告别 python-docx:用纯 Python 标准库实现的一个 Word 转 Markdown 的工具-超好用(附源码)
前言
在日常工作中,我们经常需要将 Word 文档转成 Markdown——比如把技术文档发布到博客,或者把论文转成纯文本方便版本管理。市面上现有的方案通常依赖 python-docx、pandoc 或 mammoth 等第三方库,要么安装链条长,要么转换结果不够理想(丢标题层级、编号乱掉、图片丢失……)。
我想做一件事:仅用 Python 标准库(xml.etree.ElementTree + zipfile),直接拆 .docx 的 XML,精准还原 Word 文档的结构到 Markdown。
感恩AI加持,快速实现了 docx2md —— 一个零转换依赖、支持命令行与 Web 双界面的 Word 转 Markdown 工具。这篇文章记录整个实现过程。
在线体验:点击立即体验 DocX 转 Markdown (在线体验的前端是另外工程维护,为最新代码,本文完成后,界面可能有更新)
项目已开源,欢迎试用、反馈、点赞、关注,源码地址:GitHub - doc2md
转换前端界面如下:

一、.docx 文件到底是什么?
很多人以为 .docx 是一个二进制文件,其实不是——它本质上就是一个 ZIP 压缩包,里面装着一堆 XML 文件。把任意 .docx 文件重命名为 .zip,解压后你会看到这样的结构:
document.docx (ZIP)
├── [Content_Types].xml
├── word/
│ ├── document.xml ← 文档正文(段落、表格、图片引用)
│ ├── styles.xml ← 样式定义(标题级别、字体、段落格式)
│ ├── numbering.xml ← 编号定义(自动编号格式、起始值)
│ ├── _rels/
│ │ └── document.xml.rels ← 资源关系表(图片路径、超链接目标)
│ └── media/
│ ├── image1.png ← 嵌入的图片
│ └── image2.jpg
└── ...
核心思路就清晰了:用 zipfile 打开压缩包,用 xml.etree.ElementTree 解析 XML,逐个元素翻译成 Markdown。
import zipfile
import xml.etree.ElementTree as ET
with zipfile.ZipFile("document.docx") as zf:
doc_xml = zf.read("word/document.xml")
root = ET.fromstring(doc_xml)
# 接下来遍历 XML 元素...
听起来简单,但真正的挑战在于 Word XML 的复杂度——尤其是标题层级、自动编号和样式继承。
二、核心挑战:标题层级怎么判断?
放弃 “按名字匹配”
最容易想到的思路是匹配样式名称——如果段落的样式叫 “Heading 1” 就算一级标题。但这个方案很脆弱:用户完全可以把 “Heading 1” 改名为 “我的大标题”,匹配就失效了。
正解:outlineLvl 属性
Word 内部判断标题层级,靠的并不是样式名称,而是一个叫 outlineLvl(大纲级别)的 XML 属性。这个属性存储在 styles.xml 中:
<w:style w:type="paragraph" w:styleId="Heading1">
<w:pPr>
<w:outlineLvl w:val="0"/> <!-- 0 = H1, 1 = H2, ... -->
</w:pPr>
</w:style>
不管用户怎么改样式名,outlineLvl 的值不会变。我的实现就是读这个属性来判断标题级别:
outlineLvl = 0→# H1outlineLvl = 1→## H2outlineLvl = 5→###### H6outlineLvl ≥ 6或无此属性 → 正文段落
样式继承链
Word 的样式支持继承(basedOn),比如 “Heading 2” 可能继承自 “Heading 1”,而 “Heading 1” 又继承自 “Normal”。要正确拿到 outlineLvl,必须沿着继承链向上追溯:
def _resolve_outline_level(self, style_id):
