集成学习完全指南:从AdaBoost到随机森林,揭秘为什么一群“弱鸡”能吊打“学霸”
在机器学习领域,单个模型的表现往往受限于其固有的偏差(Bias)和方差(Variance)问题——这就好比一位再厉害的学霸,也难免有自己的知识盲区。集成学习(Ensemble Learning)正是为解决这一困境而生,其核心思想简单而有力:三个臭皮匠,顶个诸葛亮——通过组合多个个体学习器的预测结果,构建一个更强大的强学习器。
这项技术的价值不容低估。研究表明,对于不稳定的学习算法,Bagging可以将预测误差降低20%至30%,使其在金融风控、医疗诊断等对模型稳定性要求极高的领域广受欢迎。本文将带你系统掌握集成学习的核心方法,从AdaBoost到随机森林,从理论原理到代码实战,全方位理解为什么一堆“弱模型”能够联手击败“学霸模型”。
一、集成学习的核心思想:偏差-方差分解
在深入具体算法之前,我们首先需要理解一个关键概念:偏差-方差分解。这是理解集成学习为何有效的理论基础。
- 偏差(Bias)
:刻画学习算法本身的拟合能力。偏差高意味着模型欠拟合,连训练数据的基本规律都没学好。
- 方差(Variance)
:刻画数据扰动对模型的影响程度。方差高意味着模型过拟合,换一组训练数据就可能跑出截然不同的结果。
在大多数情况下,偏差和方差是相互冲突的——降低一方往往以升高另一方为代价,这就是机器学习中著名的偏差-方差权衡。
集成学习的魅力在于,它能够巧妙地同时处理这两个问题:Boosting主要专注于降低偏差,而Bagging和随机森林则专注于降低方差。这种分工配合使得集成方法能够在泛化性能上超越任何单一模型。
二、Boosting:让后浪踩着前浪的肩膀前进
2.1 Boosting的核心逻辑
Boosting是一种串行式的集成学习方法。它通过顺序训练模型,让每个新模型重点关注前一个模型犯错的样本,从而逐步提升整体性能。这种“迭代修正”的机制,使得Boosting能够将一系列弱学习器组合成一个强学习器。
从偏差-方差分解的角度来看,Boosting之所以能有效降低偏差,是因为其原理就是将多个弱学习器逐步组合成强学习器。每个弱学习器都在努力修正前序模型的错误,最终得到一个拟合能力极强的整体模型。
2.2 AdaBoost:自适应提升
AdaBoost(Adaptive Boosting)是Boosting家族中最具代表性的算法。它的核心思想可以概括为两句话:改变数据权重,让后一个学习器更关注前一个的错误;改变学习器权重,让表现好的学习器有更大发言权。
算法流程详解
下面用流程图展示AdaBoost的工作机制:
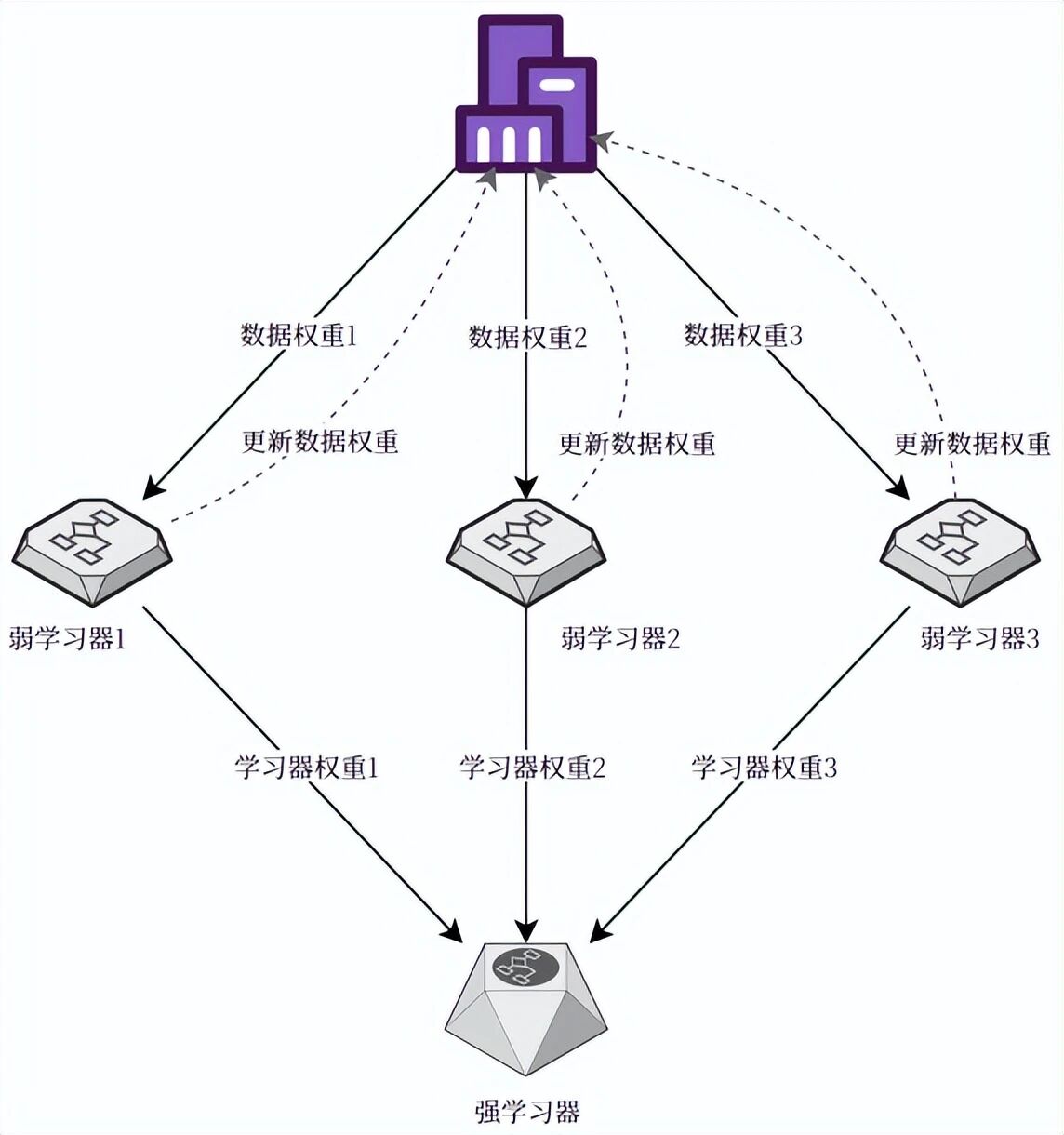
具体来说,AdaBoost的执行过程如下:
第一步:初始化所有训练样本的权重相等(假设有N个样本,每个样本权重为1/N)。
第二步:在当前权重分布下训练一个弱分类器,通常使用决策树桩(Decision Stump,即最大深度为1的决策树)。
第三步:计算该弱分类器的分类误差率,并根据误差率计算该学习器的权重系数——误差越小,权重越高;误差越大,权重越低。
第四步:更新训练样本的权重分布:被当前分类器正确分类的样本权重降低,被错误分类的样本权重升高。这样一来,下一个弱分类器会“被迫”更多地关注那些难分类的样本。
第五步:回到第二步,继续训练下一个弱分类器,直到达到预设的迭代次数。
最终,AdaBoost将所有弱分类器按照各自的权重系数进行加权投票,输出最终的强分类结果。
代码实战:从数据到模型
下面我们用完整的代码演示AdaBoost的整个流程,包括数据集准备、模型训练、预测评估和可视化。
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification, make_gaussian_quantiles
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.inspection import DecisionBoundaryDisplay
# 设置随机种子,确保结果可复现
np.random.seed(42)
# ==================== 1. 准备数据集 ====================
# 方案一:使用make_gaussian_quantiles生成非线性的高斯分位数数据集
# 该数据集由嵌套的同心球面边界分隔三个类别
X, y = make_gaussian_quantiles(
n_samples=2000, # 样本总数
n_features=10, # 特征维度
n_classes=3, # 类别数
random_state=1 # 随机种子
)
