VIT与多模态
1. Vision Transformer
1)ViT模型概述
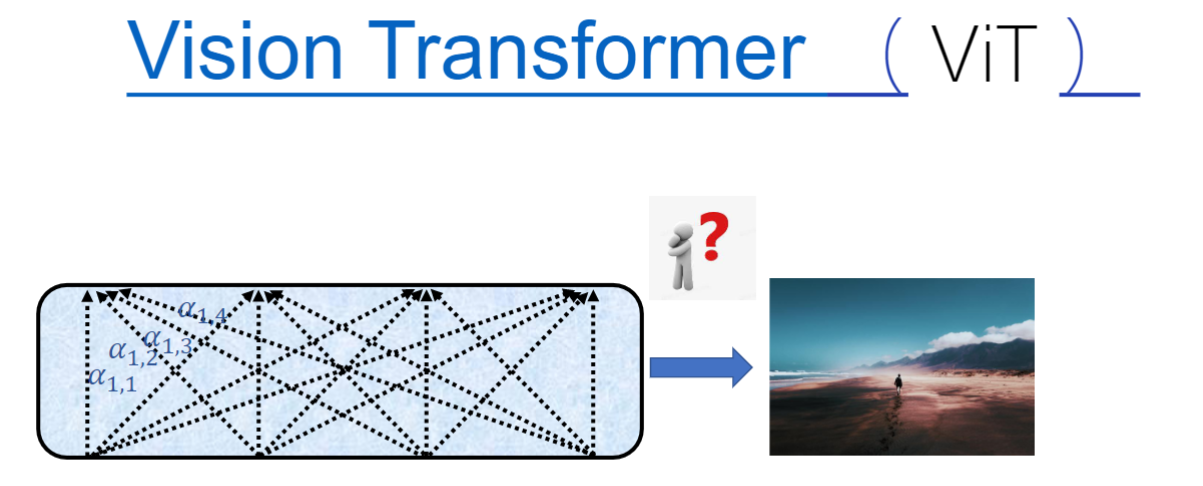
- 模型全称: Vision Transformer (ViT),即视觉领域的Transformer
- 核心思想: 将NLP界的Transformer架构迁移到视觉领域使用
- 创新点: 首次证明图片可以被离散化为token进行处理
2)Transformer在NLP中的应用原理
- 交互机制: 通过qkv注意力计算实现token间交互
- 输入无关性: 无论输入是文字/图片/声音,只要转换为向量即可处理
- 向量维度: 典型维度包括768维、2048维或3500+维向量
