[CVPR 2024] Unleashing the Potential of SAM for Medical Adaptation via Hierarchical Decoding
CVPR 2024 | 碾压半监督SOTA!H-SAM:基于分层解码释放SAM的医疗分割潜能
论文题目:Unleashing the Potential of SAM for Medical Adaptation via Hierarchical Decoding
发表出处:CVPR 2024
作者机构:Zhiheng Cheng 等 (华东师范大学,斯坦福大学,约翰斯·霍普金斯大学等)
关键词:Medical Image Segmentation, Segment Anything Model (SAM), Prompt-free, Hierarchical Decoding
1. 🚀 省流版摘要 (TL;DR)
为了解决 Segment Anything Model (SAM) 在医疗图像上水土不服且依赖高质量人工提示(Prompt)的痛点,本文提出了一种专为医疗图像微调设计的免提示(Prompt-free)变体 H-SAM。该模型通过引入两阶段分层解码器(Two-stage Hierarchical Decoding),第一阶段先生成一个先验概率掩码,以此引导第二阶段进行更精细的解码。最惊艳的是,在极少样本(Few-shot)的情况下,H-SAM 即使完全不使用无标签数据,也能直接击败那些依赖大量无标签数据进行训练的最先进(SOTA)半监督方法。
2. 🧐 背景与痛点 (Motivation)
- 现有问题:SAM 在自然图像上表现出了惊人的零样本(Zero-shot)泛化能力,但在面对未见过的医疗图像特征时,其准确性和鲁棒性会显著下降。
- 传统方法的局限:
- 如果仅在医疗数据集上对 SAM 进行全参数微调,不仅训练成本极高,还容易陷入单一样本集过拟合的风险。
- 当前主流的微调方法(如加 Adapter)大多需要医生在测试时手动提供点或框作为提示(Prompt),这不仅耗时耗力,而且容易引入噪声。
- 现有的免提示(Prompt-free)SAM 变体(如 SAMed)由于缺乏医学先验知识的引导,性能通常不如那些带提示的方法。
- 本文的切入点:既然免提示方法缺少目标指引,我们能不能让模型自己“生成”提示?作者巧妙地利用 SAM 原本的解码器在第一阶段生成一个先验掩码(Prior Mask),然后基于这个先验知识,通过精心设计的注意力机制去引导下一阶段的精准分割。
3. 💡 核心方法 (Methodology)
3.1 整体架构 (Overall Architecture)
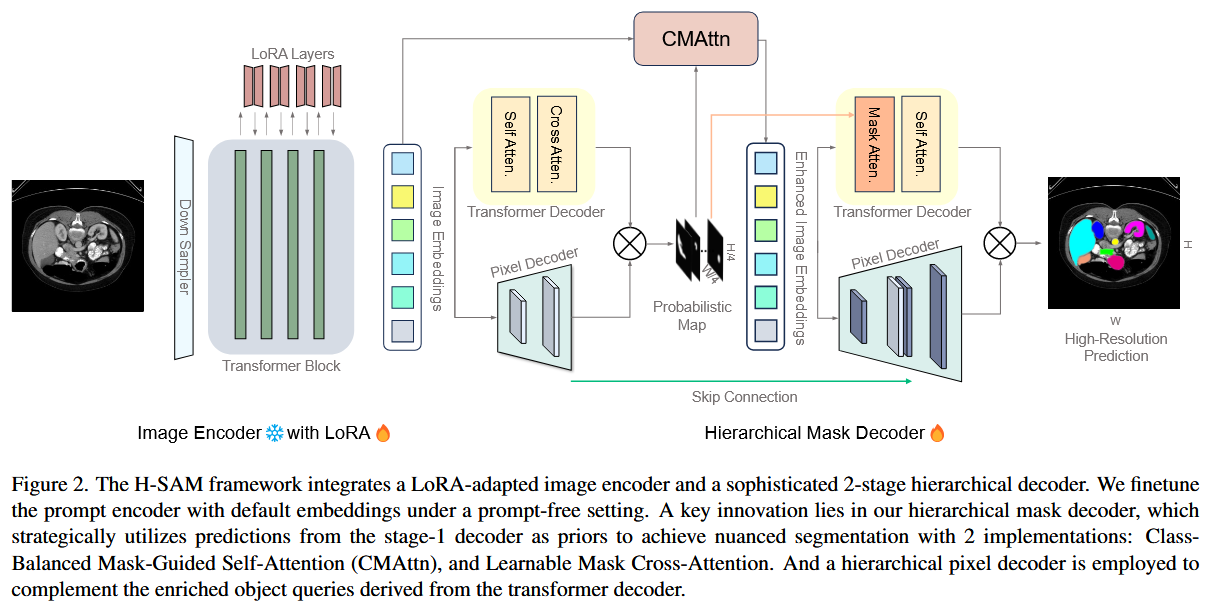
[插图占位:论文中的 Figure 2,H-SAM 包含带有 LoRA 的图像编码器和分层掩码解码器整体框架]
H-SAM 保持了 SAM 庞大的图像编码器参数冻结,仅在其中插入了轻量级的 LoRA 层以防止过拟合。其真正的杀手锏在于两阶段分层掩码解码器:
- 第一阶段:使用 SAM 原始的轻量级解码器,输出一个粗略的先验概率掩码(Prior Probabilistic Mask)。
- 第二阶段:利用第一阶段的先验掩码,通过以下两个核心模块深度挖掘特征空间,实现精准分割。
3.2 关键模块详解 (Key Modules)
-
模块 A:类别平衡的掩码引导自注意力 (Class-Balanced Mask-Guided Self-Attention, CMAttn)
