对于Linux:进程控制的解析
开篇介绍:
hello 大家,我们很快的就再次见面了,哈哈,那么上节课我们初步了解了进程地址空间的概念,知道页表、缺页中断的设计,让我们受益匪浅,而在本篇博客中,我们将了解一个新的概念,进程控制,它是非常重要的内容,将会帮助大家对系统的了解更进一步,让大家的知识大大提高,但是同样的,其之难度,肯定也是成正比的,但是大家大可不必担心,相信自己,我们一定行。
OK,话不多说,我们开始。
我们从 “进程是什么” 的基础概念入手,用 “工厂工人” 的生活类比贯穿始终,把 Linux 进程的创建、终止、等待讲清楚。
一、先搞懂:进程到底是什么?
我们可以把进程理解成 “工厂里的工人”:
- 工厂(操作系统)里有很多工人(进程),每个工人负责一项具体任务(比如 “处理客户订单”“打印文件”);
- 工人干活需要工具(内存、CPU 时间),工厂会给每个工人分配独立的工具间(进程地址空间);
- 工人的 “干活流程” 就是程序(比如
a.out文件),一旦程序运行,就变成了进程。
在 Linux 里,每个进程都有一个唯一的 “工号”——PID(进程 ID),用ps aux命令能看到所有正在干活的 “工人”(进程)。
二、进程创建:用 fork “招一个新工人”
要让工厂多一个工人,Linux 里靠fork函数实现 —— 它的作用就是 “复制一个已有的工人(父进程),得到一个几乎一模一样的新工人(子进程)”。新工人会继承老工人的 “干活流程(代码)”“工具(数据)”,但有自己独立的工号(PID)。
1. fork 函数:“复制工人” 的操作指南
(1)函数原型与头文件
用fork前必须包含头文件,函数本身不需要参数,只返回一个 “工号相关的值”:
#include <unistd.h> // fork函数的头文件
#include <sys/types.h> // pid_t类型的头文件(PID的类型)
pid_t fork(void); // 复制当前进程,返回值是“子进程PID”或“0”或“-1”
pid_t:专门存储 PID 的类型,本质是 “整数”,就像 “工号本”;- 返回值规则(记死!这是理解 fork 的关键):① 若返回
-1:“招工失败”(比如工厂工人满了,系统进程数超限);② 若返回大于 0 的数:“这是老工人(父进程)”,返回的数是 “新工人(子进程)的工号(PID)”;③ 若返回0:“这是新工人(子进程)”,表示 “我是刚复制出来的”。
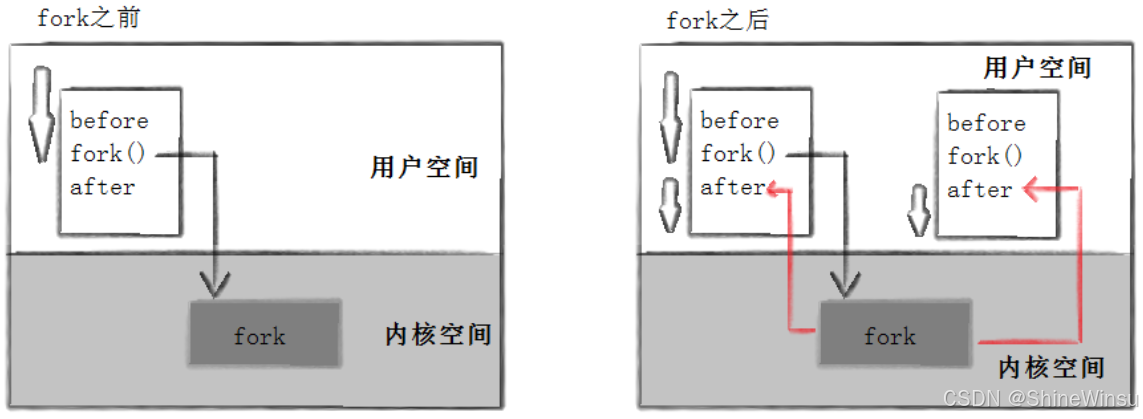
(2)为什么 fork 会有 “两个返回值”?
这是新手最懵的点,用 “复印身份证” 类比就懂了:你(父进程)拿着身份证去复印店,店员(内核)帮你复印了一张一模一样的身份证(子进程)。复印完成后:
- 你手里的原身份证上,多了一行备注:“复印件工号是 12345”(父进程得到子进程 PID);
- 复印件上,多了一行备注:“我是复印件”(子进程得到 0)。
本质:fork调用时,内核先做 “复制工作”(创建子进程、分配 PID、复制数据),然后父进程和子进程会 “各走各的路”—— 同时执行fork之后的代码。所以 “两个返回值” 不是 “一个函数返回两次”,而是 “两个进程各自执行了一次返回操作”。
2. 代码实例:亲眼看看 fork 的 “复制效果”
我们写一个带 “超详细注释” 的代码,跑起来就能直观看到父子进程的区别:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <stdlib.h>
int main() {
// 1. 定义变量:存储fork的返回值(子进程PID或0)
pid_t child_pid;
// 定义一个普通变量,测试“数据是否共享”
int shared_num = 10;
// 2. fork调用前:只有“老工人(父进程)”在干活
printf("===== fork调用前 =====\n");
printf("父进程:我的工号(PID)是%d,shared_num=%d\n", getpid(), shared_num);
// getpid():获取当前进程的PID(工号),每个进程调用都能拿到自己的工号
// 3. 关键一步:调用fork,“招新工人(子进程)”
child_pid = fork();
// 4. 检查fork是否成功(招工失败的情况)
if (child_pid == -1) {
// perror:打印错误原因(比如“资源不足”“进程数超限”)
perror("fork创建子进程失败!原因是");
exit(1); // 退出程序,1表示“出错退出”
}
// 5. fork调用后:父进程和子进程“同时干活”,走不同的分支
if (child_pid == 0) {
// ===== 这是子进程(新工人)的代码 =====
printf("\n===== 子进程开始干活 =====\n");
// 子进程的PID:用getpid()获取,父进程PID:用getppid()获取(parent PID)
printf("子进程:我的工号(PID)是%d,我爹(父进程PID)是%d\n", getpid(), getppid());
// 测试:修改shared_num,看父进程的变量会不会变
shared_num = 20;
printf("子进程:我把shared_num改成了%d(这是我的独立数据)\n", shared_num);
sleep(3); // 让子进程“干3秒活”,避免提前退出
printf("子进程:我干完活了,准备退出\n");
} else {
// ===== 这是父进程(老工人)的代码 =====
printf("\n===== 父进程继续干活 =====\n");
printf("父进程:我的工号(PID)是%d,我招的新工人(子进程PID)是%d\n", getpid(), child_pid);
// 父进程不修改shared_num,看子进程改了之后自己的会不会变
printf("父进程:我的shared_num还是%d(没被子进程影响)\n", shared_num);
sleep(5); // 让父进程“多干2秒”,等子进程先退出
printf("父进程:我也干完活了,准备退出\n");
}
return 0;
}
(1)怎么运行代码?
