(学习记录)AlexNet在CIFAR-10上的图像分类
本文记录了在CIFAR-10数据集上学习AlexNet复现的过程,包括论文阅读(即总结摘记)、代码复现(代码阅读、在CIFAR-10上的适配、完整代码、未来改进)两部分。本文仅为跑通AlexNet而写,我只有一块RTX2050,为效率选择CIFAR-10数据集,不追求CIFAR-10数据集上最好的正确率。学习论文为ImageNet Classification with Deep Convolutional Neural Networks,学习原代码来自github项目alexnet-pytorch。
读论文之前
-
ImageNet 数据集有 120 万张高分辨率图片(120GB+)。可用简化版本,重点关注模型架构。可在 CIFAR-10 上跑通,想更还原可下载 Tiny-ImageNet。
-
2012 年的 GTX 580 只有 3GB 显存,作者将网络拆成两半跑在两块显卡上,现在可忽略双路并行,直接写成单路网络。
-
注意:LRN(Local Response Normalization)已被 BN(Batch Normalization)取代; Overlapping Pooling(步长小于核尺寸)是防止过拟合的小技巧。
-
手动推导每一层卷积后 Feature Map 的尺寸变化,权重初始化和遮挡要显式设置。
论文阅读
摘要
构建了具有 60 万参数、65 万神经元的网络的5 个卷积层(有些带最大池化层)+ 3 个全连接层 + 1000 分类 Softmax组成的神经网络,使用非饱和神经元与 GPU 加速训练,全连接层使用 Dropout 防止过拟合,在 ImageNet 上取得突破性成果。
引言
为取得比机器学习更好的结果,可收集更大的数据集、学习更强大的模型、用更好的技术防止过拟合。ImageNet 有 1500 万带标签的高分辨率图像,涵盖 2 万类别。需要有强大学习能力和大量先验知识的模型。CNN 适合此任务,它可通过约束深度和宽度调整容量,且对图像统计平稳性和像素依赖的局部性做出了强而正确的假设。GPU 配合二维卷积实现,有助于训练大型 CNN。
贡献:优化的2D卷积的GPU配置以及其他 CNN 训练操作,包含新特点,提升表现、缩短时间;使用防止过拟合技术;最终在双 GTX 580 3GB GPU 上需训练 5-6 天。
数据集
ILSVRC 使用 ImageNet 子集,包含 1000 类别,每类约 1000 张图像:
-
训练图像:约 120 万张
-
验证图像:5 万张
-
测试图像:15 万张
常用错误率指标:
-
Top-5 错误率:正确标签不在模型认为最可能的前五个标签中
-
Top-1 错误率:一般错误率
预处理:将所有图像短边缩放到 256像素,再取中心 256*256 区域,RGB各通道减去训练集平均值(中心化)。
架构
5卷积层+3全连接层
特点:
1. ReLU 非线性激活
处理一个神经元的输出的标准方式: 或
。
这种饱和非线性(Saturating Nonlinearity)比不饱和非线性更慢。
如: (Rectified Linear Unit)。
深层 CNN 用 ReLU 训练比用 tanh 快几倍。
2. 在多个 GPU 上训练
一个 GTX 580 上有 3GB 内存,限制了网络的大小。120 万训练样本足够训练一个 GPU 跑不下的网络,因此我们把网络放在了两块 GPU 上并行训练。我们将神经元各一半放在两块 GPU 上,而 GPU 仅在某些层通信(选择连接模式成为交叉验证的一个问题)。
这样的架构让我们的 top-1 和 top-5 错误率下降了 1.7% 和 1.2%(对比在一块 GPU 上训练)。
3. 局部响应归一化
ReLU 不需要输入归一化来防止其饱和,但以下局部归一化方法对泛化有益。
:在
应用卷积核
与 ReLU 得到的神经元活动信号。
响应归一化:
这种归一化从实际神经元的一种 侧抑制(Lateral Inhibition) 机制启发而来,使不同 kernel 的神经元输出之间产生竞争。
为由验证集确定的超参数。我们取
。
这个“亮度归一化”与“对比度归一化”有些类似,它让我们的 top-1 和 top-5 误差分别降低 1.4% 和 1.2%。
4. 重叠池化
CNN 中的池化层汇总了同 kernel map 中神经元组的输出。传统的相邻池化单元的汇总邻域不会重叠。我们令单元距离 小于汇总邻域宽度
