Google DeepMind 提出 AutoHarness:先别急着训练大模型,先让它学会“别犯规”
很多人讨论大模型 agent 时,注意力都放在“它会不会规划”“它会不会推理”“它能不能多想几步”。
但 Google DeepMind 这篇 2026 年 3 月 5 日发布的论文《AutoHarness: improving LLM agents by automatically synthesizing a code harness》,盯上的却是另一个更朴素、也更致命的问题:
模型不是不会想,而是经常先犯规。
比如下棋时走出非法步、文本游戏里输出环境根本不接受的动作。这种错误看起来不高级,却足以让一个本来“懂规则”的模型,持续输给环境。
DeepMind 的做法很有意思。他们没有先去重新训练一个更大的模型,也没有靠人工手写一堆规则补丁,而是让 Gemini-2.5-Flash 自动给自己写一个代码外壳,也就是 harness。这个外壳负责两件事:一,检查动作是否合法;二,在必要时重试、过滤,甚至直接接管决策。
结果很夸张:
一个更小的 Gemini-2.5-Flash,在加上自动合成的 harness 之后,居然能在不少任务上压过 Gemini-2.5-Pro;如果把这个思路再往前推,直接让代码本身成为 policy,连推理时的 LLM 调用都可以省掉,而且平均得分还超过了 GPT-5.2-High。
这篇论文真正值得看的,不只是一个实验结果,而是它在提醒我们:
Agent 的能力,不一定只来自“模型本体”,也可能来自模型外那层被长期低估的系统结构。
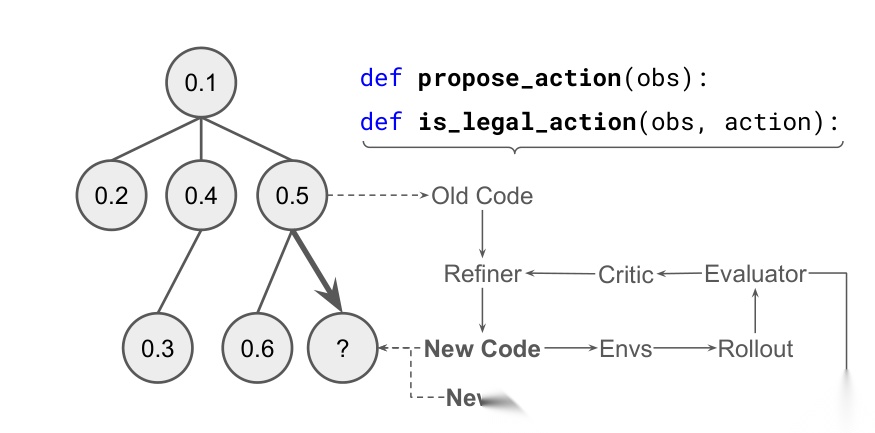
这张图对应论文里的Figure 1,核心是让代码在 rollout、critic、refiner 的闭环里不断自我修正。
正文
一、这篇论文到底在解决什么问题
作者开篇举了一个很典型的例子。
在 Kaggle GameArena 国际象棋比赛里,Gemini-2.5-Flash 的失败中,有 78% 不是因为策略太差,而是因为走了非法步。换句话说,模型很多时候不是“不会博弈”,而是“连进入博弈都没进成功”。
这背后暴露的是一个被很多人低估的问题:LLM 可能理解规则,但不一定稳定地遵守规则;它可能知道什么动作是合理的,但在具体输出时,仍然会给出环境不接受的答案。
如果这个问题不解决,后面所有关于规划、搜索、长推理的讨论,都会被底层执行错误冲掉。
所以这篇论文的切口非常务实:
先别急着让模型更聪明,先让它别犯低级错误。
二、AutoHarness 的核心思想,不是“换模型”,而是“给模型加一个会自我进化的外壳”
什么是 harness?
