Scalable Diffusion Models with Transformers翻译
⚠️ 在开始阅读之前,如果你对 实时 Agent / 数字人 / 多模态系统 / LiveKit 架构 感兴趣,
欢迎先到 GitHub 给项目点一个 ⭐ Star,这是对开源作者最大的支持。
🚀 AlphaAvatar 项目地址(强烈建议先收藏,该项目正在持续更新维护):
👉 https://github.com/AlphaAvatar/AlphaAvatar
🚀 AIPapers 项目地址(具有更全的有关LLM/Agent/Speech/Visual/Omni论文分类):
👉 https://github.com/AlphaAvatar/AIPaperNotes
摘要
我们探索了一种基于 Transformer 架构的新型扩散模型。我们训练图像的潜在扩散模型,用一个作用于潜在图像块的 Transformer 网络替换了常用的 U-Net 骨干网络。我们通过前向传播复杂度(以Gflops衡量)来分析扩散 Transformer(DiT)的可扩展性。我们发现,通过增加Transformer 的深度/宽度或增加输入标记的数量来提高 Gflops 的 DiT,其 FID 值始终更低。除了具有良好的可扩展性之外,我们最大的 DiT-XL/2 模型在 ImageNet 512×512 和 256×256 基准测试中均优于所有先前的扩散模型,并在后者上实现了 2.27 的FID值,达到了目前最先进的水平。
1.介绍

机器学习正经历着一场由 Transformer 驱动的复兴。过去五年,自然语言处理、视觉以及其他多个领域的神经网络架构已基本被 Transformer 所取代。然而,许多图像级生成模型仍然未能跟上这一趋势——尽管 Transformer 在自回归模型中得到了广泛应用,但在其他生成建模框架中却鲜有采用。例如,扩散模型一直是图像级生成模型领域最新进展的前沿;然而,它们都采用了卷积 U-Net 架构作为默认的主干网络。
Ho et al. [19] 的开创性工作首次引入了用于扩散模型的 U-Net 骨干网络。U-Net 最初在像素级自回归模型和条件生成对抗网络 (GAN) 中取得了成功,之后在 PixelCNN++ 的基础上进行了一些修改。该模型是卷积神经网络,主要由 ResNet 模块组成。与标准 U-Net 不同的是,U-Net 在较低分辨率下穿插了额外的空间自注意力模块,这些模块是 Transformer 模型的重要组成部分。Dhariwal and Nichol [9] 对 U-Net 的架构选择进行了改进,例如使用自适应归一化层来注入条件信息以及卷积层的通道数。然而, Ho et al. 提出的 U-Net 的高层设计基本保持不变。
本文旨在阐明扩散模型中架构选择的重要性,并为未来的生成建模研究提供实证基准。我们发现,U-Net 的归纳偏置对扩散模型的性能并非至关重要,可以很容易地被诸如 Transformer 之类的标准设计所替代。因此,扩散模型能够很好地受益于近期架构统一的趋势——例如,通过借鉴其他领域的最佳实践和训练方法,同时保留可扩展性、鲁棒性和效率等优良特性。标准化的架构也将为跨领域研究开辟新的可能性。
