金融大模型落地应用全解(非常详细),时序知识图谱构建从入门到精通,收藏这一篇就够了!
主题是知识图谱结合大模型用于股票预测方案,类似于事件驱动的那套模式,《TRACE: Temporal Rule-Anchored Chain-of-Evidence on Knowledge Graphs for Interpretable Stock Movement Prediction》(https://arxiv.org/pdf/2603.12500),将符号规则先验、动态时序知识图谱多跳探索与大模型决策融合,用于可解释股票走势预测,通过规则引导图谱搜索、文本锚定证据链,最终在标普500数据集上实现55.1%准确率、60.8%F1值【其实并不高,准确率比投硬币高一点】,但是可以看看咋做的,重温下事件驱动或者叫事理图谱的模式。
看看趋势,也好的,这里做个记录。
一、金融时序知识图谱构建
整个的入口就是金融时序知识图谱,所以要看知识图谱构建的思路。
1、金融时序知识图谱构建

先看图谱的形式:
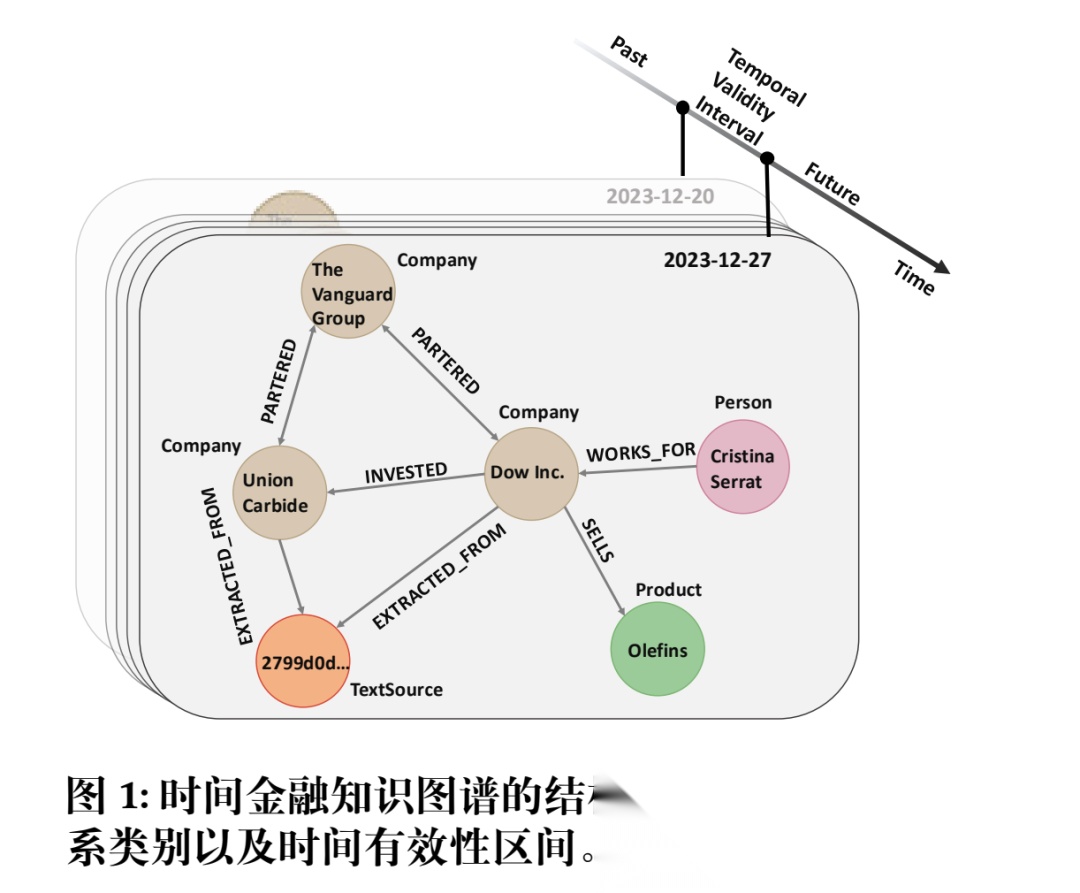
核心在于设计,其中:
实体类型:6类(TextSource/Event/Product/Financial/Company/Person),共42,188个节点; 关系类型:包括投资、合作、因果、法律等12种关系,共174,415条时序三元组。所有事实带时间窗口,仅使用≤t的信息;
关系类型:包括投资、合作、因果、法律等12种关系,共174,415条时序三元组。所有事实带时间窗口,仅使用≤t的信息;

 特别的,每个文本来源TextSource结点x都包含标题、出版商、URL和出版日期等元数据τ(x)。x中提到的实体通过EXTRACTED_FROM边连接,使得推理路径能够基于明确的文本证据。
特别的,每个文本来源TextSource结点x都包含标题、出版商、URL和出版日期等元数据τ(x)。x中提到的实体通过EXTRACTED_FROM边连接,使得推理路径能够基于明确的文本证据。
二、基于图谱的规则挖掘
金融时序知识图谱中自动挖掘出有预测力、高置信度的关系模式,用来约束后续图搜索,让推理只走“金融上有意义”的路径,而不是随机游走。这个就很像抽象的推理模式【我们一直说的事理图谱】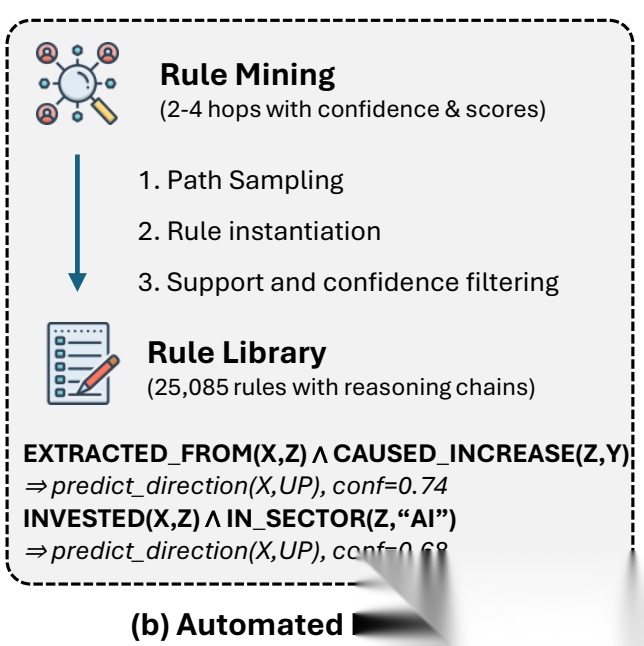 规则定义为:关系体(Body)→预测头(Head),其中:
规则定义为:关系体(Body)→预测头(Head),其中:
Body表示一段关系序列(多跳路径),比如INVESTED_IN(X,Z)∧IN_SECTOR(Z,"AI");Head表示预测方向,predict_direction(X,UP/DOWN)
两个整体意义就是如果X满足左边的关系链,那么X的股价倾向于UP或DOWN。
但是,额外的,还需要加点量化信息,每条规则还附带两个关键指标:一个是支持度Support:历史上满足Body的样本数量;一个是置信度Confidence:满足Body且预测正确的比例,Conf(ρ)=正确样本数/总满足样本数。【所以,这个还是靠曝光度来做的,黑天鹅事件做不了】
如PARTNERED(X,Z)∧CAUSED_INCREASE(Z,Y)⇒predict_direction(X,UP),Conf=0.74,表示,X和Z合作,且Z引发市场正向影响→X涨,置信度74%;
定义好了,具体怎么挖的?分成几步:
step1.路径采样(PathSampling),从时序知识图谱的所有三元组中。
具体的,先枚举多跳路径,先枚举所有2跳路径,递归组合生成3跳、4跳路径(论文默认最多4跳),只保留以目标股票(Company节点)为起点、最终能关联到事件/新闻/产品的路径,形成“实体-关系-实体”链;
step2.规则实例化(RuleInstantiation),把具体路径泛化成变量规则。
具体的,把路径里的具体实体替换成变量X、Z、Y等例:Tesla→PARTNERED→Panasonic→泛化为PARTNERED(X,Z),给每条泛化后的Body,同时生成UP和DOWN两个Head,即:同一条关系链,既测试它是否预示涨,也测试是否预示跌,最终形成完整候选规则:r₁(X,Z₁)∧r₂(Z₁,Z₂)∧…→predict_direction(X,UP/DOWN);
step3.支持度与置信度过滤(Filtering),只保留高置信、高覆盖的规则。
对每条候选规则ρ:x=历史中满足Body的(股票-日期)样本数,y=其中真实涨跌与Head一致的样本数,Conf(ρ)=y/x,剔除Conf(ρ)<0.6的规则;
step4.规则剪枝(Pruning),精简规则库,避免冗余与过拟合