。(
) 则得到一个重叠池化层,它将 top-1 和 top-5 错误率分别降低了 0.4% 和 0.3%(与传统池化层的
相比)。同时这种方式更难过拟合。
5. 整体架构
-
5 个卷积层 + 3 个全连接层(接1000 路 Softmax 输出)。
-
最大化目标:多项式逻辑回归目标(等价于最大化预测分布下训练集中正确标签的平均对数)。
-
第 2, 4, 5 个卷积层的 kernel 只连接到同 GPU 的前一层 kernel map。
-
响应归一化层在第 1, 2 卷积层后。
-
最大池化层在响应归一化层和第 5 卷积层后。
这份笔记是关于 AlexNet 如何减少过拟合的关键技术。以下是转写的文字内容:
减少过拟合
1. 数据增强
图像数据中最简单也最常见的防止过拟合方法是通过保持标签变换人工增大数据集。我们采用了两种不同的形式,可以通过很少的计算从原图像产生变换图像,因此变换图像不需要储存。我们在运行 GPU 进行训练的同时用 CPU 生成变换图像,以节省算力。
-
法一:生成图像翻译与水平翻转
从
图像中提取
区域与其水平翻转,在区块上训练网络。这使训练集增大了 2048 倍。预测时,提取 5 个
-
法二:改变 RGB 通道的强度(训练集)
我们在训练集的 RGB 像素值上做 PCA:
其中
与
为 RGB 值的协方差矩阵的第
个特征向量及特征值。
为高斯随机值
,
目的: 使神经网络对光照颜色不敏感。
2. Dropout
“结合‘不同模型’的预测”
以 0.5 概率将隐层神经元的输出置零(dropped out)。它们不参与正向传播与反向传播。测试时将所有神经元输出乘 0.5。
-
减少了神经元之间复杂的协同适应。
-
我们在前两个全连接层中使用 dropout,它避免了过拟合,降低了收敛所需训练轮数。
学习细节
-
SGD(随机梯度下降)
-
Batch size: 128
-
Momentum: 0.9
-
Weight decay: 0.0005(这不仅是正则化,也可减少训练误差)
权重更新公式:
-
: momentum variable(动量变量)
-
: learning rate(学习率)
-
: 第
上,目标函数梯度的平均
初始化:
-
权重:
-
偏置 (Bias):
-
1:第 2, 4, 5 卷积层,全连接隐层。
-
0:其它。 目的:为 ReLU 提供正输入,加速早期训练。
-
学习率策略:
学习率全部相同,当验证误差停止增长时将其除以 10。初始化为 0.01,降三次。
90 轮训练,120万图,花费 5-6 天。
结论
取得了比前人更好的 error rate(错误率)。
定性评价
-
非中心物体也能识别,有时会失去关键信息。
-
相似的图产生相似的高层特征(“找相似”:在高层的输出上做自编码)。
讨论
监督深层 CNN 能给出突破性结果。算力增强,我们的结果还将进步,但仍与人类视觉系统有很大数量级的差距。我们最终希望在视频序列上训练很大的深层 CNN,时间结构提供静态图像中缺失或不明显的信号。
代码复现
代码阅读
参考 github: dansuh17/alexnet-pytorch
part I. 导入所需python库
-
import torch: pytorch 主库,提供多维张量数据结构。 -
(结构)
torch.nn: 包含构建神经网络所需的层、损失函数容器。 -
(函数)
torch.nn.functional: 包含 nn 中各种层的函数实现(用于不需要储备权重的操作,如 ReLU、pooling 等)。 -
(优化)
torch.optim: 包含各种深度学习优化算法,如 SGD、Adam。 -
(加载)
from torch.utils import data: 处理数据集的基础,包含 Dataset、DataLoader 等。 -
(内容)
torchvision.datasets: 内置了计算机视觉的标准数据集(MNIST、CIFAR-10、ImageNet 等)。 -
(处理)
torchvision.transforms: 对图像进行预处理。 -
(路径)
os: 处理文件路径,指定使用显卡。 -
from tensorboardX import SummaryWriter: 用于可视化(实时查看 Loss 等)。
part II. 配置与初始化
-
硬件设备配置:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')(有显卡用显卡,否则用 cpu)。 -
