RAG相关技术介绍及Spring AI中使用--第一期
一.什么是RAG
RAG (Retrieval Augmented Generation,检索增强生成),是一种结合信息检索 (Retrieval) 和文本生成 (Generation) 的混合架构。
你有没有遇到过这样的情况:向 AI 提问 "公司最新的隐私政策是什么",结果它一本正经地胡编乱造?这就是传统大型语言模型 (LLM) 的 "幻觉" 问题 —— 它们依赖训练数据中的知识,但无法获取最新信息以及一些非公开信息。
RAG 就像给 AI 装上了 "外挂大脑",让它在回答问题时,先从外部知识库 (如文档、数据库) 中检索相关片段,再将这些片段作为上下文,输入给模型。这样,AI 的回答就基于真实、最新数据,大幅减少 "幻觉",同时支持动态知识更新。
通俗类比:开卷考试 vs 闭卷考试
想象你是个学生,参加开卷考试(比如历史题),你本身已经记忆了一些知识(对应 AI 模型训练数据里的知识)
- 传统 LLM 就像闭卷考试—— 你只能靠死记硬背答题,很可能把 "秦始皇统一六国" 错记成 "秦始皇统一七国"。
- RAG 就像开卷考试—— 给你发了一本历史书(对应 RAG 的知识库),你先快速翻书找到 "秦朝" 相关章节(检索),再根据书里的内容组织答案(生成),确保答案的真实性。
RAG 让 AI 从 "背书机器" 升级为 "会查资料的专家",尤其适合需要高准确性的场景,比如医疗咨询、法律问答。
二.RAG的工作流程
RAG 不是魔法,而是一套严谨的流水线。它的流程主要包括检索和生成两大核心步骤。
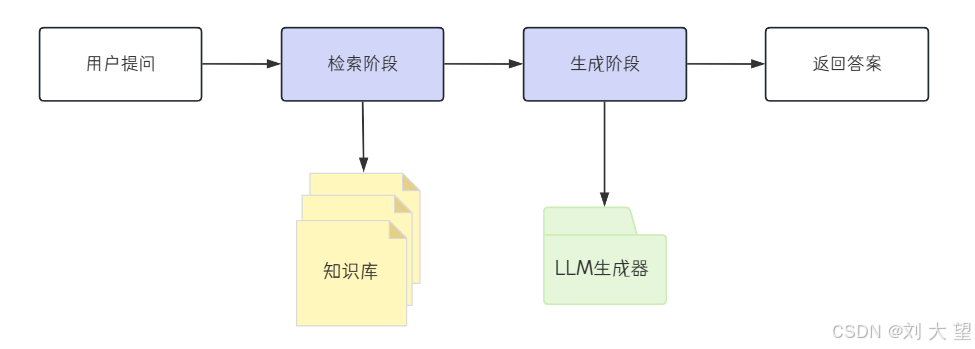
通过从外部知识库获取相关信息来增强大语言模型 (LLM) 的输出,从而生成更准确、上下文更丰富的回答,有效解决模型幻觉、知识过时等问题。
RAG 知识库可以是本地文档、公司内部文档等非公开数据。但这些数据或文档无法被直接高效地检索访问,因此需要对这些数据进行专项处理,最终构建成可被检索的标准化知识库。
从知识库中检索出结果后,将其输入给大模型,通过大模型完成生成结果增强的过程。
1.概念解释:
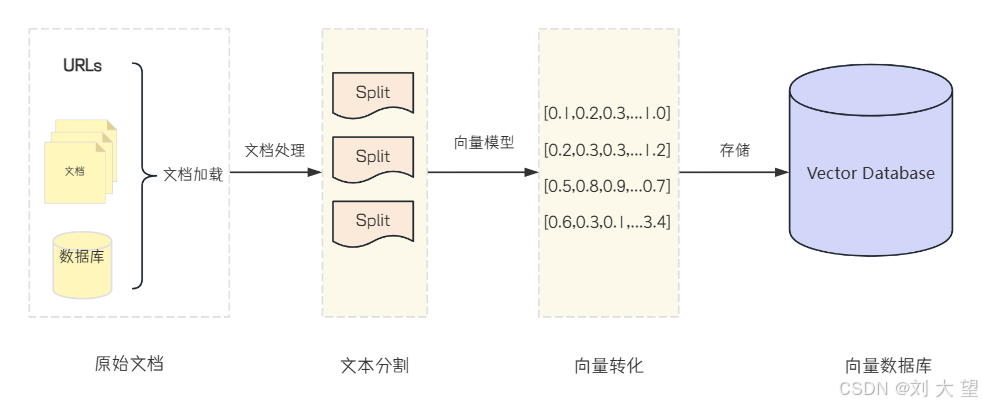
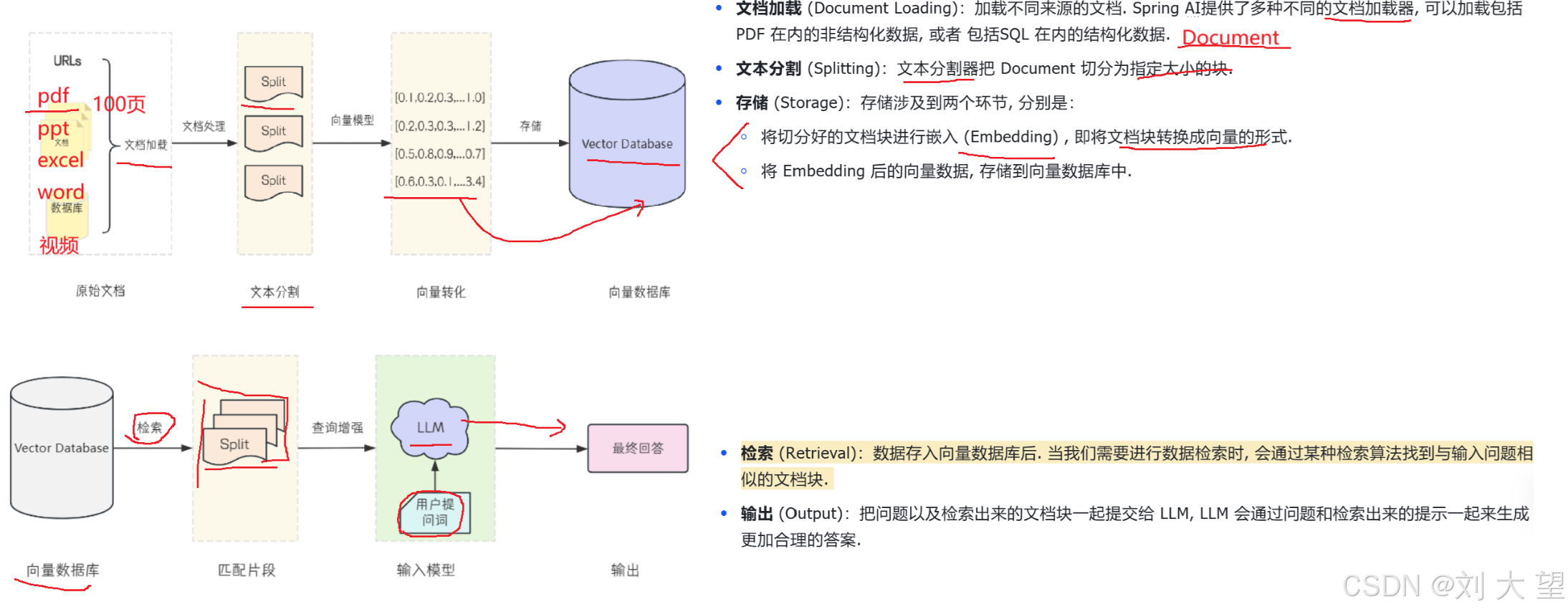
文档加载 (Document Loading)加载不同来源的文档。Spring AI 提供了多种文档加载器,可加载包括 PDF 在内的非结构化数据,或是包括 SQL 在内的结构化数据。
文本分割 (Splitting)文本分割器会将完整的 Document 切分为指定大小的文本块。
存储 (Storage)存储环节主要分为两个核心步骤:
- 将切分好的文档块进行嵌入 (Embedding),即把文档块转换为向量形式
- 将 Embedding 完成的向量数据,存储到向量数据库中
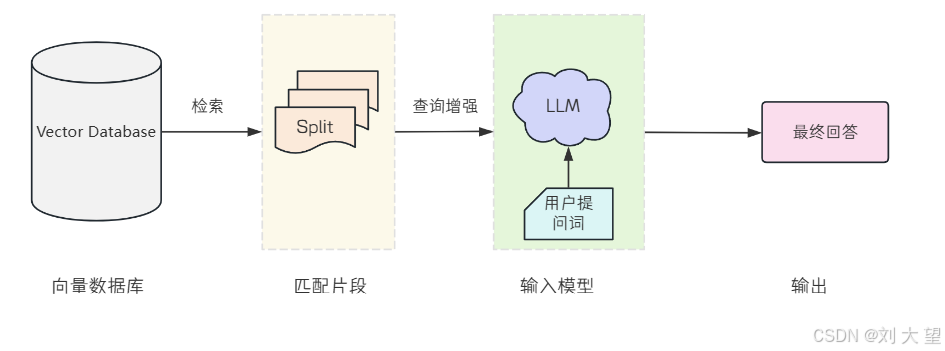
检索 (Retrieval)数据存入向量数据库后,当发起查询请求时,会通过对应的检索算法,找到与输入问题相似度匹配的文档块。
输出 (Output)把用户问题以及检索到的相关文档块一同提交给 LLM,LLM 会结合问题与检索到的提示内容,生成更精准、合理的答案。
有些这里没涉及的知识后面会说到比如embedding
2.举个例子:
RAG 通俗类比:AI 的智能小秘书
RAG 就像给 AI 配了个智能小秘书—— 帮你从海量资料里快速找到对应答案,再让 AI 严格基于检索到的信息回答问题,杜绝胡编乱造。
文档加载:收资料公司来了一个小秘书,你扔给她一摞资料让她提前熟悉,资料包括员工报销指南 (PDF)、客户订单记录 (数据库)、最新产品价目表 (Excel) 等各类文件。
文本分割:按章节进行拆分把长文档拆分成固定篇幅的 “小纸条”(比如每个小纸条 500 字),避免 AI 记不住长内容,就像把厚文档按章节拆分归类,方便后续快速检索。
存储:贴码存柜