- 把代码保存为
fork_test.c; - 用 gcc 编译:
gcc fork_test.c -o fork_test; - 运行程序:
./fork_test。
(2)运行结果(PID 是系统分配的,每次可能不同)
===== fork调用前 =====
父进程:我的工号(PID)是1234,shared_num=10
===== 父进程继续干活 =====
父进程:我的工号(PID)是1234,我招的新工人(子进程PID)是1235
父进程:我的shared_num还是10(没被子进程影响)
===== 子进程开始干活 =====
子进程:我的工号(PID)是1235,我爹(父进程PID)是1234
子进程:我把shared_num改成了20(这是我的独立数据)
子进程:我干完活了,准备退出
父进程:我也干完活了,准备退出
(3)从结果里能看出的 3 个关键结论
① fork 前只有父进程干活:fork调用前的打印只出现一次,说明子进程不会重复执行 fork 之前的代码;② 父子进程数据独立:子进程把shared_num改成 20,父进程的还是 10,这就是 “写时拷贝” 的效果;③ 父子进程各有 PID:子进程的 PID 是 1235,父进程的是 1234,子进程能通过getppid()找到父进程的 PID。
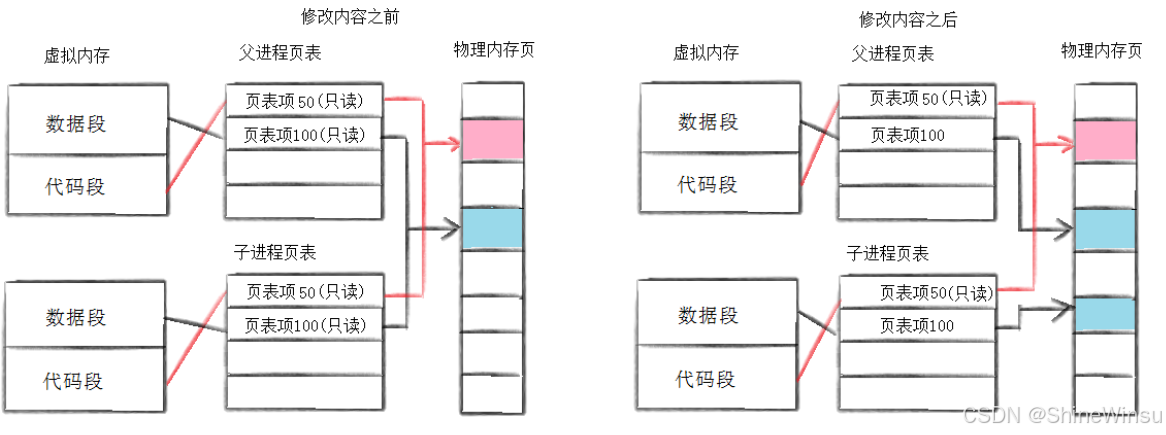
3. 写时拷贝:“为什么复制进程不浪费内存?”
刚用 fork 创建子进程时,父子进程的 “代码” 和 “数据” 并不是真的 “复制了两份”—— 而是 “共用一份”,就像两个工人共用一本 “操作手册(代码)” 和 “原材料(数据)”。只有当其中一个工人 “修改原材料” 时,工厂才会 “偷偷复制一份新的原材料” 给修改的工人,另一个工人的原材料不变。这种机制叫 “写时拷贝(Copy-On-Write,COW)”。
(1)用生活例子再讲透
你和同桌共用一本数学书(代码 + 未修改的数据):
- 平时一起看(读数据),不用各自买一本(节省内存);
- 某天你想在书上画重点(修改数据),老师会给你一本新的书(拷贝),同桌的书还是原来的(数据独立)。
(2)代码验证写时拷贝
我们在之前的代码基础上,增加 “父子进程修改同一变量” 的对比:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <stdlib.h>
int main() {
pid_t child_pid;
int num = 100; // 父子共用的变量
child_pid = fork();
if (child_pid == -1) {
perror("fork失败");
exit(1);
}
if (child_pid == 0) {
// 子进程修改变量
num = 200;
printf("子进程:修改后num=%d,我的变量地址是%p\n", num, &num);
sleep(2);
} else {
// 父进程先等1秒,让子进程先修改
sleep(1);
printf("父进程:num还是%d,我的变量地址是%p\n", num, &num);
sleep(2);
}
return 0;
}
运行结果
子进程:修改后num=200,我的变量地址是0x7ffd8b7c3aec
父进程:num还是100,我的变量地址是0x7ffd8b7c3aec
- 神奇的是:父子进程的
num地址看起来一样!但值不一样 —— 这是因为 “虚拟地址” 的作用,虽然地址显示相同,但实际对应物理内存的不同位置(子进程修改时触发了写时拷贝,分配了新的物理内存); - 结论:写时拷贝既节省了内存(不修改时共用),又保证了进程独立(修改时分开)。
4. fork 的 2 个常见用法(附代码)
(1)用法 1:父子进程 “分工干活”
就像工头(父进程)负责 “接订单”,新工人(子进程)负责 “处理订单”:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <stdlib.h>
// 子进程的任务:处理订单
void handle_order() {
printf("子进程(PID=%d):开始处理客户订单...\n", getpid());
sleep(3); // 模拟处理时间
printf("子进程:订单处理完成!\n");
}
// 父进程的任务:接收新订单
void accept_order() {
printf("父进程(PID=%d):等待新客户订单...\n", getpid());
sleep(5); // 模拟等待时间
printf("父进程:收到新订单啦!\n");
}
int main() {
pid_t child_pid = fork();
if (child_pid == -1) {
perror("fork失败");
exit(1);
}
if (child_pid == 0) {
handle_order(); // 子进程处理订单
} else {
accept_order(); // 父进程接收订单
}
return 0;
}
运行结果
子进程(PID=1236):开始处理客户订单...
父进程(PID=1234):等待新客户订单...
子进程:订单处理完成!
父进程:收到新订单啦!
(2)用法 2:子进程 “换活干”(执行新程序)
有时候新工人(子进程)不想干父进程的活,想换个新活(执行新程序,比如ls命令),这时候需要用exec系列函数 —— 它会 “扔掉子进程原来的代码”,加载新程序的代码。
最常用的是execlp函数,原型:
#include <unistd.h>
int execlp(const char *file, const char *arg, ..., (char *)NULL);
// file:要执行的程序名(比如"ls")
// arg:程序的参数(第一个参数必须是程序名,最后用NULL结尾)
代码示例:子进程执行ls -l命令(查看当前目录文件详情)
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <stdlib.h>
int main() {
pid_t child_pid = fork();
if (child_pid == -1) {
perror("fork失败");
exit(1);
}
if (child_pid == 0) {
printf("子进程(PID=%d):准备执行ls -l命令...\n", getpid());
// 执行ls -l:第一个参数是程序名"ls",第二个是参数"-l",最后用NULL结尾
execlp("ls", "ls", "-l", NULL);
// 注意:execlp如果执行成功,下面的代码不会执行(子进程代码被替换了)
printf("子进程:这条打印不会出现!\n");
} else {
sleep(2); // 父进程等2秒,让子进程先执行ls命令
printf("父进程(PID=%d):子进程干完活了!\n", getpid());
}
return 0;
}
运行结果
子进程(PID=1237):准备执行ls -l命令...
总用量 16
-rwxr-xr-x 1 root root 8368 10月 1 15:30 fork_exec
-rw-r--r-- 1 root root 689 10月 1 15:29 fork_exec.c
父进程(PID=1234):子进程干完活了!
