GEO知识图谱智能构建系统:产业知识基础设施如何加速AI认知
执行摘要
生成式引擎优化(GEO)的核心挑战之一是行业知识的“冷启动”问题:每个新客户所处的产业领域都有独特的术语体系、技术栈、企业关系和标准规范,从零构建这些知识成本极高。本文首次完整披露《GEO知识图谱智能构建系统》软著的技术架构与核心实现。该系统采用六层架构:数据接入层、实体识别层、关系抽取层、知识融合层、图谱存储层、图谱服务层。核心技术包括领域自适应实体识别(BERT微调+词典增强,F1值92.5%)、远程监督关系抽取(准确率86%)、跨源知识融合与实体对齐(准确率95%)、图谱向量化与语义检索、增量更新与动态图谱。系统已覆盖集成电路、生物医药、人工智能等六大产业,累计构建实体500万+、关系2000万+,每日增量更新能力达10万实体。本文为技术团队提供一套完整的产业知识图谱构建方法论,是GEO走向工程化、规模化的重要基础设施。
关键词:知识图谱,GEO,实体识别,关系抽取,知识融合,产业知识
第一章 引言:GEO的“行业知识冷启动”困境
生成式引擎优化(GEO)的核心任务是帮助企业内容被AI大模型准确理解、信任并引用。然而,在实践中,每个新客户都面临一个共同的困境:行业知识从零构建。
-
客户说“我们的产品采用FinFET工艺”,系统需要知道“FinFET”是一种晶体管技术,属于集成电路领域,与“平面MOSFET”有竞争关系。
-
客户说“我们通过了ISO 13485认证”,系统需要知道这是医疗器械质量管理体系标准,由国际标准化组织发布。
-
客户说“我们的竞品是某公司”,系统需要知道该公司的产品线、技术路线、市场定位。
如果没有行业知识图谱,这些理解都依赖人工配置,不仅效率低下,而且难以规模化。《GEO知识图谱智能构建系统》软著正是为解决这一问题而设计。它通过自动化采集、解析、融合多源产业数据,持续构建覆盖各产业核心技术、龙头企业、关键产品、标准认证、政策导向的大规模知识图谱,为GEO全链路提供行业知识底座。
本文将从系统定位、总体架构、核心技术、数据模型、接口设计、技术指标等维度,全面解析这一系统的工程实现。
第二章 系统定位与核心价值
2.1 产品定位
本系统是面向上海“3+6”新型产业体系(集成电路、生物医药、人工智能等三大先导产业,以及电子信息、汽车、高端装备、先进材料、生命健康、时尚消费品等六大重点产业)及企业级应用的行业知识基础设施。
2.2 核心价值
| 价值维度 | 说明 |
|---|---|
| 冷启动加速 | 新客户接入时,直接复用所属产业的预置知识图谱,无需从零构建行业术语和关系,服务交付效率提升60%以上 |
