亚马逊的2026年最新算法变革自然流量分发机制“文本匹配”到“多模态意图理解”的范式革命
要理解算法如何运作,关键在于其背后的数学语言。下面,我们将从宏观的流量分配到微观的梯度更新,逐一拆解其中核心环节的“推导过程”。
📈 公式拆解:亚马逊A9算法
在亚马逊的A9算法体系中,一个商品Listing获得的总流量(Y),可以分解为:
-
流量公式: Y=X×CY=X×C
-
XX:曝光量(Impression)
-
CC:点击率(Click-Through Rate, CTR)
-
而曝光量(X)的构成,则是一个复杂的多变量问题,它与你的关键词总搜索量和搜索结果页排名紧密相关。
-
X=F×P(X)X=F×P(X)
-
FF:用户通过某个关键词搜索的总次数。
-
P(X)P(X):你的Listing在这个关键词下的“搜索曝光率”。你的产品在搜索结果中排名越靠前,这个值就越高。而排名,则由A9算法依据相关性、转化率、客户留存率等指标综合计算得出。
-
这意味着,提升流量,需要同时优化关键词、排名和主图,三者缺一不可。
🧠 深入模型:从宏观排序到微观梯度
如果说A9算法是宏观的流量分配规则,那么梯度提升决策树(GBDT) 就是驱动A9实现精细化排名的核心微观模型,常用于预估点击率(CTR)。其核心思想是“积少成多,不断纠错”,通过数学推导让这个“纠错”过程变得精确可控。
-
核心思想与数学原理:GBDT通过迭代构建多个决策树来逼近真实值。它的数学原理在于,每一棵新树都致力于拟合前一棵树预测结果的“残差”。更精确地说,它拟合的是损失函数 L(y,y^)L(y,y^) 在当前模型处的负梯度方向。这个“负梯度”可以理解为当前预测值与真实值之间差距的“最佳下降方向”。
-
场景代入(回归问题):假设要预测一位用户的购买意愿,真实值 y=30y=30。
-
第一棵树预测 y^1=20y^1=20,残差 r1=y−y^1=10r1=y−y^1=10。
-
第二棵树的目标就是预测这个残差 r1r1,它预测 h2=6h2=6,此时新的预测值 y^2=20+6=26y^2=20+6=26,新残差 r2=30−26=4r2=30−26=4。
-
第三棵树预测 h3=3h3=3,预测值更新为 y^3=29y^3=29。
这个过程持续迭代,直到预测值与真实值的差距足够小。import numpy as np from sklearn.tree import DecisionTreeRegressor class SimpleGBDT: def __init__(self, n_estimators=100, learning_rate=0.1): self.n_estimators = n_estimators self.lr = learning_rate self.trees = [] def fit(self, X, y): # 初始化预测值为0 self.initial_pred = np.mean(y) F = np.full(len(y), self.initial_pred) for _ in range(self.n_estimators): # 1. 计算负梯度(对于平方损失,即残差) residuals = y - F # 2. 训练回归树拟合残差 tree = DecisionTreeRegressor(max_depth=3) tree.fit(X, residuals) self.trees.append(tree) # 3. 更新预测值 F += self.lr * tree.predict(X) def predict(self, X): F = np.full(len(X), self.initial_pred) for tree in self.trees: F += self.lr * tree.predict(X) return F -
算法精髓:通过“拟合负梯度”这一核心机制,GBDT能够灵活地处理多种损失函数,从而广泛应用于回归、分类等多种问题。
-
核心原理:InfoNCE损失的目标是让“匹配”的图像-文本对在向量空间中距离更近,而“不匹配”的对距离更远。从数学上讲,最小化InfoNCE损失等价于在数据的相似性图上执行谱聚类(Spectral Clustering) 。
