Seedance 2.0有多离谱?这款动画师能生成角色一致性视频的AI工具你一定要用
作为一个动画师,这两年,我后台被问得最多的一类问题,不是“哪款 AI 生图最好”,也不是“哪款 AI 视频最火”,而是更具体、更扎心的一句:
动画师能生成角色一致性视频的AI工具,到底有没有真的能用的?
因为只要你做过角色动画、漫剧、虚拟人短片,你就会明白,创作里最折磨人的,从来不是没创意,而是——角色根本锁不住。
上一秒还是你精心设定的男主,下一秒切个镜头,脸型变了;
前一帧还是白发红瞳,后一帧头发颜色就开始乱飘;
更别说一开口,声音又像换了个配音演员。
这也是为什么,很多动画师明明已经接受 AI 了,却迟迟不敢把 AI 放进正式工作流。
不是因为不相信未来,而是因为过去踩过太多坑。
但这次,我把即梦 AI 的 Seedance 2.0 真正拉进项目里狠狠干了一轮后,想法变了。
我先把结论放这儿:
如果你正在找动画师能生成角色一致性视频的AI工具,即梦Seedance 2.0 绝对是现在最值得优先试的一款。
不是因为它参数写得漂亮,而是因为它终于开始解决动画师最核心的那两个痛点:人物一致性高,音色一致性高。
一、为什么过去很多 AI 视频工具,动画师根本用不下去?
先说最真实的。
-
角色“变脸”,一切白搭
做角色动画最怕什么? 不是动作差一点,不是特效弱一点,而是主角都不像主角了。
你明明有完整人设:五官、发型、服装、配色、气质。
结果一生成视频,镜头一换,角色像去了隔壁剧组串戏。
这不是“小问题”,这是整条视频直接报废。
-
动作和镜头全靠抽卡
很多老模型最大的问题就是:你只能“许愿”,不能“控制”。
想让角色转身、挥剑、奔跑、跳舞,最后出来什么,全看运气。
-
声音不稳,角色感直接塌了
动画角色为什么能立住?
因为观众记住的不只是脸,还有声音。
但过去很多 AI 视频工具,画面刚有点样子,一开口就露馅。
今天是少年音,明天变御姐音,后天又像旁白机。
对做漫剧、动画短片、虚拟人内容的人来说,这种不稳定太致命了。
二、哪个工具适合哪些动画创作者?重点差异拆解(只讲动画师最在意的)
1、角色一致性:能不能“同一个人演完整段”
-
Runway / Pika: 短镜头还能勉强维持,一旦换场景或镜头,人物就开始“轻微变形”,再长一点直接换脸
-
即梦Seedance 2.0: 明显更“咬参考图”,五官、发型、服装细节更稳定 👉 更接近“同一个角色在不同镜头里演戏”
这也是我为什么敢说它是:动画师能生成角色一致性视频的AI工具里,更接近可用的一档
2、动作控制:是“抽卡”,还是“执行”
-
Runway / Pika: 可以动,但很难“按你想要的动”,尤其复杂动作容易失控
-
即梦Seedance 2.0: 可以直接用参考视频去“带动作” 👉 更像“复刻动作逻辑”,而不是随机生成
对动画师来说,这差别非常关键:你是在导演角色,还是在赌运气
3、音色一致性:很多人忽略,但它决定角色有没有灵魂
这个维度我一定要单独说,因为大多数测评都没认真测。
-
Runway / Pika: 更偏“生成声音”,但角色声音连续性不强
-
即梦Seedance 2.0: 同一角色多条视频里,音色更稳定 音画同步更自然
👉 人物一致性 + 音色一致性同时成立,角色才真正“活起来”
4、 工作流:工具是帮你,还是拖你后腿
-
Runway / Pika: 多数时候需要拆分流程(图、动、音分开处理)
-
即梦Seedance 2.0: 图像 / 视频 / 音频 / 文本可以一起参考
👉 对个人动画师来说,这意味着:少切工具,少折腾,直接出结果
5、生成效率:这不是体验问题,是生产力问题
这一点直接影响“能不能进工作流”。
-
Runway / Pika: 普遍需要排队,生成节奏慢
-
即梦Seedance 2.0: 👉 fast模式不排队 👉 生成速度快 👉 积分消耗少30%-50%
目前国内最快的、唯一不排队的Seedance2.0,就在即梦(Dreamina)。