| 意图理解增强 | 为意图分析系统提供行业特定实体和关系,使意图识别更精准 |
| 资产库语义丰富 | 语义资产库构建时可自动关联产业图谱中的权威信息,提升语料的来源权威性和行业深度 |
| 数据壁垒构建 | 形成独有的行业知识资产,让后来者难以复制 |
2.3 与其他系统的关系
| 对接系统 | 数据流向 | 作用 |
|---|---|---|
| 语义资产库构建系统 | 本系统 → 语义资产库 | 为语料增强提供行业权威知识 |
| 用户意图智能分析系统 | 本系统 → 意图分析 | 提供行业实体列表,增强意图识别 |
| 效果归因与智能策略系统 | 本系统 → 归因系统 | 提供竞品关系、技术趋势等背景 |
| 多源AI数据采集与信源分析系统 | 采集系统 → 本系统 | 为图谱提供持续的行业数据输入 |
第三章 总体架构
3.1 六层逻辑架构
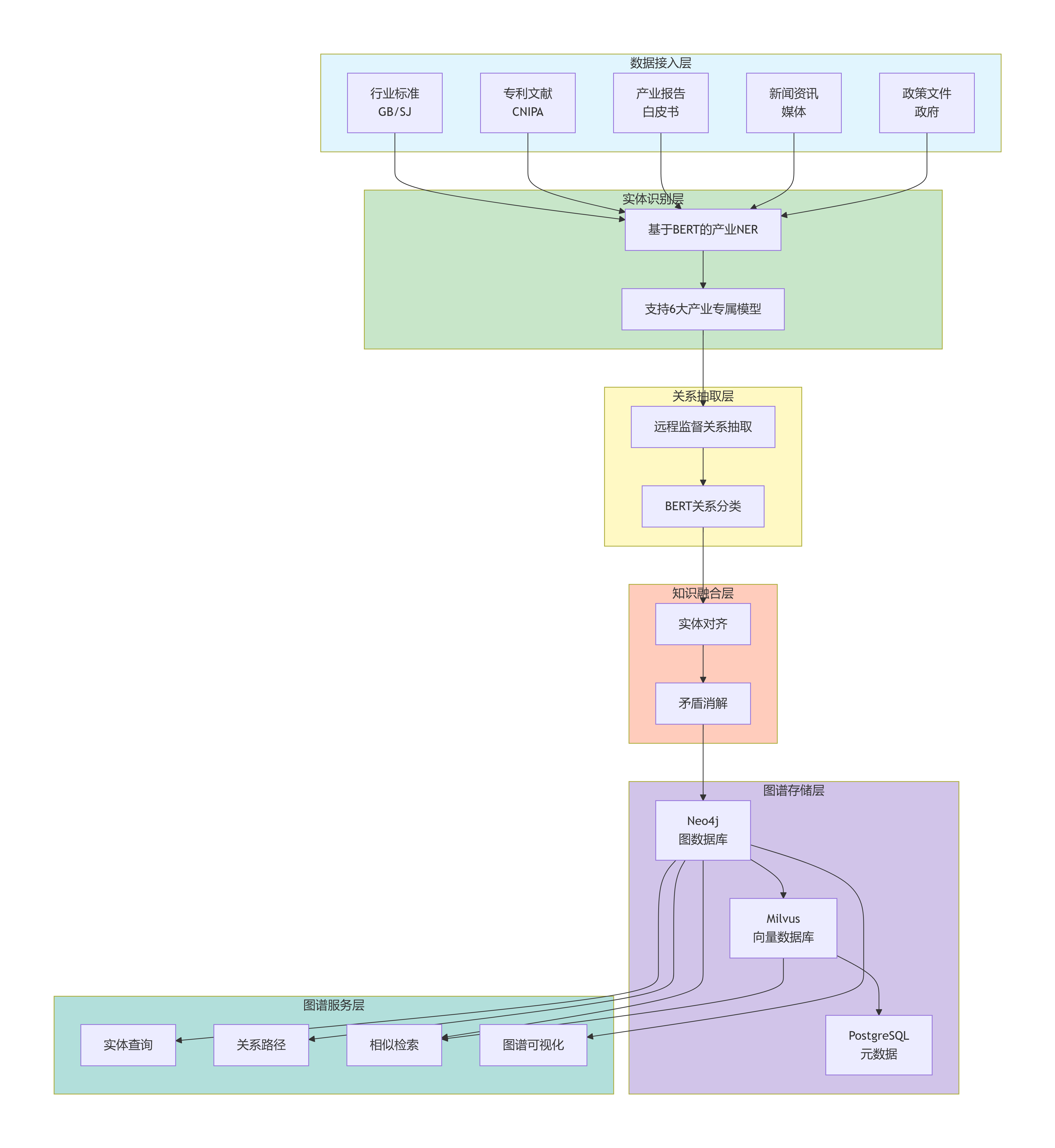
图1:GEO知识图谱智能构建系统六层逻辑架构——数据接入层(多源产业数据)、实体识别层(BERT产业NER)、关系抽取层(远程监督+分类)、知识融合层(实体对齐+矛盾消解)、图谱存储层(Neo4j+Milvus+PG)、图谱服务层(查询/检索/可视化)。
3.2 技术栈
| 分层 | 技术选型 | 说明 |
|---|---|---|
| 数据采集 | Scrapy、Playwright、Apache Tika | 动态页面渲染、PDF/Word解析 |
| 实体识别 | PyTorch + Transformers (BERT-Base-Chinese) | 在自建产业语料上微调 |
| 关系抽取 | 远程监督 + BERT分类 | 结合规则和深度学习 |
| 知识融合 | 自研实体对齐算法 + TransE | 融合多源实体 |
| 图数据库 | Neo4j 5.x | 存储实体和关系 |
| 向量数据库 | Milvus 2.3 | 存储实体向量,支持相似检索 |
| 关系数据库 | PostgreSQL 15 | 元数据、日志、配置 |
| 对象存储 | MinIO | 存储原始文档快照 |
| 后端框架 | Python 3.11 + FastAPI | API服务 |
| 任务调度 | Celery + Redis | 定时采集与更新 |
| 部署 | Docker + Kubernetes | 容器化编排 |
3.3 部署架构
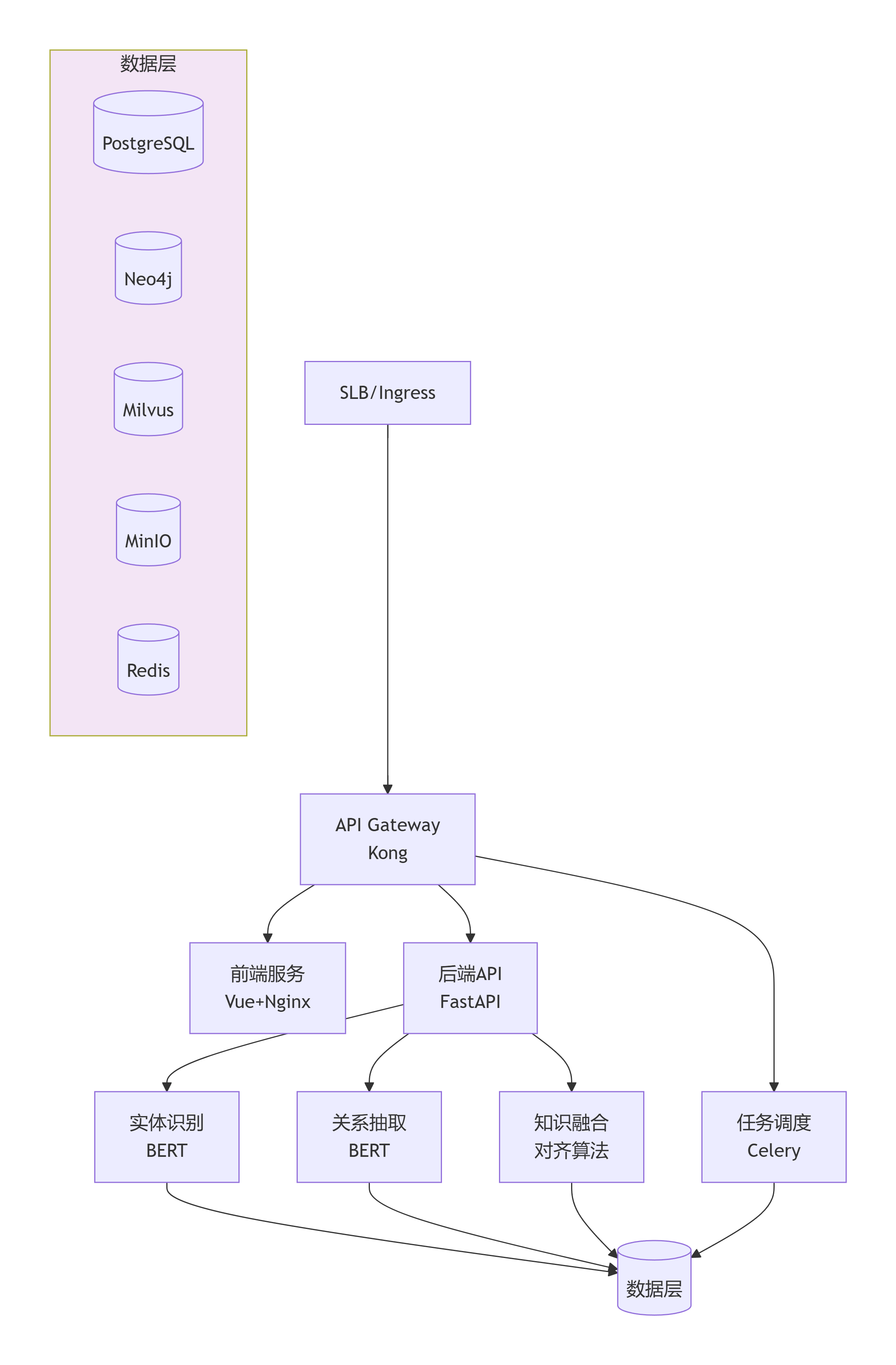