定义训练超参数:
-
训练参数:
-
NUM_EPOCHS = 90:整个数据集的迭代轮数。 -
BATCH_SIZE = 128:每次训练时同时处理 128 张图片。 -
MOMENTUM = 0.9/LR_DECAY = 0.0005:优化器参数。控制梯度下降,防止过拟合。 -
LR_INIT = 0.01:初始学习率。
-
-
数据参数:
-
IMAGE_DIM = 227:规范输入图像的尺寸 ($227 \times 227$ 像素)。 -
INPUT_ROOT_DIR/TRAIN_IMG_DIR:原始图片存放位置。 -
LOG_DIR:存放 TensorBoard 日志。 -
CHECKPOINT_DIR:每运行一段时间把权重存成.pth文件,若中断可从这里加载进度继续学。
-
-
设备参数:
DEVICE_IDS = [0, 1, 2, 3]:多 GPU 并行计算。
-
-
os.makedirs(CHECKPOINT_DIR):创建 CHECKPOINT_DIR 目录。
part III. 网络架构 class AlexNet
1. 特征提取部分:self.net
-
① 卷积层
Conv2d:nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4)-
注:padding 填充默认为 0,不人为添加(边缘补 0)。stride 默认为 1。
-
维度变化:
-
-
② 激活函数
ReLU:nn.ReLU()(选择不步长训练方式) -
③ 局部响应归一化:
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2)-
公式参考:
-
-
④ 最大池化:
nn.MaxPool2d(kernel_size=3, stride=2)-
维度变化:
-
2. 分类器部分:self.classifier
-
①
nn.Dropout(p=0.5, inplace=True):让神经元以 0.5 概率失活,防止过拟合。-
注:
inplace表示直接在输入的内存块上进行原地修改,不开辟新空间,节省显存。默认 False 是为了在反向传播时可用原数据。
-
-
②
nn.Linear(in_features=(256*6*6), out_features=4096)
3. 权重初始化部分:self.init_bias()
-
self.net中Conv2d层的权重初始化为 -
第 2, 4, 5 卷积层 偏置初始化为 1。
-
全连接层 用默认初始化:Kaiming Uniform
-
权重:
随机采样,其中
-
偏置:
表示均匀分布)
-
4. 前向传播部分:forward
-
输入
(一张
的图片)。
-
提取特征:经过
self.net得到特征图。 -
展平 (flatten) :
x.view(-1, 256*6*6),将三维特征拉成一维向量。 -
将一维向量特征输入
self.classifier得到最终预测。
part IV. 主循环
-
模型与硬件绑定(设置随机种子):
-
torch.nn.parallel.DataParallel(...):将模型包装起来,使得它能同时在多个 GPU 上运行(自动将一个 Batch 的数据平均分给多个 GPU)。 -
SummaryWriter:初始化 TensorBoard 以记录训练进度。
-
-
数据流水线:
-
transforms.Compose:-
CenterCrop:从中心裁剪出区域。
-
Normalize:使用 ImageNet 的标准均值和方差进行归一化。
-
-
DataLoader:-
num_workers:开启 8 个线程预读数据,防止 CPU 读图太慢导致 GPU 闲置。 -
pin_memory = True:加快数据从内存复制到显存的速度。
-
-
3. 优化器与学习率策略
-
Adam vs SGD:原论文使用的 SGD 没训练出来,换成 Adam 就成功了。Adam 带有自适应学习率,更易调试。
-
StepLR:学习率衰减器,每 30 个 Epoch,学习率乘以 0.1。
4. 核心训练循环
-
将图片搬到显存:
imgs.to(device) -
前向传播:
output = alexnet(imgs) -
计算损失:
F.cross_entropy -
更新参数:step 1.
