别再说不懂知识图谱了!大模型结合KG的科学视角深度拆解,从进化到构建,这一篇讲透了!
来看看科学知识图谱(SciKGs) 总结,工作在《Bridging Data and Discovery: A Survey on Knowledge Graphs in AI for Science》,https://www.techrxiv.org/doi/pdf/10.36227/techrxiv.176369442.22009541/v1,梳理了SciKGs 的概念基础、构建方法、跨域应用,阐述其与大模型的结合思路。
这是个不错的读物,看图说话的方式来回顾。
一、科学领域知识图谱技术的四个演进阶段
知识图谱从早期数据管理到如今驱动科学发现的演进历程,如下图随所示:
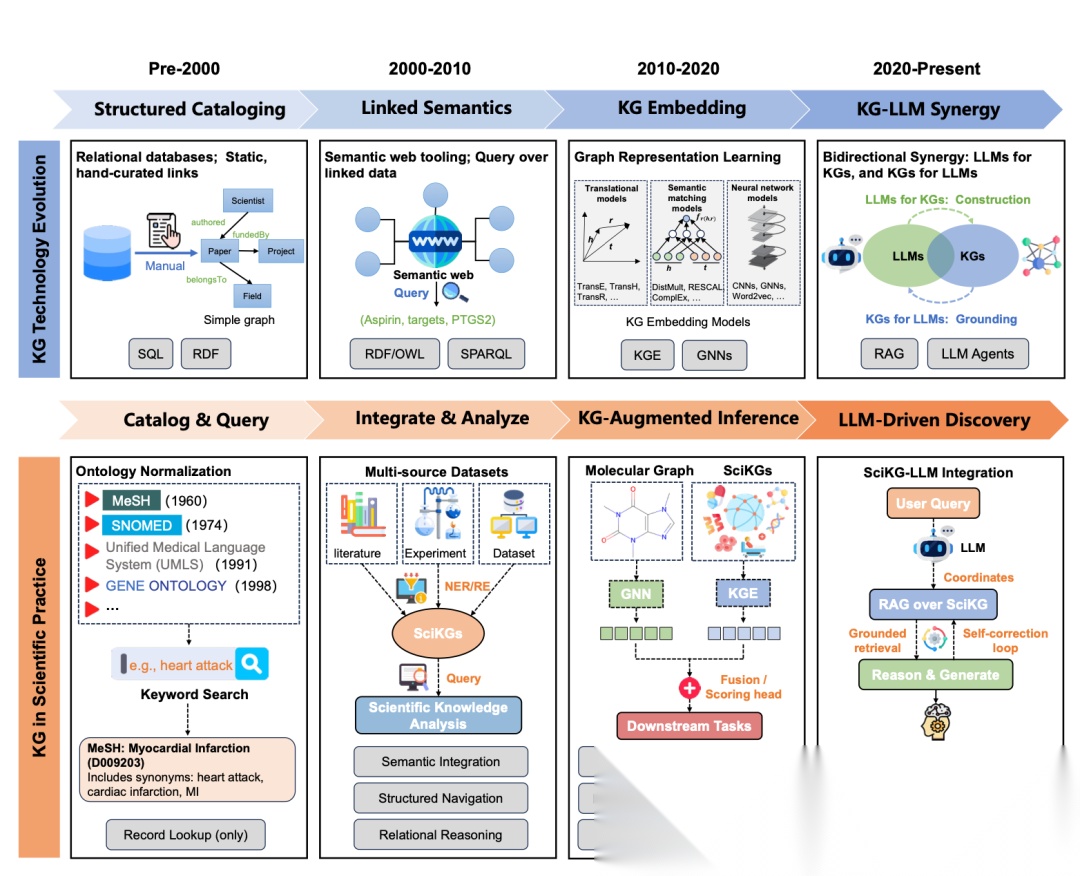
2000年以前(结构化编目阶段), KG技术主要依赖关系型数据库和静态的手动链接,侧重于数据的结构化存储与基础编目,科学实践上仅停留在简单的关键词检索和本体规范化(如MeSH);