3)图片输入ViT模型的处理方式
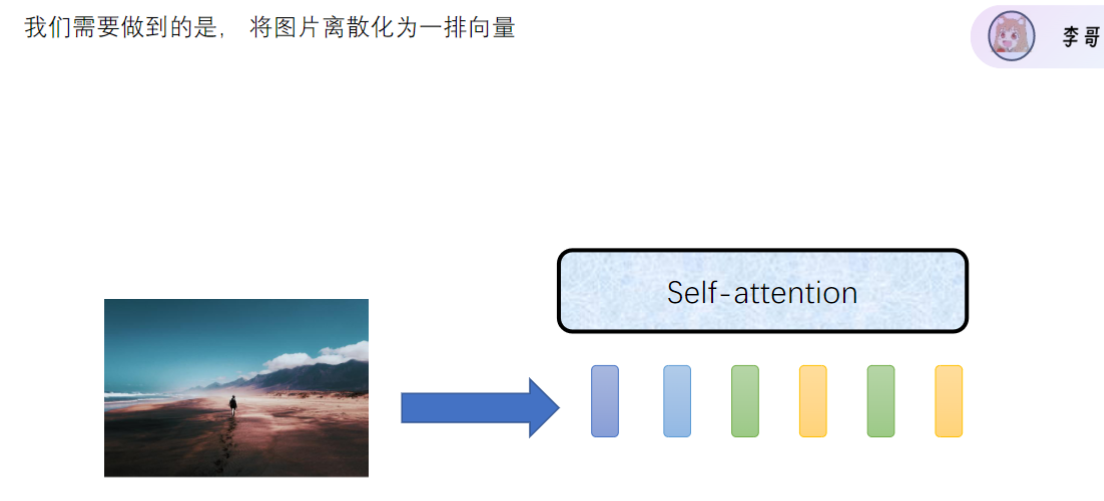
- 离散化方法: 将图片分割为14×14的patch(补丁)
- 典型配置: 实际应用中常采用16×16分块,产生196个token
- 向量转换: 每个patch展平后通过线性层投影为768维向量
- 位置编码: 每个patch添加位置embedding保持空间信息
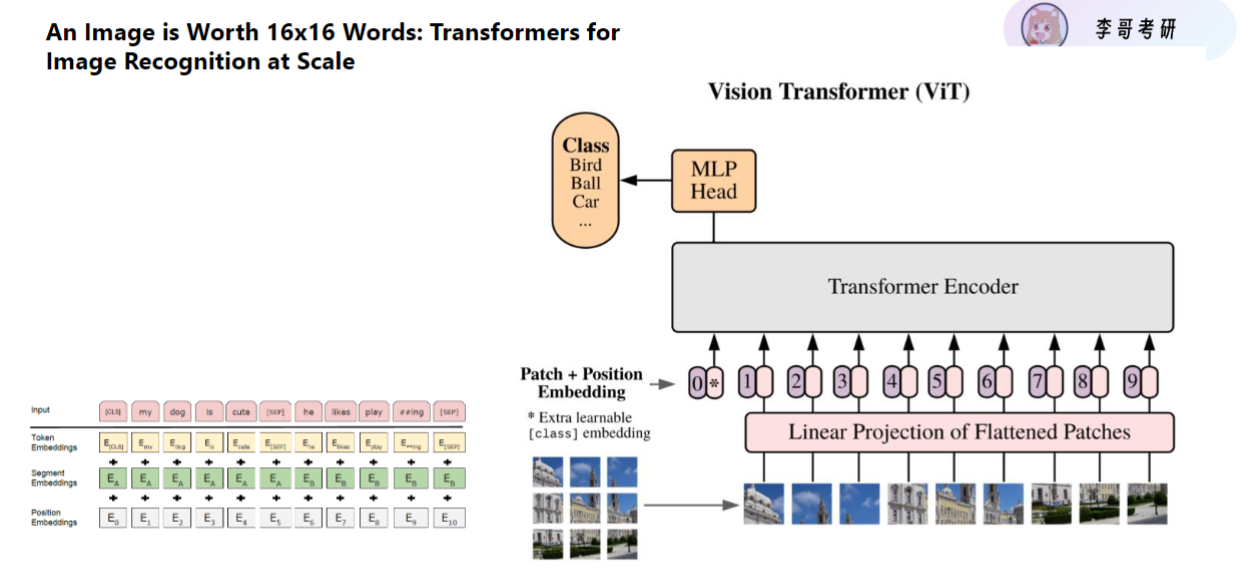
4)ViT模型在分类任务中的应用与局限性
- 基本流程: 图片→分块→Transformer特征提取→MLP分类