- 可以看到:子进程执行了
ls -l命令,打印出了当前目录的文件列表; - 子进程中
execlp后面的printf没有执行 —— 因为execlp成功后,子进程的代码已经被ls的代码替换了。 - 这个我们后面会再说,这里大家仅作了解
5. fork 失败的 2 个常见原因
- 原因 1:系统进程数太多(超过内核限制)。比如 Linux 默认单个用户最多创建
1024个进程,超过后 fork 就会失败; - 原因 2:内存不足。创建进程需要分配内存(存储代码、数据),内存不够时 fork 会失败。
怎么查看进程数限制:用ulimit -u命令,比如输出1024表示当前用户最多创建 1024 个进程。
OK大家,这个其实我们之前已经有详细讲过了,这里大家就当做是复习了
三、进程终止:“工人干完活下班”
进程终止就是 “工人完成任务后离开工厂”,本质是 “释放工厂分配的资源”(比如内存、PID、CPU 时间)。终止分两种情况:“正常下班”(任务完成)和 “意外离岗”(干活出错被开除)。
1. 先搞懂:进程退出的 3 种场景
用工人的例子对应:
- 场景 1:正常下班(结果正确):工人按要求完成订单,没有出错;
- 场景 2:正常下班(结果错误):工人完成了订单,但算错了金额(代码跑完了但结果不对);
- 场景 3:意外离岗:工人干活时摔碎了机器(代码出错,比如除 0),或被厂长(用户)开除(按
ctrl+c)。
2. 正常终止:“工人按流程下班”
有 3 种 “下班流程”,核心区别是 “下班前要不要收拾工具(清理资源)”。
(1)方式 1:从 main 函数 return(最简单)
main函数是进程的 “入口”,也是 “出口”——return n就相当于 “工人干完活,交差后下班”,n是 “交差结果”(退出码)。
规则:
return 0:“任务完成,结果正确”(正常下班);return 非0(比如return 1):“任务完成,结果错误”(比如计算错了)。
代码示例:
#include <stdio.h>
int main() {
printf("工人(进程PID=%d):开始算1+1...\n", getpid());
int result = 1 + 1;
if (result == 2) {
printf("工人:算对了!准备下班\n");
return 0; // 结果正确,正常退出
} else {
printf("工人:算错了!准备下班\n");
return 1; // 结果错误,正常退出
}
}
怎么查看退出码:运行程序后,用echo $?命令查看 “交差结果”。比如:
$ ./return_test # 运行程序
工人(进程PID=1238):开始算1+1...
工人:算对了!准备下班
$ echo $? # 查看退出码
0 # 表示结果正确
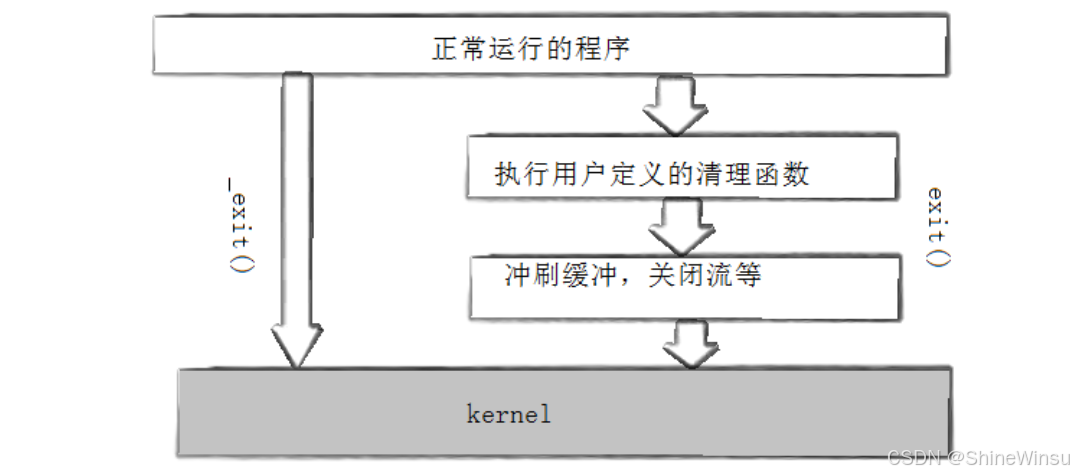
(2)方式 2:exit 函数(“下班前收拾工具”)
exit函数是 “标准下班流程”—— 工人下班前会 “收拾工具、关闭文件”(清理资源),然后再离开,那么它和main函数的return一样,都是直接让本程序(进程)结束,即使是把它放在非main函数里面,这么说,我们之前在非main函数里面写return的话,那么只是代表说那个函数结束了,并不代表我们的本进程结束,必须要到了main函数的return,才算是本进程结束。
而要是我们用上exit函数的话,那么不好意思,哪怕你是在非main函数里面调用,也会直接结束本进程,就是这么不讲道理,又是一个霸道总裁。
函数原型与头文件:
#include <stdlib.h> // exit函数的头文件
void exit(int status); // status:退出码(和return的n一样)
exit 的 3 步清理流程:
- 执行 “提前注册的清理函数”(比如工人提前说 “下班前要关电脑”,exit 会自动执行这个操作);
- 刷新 “输出缓冲区”(比如工人写的 “工作报告” 在草稿本上,exit 会把草稿本内容抄到正式报告上);
- 调用
_exit函数,真正 “离开工厂”(释放资源)。
重点 1:注册清理函数(atexit)可以用atexit函数 “提前告诉 exit 要做的清理工作”,比如关闭文件、释放内存。atexit可以注册多个函数,exit 会 “倒序执行”(先注册的后执行)。
代码示例:注册 2 个清理函数
#include <stdio.h>
#include <stdlib.h> // exit和atexit的头文件
// 清理函数1:关电脑
void close_computer() {
printf("清理1:关闭电脑\n");
}
// 清理函数2:锁门
void lock_door() {
printf("清理2:锁上车间大门\n");
}
int main() {
// 注册清理函数:先注册close_computer,再注册lock_door
atexit(close_computer);
atexit(lock_door);
printf("工人:开始干活...\n");
sleep(2); // 模拟干活
printf("工人:活干完了,准备下班(执行exit)\n");
exit(0); // 执行exit,触发清理函数
// exit后代码不会执行
printf("这条打印不会出现!\n");
return 0;
}
运行结果:
工人:开始干活...