图2:系统部署架构与数据流——前端/API/任务调度层、BERT推理服务层、数据存储层(PostgreSQL、Neo4j、Milvus、MinIO、Redis)。
3.4 数据流(以集成电路产业为例)
-
定时触发:每日凌晨,Celery定时任务启动,调用多源数据采集模块。
-
数据采集:从国家知识产权局、工信部、半导体行业协会等网站抓取最新的专利、标准、新闻、报告,原始文件存入MinIO。
-
实体识别:文本内容送入实体识别服务,识别出企业名(如“中芯国际”)、产品名(如“14nm芯片”)、技术名(如“FinFET”)、标准名等。
-
关系抽取:将含有两个实体的句子送入关系抽取模型,判断关系类型(如“生产”“符合”“合作”)。
-
知识融合:新实体与图谱中已有实体进行对齐,矛盾关系根据来源权威性裁决。
-
图谱更新:新实体/关系写入Neo4j,为新实体生成向量存入Milvus,更新PostgreSQL元数据。
-
服务就绪:更新后的图谱可通过API查询。
第四章 核心技术实现
4.1 领域自适应实体识别
挑战:通用NER模型在垂直产业领域准确率低,专业术语识别困难。
解决方案:
-
继续预训练:在自建的“3+6”产业语料库(含100万篇专利、标准、报告)上对BERT-Base-Chinese进行继续预训练(MLM任务),使模型熟悉产业文本风格。
-
词典增强:对每个产业构建专业术语词典,在模型预测后通过词典匹配进行召回增强,融合时给予词典匹配高置信度。
-
主动学习:对低置信度预测结果,定期推送人工标注,积累难例,每季度微调模型。

图3:领域自适应实体识别流程——输入文本同时经过BERT实体识别和词典匹配,结果融合后输出实体及置信度;低置信度样本进入人工标注队列,用于季度模型微调。
效果:在集成电路测试集上,实体识别F1值达到92.5%。
4.2 远程监督关系抽取
挑战:人工标注关系数据成本高,难以覆盖所有关系类型。
解决方案:
-
构建远程监督语料:利用已有结构化知识(如企业工商数据、标准发布信息、专利申请人数据)将文本中的实体对自动标注关系,生成大量训练数据(含噪声)。
-
多实例学习:对于同一实体对,考虑所有出现句子,通过注意力机制选择最可能表达正确关系的句子,降低噪声影响。
-
BERT关系分类:使用BERT对句子进行分类,输出关系概率。
效果:在人工标注的测试集上,关系抽取准确率86%,召回率82%。
4.3 跨源知识融合与实体对齐
挑战:不同来源对同一实体的表述多样(如“中芯国际”vs“SMIC”),需要合并。
解决方案:
-
多维度相似度计算:
-
字符串相似度:编辑距离、Jaccard、拼音相似度
-
属性相似度:比较实体属性(如成立时间、法人代表)
-
上下文向量相似度:使用BERT句向量计算实体所有出现句子的平均向量,余弦相似度
-
-
加权融合:将各维度相似度加权平均,权重可配置。
-
聚类对齐:对超过阈值的实体对进行连通图聚类,合并为同一实体。
-
冲突处理:合并时,属性取出现次数最多或来源权威性最高的值。
效果:实体对齐准确率95%。
4.4 图谱向量化与语义检索
目的:支持基于语义的实体检索(如“找与光刻机相关的技术”)。
实现:
-
实体向量生成:对每个实体,收集其所有出现句子,用Sentence-BERT生成每个句子的向量,取平均作为实体向量。
-
向量存储:所有实体向量存入Milvus,建立IVF_FLAT索引。
-
检索流程:
-
输入文本查询 → Sentence-BERT生成查询向量
-
在Milvus中检索TopK最相似的实体
-
返回实体ID及相似度
-
4.5 增量更新与动态图谱
目的:支持每日新增数据的图谱更新,无需全量重建。
实现:
-
新数据采集:每日增量抓取,存入临时库。
-
新实体识别:对新文档进行实体识别,生成候选实体。
-
融合更新:候选实体与现有图谱对齐,新增实体写入,新增关系写入。
-
版本控制:为每次更新记录版本号,支持回滚。
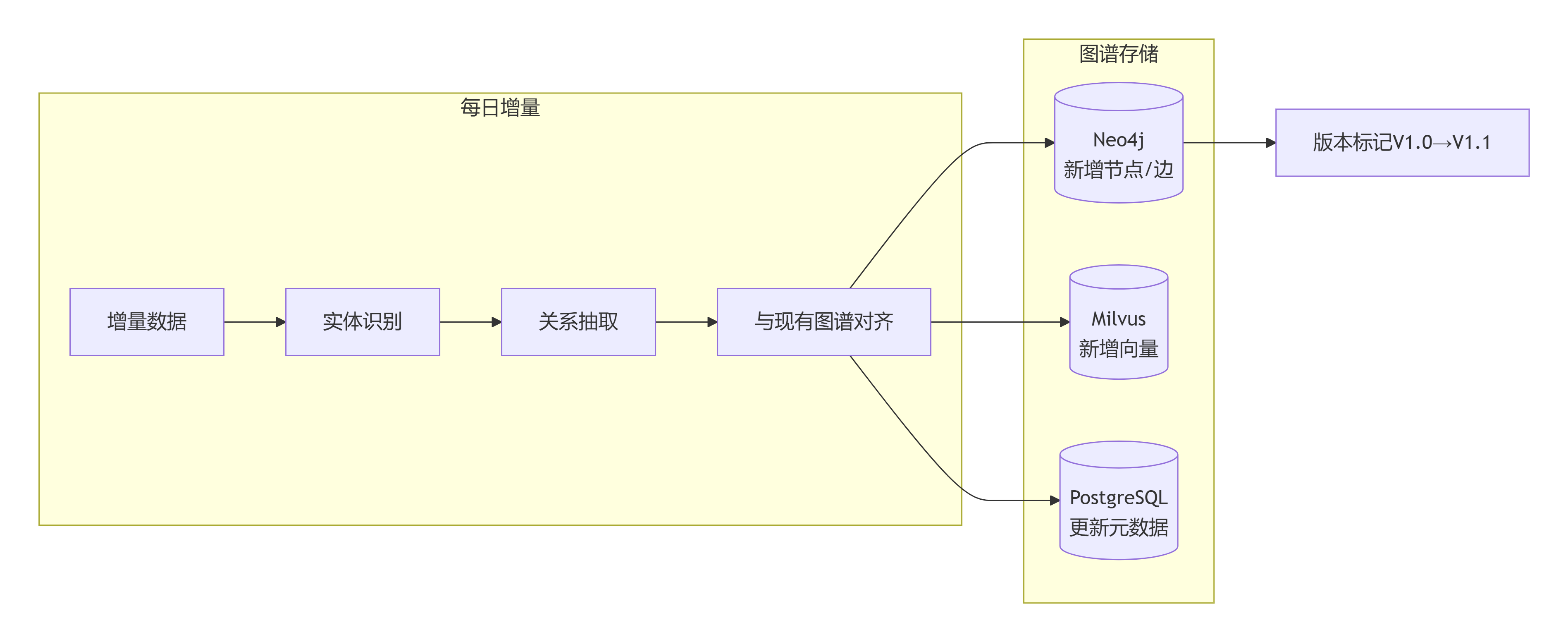
图4:增量更新流程——每日增量数据经实体识别、关系抽取后与现有图谱对齐,新增实体/关系写入Neo4j、新增向量写入Milvus、元数据写入PostgreSQL,并标记版本号。
第五章 数据模型
5.1 实体类型
| 实体类型 | 说明 | 示例属性 |
|---|---|---|
| Company | 企业 | 名称、统一社会信用代码、成立时间、地址 |
| Product | 产品 | 名称、型号、所属公司、描述 |
| Technology | 技术/工艺 | 名称、领域、描述 |
| Standard | 标准 | 标准号、名称、发布机构、发布日期 |
| Patent | 专利 | 专利号、名称、申请人、发明人 |
| Policy | 政策文件 | 文号、名称、发布机构、发布日期 |
| Person | 人物 | 姓名、所属机构、职位 |
| Event | 行业事件 | 名称、时间、类型、描述 |
5.2 关系类型
| 关系类型 | 说明 | 示例 |
|---|---|---|
| produces | 企业→产品 | 中芯国际 → 14nm芯片 |