- a. Embedding (嵌入):用 Embedding 模型把每张小纸条转换成一串 “数字条形码”(向量),语义相似的内容,对应的数字特征也相近(比如 “打车报销” 和 “机票报销” 的 “条形码” 会挨得很近)。
- b. 存入向量数据库:把这些 “数字条形码” 存进 “智能文件柜”(向量数据库)。普通文件柜需要翻抽屉找内容,而智能文件柜可以直接 “扫码” 快速定位。
检索:匹配相关内容把用户的问题也转换成对应的 “条形码”(向量),在向量数据库中匹配找到语义相似的文档块。
- 核心是语义匹配,而非单纯的关键词搜索
- 示例:问 “网约车能报销吗”,小秘书扫完问题的 “条形码”,就会弹出匹配的相关纸条(打车报销规则、发票要求、费用上限等)
输出:生成最终答案把用户的问题 + 检索到的相关文档块一同输入给 LLM,让模型基于真实信息生成精准的最终答案(示例:需提供电子发票 + 行程单,单次报销上限 50 元)。
三.相关名词技术
1.向量
向量是高维(成千上万维度)空间中的数值数组(如[0.2, -1.5, 3.1,…]),每个维度代表语义特征。
1.1向量在 AI 领域的应用
在人工智能和自然语言处理领域,向量常被用来将文本、图像、音频等复杂对象映射到高维空间中的点。每一个维度代表某种潜在的语义特征或属性。这些特征不一定对应人类可直观理解的具体概念(如 "颜色" 或 "大小"),但它们共同编码了对象的意义和特性。
1.2向量的生成方式
这个过程通常通过 Embedding 模型(嵌入模型)实现。当我们把词语输入给同一个模型时,它们会被转换成各自的向量表示,语义相似的文本(如 "香蕉" 和 "橘子")在向量空间中距离更近。
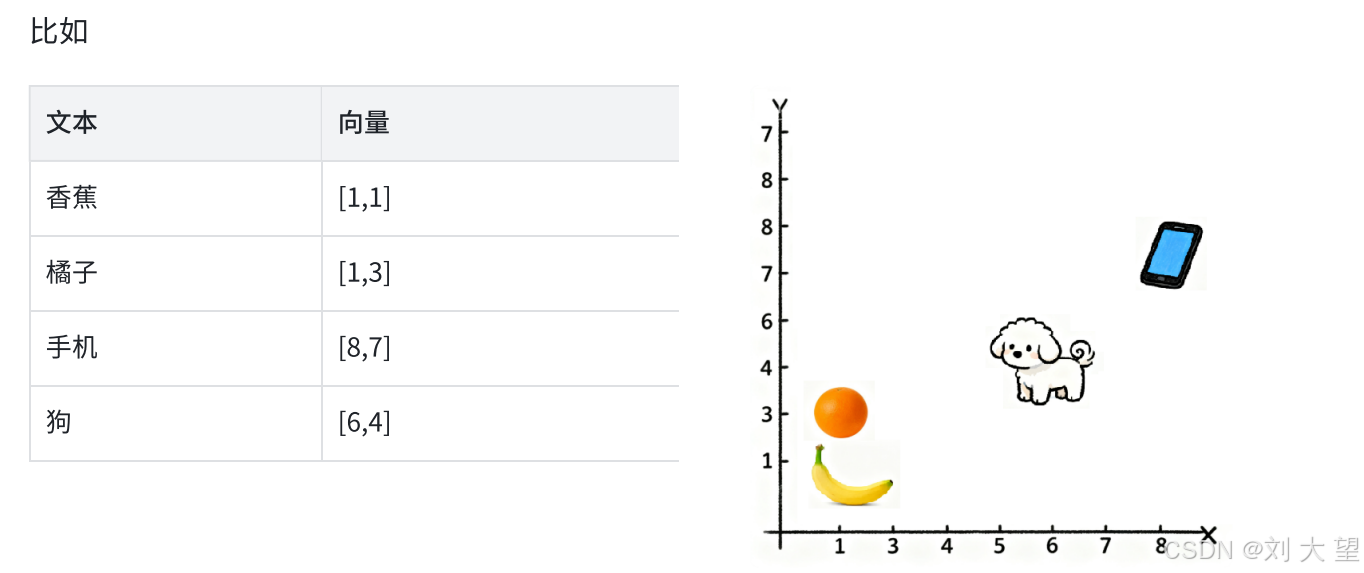
1.3多维向量的核心价值
简单的一维数值无法捕捉复杂对象的丰富信息,例如,描述一个人,仅靠一个维度(如性别)远远不够。我们需要多个特征来全面刻画它,比如:性别、地区、喜好、身高、体重、年龄等。每个特征都可以被编码为向量的一个维度,最终形成一个多维向量,如 [0.8, -1.2, 2.5, ..., 1.7](具体数值由模型自动生成)。
在这样的高维空间中,我们难以可视化,但机器可以通过计算向量间的距离或角度来判断两个对象是否相似。
1.4常用的相似性度量方法
-
余弦相似度:衡量两个向量方向的夹角,值越接近 1 表示越相似;
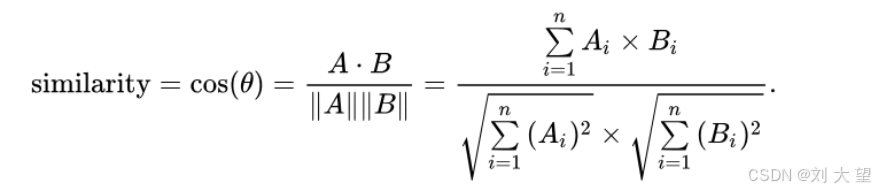
-
欧氏距离:衡量两点之间的直线距离,距离越小越相似。
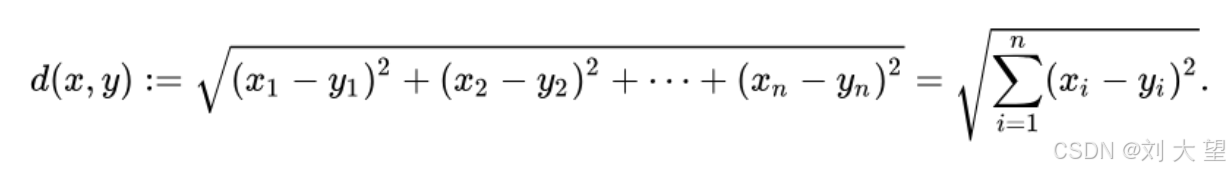
2.Embedding模型
2.1核心定义
Embedding 是将文本映射为向量的技术(典型实现:BERT、OpenAI 的 text-embedding-ada-002)。好的 Embedding 能让 "人工智能" 和 "AI" 的向量高度相似,而 "人工智能" 和 "西红柿" 的向量距离很远。
就像把中文 "充电" 翻译成英文 "charge",Embedding 是把文字 "翻译" 成数字语言
2.2Embedding(嵌入)模型
Embedding (嵌入) 模型,是指完成文本向量化过程的模型。
Embedding 模型就像是一个 "文本翻译器",它的任务是把文字(比如词语、句子或段落)翻译成数字向量 —— 也就是一串能代表其含义的数字这些数字不是随机的,而是经过精心计算,使得语义相近的内容,对应的向量也彼此接近
2.3Embedding 的核心思想
计算机天生擅长处理数字,但不理解文字、图片的含义。Embedding 的核心思想,就是将人类世界的符号(如单词、句子、产品、用户、图片)转换为计算机能够理解的数值形式(即向量,本质上是一个数字列表),并且要求这种转换能够保留原始符号的语义和关系。
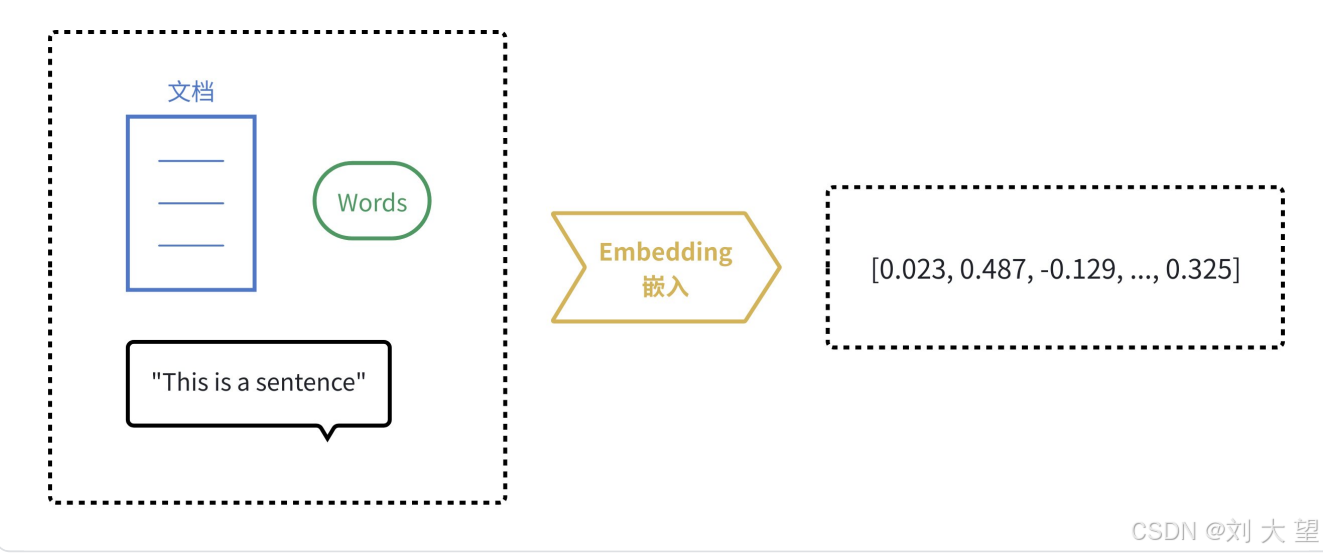
我们可以把它想象成⼀个翻译过程,把⼈类语⾔"翻译"成计算机的"数学语⾔".