工人:活干完了,准备下班(执行exit)
清理2:锁上车间大门
清理1:关闭电脑
- 注意:清理函数的执行顺序是 “倒序”—— 先注册的
close_computer后执行,后注册的lock_door先执行。
重点 2:刷新缓冲区的效果我们之前学过printf函数 —— 它的输出不会 “立即显示到屏幕”,而是先存在 “缓冲区”(草稿本)里。exit会刷新缓冲区,把内容显示出来;而后面要讲的_exit不会。
代码对比:exit vs 不刷新缓冲区
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
// printf没有加换行符\n,内容会存在缓冲区
printf("工人:这是我的工作报告");
// 用exit退出:会刷新缓冲区,内容会显示
printf("\n用exit退出:\n");
exit(0);
}
运行结果:
工人:这是我的工作报告
用exit退出:
如果把exit(0)换成_exit(0),结果会变成:
用_exit退出:
—— 因为_exit不刷新缓冲区,“工作报告” 没显示就退出了。
(3)方式 3:_exit 函数(“紧急下班,啥也不收拾”)
_exit是 “紧急下班流程”—— 工人遇到紧急情况(比如工厂着火),直接跑出去,不收拾工具、不写报告(不清理资源)。
函数原型与头文件:
#include <unistd.h> // _exit的头文件
void _exit(int status); // status:退出码
核心区别:_exit不执行清理函数、不刷新缓冲区,直接释放资源退出。
代码对比:exit vs _exit
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
// 清理函数
void clean() {
printf("清理:收拾工具\n");
}
int main() {
atexit(clean); // 注册清理函数
printf("工人:工作报告(没换行)"); // 内容在缓冲区
// 测试1:用exit退出
// printf("\n=== 用exit退出 ===\n");
// exit(0); // 会刷新缓冲区、执行清理函数
// 测试2:用_exit退出
printf("\n=== 用_exit退出 ===\n");
_exit(0); // 不刷新缓冲区、不执行清理函数
return 0;
}
测试 1(exit)运行结果:
工人:工作报告(没换行)
=== 用exit退出 ===
清理:收拾工具
测试 2(_exit)运行结果:
=== 用_exit退出 ===
—— 明显看到:_exit没显示 “工作报告”(没刷新缓冲区),也没执行 “收拾工具”(没执行清理函数)。
(4)3 种正常终止方式的总结
| 方式 | 特点 | 适用场景 |
|---|---|---|
| main 函数 return | 最简单,等价于 exit (返回值) | 普通程序的正常退出 |
| exit 函数 | 执行清理函数、刷新缓冲区,安全退出 | 需要清理资源的场景(如关文件) |
| _exit 函数 | 不清理、不刷新,快速退出 | 紧急场景(如信号处理) |
下面是实验这些函数的详细代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <unistd.h>
#include <fcntl.h>
//int func()
//{
// printf("i am func ,i begin\n");
// return 1;//我们需要知道,在其他函数中的返回其实是只针对这个函数的返回,并不代表说我们这个程序(进程)结束
// printf("i over");
//}
//int main()
//{
// printf("i am main ,i begin\n");
// int ret=func();
// printf("this is func return%d\n",ret);
// return 0;//只有main函数里的return结束了,才代表本程序(进程)结束
//}
int func()
{
// printf("i am func ,i begin\n");
// return 1;//我们需要知道,在其他函数中的返回其实是只针对这个函数的返回,并不代表说我们这个程序(进程)结束
// printf("i over");
//但是exit函数不同,一旦调用了它,那么就是相当于直接本进程退出,即使是用到函数里面
exit(1);//里面的参数其实也是返回码,我们也可以使用errno
//exit(errno);
//除了exit函数之外,还有_exit函数,这个是系统函数,它的功能和exit差不多,但是它不会刷新缓冲区,而exit函数会,
//其实exit库函数里面就是调用了_exit这个系统函数
}3. 退出码:“工人的交差结果”
退出码是进程终止时给 “工厂(操作系统)” 或 “父进程” 的 “交差结果”,用status参数传递,规则很简单:
0:“任务完成,结果正确”(优秀工人);- 非 0(1~255):“任务完成但结果错误” 或 “出错退出”(比如 1 表示 “计算错误”,2 表示 “文件找不到”)。
(1)常见退出码含义
| 退出码 | 含义 | 例子 |
|---|---|---|
| 0 | 成功 | 1+1 算对了 |
| 1 | 通用错误 | 除 0 错误、权限不足 |
| 2 | 命令错误 | 执行了不存在的命令(如lss) |
| 130 | 被ctrl+c杀死(SIGINT 信号) |
按ctrl+c终止程序 |
| 143 | 被kill命令杀死(SIGTERM 信号) |
kill 1234终止进程 |
(2)用 strerror 函数查看退出码描述
strerror函数能把 “退出码” 翻译成 “人类能看懂的描述”,需要包含string.h头文件。
代码示例:
#include <stdio.h>
#include <string.h> // strerror的头文件
int main() {
// 查看常见退出码的描述
int codes[] = {0, 1, 2, 130};
int n = sizeof(codes) / sizeof(codes[0]);
for (int i = 0; i < n; i++) {
printf("退出码%d:%s\n", codes[i], strerror(codes[i]));
}
return 0;
}
运行结果:
退出码0:Success
退出码1:Operation not permitted
退出码2:No such file or directory
退出码130:Interrupted system call
大家,对于这一块,我们并不陌生,在很久之前的C语言学习之路中,我们也学过,更是知道perror这个更好使的函数。
那么如果大家想看所有的退出码对应的错误的话,大家可以使用for循环:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <unistd.h>
int main()
{
//在main函数中,其实不同的返回值,有不同的含义,0代表正常退出,叫做返回码
//而非0则每个数字有其各自的意思,系统为了方便用户理解
//将每个数字代表的意思转换为字符串,但是需要我们去使用strerror,因为是存储在这里面
//for(int i=0;i<200;++i)
//{
// printf("每个数字代表的意思:%d->%s\n",i,strerror(i));//要注意strerror是个函数,里面传入不同的整型,就会输出不同的对应字符串
//}
//那么errno的作用就是获取到程序运行错误的返回值(比如2,3,4什么的),然后我们可以用strerror函数获取
// FILE* f=fopen("text.txt","r");//我们打开一个本目录下没有的文件,肯定是会错的,但是我们不知道哪里错了,所以可以使用errno获取
//if(f==NULL)
//{
// printf("打开失败,原因是%s\n",strerror(errno));
// //也可以直接使用perror,这个直接可以达到上面的目的
//}
//fclose(f);
//当然,我们也可以自己设置指定返回值,不用系统所提供的,但是没什么意义
FILE* f=fopen("text.txt","r");//我们打开一个本目录下没有的文件,肯定是会错的,但是我们不知道哪里错了,所以可以使用errno获取
if(f==NULL)
{
return 25;//但是需要注意的是,如果是异常情况的话,那么系统就不理会我们设置的了,直接使用准确的
}
fclose(f);
return 0;
}4. 异常终止:“工人意外离岗”
异常终止是 “进程没干完活就被迫退出”,常见原因有 2 种:
(1)原因 1:代码出错(工人干活出错)
比如:
- 除 0 错误(
int a = 1 / 0;); - 访问不存在的内存(比如空指针
int *p = NULL; *p = 10;); - 数组越界(
int arr[3]; arr[10] = 5;)。
这些错误会触发 “系统信号”,进程收到信号后会立即退出。
代码示例:除 0 错误触发异常终止
#include <stdio.h>
int main() {
printf("工人:开始算1/0...\n");
int a = 1 / 0; // 除0错误,触发异常终止
printf("这条打印不会出现!\n");
return 0;
}
运行结果:
工人:开始算1/0...