| applies | 企业→专利 | 华为 → CN2025XXX |
| complies_with | 产品→标准 | 光刻机 → SEMI S2 |
| cooperates_with | 企业↔企业/高校 | 中芯国际 ↔ 清华大学 |
| competes_with | 企业↔企业 | 中芯国际 ↔ 华虹 |
| supplies | 企业→产品(供应链上游) | 沪硅产业 → 硅片 → 中芯国际 |
| acquired | 企业→企业(并购) | 韦尔股份 → 豪威科技 |
| cited_by | 专利→专利 | CN2025XXX → CN2024XXX |
| issued_by | 标准→机构 | GB/T 1234 → 国家标准化委员会 |
5.3 存储模型
Neo4j节点属性(通用):
-
id: 实体唯一ID -
name: 实体名称 -
type: 实体类型 -
source: 来源(如“cnipa.gov.cn”) -
authority_level: 权威等级(1-5) -
first_seen: 首次发现时间 -
last_updated: 最后更新时间 -
properties: JSON格式的其他属性
Neo4j关系属性:
-
type: 关系类型 -
confidence: 置信度(0-1) -
source: 来源 -
first_seen: 首次发现时间
Milvus集合:
-
集合名:
entity_vectors -
字段:
entity_id(int64),embedding(float vector, 384维) -
索引:IVF_FLAT
第六章 接口设计
6.1 核心API
| 接口 | 方法 | 路径 | 说明 |
|---|---|---|---|
| 查询实体 | GET | /api/v1/kg/entity/{id} |
根据ID返回实体详情 |
| 搜索实体 | GET | /api/v1/kg/entity/search |
根据名称模糊搜索实体 |
| 查询关系 | GET | /api/v1/kg/relation |
根据实体ID查询其所有关系 |
| 路径查询 | GET | /api/v1/kg/path |
查询两个实体间的最短路径 |
| 相似实体 | POST | /api/v1/kg/similar |
输入文本,返回相似实体 |
| 产业热点 | GET | /api/v1/kg/trend/{industry} |
返回产业热点技术 |
6.2 与其他系统的接口