2000年至2010年(链接语义阶段),随着语义网的兴起,技术重心转向利用RDF和SPARQL进行数据链接与查询,实现跨数据集的语义整合,科学应用上开始进行多源数据的集成与语义导航;
2010年至2020年(KG嵌入阶段),图表示学习成为主流,通过图神经网络等技术将知识转化为向量进行计算,增强推理能力,推动药物-靶点相互作用预测等复杂的科学分析任务;
2020年至今(KG与大模型协同阶段),进入了知识图谱与大模型双向赋能的时代,利用检索增强生成和智能体解决大模型的幻觉问题,实现由大模型驱动的假设生成与自动化科学发现工作流。
与此同时,也出现了许多概念,可以看下:SQL:结构化查询语言、RDF:资源描述框架、OWL:网络本体语言、SPARQL:SPARQL协议与RDF查询语言、GNN:图神经网络、KGE:知识图谱嵌入、RAG:检索增强生成
二、科学领域知识图谱从构建到维护的全流程
科学领域知识图谱从构建到维护的全流程,核心可拆解为四个关键模块:
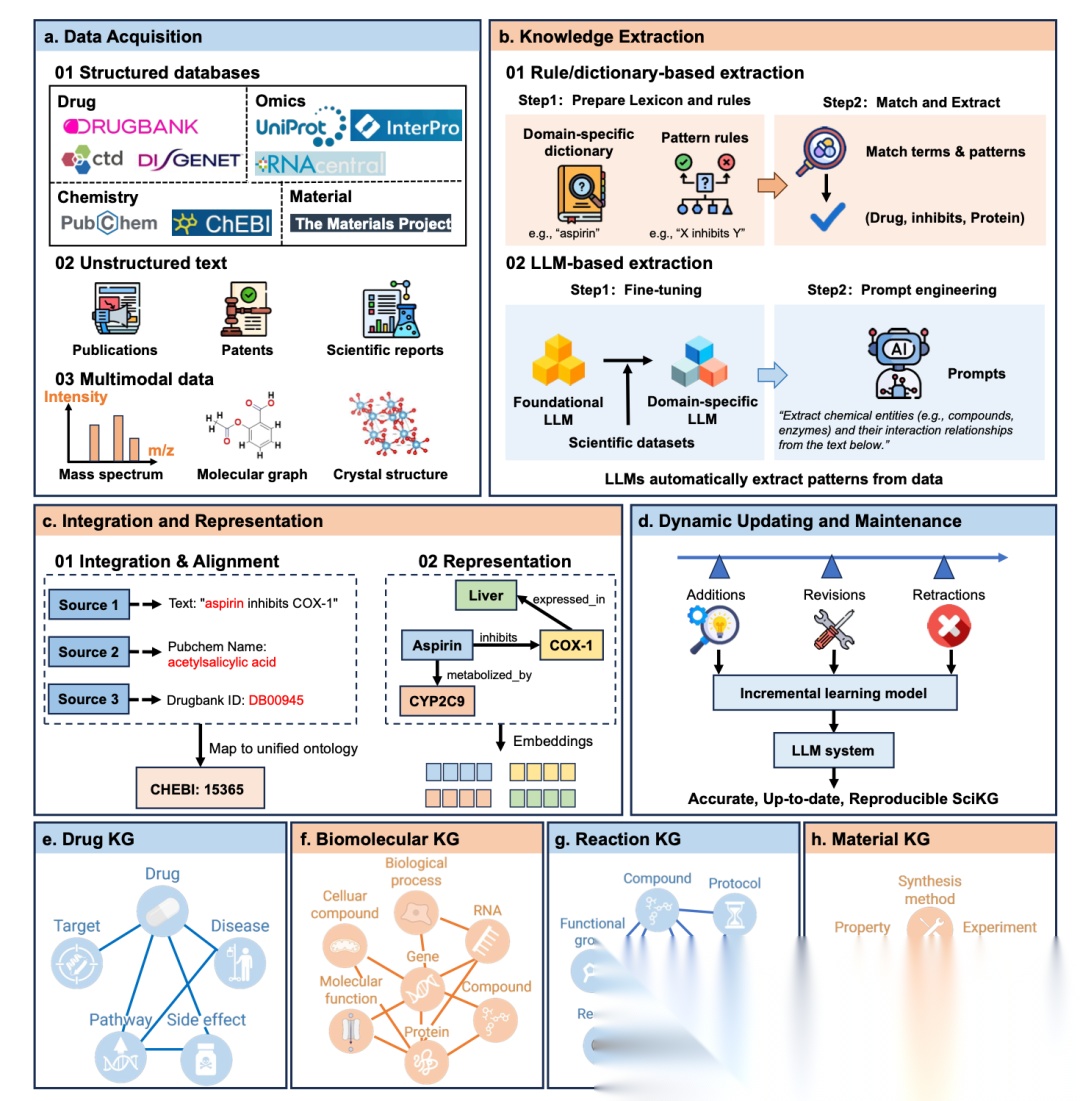
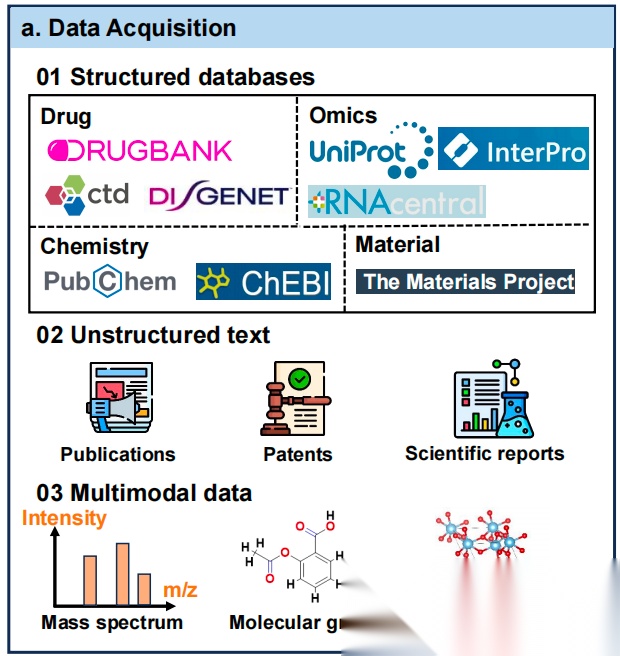
首先,数据获取:作为基石,整合了三类数据源,包括结构化数据库(如DrugBank、UniProt)、非结构化文本(如科学出版物、专利)以及多模态数据(如质谱图、分子结构)。
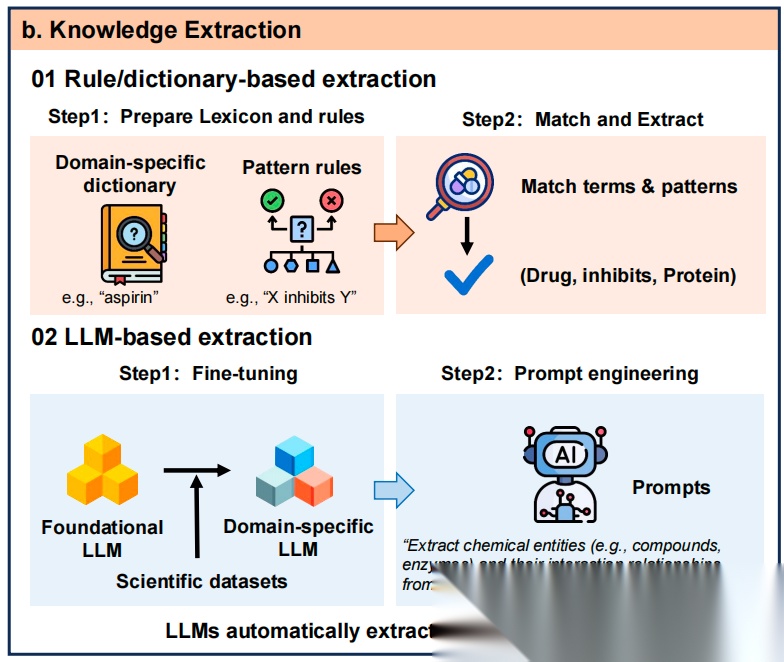
其次,知识提取,核心处理环节,包含基于规则/词典的提取(利用预定义词典和模式匹配)和基于大模型的提取(通过微调和提示工程自动抽取)两种子模块。
接着,整合与表示,负责数据清洗与转化,包含整合与对齐(解决多源数据名称不一致问题,如将Aspirin映射到统一ID)和表示(将知识转化为向量嵌入或图结构)两个子模块。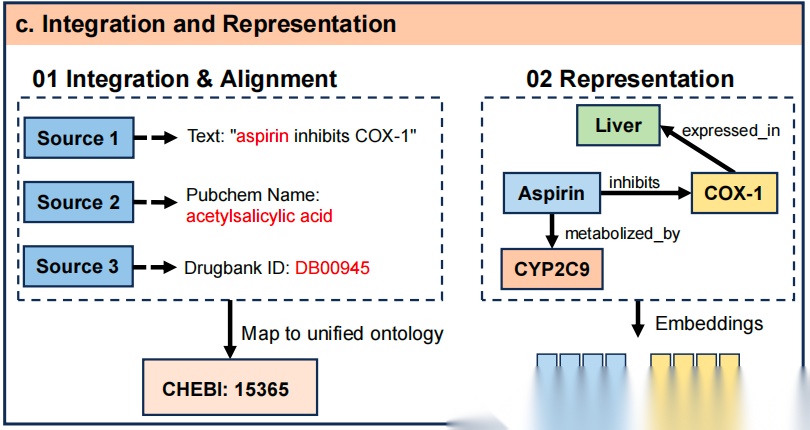