具体实现上,两步,一步是冗余剪枝,如果一条长规则被更短的规则完全包含,且效果相近,删掉长规则。一步是过特异性剪枝,支持度过小、只在极少数股票出现的规则删掉;
最终得到的结果如下:
三、基于知识图谱+大模型做推理
有了之前的时序知识图谱和挖掘好得推理规则模式,现在可以用下,用来股价预测流程,为每只股票、每个交易日t,找出支持 UP/DOWN 的证据路径。
核心几个步骤:
step1,以目标股票为起点,仅用≤t的图谱数据
起点是目标股票对应的Company节点,而非文本/事件节点,然后,严格过滤图谱,只保留时间戳≤预测交易日t的节点、边、文本信息【主要用于杜绝未来数据泄露】,最后得到初始化路径列表,仅包含这条起点路径[股票节点]。
step2,束搜索(K=8,最大3跳)逐层扩展路径
需要做扩展,目的是找出所有可能的触达的路径。所以这里用束搜索,这个很常见【大模型生成内容时常用。beam search】,核心是每一步只保留K个最优路径,避免图遍历复杂度爆炸;k设置为8,每轮扩展后只留8条路径,最大设置3跳,路径最多走3层关系(如股票→事件→新闻)。扩展规则为对当前路径的最后一个节点,遍历其所有出边,生成原路径+新边的候选路径。【注意,这里还没有用到挖掘好的规则】
step3,只保留符合规则前缀的关系序列
扩展后,需要做过滤,找出真正有效的,这个时候,就用规则库去筛选,这里做两个筛选估,规则为规则前缀,即候选路径的关系链,必须是规则库中某条规则body的前半段(如规则是A→B→C,则A→B是前缀)。
具体的,不匹配任何规则前缀的路径直接丢弃,只留“有规则支撑”的路径,另外加一个规则阈值:仅匹配置信度≥0.6的规则。这是第一步筛选。
step4,LLM过滤无效关系
第二步,继续过滤,通过LLM做,输入当前路径、节点类型、时间约束、邻居统计,然后让其过滤目标,剔除无金融意义的关系(如“公司→无关新闻”)。
不用LLM时,用邻居出现频率+时间新鲜度替代打分。
step5,按规则完成度→覆盖率→新鲜度→反hub排序
第三次过滤是做排序,设计几个打分维度。规则完成度:是否完整匹配一条规则(优先级最高,是=1,否=0); 覆盖率:路径匹配规则body的比例(越高越优); 新鲜度:路径中新闻/事件的时间越新,分数越高; 反hub:避开高度节点(如“大盘”),防止路径走捷径、失去解释性。
step6,保留Top-8路径进入下一层
排序后,卡窗口。为了控制计算量,同时保留高价值路径。按step5的排序结果,只留前8条最优路径; 然后针对每一跳(1/2/3跳)都执行此裁剪;