本文重点介绍一类基于 Transformer 的新型扩散模型,我们称之为 Diffusion Transformer(简称DiT)。DiT 遵循 Vision Transformer(ViTs)的最佳实践,ViTs 已被证明在视觉识别方面比传统卷积网络(例如ResNet)更具扩展性。
更具体地说,我们研究了 Transformer 模型在网络复杂度和样本质量方面的扩展性。我们证明,通过在潜在扩散模型(LDM)框架下构建和评估 DiT 设计空间(其中扩散模型在 VAE 的潜在空间中训练),我们可以成功地用 Transformer 模型替换 U-Net 骨干网络。我们进一步证明,DiT 是扩散模型的可扩展架构:网络复杂度(以Gflops衡量)与样本质量(以FID衡量)之间存在很强的相关性。通过简单地扩展 DiT 并使用高容量骨干网络(118.6 Gflops)训练 LDM,我们能够在类别条件 256×256 ImageNet 生成基准测试中取得 2.27 FID 的最新结果。
2.Related Work
Transformers。Transformer 已在语言、视觉、强化学习和元学习等领域取代了特定领域的架构。它们在模型规模、训练计算量和数据量不断增加的情况下,在语言领域、作为通用自回归模型以及作为 ViTs 时,都展现出了卓越的扩展性。除了语言领域,Transformer 还被训练用于自回归预测像素。它们也被训练用于离散码本,既可以作为自回归模型,也可以作为掩码生成模型;前者在高达 20B 个参数的情况下也展现出了优异的扩展性。最后,Transformer 还被用于 DDPM 中以合成非空间数据;例如,在 DALL·E 2 中生成 CLIP 图像嵌入。本文研究了 Transformer 作为图像扩散模型骨干时的扩展性。
Denoising diffusion probabilistic models (DDPMs)。扩散模型和基于分数的生成模型作为图像生成模型取得了显著成功,在许多情况下甚至超越了此前最先进的生成对抗网络(GAN)。过去两年中,DDPMs 的改进主要得益于采样技术的进步,其中最显著的是无分类器引导、将扩散模型重新构建为预测噪声而非像素以及使用级联 DDPM 流水线,其中低分辨率基础扩散模型与上采样器并行训练。对于上述所有扩散模型,卷积 U-Net 是事实上的主干架构首选。同期,文献[24]提出了一种基于注意力机制的新型高效 DDPM 架构;我们则探索了纯 Transformer 架构。
Architecture complexity。在评估图像生成文献中的架构复杂度时,使用参数数量是一种相当常见的做法。然而,参数数量通常不能很好地代表图像模型的复杂度,因为它没有考虑图像分辨率等因素,而图像分辨率会显著影响性能。因此,本文的大部分模型复杂度分析都基于理论浮点运算次数(Gflops)。这与架构设计文献中广泛使用 Gflops 来衡量复杂度的做法一致。实际上,最佳复杂度指标仍然存在争议,因为它通常取决于具体的应用场景。Nichol 和 Dhariwal 改进扩散模型的开创性工作与我们的研究最为相关——他们分析了 U-Net 架构类的可扩展性和 Gflop 特性。本文则重点关注 Transformer 架构类。