visited = set()
while style_id and style_id not in visited:
visited.add(style_id)
style = self._styles.get(style_id)
if style and style.get("outlineLvl") is not None:
return style["outlineLvl"]
style_id = style.get("basedOn") if style else None
return None
用 visited 集合防止循环继承导致无限递归——虽然正常文档不会有这种情况,但做防御性处理总没坏处。
三、最复杂的部分:自动编号
如果说标题层级是"有点麻烦",那自动编号就是"真正的Hard模式"。Word 的编号系统涉及三层 XML 结构,加上格式模板、计数器状态管理、Legal 编号模式……这是整个项目最复杂的模块。
编号系统架构
Word 的编号由三层结构组成:
numbering.xml
├── abstractNum (抽象编号定义)
│ ├── lvl ilvl="0": numFmt="chineseCounting", lvlText="第%1章"
│ ├── lvl ilvl="1": numFmt="decimal", lvlText="%1.%2"
│ └── lvl ilvl="2": numFmt="decimal", lvlText="%1.%2.%3"
│
├── num numId="1" → abstractNumId="0" (具体编号实例)
│ └── 可选 lvlOverride (覆盖某些层级的格式或起始值)
│
└── 段落通过 numPr 引用:
<w:numPr>
<w:numId w:val="1"/>
<w:ilvl w:val="0"/>
</w:numPr>
- abstractNum 定义编号的"模板"——每个层级用什么格式(中文、罗马数字、阿拉伯数字),文本模板是什么(
"第%1章"、"%1.%2.%3") - num 是具体的编号实例,指向某个 abstractNum,并且可以覆盖部分设置
- 段落 通过
numPr引用 numId + ilvl(层级)
格式模板展开
编号的文本模板类似于 printf 格式化。比如 "第%1章" 中的 %1 表示第 1 层级的当前计数值。"%1.%2.%3" 表示用点号连接三个层级的计数。
def _format_level_text(self, lvl_text, ilvl, counters, levels_info):
result = lvl_text
for i in range(ilvl + 1):
placeholder = f"%{i + 1}"
if placeholder in result:
counter_val = counters.get(i, 1)
formatted = self._format_number(counter_val, fmt)
result = result.replace(placeholder, formatted)
return result
其中 _format_number() 需要支持多种编号格式:
| numFmt 值 | 输出示例 |
|---|---|
decimal |
1, 2, 3 |
chineseCounting / koreanDigital2 |
一, 二, 三 |
upperRoman |
I, II, III |
lowerLetter |
a, b, c |
bullet |
• (无序列表) |
计数器管理
编号计数的核心逻辑:当父级别递增时,所有子级别的计数器必须重置。
第一章 (ilvl=0, counter=1)
1.1 (ilvl=1, counter=1)
1.2 (ilvl=1, counter=2)
第二章 (ilvl=0, counter=2)
2.1 (ilvl=1, counter=1) ← 自动重置!
2.2 (ilvl=1, counter=2)
这个逻辑在代码中的实现是:当某个 ilvl 的计数器递增时,清除所有 > ilvl 的计数器条目。
Legal 编号模式(isLgl)