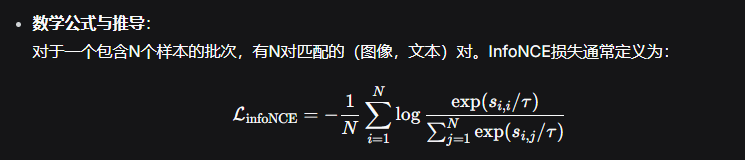
-
🌌 跃迁到向量世界:多模态对比学习(如InfoNCE损失)
除了GBDT,现代电商推荐系统还广泛采用基于向量的方法,例如用于多模态模型训练的InfoNCE损失。它通过比较不同模态数据(如图像和文本)在向量空间中的距离,来学习如何将它们有效关联。
-
-
si,jsi,j 是第i张图片和第j段文本的相似度(通常为余弦相似度)。
-
ττ 是温度参数,用于控制模型对负样本的区分度。
-
直观理解:这个公式的目标是,对于批次中的每个正样本对 ii,其相似度 si,isi,i 相对于所有负样本对 si,j(j≠i)si,j(j=i) 的比值要尽可能大。这样,模型才能“学到”哪些视觉特征和哪些语义特征是紧密关联的。
-
-
Rufus:生成式AI购物助手
Rufus基于检索增强生成(RAG) 技术,结合了语义搜索和大语言模型(LLM)。-
核心过程:它首先在亚马逊庞大的产品目录、用户评论和社区问答中检索与用户问题相关的信息。然后,将这些检索到的信息作为“上下文”提供给一个专门为购物场景定制的大语言模型(LLM),最终生成自然、准确的回答。
-
数学本质:虽然Rufus内部模型复杂,但其核心是一个条件生成模型:P(answer∣question,retrieved_docs)P(answer∣question,retrieved_docs)。它通过 “强化学习(RL)” 机制,根据用户的反馈不断优化,学习哪些回答模式是更有帮助的。
-
-
COSMO:电商常识知识图谱
COSMO(Common Sense Knowledge)是一个大规模知识图谱,其数学基础是图论和知识表示学习(KRL)。-
核心结构:COSMO将常识知识编码为三元组(实体-关系-实体) 的形式,例如
<瑜伽垫, 用于场景, 居家健身>。它通过大语言模型从海量的用户交互行为(如查询-购买对)中挖掘并构建出这些三元组,形成一个覆盖广泛品类的常识网络。 -
数学模型:本质上,它是一个异构图 G=(V,E)G=(V,E),其中节点 VV 代表实体(产品、场景、人群),边 EE 代表它们之间的常识关系。通过图嵌入(Graph Embedding) 技术,可以将图中的节点映射到低维向量空间,从而让算法能够计算“孕妇鞋”与“防滑鞋”之间的语义距离。
-
-
SODA与ABR:动态自适应比特率算法
在流媒体领域,ABR(Adaptive Bitrate,动态自适应比特率)算法用于优化视频播放体验。-
SODA的核心优化:SODA算法采用了“码率地平线规划”策略。它不只看当前的网络状况,而是预测未来K个视频块的可用带宽,并一次性规划出一个最优的码率序列(R1,R2,...,RKR1,R2,...,RK)。

-
-
🔬 技术深潜:其他算法的核心推导
除了上述微观模型,系统的其他部分也涉及精妙的算法设计。
-
-
-
Q(Rt)Q(Rt):选择码率 RtRt 时获得的视频质量分数(如VMAF)。
-
λλ:平滑系数,用于平衡画质提升与切换惩罚。
-
-
求解过程:这是一个动态规划问题。SODA使用滚动优化(Receding Horizon) 策略,在每个时刻只求解未来一小段时间的最优解并执行第一个动作,然后重复此过程,实现了近90%的码率切换次数减少。
-
-
💎 总结
-
亚马逊的流量分发机制正经历一场从“文本匹配”到“多模态意图理解”的范式革命。曾经的核心A9算法依然重要,但现在,能“看懂”图片的 COSMO 算法和基于生成式AI的 Rufus 购物助手已成为决定自然流量的关键变量。
简单来说,自然流量的获取,正从优化关键词全面转向优化用户场景。以下是这套新机制的深度拆解:
🧠 算法总览:从A9到COSMO的范式革命
要理解主图为何变得空前重要,必须先看懂亚马逊算法的代际切换:
-
A9算法 (文本匹配时代):核心逻辑是“关键词匹配”。搜索“yoga mat”,系统会检索标题、描述里含这个词的Listing。在这个阶段,主图主要影响点击率(CTR),间接作用于排名。
-
COSMO算法 (多模态意图理解时代):核心是理解“用户真正想要什么”。当搜索“maternity clothes”时,A9只看字面意思,COSMO则会理解深层需求可能是“孕期产检时的舒适穿着”,并会优先推荐图片中呈现了“孕妇在产检环境”场景的产品。