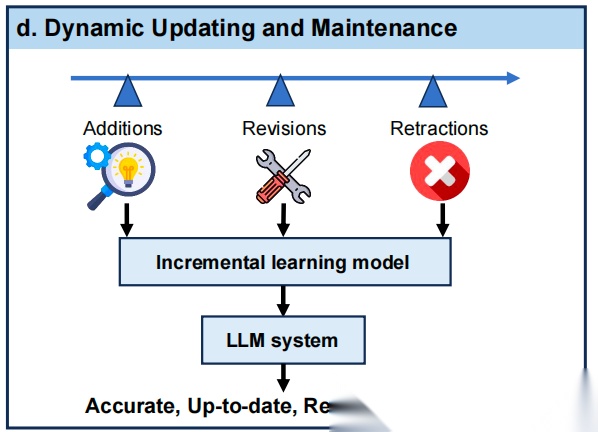
最后,动态更新与维护,利用增量学习和大模型驱动的错误纠正,确保图谱随新数据实时更新且保持准确。
三、科学领域知识图谱与大模型结合
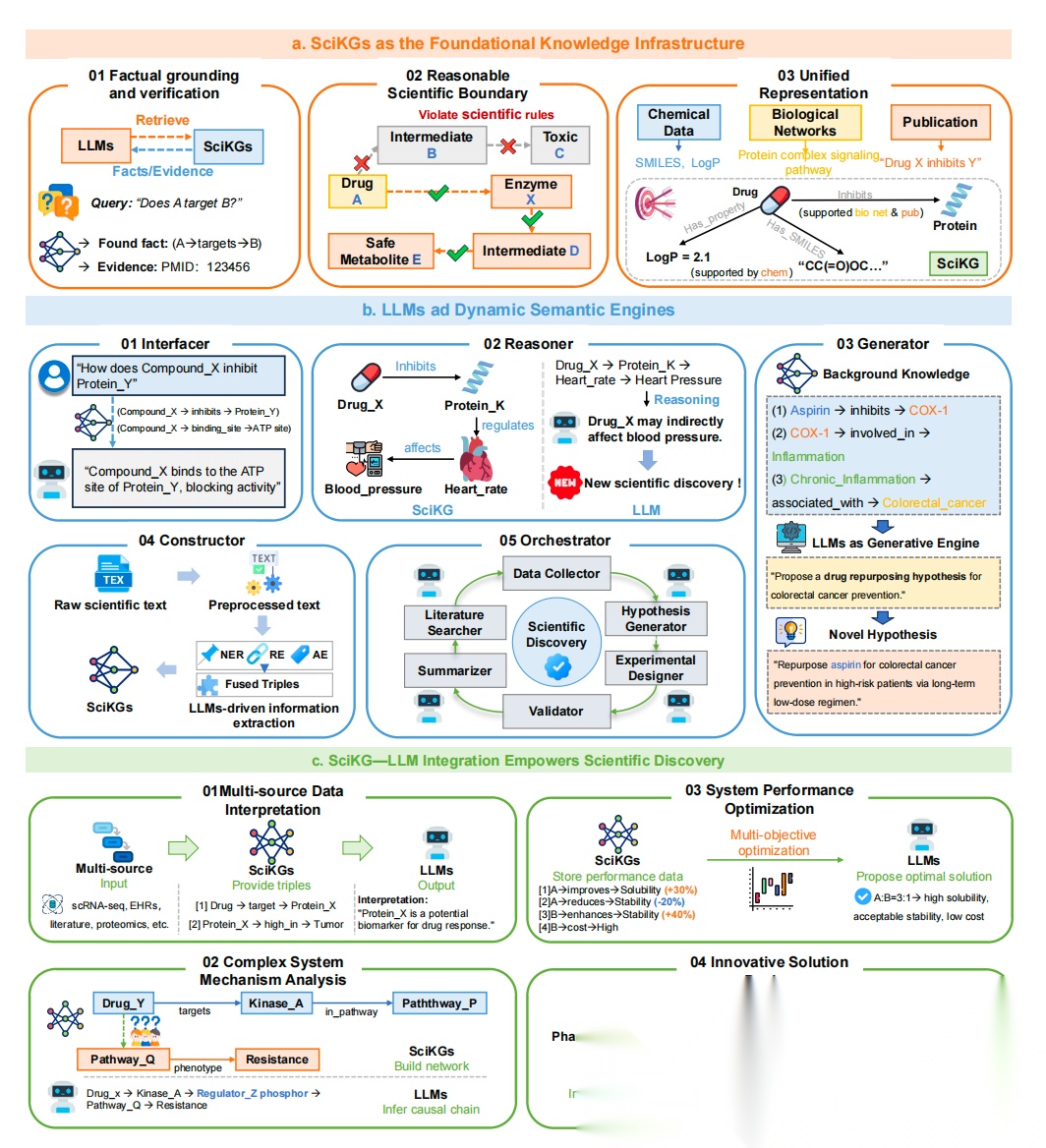
主要是3块的内容,科学领域知识图谱提供事实依据和统一表示,大模型作为动态引擎处理语义、推理、生成,二者协同做多源数据解读、机制分析、性能优化和创新设计等科学任务。
具体的,
首先,科学领域知识图谱作为基础,包括有:
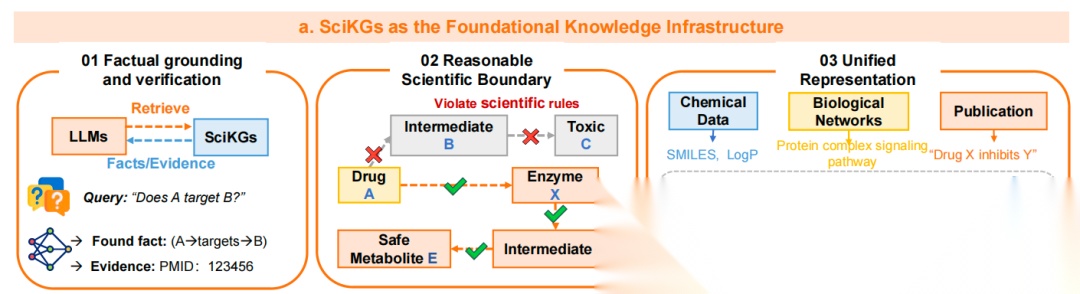
事实依据与验证,大模型通过查询科学领域知识图谱,获取并验证事实(如“药物A是否靶向B”),依据图谱中的证据(如PMID文献编号)确认事实;
科学边界界定,科学领域知识图谱通过规则(如“药物→酶→中间体”的合法路径)排除不合理关联(如“药物→有毒中间体”),确保科学合理性;