https://jimeng.jianying.com/
因为这对动画师来说,本质就是:
👉 能不能快速试镜头
👉 能不能连续迭代
三、即梦Seedance 2.0 为什么让我第一次认真推荐?
说白了,因为它不是“会生成视频”,而是开始接近“会做角色视频”。
-
人物一致性真的上来了
这是最核心的价值。
你可以用角色立绘、定妆图、三视图去做参考,让模型尽量锁住人物的:
-
五官比例
-
发型特征
-
服装细节
-
整体画风
它最让我舒服的一点是: 不是只在单帧里像,而是跨镜头也尽量保持同一个人。 这对动画师来说,意义太大了。因为只有角色稳定,剧情、分镜、系列内容才有成立的可能。
-
音色一致性高,角色终于像“同一个人”
很多人讲 AI 视频,只盯画面,我不一样,我特别看重声音。
因为只要你做系列角色内容,你就知道:音色不稳,角色人格就立不住。
即梦Seedance 2.0 在音画配合这一层,给我的感受是:
它开始让“同一个角色的声音连续性”变得可用。
不是每条都换一个感觉,而是更接近同一个人物在不同情绪下说话。
-
多模态参考,终于不是纯靠猜
它支持图像、视频、音频、文本多模态一起参考。
这意味着你可以:
-
用角色图锁人设
-
用参考视频学动作和运镜
-
用音频带节奏和情绪
-
用文本补足分镜意图
这就不是“抽卡式生成”了, 而是开始有点像:你给参考,它替你执行。
-
让 P 视频,开始像 P 图一样直接
这句话以前我不太信,现在我信了一半以上。
因为它确实在把视频制作这件事,往更低门槛的方向拉。
你不用先变成技术型动画工具专家,才能做出结果。
你更像是在用一个懂你意图的工作台,快速把想法跑出来。
如果你是下面这几类人,我觉得都值得试:
-
做角色动画、漫剧短片的动画师
-
做原创 IP、虚拟角色内容的插画师 / 导演
-
做动画分镜验证、角色测试片的团队
-
想把静态设定图快速变成动态视频的个人创作者
尤其是那种平时最怕“角色不稳、声音不稳、镜头不听话”的人,真的会更有体感。
以前我们做动画,最大的问题是“画不动”。
现在的问题变成了——“能不能稳定地一直动下去”。
当人物一致性和音色一致性同时成立时,
动画就不再是单条内容,而是可以持续生产的“角色资产”。
这也是我为什么说,动画师能生成角色一致性视频的AI工具,现在才真正出现。
四、上实操
案例一:连载漫剧片段 —— “跨镜头绝不变脸”
(核心利用:全能参考 + 人物一致性 + 分镜控制)
【项目痛点】
我最近在帮一个IP做短剧化尝试,想把原本的漫画做成“可连载的AI漫剧”。
但只要用过AI的人都知道,这件事最大的坑就是:
👉 同一个主角,在不同镜头里会“变人”。
-
第一镜是少年脸
-
下一镜五官就变了
-
衣服纹理、发型甚至画风都会漂
这种视频,别说连载,连剪都没法剪。
【即梦实操 SOP】
Step 1:准备“角色基因图”
一张标准的人物设定图(正面/全身最佳)