optimizer.zero_grad():清空旧的梯度。step 2.loss.backward():反向传播,计算参数调整方向。step 3.optimizer.step():根据计算出的方向修改参数。
5. 监控与可视化
-
每 10 步计算一次准确率,把 Loss 传给 TensorBoard 画图。
-
每 100 步打印并保存参数的梯度平均值和权重分布。
6. 模型持久化
每个 epoch 结束保存进度,实现断点续训
state = {'model': alexnet.state_dict(), ...}
torch.save(state, checkpoint_path)
在 CIFAR-10 上的适配:
-
Batch size = 128
-
读数据 num_workers = 4
-
Image_dim = 64 (扩充成 64)
-
num_classes = 10
-
全连接层 4096
1024
维度参数计算:
卷积层:
-
第一卷积层:(3, 96, kernel=10, stride=1, padding=0)
-
第一池化层:(ker=3, str=2)
-
第二卷积层:(96, 256, 5, padding=2)
-
第二池化层:(ker=3, str=2)
-
第三卷积层:(256, 384, 3, padding=1)
-
第四卷积层:(384, 384, 3, p=1)
-
第五卷积层:(384, 256, 3, p=1)
-
第三池化层:(ker=3, str=2)
全连接层:
-
第一全连接层:
-
第二全连接层:
-
第三全连接层:
完整代码
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils import data
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from tensorboardX import SummaryWriter
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') #选择计算设备
NUM_EPOCHS = 30
BATCH_SIZE = 128
# MOMENTUM = 0.9
# LR_DECAY = 0.0005
LR_INIT = 0.0001
IMAGE_DIM = 64
NUM_CLASSES = 10
# INPUT_ROOT_DIR = ''
# TRAIN_IMG_DIR = ''
OUTPUT_DIR = 'mynet_data_out'
LOG_DIR = OUTPUT_DIR+'/tblogs'
CHECKPOINT_DIR = OUTPUT_DIR+'/models'
os.makedirs(CHECKPOINT_DIR, exist_ok=True) #创建checkpoint目录(用于储存每一epoch的中间结果)
class AlexNet(nn.Module):
def __init__(self,num_classes=NUM_CLASSES):
super().__init__() #调用父类nn.Module的初始化方法
self.net = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=10, stride=1),
nn.ReLU(),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96,256,5,padding=3),
nn.ReLU(),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256,384,3,padding=1),
nn.ReLU(),
nn.Conv2d(384,384,3,padding=1),
nn.ReLU(),
nn.Conv2d(384,256,3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(in_features=(6*6*256), out_features=1024),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(in_features=1024, out_features=1024),
nn.ReLU(),
nn.Linear(in_features=1024, out_features=num_classes)
)
self.init_bias()
def init_bias(self): #参数初始化
for layer in self.net:
if isinstance(layer, nn.Conv2d):
nn.init.normal_(layer.weight, 0, 0.01)
nn.init.constant_(layer.bias, 0)
nn.init.constant_(self.net[4].bias, 1)
nn.init.constant_(self.net[10].bias, 1)
nn.init.constant_(self.net[12].bias, 1)
def forward(self, x): #前向传播
x = self.net(x)
x = x.view(-1, 256*6*6)
return self.classifier(x)
if __name__ == '__main__':
seed = torch.initial_seed() #设置随机种子
print(f'Used seed:{seed}')
tbwriter = SummaryWriter(log_dir=LOG_DIR) #创建记录日志,以实时绘制训练曲线
print('TensorboardX summary writer created')
alexnet = AlexNet(num_classes=NUM_CLASSES).to(device) #创建网络实例,并放到计算设备上
print(alexnet)
print('AlexNet created')
dataset = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=transforms.Compose([
transforms.Resize(64),
transforms.ToTensor(),
transforms.Normalize(mean=[0.491, 0.482, 0.447], std=[0.202, 0.199, 0.201]),
])
) #从数据集找出数据,预处理
print('Dataset created')
dataloader = data.DataLoader(
dataset,
shuffle=True,
pin_memory=True,
num_workers=4,
drop_last=True,
batch_size=BATCH_SIZE
) #读取并打包数据,备计算设备取用
print('Dataloader created')
val_dataset = datasets.CIFAR10(
root='./data',
train=False,
download=True,
transform=transforms.Compose([
transforms.Resize(64),
transforms.ToTensor(),
transforms.Normalize(mean=[0.491, 0.482, 0.447], std=[0.202, 0.199, 0.201]),
])
)
val_dataloader = data.DataLoader(
val_dataset,
batch_size=BATCH_SIZE,
num_workers=4,
shuffle=False,
)
print('Val_Dataset loaded')
optimizer = optim.Adam(params=alexnet.parameters(), lr = LR_INIT) #设置优化器
print('Optimizer created')
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5) #设置学习率策略
print('LR scheduler created')
print('Starting training...')