- 初期表现: 分类效果不如CNN,主要因为:
- 感受野缺失: 缺乏卷积的局部感受野优势
- 分割风险: 关键物体可能被错误分割
- 架构优势: 为后续多模态发展奠定基础
2. 多模态
1)多模态任务
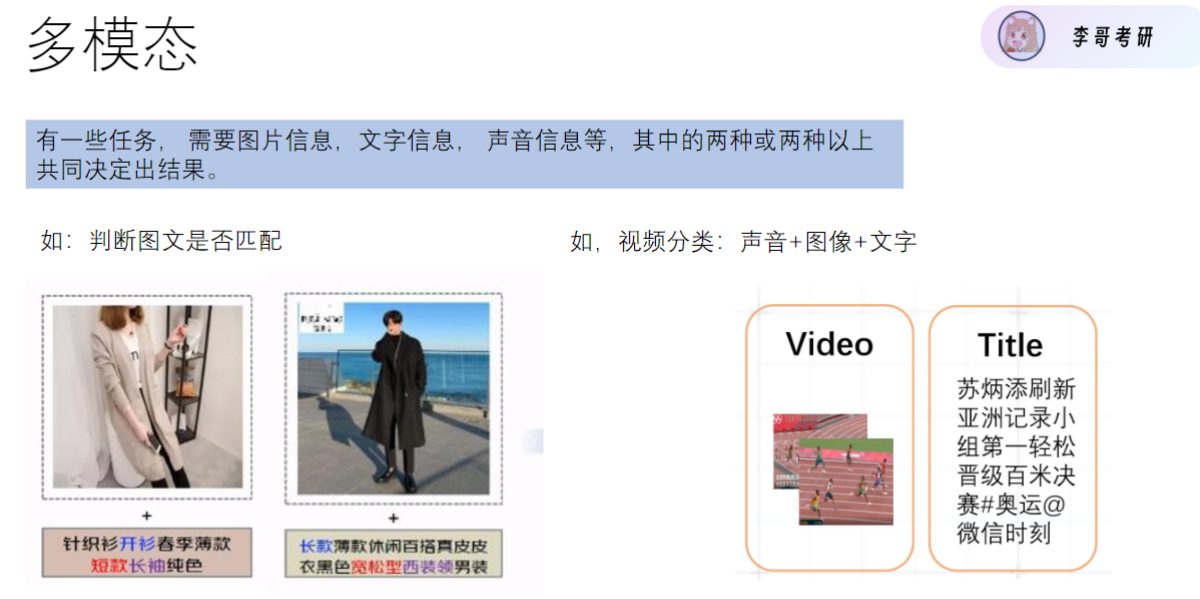
- 基本定义: 需要两种及以上模态信息(如图片+文字+声音)共同决策的任务
- 典型场景:
- 图文匹配判断
- 视频分类(结合视频内容与标题文字)
- 短视频平台内容分类
- 例题:图文检索任务
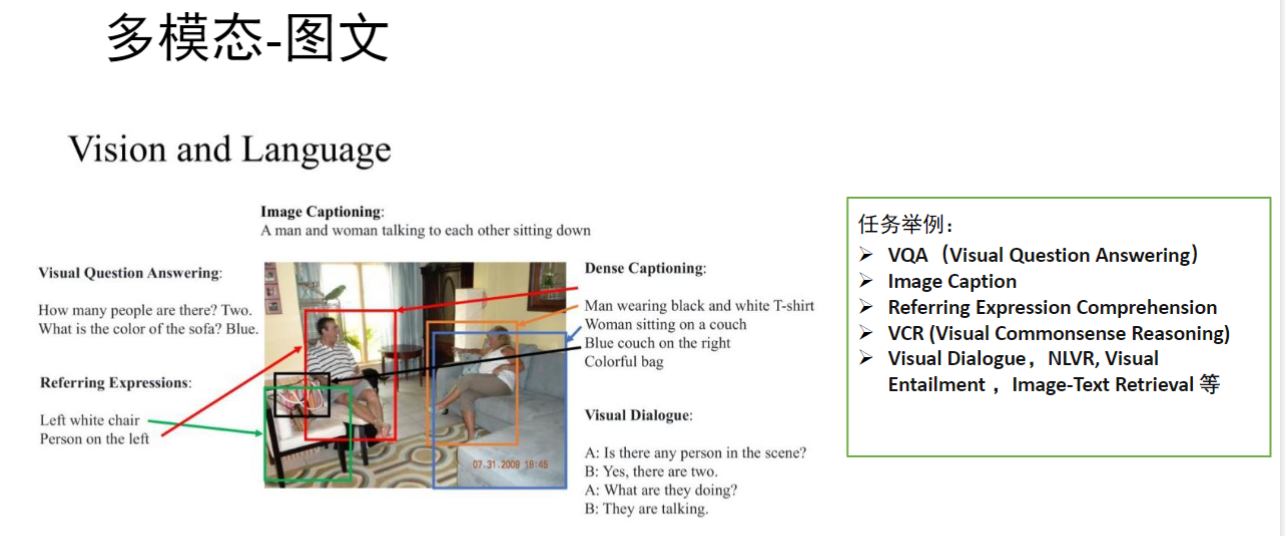
- 任务类型:
- Image Captioning(图像描述生成)
