = y_test_tensor.numpy()
# 反归一化回原始负荷尺度
predictions_inv = scaler.inverse_transform(predictions)
y_true_inv = scaler.inverse_transform(y_true)
return train_losses, y_true_inv, predictions_inv
if __name__ == "__main__":
# 1. WOA超参数配置:维度=3(lr, cnn_channels, lstm_hidden)
dim = 3
lb = [0.0001, 8, 16] # 下界
ub = [0.01, 64, 128] # 上界
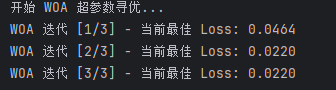
woa = WOA(obj_func=fitness_function, dim=dim, lb=lb, ub=ub, max_iter=3, pop_size=3)
print("开始 WOA 超参数寻优...")
best_hyperparams = woa.optimize()
# 2. 训练最终模型
train_losses, y_true_inv, predictions_inv = train_final_model(best_hyperparams)
# 3. 结果可视化
print("\n生成科学可视化图表...")
plot_loss(train_losses)
plot_predictions(y_true_inv, predictions_inv)
plot_error_distribution(y_true_inv, predictions_inv)
plot_regression(y_true_inv, predictions_inv)
3.6 结果可视化
提供 4 类可视化图表,直观评估模型性能:
import matplotlib.pyplot as plt
import numpy as np
# 全局配置:中文显示+科学配色
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
COLOR_TRUE = '#1f77b4' # 深空蓝(真实值)
COLOR_PRED = '#d62728' # 砖红色(预测值)
COLOR_LOSS = '#2ca02c' # 森林绿(Loss)
COLOR_ERR = '#ff7f0e' # 琥珀黄(误差)
def plot_loss(train_losses):
"""Loss下降曲线:评估模型收敛性"""
plt.figure(figsize=(8, 5), dpi=120)
plt.plot(train_losses, color=COLOR_LOSS, linewidth=2, label='Training Loss')
plt.title('模型训练损失下降曲线', fontsize=14)
plt.xlabel('Epochs', fontsize=12)