# 方案二:使用make_classification生成更具挑战性的分类数据集(可根据需要切换)
# X, y = make_classification(
# n_samples=2000,
# n_features=10,
# n_informative=8,
# n_redundant=2,
# n_classes=3,
# random_state=42
# )
# 划分训练集和测试集(70%训练,30%测试)
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=0.7, random_state=42
)
print(f"训练集样本数: {len(X_train)}")
print(f"测试集样本数: {len(X_test)}")
print(f"特征维度: {X.shape[1]}")
print(f"类别数: {len(np.unique(y))}")
# ==================== 2. 训练AdaBoost模型 ====================
# AdaBoost默认使用决策树桩(max_depth=1的决策树)作为基学习器
# 这是AdaBoost的标准配置,也是大多数场景下的最优选择[reference:7]
base_model = DecisionTreeClassifier(max_depth=1, random_state=42)
# 创建AdaBoost分类器
# n_estimators: 弱分类器数量
# learning_rate: 学习率,控制每个弱分类器的贡献程度
# algorithm: 使用'SAMME.R'(Real SAMME)算法,收敛更快
adaboost = AdaBoostClassifier(
estimator=base_model,
n_estimators=50,
learning_rate=1.0,
algorithm='SAMME.R',
random_state=42
)
# 训练模型
adaboost.fit(X_train, y_train)
# 预测
y_pred = adaboost.predict(X_test)
# ==================== 3. 评估模型性能 ====================
accuracy = accuracy_score(y_test, y_pred)
print(f"\n=== 模型评估 ===")
print(f"AdaBoost (50个基学习器) 测试集准确率: {accuracy:.4f}")
print(f"\n分类报告:")
print(classification_report(y_test, y_pred))
# ==================== 4. 不同基学习器数量下的性能对比 ====================
# 图表清晰地展示了:随着基学习器数量的增加,模型的决策边界越来越精细
# 5个基学习器 → 10个基学习器 → 20个基学习器 → 50个基学习器
n_estimators_list = [5, 10, 20, 50]
train_accuracies = []
test_accuracies = []
for n in n_estimators_list:
ada_temp = AdaBoostClassifier(
estimator=base_model,
n_estimators=n,
learning_rate=1.0,
random_state=42
)
ada_temp.fit(X_train, y_train)
train_acc = accuracy_score(y_train, ada_temp.predict(X_train))
test_acc = accuracy_score(y_test, ada_temp.predict(X_test))
train_accuracies.append(train_acc)
test_accuracies.append(test_acc)
print(f"n_estimators={n:2d} | 训练准确率: {train_acc:.4f} | 测试准确率: {test_acc:.4f}")
# 绘制性能对比曲线
plt.figure(figsize=(10, 6))
plt.plot(n_estimators_list, train_accuracies, 'o-', label='训练集准确率', linewidth=2)
plt.plot(n_estimators_list, test_accuracies, 's-', label='测试集准确率', linewidth=2)
plt.xlabel('弱学习器数量 (n_estimators)', fontsize=12)
plt.ylabel('准确率', fontsize=12)
plt.title('AdaBoost: 基学习器数量对性能的影响', fontsize=14)
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()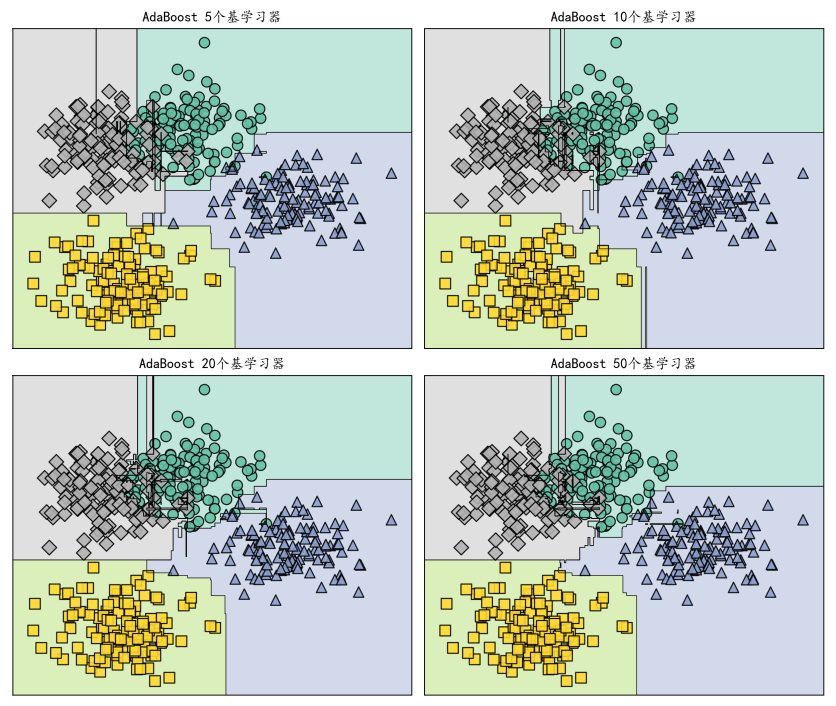
关键超参数解析
|
超参数 |
含义 |