- VQA(视觉问答)
- Referring Expression Comprehension(指代表达理解)
- Visual Dialogue(视觉对话)
- 交互特点: 模型需要同时理解视觉内容和语言表达
- 任务类型:
2)Bert(Transformer)与多模态
- 架构优势: Transformer天然适合多模态处理
- 核心原理: 只处理向量交互,不关心原始输入形式
- 实现方式: 将不同模态数据统一转换为向量表示

3)ViltBert(以下都是多模态模型)
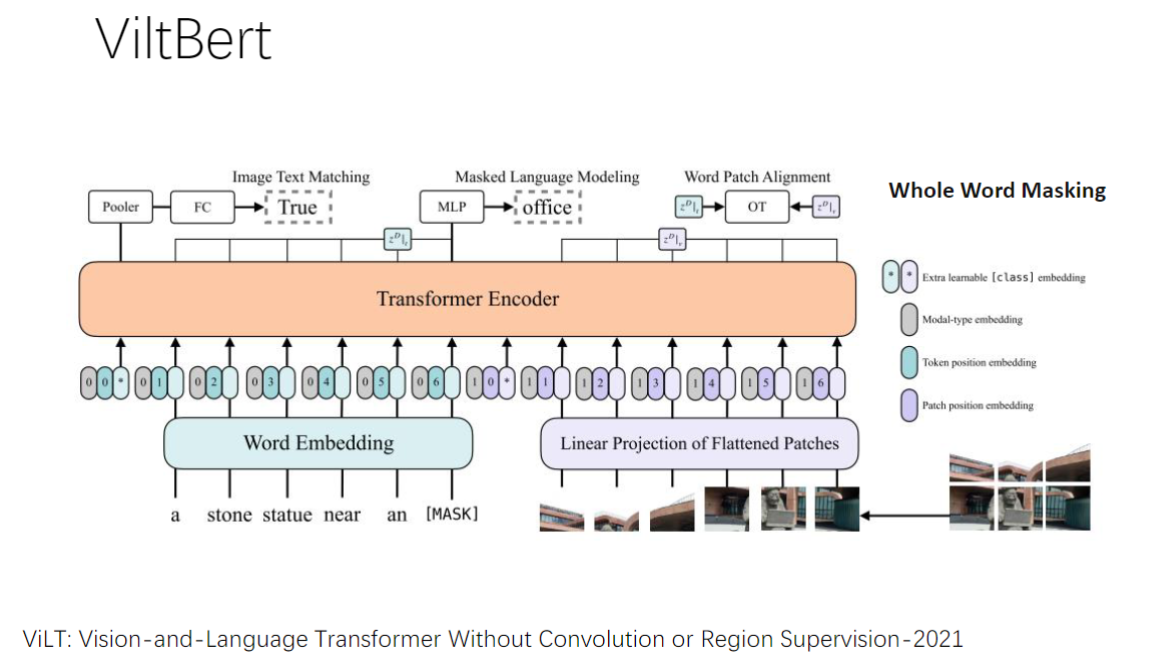
- 预处理任务:
- ITM:图文匹配判断