3.Diffusion Transformers
3.1 Preliminaries
Diffusion formulation。在介绍我们的架构之前,我们简要回顾一些理解扩散模型(DDPM)所需的基本概念。高斯扩散模型假设一个前向噪声过程,该过程逐渐将噪声施加到真实数据 x 0 : q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) x_0:q(x_t|x_0) =\mathcal N(x_t;\sqrt{\bar α_t}x_0,(1 − \bar α_t)\textbf I) x0:q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I),其中常数 α ˉ t \bar α_t αˉt 是超参数。通过应用重参数化技巧,我们可以对 x t = α ˉ t x 0 + 1 − α ˉ t ϵ t x_t =\sqrt{\bar α_t}x_0 +\sqrt{1 − \bar α_t}\epsilon_t xt=αˉtx0+1−αˉtϵt 进行采样,其中 ϵ t ∼ N ( 0 , I ) \epsilon_t ∼ \mathcal N(0, \textbf I) ϵt∼N(0,I)。
扩散模型经过训练,可以学习逆转正向过程偏差的逆向过程: p θ ( x t − 1 ∣ x t ) = N ( µ θ ( x t ) , Σ θ ( x t ) ) p_θ(x_{t−1}|x_t) = \mathcal N(µ_θ(x_t), \Sigma_θ(x_t)) pθ(xt−1∣xt)=N(µθ(xt),Σθ(xt)),其中神经网络用于预测 p θ p_θ pθ 的统计量。逆向过程模型使用 x 0 x_0 x0 的似然函数的变分下界进行训练,该下界简化为 L ( θ ) = − p ( x 0 ∣ x 1 ) + ∑ t D K L ( q ∗ ( x t − 1 ∣ x t , x 0 ) ∣ ∣ p θ ( x t − 1 ∣ x t ) ) \mathcal L(θ) = −p(x_0|x_1) + \sum_t \mathcal D_{KL}(q^∗(x_{t−1}|x_t, x_0)||p_θ(x_{t−1}|x_t)) L(θ)=−p(x0∣x1)+∑tDKL(q∗(xt−1∣xt,x0)∣∣pθ(xt−1∣xt)),其中排除了一个与训练无关的附加项。由于 q ∗ q^∗ q∗ 和 p θ p_θ pθ 均为高斯分布,因此可以使用这两个分布的均值和协方差来评估 D K L \mathcal D_{KL} DKL。