典型取值范围 |
调优建议 |
|
n_estimators |
弱学习器数量 |
10-500 |
过少导致欠拟合,过多可能过拟合且计算量大 |
|
learning_rate |
每个学习器的贡献度 |
0.0001-1.0 |
较小学习率需要更多学习器,但泛化能力可能更好 |
|
algorithm |
算法选择 |
'SAMME'或'SAMME.R' |
SAMME.R收敛更快,测试误差更低 |
|
base_estimator |
基学习器类型 |
决策树桩(默认) |
深度1的决策树桩是最经典选择 |
AdaBoost在scikit-learn中的默认n_estimators为50,base_estimator为max_depth=1的决策树。这个默认配置已经在大量实践中被证明效果良好。
案例:手写数字识别
下面展示AdaBoost在光学字符识别(OCR)任务中的应用——这是一个典型的机器学习实战场景:
from sklearn.datasets import load_digits
from sklearn.ensemble import AdaBoostClassifier
# 加载手写数字数据集(8x8像素的灰度图像,共1797个样本)
digits = load_digits()
X, y = digits.data, digits.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 训练AdaBoost模型
adaboost_ocr = AdaBoostClassifier(n_estimators=100, random_state=42)
adaboost_ocr.fit(X_train, y_train)
# 预测并评估
y_pred_ocr = adaboost_ocr.predict(X_test)
accuracy_ocr = accuracy_score(y_test, y_pred_ocr)
print(f"手写数字识别准确率: {accuracy_ocr:.4f}")2.3 现代Boosting:XGBoost与LightGBM
AdaBoost奠定了Boosting的基础,而近年来XGBoost和LightGBM的崛起,则将Boosting推向了新的高度。这两个算法都是梯度提升树(Gradient Boosting Decision Tree)的高效实现,在大规模数据处理和比赛场景中表现卓越。
# 安装命令
# pip install xgboost lightgbm
import xgboost as xgb
import lightgbm as lgb
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# ==================== XGBoost ====================
# 创建DMatrix格式数据(XGBoost的高效内部数据格式)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# 设置参数
xgb_params = {
'objective': 'multi:softmax', # 多分类任务
'num_class': 3, # 类别数
'max_depth': 6, # 树的最大深度
'learning_rate': 0.1, # 学习率
'subsample': 0.8, # 每棵树的样本采样比例
'colsample_bytree': 0.8 # 每棵树的特征采样比例
}
# 训练模型
xgb_model = xgb.train(xgb_params, dtrain, num_boost_round=100)
# 预测
xgb_pred = xgb_model.predict(dtest)
# ==================== LightGBM ====================
# 创建Dataset格式数据
lgb_train = lgb.Dataset(X_train, y_train)
# 设置参数
lgb_params = {
'boosting_type': 'gbdt', # 梯度提升决策树
'objective': 'multiclass', # 多分类
'num_class': 3,
'num_leaves': 31, # 每棵树的最大叶子数(LightGBM特有)
'learning_rate': 0.1,
'feature_fraction': 0.8, # 特征采样比例
'bagging_fraction': 0.8, # 数据采样比例
'verbose': -1
}
# 训练模型
lgb_model = lgb.train(lgb_params, lgb_train, num_boost_round=100)
# 预测
lgb_pred = lgb_model.predict(X_test)