- MLM:掩码语言建模(遮盖15%token)
- WPA:词块对齐(word-patch alignment)
- 技术创新:
- 全词遮盖:对英文词根分词时保持完整词遮盖
- 注意力可视化:验证文字token能正确关注相关图像区域

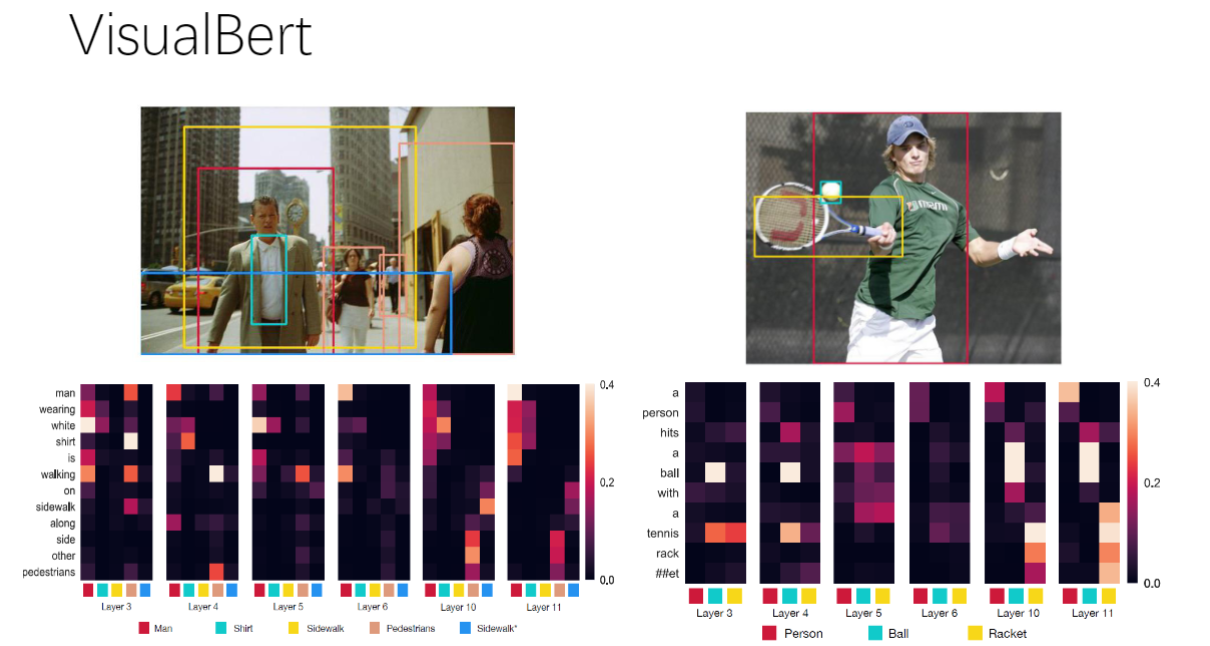
4)VisualBert
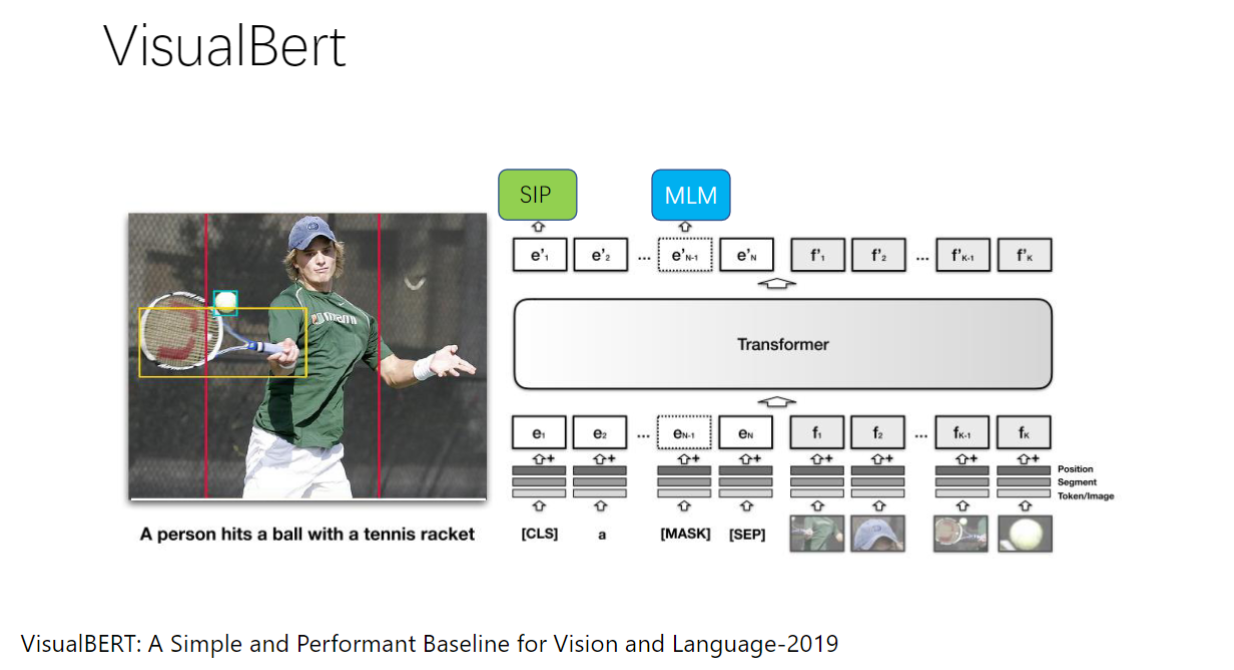
- 关键区别: 使用目标检测提取图像区域作为token
- token特性: 每个token对应一个语义实体(如人、球拍等)
- 层间进化: 注意力对齐效果随网络层数加深而改善