通过将 µ θ µ_θ µθ 重参数化为噪声预测网络 ϵ θ \epsilon_θ ϵθ,可以使用预测噪声 ϵ θ ( x t ) \epsilon_θ(x_t) ϵθ(xt) 与真实采样高斯噪声 ϵ t \epsilon_t ϵt 之间的简单均方误差来训练模型: L s i m p l e ( θ ) = ∣ ∣ ϵ θ ( x t ) − ϵ t ∣ ∣ 2 2 \mathcal L_{simple}(θ) = ||\epsilon_θ(x_t) − \epsilon_t||^2_2 Lsimple(θ)=∣∣ϵθ(xt)−ϵt∣∣22。但是,为了使用学习到的逆过程协方差 Σ θ \Sigma_θ Σθ 来训练扩散模型,需要优化完整的 D K L D_{KL} DKL 项。我们遵循 Nichol 和 Dhariwal 的方法:使用 L s i m p l e \mathcal L_{simple} Lsimple 训练 ϵ θ \epsilon_θ ϵθ,并使用完整的 L \mathcal L L 训练 Σ θ \Sigma_\theta Σθ。一旦 p θ p_θ pθ 训练完成,就可以通过初始化 x t m a x ∼ N ( 0 , I ) x_{t_{max}} ∼ \mathcal N(0, I) xtmax∼N(0,I) 并通过重新参数化技巧对 x t − 1 ∼ p θ ( x t − 1 ∣ x t ) x_{t−1} ∼ p_θ(x_{t−1}|x_t) xt−1∼pθ(xt−1∣xt) 进行采样来对新图像进行采样。
Classifier-free guidance。条件扩散模型将额外信息作为输入,例如类别标签 c c c。在这种情况下,逆过程变为 p θ ( x t − 1 ∣ x t , c ) p_θ(x_{t−1}|x_t, c) pθ(xt−1∣xt,c),其中 ϵ θ \epsilon_θ ϵθ 和 Σ θ Σ_θ Σθ 以 c c c 为条件。在此设置下,可以使用无分类器指导来鼓励采样过程找到 x x x,使得 l o g p ( c ∣ x ) log~p(c|x) log p(c∣x) 较高。根据贝叶斯规则, l o g p ( c ∣ x ) ∝ l o g p ( x ∣ c ) − l o g p ( x ) log~p(c|x) ∝ log~p(x|c) − log~p(x) log p(c∣x)∝log p(x∣c)−log p(x),因此 ∇ x l o g p ( c ∣ x ) ∝ ∇ x l o g p ( x ∣ c ) − ∇ x l o g p ( x ) ∇_x log~p(c|x) ∝ ∇_x log~p(x|c)−∇_x log p(x) ∇xlog p(c∣x)∝∇xlog p(x∣c)−∇xlogp(x)。