可以把它理解成模型和环境之间的一层“保险丝”或者“中间件”。模型先提出动作,harness 再判断这个动作能不能被环境接受。如果不行,就拦下、修正、重试。
以前这层东西常常是工程师手写的。
但手写 harness 的问题也很明显:
每个游戏、每个环境都要单独做,成本高,而且非常脆。
AutoHarness 的创新点就在这里:
不是人来写 harness,而是让 LLM 自己根据环境反馈,自动把 harness 写出来、再一点点改好。
更具体一点,它让模型维护两类代码能力:
propose\_action(board):给出一个动作。
is\_legal\_action(board, action):判断这个动作是否合法。
如果环境告诉它“这个动作非法”,系统就把出错轨迹、错误信息、旧代码一起喂回去,让模型继续改代码。这个过程不是盲改,而是放在一个树搜索框架里,用 Thompson sampling 在不同候选代码之间做探索与利用。
说白了,它不是让模型直接变强,而是让模型在外面长出一层“不会轻易犯规的程序骨架”。
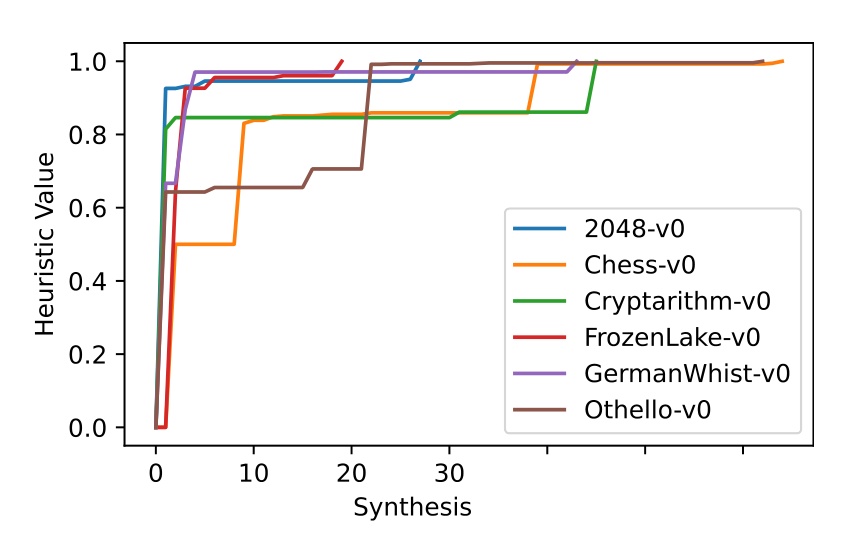
这张图对应Figure 2,能看到不同游戏里,合法动作率会随着代码迭代快速爬升。
三、这套方法为什么有效
论文最关键的一点,不是“代码比语言强”,而是“把可验证的部分剥离出来”。
下棋是否合法、动作格式对不对、当前局面下哪些选择能被接受,这些问题本质上是可执行、可验证、可外部检查的。
如果你把这些事情全压给 LLM 内部去“想”,它就会出现两个问题:
第一,它的内部世界模型可能是模糊的。
第二,它即使知道规则,也未必每次都输出得稳定。
而一旦把“合法性约束”写成代码,情况就变了。代码不会因为温度变化突然忘记规则,也不会在第 17 步开始莫名其妙输出一个非法格式。
换句话说,AutoHarness 其实是在做一件很重要的系统工程工作:
把“创造性决策”留给模型,把“硬边界约束”交给程序。
这件事听起来不像 AGI 叙事那么热血,但在 agent 落地里往往更值钱。
四、实验结果最震撼的地方,是“小模型+好外壳”能打过“大模型裸奔”
论文在 TextArena 的 145 个文本游戏上训练 harness,并在其中 32 个游戏上做端到端评测。
先看最基础的结果:
作者报告,他们在全部 145 个游戏上都把合法动作成功率做到了 100%。
这意味着,至少在这类有明确规则边界的环境里,AutoHarness 几乎把“非法动作”这个错误类型彻底清掉了。
训练成本也没有夸张到离谱。论文里提到,harness-as-action-verifier 的训练平均只需要 14.5 次树搜索迭代,32 个游戏里有 19 个在 10 次以内就收敛。
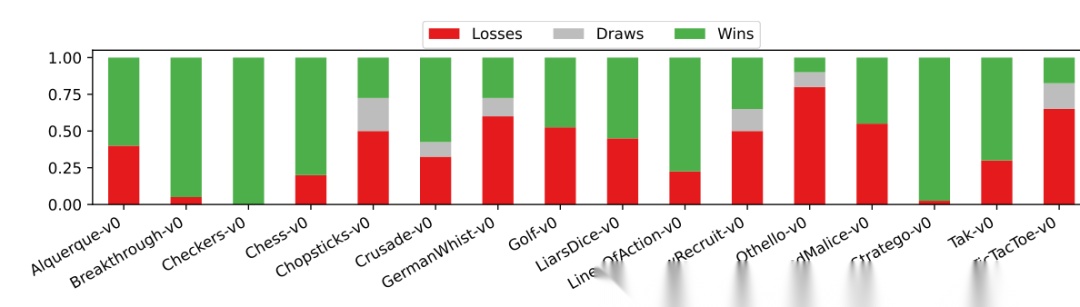
这张图对应Figure 3,展示的是 16 个双人游戏里,Gemini-2.5-Flash+Harness 对 Gemini-2.5-Pro 的胜负分布。
更有意思的是对战结果。
在 16 个双人游戏里,Gemini-2.5-Flash 加上 harness 后,打赢了 9 个游戏,对 Gemini-2.5-Pro 的整体胜率达到 56.3%;后者是 38.2%。
这其实是在说:
你不一定要先追求更大的底座模型。很多时候,一个更小但被系统结构保护好的模型,反而比“直接裸用的大模型”更能打。
这对行业的启发非常大,因为它动摇了一个默认假设:
性能提升不一定只能靠参数规模,也可以靠 agent architecture。