lgb_pred_class = np.argmax(lgb_pred, axis=1)
# ==================== 性能对比 ====================
print("=== XGBoost vs LightGBM 性能对比 ===")
print(f"XGBoost 准确率: {accuracy_score(y_test, xgb_pred):.4f}")
print(f"LightGBM 准确率: {accuracy_score(y_test, lgb_pred_class):.4f}")XGBoost与LightGBM的核心区别:
|
特性 |
XGBoost |
LightGBM |
|
树生长策略 |
按层生长(Level-wise) |
按叶生长(Leaf-wise) |
|
内存占用 |
较高 |
较低 |
|
训练速度 |
中等 |
快 |
|
特征处理 |
需要预处理缺失值 |
原生支持缺失值 |
|
典型应用 |
中小数据集、需要精细控制的场景 |
大规模数据集、追求速度的场景 |
LightGBM采用“按叶生长”策略,每次选择增益最大的叶子进行分裂,虽然训练速度更快,但在小数据集上容易过拟合;XGBoost的“按层生长”策略则更为稳健。
三、Bagging与随机森林:多样性带来鲁棒性
3.1 Bagging的基本原理
Bagging的全称是Bootstrap Aggregating(自助聚合),由统计学家Leo Breiman于1996年正式提出。它的核心机制包含双重随机性:首先通过有放回抽样从原始数据集中生成多个不同的训练子集,然后在每个子集上并行训练一个基学习器,最终通过投票(分类)或平均(回归)聚合所有预测结果。
这种设计的精妙之处在于:Bootstrap采样使得每个训练子集中约有36.8%的原始样本不会被选中,这确保了基学习器之间的差异性。如果所有基学习器都产生相似的预测,聚合带来的收益将十分有限。正是这种适度的数据扰动,保证了基学习器既保持一定的准确性,又具备足够的差异性。
从偏差-方差分解的角度看,Bagging之所以能降低方差,是因为多个模型的预测结果被平均后,单个模型波动带来的影响被显著平滑了。
3.2 随机森林:Bagging的进化版
随机森林是Bagging最著名的变体。它在Bagging的基础上,进一步在决策树训练过程中引入了随机属性选择:基决策树的每个节点在划分时,先从特征集合中随机选择一个包含k个特征的子集,再从这个子集中选出最优特征用于分裂。
特征选择的随机性
这种“双重随机性”设计——既随机采样样本,又随机采样特征——让随机森林成为集成学习领域的标杆方法:
-
当k = d(全部特征)时,与传统决策树无异,基学习器多样性仅来自样本扰动
-
当k = 1时,完全随机选择一个特征进行划分,极端强调多样性
- 一般推荐k = log₂d
,这是在多样性与准确率之间的最佳平衡
随机森林之所以被誉为“代表集成学习技术水平的方法”,正是因为这种多样性的提升带来了更强的泛化性能。
3.3 代码实战:随机森林完整示例
下面用完整的代码展示随机森林的整个流程,并对比不同树数量对性能的影响。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
import time
# ==================== 1. 准备数据集 ====================
# 使用与AdaBoost相同的数据集,便于对比
X, y = make_gaussian_quantiles(
n_samples=2000,
n_features=10,
n_classes=3,
random_state=1
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=0.7, random_state=42
)
# ==================== 2. 训练随机森林 ====================
# 创建随机森林分类器
# n_estimators: 树的数量
# max_features: 每个节点分裂时考虑的特征数量
# max_depth: 树的最大深度(None表示不限制,让树自由生长)
random_forest = RandomForestClassifier(
n_estimators=100, # 树的数量
max_features='sqrt', # 使用sqrt(n_features)个特征,对应推荐值log2d
max_depth=None, # 树完全生长
min_samples_split=2, # 内部节点再划分所需最小样本数
min_samples_leaf=1, # 叶子节点的最小样本数
bootstrap=True, # 使用Bootstrap采样
oob_score=True, # 计算袋外误差
random_state=42,
n_jobs=-1 # 使用所有CPU核心并行训练
)
# 训练模型
start_time = time.time()