统一表示,整合化学数据(如SMILES、LogP)、生物网络(如蛋白信号通路)和文献,形成统一的知识图谱结构。
其次,大模型作为动态引擎,分成多个模块:
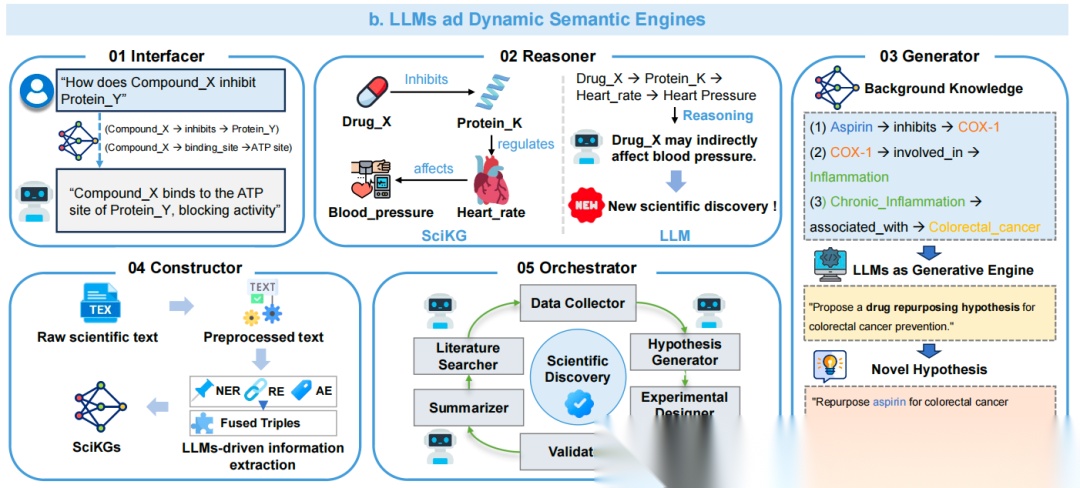
接口模块,接收用户查询(如“化合物X如何抑制蛋白Y”),从科学领域知识图谱中提取关联信息(如“结合位点”),并生成自然语言解释;
推理模块,基于科学领域知识图谱的关联(如“药物X抑制蛋白K→心率→血压”),推理间接影响(如“药物X可能间接影响血压”),甚至提出新科学发现;
生成模块,结合背景知识(如“阿司匹林抑制COX-1→炎症→结直肠癌”),生成新假设(如“重新利用阿司匹林预防结直肠癌”);
构建模块,从原始文本中提取实体、关系,融合为三元组,驱动科学领域知识图谱的信息提取;
编排模块,协调文献检索、假设生成、实验设计、验证等工作流,自动化科学发现流程。