Floating point exception (core dumped)
——“Floating point exception” 就是 “浮点异常”(除 0 错误),进程被信号杀死,异常退出。
(2)原因 2:被信号杀死(工人被开除)
用户或操作系统会给进程发 “信号”,强制进程退出。常见信号:
SIGINT(编号 2):按ctrl+c触发,“温和开除”,进程可以选择处理(比如清理资源);SIGKILL(编号 9):用kill -9 PID触发,“强制开除”,进程无法抵抗,必须退出;SIGSEGV(编号 11):代码出错(如访问非法内存)触发,“因出错开除”。
怎么给进程发信号:
- 按
ctrl+c:给当前终端的前台进程发SIGINT信号; - 用
kill命令:kill -信号编号 进程PID,比如kill -9 1234(强制杀死 PID=1234 的进程)。
代码示例:测试 SIGINT 信号
#include <stdio.h>
#include <unistd.h>
int main() {
printf("进程(PID=%d):我在运行,按ctrl+c试试...\n", getpid());
while (1) {
sleep(1); // 无限循环,一直运行
printf("我还在运行...\n");
}
return 0;
}
操作步骤:
- 运行程序,看到 “我在运行,按 ctrl+c 试试...”;
- 按
ctrl+c,程序会退出,输出:^C(表示收到 SIGINT 信号)。
如果用 kill -9 杀死:
- 运行程序,记住 PID(比如 1239);
- 另开一个终端,执行
kill -9 1239; - 原终端的程序会立即退出,没有额外输出(强制杀死)。
5. 怎么查看进程状态(是否正常退出)
用ps aux命令查看进程状态,常见状态:
R(Running):正在运行;S(Sleeping):睡眠中(等待事件,如 sleep);Z(Zombie):僵尸进程(已退出但资源没被回收);T(Stopped):暂停状态(如按ctrl+z)。
比如查看僵尸进程:ps aux | grep Z,会显示所有僵尸进程的 PID 和父进程 PID,这个我们之前讲进程状态的时候也是说过了,相信大家并不陌生。
四、进程等待:“工头等新工人下班”
如果新工人(子进程)下班了,工头(父进程)不管不问,新工人的 “工牌(PID)” 和 “工具间(内存)” 就会留在工厂里 —— 这就是 “僵尸进程”。僵尸进程占着资源不放,多了会导致工厂(系统)变慢,甚至无法招新工人(创建新进程)。
进程等待就是 “工头主动等新工人下班”,做两件事:
- 回收新工人的资源(工牌、工具间),避免僵尸进程;
- 问新工人:“活干得怎么样?”(获取退出状态:正常退出码或被杀死的信号)。
1. 为什么必须进程等待?(3 个核心原因)
- 原因 1:避免僵尸进程。子进程退出后,父进程不等待,子进程会变成僵尸进程,资源无法回收;
- 原因 2:获取任务结果。父进程需要知道子进程的活干得怎么样(是算对了,还是算错了,还是被开除了);
- 原因 3:僵尸进程无法杀死。一旦变成僵尸进程,就算用
kill -9也杀不死(因为已经 “死了”),只能通过父进程等待来回收。
2. 等待函数:wait 和 waitpid(工头的 “等待工具”)
Linux 提供两个等待函数:wait(简单等待)和waitpid(灵活等待),核心是waitpid——wait是waitpid的简化版。
(1)先学 wait 函数(“等任意一个新工人下班”)
wait函数的作用:“工头等任意一个新工人下班,回收资源并获取退出状态”。
函数原型与头文件:
#include <sys/wait.h> // wait和waitpid的头文件
#include <sys/types.h>
pid_t wait(int *status);
// 参数status:输出型参数,存储子进程的退出状态(不关心可以传NULL)
// 返回值:成功——返回下班的子进程PID;失败——返回-1(比如没有子进程)
核心特性:阻塞等待—— 工头(父进程)会暂停干活,直到有一个新工人(子进程)下班,才继续干活。
代码示例:wait 等待子进程退出
#include <stdio.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main() {
pid_t child_pid = fork();
if (child_pid == -1) {
perror("fork失败");
exit(1);
}
if (child_pid == 0) {
// 子进程:干活3秒后正常退出,退出码10
printf("子进程(PID=%d):开始干活,3秒后下班\n", getpid());
sleep(3);
printf("子进程:活干完了,退出码10\n");
exit(10);
} else {
// 父进程:用wait等待子进程下班
int status; // 存储子进程退出状态
printf("父进程(PID=%d):开始等子进程(PID=%d)下班...\n", getpid(), child_pid);
// 阻塞等待:父进程会暂停3秒,直到子进程退出
pid_t wait_pid = wait(&status);
// 等待成功后,处理退出状态
if (wait_pid == child_pid) {
printf("父进程:子进程(PID=%d)下班了!\n", wait_pid);
// 判断子进程是否正常退出(用WIFEXITED宏)
if (WIFEXITED(status)) {
// 正常退出:用WEXITSTATUS宏获取退出码
printf("父进程:子进程正常退出,退出码=%d\n", WEXITSTATUS(status));
} else {
// 异常退出:用WTERMSIG宏获取杀死子进程的信号
printf("父进程:子进程被信号%d杀死\n", WTERMSIG(status));
}
} else {
perror("wait失败");
exit(1);
}
}
return 0;
}
运行结果:
父进程(PID=1240):开始等子进程(PID=1241)下班...
子进程(PID=1241):开始干活,3秒后下班
子进程:活干完了,退出码10
父进程:子进程(PID=1241)下班了!
父进程:子进程正常退出,退出码=10
关键:解析 status 的 4 个宏status是 “输出型参数”,里面存的不是简单的整数,而是 “位图”(可以理解成 “多个开关”),需要用专门的宏来 “读取开关状态”:
| 宏 | 作用 | 返回值含义 |
|---|---|---|
| WIFEXITED(status) | 判断子进程是否正常退出 | 1 = 正常退出;0 = 异常退出 |
| WEXITSTATUS(status) | 若正常退出,获取退出码 | 0~255(子进程的 exit/return 值) |
| WIFSIGNALED(status) | 判断子进程是否被信号杀死 | 1 = 被信号杀死;0 = 不是 |
| WTERMSIG(status) | 若被信号杀死,获取信号编号 | 2=SIGINT;9=SIGKILL 等 |
waitpid 函数的第二个参数是一个输出型参数,其作用是让函数将子进程的退出状态信息 “写回” 到我们指定的变量中。具体来说,我们需要先在函数外部定义一个整型变量(比如 int status;),然后将这个变量的地址(&status)作为参数传入 waitpid 的第二个位置。当 waitpid 函数执行时,它会根据子进程的退出情况,自动修改这个变量的值,以此传递子进程的退出状态。
不过,这个被修改后的整型变量的值并非简单的 “退出码”,而是一个包含多层信息的 “复合值”,其内部结构有明确的划分:整个整型变量共 32 个比特位,其中前 16 位(高 16 位)是被系统忽略的,不存储任何有效信息;真正有用的是后 16 位(低 16 位),这 16 位又被进一步拆分为两个 8 位区域:
- 后 16 位中的前 8 位(即整个变量的第 17-24 位):存储的是子进程的 “正常退出码”。当子进程通过 exit、return 等方式正常终止时,这里会记录具体的退出码(比如 exit (10) 中的 10)。
- 后 16 位中的后 8 位(即整个变量的第 25-32 位):存储的是 “信号信息”。当子进程因异常被信号杀死(比如被 kill -9 强制终止)时,这里会记录导致其终止的信号编号(比如信号 9 对应 SIGKILL)。
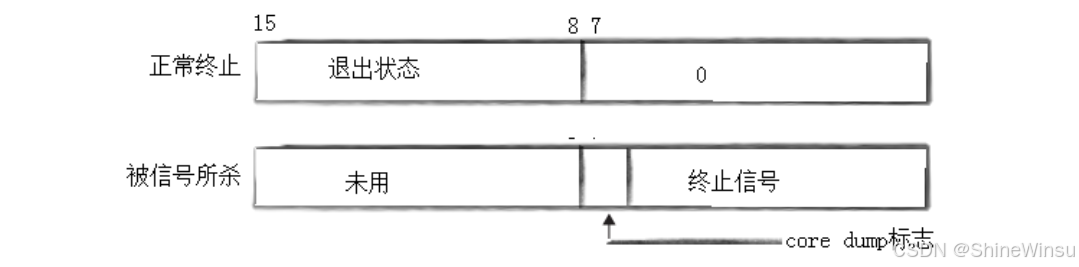
正因为这个变量的结构是 “复合” 的,若直接输出这个整型变量(比如 printf ("% d", status);),得到的会是一个混合了退出码和信号信息的数值,显然不是我们预期的 “纯退出码” 或 “纯信号编号”。
为了正确提取其中的信息,系统提供了专门的宏来解析这个变量:
- 用 WIFEXITED (status) 判断子进程是否正常退出(若为真,说明前 8 位的退出码有效);
- 用 WEXITSTATUS (status) 从正常退出的子进程中提取具体退出码(本质是取后 16 位中前 8 位的值);
- 用 WIFSIGNALED (status) 判断子进程是否被信号杀死(若为真,说明后 8 位的信号信息有效);
- 用 WTERMSIG (status) 提取导致子进程异常终止的信号编号(本质是取后 16 位中后 8 位的值)。
通过这些宏,我们才能准确解析出子进程的退出状态,而不是直接使用这个复合的整型变量值。
测试异常退出:把子进程的exit(10)改成while(1)sleep(1),然后在父进程等待时,用kill -9 子进程PID杀死子进程,运行结果会变成:
父进程(PID=1242):开始等子进程(PID=1243)下班...