total_steps = 1
for epoch in range(NUM_EPOCHS): #训练循环,一次循环遍历一次训练集
alexnet.train() #训练模式
running_loss = 0.0 #记录训练集当前epoch累计loss
for imgs, classes in dataloader: #遍历dataloader里的数据,一次循环取一个batch
imgs, classes = imgs.to(device), classes.to(device) #把dataloader中备取的数据取到计算设备上
output = alexnet(imgs) #图片数据进入模型,前向传播得到预测类别概率
loss = F.cross_entropy(output, classes) #根据预测类别概率和实际类别概率计算损失
optimizer.zero_grad() #清空旧的梯度
loss.backward() #反向传播
optimizer.step() #更新参数
if total_steps%10 == 0: #每10个batch计算准确度,并画loss图
with torch.no_grad(): #接下来不需要追踪梯度,省显存
_, preds = torch.max(output, 1) #输出每一行最大值和所在索引
accuracy = torch.sum(preds==classes) #预测正确的数量
print('Epoch:{}\tStep:{}\tLoss:{:4f}\tAcc:{}'
.format(epoch+1, total_steps, loss.item(), accuracy.item()))
tbwriter.add_scalar('loss', loss.item(), total_steps) #将数据写入Tensorboard的日志文件
tbwriter.add_scalar('accuracy', accuracy.item(), total_steps)
if total_steps%100 == 0: #每100个batch打印并保存参数的梯度平均值和权重分布
with torch.no_grad():
print('*' * 10)
for name, parameter in alexnet.named_parameters(): #该方法可以输出所有层名与对应的所有参数
if parameter.grad is not None:
avg_grad = torch.mean(parameter.grad)
print('\t{} - grad_avg:{}'.format(name, avg_grad))
