AI 编程 Harness 框架深度拆解(非常详细),6 大框架从入门到精通,收藏这一篇就够了!
AI 会写,不等于 AI 能稳定交付。
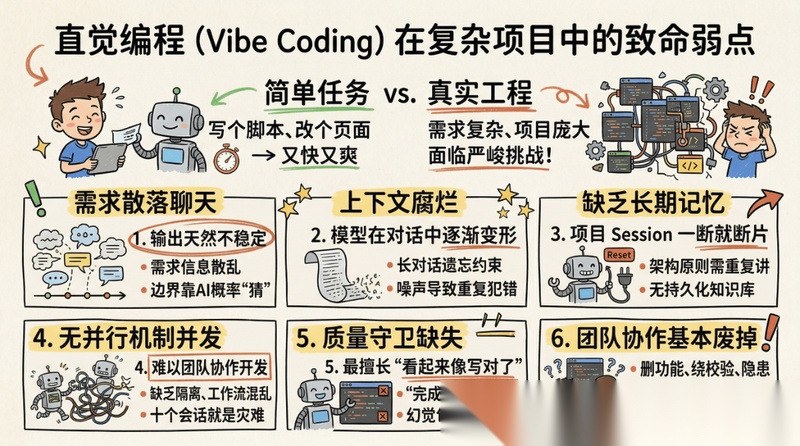
前段时间我们都在说 Vibe Coding,大家都知道是氛围编程的意思,但是现在也有叫“直觉编程”。什么叫直觉编程,就是完全不用管其它的,想到什么就做什么,主打一个靠直觉写代码。
你要只是让它写个脚本、补个函数、改个页面,那没问题,当然是又快又爽。
但一旦任务进入需求复杂、代码项目庞大、多人协作、分支并行、需要质量把关的真实工程。那么,Vibe Coding 这种方法,很快就会露出底牌:
- 需求只存在于聊天里,输出天然不稳定。
当需求、边界、设计决策都散落在对话记录里,AI 本质上只能靠概率去“猜”你真正想要什么。同一句话换个会话、换个上下文,结果就可能完全不同。 - 上下文腐烂崩坏,模型会在长对话中逐渐变形。
历史信息越多、无效噪音越重、窗口越接近上限,AI 越容易忘约束、重复犯错、误判因果。很多时候不是模型降智,而是上下文已经坏了。 - 普通会话没有长期记忆,项目一跨 session 就像断片。
你今天讲清楚的架构原则、昨天确认的约束、上轮讨论过的边界,下一次新会话基本上就要从头再讲一遍,不然就看 AI 自我发挥了。没有历史知识库、执行状态、Spec、任务文档、工作日志这些持久化资产,AI 就很难真正“接班”。 - 没有并行与隔离机制,AI 很难像团队一样协作。
一个会话能盯,两个会话还能勉强切换,十个会话并发开发基本就是灾难。没有分支隔离、worktree、角色分工和统一回收机制,多代理只会把混乱放大。 - 没有质量守卫,AI 最擅长的是“看起来像写对了”。
能运行,不代表对;有测试,不代表测到了关键路径;自称“已完成”,也不代表没有偷偷删功能、绕校验、留隐患。没有验证闭环,幻觉就会被包装成进度。 - 基本无法团队协作,大家用着自己的方式在“抽卡”
谁来解释这段代码为什么这么写?谁来判断这个依赖是不是该引?谁来保证风格统一、测试齐全、改动可回溯?一旦这些都没有,团队拿到的就不是资产,而是一堆需要共同供养的随机产物。
 这就是为什么前段时间总有人质疑 AI 编码怎么敢在生产上实际使用的原因,也正是现在 Harness 开始变得越来越重要的原因。
这就是为什么前段时间总有人质疑 AI 编码怎么敢在生产上实际使用的原因,也正是现在 Harness 开始变得越来越重要的原因。
在 AI 编程语境里,你可以把 Harness 理解成一套规范好的“智能体脚手架”:它不是单个 Prompt,也不只是某个插件,而是一套围绕 AI 助手构建的工程化运行环境与规则系统。它会把需求、上下文、技能、验证、记忆、并行协作这些原本散落在聊天中的东西,沉淀成可复用的结构。
所以,Harness 的价值并不是“让 AI 更会聊天”,而是让 AI 在复杂工程里变得更可控、更可验证、更可规模化。
Harness 的定义相信大家也看得不少了,这里也就是稍微给一些还不清楚的朋友科普一下。今天我想讨论的,不是继续抽象地解释 Harness 是什么,而是更具体的问题:当市面上出现了 OpenSpec、GSD、OMC、ECC、Trellis、Superpowers 这些不同路线的工程化框架之后,我们到底该怎么理解它们、比较它们,并把它们搭成一套真正可用的体系?