子进程(PID=1243):开始干活,3秒后下班
(另开终端执行kill -9 1243)
父进程:子进程(PID=1243)下班了!
父进程:子进程被信号9杀死
(2)重点学 waitpid 函数(“灵活等待,想等谁就等谁”)
wait只能 “等任意一个子进程”,而waitpid可以 “指定等某个子进程”,还能 “边等边干活(非阻塞等待)”,更灵活。
函数原型:
pid_t waitpid(pid_t pid, int *status, int options);
返回值解析:
waitpid函数的返回值需分场景理解,以下是详细说明:
1. 成功收集到子进程退出状态
- 返回值:被等待的子进程 PID。
- 场景:子进程已正常退出或被信号杀死,
waitpid成功回收其资源并获取退出状态。
2. 设置WNOHANG选项且子进程未退出
- 返回值:
0。 - 场景:当
options参数设置为WNOHANG(非阻塞等待)时,若子进程仍在运行、未退出,waitpid会立即返回0,表示 “没有可收集的子进程”。
3. 调用出错
- 返回值:
-1。 - 场景:
- 无符合条件的子进程(如指定
pid>0但该 PID 的子进程不存在); - 调用被信号中断等。
- 无符合条件的子进程(如指定
- 辅助判断:出错时可通过
errno变量(需包含<errno.h>)查看具体错误原因,例如errno=ECHILD表示 “没有子进程可等待”。
总结
| 场景 | 返回值 | 说明 |
|---|---|---|
| 成功收集子进程退出状态 | 子进程 PID | 正常回收资源 |
| WNOHANG 且子进程未退出 | 0 | 非阻塞等待时的 “无结果” |
| 调用出错 | -1 | 需结合errno分析原因 |
3 个参数的详细解析:
参数 1:pid(指定要等的子进程)
| pid 值 | 含义 | 例子 |
|---|---|---|
| -1 | 等任意一个子进程(和 wait 一样) | waitpid(-1, &status, 0) = wait(&status) |
| >0 | 只等 “PID 等于这个值” 的子进程 | waitpid (1241, &status, 0):只等 PID=1241 的子进程 |
| 0 | 等 “和父进程在同一个进程组” 的子进程 | (初学者暂时用不到,不超纲) |
| < -1 | 等 “进程组 ID 等于 pid 绝对值” 的子进程 | (初学者暂时用不到,不超纲) |
参数 2:status(存储退出状态)
和wait的status完全一样,用 4 个宏解析(WIFEXITED、WEXITSTATUS 等)。
参数 3:options(等待方式)
控制父进程是否 “暂停干活”,有两个常用值:
| options 值 | 含义 | 特点 |
|---|---|---|
| 0 | 阻塞等待(默认) | 父进程暂停,直到子进程退出 |
| WNOHANG | 非阻塞等待 | 父进程不暂停,立即返回 |
返回值规则(重点!):
| 情况 | 返回值 |
|---|---|
| 成功等到子进程退出 | 返回子进程的 PID |
| 非阻塞等待(WNOHANG)且子进程还在运行 | 返回 0 |
| 出错(比如没有子进程) | 返回 - 1,同时设置 errno |
3. 阻塞等待 vs 非阻塞等待(工头的两种等待方式)
(1)阻塞等待(“站在门口等,啥也不干”)
就是options=0的情况:父进程暂停所有工作,直到子进程退出。
- 优点:简单,不用自己循环检查;
- 缺点:父进程在等待期间 “啥也干不了”,浪费时间。
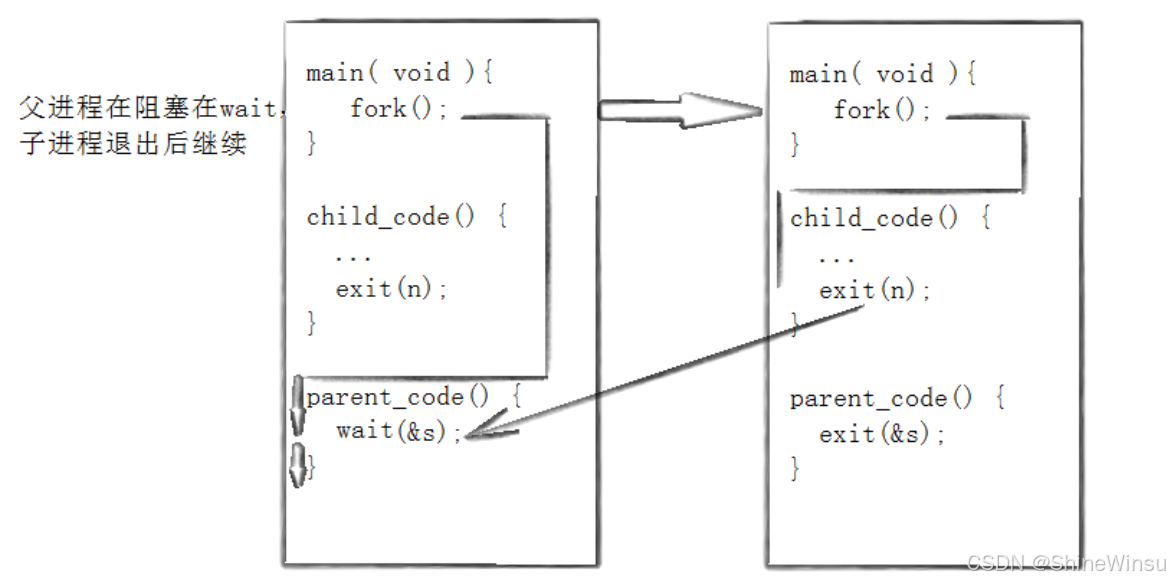
代码示例:和前面的wait示例类似,把wait换成waitpid(child_pid, &status, 0)即可:
// 阻塞等待PID=child_pid的子进程
pid_t wait_pid = waitpid(child_pid, &status, 0);
(2)非阻塞等待(“时不时去门口看看,期间干别的活”)
就是options=WNOHANG的情况:父进程调用waitpid后 “立即返回”—— 如果子进程没退出,就先干别的活,过一会儿再检查;如果子进程已退出,就回收资源。
- 优点:父进程不浪费时间,能同时处理多个任务;
- 缺点:需要自己写循环,不断检查子进程是否退出。
代码示例:非阻塞等待,期间处理其他任务
#include <stdio.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
// 父进程在等待期间干的活:整理订单
void organize_orders() {
static int count = 0; // 静态变量,记录整理次数
count++;
printf("父进程:等待期间整理第%d份订单...\n", count);
sleep(1); // 模拟整理时间
}
int main() {
pid_t child_pid = fork();
if (child_pid == -1) {
perror("fork失败");
exit(1);
}
if (child_pid == 0) {
// 子进程:干活5秒后退出
printf("子进程(PID=%d):开始干活,5秒后下班\n", getpid());
sleep(5);
printf("子进程:活干完了,退出码20\n");
exit(20);
} else {
int status;
pid_t wait_pid;
printf("父进程(PID=%d):开始等子进程(PID=%d),期间整理订单...\n", getpid(), child_pid);
// 非阻塞等待:循环检查子进程是否退出
do {
// WNOHANG:非阻塞,立即返回
wait_pid = waitpid(child_pid, &status, WNOHANG);
if (wait_pid == 0) {
// 返回0:子进程还在运行,父进程先干别的活
organize_orders();
} else if (wait_pid == child_pid) {
// 返回子进程PID:子进程已退出,处理退出状态
printf("\n父进程:子进程(PID=%d)下班了!\n", wait_pid);
if (WIFEXITED(status)) {
printf("父进程:子进程正常退出,退出码=%d\n", WEXITSTATUS(status));
} else {
printf("父进程:子进程被信号%d杀死\n", WTERMSIG(status));
}
} else {
// 返回-1:出错
perror("waitpid失败");
exit(1);
}
} while (wait_pid == 0); // 子进程没退出就继续循环
}
return 0;
}
运行结果:
父进程(PID=1244):开始等子进程(PID=1245),期间整理订单...