3.向量数据库
3.1核心定义
向量数据库 (Vector Database) 是一种专门用于存储、管理和高效检索高维向量数据的数据库系统。它以向量作为基本存储单元,支持对非结构化数据(如文本、图像、音频、视频)进行语义级相似性搜索。
3.2向量数据库的核心能力
与传统关系型数据库(如 MySQL)基于文本匹配不同,向量数据库的核心能力在于:
- 向量化处理:可以将原始数据转换为高维向量(向量维度通常为几百到几千之间)
- 相似性度量:使用余弦相似度、欧氏距离等方法衡量向量间的语义接近程度,实现 "语义搜索"
- 高效检索:面对 "高维空间中计算距离效率极低" 的问题,采用高效的索引算法,在保证较高准确率的前提下大幅提升查询速度
你拍了一张猫的照片,想在手机相册里找 "长得像" 的其他猫咪照片。传统数据库的方法是靠标签 (字段),我们需要手动标注 "白色"、"长毛"、"圆脸",按关键词搜。如果没打标签的话,AI 不能自己看图凭 "感觉" 找相似的。
3.3向量数据库的工作逻辑
向量数据库就像是一个 **"记忆仓库"**,把图片转换成一个个向量,并存储起来。比如:
- "一只白猫" 的照片 → 变成一串数字
[0.2, -1.4, 3.1, ...] - "一只黑猫" 的照片 → 变成另一串数字
[0.9, 1.1, -0.5, ...]
这个过程就是上文提到的Embedding (嵌入),可以理解为:把人类能看懂的信息,"翻译" 成机器能计算的数学语言。
向量数据库的任务就是把这些数字存起来,当你问它 "有没有长得像这张猫的照片" 时,它能在几毫秒内从上百万条数据里,找出最相似的那个。
3.4与传统数据库的核心差异
并不是只有向量数据库才能存向量 —— 我们也可以在普通数据库(比如 MySQL)里加个字段存数组。但是当你要从 1 亿个向量中找最相似的一个时,传统数据库会慢得像蜗牛,向量数据库就像开了火箭。
四.RAG快速使用
1.使用介绍
RAG 是一套流水线,Spring AI 框架 为我们提供了 RAG 全流程 的支持。
1.1RAG 的核心执行流程
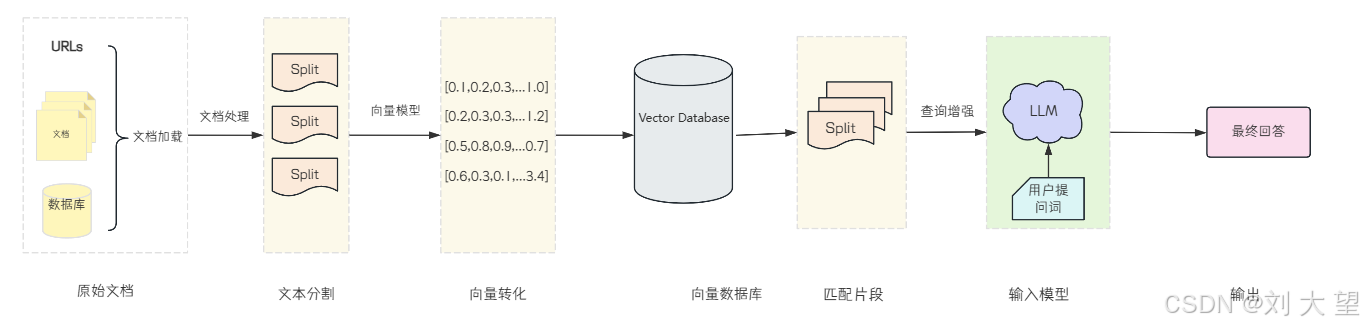
我们想使用 RAG 的话,需要先建立知识库,从知识库中检索,把检索结果输入给大模型,通过大模型增强生成结果的过程。但这个过程非常繁琐,我们进行一下概括,简单分为以下几步:
- 文档加载
- 文档拆分
- 向量转换
- 向量存储
- 相似检索
- 查询增强
其中1-4 步属于知识库的创建环节,也就是ETL (The Extract, Transform, and Load,提取、转化和加载) 的核心内容。
1.2入门级简化 RAG 流程
作为第一个 RAG 程序,我们进行简化,省略掉文档加载和拆分环节,分为以下几步:
- 文本向量化
- 向量存储
- 相似性检索
- 查询增强
2.准备工作
2.1创建项目
2.2完善pom
spring boot 版本为3.5.2
<!-- 完善依赖 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>2.3添加启动类
先建好包路径
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class RagApplication {
public static void main(String[] args) {
SpringApplication.run(RagApplication.class, args);
}
}
基本项目搭建完毕
3.文本向量化
3.1文本向量化与向量模型基础
通过向量模型即可实现文本向量化,目前常见的大语言模型(如 deepseek)并不具备文本向量化的能力,因此需要引入专门的向量模型来完成这项工作。