最后,科学领域知识图谱-大模型整合赋能科学发现,这个主要是应用层:
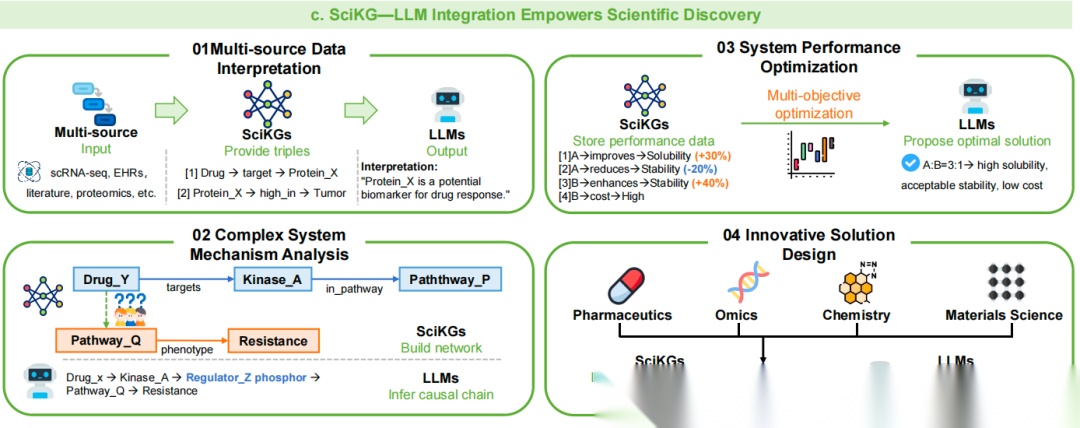
多源数据解读,整合多源数据(如单细胞测序、文献、蛋白质组学),科学领域知识图谱提供三元组,大模型输出解读(如“蛋白X是药物响应的潜在生物标志物”);
复杂系统机制分析,基于科学领域知识图谱构建网络(如“药物Y→激酶A→通路P→耐药性”),大模型推断因果链,解析复杂机制;
系统性能优化,科学领域知识图谱存储性能数据(如“分子A提升溶解度30%”),大模型通过多目标优化(如“溶解度、稳定性、成本”)提出最优方案;
创新方案设计,整合跨领域知识(如药学、组学、化学、材料学),科学领域知识图谱与大模型协同生成新设计(如新型药物、材料)。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献166条内容
已为社区贡献166条内容

所有评论(0)