《Attention Is All You Need》读书报告
一、 论文基本信息
-
论文标题:Attention Is All You Need
-
作者团队:Ashish Vaswani, Llion Jones, Noam Shazeer 等(主要来自 Google Brain 和 Google Research)
-
发表时间:2017年(NIPS 2017)
-
核心贡献:提出了一种全新的、完全基于注意力机制(Attention Mechanism)的网络架构——Transformer,彻底抛弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)。
二、 研究背景与动机
在 Transformer 提出之前,主流的序列转录模型(如机器翻译)严重依赖于复杂的循环神经网络(RNN,如 LSTM、GRU)或卷积神经网络(CNN),并采用 Encoder-Decoder(编码器-解码器)架构。
传统架构的痛点:
-
难以并行化(RNN的致命伤):RNN 的本质是序列计算,计算当前状态
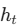 必须依赖上一个状态
必须依赖上一个状态 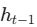 。这种顺序特性导致模型无法在训练样本内部进行高度并行化,严重限制了计算效率,尤其是在处理长序列时。
。这种顺序特性导致模型无法在训练样本内部进行高度并行化,严重限制了计算效率,尤其是在处理长序列时。 -
长距离依赖问题:虽然 LSTM 缓解了梯度消失问题,但在极长的序列中,相隔很远的两个词建立联系仍然非常困难。
-
CNN的局限性:虽然基于 CNN 的模型(如 ByteNet, ConvS2S)可以并行计算,但关联两个相距较远的输入位置需要堆叠大量的卷积层,导致长距离依赖的学习变得极其困难。
为了解决这些问题,作者提出了**“仅仅需要注意力机制”**的破局思路。
三、 核心架构剖析:Transformer
Transformer 依然采用了 Encoder-Decoder 的整体架构,但内部的子层发生了翻天覆地的变化。
1. 缩放点积注意力 (Scaled Dot-Product Attention)
这是 Transformer 的最小运算单元。它将输入映射为三个向量:Query (Q,查询), Key (K,键) 和 Value (V,值)。
其数学表达式为:
-
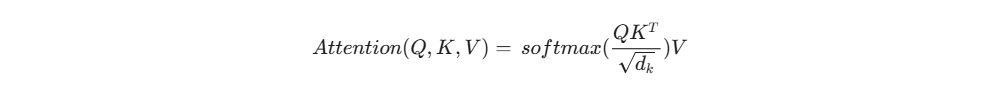 为什么要除以
为什么要除以 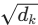 (缩放因子)?
(缩放因子)?
作者发现在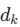 (Key的维度)较大时,点积的结果会变得非常大,导致传入 softmax 函数后落入梯度极小的区域(梯度消失)。除以维度的平方根可以平滑 softmax 的输出,保持梯度的稳定。
(Key的维度)较大时,点积的结果会变得非常大,导致传入 softmax 函数后落入梯度极小的区域(梯度消失)。除以维度的平方根可以平滑 softmax 的输出,保持梯度的稳定。
2. 多头注意力 (Multi-Head Attention)
作者没有直接对整个高维向量做一次 Attention,而是将 Q、K、V 通过不同的线性变换投影到多个低维子空间中,分别计算 Attention,最后再拼接起来。
-
优势:允许模型在不同的表示子空间(Representation Subspaces)中并行地关注不同位置的信息。例如,有的“头”可能关注语法结构,有的“头”可能关注指代消解。
3. 三种不同的注意力应用场景
-
编码器自注意力 (Encoder Self-Attention):Q, K, V 均来自编码器的上一层。序列中的每个词都可以关注序列中的所有其他词。
-
解码器自注意力 (Decoder Self-Attention):加入了一个 Mask(掩码)机制。为了保持自回归特性(预测当前词时不能“偷看”未来的词),模型将未来位置的注意力得分设为
 。
。 -
编码器-解码器注意力 (Encoder-Decoder Attention):Q 来自上一个解码器层,而 K 和 V 来自编码器的输出。这让解码器在生成每个词时,都能去关注输入序列中最相关的部分。
4. 位置编码 (Positional Encoding)
既然抛弃了 RNN 和 CNN,模型就失去了感知序列顺序(“你打我”和“我打你”)的能力。为了弥补这一点,作者巧妙地引入了位置编码。
-
使用了不同频率的正弦和余弦函数:

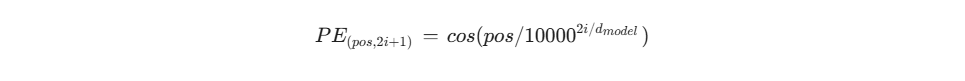
-
妙处:这种绝对位置编码允许模型学习到相对位置关系,因为对于任何固定的偏移量
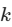 ,
, 都可以表示为
都可以表示为  的线性函数。此外,它也能很好地外推到训练时未见过的更长序列。
的线性函数。此外,它也能很好地外推到训练时未见过的更长序列。
5. 其他关键组件
-
位置前馈网络 (Position-wise FFN):在 Attention 层之后接两个线性变换(中间夹一个 ReLU),分别独立应用于每个位置,增加非线性。
-
残差连接与层归一化 (Add & Norm):解决深层网络训练的退化问题,加速收敛。
四、 为什么选择自注意力?(核心优势)
论文中通过图表(Table 1)详细对比了 Self-Attention、RNN 和 CNN 的性能差异,揭示了 Transformer 胜出的三个决定性因素:
-
最大路径长度为
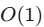 :在序列中任意两个位置之间传递信息的路径长度始终为 1。这彻底解决了长距离依赖的学习难题。
:在序列中任意两个位置之间传递信息的路径长度始终为 1。这彻底解决了长距离依赖的学习难题。 -
串行操作数量为
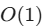 :完全打破了 RNN
:完全打破了 RNN  的串行瓶颈,支持矩阵乘法级别的高效全局并行计算。
的串行瓶颈,支持矩阵乘法级别的高效全局并行计算。 -
计算复杂度:当序列长度
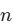 小于表示维度
小于表示维度 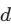 时(NLP任务中的常态),自注意力层的每层计算复杂度实际上低于 RNN。
时(NLP任务中的常态),自注意力层的每层计算复杂度实际上低于 RNN。
五、 实验结果
-
机器翻译(核心任务):
-
在 WMT 2014 英语-德语任务上,Transformer (big) 取得了 28.4 BLEU 的历史新高(当时),超越了之前所有的集成模型。
-
在英语-法语任务上取得了 41.8 BLEU。
-
惊人的效率:训练成本(FLOPs)和耗时只有以往主流模型(如 GNMT)的一小部分。8张 P100 GPU 仅需 3.5 天。
-
句法分析(泛化能力):
在没有进行大量任务特定调优的情况下,在 English Constituency Parsing 任务上也取得了极佳的成绩,证明了其通用性。
六、 总结与深刻启发
《Attention Is All You Need》之所以伟大,不仅在于它刷新了当时的各种榜单,更在于它展现了一种极致的架构美学——大道至简。它证明了复杂的序列处理并不需要复杂的递归和卷积结构,仅仅通过并行化的注意力矩阵运算,结合位置编码和前馈网络,就能达到前所未有的高度。
深远影响:
这篇论文犹如普罗米修斯盗取的火种,直接点燃了随后的“大模型时代”。从 BERT 的双向编码器,到 GPT 系列的单向解码器,再到如今改变世界的 ChatGPT,其底层的绝对核心依然是这座名为 Transformer 的大厦。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)