这篇文章的重点,就在这里。
6 个代表性 Harness 路线拆解:从单层补位到体系化搭建
先说结论:这 6 个框架并不是同一种东西。
如果把它们都笼统地称为“AI 编程框架”,我感觉我的文章很容易写偏。我是按照我理解,把它们看作了 Harness 不同层级上的能力模块。
我也没有试图穷尽所有 Harness 项目,也不想把每个框架代码详细解释念给大家听。毕竟我还是那句话,相比于在纷杂的框架中做选择,我希望大家更关注 Harness 思想本身。所以我选择了开源社区里较有代表性的 6 条路线,看看它们分别在补哪一层。
而为了更方便理解,我这里按一个更接近真实采用路径的顺序来写:从单层补位到体系化搭建。
也就是:OpenSpec → Superpowers → GSD → OMC → ECC → Trellis
这个顺序不是统一排行榜,更像是一条从局部补强走向体系化建设的采用路径。
先看一张总表
| 框架 | 更接近哪一层 | 核心关注点 | 更适合谁 |
|---|---|---|---|
| OpenSpec | 规范层 | 先把需求、设计、任务写清楚 | 需要先对齐再开工的个人/团队 |
| Superpowers | 方法论与技能层 | 把 TDD、调试、review、worktree 等工程习惯变成默认动作 | 重视质量纪律和流程约束的开发者 |
| Get Shit Done | 上下文工程 + 阶段化执行层 | 解决 context rot,把复杂任务拆成原子计划 | 长任务、复杂仓库、重构场景 |
| Oh My ClaudeCode | 多代理编排层 | 围绕 Claude Code 做 team-first orchestration | Claude Code 重度用户、并行开发场景 |
| Everything Claude Code | 增强层 | 用 skills、instincts、memory、安全、验证补全 Harness 能力 | 想把 AI workflow 长期工程化的人 |
| Trellis | 结构层 | 用 specs / tasks / workspace 组织跨平台工作流和项目记忆 | 多工具团队、长期协作项目 |
这张表先看功能定位;至于它们在覆盖面、重量和体系化程度上的差异,后面会在落地建议里展开。
OpenSpec:先把“要做什么”写清楚
 如果只用一句话概括 OpenSpec,那就是:
如果只用一句话概括 OpenSpec,那就是:
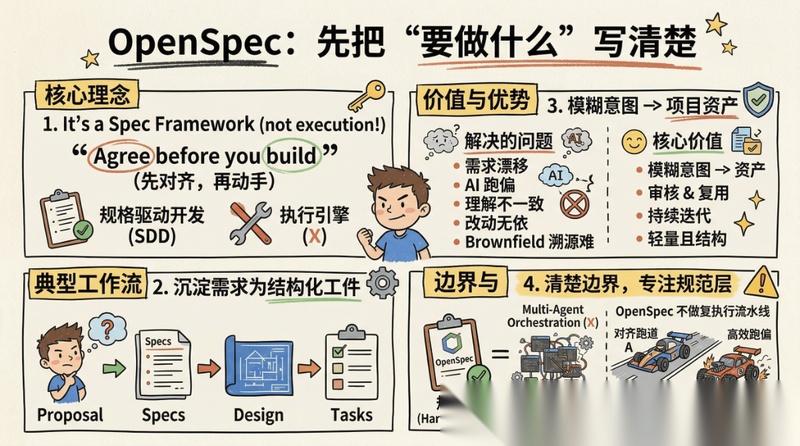
它是一个 spec framework,而不是一个执行引擎。
OpenSpec 在 README 里的定位非常清晰:
它强调的是 SDD(规格驱动开发),核心主张是:
Agree before you build
也就是:先对齐,再动手。
它的典型工作流,是把一个需求沉淀成一组结构化工件:
- proposal
- specs
- design
- tasks
这样做的价值非常直接:把原本只存在于聊天记录里的模糊意图,变成可以被审核、被复用、被持续迭代的项目资产。
它最适合解决的问题,是:
- 需求经常漂
- AI 老跑偏
- 团队对边界理解不一致
- 改动缺少结构化依据
- Brownfield 项目里聊天记录越来越难追溯
它的长处,在于轻量但不失结构,而且对现有项目也比较友好,不是那种只能从零开始的“新项目模板”。
但也要说清楚边界:OpenSpec 不主打多代理编排,不主打上下文压缩,不主打复杂执行流水线。
它解决的是最基础、也最常被忽视的一层:先把需求和设计讲清楚。
换句话说,OpenSpec 更像 Harness 里的规范层。