百炼平台和 Ollama 都提供了多种向量模型选择,为方便学习,我们使用阿里百炼平台提供的向量模型来学习。
向量模型是指能把数据(尤其是文本)转为数值向量表示的模型的统称。
Embedding 模型属于向量模型的一种,侧重维护数据间的词义关系,生成的是低维、稠密、有语义的向量。
3.2常见向量模型示例
比如:
- one-hot:用 0 和 1 表示一个词有没有出现(很简单,但也是向量)
- 示例:词汇表大小为 10,000,则每个词是一个 10,000 维的向量,只有一个位置是 1,其余为 0
- Embedding:用一串小数表示语义(比如
[-0.2, 0.8, 1.3, ...]),能捕捉语义的相似性
尽管两者在表达能力和效率上有显著差异,但它们都属于向量模型的范畴。
3.3千问的两款向量模型
链接
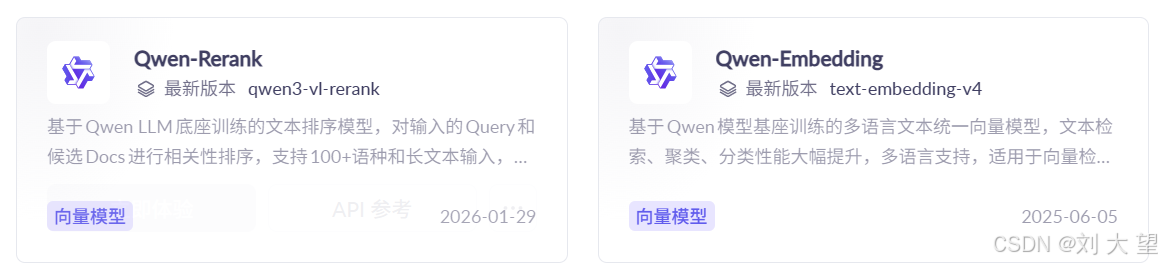
本文使用Qwen-Embedding
Qwen-Embedding的API 文档参考链接-> 大模型服务平台百炼控制台
4.添加依赖和配置
4.1pom配置
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webflux</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>1.0.0.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>4.2yml配置
spring:
ai:
dashscope:
api-key: ${DASH_SCOPE_API_KEY} #你在阿里百炼平台申请的AK5.简单使用
使用测试用例的形式来演示结果
5.1代码
import com.alibaba.cloud.ai.dashscope.embedding.DashScopeEmbeddingModel;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
@SpringBootTest
public class TextEmbeddingTest {
@Autowired
private DashScopeEmbeddingModel embeddingModel;
@Test
public void testEmbedding() {
float[] embed = embeddingModel.embed("Hello, World!");
System.out.println(embed.length);
System.out.println(Arrays.toString(embed));
}
}
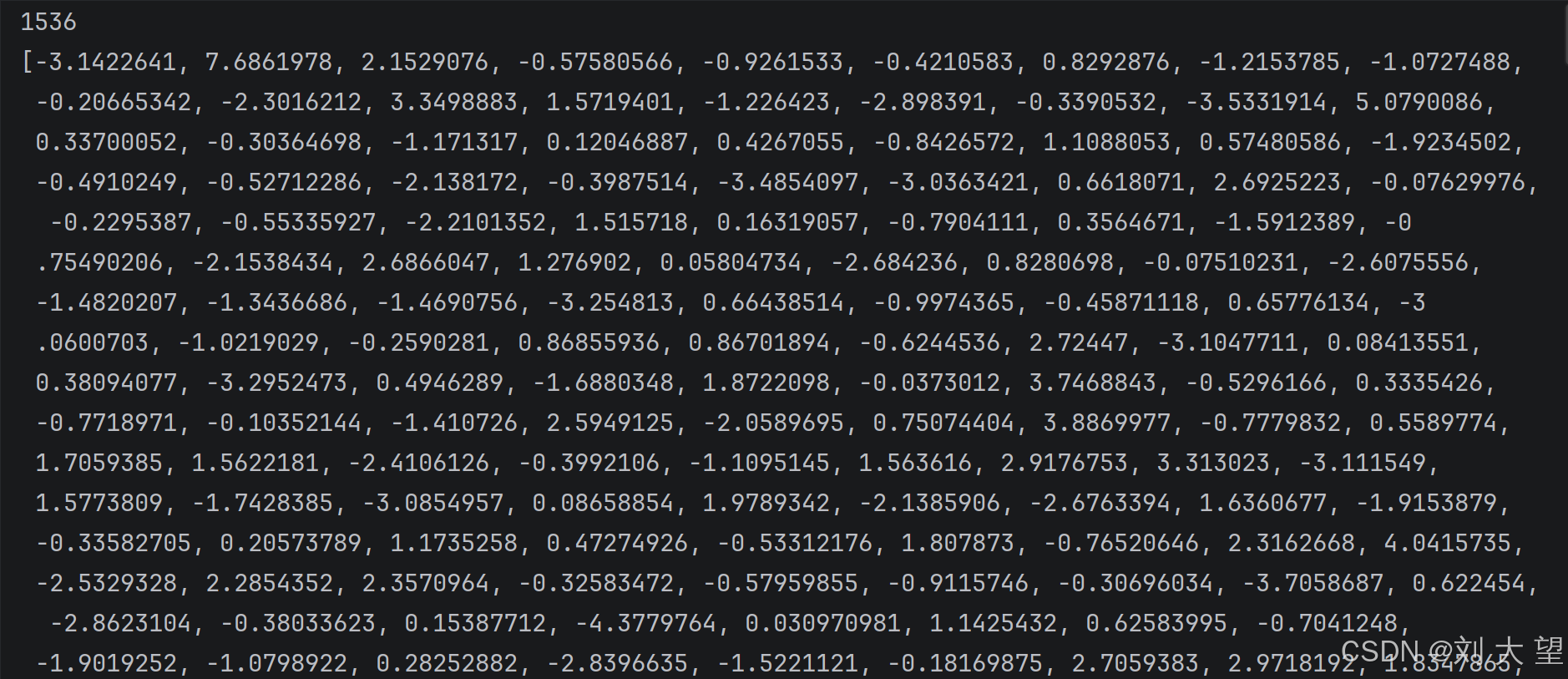
5.2结果
生成的维度有1536维
不配置 默认使用的模型是text-embedding-v1
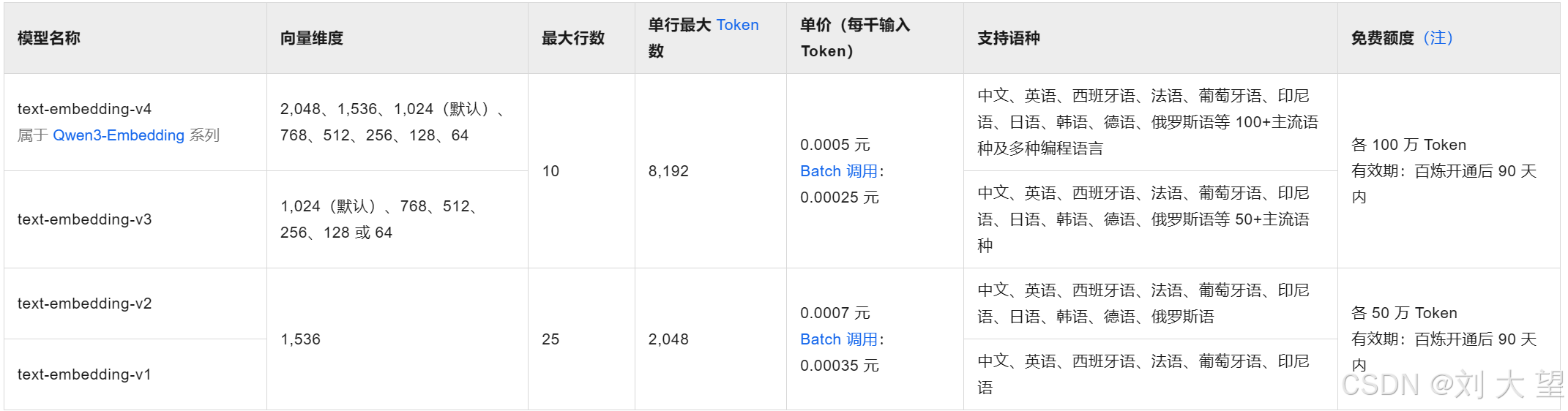
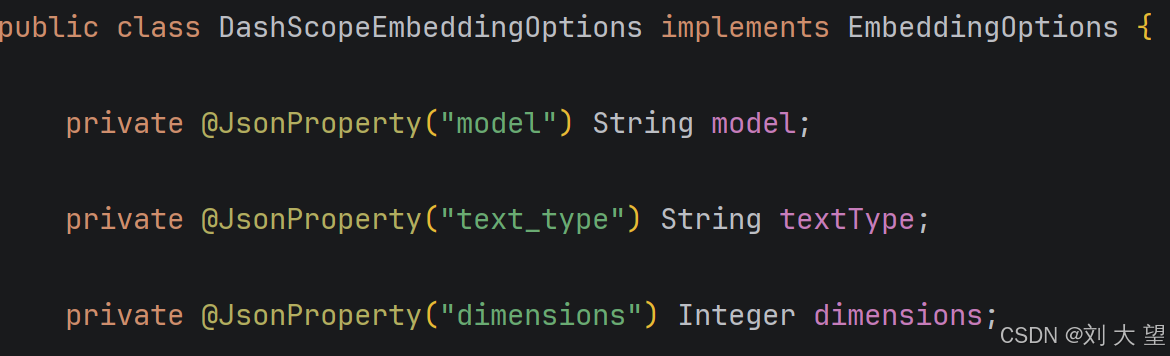
下图是DashScopeEmbedding可选参数
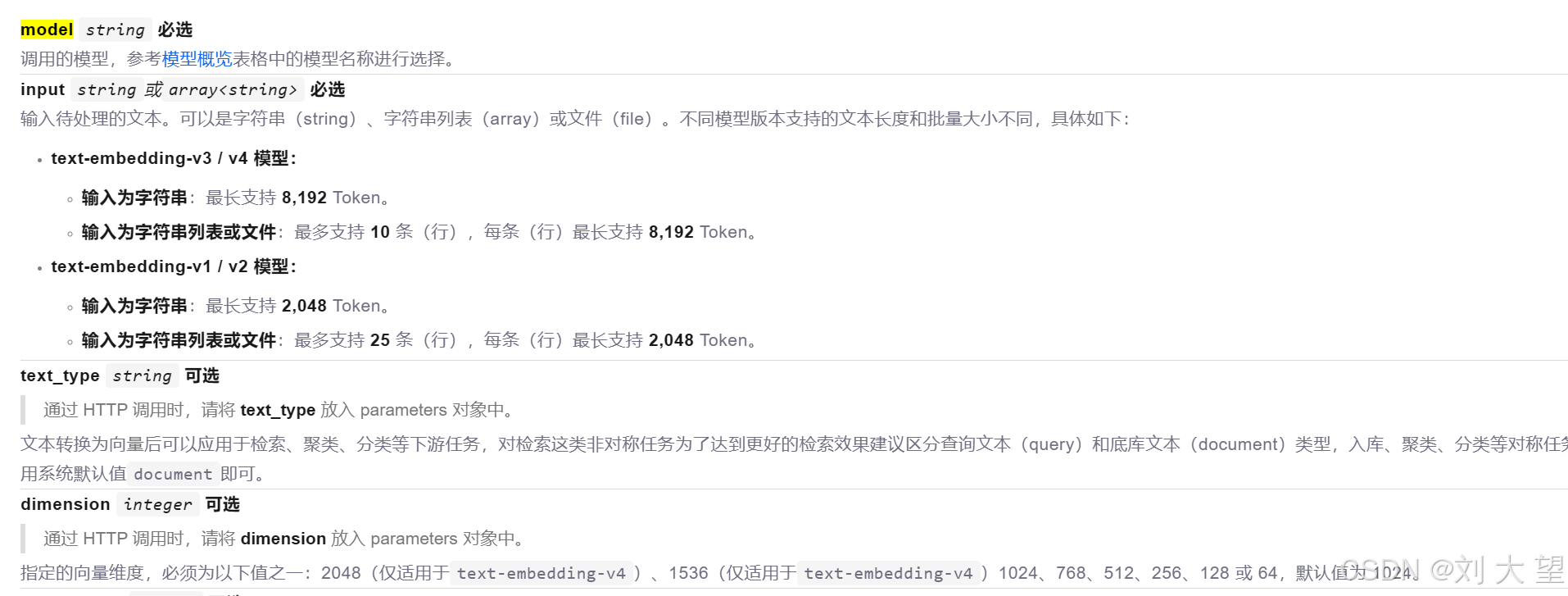
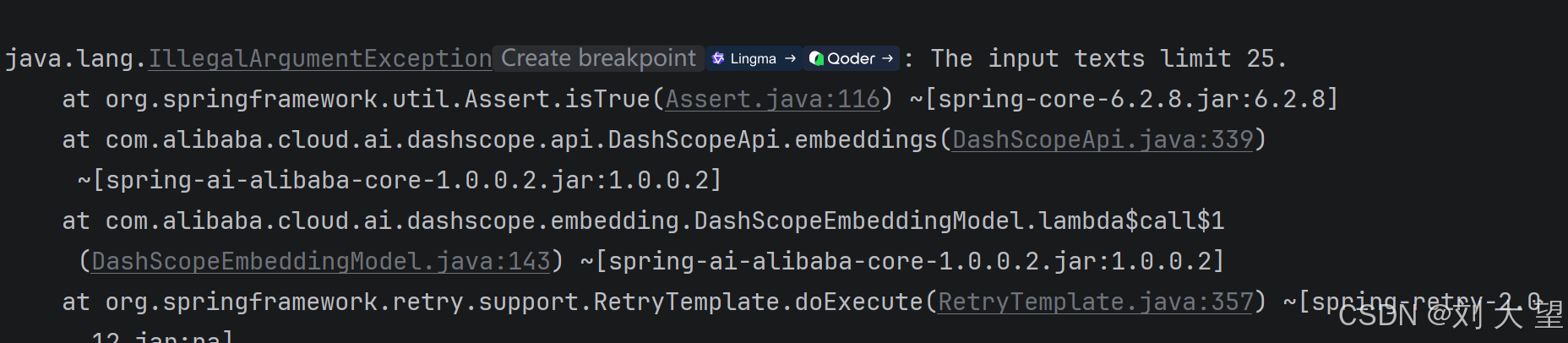
5.3批次测试
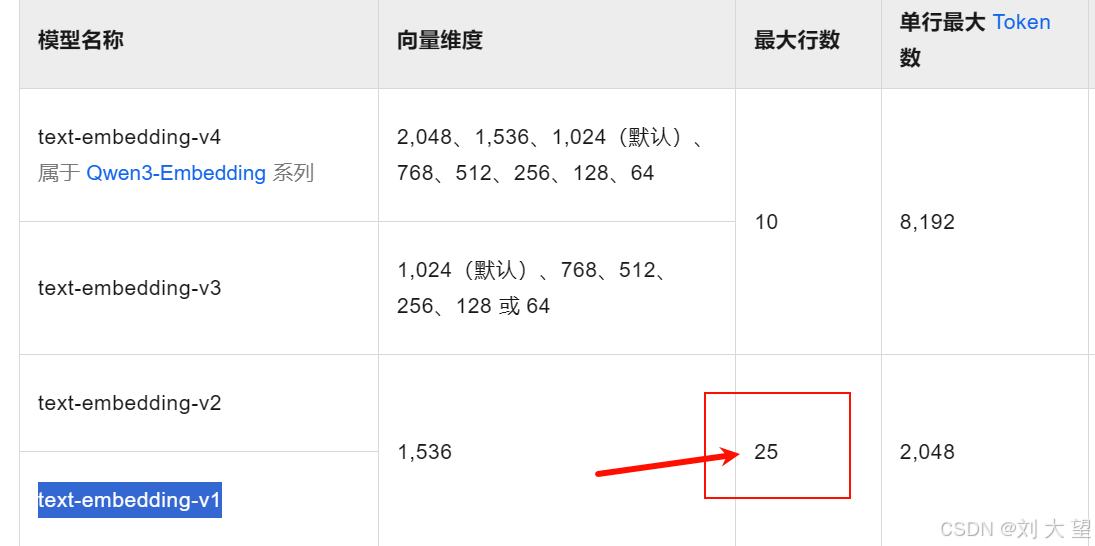
每次处理的文本本能多余25个
@Test
public void batchEmbedding() {
List<String> texts = List.of("Hello, World!", "Hello, World!", "Hello, World!", "Hello, World!"
