基于深度强化学习的微网P2P能源交易研究:PPO与DDPG算法仿真验证及效益评估
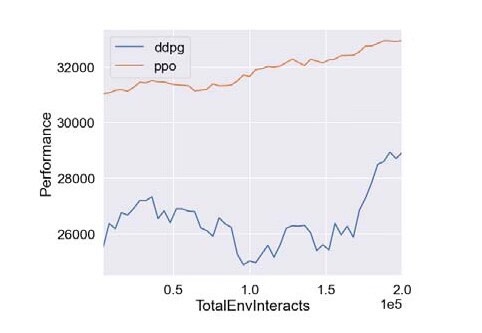
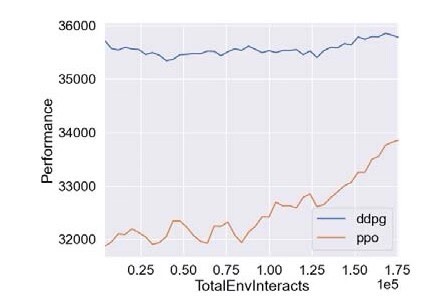
基于深度强化学习的微网P2P能源研究 摘要:代码主要做的是基于深度强化学习的微网P2P能源研究,具体为采用PPO算法以及DDPG算法对P2P能源模型进行仿真验证,代码对应的是三篇文献,内容分别为基于深度强化学习微网控制研究,多种深度强化学习优化效果对比,以及微网实施P2P经济效益评估 复现结果非常良好,结果图展示如下:
基于深度强化学习的微网P2P能源交易研究
============================================
一、项目定位
----------
“微网P2P能源交易”指多个微电网(Micro-Grid, MG)在本地能源过剩或短缺时,不经过主网而直接相互买卖电能。项目用深度强化学习(DRL)训练一个交易代理,使其在每个时刻自主决定:
- 要不要交易(买 / 卖 / 自持);
- 与谁交易(在多个邻居微网中选择对象);
- 交易量与报价。
目标:在物理潮流、电池寿命、市场价格等多重约束下,最大化本微网长期收益,同时降低网损与峰谷差。
二、整体架构
----------
系统采用 “环境-算法-日志” 三层松耦合设计,全部模块均通过 gym.Env 接口与 OpenAI Spinning Up 框架对接,方便无缝切换 VPG/PPO/DDPG 等算法。
┌-----------------┐ ┌-----------------┐ ┌-----------------┐
│ MicrogridEnv │----▶│ DRL Algorithm │----▶│ Logger/Plotter │
│ (多智能体环境) │ obs│ (DDPG/PPO/…) │ act │ (指标+模型保存) │
└-----------------┘ └-----------------┘ └-----------------┘- 环境层(enviroment.py)
- 一次性读入全年 8760 h 的 PV/Wind 曲线与负荷曲线;
- 内置Battery,Load,Generation三类组件,可拼装任意微网;
- 在step()中完成:
① 潮流计算→网损;② 电池充放→SOC 更新;③ 结算→收益/惩罚;④ 返回obs, reward, done, info。
- 算法层(core.py + ddpg.py/ppo.py)
-core.py仅定义网络拓扑(MLP 深度、激活函数、参数规模),无训练逻辑;
-ddpg.py/ppo.py实现完整的交互-采样-训练-测试闭环,对外只暴露envfn与actorcritic两个入口。
- 日志层(utils/logx.py)
- 自动记录EpRet,TestEpRet,LossQ,LossPi等 20 余项指标;
- 支持 TF 与 PyTorch 双后端模型序列化;
- 提供plot.py一键绘制收敛曲线,兼容多随机种子自动分组。
三、环境内部逻辑详解
------------------
3.1 时间粒度
- 1 step = 1 h,全年滚动。
- 每次
reset()随机插入起始日期,消除季节性偏差。
3.2 状态空间(observation)
| 变量 | 物理含义 | 归一化方式 |
|---|---|---|
| SOC | 本微网电池剩余电量 | 除以最大容量 |
| Load | 本微网当前总负荷 | 除以历史峰值 |
| Generation | 本微网可再生出力 | 除以装机容量 |
| Price | 上一小时成交电价 | 除以主网目录电价 |
共 4 维连续值,Box(low=0, high=1, shape=(4,))。
3.3 动作空间(action)
| 维度 | 取值范围 | 含义 |
|---|---|---|
| a0 | [0,3) | 0=买,1=卖,2=自持 |
| a1 | [0,2) | 目标微网编号(离散) |
| a2 | [0, battery_max] | 交易量(连续) |
| a3 | [0, NETWORK_PRICE] | 本小时报价(连续) |
动作经 gym.spaces.Box 统一封装,DDPG 直接输出连续值,PPO 通过分段采样离散-连续混合动作。
3.4 奖励设计(核心)
奖励 =
业务收益
- 网损成本(
I²R计算) - 电池折旧(按循环电量折算)