如果需求都还没固定下来,后面再强的 orchestration 也只是在更高效地跑偏。
Superpowers:把工程方法论做成自动触发的技能
 Superpowers 的定位也非常清楚,它不是把自己描述成“完整工程平台”,而是:
Superpowers 的定位也非常清楚,它不是把自己描述成“完整工程平台”,而是:
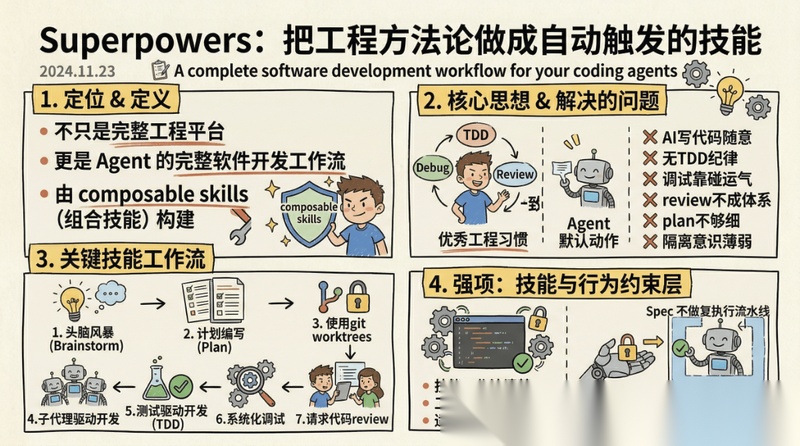
A complete software development workflow for your coding agents, built on composable skills
关键词是 composable skills,组合技能。
它围绕 skills 组织工作流,从:
- 头脑风暴
- 计划编写
- 使用git worktrees
- 子代理驱动开发
- 测试驱动开发
- 系统化调试
- 请求代码review
一路往下铺开。
它最重要的思想不是“结构有多宏大”,而是:优秀工程师的工作方法,能不能被做成 agent 的默认动作。
它最适合解决的问题是:
- AI 写代码太随意
- 没有 TDD 纪律
- 调试靠碰运气
- review 不成体系
- plan 不够细
- 分支与 worktree 隔离意识薄弱
它的强项也非常明确:技能工作流清楚,工程纪律导向很强,适合作为 AI 行为约束层。
它不是在做统一规格平台,也不是在做跨平台任务骨架,更不是项目记忆系统。它真正擅长的是:把 brainstorming、plan、TDD、debugging、review、worktree 这些优秀工程习惯,做成 agent 的默认行为。
所以,Superpowers 更像 Harness 里的技能与行为约束层。
如果你担心 AI “会写,但写得不像工程师”,它特别有价值。
Get Shit Done:把复杂任务拆进干净上下文里
 GSD 的定位也很鲜明,它在 README 里几乎是直接把卖点写在脸上:
GSD 的定位也很鲜明,它在 README 里几乎是直接把卖点写在脸上:
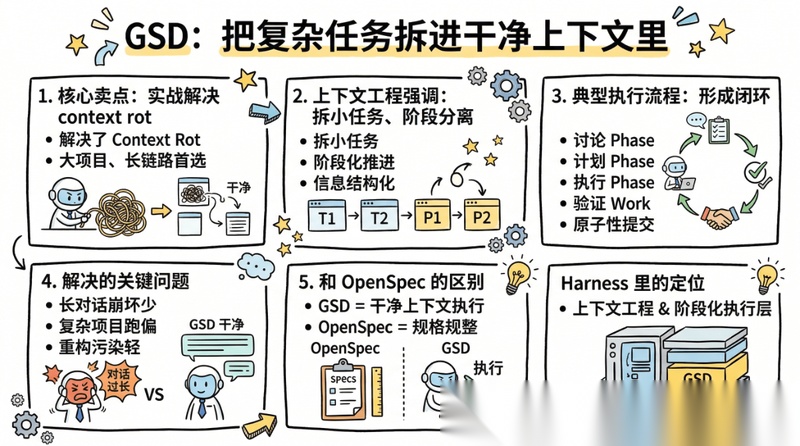
Solves context rot
“解决上下文腐烂问题”,相比很多“概念上很完整”的框架,GSD 有一种很强的实战气质。
它不是强调企业流程表演,而是强调:
- 上下文工程
- 阶段化推进
- 刷新上下文
- wave执行
- 原子性提交
- 状态管理
它的典型工作流是:
new-projectdiscuss-phaseplan-phaseexecute-phaseverify-work
这套流程的关键,不是“看起来完整”,而是为了防止复杂任务在长对话中失真。
它最适合解决的问题,是:
- 对话一长就崩
- 项目越复杂越容易偏
- 大仓库重构时上下文污染严重
- 长链路任务需要高稳定推进
- 想让 AI 真正跑完整个 phase,而不是只出点子
它最强的地方在三个方面:
- 上下文工程意识非常强:默认承认大模型在长会话里会退化,所以必须拆小任务、阶段分离、信息结构化。
- 执行流程完整:从讨论、研究、计划、执行到验证,形成闭环。
- 工程痕迹清楚:原子提交、阶段文档、验证结果,都让推进过程有回溯性。
和 OpenSpec 的差异也很好理解:OpenSpec 更像“先把规格讲清楚”;GSD 更像“把复杂任务拆进干净上下文里执行”。
所以,GSD 更像 Harness 里的上下文工程与阶段化执行层。
如果你最痛的是 context rot,它比很多“会聊天的 agent 套件”更直击问题本质。
Oh My ClaudeCode:把 Claude Code 从单助手变成团队系统