Word 有一个不太常见但很重要的功能叫 Legal Numbering。启用时,上级层级的占位符会强制转为阿拉伯数字,而当前层级保持自己的格式。比如章节标题用中文(“第一章”),但小节编号中引用章节号时变成阿拉伯数字(“1.1” 而不是 “一.1”)。这个细节的正确处理让文档转换出来的编号更接近 Word 原始显示效果。
四、其他内容元素的处理
表格
Word 的表格是 <w:tbl> → <w:tr> → <w:tc> 的嵌套结构。转换策略:
| 列1 | 列2 | 列3 |
|-----|-----|-----|
| 数据 | 数据 | 数据 |
关键细节:
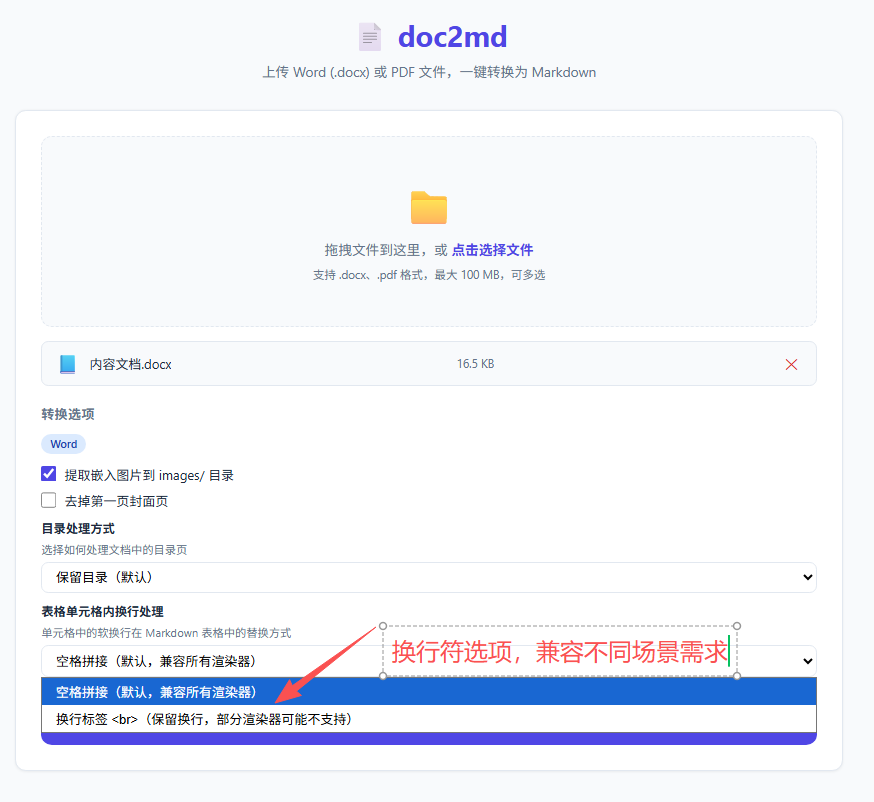
- 单元格内的
|字符必须转义为\|,否则会破坏 Markdown 表格结构 - 单元格内的多段落(换行)提供两种模式:用空格合并(兼容性好),或用
<br>保留(结构清晰)
图片
图片的提取链条比较长:
document.xml 中的 <w:drawing>
→ 找到 <a:blip r:embed="rId5">
→ 查 document.xml.rels 得到 rId5 → "media/image1.png"
→ 从 ZIP 中读取 word/media/image1.png
→ 保存到输出目录 images/image_001.png
一个有趣的细节:Word 有时会在图片的 alt text 中插入 AI 生成的描述附带免责声明(“AI 生成的内容可能不正确”),代码中会自动清理这类文本。
超链接
超链接也依赖 document.xml.rels 关系表。段落中的 <w:hyperlink r:id="rId7"> 对应到关系表中的外部 URL,最终转为 [链接文字](https://example.com) 格式。
内联格式
| XML 属性 | Markdown |
|---|---|
<w:b/> |
**加粗** |
<w:i/> |
*斜体* |
<w:b/> + <w:i/> |
***粗斜体*** |
<w:strike/> |
~~删除线~~ |
| 等宽字体 (Consolas 等) | `代码` |
需要注意的是,Word 中属性的"开关"写法:<w:b/> 表示开启加粗,而 <w:b w:val="0"/> 表示显式关闭加粗——不能简单地看标签是否存在。
五、封面、目录与摘要的智能处理
学术论文场景下,通常希望在转 Markdown 时去掉封面页和目录页。这需要在 XML 层面准确识别它们。
封面检测
封面页的终止标志是第一个分页符——Word 会在封面和正文之间插入强制分页:
<w:br w:type="page"/>
<!-- 或节分页 -->
<w:sectPr><w:type w:val="nextPage"/></w:sectPr>
找到第一个分页符的位置,之前的全部内容就是封面。
目录检测(三重策略)
目录在 Word XML 中可能以三种形式出现,代码用三种策略逐一检查:
- SDT(结构化文档标签):
<w:sdt>中包含<w:docPartGallery w:val="Table of Contents"/> - 段落样式:样式 ID 匹配
TOC1–TOC9、TOCHeading等 - 域代码:
<w:instrText>中包含"TOC"关键字
摘要保留
在 before_toc_keep_abstract 模式下,虽然会删除目录之前的所有内容,但会智能保留"摘要"和"Abstract"对应的段落。识别方式是扫描标题文本中包含 “摘要” 或 “Abstract” 关键词的段落及其后续正文内容。
四种目录处理模式
| 模式 | 效果 |
|---|---|
none |
保留所有内容 |
toc_only |
只移除目录条目 |
before_toc |
移除目录及其之前的全部内容 |
before_toc_keep_abstract |
移除目录及之前内容,但保留摘要 |
六、Web 界面实现
除了命令行工具,我还用 Flask 做了一个 Web 界面,方便不熟悉命令行的用户使用。
整体架构
浏览器 (index.html)
├─ 拖拽/选择文件上传
├─ 设置转换选项
├─ POST /convert → 后端转换
├─ 接收 JSON 结果 → 渲染预览
└─ GET /download/<id> → 下载文件
后端只有 5 个核心路由:
| 路由 | 功能 |