random_forest.fit(X_train, y_train)
train_time = time.time() - start_time
# 预测和评估
y_pred_rf = random_forest.predict(X_test)
accuracy_rf = accuracy_score(y_test, y_pred_rf)
print(f"=== 随机森林模型评估 ===")
print(f"训练时间: {train_time:.2f} 秒")
print(f"测试集准确率: {accuracy_rf:.4f}")
print(f"袋外误差估计: {1 - random_forest.oob_score_:.4f}")
# ==================== 3. 不同树数量下的性能对比 ====================
# 图表展示了:5棵树 → 10棵树 → 20棵树 → 50棵树时,决策边界的演变
n_trees_list = [5, 10, 20, 50]
rf_train_times = []
rf_accuracies = []
for n in n_trees_list:
rf_temp = RandomForestClassifier(
n_estimators=n,
max_features='sqrt',
random_state=42,
n_jobs=-1
)
start = time.time()
rf_temp.fit(X_train, y_train)
elapsed = time.time() - start
acc = accuracy_score(y_test, rf_temp.predict(X_test))
rf_train_times.append(elapsed)
rf_accuracies.append(acc)
print(f"n_estimators={n:2d} | 训练时间: {elapsed:.2f}s | 准确率: {acc:.4f}")
# 绘制性能对比
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# 左图:准确率随树数量变化
axes[0].plot(n_trees_list, rf_accuracies, 'o-', linewidth=2, markersize=8, color='darkgreen')
axes[0].set_xlabel('树的数量 (n_estimators)', fontsize=12)
axes[0].set_ylabel('测试集准确率', fontsize=12)
axes[0].set_title('随机森林: 树数量对准确率的影响', fontsize=14)
axes[0].set_ylim([0.8, 1.0])
axes[0].grid(True, alpha=0.3)
# 右图:训练时间随树数量变化
axes[1].plot(n_trees_list, rf_train_times, 's-', linewidth=2, markersize=8, color='coral')
axes[1].set_xlabel('树的数量 (n_estimators)', fontsize=12)
axes[1].set_ylabel('训练时间 (秒)', fontsize=12)
axes[1].set_title('随机森林: 树数量对训练时间的影响', fontsize=14)
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# ==================== 4. 特征重要性分析 ====================
feature_importance = random_forest.feature_importances_
feature_names = [f'特征 {i+1}' for i in range(X.shape[1])]
plt.figure(figsize=(10, 6))
indices = np.argsort(feature_importance)[::-1]
plt.bar(range(X.shape[1]), feature_importance[indices], color='steelblue')
plt.xticks(range(X.shape[1]), [feature_names[i] for i in indices], rotation=45)
plt.xlabel('特征', fontsize=12)
plt.ylabel('重要性得分', fontsize=12)
plt.title('随机森林特征重要性排序', fontsize=14)
plt.tight_layout()
plt.show()
print("\n=== 特征重要性排序 ===")
for i in range(X.shape[1]):