Step 2:做分镜 A(站立+情绪铺垫)
上传角色图 → 作为核心参考
👉 Prompt:
“角色设定图,保持人物五官、发型、服装细节完全一致,橘猫侠,微风吹动衣服,情绪克制,电影感镜头”
【即梦实操 SOP】
Step 1:准备角色设定
统一角色形象(用于视频生成)
[图片]
Step 2:准备台词内容
比如一段剧情对白 / 独白
Step 3:进入 即梦Seedance 2.0
-
上传角色图(锁定人物)
-
输入台词(生成语音)
👉 Prompt:
“@角色图,保持人物一致,角色进行口播对白,语气自然,有情绪变化,声音稳定统一,动画风格,音画同步”
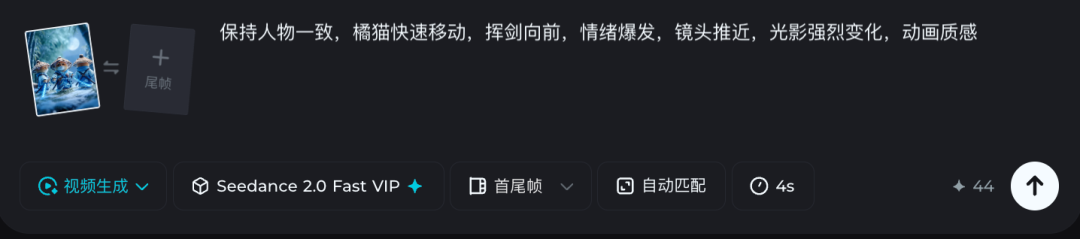
Step 3:做分镜 B(情绪爆发+动作)同一张角色图继续用,不换!
👉 Prompt:
第一个镜头“保持人物一致,橘猫快速移动,挥剑向前,情绪爆发,镜头推近,光影强烈变化,动画质感”

【复盘效果】
这一段做完,我其实只看一个点:
👉 是不是同一个人物。
结果非常干脆:
-
脸没变
-
发型没变
-
衣服细节没乱
-
动作过程中也没有“融化”
甚至在情绪变化的时候,表情是连贯的。
案例二:虚拟角色配音动画 —— “声音也不再换人”
(核心利用:人物一致性 + 音色一致性 + 音画同步)
【项目痛点】
很多动画师其实已经能做出画面了,但卡在一个更隐蔽的问题:
👉 声音不统一。
-
这一条像少女音
-
下一条变成成熟声
-
或者干脆AI感很重
结果就是:
👉 角色“没有灵魂”,观众记不住。
【即梦实操 SOP】
Step 1:准备角色设定
统一角色形象(用于视频生成)

Step 2:准备台词内容
比如一段剧情对白 / 独白
Step 3:进入 即梦Seedance 2.0
-
上传角色图(锁定人物)
-
输入台词(生成语音)
👉 Prompt:
“@角色图,保持人物一致,角色进行口播对白,语气自然,有情绪变化,声音稳定统一,动画风格,音画同步”

【复盘效果】
这一段我反复测了几次,重点只看两件事:
① 人物一致性
角色形象在不同视频里是统一的
👉 可以连续做剧情
② 音色一致性(重点)
声音是“同一个人”
-
不漂
-
不换
-
情绪有变化但底色一致
五、最打动我的,不只是效果,还有效率
这一点必须单独说。
做动画、做角色内容的人都知道,灵感这种东西,是最怕被进度条磨没的。
而即梦这边现在有个很现实的优势:
即梦AI上线了 Seedance2.0 fast 模式,目前不排队,生成速度很快,消耗积分少 30%-50%,又快又便宜!目前国内最快的、唯一不排队的 Seedance2.0,就在即梦(Dreamina)。
这意味着什么?
意味着你不是今天提一个镜头,明天才看到结果。
而是可以更快试错、更快改镜头、更快确认角色状态。
对于创作者来说,这种效率不是附加值,是护城河。
六、一句话总结:它终于开始配得上“生产力”这三个字了
如果你问我,动画师能生成角色一致性视频的AI工具,到底现在哪款最值得先上手?
我的回答会很直接:
先试即梦 AI 的 Seedance 2.0(https://jimeng.jianying.com/)
它不一定代表“从此再也没有后期”,
但它已经非常明确地向前走了一大步:
-
人物一致性高
-
音色一致性高
-
多模态参考更可控
-
出片效率更高
-
更适合真正进入动画创作流程
对于动画师来说,这种工具的意义,不只是省时间,
而是终于让“我脑子里的角色,能稳定地活在视频里”这件事,开始变得现实。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)