tbwriter.add_scalar('grad_avg/{}'.format(name), avg_grad.item(), total_steps) #记录平均梯度,若长期趋于0则说明这一层学不动了
tbwriter.add_histogram('grad/{}'.format(name),
parameter.grad.cpu().numpy(), total_steps) #直方图,记录一层的梯度分布情况,突然塌陷或极平说明出问题了
if parameter.data is not None:
avg_weight = torch.mean(parameter.data)
print('\t{} - param_avg:{}'.format(name, avg_weight))
tbwriter.add_scalar('weight_avg/{}'.format(name), avg_weight.item(), total_steps) #若突然很大,可能出现了梯度爆炸
tbwriter.add_histogram('weight/{}'.format(name),
parameter.data.cpu().numpy(), total_steps) #好的权重呈现以0为中心的钟形曲线
running_loss += loss.item()*imgs.size(0)
total_steps += 1
epoch_train_loss = running_loss / len(dataset)
alexnet.eval() #验证模式
val_loss = 0.0
val_correct = 0
with torch.no_grad():
for v_imgs, v_classes in val_dataloader:
v_imgs, v_classes = v_imgs.to(device), v_classes.to(device)
v_output = alexnet(v_imgs)
v_l = F.cross_entropy(v_output, v_classes)
val_loss += v_l.item() * v_imgs.size(0)
_, v_preds = torch.max(v_output, 1)
val_correct += torch.sum(v_preds==v_classes).item()
epoch_val_loss = val_loss/len(val_dataset)
epoch_val_acc = val_correct/len(val_dataset)
tbwriter.add_scalar('Loss/Train_Epoch', epoch_train_loss, epoch+1)