print(f"{feature_names[indices[i]]}: {feature_importance[indices[i]]:.4f}")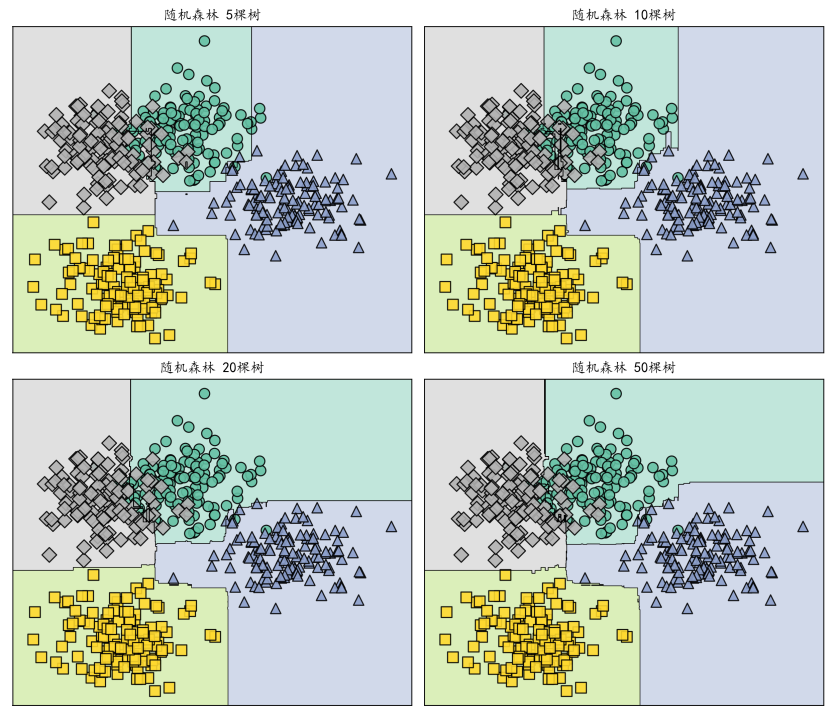
随机森林关键超参数
|
超参数 |
含义 |
推荐值 |
调优思路 |
|
n_estimators |
树的数量 |
100-500 |
越多越好,但收益递减,计算成本线性增长 |
|
max_features |
分裂时考虑的特征数 |
sqrt 或 log2 |
越小多样性越强,但单棵树的准确性会下降 |
|
max_depth |
树的最大深度 |
None (完全生长) |
Bagging理念:让单棵树充分生长 |
|
min_samples_split |
分裂所需最小样本数 |
2 |
控制树的复杂度 |
|
oob_score |
是否计算袋外误差 |
True |
无需验证集即可评估泛化性能 |
scikit-learn官方文档指出,调整随机森林时最关键的参数是n_estimators和max_features。
超参数调优实战
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
# ==================== 网格搜索 ====================
# 适用于参数空间较小的情况
param_grid = {
'n_estimators': [50, 100, 200],
'max_features': ['sqrt', 'log2', None],
'max_depth': [10, 20, None]
}
grid_search = GridSearchCV(
RandomForestClassifier(random_state=42),
param_grid,
cv=5,
scoring='accuracy',
n_jobs=-1,
verbose=1
)
grid_search.fit(X_train, y_train)
print(f"网格搜索最佳参数: {grid_search.best_params_}")
print(f"网格搜索最佳得分: {grid_search.best_score_:.4f}")
# ==================== 随机搜索 ====================
# 适用于参数空间较大的情况,效率更高
param_dist = {
'n_estimators': [50, 100, 150, 200, 300],
'max_features': ['sqrt', 'log2', 0.3, 0.5, 0.7],
'max_depth': [5, 10, 15, 20, None],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
random_search = RandomizedSearchCV(
RandomForestClassifier(random_state=42),
param_dist,
n_iter=50, # 随机搜索的迭代次数
cv=5,
scoring='accuracy',
n_jobs=-1,
random_state=42,
verbose=1
)
random_search.fit(X_train, y_train)
print(f"\n随机搜索最佳参数: {random_search.best_params_}")
print(f"随机搜索最佳得分: {random_search.best_score_:.4f}")Bagging与随机森林的关系
|
对比维度 |
标准Bagging |
随机森林 |
|
样本采样 |
Bootstrap有放回采样 |
Bootstrap有放回采样 |
|
特征采样 |
所有特征参与分裂 |
每个节点随机选择特征子集 |
|
多样性来源 |
仅样本扰动 |
样本扰动 + 特征扰动 |
|
基学习器 |
任意类型(常为决策树) |
决策树 |
|
泛化能力 |
较强 |
更强 |
随机森林在Bagging的基础上增加了特征扰动,这使得基学习器之间的差异度更大,从而进一步提升了集成的泛化性能。
四、Stacking:分层融合的多模型协作
4.1 Stacking的核心思想
Stacking(堆叠泛化)是集成学习中最灵活的方法。不同于Boosting的串行修正和Bagging的并行投票,Stacking采用分层架构:先训练多个不同类型的基模型(如决策树、SVM、神经网络),然后将它们的预测结果作为新特征,再训练一个元模型(meta-model)来学习如何最优地组合这些基模型的输出。
Stacking的核心思想是利用不同模型的优势,通过元模型学习每个基模型在什么情况下应该被赋予更大的权重。
4.2 代码实战:Stacking完整示例
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