, "Hello, World!", "Hello, World!", "Hello, World!", "Hello, World!", "Hello, World!", "Hello, World!"
, "Hello, World!", "Hello, World!", "Hello, World!", "Hello, World!", "Hello, World!", "Hello, World!"
);
List<float[]> embeds = embeddingModel.embed(texts);
System.out.println(embeds.size());
}多余的时候报错如图
5.4测试维度
添加配置
spring:
ai:
dashscope:
api-key: ${DASH_SCOPE_API_KEY}
embedding:
options:
model: text-embedding-v3
dimensions: 512
运行第一个测试代码
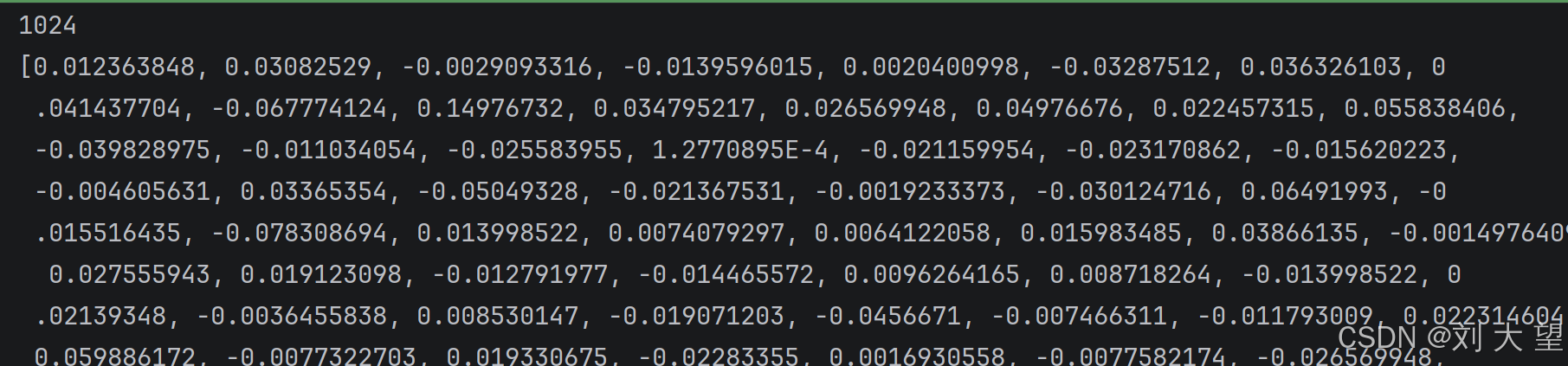
可以看到结果虽然配置了维度是512 但是输出的还是v3模型默认的1024 我觉得是(spring ai alibaba的bug)
6.向量存储
6.1向量存储的核心作用
文本转化为向量之后,需要把向量存储到向量数据库中,并利用向量数据库来计算两个向量之间的相似度,或者根据一个向量查找跟这个向量相似的向量。
6.2Spring AI 的向量能力支持
Spring AI 提供了一套统一的 API,让开发人员不用关心底层实现逻辑,就能完成以下核心流程:
- 文本转向量(调用 Embedding 模型)
- 存入向量数据库
- 接收用户问题 → 转向量 → 搜相似内容 → 返回给大模型做回答
Spring AI 支持多种数据库,目前支持的向量数据库参考:spring ai官方链接 我们熟悉的一些数据库都可以用来存储向量,比如 Elasticsearch、MongoDB、Oracle、Redis 等。入门阶段,我们先使用 SimpleVectorStore 来存储向量。
6.4SimpleVectorStore 介绍
SimpleVectorStore 是 Spring AI 内置的一个「内存版」向量数据库,无需外部依赖,开箱即用,特别适合本地测试和快速原型开发。
SimpleVectorStore 实现了 VectorStore,VectorStore 继承了 DocumentWriter(文档写入的接口,后续会讲),因此具备文档写入的能力。
6.4.1为什么选择 SimpleVectorStore
- Spring AI 原生支持,不需要额外集成
- 其他专业的向量数据库(如 Pinecone、Milvus 等)有一定使用门槛与运维成本,在入门学习阶段暂不涉及相关内容。
6.5快速上手
6.5.1代码
import com.alibaba.cloud.ai.dashscope.embedding.DashScopeEmbeddingModel;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
@SpringBootTest
public class VectorStoreTest {
private SimpleVectorStore vectorStore;
@Autowired
private DashScopeEmbeddingModel dashScopeEmbeddingModel;
@BeforeEach
void setUp() {
this.vectorStore = SimpleVectorStore.builder(dashScopeEmbeddingModel).build();
}
@Test
void save() {
// 1. 声明内容文档
Document doc = Document.builder()
.text("2026年米兰-科尔蒂纳丹佩佐冬奥会将于意大利举办,预计汇聚全球顶尖冰雪运动员参赛")
.build();
Document doc2 = Document.builder()
.text("大语言模型RAG检索增强技术的落地实践与性能优化方案")
.build();
Document doc3 = Document.builder()
.text("清晨的薄雾漫过青石板路,檐角的露珠坠落在盛放的兰草上")
.build();
Document doc4 = Document.builder()
.text("基于多模态大模型的跨模态语义对齐与内容生成研究")
.build();
// 2. 将文本进行向量化,并且存入向量数据库(大模型自动完成无需再手动向量化)
vectorStore.add(Arrays.asList(doc, doc2, doc3, doc4));
System.out.println("向量数据库初始化完成");
}
}
6.5.2结果
6.5.3向量数据库存了什么
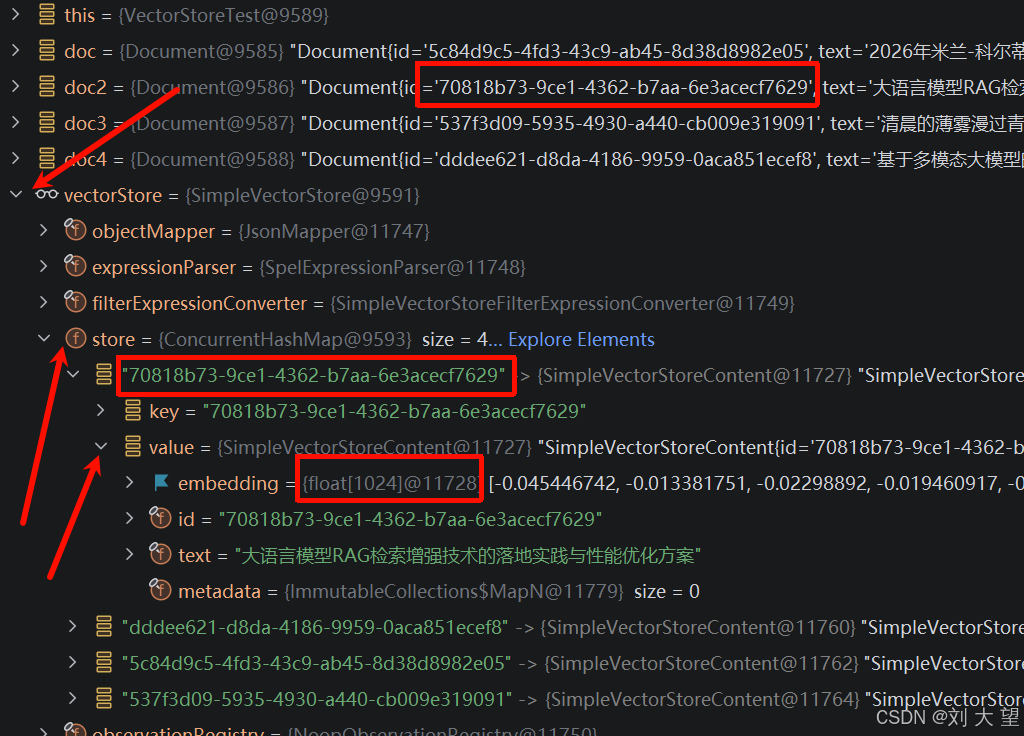
simpleVectorStore是内存向量数据库不能可视化 可以debug的方式启动
6.5.4代码解释
vectorStore.add(Arrays.asList(doc, doc2, doc3, doc4));这个add方法底层是怎么实现的