tbwriter.add_scalar('Loss/Validation', epoch_val_loss, epoch+1)
tbwriter.add_scalar('Accuracy/Validation', epoch_val_acc, epoch+1)
print(f'>> Epoch {epoch+1} Finished. Train Loss: {epoch_train_loss:.4f}, Val Loss: {epoch_val_loss:.4f}, Val Acc: {epoch_val_acc:.4f}')
lr_scheduler.step() #学习率迭代
checkpoint_path = os.path.join(CHECKPOINT_DIR, 'mynet_states_e{}.pkl'.format(epoch+1))
state = {
'epoch':epoch,
'total_steps':total_steps,
'optimizer':optimizer.state_dict(),
'model':alexnet.state_dict(),
'seed':seed
}
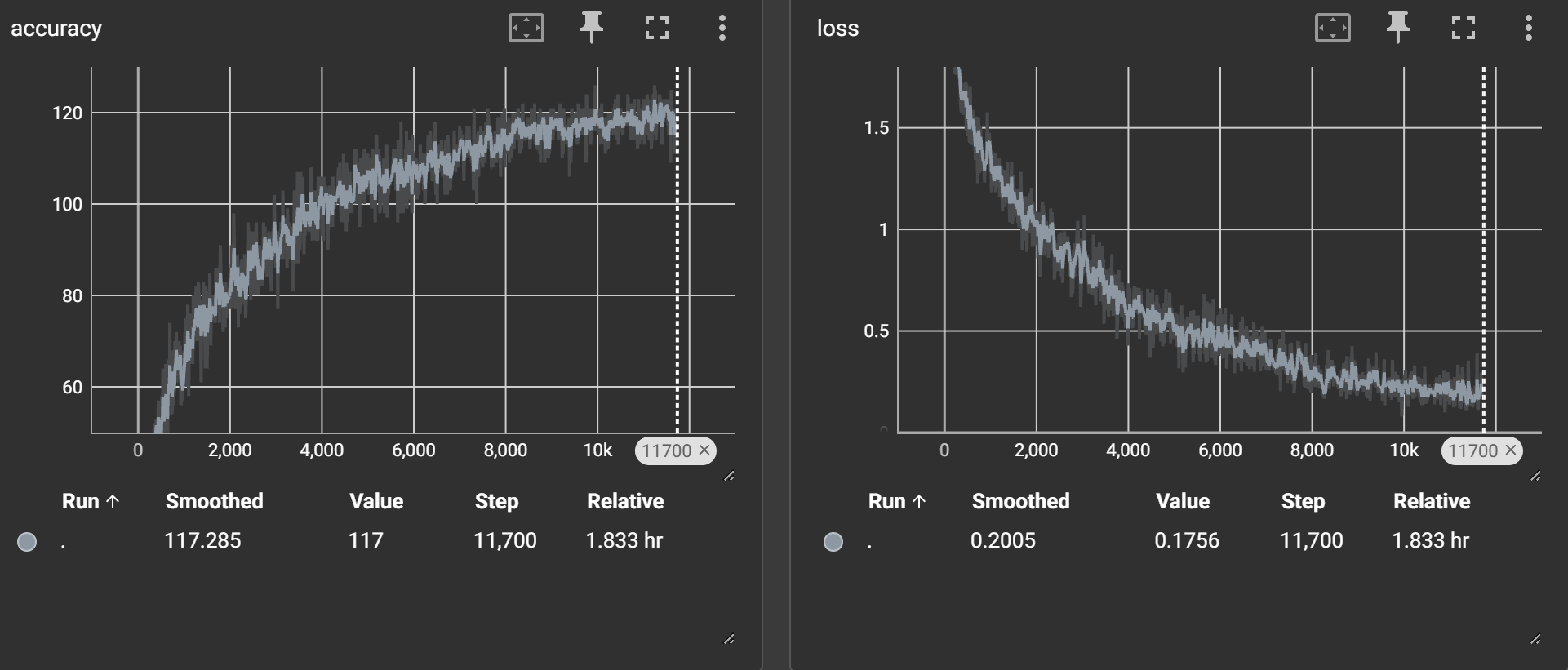
torch.save(state, checkpoint_path) #把此刻系统状态保存到checkpoint_path目录我在RTX2050上跑了1.8h。训练时的loss曲线与acc曲线(一个batch,即128张图片中猜对个数)如下:
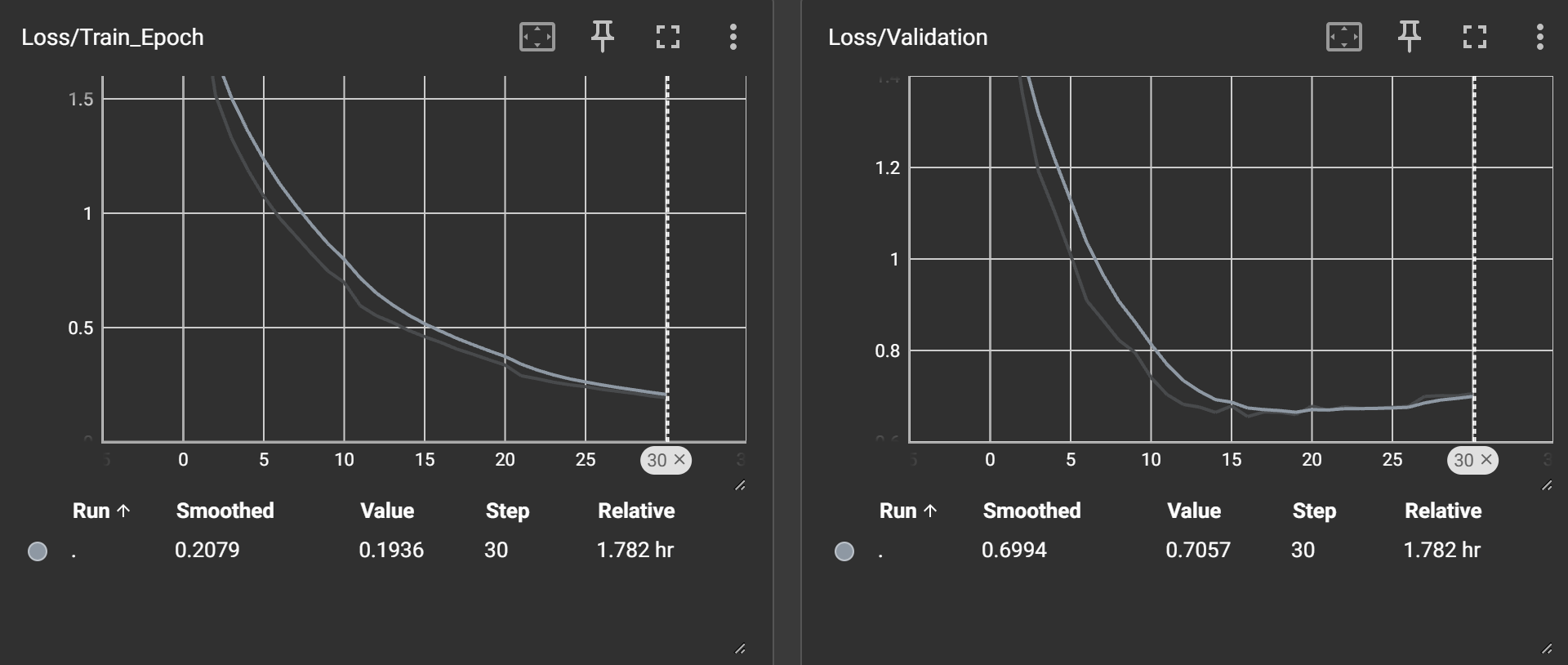
每个epoch计算的训练集与验证集的loss曲线如下:
以及验证集上的准确率(猜对数量的百分比)曲线:
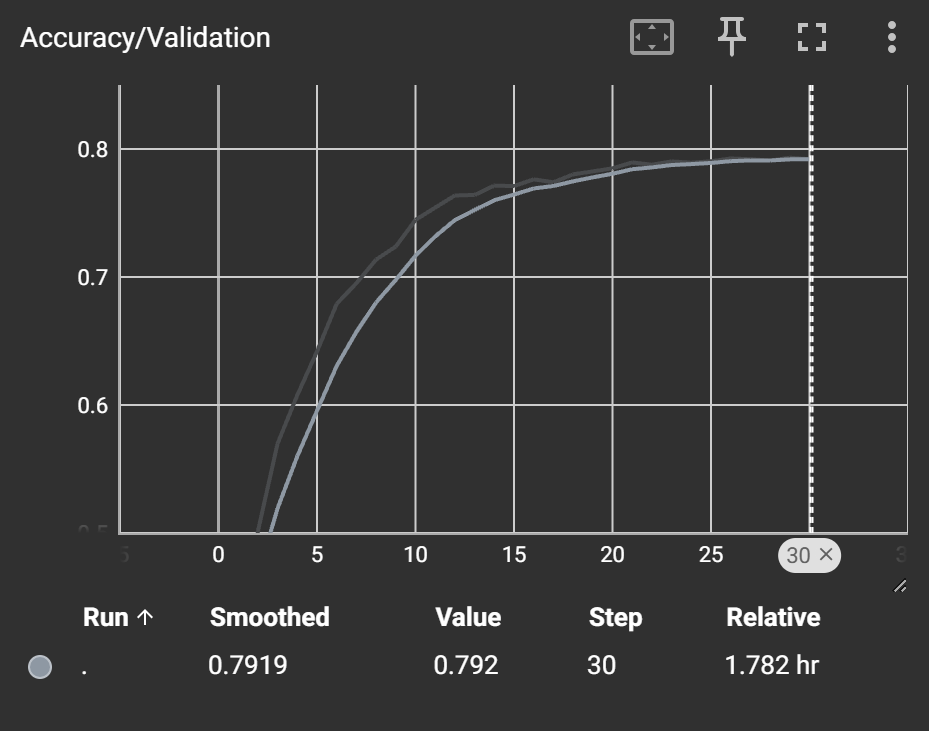
可以看到在20epoch之后训练集的loss下降,验证集的loss不降反升,说明过拟合了,这个模型在CIFAR-10数据集上最高能达到大致80%正确率。
最后,可以用以下代码生成测试例子:
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
# 1. 定义和训练时完全一致的架构,即AlexNet类(此处简写)
# class AlexNet(nn.Module):
# 2. 基础配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 3. 加载模型
model = AlexNet(num_classes=10).to(device)
checkpoint = torch.load('mynet_data_out/models/mynet_states_e19.pkl')