5)ALBEF
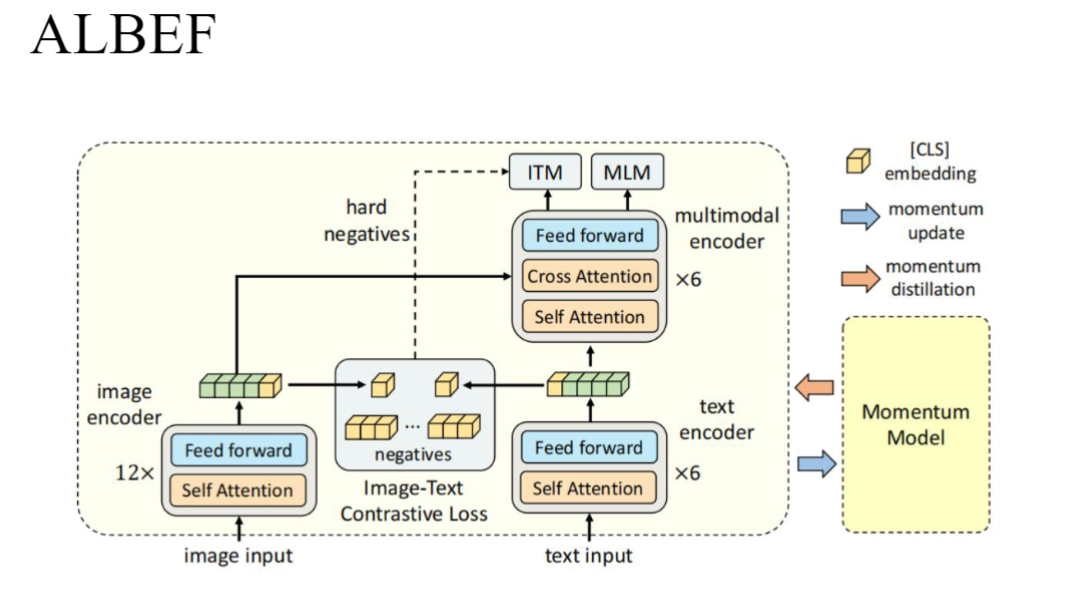
- 双编码结构:
- 图像编码器(12层Transformer)
- 文本编码器(6层Transformer)
- 对比学习: 使用对比损失拉近匹配图文对的表示
- 交叉注意力: 在深层进行跨模态注意力交互
- 应用特点: 比赛刷榜专用模型,实际工业应用有限
3. 深度学习常见研究方向
16:26
1)文字生成类
16:36
- 典型应用:
- 写诗:如生成"君不见黄河之水天上来,奔流到海不复回"等古诗风格文本
- 写文章:包括文学创作和学术写作,例如求解数学问题"设f(z)在0到正无穷上二阶可导..."