还是调用embedding的embed方法转化为向量 然后构建SimpleVectorStoreContent对象 最后存储到数据库中 simpleVectorStore本质还是一个Map类型
protected Map<String, SimpleVectorStoreContent> store = new ConcurrentHashMap();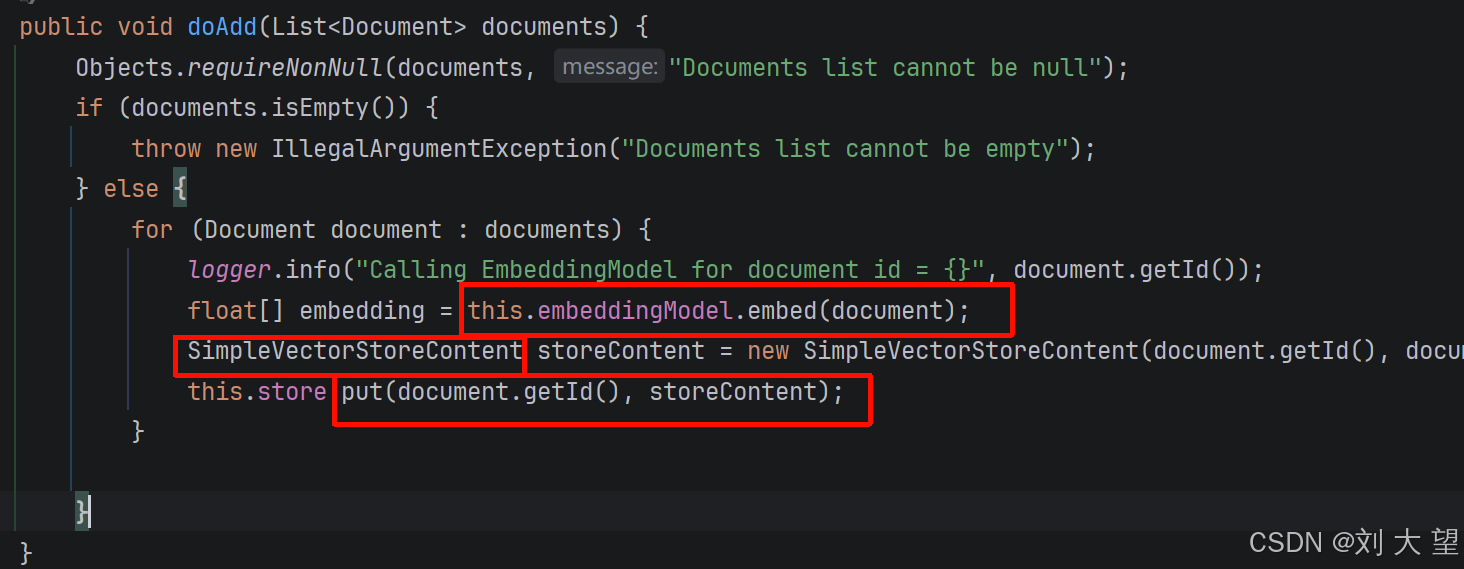
7.相似性检索
向量存入到向量数据库之后,就可以来查找了,把上述代码进行修改
在Spring AI中 VerctorStore也提供了相似性检索的方法similaritySearch
7.1代码
import com.alibaba.cloud.ai.dashscope.embedding.DashScopeEmbeddingModel;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
import java.util.List;
@SpringBootTest
public class VectorStoreTest {
private SimpleVectorStore vectorStore;
@Autowired
private DashScopeEmbeddingModel dashScopeEmbeddingModel;
@BeforeEach
void setUp() {
this.vectorStore = SimpleVectorStore.builder(dashScopeEmbeddingModel).build();
//向量数据库只需要加载一次
// 1. 声明内容文档
Document doc = Document.builder()
.text("2027年米兰-科尔蒂纳丹佩佐冬奥会将于意大利举办,预计汇聚全球顶尖冰雪运动员参赛")
.build();
Document doc2 = Document.builder()
.text("大语言模型RAG检索增强技术的落地实践与性能优化方案")
.build();
Document doc3 = Document.builder()
.text("清晨的薄雾漫过青石板路,檐角的露珠坠落在盛放的兰草上")
.build();
Document doc4 = Document.builder()
.text("基于多模态大模型的跨模态语义对齐与内容生成研究")
.build();
// 2. 将文本进行向量化,并且存入向量数据库(大模型自动完成无需再手动向量化)
vectorStore.add(Arrays.asList(doc, doc2, doc3, doc4));
System.out.println("向量数据库初始化完成");
}
// @Test
// void save() {
//
// }
@Test
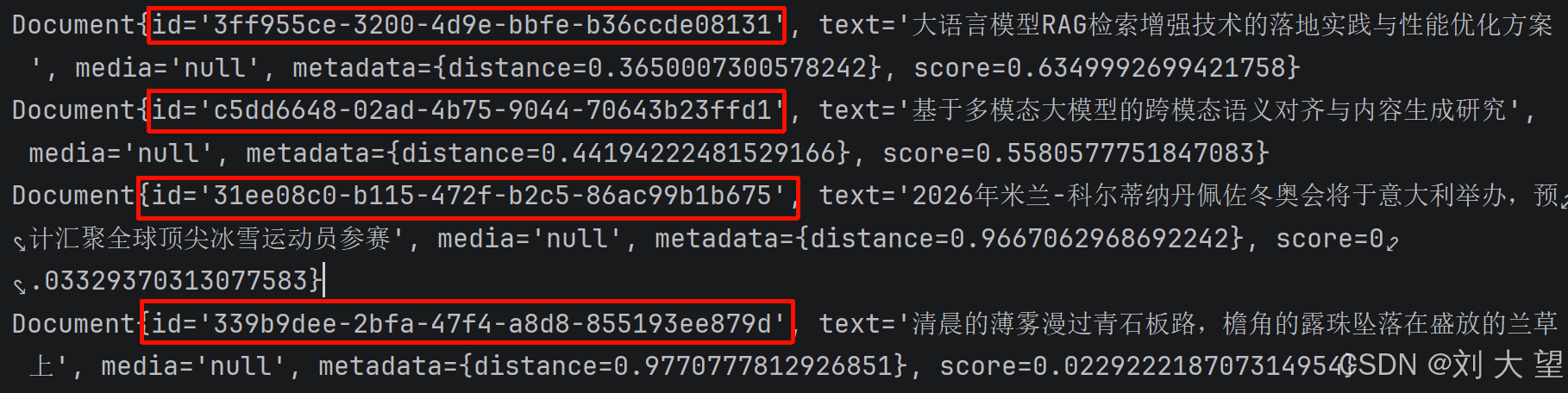
void similaritySearch() {
List<Document> documents = vectorStore.similaritySearch("大语言模型");//根据文本检索
documents.forEach(System.out::println);
}
}7.2结果
7.3问题
按照我们理解的语言来说 返回的应该是第二个文档 再次返回二和四 但是目前把所有的文档都返回过来了 如何解决呢 此时就需要通过相似度(score分数)来过滤了
7.4解决
看到similaritySearch重载的另一个方法可以传入一个查询的请求对象这里面就可以传入过滤的参数了

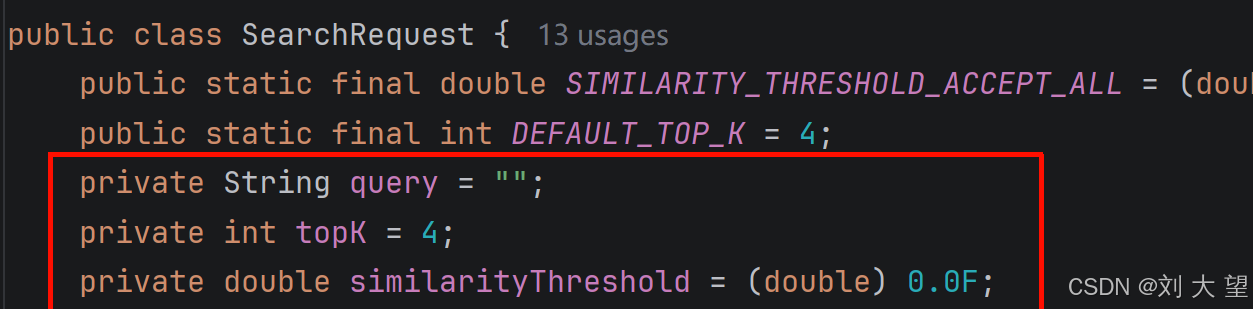
修改后的代码
@Test
void similaritySearch() {
// List<Document> documents = vectorStore.similaritySearch("大语言模型"); //根据文本检索
// documents.forEach(System.out::println);
SearchRequest searchRequest = SearchRequest.builder()
.query("大语言模型") //查询的文本
.topK(5) //匹配文档的前N个
.similarityThreshold(0.5) //相似度分数大于等于0.5
.build();
List<Document> documents = vectorStore.similaritySearch(searchRequest);
documents.forEach(System.out::println);
}结果

把过滤分数改成0.6 进一步的结果

7.5源码
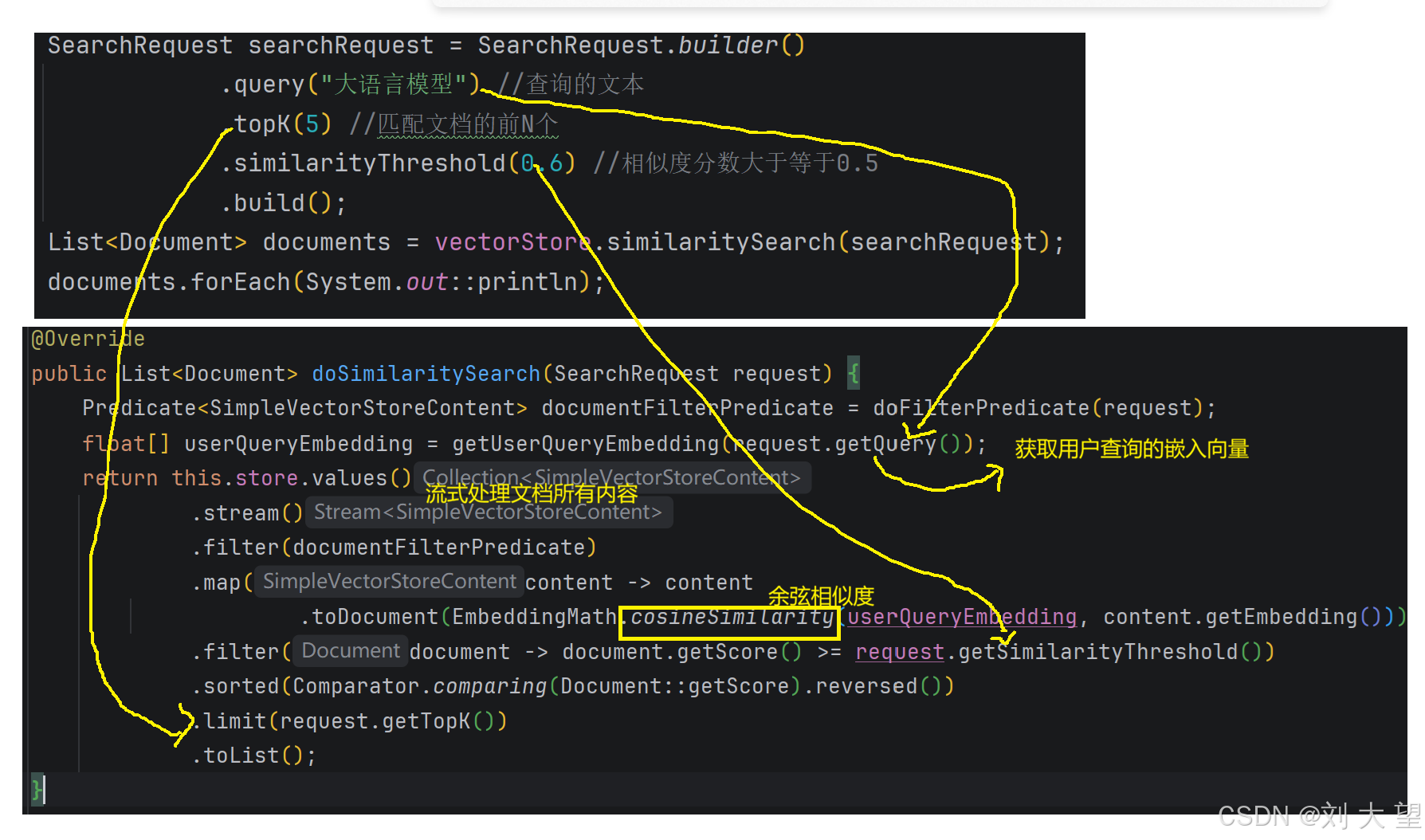
8.Advisor(实现检索增强生成)
8.1介绍
通过上面的案例可以观察到,如何根据关键词从向量数据库中进行搜索相似语义的词。但是在实际应用中,AI 模型本身是 "知识封闭" 的 —— 它只能基于训练时所见的数据生成回答,无法知晓训练数据之外的新信息 (如企业私有文档、最新政策等)。那么,如何将向量数据库中的内容作为额外上下文传递给大模型 (LLM),使其在推理时 "看到" 这些外部知识?
