RNN,LSTM,BiLSTM算法的具体细节
NLP-AHU-046
各位CSDN的小伙伴们,大家好,对于学习深度学习序列模型的同学们来说,我们会无可避免的遇到RNN(循环神经网络),LSTM(长短期记忆网络),BiLSTM(双向 LSTM)这些在深度学习中非常重要的三兄贵。

那么接下来博主将根据自身的理解来为大家从算法设计启发,设计思路,算法细节和数学表达这几个方面来剖析这三个算法。
一、循环神经网络 RNN (Recurrent Neural Network)(会记一点东西,但记性很差的普通人)
RNN设计启发
传统前馈神经网络(如 MLP、CNN)无法处理序列依赖,比如文本、语音、时间序列。人类理解语言是按顺序、依赖上下文的,RNN 就是模拟这种“记忆之前信息”的过程。其设计灵感,正是源于人类的记忆机制和大脑神经元的反馈连接。其核心思想是对每个时间步,网络不仅接收当前输入,还接收上一时刻的隐藏状态,从而形成循环依赖。
RNN结构设计
结构图:
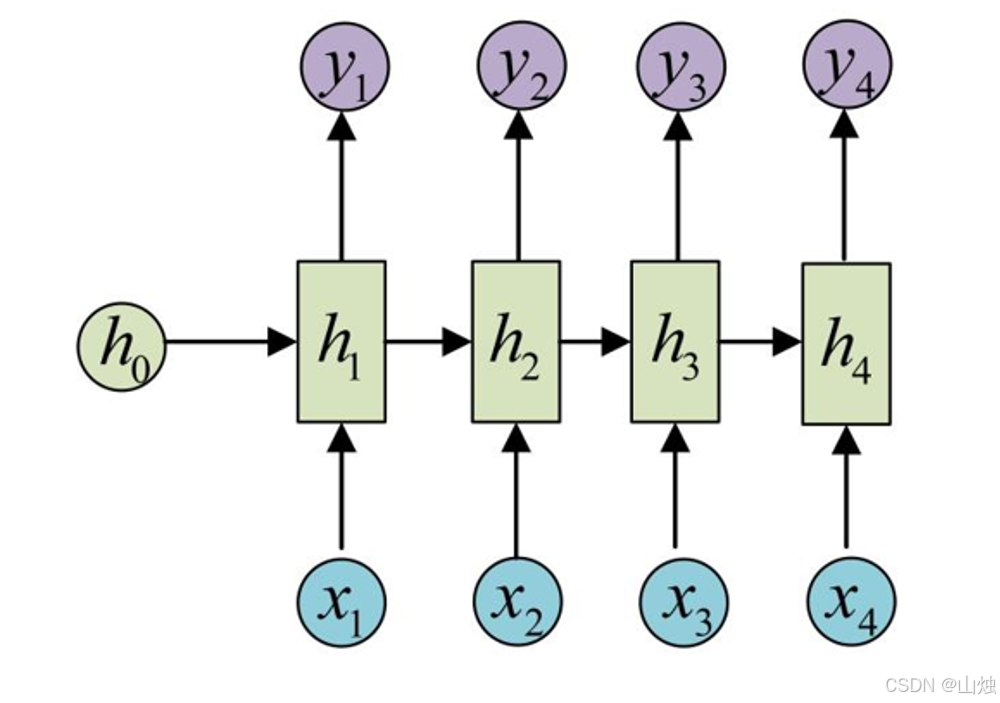
- 输入序列:x1,x2,…,
- 隐藏状态序列:h1,h2,…,
- 输出序列:y1,y2,…,
算法与数学表达
隐藏状态更新
:第 t 时刻隐藏状态
:第 t 时刻输入
:上一时刻隐藏状态(记忆)
:输入到隐藏层权重
:隐藏层自循环权重
- σ:通常为 tanh 或 sigmoid
输出(可选,视任务而定)
小结
RNN作为算法三兄贵的老大哥,其有着结构简单、能建模时序、有短期记忆和适配多种序列任务等优点。但应其训练模型的局限性会训练次数的增加导致训练的梯度消失或爆炸,从而使得RNN无法处理长序列。所以为了LSTM(长短期记忆网络)的诞生就是为了解决上述RNN算法的局限的。
二、长短期记忆网络 LSTM (Long Short-Term Memory)(带笔记本、会筛选记忆的学霸)
LSTM设计启发
为解决RNN无法处理长序列问题,研究者提出LSTM(Long Short-Term Memory)。它在RNN基础上增加了门控机制,能像个带笔记本的学霸一样,筛选所需要的重要"记忆“(信息),遗忘无关信息,以此来实现对长序列的处理。这就好比你在上课时,你的笔记本只会记录老师上课所讲解的重点,而不是记录你昨天和早上吃了什么。这样才能使你的笔记本上能记录更多你所需要的重要的信息。
LSTM结构设计和算法表达
LSTM 包含 4 个非线性层 + 1 条细胞状态链: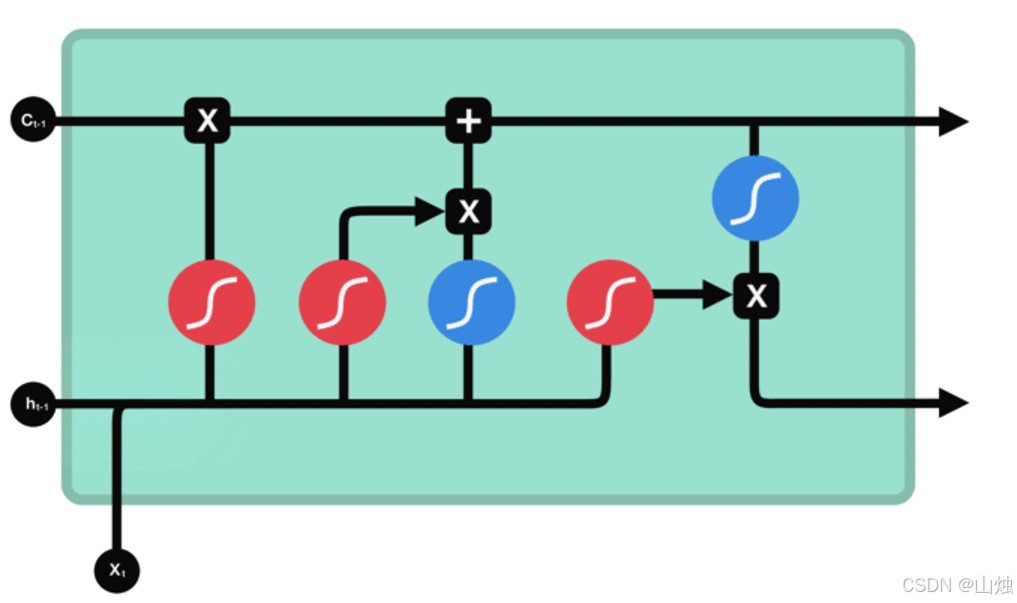
- 遗忘门
- 输入门
- 候选细胞状态