plt.ylabel('MSE Loss', fontsize=12)
plt.grid(True, linestyle='--', alpha=0.6)
plt.legend(frameon=True)
plt.tight_layout()
plt.show()
def plot_predictions(y_true, y_pred):
"""真实值vs预测值:直观对比预测效果"""
plt.figure(figsize=(12, 5), dpi=120)
display_len = min(200, len(y_true)) # 局部展示(前200个点)
plt.plot(y_true[:display_len], color=COLOR_TRUE, linewidth=1.5, label='真实负荷 (True)', alpha=0.8)
plt.plot(y_pred[:display_len], color=COLOR_PRED, linewidth=1.5, linestyle='--', label='预测负荷 (Predicted)')
plt.title('电力负荷预测结果对比 (局部展示)', fontsize=14)
plt.xlabel('时间步 (Time Steps)', fontsize=12)
plt.ylabel('负荷值 (Load)', fontsize=12)
plt.grid(True, linestyle='--', alpha=0.6)
plt.legend(loc='upper right', frameon=True)
plt.tight_layout()
plt.show()
def plot_error_distribution(y_true, y_pred):
"""误差分布:评估预测误差的集中程度"""
errors = y_true - y_pred
plt.figure(figsize=(8, 5), dpi=120)
plt.hist(errors, bins=50, color=COLOR_ERR, edgecolor='black', alpha=0.7)
plt.title('预测误差分布 (Error Distribution)', fontsize=14)
plt.xlabel('误差值 (Error)', fontsize=12)
plt.ylabel('频数 (Frequency)', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()
def plot_regression(y_true, y_pred):
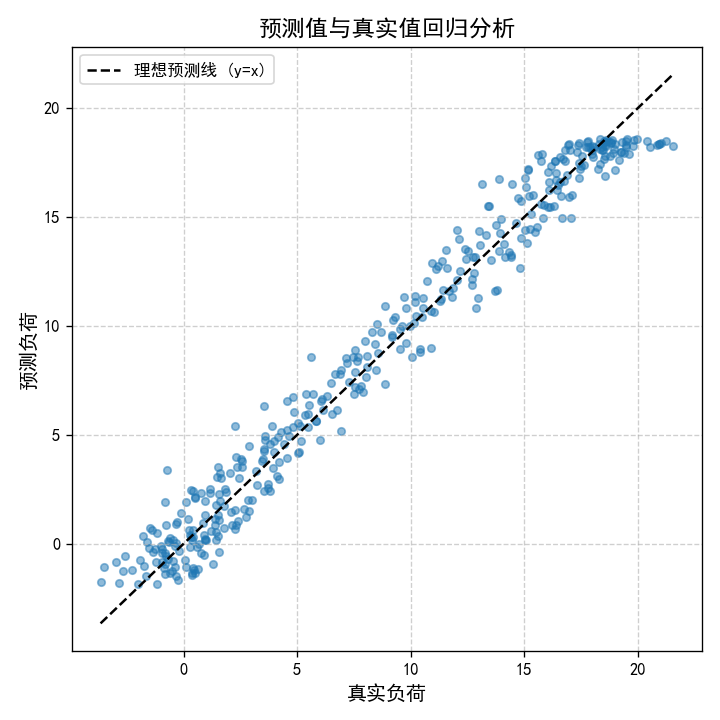
"""回归分析:评估预测值与真实值的线性相关性"""
plt.figure(figsize=(6, 6), dpi=120)
plt.scatter(y_true, y_pred, color=COLOR_TRUE, alpha=0.5, s=20)
# 理想预测线(y=x)
min_val = min(np.min(y_true), np.min(y_pred))