五、更激进的一步:连 LLM 推理都不要了,直接让代码当 policy
论文最有冲击力的部分,其实还不是前面,而是后面的 harness-as-policy。
这里作者把事情做得更彻底:
不只是让代码检查动作合不合法,而是直接让代码决定下一步该做什么。也就是说,测试时不再调用 LLM,整个策略就写在 Python 代码里。
这有点像把模型在某个环境里摸索出来的“做事方式”,蒸馏成一段可执行程序。
结果也非常夸张。
在 16 个单人游戏上,Harness-as-Policy 的平均 reward 达到 0.870,高于 Gemini-2.5-Pro 的 0.707,也高于 GPT-5.2-High 的 0.844。
而且论文特别强调了一点:GPT-5.2 和 GPT-5.2-High 的测试成本大约是 640 美元,而 Harness-as-Policy 在测试时几乎没有 LLM 成本,因为它本质上已经变成纯代码执行了。
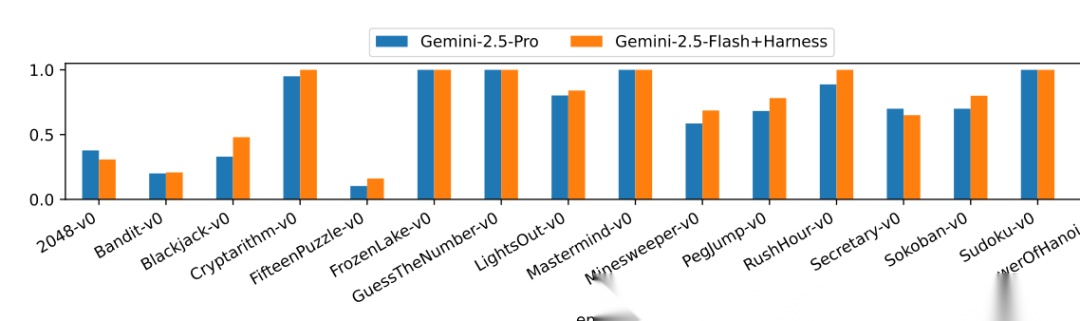
这张图对应Figure 4,比较的是单人游戏里 Gemini-2.5-Flash+Harness 和 Gemini-2.5-Pro 的 reward。
这件事真正厉害的地方在于,它不只是提升了正确率,还把推理成本结构一起改掉了。
六、这篇论文对 agent 设计最大的启发是什么
过去我们做 agent,太容易把所有问题都理解成“模型能力问题”;但 AutoHarness 说明,很多问题其实是“接口设计问题”“约束表达问题”“执行系统问题”。
一个 agent 至少有三层:
模型本身,负责生成。
外部环境,负责反馈。
中间那层 harness,负责把两者接起来。
很多团队把前两层卷得很厉害,却把第三层当成胶水代码随便处理。可这篇论文反过来证明,第三层也许正是最容易出 alpha 的地方。
如果把这个思路再往外推,你会得到几个很实际的方向:
第一,凡是存在明确约束、明确格式、明确规则边界的任务,都值得把约束外显成程序,而不是全丢给提示词。
第二,很多 agent 优化,不一定要先做 costly fine-tuning,也可以先做可验证的 harness learning。
第三,未来“模型生成代码,再由代码承担执行策略”的范式,可能会比“每一步都让大模型在线思考”更便宜,也更稳。
七、这篇论文也有边界
当然,这篇工作并不是在宣布“代码方法全面取代大模型”。
它至少有几个前提。
第一,它现在主要验证的是规则明确、反馈清晰的游戏环境。这类环境天然适合把合法性和策略结构化。
第二,它目前是“每个环境学一个 harness”,泛化能力还没有被证明。作者在结论里也明确写了,下一步希望把这些环境专属专家再蒸馏回基础模型,或者建立可复用的 harness 库。
第三,双人博弈里如果需要复杂的对手建模和搜索,单靠静态代码 policy 未必够,论文自己也承认 2P 场景更难。
所以更准确的理解不是:
“以后不用更强模型了。”
而是:
“在可验证任务里,模型外的程序结构,可能是比继续堆参数更快见效的杠杆。”
结尾
如果只用一句话概括这篇论文:
AutoHarness 真正证明的,不是小模型突然比大模型更聪明了,而是一个被良好约束、良好包裹、良好校验的小模型,完全可能比一个裸奔的大模型更有战斗力。
它谈的不是抽象的“智能神话”,而是非常具体的 agent engineering:错误怎么被拦住,能力怎么被放大,成本怎么被重写。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献171条内容
已为社区贡献171条内容

所有评论(0)