step7,路径匹配高置信规则+到达新闻节点→生成假设并早停
因为去beam搜索,所以最后有中止条件,所以设定触发条件:一个是路径完整匹配高置信规则(≥0.6);一个是终点是TextSource(新闻/公告),触发后停止。
然后,生成假设:包含路径+规则+预测方向(UP/DOWN)+新闻证据,生成假设后,该路径不再扩展。
step8,输出所有假设与证据链
输出所有满足条件的假设,每条对应完整推理路径+新闻文本+置信度,然后让LLM去做生成,最终给出答案。
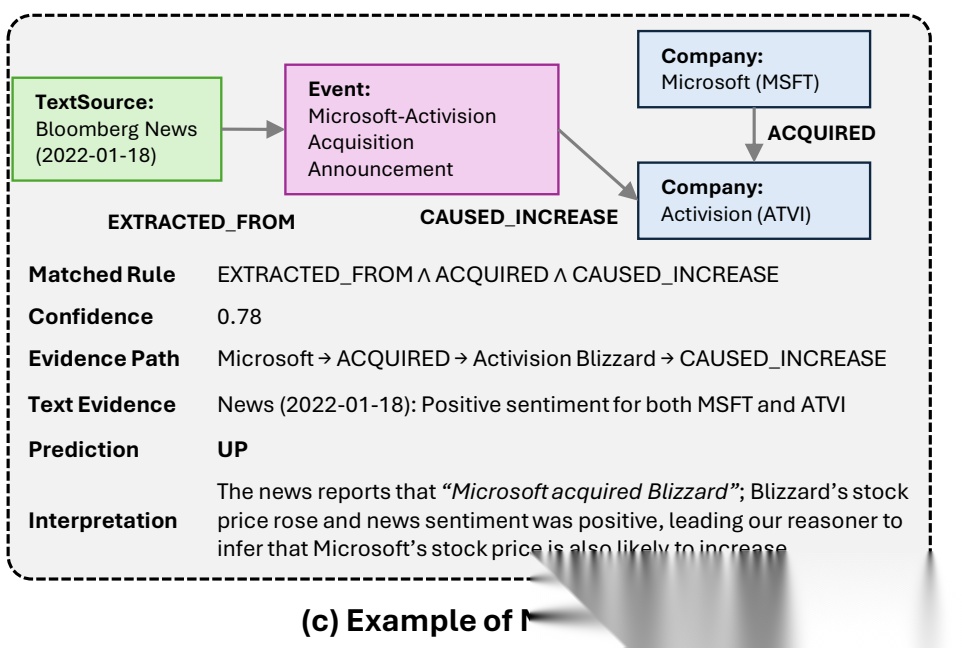
可以用一个简化的例子来说明,例如;特斯拉(TSLA)某天的预测,如下:

步骤1:匹配规则库(Rule Bank Matching),从预设的规则库中,匹配与当前事件逻辑最契合的规则。 匹配结果:命中规则为 PARTNERED(X, Z) ∧ CAUSED_INCREASE(Z, Y) ⇒ predict_direction(X, UP),置信度 conf = 0.74,逻辑在于:若 A 公司(特斯拉)与 B 实体(松下)合作,且 B 实体的行为引发了积极市场效应(EV 电池市场增长),则 A 公司的股价倾向于上涨。
步骤 2:基于图的推理(Graph-Based Reasoning),构建结构化的推理路径,串联事件逻辑,推理路径:特斯拉 → PARTNERED(合作) → 松下 → CAUSED_INCREASE(引发增长) → 电动汽车电池市场 → EXTRACTED_FROM(提取自) → 新闻,这里有个路径验证:规则匹配覆盖率 100%,路径时效性为 1 天(信息较新),且与其他特斯拉相关规则无冗余,最终得出 看涨(UP)的结论。
步骤 3:大模型引导验证(LLM-Guided Validation),将新闻内容与图推理结果输入 LLM,进行逻辑校验与解读,模型输出:最终的预测判定股价看涨(UP)以及推理链支撑,这就是说的可解释性: “特斯拉 - 松下合作” 的结构化关系、“松下扩张引发电池市场增长” 的事件效应、新闻文本的积极 sentiment(情绪)。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献147条内容
已为社区贡献147条内容

所有评论(0)