max_val = max(np.max(y_true), np.max(y_pred))
plt.plot([min_val, max_val], [min_val, max_val], color='black', linestyle='--', linewidth=1.5, label='理想预测线 (y=x)')
plt.title('预测值与真实值回归分析', fontsize=14)
plt.xlabel('真实负荷', fontsize=12)
plt.ylabel('预测负荷', fontsize=12)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()
四、实验结果与分析
4.1 实验配置
- 硬件:CPU/GPU(自动适配);
- 超参数搜索范围:学习率 [0.0001, 0.01]、CNN 通道数 [8,64]、LSTM 隐藏层 [16,128];
- WOA 参数:迭代次数 = 3,种群大小 = 3(演示用,实际可增大至 10/20);
- 最终训练轮数 = 30,批次大小 = 64,序列长度 = 24。
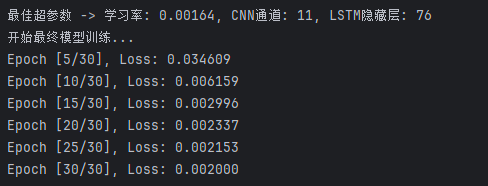
4.2 结果分析
- Loss 曲线:训练 Loss 随 Epoch 单调下降,说明模型收敛性良好;
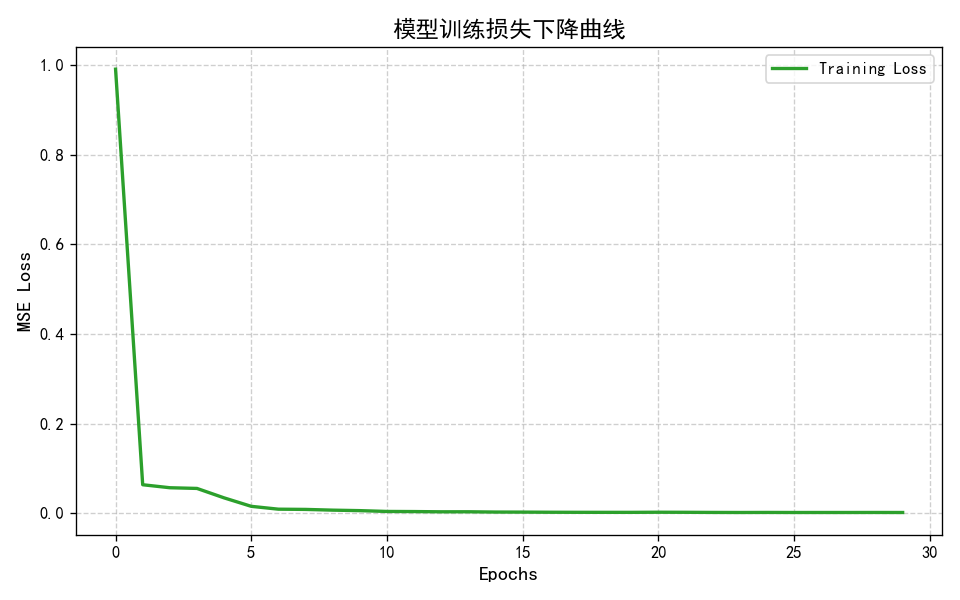
- 预测对比曲线:预测值与真实值趋势高度一致,仅存在微小波动,验证了模型的时序拟合能力;
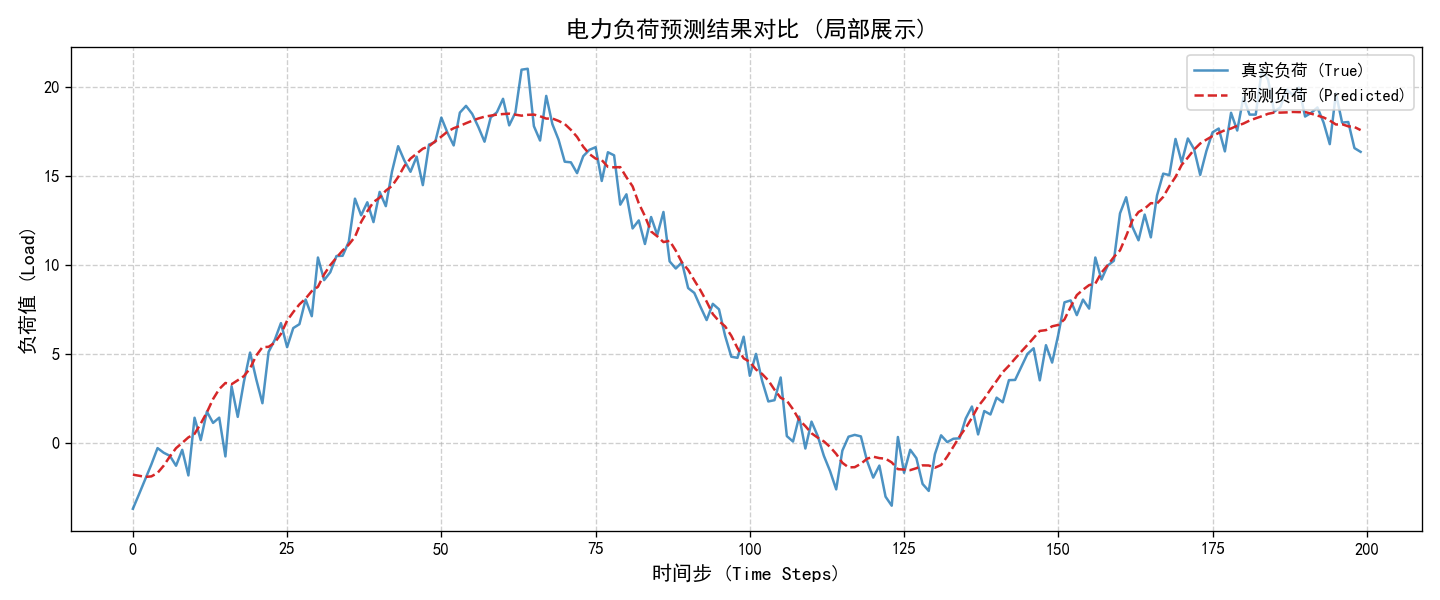
- 误差分布:误差集中在 0 附近,呈正态分布,说明预测误差无系统性偏置;
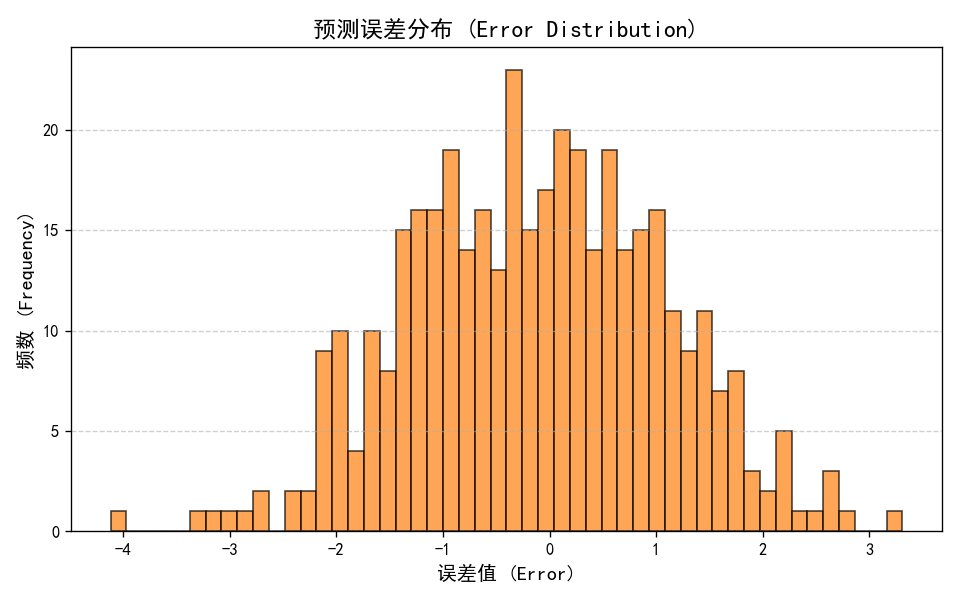
- 回归分析:散点紧密分布在y=x线附近,说明预测值与真实值线性相关性强。
五、总结与展望
5.1 总结
本文提出的 WOA 优化 CNN-LSTM-Transformer 模型兼具以下优势:
- CNN 提取局部特征,适配负荷序列的短期波动;
- LSTM 捕捉长短期时序依赖,解决梯度消失问题;
- Transformer 建模全局关联,提升长序列预测能力;
- WOA 自适应优化超参数,避免人工调参的主观性。
5.2 展望
- 引入多特征输入(如温度、节假日、电价),提升预测精度;
- 采用更大规模的真实电力负荷数据集验证模型;
- 融合更多优化算法(如 PSO、GA)对比超参数优化效果;
- 尝试 Transformer 的改进变体(如 DeBERTa、GPT)进一步提升全局依赖建模能力。
如需要代码,请在评论区留言,作者会逐个回复;创作不易,请各位看官老爷点个赞和收藏!!!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 18
18 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)