- 聊天机器人:实现自然对话交互
- 文本摘要:根据长文章生成精简摘要
- 技术演进:传统由小模型完成的任务现已被大模型取代,导致部分研究方向失去原有价值
- 风格转换:
- 语气调整:如将"你是XX把?这事都不会"转换为更温和的表达
- 文本复述:保持语义不变的情况下改变表达方式
2)命名实体识别
17:09
- 基本概念:识别文本中特定类型的实体
- 典型实体类型:
- 时间表达式:如"1949年10月1日"
- 地名:如"中国"、"北京"
- 人名:如"毛泽东"
- 组织机构:如"共产党"
- 应用价值:在推荐系统等实际应用中具有重要作用
3)医学图像分类、分割、检测
17:29
- 主要任务:
- 分类:判断图像是否显示病理特征
- 分割:精确划分解剖结构(如脑干、前额叶等)
- 检测:定位病灶区域
- 行业特点:
- 数据稀缺:医学影像数据通常不共享,导致数据集规模小
- 研究现状:不同机构使用私有数据训练模型,结果难以直接比较
- 技术优势:是目前大模型尚未完全取代的传统研究方向
4)小样本
19:02
- 核心挑战:在仅20个训练样本条件下实现良好效果
- 解决方法:
- 迁移学习:利用预训练模型进行知识迁移
- 数据增广:通过变换扩充有限数据集
- 研究意义:与大模型需要海量数据的特性形成鲜明对比
5)异常检测
19:36
- 典型场景:
- 金融交易:正常交易占99.9%,欺诈交易仅0.01%
- 网络流量:异常流量占比极低
- 技术难点:
- 模型容易通过"全部预测为正常"获得虚假高准确率
- 实际需要检测的恰恰是罕见异常样本
- 研究价值:解决类别极度不平衡问题的有效方法
6)可解释性
21:15
- 研究目标:揭示深度神经网络的黑箱机制
- 学科特点:主要由数学背景研究者推动
- 发展现状:实践应用领先于理论解释
7)分子结构预测
21:37
- 研究内容:
- 预测化合物的三维空间结构
- 评估不同结构的药物性能
- 技术基础:主要基于图神经网络
- 实际应用:在药物设计领域具有重要价值
8)解微分方程
22:41
- 应用背景:解决核工程、航天等领域的复杂微分方程
- 技术挑战:深度学习处理数学问题的能力仍有局限
- 方程示例:如
ω′=[010070−6−50001002−10]ω+[0000.5]\omega' = \begin{bmatrix}0&1&0&0\\7&0&-6&-5\\0&0&0&1\\0&0&2&-10\end{bmatrix}\omega + \begin{bmatrix}0\\0\\0\\0.5\end{bmatrix}ω′=070010000−6020−51−10ω+0000.5
9)颅面复原到人脸
23:03
- 应用领域:
- 刑侦:通过头骨复原嫌疑人面貌
- 考古:重建古人面部特征
- 技术特点:需要结合医学影像处理和生成模型
10)分布式训练
23:32
- 主要形式:
- 单机多卡:协调多GPU之间的数据流动
- 多机训练:解决数据隐私限制下的模型训练
- 联邦学习:
- 核心思想:只传输梯度而非原始数据
- 伦理争议:梯度仍可能泄露部分数据信息
- 应用场景:移动设备数据训练等隐私敏感领域
11)大语言模型
25:26
- 研究建议:需要大厂实习经历才能获得相关实践经验
- 技术组成:包含编码器-解码器结构、注意力机制等组件
- 关键参数:层数L、嵌入维度
dmodeld_{model}dmodel
、多头数H
12)代码中用的细节之处
25:36
- 优化重点:
- 学习率设计:调整训练过程的收敛速度
- 模型量化:用8位数表示原本32位的参数
- 架构创新:改进注意力机制等核心组件
- 行业现状:研究方向高度饱和,竞争激烈
4. 如何把学的内容写到简历之中
26:08
1)例题:回归任务写入简历方法
26:12
- 数据处理重点:回归任务看似简单,但重点在于数据处理方式。需突出两个数据集的不同处理方法和特征选择技巧
- 技术深度体现:即使使用简单回归,也要展示独特技术手段(如特征处理、训练技巧),可参考Kaggle比赛冠军方案
- 案例佐证:2025年清华大数据比赛就是回归任务,获胜者使用了非常规特征处理方法
- 关键问题准备:
- 如何处理不同数据集?
- 如何选择特征?
- 使用哪些训练技巧?(如dropout、
W2W^2W2
正则项)
2)例题:分类任务写入简历方法
28:08
- 模型对比写法:
- 尝试不同模型(如ResNet、VGG)
- 准备模型理解问题:ResNet为什么深?与VGG的区别?