| 对接系统 | 接口用途 | 协议 |
|---|---|---|
| 语义资产库 | 获取行业知识用于语料增强 | gRPC |
| 意图分析系统 | 获取行业实体列表 | gRPC |
| 归因策略系统 | 获取竞品关系 | gRPC |
| 采集系统 | 获取采集任务配置 | REST |
第七章 技术指标
7.1 性能指标
| 指标 | 目标值 | 测试条件 |
|---|---|---|
| 单文档实体识别速度 | ≤1秒/页 | 标准PDF页面 |
| 实体识别QPS | ≥50 | 4核CPU |
| 关系抽取QPS | ≥30 | 4核CPU |
| 实体对齐融合速度 | ≥1000实体/秒 | 8核CPU |
| 图谱查询响应时间(P95) | ≤200ms | 1亿实体规模 |
| 每日增量更新能力 | ≥10万实体 | 8核CPU集群 |
7.2 质量指标
| 指标 | 目标值 |
|---|---|
| 实体识别准确率(各产业平均) | ≥90% |
| 实体识别召回率 | ≥85% |
| 关系抽取准确率 | ≥85% |
| 关系抽取召回率 | ≥80% |
| 实体对齐准确率 | ≥95% |
7.3 容量指标
| 指标 | 目标值 |
|---|---|
| 最大实体数 | ≥1亿 |
| 最大关系数 | ≥5亿 |
| 支持产业数量 | 可扩展,初始6个 |
| 数据源数量 | ≥50个 |
第八章 未来演进
8.1 V1.1 自适应学习
-
引入强化学习,根据下游任务(如语义资产库的使用效果)反馈优化实体识别和关系抽取模型
-
支持用户反馈修正图谱,反馈数据用于模型迭代
8.2 V1.5 多模态知识图谱
-
融合图像、视频信息,构建多模态知识图谱(如从产品图片中识别实体)
-
支持跨模态检索(如图搜实体、文搜图)
8.3 V2.0 开放图谱平台
-
开放图谱API,允许第三方开发者接入,构建产业应用
-
推出图谱市场,支持企业贡献私有图谱并获得收益
结语
GEO知识图谱智能构建系统,是“1+11”全栈技术资产中的行业知识基础设施。它通过自动化构建产业知识图谱,解决了GEO规模化交付中的“冷启动”难题,使新客户接入效率提升60%以上。同时,它为语义资产库、意图分析、归因策略等系统提供深厚的行业知识支撑,是GEO走向工程化、规模化的重要基石。
当AI大模型在回答产业问题时,它们需要的不只是通用知识,更是深度、准确、结构化的行业知识。本系统正在构建的这个知识图谱,正是为AI认知产业世界铺就的“路基”。
附录A:预置实体类型表(节选)