子进程(PID=1245):开始干活,5秒后下班
父进程:等待期间整理第1份订单...
父进程:等待期间整理第2份订单...
父进程:等待期间整理第3份订单...
父进程:等待期间整理第4份订单...
父进程:等待期间整理第5份订单...
子进程:活干完了,退出码20
父进程:子进程(PID=1245)下班了!
父进程:子进程正常退出,退出码=20
- 可以看到:父进程在等待的 5 秒里,没闲着,而是整理了 5 份订单 —— 这就是非阻塞等待的优势。
3. 常见问题:子进程变成 “孤儿进程” 怎么办?
如果 “工头(父进程)” 比 “新工人(子进程)” 先下班,子进程会变成 “孤儿进程”—— 没有父进程的 “孤儿”。
Linux 会让 “孤儿院院长(init 进程,PID=1)” 收养孤儿进程,当孤儿进程下班时,init 进程会自动等待回收资源,不会变成僵尸进程。
代码示例:父进程先退出,子进程变成孤儿进程
#include <stdio.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main() {
pid_t child_pid = fork();
if (child_pid == -1) {
perror("fork失败");
exit(1);
}
if (child_pid == 0) {
// 子进程:先睡1秒,让父进程先退出
sleep(1);
printf("子进程(PID=%d):我爹(父进程)呢?\n", getpid());
printf("子进程:我的新爹(收养我的进程)PID是%d\n", getppid());
sleep(3); // 子进程再活3秒
printf("子进程:我下班了,新爹会等我\n");
} else {
// 父进程:不等待子进程,直接退出
printf("父进程(PID=%d):我先下班了,不管子进程了\n", getpid());
exit(0);
}
return 0;
}
运行结果:
父进程(PID=1246):我先下班了,不管子进程了
子进程(PID=1247):我爹(父进程)呢?
子进程:我的新爹(收养我的进程)PID是1 // 1是init进程的PID
子进程:我下班了,新爹会等我
- 可以看到:子进程的父进程 PID 变成了 1(init 进程),init 进程会在子进程退出时自动等待,回收资源。
下面是实验wait、waitpid函数的详细代码:
//这个主要是来测试我们之前的僵尸进程如何使用wait函数和waitpid函数解决
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h> // 包含getpid()(获取自身PID)、getppid()(获取父进程PID)、sleep()函数
#include <sys/wait.h> // 包含wait()函数(这里故意不调用)
//int main() {
// pid_t id = fork(); // 创建子进程:父进程返回子进程PID,子进程返回0,失败返回-1
// if (id > 0) { // 父进程执行逻辑(id是子进程的PID)
// printf("父进程PID: %d,父进程的父进程PID: %d\n", getpid(), getppid());
// printf("父进程睡30秒,期间不回收子进程\n");
// sleep(30); // 父进程睡眠30秒,这段时间内不会调用wait()
// // 注:如果在这里添加wait(NULL); 子进程退出后会被立即回收,不会产生僵尸
// wait(NULL);//wait函数要求的参数是int*类型,这个我们下面会再去使用,
// //但是这里我们就可以直接传入NULL,那么父进程就会去等待,解决僵尸进程
// //这里还需要知道的是,只要没等到,那么wait函数就会一直阻塞等待子进程,期间就不干任何其他事了,比较鸡肋
// //所以下面会用到waitpid函数,这个可以进行控制是阻塞调用还是非阻塞调用
// } else if (id == 0) { // 子进程执行逻辑
// printf("子进程PID: %d,子进程的父进程PID: %d\n", getpid(), getppid());
// printf("子进程睡5秒后退出\n");
// sleep(5); // 子进程睡眠5秒,模拟执行任务
// exit(0); // 子进程退出,等待父进程回收PCB
// } else { // fork创建子进程失败
// perror("fork创建子进程失败"); // 打印失败原因
// return 1; // 非0退出表示程序异常
// }
// return 0;
//}
int main() {
pid_t id = fork();
if (id > 0) {
printf("父进程PID:%d,父进程的父进程PID:%d\n", getpid(), getppid());
printf("父进程睡30秒,期间不回收子进程\n");
sleep(30);
//wait(NULL);
//我们可以直接使用waitpid函数,这个函数会比wait函数更高级
int waitret=waitpid(id,NULL,WNOHANG)//第一个参数要传入子进程的pid,这么一来它就会针对某个指定的子进程进行等待,
//而要是传入-1,就是和wait函数一样,针对所有进程进行等待
//第二个参数是和wait函数的参数一样的,要传入返回码的地址,而第三个参数就是控制使用什么阻塞的选项
//传入WNOHANG就是非阻塞调用的意思,此时会使用非阻塞轮询,
//即系统不会去一直就等待子进程,而是时不时就等待一下,期间可以干其他的事情,效率会变高
} else if (id == 0) {
printf("子进程PID:%d,子进程的父进程PID:%d\n", getpid(), getppid());
printf("子进程睡5秒后退出\n");
sleep(5);
exit(0);
} else {
perror("fork创建子进程失败");
return 1;
}
return 0;
}
int main() {
pid_t id = fork();
if (id > 0) {
printf("父进程PID:%d,父进程的父进程PID:%d\n", getpid(), getppid());
printf("父进程睡30秒,期间不回收子进程\n");
sleep(30);
//下面来详细讲一下waitpid函数的第二个参数的意义以及函数返回值
//函数返回值其实很简单,如果小于0,就是等待失败
//如果大于0,要分两个情况,一个是正常等待成功,另一个则是有异常
//而这个就需要返回码进行判断,那么我们怎么获取返回码呢?其实是依靠waitpid函数的第二个参数
//这一个参数其实是输出型参数,意思就是说,我们先在外面随便设置一个整型变量
//然后把这个整型变量的地址传入函数的第二个参数
//那么这个函数就会去把这个参数(也就是这个变量)修改为错误码
//但是这个错误码其实有讲究,系统把这个整型的前16位比特位忽略
//然后后16位拿来使用,前8位就是真正的前面说的错误码,而后8位则是信号,通俗一点就是是否异常
//所以我们要是直接输出这个整型,会发现他不是预期的真正的返回码,就是因为上面所说的
//那么如果我们想获取的话,系统也提供了两个宏去帮助我们获取
//一个是WIFEXITED,这个可以获得真正的错误码,还有一个是忘记了
int status=0;
int waitpidret=waitpid(id,&status,WNOHANF);
if(waitpidret>0)
{
if(WIFEXITED(status))//代表有真正的错误码
{
printf("wait success ret=%d",waitpidret);
}
else//有异常了
{
printf("have abnormal");
}
}
else
{
printf("wait failed ret=%d",waitpidret);
}
} else if (id == 0) {
printf("子进程PID:%d,子进程的父进程PID:%d\n", getpid(), getppid());
printf("子进程睡5秒后退出\n");
sleep(5);
exit(0);
} else {
perror("fork创建子进程失败");
return 1;
}
return 0;
}五、总结:进程管理的 “三板斧”
我们用 “工厂工人” 的类比,把 Linux 进程的核心操作拆成了 3 步:
| 操作 | 核心函数 | 作用(工人类比) | 关键知识点 |
|---|---|---|---|
| 进程创建 | fork | 招新工人,复制老工人的干活流程和工具 | 写时拷贝、父子进程 PID 区别、exec 函数 |
| 进程终止 | exit/_exit/return | 工人下班,释放工具和工牌 | 退出码、清理函数、信号杀死 |
| 进程等待 | wait/waitpid | 工头等新工人下班,回收资源并问结果 | 阻塞 / 非阻塞等待、status 宏解析、僵尸进程 |
这些是 Linux 进程管理的 “地基”,理解后再学 “进程间通信(管道、消息队列)”“信号处理”“线程” 等内容,就会轻松很多。建议大家把每个代码示例都跑一遍,亲手验证效果 —— 实践是理解的最好方式!