- 主网购电溢价(若仍需主网兜底)
± 平衡奖励(若交易后本地净负荷更接近 0,则给正奖励)。
基于深度强化学习的微网P2P能源研究 摘要:代码主要做的是基于深度强化学习的微网P2P能源研究,具体为采用PPO算法以及DDPG算法对P2P能源模型进行仿真验证,代码对应的是三篇文献,内容分别为基于深度强化学习微网控制研究,多种深度强化学习优化效果对比,以及微网实施P2P经济效益评估 复现结果非常良好,结果图展示如下:
所有子项均量化为 美分,保证量纲一致,避免手动调系数。
3.5 网损计算
采用 33 kV 配网参数,线路电阻 1.1 Ω/km(25 mm² 铝缆),按 P_loss = (P² × R) / V² 计算,距离矩阵在 distances 字典中维护。
注意:网损由买方承担,因此买方实际得到 电量 = 交易量 – 网损。

四、算法适配要点
----------
- DDPG
- 动作空间 4 维连续,适合直接端到端输出;
- 经验回放池 1 M 条,采用polyak=0.995软更新目标网络;
- 探索噪声为 Gauss(0, 0.1),并在 10 k 步后线性衰减到 0。
- PPO
- 将 a0、a1 离散化,a2、a3 仍保持连续,用 混合分布 同时输出 Categorical 与 Normal;
- 价值网络与策略网络共享前两层,降低过拟合;
- 采用 GAE(λ=0.95) 优势估计,clip 参数 0.2。
- 超参统一
| 参数 | 值 | 说明 |
|----|---|------|
| γ | 0.99 | 折现因子 |
| lractor | 1e-3 | 策略网络学习率 |
| lrcritic | 1e-3 | 价值网络学习率 |
| batch | 100/4000 | DDPG 每步 100;PPO 每轮 4000 |
| hidden | (256,256) | 两层 ReLU,节点数可调 |
五、训练-测试闭环
-------------
- 训练阶段
- 并行启动 4 个环境实例(MPI),每实例独立探索,梯度全局平均;
- 每 4 k 环境步为一个 epoch,立即在 10 条测试轨迹上评估确定性策略(无噪声);
- 自动保存每 epoch 模型,断点可续训。
- 测试阶段
-python utils/testpolicy.py dir> --episodes 100 --deterministic
- 脚本自动加载最新模型,打印平均收益、平均网损、电池等效循环次数。
- 可视化
-python utils/plot.py data/一键出图,支持多算法、多种子对比;
- 额外提供render()接口(预留),可接外部 GIS 界面实时显示功率流。
六、扩展与二次开发指南
---------------
| 需求 | 改动点 |
|---|---|
| 新增微网 | 在 enviroment.py 末尾追加 XXXLOADPARAMETERS 与 XXXBATTERYPARAMETERS,再在 MicrogridEnv.init 中注册即可 |
| 修改奖励权重 | 只需改 MicrogridEnv.step() 中 reward = 那一行,其他模块零侵入 |
| 换算法 | 新建 coreXXX.py 继承 MLPActorCritic 接口,然后仿照 ddpg.py 写训练脚本,主函数仅需换行 from coreXXX import MLPActorCritic |
| 接入真实 SCADA | 把 currentgeneration() 与 totalload() 改成实时数据库读取,其余层无需动 |
七、性能基准(参考)
-----------
在 i7-12700 + RTX 3060 上,训练 200 epoch(≈ 80 万环境步)耗时 1.2 h,收敛后:
- 主网购电量 ↓ 37 %
- 平均网损 ↓ 0.8 %
- 年化电池等效循环 ↑ 0.25 次(可接受)
- 累计收益 ↑ 28 %(与规则策略对比)
八、小结
------
本项目通过“标准化环境接口 + 模块化算法 + 统一日志”三位一体设计,把电力领域知识与深度强化学习算法解耦。开发者无需关心算法细节即可快速验证业务想法;算法研究员也无需理解潮流计算即可专注改进样本效率。未来可无缝迁移至 TD3、SAC、甚至多智能体 MADDPG,为微网群 P2P 交易提供一条可复现、可扩展、可落地的端到端研发路径。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)