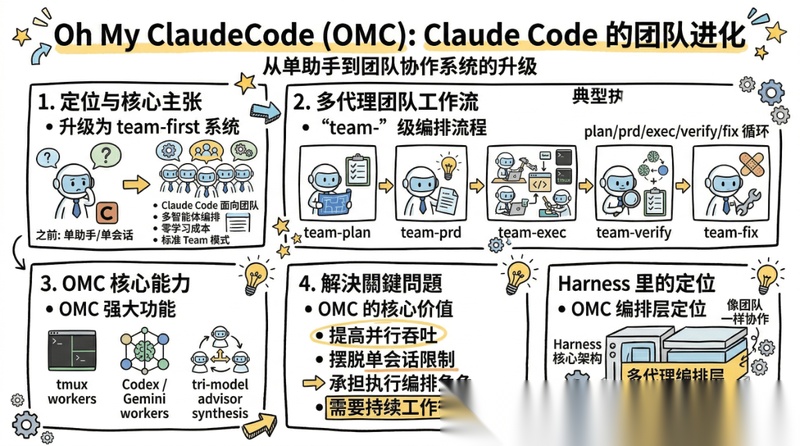 如果说 OpenSpec 解决“别乱开始”,GSD 解决“别把上下文聊烂”,那 OMC 主要解决的是另一类问题:
如果说 OpenSpec 解决“别乱开始”,GSD 解决“别把上下文聊烂”,那 OMC 主要解决的是另一类问题:
怎么把 Claude Code 升级成 team-first 的多代理系统。
它的 README 写得很直接:
- 面向Claude Code的多智能体编排
- 以团队为核心的协同调度
- 零学习成本
- 标准编排方式是 Team 模式
它不是泛泛而谈“agentic coding 理念”,而是明确围绕 Claude Code 提供一套团队式编排工作流。
比如它的团队工作流:
team-planteam-prdteam-execteam-verifyteam-fix
再加上 tmux workers、Codex / Gemini CLI workers、tri-model advisor synthesis 等能力,目的都很明确:让多个 agent 以结构化方式协同工作。
它最适合解决的问题是:
- 想提高并行吞吐
- 不满足于单会话、单 agent 使用方式
- 希望 Claude Code 真正承担执行编排角色
- 需要 plan / exec / verify / fix 的持续循环
它的长处,在于多代理编排是主线而不是附属功能,对 Claude Code 深度用户非常友好,而且可以把外部模型纳入协作。
但边界也很清楚:OMC 的重点不是通用 spec 资产体系,也不是跨平台统一结构层,更不是 repo 内长期任务资产组织。
它明显偏向:Claude Code 场景下的以团队为核心的协同编排。
所以,OMC 更像 Harness 里的多代理编排层。
如果你想解决的是“怎么让多个 agent 像团队一样协作”,它的定位非常清楚。
Everything Claude Code:给 Harness 再补一层“性能增强系统”
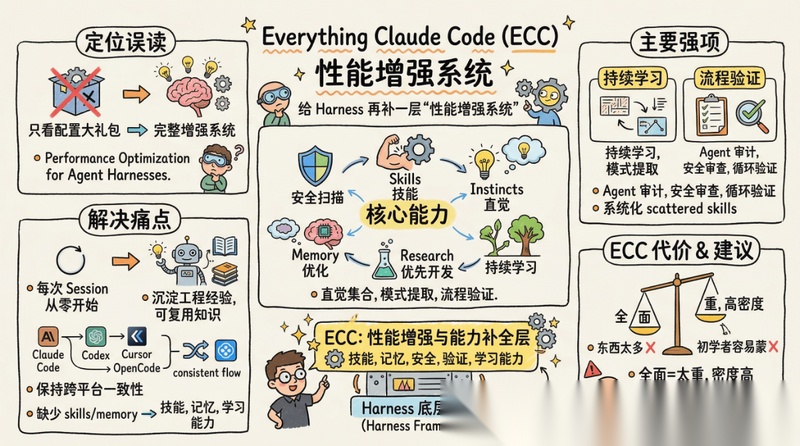 ECC 是这几个项目里最容易被误读的一个。
ECC 是这几个项目里最容易被误读的一个。
很多人第一次看它,会以为它只是个 Claude Code 配置大礼包。但按 README 的自我描述,它其实更想表达的是:
The performance optimization system for AI agent harnesses
这句话非常关键。
和上面的不一样,ECC 不是只把自己定义成“一个 IDE 插件”,而是定义成一整套围绕 AI harness 的增强系统,并且把这些能力系统化:
- skills
- instincts
- memory 优化
- 持续学习
- 安全扫描
- research 优先开发
它最适合解决的问题是:
- 工程经验没法沉淀
- 每次 session 都像从零开始
- 缺少 skills / instincts 这样的可复用知识
- 缺少 hooks、rules、安全、验证闭环
- 想在 Claude Code、Codex、Cursor、OpenCode 之间保持一定一致性
它的长处非常明显:拥有直觉集合、持续学习、模式提取,来强调持续学习;Agent审计、安全审查、循环验证来执行流程验证;它努力把 AI 工程系统里那些“散的、弱的、靠人记的能力进行”系统化,目标是一整套 Harness 框架体系。
它的代价也很明显:全面,往往意味着太重。
另外,ECC 的信息密度很高,对初学者来说容易会有“东西太多”的感觉,也更建议进阶阶段选择它来进行学习。
因为更多的时候还是有自己项目的知识库,所以它不是替代底层结构,而是给底层结构补上“技能、记忆、安全、验证、学习”这些能力。 所以,对我来说,与其说它是一整套 Harness 体系,我觉得它更像 Harness 里的性能增强与能力补全层。