结语:每一次对 “进程” 的拆解,都是对系统世界的一次温柔叩响
敲完最后一个代码示例的回车时,窗外的天或许已经暗了,屏幕的光映在脸上,手里的咖啡可能早就凉了 —— 但我猜,你心里一定是热的。
当你第一次看到fork的 “两个返回值” 时,会不会像当年的我一样,对着屏幕皱起眉头:“一个函数怎么会返回两次?”;当你调试waitpid的status参数时,是不是也曾对着那串奇怪的整数发呆,疑惑 “为什么退出码不是我传的 10,而是一串乱七八糟的数字”;当你终于用WEXITSTATUS宏解析出正确的退出码时,嘴角是不是忍不住向上扬了扬?
这些困惑、试错、突然的顿悟,正是我们走进 “系统世界” 的脚印。
进程控制这部分内容,确实像开篇说的那样 —— 重要,也有难度。它不像学printf那样 “写完就看到结果”,也不像写一个简单的循环那样 “逻辑清晰、一步到位”。它需要我们跳出 “单线程思维”,学会用 “操作系统的视角” 看问题:当fork调用时,内核在背后做了多少事?从复制页表到分配 PID,从写时拷贝的内存优化到父子进程的独立运行,每一个细节都是几十年操作系统设计的智慧沉淀。
你看,我们用 “工厂工人” 的类比串起了整个故事:进程是 “工人”,PID 是 “工号”,fork是 “招工”,exit是 “下班”,waitpid是 “工头等新工人交差”。这个类比或许不完美,但它像一座桥,帮我们从 “看得见的代码” 走到了 “看不见的内核逻辑”。当你能笑着说出 “僵尸进程就是没被工头回收的工牌” 时,其实已经悄悄完成了一次认知跃迁 —— 你不再把进程当成冷冰冰的代码,而是开始理解它作为 “系统基本单位” 的生存逻辑。
还记得fork之后父子进程的shared_num吗?子进程改了值,父进程却没变,那一刻你是不是突然明白了 “写时拷贝” 不是课本上的名词,而是系统为了节省内存的 “小心机”?还有execlp函数,子进程执行ls -l时,原来的代码被 “扔掉”,就像新工人撕毁旧合同,拿起了新工具 —— 这种 “彻底的改变”,不正是进程灵活性的体现吗?
进程终止的三种方式里,藏着系统设计的 “温度”:return是 “到点下班” 的从容,exit是 “收拾好工具再走” 的负责,_exit是 “紧急情况先撤离” 的果断。而那几个清理函数的 “倒序执行”,像极了我们出门前 “先关窗、再锁门” 的习惯 —— 系统也在教我们 “有始有终”。
最让人头疼的waitpid,其实是 “责任” 的代名词。父进程不等待,子进程就成了 “僵尸”,占着资源不放手 —— 这多像现实里 “虎头蛇尾的工作”。而阻塞等待与非阻塞等待的选择,像极了 “守在门口等快递” 和 “时不时查一下物流、期间继续干活” 的区别,系统在用它的方式教我们 “效率与责任的平衡”。
这些知识点,单独看是零散的函数和宏,但串起来就是 “操作系统如何管理任务” 的底层逻辑。你现在掌握的,不只是fork和waitpid的用法,更是一种 “拆解复杂系统” 的能力 —— 这种能力,会帮你在未来面对更难的知识(比如进程间通信、线程同步、甚至分布式系统)时,保持从容。
或许你现在还会偶尔混淆WIFEXITED和WIFSIGNALED,或许你调试非阻塞等待时还会漏掉while循环的条件,或许你看到僵尸进程时还会慌一下 —— 但这都没关系。学习本来就是 “在错误里找规律,在困惑里建框架” 的过程。就像你第一次骑自行车时总摔,但摔着摔着,突然就找到了平衡的感觉。进程控制这部分内容,也会在你一次次编译、运行、修改代码的过程中,从 “陌生的概念” 变成 “顺手的工具”。
我特别想对你说:别小看自己此刻的积累。当你能写出一个 “父进程等待子进程、正确解析退出码” 的程序时,你已经站在了很多人的前面。因为大部分人停留在 “知道有这个函数”,而你做到了 “理解它为什么存在,掌握它怎么用”。这种 “知其然,更知其所以然” 的习惯,会成为你未来进阶的核心竞争力。
接下来的路还很长:进程间怎么通信?信号到底是怎么回事?线程和进程有什么区别?但请相信,你今天在进程控制上花的时间,已经为这些问题铺好了路。就像盖房子时打好的地基,它或许不显眼,但每一层楼的稳固都离不开它。
最后,想送给你一句我很喜欢的话:“计算机科学里的所有问题,都可以通过增加一个中间层来解决;但理解每一层的逻辑,才能真正掌握系统的本质。” 进程控制,就是操作系统这座大厦里非常关键的一层。
当你下次在终端里敲下ps aux,看到那些跳动的 PID 时,或许会想起今天学的 “工厂工人”—— 那个被fork出来的新工人,那个用exit体面下班的工人,那个被waitpid妥善回收的工人。那时你会明白:我们学的不只是代码,更是系统运行的 “故事”。
别停下脚步,也别害怕复杂。每一个函数的背后,都藏着前辈们的思考;每一次成功的运行,都是你向系统世界迈出的坚定一步。
加油,未来的系统工程师。我们下一个知识点见。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 35
35 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)