- 模型设计写法:
- 根据数据集特点设计模型
- 准备设计思路说明
- 数据处理写法:
- 数据增广方式选择(如MNIST不适合翻转)
- 不同增广方式对比
- 进阶写法:
- 半监督学习实现原理
- 迁移学习方法及对比实验
- 科研思维体现:通过对比实验展示研究能力
3)例题:自然语言处理写入简历方法
29:24
- 兴趣导向写法:
- 表达对NLP方向的兴趣
- 提前学习self-attention等核心技术
- 模型架构理解:
- 比较RNN、LSTM优劣
- 解释self-attention流行原因及架构细节
- BERT专项准备:
- BERT原理及有效性原因
- 预训练任务说明
- 微调与下游任务区别
- 训练细节(优化器选择、epoch数等)
4)例题:生成任务写入简历方法
30:12
- 模型介绍:
- BART模型背景(源自芝麻街动漫)
- 与BERT的区别
- 预训练任务说明
- 技术细节准备:
- 生成任务原理(自回归生成)
- 训练与测试差异(批量vs逐字)
- 输入输出处理方式
- 对比实验:
- 与GPT等模型的对比选择
- 不同模型效果比较
5)写简历的其他方法
31:07
- 直球法:
- 如实说明自学经历(如"考研后寒假自学深度学习")
- 强调快速学习能力和掌握程度
- 兴趣导向法:
- 明确研究方向兴趣(如对比学习、多模态)
- 展示相关领域知识储备
- 技术专项:
- 不同激活函数比较(优缺点)
- 优化器原理与选择
- 注意事项:
- 只写真正了解的内容
- 避免虚假夸大
6)知网检索法
- 操作步骤:
- 搜索熟悉领域(如图像识别、目标检测)
- 筛选硕士学位论文(内容最详细)
- 学习论文中的项目背景、技术方案、改进方法
- 优势:
- 获取完整项目描述
- 学习规范的研究方法
- 掌握领域专业术语
- 应用技巧:
- 重点理解技术实现部分
- 转化为自己的项目经验
- 准备可能的技术细节问题
二、课程总结
1. 课程时长与学习安排
- 课程结构: 共13节课,总时长约20小时
- 学习周期: 建议15-20天完成(按每天学习4小时计算)
- 学习要求: 必须亲自实践代码,仅听课无法掌握

三、知识小结
|
知识点 |
核心内容 |
考试重点/易混淆点 |
难度系数 |
|
ViT模型 |
视觉Transformer,将图片拆分为patch(如14×14)作为token输入,无需卷积层 |
与CNN的对比(ViT无卷积,依赖全局注意力)、patch嵌入方式 |
⭐⭐⭐ |
|
多模态任务 |
需结合多种数据类型(如图片+文字),典型应用:图文匹配、视频标题分类 |
模态融合技术(如拼接/交叉注意力)、预训练任务设计(MLM、对比损失) |
⭐⭐⭐⭐ |
|
多模态模型(ViLBERT/VisualBERT/ALBEF) |
- ViLBERT:图片分patch+文本联合输入 - VisualBERT:目标检测提取实体作为token - ALBEF:双编码器+对比损失+交叉注意力 |
模型差异(ViLBERT vs ALBERT)、预训练任务(全词掩码/图文对齐) |
⭐⭐⭐⭐ |
|
小样本学习 |
数据极少(如20样本)下的训练方法,依赖数据增广/迁移学习 |
与大模型对立(数据需求相反)、医学图像中的实际应用困境 |
⭐⭐⭐⭐ |
|
异常检测 |
处理极端不平衡数据(正常样本占99.9%),模型易陷入全预测正常陷阱 |
评估指标选择(准确率失效,需用F1/召回率)、损失函数设计 |
⭐⭐⭐⭐⭐ |
|
简历书写技巧 |
- 回归任务:突出特征工程/比赛排名 - 分类任务:对比不同模型/数据增广策略 - NLP项目:解释Self-Attention/微调方法 |
科研思维体现(对比实验/迁移学习)、避免编造(可参考硕士论文) |
⭐⭐ |
|
研究方向案例 |
- 医学图像(数据私有化问题) - 分子结构预测(图神经网络) - 联邦学习(隐私与梯度传输伦理) |
领域特殊性(如医学数据壁垒)、技术交叉应用(如Transformer解微分方程) |
⭐⭐⭐⭐ |
|
课程学习建议 |
强调动手实践(如卷积维度计算)、避免被动输入,需结合代码理解 |
自学路径(20小时/10天攻坚)、与高阶课程(如李宏毅课)对比 |
⭐⭐ |
以下为AI生成的图文笔记的内容

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)