Spring AI 提供了基于 Advisor 机制 的开箱即用支持,用于实现检索增强生成 (RAG, Retrieval-Augmented Generation)。其中,QuestionAnswerAdvisor、RetrievalAugmentationAdvisor 是 Spring AI 中实现 RAG 的两个核心组件,分别适用于不同层次和复杂度的场景。
8.1.1QuestionAnswerAdvisor: 面向问答场景的语义检索增强
QuestionAnswerAdvisor 是专为问答系统设计的 Advisor 实现。当你希望快速构建一个基于知识库的智能客服或 FAQ 助手时,它是首选方案。
在用户提问时,它会自动将问题转换为 Embedding 向量,并在配置好的向量存储 (Vector Store) 中进行相似性搜索,找出最相关的文档片段。
例如,当用户提问:"如何申请年假?" 时,
QuestionAnswerAdvisor会:
- 调用 Embedding 模型将问题编码为向量;
- 在企业内部文档的向量数据库中检索 top-k 最相似的段落;
- 将这些段落作为上下文拼接到原始 Prompt 中;
- 最终将增强后的 Prompt 交给 LLM 进行回答生成。
advisor相当于又在向量数据库外套了一层 借助别人的力量完善自己

这种方式不仅提升了回答的准确性,还确保了输出内容源自可信的知识源,避免了 "幻觉" 问题。
适用场景:企业内部制度查询、产品帮助文档问答、标准化流程咨询等结构化程度较高的问答任务。
8.1.2RetrievalAugmentationAdvisor: 灵活可控的通用 RAG 增强层
相较于 QuestionAnswerAdvisor 的开箱即用,RetrievalAugmentationAdvisor 提供了更高级别的可定制能力。它不局限于问答场景,而是作为一个通用的增强层,适用于任何需要引入外部知识的生成任务。
开发者可以通过实现自定义的 Retriever 接口来控制检索逻辑,比如结合关键词匹配与向量相似度的混合检索策略,或者引入重排序 (re-ranker) 机制提升召回质量。同时,还可以通过 PromptTemplate 灵活定义上下文如何融入最终提示。
8.2使用
8.2.1引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>8.2.2应用
AI 模型并不知道向量数据库存储的数据,当用户的问题发送到 AI 模型时,QuestionAnswerAdvisor 会向向量数据库查询与用户问题相关的文档。检索得到的文档,会被附加到用户的提问文本中,为 AI 模型的响应提供上下文。
代码
不加入advisor效果
@Test
void testAdvisor(@Autowired ChatModel chatModel) {
ChatClient client = ChatClient.builder(chatModel).build();
String message = "米兰奥运会什么时候举行";
String content = client.prompt().user(message).call().content();
System.out.println(content);
}
结果

加入advisor效果
@Test
void testAdvisor(@Autowired ChatModel chatModel) {
ChatClient client = ChatClient.builder(chatModel).build();
QuestionAnswerAdvisor advisor = QuestionAnswerAdvisor.builder(vectorStore).build();
String message = "米兰奥运会什么时候举行";
String content = client.prompt().user(message).advisors(advisor).call().content();
System.out.println(content);
}结果
Document doc = Document.builder()
.text("2027年米兰-科尔蒂纳丹佩佐冬奥会将于意大利举办,预计汇聚全球顶尖冰雪运动员参赛")
.build();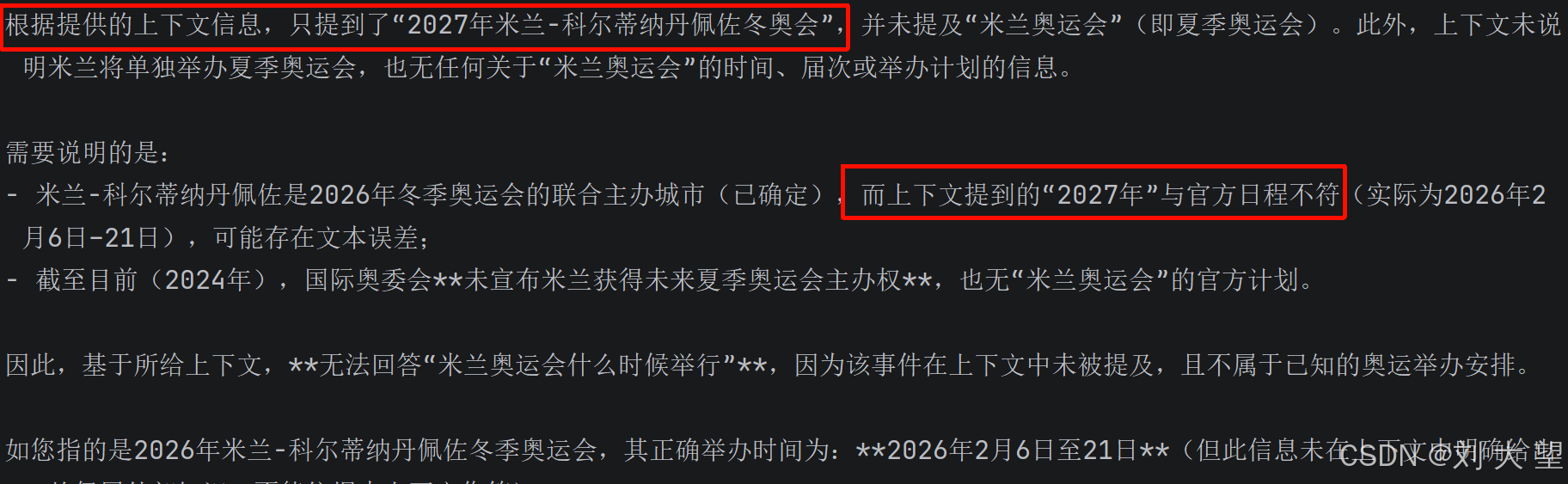
可以看到确实加载了上述文档只不过是文档内容与实际有错误
为了更好的搜索文档,我们也可以在创建 QuestionAnswerAdvisor 时,配置 SearchRequest(一个类似 SQL 的过滤器表达式)
代码
@Test
void testAdvisor2(@Autowired ChatModel chatModel) {
ChatClient client = ChatClient.builder(chatModel).build();
QuestionAnswerAdvisor advisor = QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder().