-
Rufus AI (生成式购物助手):这是直接面向用户的AI对话机器人。它能根据用户的自然语言提问,结合产品目录、评论等全网信息,直接生成个性化的推荐列表。这意味着商品可能不经过传统的搜索排名,就直接被AI推荐。
这三者并非完全取代,而是共同构成了一个多层级的流量分发网络。
🧩 视觉推流全链路拆解
在这个新体系下,主图被推送到用户面前,经历了以下几个关键步骤:
🔎 第一层:A9的“相关性初筛”与主图CTR
COSMO虽然权重更高,但A9仍是第一道门槛。
-
基础相关性:A9仍会快速匹配标题、五点描述等文本信息。
-
主图点击率(CTR):在海量商品中,一张能脱颖而出的主图至关重要。主图必须使用纯白背景(RGB 255,255,255),且产品占比在65%-85%之间,平台已将此项指标纳入了排名因子。更重要的是,你的主图必须让用户想点击。数据显示,一张高点击率的主图,能直接提升在该关键词下的自然排名。
🧠 第二层:COSMO的“意图理解”与多模态识别
COSMO算法的核心在于,它具备“多模态”理解能力,能将图片中的视觉元素转化为算法能懂的“视觉标签”。你的图片会被算法拆解分析:
-
场景 (Scene):用户在什么环境下使用?(如:厨房、健身房)
-
人物 (People):用户是谁?(如:孕妇、家庭主妇)
-
动作 (Action):产品是如何被使用的?(如:一个戴着手套的手正在擦拭桌面)
-
物品关联 (Items):产品还和什么东西一起出现?(如:瑜伽垫、运动水壶)
当图片中的视觉标签与搜索词的意图高度匹配时,COSMO就会判定“场景-需求”精准映射,从而给予更高的排名权重。一个真实的A/B测试显示:同为“cleaning gloves”关键词,使用清洁场景图的B产品,7天内排名从32名跃升至第8名,点击率提升42%;而纯白底图的A产品则毫无起色。
🤖 第三层:Rufus的“AI代理”与直接推荐
Rufus是亚马逊内置的生成式AI导购助手,它不再让用户被动搜索,而是通过对话主动理解需求。
-
工作原理:Rufus基于RAG(检索增强生成)技术,从产品目录、评论和全网信息中实时检索。
-
对主图的影响:Rufus具备读取图片信息的能力。例如,用户上传车内杂乱的照片并询问如何整理,Rufus能识别出“杂物堆积”的场景,并推荐收纳产品,无需用户输入任何关键词。
📈 数据引擎:主图如何驱动“推流飞轮”
高质量的视觉内容,是启动自然流量“推流飞轮”的起点。
-
1. 主图引发共鸣 → 提升点击率 (CTR):用户在搜索结果中,第一眼看到的就是主图。如果主图能展示他们想象中的使用画面,便能引发共鸣,提高点击率。含白底主图+场景化副图的Listing,其CTR可达14.8%,比行业平均水平高出61%。
-
2. 场景图建立信任 → 提升转化率 (CVR):场景图让用户“看见”自己使用产品的样子,降低了购买决策成本。数据显示,包含场景图的链接,转化率可提升18%以上。
-
3. 更高CTR/CVR → 更强的排名信号:高点击和高转化不断向算法发送“这个产品很受欢迎”的信号,平台随之给予更多自然曝光,形成良性循环。
🛠️ 实战指南:如何优化主图,最大化自然流量
理解上述机制后,优化的重点应从“我的图美不美”转向“我的图能否被算法看懂并被用户共鸣”。
-
1. 打好合规基础:主图使用纯白背景,产品占图65%-85%,避免水印和文字。
-
2. 打造“意图图”而非“产品图”:不要只拍产品,要拍用户的使用场景。每张图都应回答一个问题:“我的产品为用户解决了什么问题?”
-
3. 视觉标签策略:分析核心关键词背后的意图,确保图片场景能精准匹配。
-
4. 图片顺序与测试:建议采用“主图(白底)→ 场景图(25%权重)→ 功能图 → 尺寸图 → 包装图”的序列。务必进行A/B测试,验证不同主图的CTR和转化率。
-
5. 确保图文信号一致:你的主图、标题、五点描述和A+内容必须传达一致的核心信息。
-
6. 关注加载速度:将图片压缩至200-500KB,因为加载时间超过1.5秒可能导致15%的用户流失。
总的来说,亚马逊的自然流量算法正在经历一场深刻的变革。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)