Trellis:最后单独说,因为它更像工作流骨架
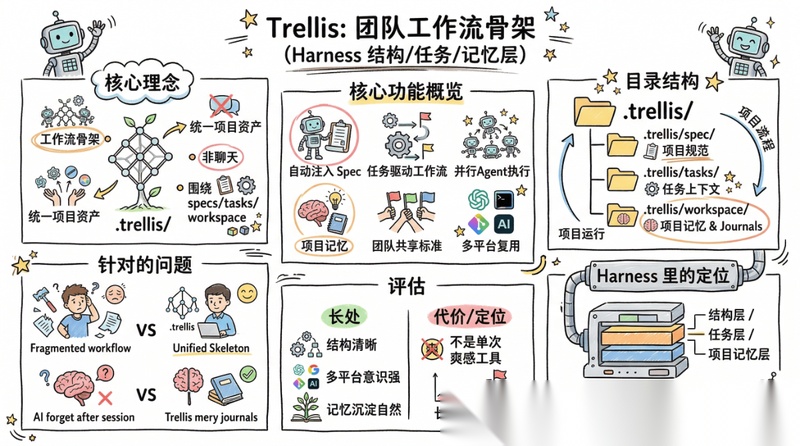 我把 Trellis 放到最后,是因为它和前面几个的模式又有不同。(当然也因为是社区内的佬做的,所以稍微有一些私心)
我把 Trellis 放到最后,是因为它和前面几个的模式又有不同。(当然也因为是社区内的佬做的,所以稍微有一些私心)
Trellis 的关键词非常鲜明:
- 自动注入 Spec
- 任务驱动工作流
- 并行Agent执行
- 项目记忆
- 团队共享标准
- 多平台复用
它最重要的,不是某个单一命令有多酷,而是它试图用 .trellis/ 这套结构,把项目规范、任务上下文和工作连续性统一起来。
核心目录也非常能说明问题:
.trellis/spec/.trellis/tasks/.trellis/workspace/
这说明 Trellis 更关注的是:
如何让项目围绕结构化 specs / tasks / workspace 运行,而不是围绕某一次聊天运行。
它最适合解决的问题,是:
- 团队不是只用一个 AI 工具
- 工作流在不同平台间碎片化
- 任务上下文和项目记忆难以沉淀
- 团队标准难共享
- 想把个人经验和团队资产都收进 repo
它的长处在于:
- 结构非常清楚:spec、task、workspace 分层明确;
- 多平台意识强:不把能力绑定死在某个单一平台;
- 项目记忆沉淀自然:workspace journals 和 task context,本质上就是在补 AI 跨会话“失忆”的问题。
但也正因为如此,它不是那种“单次执行爽感很强”的工具。
它更像一个长期结构化沉淀框架。
所以,我更愿意把 Trellis 看成 Harness 里的结构层、任务层和项目记忆层。
如果你的问题不是“某个 agent 不够强”,而是“团队 workflow 没有统一骨架”,那 Trellis 的价值会非常高。
把这 6 个框架放在一起看,真正差异是什么?
在我看来,它们都有侧重点,都属于 Harness 思想的一种体现。如果非要一句话概括它们的分工,我会这样说:
- OpenSpec 负责:先把“要做什么”说清楚
- Superpowers 负责:让 agent 默认按工程纪律工作
- GSD 负责:把复杂任务拆进干净上下文中执行
- OMC 负责:把 Claude Code 组织成团队式执行系统
- ECC 负责:给 Harness 补技能、记忆、安全、验证和学习能力
- Trellis 负责:把 specs、tasks、workspace 变成统一工作流骨架
如果再把它们按定位压缩一句,可以更清楚地看出差异:
- OpenSpec、Superpowers、GSD 则更偏向单层补位:分别聚焦规范、工程技能、上下文与阶段执行
- OMC、ECC、Trellis 更偏体系型方案,只是各自覆盖的主轴不同
- ECC 更像在补 skills、memory、安全、验证、学习等能力,覆盖面更广,也更偏体系型增强系统
- Trellis 在 specs / tasks / workspace / project memory 上更完整,更像长期工作流骨架
- OMC 在 Claude Code 的 team-first orchestration 上更像一套成体系的编排套件
 我更建议把 Harness 理解成一个分层搭建、按缺口补位的问题,而不是单工具选择题。
我更建议把 Harness 理解成一个分层搭建、按缺口补位的问题,而不是单工具选择题。
总有人问我:“Harness 用哪个框架最强、最全面?”