model.load_state_dict(checkpoint['model'])
model.eval() # 必须切换到推理模式,这会关闭 Dropout
def test_random_image():
# 这里的 transform 必须和训练时的一致(Resize 64 和 Normalize)
transform = transforms.Compose([
transforms.Resize(64),
transforms.ToTensor(),
transforms.Normalize(mean=[0.491, 0.482, 0.447], std=[0.202, 0.199, 0.201]),
])
# 加载测试集
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
# 随机选一张图
idx = np.random.randint(len(testset))
img_tensor, label = testset[idx]
# 模型预测
with torch.no_grad():
output = model(img_tensor.unsqueeze(0).to(device)) # 增加 Batch 维度
_, predicted = torch.max(output, 1)
# 反标准化以便显示图片
img_show = img_tensor.permute(1, 2, 0).numpy()
img_show = img_show * np.array([0.202, 0.199, 0.201]) + np.array([0.491, 0.482, 0.447])
img_show = np.clip(img_show, 0, 1)
plt.imshow(img_show)
plt.title(f'Predict: {classes[predicted]} | Real: {classes[label]}')
plt.show()
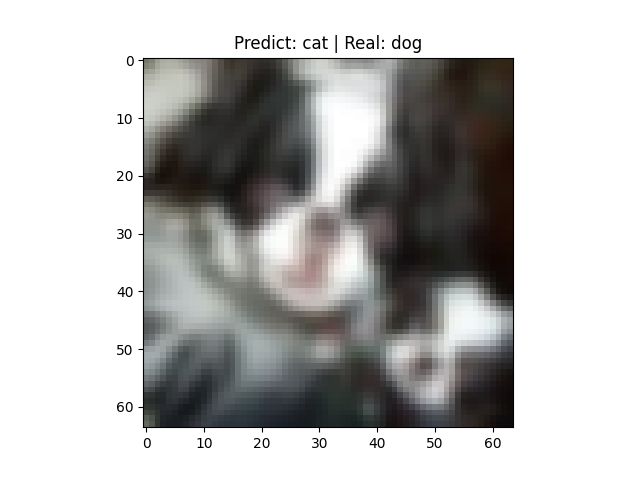
test_random_image()如下,得到随机图片的预测标签与真正标签,可以看到是一个判错的例子,将狗判断成了猫:
未来改进
为了适配CIFAR-10数据集,第一个卷积层设置了核大小为10*10,步长为1,可能会使得模型过分关注大范围的特征,反而忽略像猫和狗这种细节上有差异的情况。另外,全连接层可能还是过大,1024对于CIFAR-10来说太大,导致产生过拟合。最后,我还没有用数据增强的方法,如果把图片水平翻转,加入训练集,也许可以使得训练效果更好。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)