|---|---|
GET / |
渲染上传页面 |
POST /convert |
接收文件、转换、返回预览 JSON |
GET /download/<id> |
下载 .md 或 .zip |
GET /files/<id>/<path> |
提供图片资源服务 |
GET /health |
健康检查 |
前端页面展示
前端是一个单页应用,所有功能集中在一个 HTML 文件中,使用原生 JavaScript(无框架依赖)。
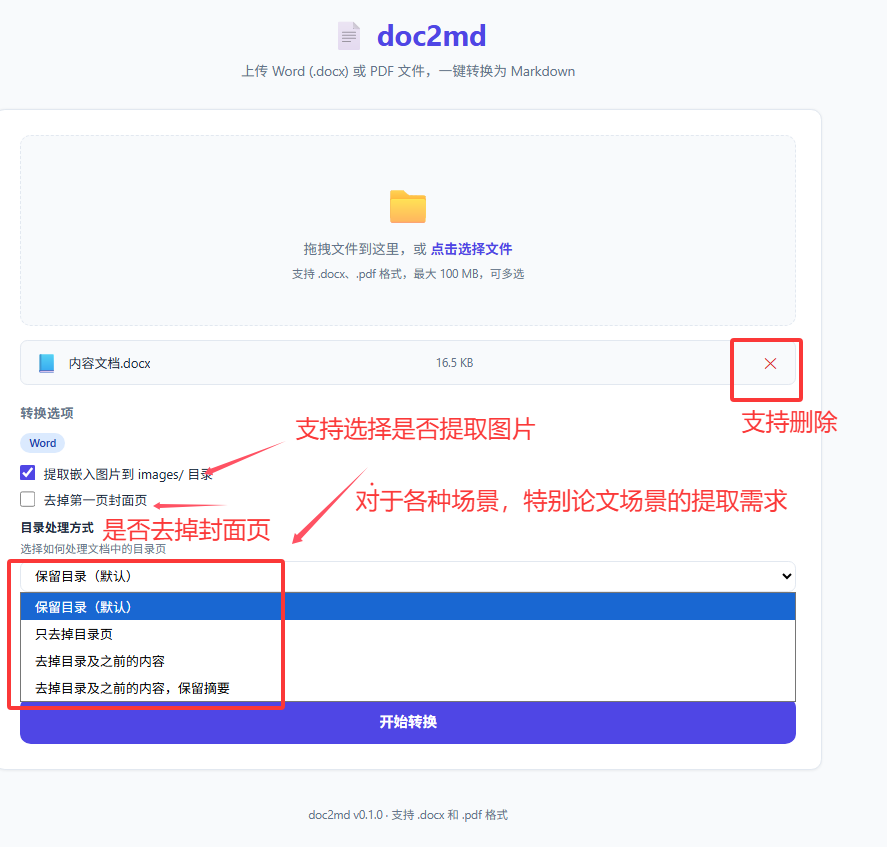
上传区域
拖拽或点击上传 .docx 文件,支持多文件批量上传。上传后显示文件列表,包含文件名、大小信息和删除按钮。
转换选项
选择文件后会展开选项面板:
- ✅ 提取嵌入图片
- ✅ 去掉第一页(封面)
- 🔽 目录处理模式(4 种可选)
- 🔽 表格单元格换行方式(空格 /
<br>)
转换与预览
点击"开始转换"后,页面显示进度条。转换完成后自动切换到预览区域,提供两种视图:
- 源码视图:显示原始 Markdown 文本,深色背景代码风格
- 渲染预览:使用
marked.js将 Markdown 渲染为 HTML,直接在页面内预览效果
多文件时顶部会出现 Tab 标签页切换。


下载与复制
预览区域底部提供:
- 📋 一键复制 Markdown 源码到剪贴板
- ⬇️ 智能下载:单文件无图片 → 直接下载
.md;有图片或多文件 → 打包为.zip 
前端关键技术细节
图片路径重写:预览时,Markdown 中的相对图片路径(如 images/image_001.png)需要重写为服务器的资源路由 /files/{result_id}/{filename}/images/image_001.png,这样图片才能在浏览器中正确显示。
文件清理:后端维护一个内存字典存储转换结果,后台线程每 60 秒检查一次,自动清理超过 10 分钟的结果和临时文件,避免磁盘占用累积。
七、项目结构
最终的项目结构非常精简:
doc2md/
├── pyproject.toml # 项目配置 & 依赖声明
├── requirements.txt # pip 依赖(仅 Flask)
├── README.md
├── templates/
│ └── index.html # Web 前端(~700 行,单文件 SPA)
└── converter/
├── __init__.py # 包元信息
├── cli.py # CLI 入口(argparse)
├── webapp.py # Flask Web 服务(~500 行)
├── word2md.py # 核心转换引擎(~850 行)
└── numbering.py # 编号与大纲解析(~550 行)
整个转换核心不到 1500 行代码,加上 Web 服务和 CLI 也不到 2500 行。唯一的第三方依赖是 Flask(用于 Web 界面),Word 转换本身完全基于标准库。
八、使用效果
命令行
# 单文件
doc2md paper.docx -o paper.md
# 论文场景:去封面、去目录、保留摘要
doc2md paper.docx --skip-cover --toc-mode before_toc_keep_abstract
# 批量转换
doc2md *.docx
Web 界面
python -m converter.webapp
# 浏览器打开 http://localhost:5000

总结
这个项目最大的收获是深入理解了 Word 的 XML 结构。.docx 看似复杂,但每个功能(标题、编号、图片、表格)都有明确的 XML 属性与之对应。只要找对了属性,转换逻辑就会非常精准——比依赖文本匹配或正则猜测可靠得多。
关键设计决策回顾:
- ✅ 用
outlineLvl而非样式名称判断标题 → 对用户自定义样式零敏感 - ✅ 直接解析 XML 而非依赖第三方库 → 零转换依赖、可控性强
- ✅ 多级编号共享计数器 + 子级自动重置 → 精确还原 Word 编号行为
- ✅ 前后端分离的预览机制 → 转换 + 预览一步到位
项目已开源,欢迎试用和反馈:GitHub - doc2md

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)