RAG技术全解析:从入门到企业级应用实践
一、为什么需要RAG?
大语言模型(LLM)虽然强大,但存在三个致命缺陷:
- 知识截止日期:训练数据截止后的事件一概不知
- 幻觉问题:对未知问题会“一本正经地胡说八道”
- 私有数据无法访问:企业内部文档、最新资讯无法融入
RAG(Retrieval-Augmented Generation,检索增强生成) 应运而生——在用户提问时,先从外部知识库中检索相关文档片段,再连同问题一起交给大模型生成答案。
> 一句话定义:RAG = 检索(相关文档) + 生成(基于文档+问题)
二、RAG核心流程(三阶段)
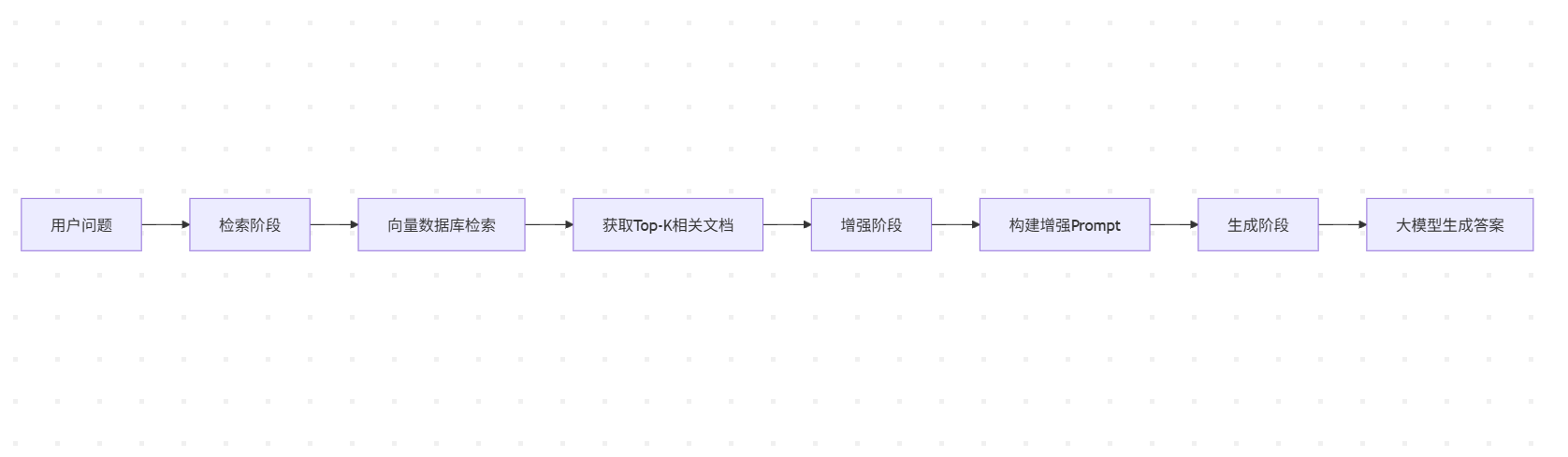
阶段1:索引(离线准备)
1. 文档切分:将PDF/Word/网页切分成小段落(chunk)
2. 向量化:用Embedding模型将每个chunk转为向量
3. 存储:存入向量数据库(同时保留原始文本)
阶段2:检索(在线查询)
1. 用户问题 → Embedding模型 → 问题向量
2. 向量数据库相似度搜索 → 召回Top-K个最相关chunk
阶段3:生成(在线回答)
1. 构造Prompt:`"基于以下资料:\n{chunks}\n\n回答问题:{question}"`
2. 大模型生成答案,可附带引用来源
三、技术栈选型
| 环节 | 开源方案 | 商业/云方案 |
| Embedding模型 | BGE-large-zh, text2vec, m3e | OpenAI text-embedding-3, 智谱Embedding |
| 向量数据库 | Chroma, Qdrant, Milvus | Pinecone, 阿里云ADB |
| 大模型 | ChatGLM3, Qwen, Yi | GPT-4o, Claude, 文心一言 |
| 编排框架 | LangChain, LlamaIndex | Dify, Coze |
新手推荐组合:LangChain + Chroma + OpenAI API(或国内智谱/通义千问)
四、手把手实战:从零构建一个RAG问答系统
环境准备
pip install langchain chromadb openai tiktoken pypdf完整代码示例(中文知识库)
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# 1. 加载文档(以PDF为例)
loader = PyPDFLoader("company_handbook.pdf")
documents = loader.load()
# 2. 切分文档(关键参数:chunk_size, overlap)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每块500字符
chunk_overlap=50, # 重叠50字符,避免上下文断裂
separators=["\n\n", "\n", "。", "!", "?", ";", " ", ""]
)
chunks = text_splitter.split_documents(documents)
# 3. 向量化并存入Chroma
embeddings = OpenAIEmbeddings() # 或替换为本地模型
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db" # 持久化
)
# 4. 构建检索器(retriever)
retriever = vectorstore.as_retriever(
search_type="similarity", # 也可用mmr(最大边际相关性)
search_kwargs={"k": 4} # 召回4个相关片段
)
# 5. 构建问答链
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # stuff, map_reduce, refine, map_rerank
retriever=retriever,
return_source_documents=True # 返回引用来源
)
# 6. 提问
response = qa_chain("公司年假有多少天?")