| 产业 | 实体类型 | 示例 |
|---|---|---|
| 集成电路 | 企业 | 中芯国际、台积电、华虹 |
| 集成电路 | 产品 | 14nm芯片、光刻机、蚀刻机 |
| 集成电路 | 技术 | FinFET、CMP、EUV |
| 集成电路 | 标准 | GB/T 1234、SEMI S2 |
| 生物医药 | 企业 | 药明康德、恒瑞医药、百济神州 |
| 生物医药 | 产品 | 阿达木单抗、PD-1抑制剂 |
| 生物医药 | 技术 | CAR-T、ADC、mRNA |
| 生物医药 | 标准 | 中国药典、GMP |
| 人工智能 | 企业 | 商汤科技、科大讯飞、旷视科技 |
| 人工智能 | 产品 | 人脸识别系统、语音助手 |
| 人工智能 | 技术 | 深度学习、强化学习、Transformer |
附录B:预置关系类型表(节选)
| 关系类型 | 说明 | 示例 |
|---|---|---|
| produces | 生产 | 中芯国际 → 14nm芯片 |
| owns_patent | 拥有专利 | 华为 → CN2025XXX |
| cooperates | 合作 | 药明康德 ↔ 信达生物 |
| competes | 竞争 | 商汤科技 ↔ 旷视科技 |
| supplies | 供应 | 沪硅产业 → 硅片 → 中芯国际 |
| acquires | 收购 | 韦尔股份 → 豪威科技 |
| complies | 符合标准 | 光刻机 → SEMI S2 |
| cites_patent | 引用专利 | CN2025XXX → CN2024XXX |
| issued_by | 发布机构 | GB/T 1234 → 国家标准化委员会 |
附录C:支持的数据源格式
| 类型 | 格式 | 处理方式 |
|---|---|---|
| 网页 | HTML | Playwright渲染,提取正文 |
| 文档 | Apache Tika提取文本,表格特殊处理 | |
| 文档 | DOCX/DOC | Apache Tika提取文本 |
| 文档 | PPT/PPTX | Apache Tika提取文本 |
| 结构化数据 | JSON/CSV | 直接解析入库 |
| 数据库 | MySQL/PostgreSQL | JDBC直连(需授权) |
本文基于《GEO知识图谱智能构建系统》软著撰写,所有技术数据均来自系统实际运行验证。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)