- 细胞状态更新
- 输出门
- 隐藏状态
LSTM的核心:3种门控结构
对于LSTM算法来说,其核心便是三种门控结构:
(1)遗忘门(Forget Gate):决定“忘什么”
- 功能:筛选上一步细胞状态(
Cₜ₋₁,LSTM的“长期记忆”载体)中需要保留或丢弃的信息
(2)输入门(Input Gate):决定“记什么”
- 功能:更新细胞状态,将当前输入的重要信息存入“长期记忆”。
(3)输出门(Output Gate):决定“输出什么”
- 功能:根据当前细胞状态和输入,生成当前隐状态
hₜ(LSTM的“短期记忆”),传递到下一步。
小结
作为改进版的RNN,LTSM能RNN功能的基础上更好的处理长序列问题,更有缓解梯度消失和记忆可控制等优点。但其缺点也很明显,因为其比 RNN 多了多组权重矩阵,所以它的计算和训练成本更高。并且因为其算法依旧是串行计算,无法像 Transformer 那样并行处理时间步。且其算法中门控多,初始化、学习率等参数需要更精细调节。虽然LSTM缓解了梯度消失,但梯度爆炸问题仍需梯度裁剪等手段处理。
三、双向长短期记忆 BiLSTM (Bidirectional LSTM)(既能往前看,又能往后看的 “上帝视角”)
BiLSTM设计启发
在深度学习中很多任务不仅依赖前文,还依赖后文。而单向 LSTM 只能看到过去,看不到未来。所以BiLSTM(双向长短期记忆 )应运而生,其使用双向的LSTM来达到对任务的瞻前顾后。就像开了“上帝视角”的人一样,既能见证过去,亦能远望未来。
BiLSTM结构设计
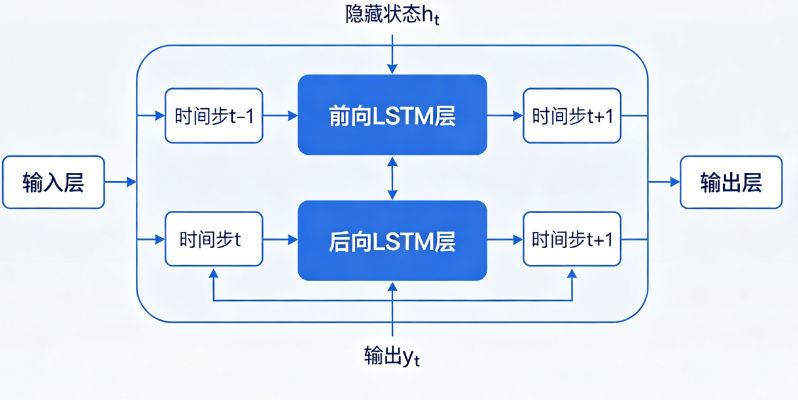
同时训练两个独立 LSTM:
- 前向 LSTM:从
→
- 反向 LSTM:从
每个时刻 t 的最终隐藏状态 = 拼接:
算法与数学表达
前向
反向
最终表示
再通过全连接层输出:
小结
虽然BiLSTM没有解决上述LSTM的各种缺点,但其在信息利用层面弥补了单向 LSTM 的不足,提高了任务完成的正确率。
四、总结
| 模型 | 核心思想 | 优点 | 缺点 |
|---|---|---|---|
| RNN | 循环共享权重,简单记忆 | 结构简单、序列建模 | 梯度消失,无法长依赖 |
| LSTM | 门控 + 细胞状态,可控记忆 | 长依赖强,梯度稳定 | 结构复杂、计算量大 |
| BiLSTM | 双向 LSTM,上下文建模 | 利用完整上下文,效果强 | 不能实时,参数量大 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)