但真实工程里,这个问题本身并不够准确。
判断一个 Harness 体系架构,至少要同时看三个维度:
- 覆盖面:它补了多少层能力,是否同时涉及 spec、skills、memory、verification、orchestration、workspace 等多个方面
- 重量:它引入的流程、文件体系、学习成本、执行纪律和生态绑定有多高
- 定位:它到底是在补某一层,还是想把自己做成 harness 整体方向这样的体系型方案
这三个维度经常相关,但不是一回事。
有些框架覆盖面更广,也更像完整 Harness;但这通常也意味着它更重。
有些框架只补一层,却因为足够轻、足够稳,反而更适合作为第一步。
而且更重要的是:更像 Harness,不等于每一层都更强;更重,也不等于能替代所有层。
这也意味着,一个团队真正成熟之后,更常见的是在问:
“我们在哪层?现在最缺的又是哪一层?”
落地建议:别把 Harness 当成“选一个最强工具”的问题
所以真实采用里,大家最终往往不需要去做“6 选 1”,而是在做三步判断:
- 先判断自己最缺哪一层
- 再判断这一层要用多重的方案来补
- 最后再决定哪些层适合组合搭配
换句话说,这 6 个框架很多时候更像是可分层组合的模块:
有些负责把某一层打深,有些负责把闭环搭起来。真正成熟的采用方式,往往不是寻找一个“大一统答案”,而是找到属于你最合适的组合。
框架使用:更稳的采用路径
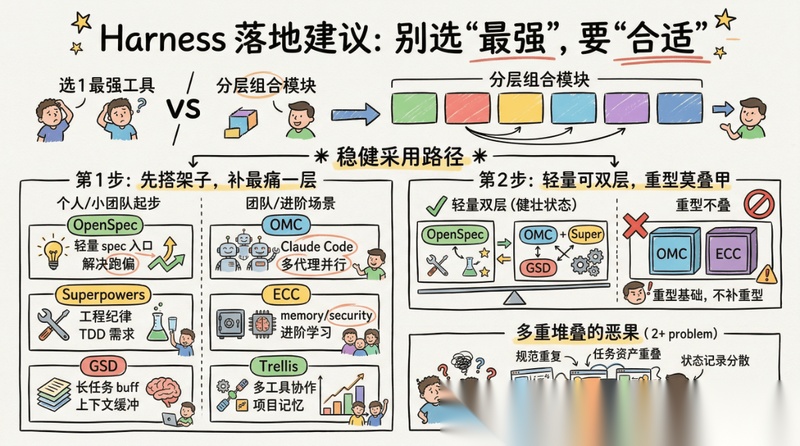 先说明一点:框架当然是可以搭配,但这不代表你应该一上来就像叠甲一样哐哐的叠很多层。
先说明一点:框架当然是可以搭配,但这不代表你应该一上来就像叠甲一样哐哐的叠很多层。
真实世界里更常见的问题,不是“框架太少”,而是:
- 主骨架不清
- 文档事实来源重复
- 规则互相打架
- 控制面膨胀快过执行面
所以,比“推荐几套套餐”更稳的写法,其实是:可以基础架构搭建的时候选择成本最高的一层框架,实际使用中再考虑实在有需要的话补第二层进行组合
- 第一步:搭建完架子后补最痛的一层
对大多数个人开发者和小团队来说,起步往往只需要一个主框架。
-
缺少 memory / security / verification,进阶学习 → ECC
-
多工具协作、项目记忆混乱,个人使用优先 → Trellis
-
需求总跑偏,轻量 spec 入口 → OpenSpec
-
工程纪律太松,TDD 需求 → Superpowers
-
长任务容易崩,上下文buff → GSD
-
主要使用Claude Code,且明显需要多代理并行 → OMC
-
更偏向于只用框架实现 harness 整体结构搭建
- 轻量框架可以考虑双层组合,重型框架就建议不要再叠甲了
当第一层已经跑稳,再补第二层,通常是最健康、也最常见的状态。
比如:
- OpenSpec + Superpowers:先解决“别跑偏”,再解决“别乱写”
- OpenSpec + GSD:前者固定规格,后者解决 context rot 和阶段化执行
- OMC + Superpowers:前者负责编排,后者补工程纪律
如果没有明确主次关系,2个以上框架一起上,就很容易出现:
- 规范重复
- 任务资产重叠
- 状态记录分散
- 事实来源不一致
最后把系统本身搞得比业务还复杂。
来自一线实战的几个校正:Harness 真正难的不是“能不能跑”,而是“能不能稳定跑久”
如果说前面的 6 个框架横评,回答的是“它们各自补哪一层”,那么一线实践真正补上的,是另一组更残酷的问题:
- 能不能连续跑几个小时甚至跨天?
- 一旦任务变复杂,产出到底是代码在增长,还是文档和协调成本在增长?
- 会话一断、上下文一压缩,系统还能不能接着干?
- 多个 agent 方式同时上场,到底是在协作,还是在制造更大的回收成本?