在多器官分割中,经常会遇到类别极度不平衡的问题(大器官像素多,小器官像素极少)。CMAttn 利用第一阶段的掩码特征来增强输入到第二阶段的图像特征。为了解决长尾问题,作者采用了一种基于对数调整的特征增强方法,为小类别引入更多变体:P(gt=i)+=N(0,var(i))P(gt=i)+=\mathcal{N}(0,var(i))P(gt=i)+=N(0,var(i))
即在掩码特征上叠加均值为0的高斯噪声,且该噪声的方差与该类别的样本频率成反比。
-
模块 B:可学习的掩码交叉注意力 (Learnable Mask Cross-Attention)
传统的掩码注意力往往只是使用二值化的掩码(只有 0 和 1),这会导致梯度消失,且无法区分前景中不同区域的重要性。H-SAM 提出使用未经过二值化转换的概率图,通过逐元素相乘将其直接作用于交叉注意力的显著图上。X=M⊙softmax(KQT)V+XX = M \odot \text{softmax}(KQ^T)V + XX=M⊙softmax(KQT)V+X
这种设计不仅解决了梯度截断的问题,还能根据概率分布在空间上智能地抑制背景噪声。
-
模块 C:分层像素解码器 (Hierarchical Pixel Decoder)
由于原始 SAM 的解码器只输出原图 1/41/41/4 分辨率的特征图,很容易丢失微小的医疗病灶细节。因此,作者受到 U-Net 架构的启发,在两个阶段的像素解码器之间引入了跳跃连接(Skip Connections),逐步恢复局部细节特征,最终输出原图同等分辨率的高精度预测。
4. 📊 实验与结果 (Experiments)
- 数据集:使用了 Synapse-CT(多器官分割)、LA(左心房 MRI 分割)和 PROMISE12(前列腺 MRI 分割)三大知名数据集。
- 少样本下的惊人表现:
- 在 Synapse 多器官数据集中,仅仅使用了 10% 的训练切片数据,H-SAM 就达到了 80.35% 的平均 Dice,比现有的免提示 SAM 变体(如 AutoSAM, SAMed)高出了惊人的 4.78%。
- 在 PROMISE12 和 LA 数据集中,H-SAM 分别仅使用了 3 个和 4 个有标签病例进行训练。在完全不接触额外无标签数据的情况下,它的表现(Dice 分别为 87.27% 和 89.22%)居然超越了诸如 UA-MT、BCP 等动用了大量(数十个)无标签数据进行训练的顶级半监督网络。
- 消融实验:数据表明,CMAttn 解决了长尾分布,可学习掩码交叉注意力提升了 2.1% 的性能,而分层像素解码器通过 U-Net 式连接进一步提升了 2.2% 的精度。
5. 🧠 笔者思考与总结 (Conclusion & Thoughts)
对于深耕计算机视觉和医学图像分析的同行们来说,这篇文章提供了一个极其巧妙的工程范式。相比于我们之前讨论过的依赖于在线推断实时更新的方案,H-SAM 走的是另外一条优雅的路线:“用魔法打败魔法,用 SAM 的初级预测来做高级 Prompt”。
- 亮点总结:H-SAM 的成功在于它深刻理解了 SAM 的结构缺陷,并没有盲目扩大参数量,而是将“粗筛 -> 精修”的人类医生诊断逻辑内化为了两阶段解码。其核心的 CMAttn 噪声注入机制完美化解了长尾器官类别的不平衡难题。
(本文由AI辅助解读,仅供参考,详细内容请查阅原论文)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)