# ==================== 1. 准备数据集 ====================
from sklearn.datasets import make_classification
X, y = make_classification(
n_samples=1000,
n_features=20,
n_informative=15,
n_redundant=5,
n_classes=2,
random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# ==================== 2. 定义基模型和元模型 ====================
# 选择不同类型的基模型,多样性越强,Stacking效果越好[reference:20]
base_models = [
('dt', DecisionTreeClassifier(max_depth=5, random_state=42)),
('svm', SVC(probability=True, random_state=42)),
('knn', KNeighborsClassifier(n_neighbors=5)),
('rf', RandomForestClassifier(n_estimators=50, random_state=42))
]
# 元模型通常选择简单的线性模型,以避免过拟合
meta_model = LogisticRegression(random_state=42)
# ==================== 3. 构建Stacking分类器 ====================
stacking_clf = StackingClassifier(
estimators=base_models,
final_estimator=meta_model,
cv=5, # 使用5折交叉验证生成元特征,防止数据泄露
stack_method='predict_proba' # 使用预测概率作为元特征
)
# ==================== 4. 训练和评估 ====================
# 训练Stacking模型
stacking_clf.fit(X_train, y_train)
# 预测
y_pred_stacking = stacking_clf.predict(X_test)
accuracy_stacking = accuracy_score(y_test, y_pred_stacking)
print(f"=== Stacking模型评估 ===")
print(f"Stacking 测试集准确率: {accuracy_stacking:.4f}")
# ==================== 5. 对比单个基模型的性能 ====================
print(f"\n=== 各模型性能对比 ===")
for name, model in base_models:
model.fit(X_train, y_train)
acc = accuracy_score(y_test, model.predict(X_test))
print(f"{name:10s} 准确率: {acc:.4f}")
print(f"{'Stacking':10s} 准确率: {accuracy_stacking:.4f}")
# ==================== 6. 交叉验证确保稳定性 ====================
stacking_cv_scores = cross_val_score(stacking_clf, X, y, cv=5, scoring='accuracy')
print(f"\nStacking 5折交叉验证: {stacking_cv_scores}")
print(f"平均准确率: {stacking_cv_scores.mean():.4f} (+/- {stacking_cv_scores.std() * 2:.4f})")Stacking的工作流程
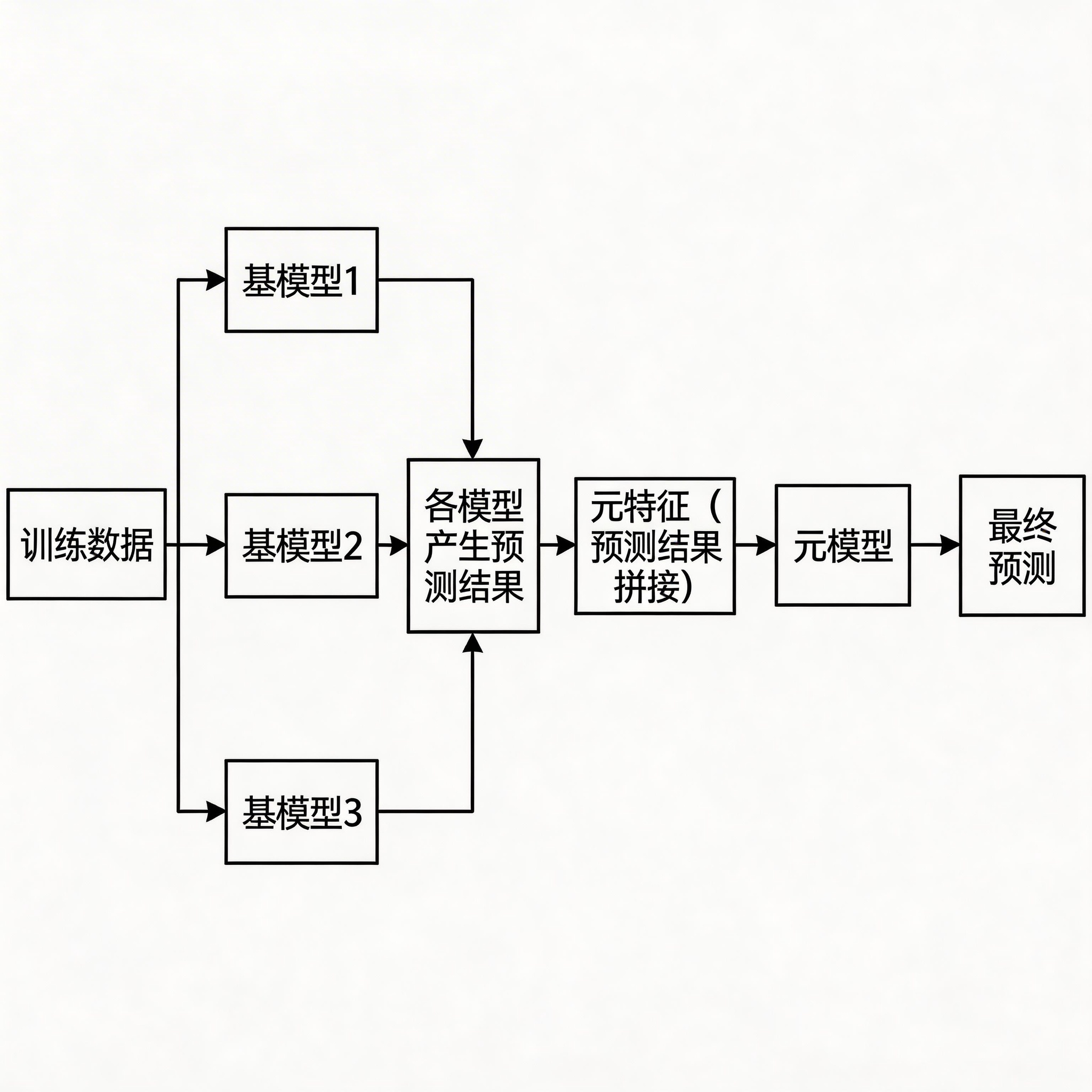
关键要点:
- 避免数据泄露
:必须使用交叉验证来生成元特征。如果直接用基模型在训练集上的预测来训练元模型,会导致严重的过拟合。上面的代码中,cv=5参数正是为了解决这个问题。
- 模型多样性至关重要
:基模型的差异越大,Stacking的效果越好。建议混合不同类型的模型——如线性模型(逻辑回归)、非线性模型(决策树)、基于距离的模型(KNN)等。
- 元模型不宜复杂
:通常使用简单的线性模型作为元模型,避免在元学习阶段产生过拟合。
Stacking的变体
- 多层级Stacking
:增加更多堆叠层,每层使用前一层的预测作为输入
- 简化版Stacking
:仅使用基模型的预测作为元特征,忽略原始特征以减少维度
五、三大方法的终极对决:该选哪一个?