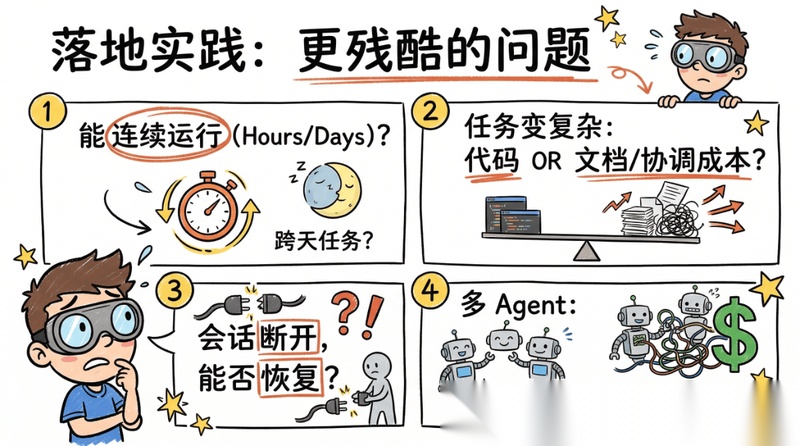 从社区实战反馈里,至少能提炼出几条很值得写进文章的校正结论。
从社区实战反馈里,至少能提炼出几条很值得写进文章的校正结论。
横评成本极高,结论天然是“短保”的
在真实世界里,Harness 的比较很难靠一次 Demo、一次 benchmark 或框架代码读后感完成。
因为一旦进入长任务、复杂仓库、大重构场景,消耗的不只是 token,更是大量的观察、回收、纠偏和复盘成本。
这意味着一个很现实的判断标准:
Harness 不是“看起来功能最全的赢”,而是“谁能在真实工程里稳定跑更久、出问题后更容易接班和纠偏”。
也正因为如此,团队在选择框架时,往往不该追求“一次选定终局方案”,而更适合用小步试运行、逐层替换、持续复盘的方法来做。
多代理不等于真正 hands-off,最怕的是“控制面膨胀”
很多人,包括现在很多的团队领导班子一听到子 Agent,Agent Team,多 Agent 这种就会以为:Agent 越多,分工越细,吞吐自然越高。
但实战里经常出现另一种结果:
- 设计文档越来越多
- 进度记录越来越多
- 协调信息越来越多
- 真正落到代码上的产出,反而没有想象中高
也就是说,多代理系统最常见的问题,不是不会干活,而是控制面膨胀得太快。
如果任务拆分、责任边界、回收机制、验证节点没有设计好,多代理很容易变成一种“看起来很忙”的系统:
日志很多、讨论很多、计划很多,但实际交付并没有同步增长。
这也是为什么在复杂任务里,衡量 Harness 不能只看“能不能并行”,还要看:
- 控制面和执行面的比例是否健康
- 产出是否真的转化为代码与验证结果
- 回收成本是否可控
上下文压缩与交接能力,往往比单次写码能力更关键
在短会话里,大家容易关注“谁单次写得更快、更像样”。
但一旦任务进入长时间运行,真正决定系统稳定性的,往往变成了另外几件事:
- 能不能把长历史压缩成干净摘要
- 能不能让决策层只看到高密度信息
- 当前会话失效后,能不能通过交接文档顺利续跑
- 新 session 接手时,能不能快速恢复关键约束
换句话说,长任务不是在比谁更会写,而是在比谁更不容易失忆。
这点也正好解释了为什么很多框架最终都会走向:
STATE.mdROADMAP.md- task 文档
- phase 文档
- 验证报告
- 工作区日志
这些东西表面看是“文档负担”,本质上却是在为长期运行提供记忆与交接能力。
超级任务最好拆成 task-centered workflow,而不是一次性许愿
社区里一个很典型的经验是:
当你把多个独立但彼此又有耦合的大计划,一次性塞给 agent 时,它并不会线性变强,反而更可能在复杂度里失真。
原因并不神秘:
- 目标太多,优先级会混乱
- 子任务之间相互污染上下文
- 验证边界变模糊
- 一旦跑偏,回滚和纠偏成本急剧上升
所以,真正更稳的做法通常不是“给一个更大的总目标”,而是:
- 先写清楚 spec
- 再拆成 task
- 再按 phase 推进
- 每一段都留验证和交接工件
也就是说,task-centered workflow 不是形式主义,而是防止 AI 把复杂任务做烂的必要结构。
决策层和执行层最好隔离,别让“最贵的大脑”泡在细节里
另一个非常有价值的一线经验,是把模型和工具按层分工:
- 高阶模型负责架构判断、偏差识别、方向决策
- 执行型工具负责跨文件修改、批量实现、重复性工作
- 压缩/总结型模型负责清洗历史、提炼大纲、生成交接材料
这个思路的核心,不是“多模型混搭更炫”,而是:不要让决策层淹没在代码细节里。
因为高阶模型最值钱的地方,往往不是写样板代码,而是:
- 识别架构问题
- 判断实现是否偏离设计
- 从现象里提炼本质
- 决定下一步该怎么推进
如果让它长期沉在 log、样板、局部补丁里,本质上是在浪费推理预算。
这个地方也是我觉得多 Agent 更有意义的地方,阶段的天然隔离也不会造成第二点的问题,让其他的代理来进行反馈,可以有效避免 AI“觉得自己的架构设计/代码是最好的”的自我良好问题。