query("米兰奥运会")
.topK(5)
.similarityThreshold(0.4).build())
.build();
String message = "米兰奥运会什么时候举行";
String content = client.prompt().user(message).advisors(advisor).call().content();
System.out.println(content);
}使用 QuestionAnswerAdvisor 完成问答场景时,有一个默认的模版,来使用检索到的文档来扩充用户问题。
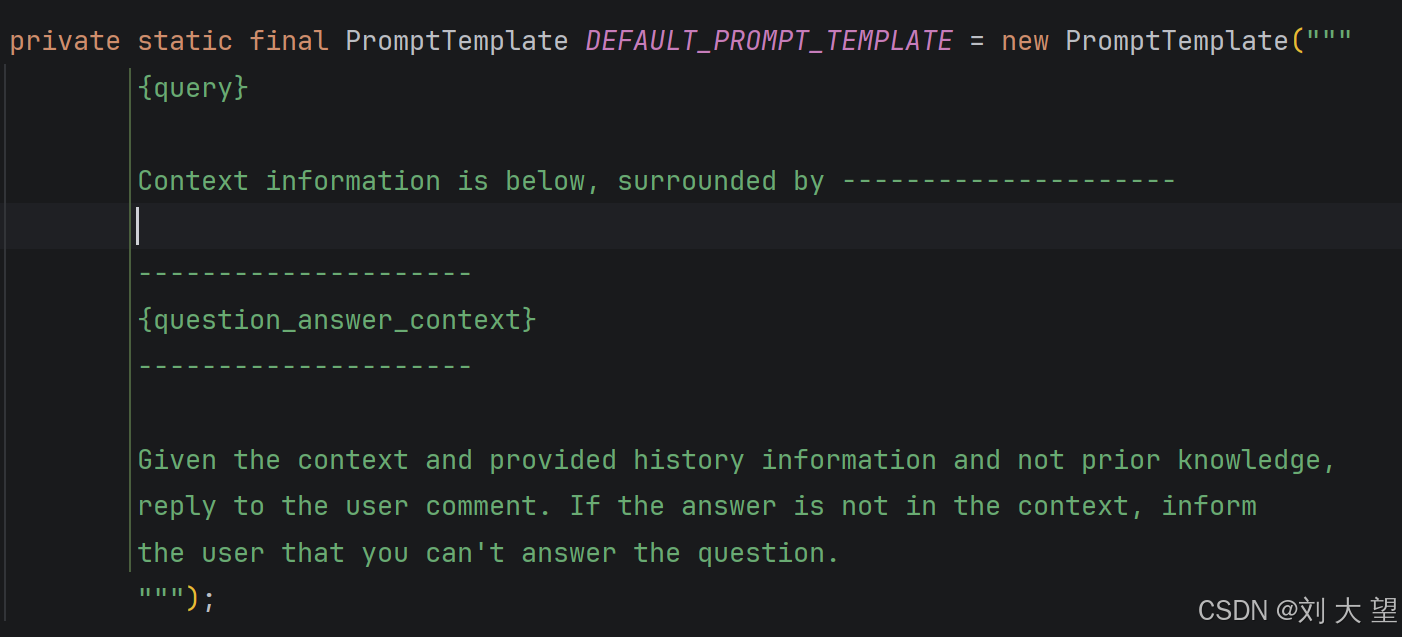
翻译成中文如下
根据上下文和提供的历史信息(而非先验知识), 回复用户评论。如果答案不在上下文中,请告知 用户您无法回答该问题。
开发人员也可以通过 .promptTemplate() 提供自己的 PromptTemplate 对象来自定义此行为。
自定义 PromptTemplate 可以使用任何 TemplateRenderer 实现(默认情况下,它基于 StringTemplate 引擎使用 StPromptTemplate),重要的要求是模板必须包含以下两个占位符:
<query>:用于接收用户的问题的占位符<question_answer_context>:用于接收检索到的上下文的占位符
代码
@Test
void testAdvisor3(@Autowired ChatModel chatModel) {
ChatClient client = ChatClient.builder(chatModel).build();
PromptTemplate promptTemplate = new PromptTemplate("""
{query}
下面是上下文信息
---------------------
{question_answer_context}
---------------------
根据给定的上下文信息进行回复, 并遵守以下规则:
1. 如果上下文信息中有相关的知识, 使用上下文的信息进行回复
2. 如果上下文信息中没有相关的知识, 直接回复"不知道"
3. 在回复时, 尽量避免使用"根据提供的信息...", "根据上下文信息..."类似的话语
""");
QuestionAnswerAdvisor advisor = QuestionAnswerAdvisor.builder(vectorStore)
.promptTemplate(promptTemplate) //添加提示模板
.searchRequest(SearchRequest.builder().
query("米兰奥运会")
.topK(5)
.similarityThreshold(0.4).build())
.build();
String message = "米兰奥运会什么时候举行";
String content = client.prompt().user(message).advisors(advisor).call().content();
System.out.println(content);
}结果

第一期结束可以看以下图片来理解 用户从提问到AI回答的整个流程中RAG是怎么工作的
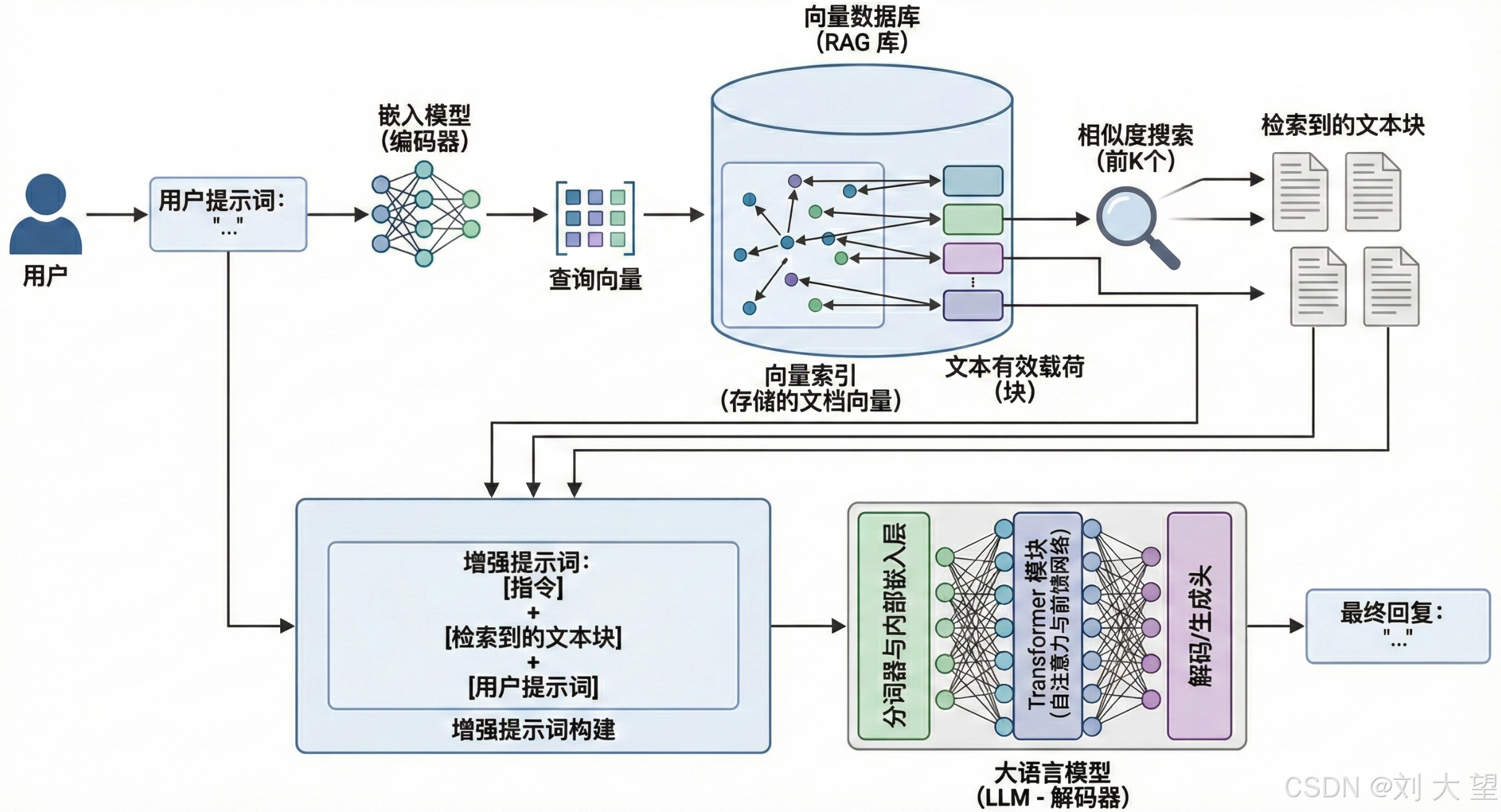
想了解更多内容请看第二期(如没有则会在一周之内发布)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 44
44 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)