以下是在典型分类任务中三种方法的综合对比:
|
维度 |
AdaBoost |
随机森林 |
Stacking |
|
核心作用 |
降低偏差 |
降低方差 |
综合利用各模型优势 |
|
训练方式 |
串行(Sequential) |
并行(Parallel) |
分层(Hierarchical) |
|
基学习器 |
同质(常为决策树桩) |
同质(决策树) |
异质(多种类型) |
|
对异常值敏感性 |
较敏感 |
不敏感 |
取决于基模型 |
|
训练时间 |
较快 |
中等 |
较慢 |
|
可解释性 |
较低 |
较高(特征重要性) |
低 |
|
内存占用 |
低 |
中 |
高 |
|
过拟合风险 |
低 |
极低 |
中(需小心设计) |
实战选择指南
选择AdaBoost的场景:
-
需要快速获得一个不错的基线模型
-
基学习器本身较弱(如决策树桩),需要提升其拟合能力
-
数据量适中,串行训练可接受
-
对模型的偏差降低有明确需求
选择随机森林的场景:
-
数据量大,需要并行训练
-
需要特征重要性分析
-
对过拟合非常敏感(随机森林是最稳健的算法之一)
-
需要处理高维数据(特征自动选择机制)
- 这是大多数场景下的首选“万金油”算法
选择Stacking的场景:
-
追求极致性能(如在Kaggle比赛中)
-
已经有一些表现不错的基模型,希望进一步提升
-
愿意投入更多计算资源来换取性能增益
-
基模型之间的多样性很高
六、前沿进展与未来趋势
集成学习领域仍在快速发展,以下几个方向值得关注:
集成剪枝(Ensemble Pruning) :随着集成规模扩大,计算开销和内存占用成为瓶颈。集成剪枝通过选择基学习器的优化子集来解决这些问题,相关研究已成为热点方向。
深度集成(Deep Ensembles) :训练多个独立的神经网络并测量其集体预测的方差,能够有效区分模型的不确定性和数据本身的噪声,这是当前深度学习不确定性量化的主流方法。
动态集成选择(Dynamic Ensemble Selection) :针对具有概念漂移的数据流,IncA-DES等算法能够在线动态调整集成结构,适应数据分布的变化。
异构数据融合:Modal-NexT等最新框架致力于实现统一的异构蜂窝数据集成,为构建人工智能虚拟细胞(AIVCs)奠定基础。这标志着集成学习的应用正在从结构化数据向更复杂的多模态数据扩展。
七、总结
集成学习的核心价值在于:让一群“弱模型”通过协作,实现远超单个“学霸模型”的性能表现。
- Boosting(以AdaBoost为代表)
:串行迭代,逐轮纠正错误,专注于降低偏差,适用于需要提升弱学习器拟合能力的场景
- Bagging与随机森林
:并行训练,通过样本扰动和特征扰动引入多样性,专注于降低方差,是工业界最稳健、最常用的集成方法
- Stacking
:分层融合,让元模型学习基模型的最优组合方式,灵活性强,是追求极致性能的首选
回顾图表数据:AdaBoost从5个基学习器增长到50个时,决策边界越来越精细;随机森林从5棵树增加到50棵时,决策边界越来越平滑;而Stacking则通过组合多种不同类型模型,进一步突破了单一方法的性能天花板。这三种方法从不同角度诠释了“三个臭皮匠,顶个诸葛亮”这一朴素而深刻的思想。
在掌握了这些核心原理和代码实现后,你已具备了在实际项目中灵活运用集成学习方法的基础。没有永远最好的算法,只有最合适的组合——根据你的具体场景和数据特性,选择最适合的集成策略,才是数据科学实践的真谛。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献142条内容
已为社区贡献142条内容

所有评论(0)