稍微想多说几句的最后
写到这里,如果一定要让我说一个我自己的结论,那就是:Harness 这件事,框架在精不在多;选自己真正需要的,比无脑叠甲重要得多。
我看到的,现在对于 Harness 体系的搭建,分为三类人: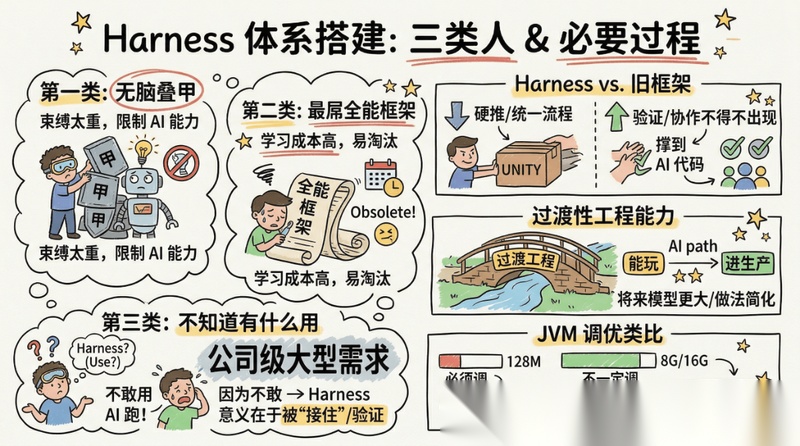
- 第一类:无脑叠甲,多层叠加短板层级
AI 的魅力在于给它更多的发挥空间,太过重的束缚就算框架自己不打架,也不一定能提升整体能力,更多的可能是限制了你 AI 本身应有的能力。 - 第二类:觉得应该找一个最屌的全能框架
和上面一样,其实问题就是过重,很多时候可能没有太多的必要,且学习成本过高,在 AI 快速发展的时代,可能没等你来得及完全摸清就过时了。(笑) - 第三类:觉得不需要Harness,不知道有什么用,能带来什么收益,只是因为公司在推所以才去了解
听到这个问题,我脑子里只蹦出来一句话:那你敢在公司级项目里真正放 AI Coding 的代码跑大型需求吗?如果答案是不敢,那 Harness 的意义其实就已经很清楚了。
这也是为什么我觉得,Harness 和以前工程时代“公司要求统一推一个框架”这件事,还是有本质区别的。
以前很多框架推进,往往是领导要求、公司要求,又或者技术栈要求。
或许就根本感知不到收益,但你不得不做,很多时候主打的就是一个“硬推”。
但 Harness 不太一样。它不是为了统一而统一,不是为了流程而流程,而是 AI 编程进入真实工程之后,为了让它能被接住、被验证、被接班、被团队协作,不得不出现的一步。
它更像一种时代演进中的过渡性工程能力。
当然,我也相信:在不久的未来模型上下文真的足够大,比如一个 G,今天 Harness 里的很多做法,可能会被简化,甚至有些部分会被系统底层直接吃掉。
但我并不觉得这意味着它现在不重要。
它更像早些年的 JVM 调优:以前服务器资源紧、运行环境弱,128M 的内存你不调就是不行;现在硬件好了、平台成熟了,动则 8 个 G,16 个 G 的服务器,很多时候都不需要手动调优了。
可在那个阶段里,它依然是你不得不做的一步。
我觉得今天的 Harness,某种程度上也有点这个味道。
它未必永远都以今天这套形式存在,但在当前这个阶段,它就是 AI Coding 从“能玩”走向“能进生产”的必要过程。
而且我更愿意把 Harness 看成一种思想,而不是一套固定模板。
核心不是“先把所有东西装满”,而是:在使用中发现缺口,再把缺口补起来。
这个思想哪怕放到未来,我觉得也不会过时。
因为哪怕有一天上下文真的大到夸张,很多流程真的可以减少,项目知识库这件事依然不会消失。
比如你让 AI 去实现一个登录系统,如果你不告诉它:公司内部已经有统一登录接口、鉴权网关、用户体系和接入规范,那它大概率还是会按网上最常见的“普通登录系统”去做。
这当然只是个很简单的例子,但已经足够说明问题:AI 再强,也不会天然知道你这个项目的“组织现实”和“历史约束”。
而 Harness 的一部分价值,恰恰就是把这些东西沉淀下来,让 AI 不要每次都从互联网默认答案开始猜。
当然,落到公司和团队里,前段时间有个群友在群里问了一个我觉得很现实的问题:
公司在推 Harness,那 Harness 怎么量化?怎么向上汇报?
毕竟不是你自己说“我们团队 AI Coding 很强”,它就真的强了。
对于个人来说,爽感和效率感可能就够了;
但对有些公司来说,真正的痛点往往不是“能不能用”,而是:怎么量化收益、怎么说明流程投入是值得的、怎么把这些东西讲成老板听得懂、管理层愿意买单的结果。
某种意义上说,至少在这个阶段,“向老板汇报”可能才是 Harness 落地里最现实的痛点之一。
都在摸石头过河。
我也很想知道答案。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献124条内容
已为社区贡献124条内容

所有评论(0)