print(response["result"])
print("引用资料:", response["source_documents"])关键参数调优建议
- chunk_size:中文建议256~512字符(英文200~400token)
- chunk_overlap:一般为chunk_size的10%~20%
- k值:通常4~10,知识库越杂越大可适当增大
- temperature:问答任务建议0~0.3,避免发散
五、进阶优化技巧(让RAG真正可用)
技巧1:混合检索(Hybrid Search)
纯向量检索可能忽略关键词精确匹配。使用**向量检索 + BM25关键词检索**,再通过RRF(倒数排名融合)合并结果。
# 使用LangChain的EnsembleRetriever
from langchain.retrievers import EnsembleRetriever
from langchain.retrievers import BM25Retriever
bm25_retriever = BM25Retriever.from_documents(chunks)
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vectorstore.as_retriever()],
weights=[0.4, 0.6] # 权重分配
)技巧2:重排序(Re-ranking)
初次召回Top-20,用更精准的交叉编码器模型重新打分,取Top-4。可大幅提升相关性。```python
from sentence_transformers import CrossEncoder
reranker = CrossEncoder('BAAI/bge-reranker-large')
# 对召回结果计算相关性分数,重新排序技巧3:查询改写(Query Rewriting)
用户原始问题可能模糊或指代不清。先用大模型改写为更明确的检索查询。
rewrite_prompt = "请将以下问题改写为更清晰、便于检索的形式:{question}"
rewritten = llm.invoke(rewrite_prompt)
# 用rewritten去检索技巧4:多路检索 + 融合
同时检索向量库、关键词索引、SQL数据库、API,最后融合结果。
技巧5:Self-RAG(自我反思)
让大模型在生成过程中判断“是否需要检索”、“检索结果是否足够”、“回答是否基于事实”,动态决策。
六、常见问题与解决方案
| 问题现象 | 根本原因 | 解决方案 |
|---|---|---|
| 回答漏掉关键信息 | 切分过大或过小,相关片段被截断 | 调整chunk_size,增大k值 |
| 答案与问题无关 | 检索召回质量差 | 改用混合检索+重排序 |
| 出现“根据提供资料...”却无内容 | 检索结果为空 | 设置fallback回答,如“未找到相关信息” |
| 回答不准确/幻觉 | 大模型未严格遵循检索内容 | 强化Prompt约束,要求“仅基于以下资料回答” |
| 响应速度慢 | 大模型调用耗时 | 缓存常见问题,用小模型做第一轮筛选 |
| 知识更新不及时 | 索引未重建 | 实现增量更新,定时重建索引 |
七、RAG vs 微调(Fine-tuning)如何选择?
| 维度 | RAG | 微调 |
|---|---|---|
| 知识更新 | 实时(只需更新文档库) | 需重新训练,成本高 |
| 可解释性 | 可溯源到原始文档 | 黑盒,难以解释 |
| 幻觉问题 | 低(强约束在检索内容上) | 中高 |
| 个性化风格 | 难(需在Prompt中调) | 易(模型学习风格) |
| 计算成本 | 低(仅推理+检索) | 高(训练+推理) |
| 典型场景 | 企业知识库、客服、法律文档 | 特定格式生成、角色扮演、风格模仿 |
最佳实践:RAG为主,微调为辅。对核心风格或特殊格式要求,可微调一个轻量LoRA;对知识类任务,RAG足够。
八、高级架构:RAG在企业级落地的演进
简单RAG(Naive RAG)
索引 → 检索 → 生成
× 问题:检索质量不稳定,长上下文丢失
模块化RAG(Modular RAG)
- 新增查询规划器:复杂问题拆解为多步检索
- 检索后处理:重排序、压缩(提取关键句)
- 生成后验证:用大模型自我检查是否忠实于资料
记忆增强RAG(MemRAG)
- 维护短期对话记忆和长期知识记忆
- 典型框架:RAPTOR(递归抽象树检索)
Agentic RAG
- 检索不再是一次性,而是Agent可以**主动决定**何时检索、检索什么、调用哪些工具(SQL、API、Web搜索)
- 代表:LangGraph、LlamaIndex的Agent模式
九、评估RAG系统的方法
| 评估维度 | 指标 | 如何计算 |
|---|---|---|
| 检索相关性 | Hit Rate, MRR, NDCG | 人工标注或利用大模型评估 |
| 生成忠实度 | 是否产生幻觉 | 用NLI模型或LLM-as-Judge |
| 答案正确性 | Exact Match, F1 | 有标准答案时使用 |
| 端到端响应时间 | P99延迟 | 系统监控 |
推荐开源评估框架:RAGAS、ARES、TruLens
# RAGAS示例
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_relevancy
result = evaluate(
dataset=your_dataset,
metrics=[faithfulness, answer_relevancy, context_relevancy]
)十、学习资源与延伸阅读
必读论文
1. RAG原始论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Lewis et al., 2020)
2. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection (Asai et al., 2023)
3. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval (Sarthi et al., 2024)
开源项目
- LangChain - 最流行的编排框架
- LlamaIndex - 专为RAG优化的数据框架
- RAGFlow - 开箱即用的RAG平台
- QAnything - 网易开源的RAG引擎
博客/视频
- Building RAG from Scratch (LangChain官方教程)
- Advanced RAG Techniques (Pinecone工程博客)
十一、写在最后:RAG的未来
RAG正在从“文档检索 + LLM”演变为多模态RAG(检索图像、表格、音频)、交互式RAG(用户反馈实时调整检索策略)和分布式RAG(企业级联邦检索)。掌握RAG意味着掌握了让大模型落地生产环境的核心钥匙。
> RAG不是万能的,但没有RAG的大模型应用是万万不能的。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)