通过将扩散模型的输出解释为得分函数,DDPM 采样过程可以通过以下方式指导采样具有高 p ( x ∣ c ) p(x|c) p(x∣c) 值的 x : ϵ θ ^ ( x t , c ) = ϵ θ ( x t , ∅ ) + s ⋅ ∇ x l o g p ( x ∣ c ) ∝ ϵ θ ( x t , ∅ ) + s ⋅ ( ϵ θ ( x t , c ) − ϵ θ ( x t , ∅ ) ) x: \hat{\epsilon_θ}(x_{t, c}) =\epsilon_θ(x_t, ∅) + s · ∇_x log~p(x|c) ∝ \epsilon_θ(x_t, ∅)+s·(\epsilon_θ(x_t, c)−\epsilon_θ(x_t, ∅)) x:ϵθ^(xt,c)=ϵθ(xt,∅)+s⋅∇xlog p(x∣c)∝ϵθ(xt,∅)+s⋅(ϵθ(xt,c)−ϵθ(xt,∅)),其中 s > 1 s > 1 s>1表示指导的尺度(注意 s = 1 s = 1 s=1 恢复为标准条件采样)。评估 c = ∅ c = ∅ c=∅ 时的扩散模型是通过在训练过程中随机丢弃 c c c 并用学习到的“空”嵌入 ∅ ∅ ∅ 替换它来实现的。众所周知,无分类器指导可以比通用采样技术产生显著更好的样本,这一趋势也适用于我们的 DiT 模型。
Latent diffusion models。直接在高分辨率像素空间中训练扩散模型在计算上可能非常耗时。潜在扩散模型(LDM)采用两阶段方法解决这个问题:(1)学习一个自编码器,该自编码器使用学习到的编码器 E E E 将图像压缩成更小的空间表示;(2)训练一个表示 z = E ( x ) z = E(x) z=E(x) 的扩散模型,而不是图像 x x x 的扩散模型( E E E 被固定)。然后,可以通过从扩散模型中采样表示 z z z,并使用学习到的解码器 x = D ( z ) x = D(z) x=D(z) 将其解码为图像来生成新图像。
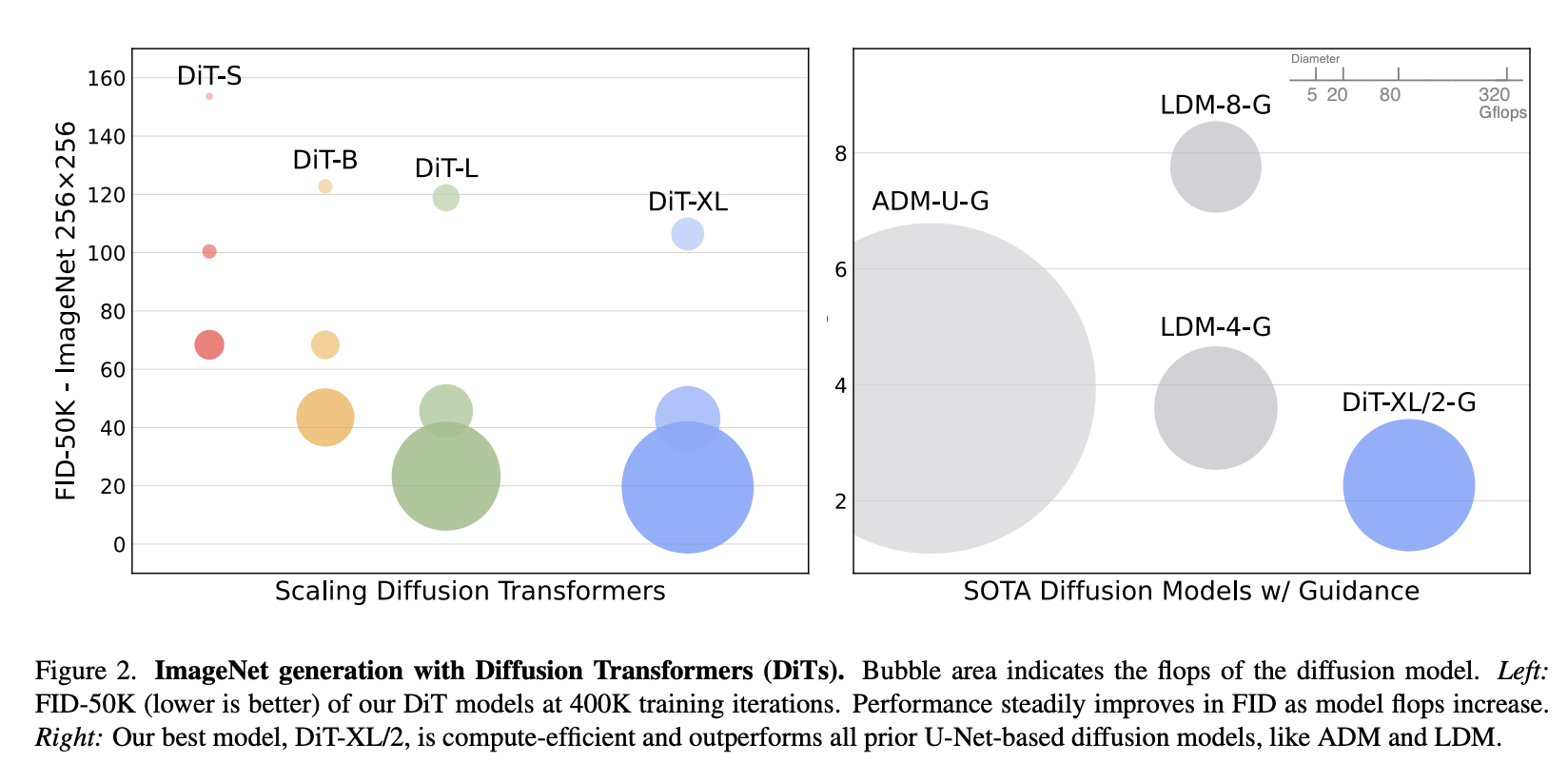
如图 2 所示,LDM 模型在仅需像素空间扩散模型(如 ADM)一小部分 Gflops 计算量的情况下,即可实现良好的性能。由于我们关注的是计算效率,因此 LDM 模型是架构探索的理想起点。本文中,我们将 DiT 模型应用于潜在空间,尽管它们无需修改即可应用于像素空间。这使得我们的图像生成流程成为一种混合方法;我们使用了现成的卷积 VAE 和基于 Transformer 的 DDPM 模型。
3.2 Diffusion Transformer Design Space
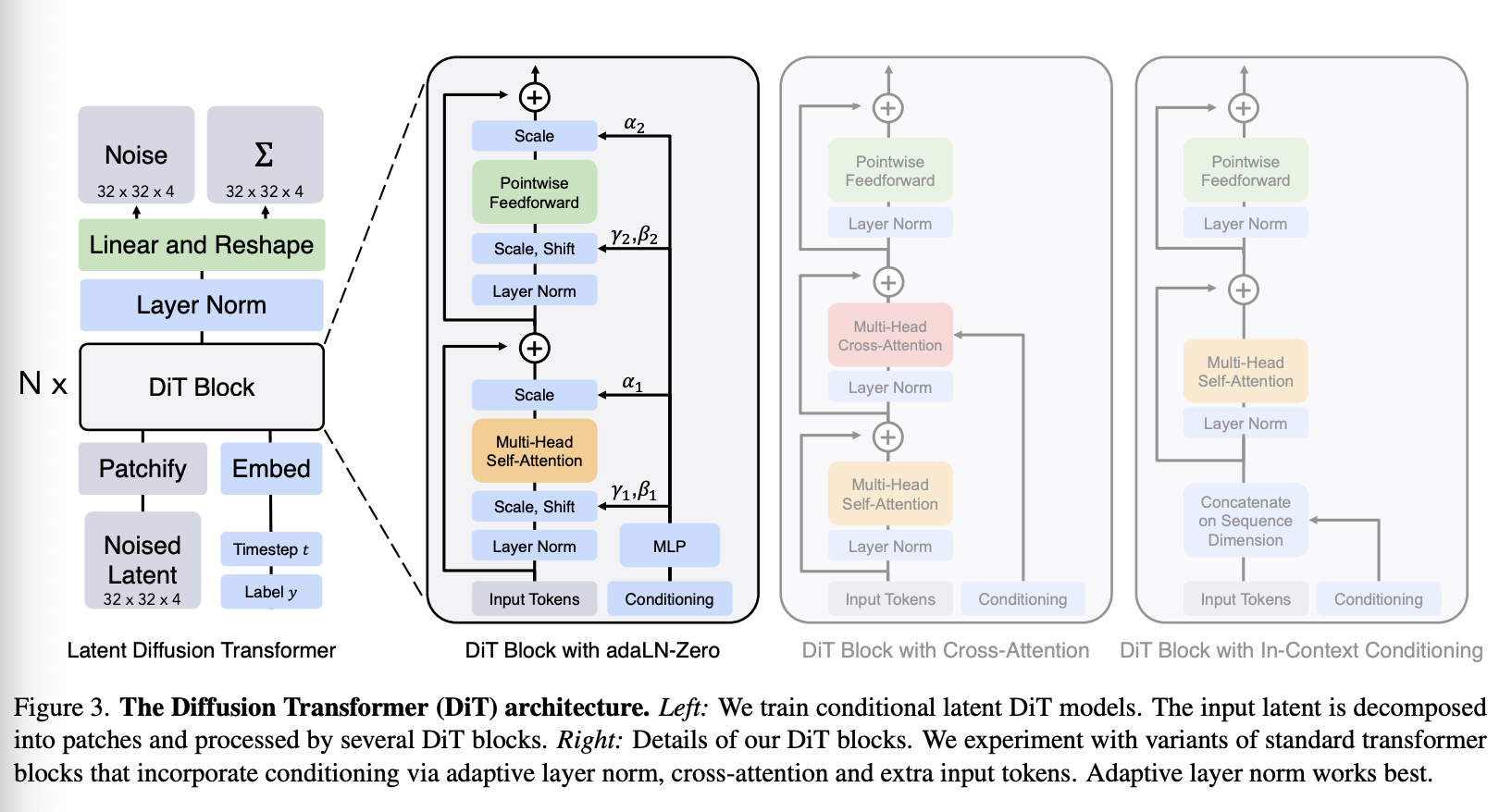
我们引入了 Diffusion Transformers (DiTs),一种用于扩散模型的新型架构。我们力求尽可能忠实于标准 transformer 架构,以保留其扩展特性。由于我们的重点是训练图像的 DDPMs(具体而言,是图像的空间表示),DiT 基于 Vision Transformer (ViT) 架构,后者处理图像块序列。DiT 保留了 ViT 的许多最佳实践。图 3 展示了完整的 DiT 架构概览。在本节中,我们将描述 DiT 的前向传播过程,以及 DiT 类设计空间的组成部分。
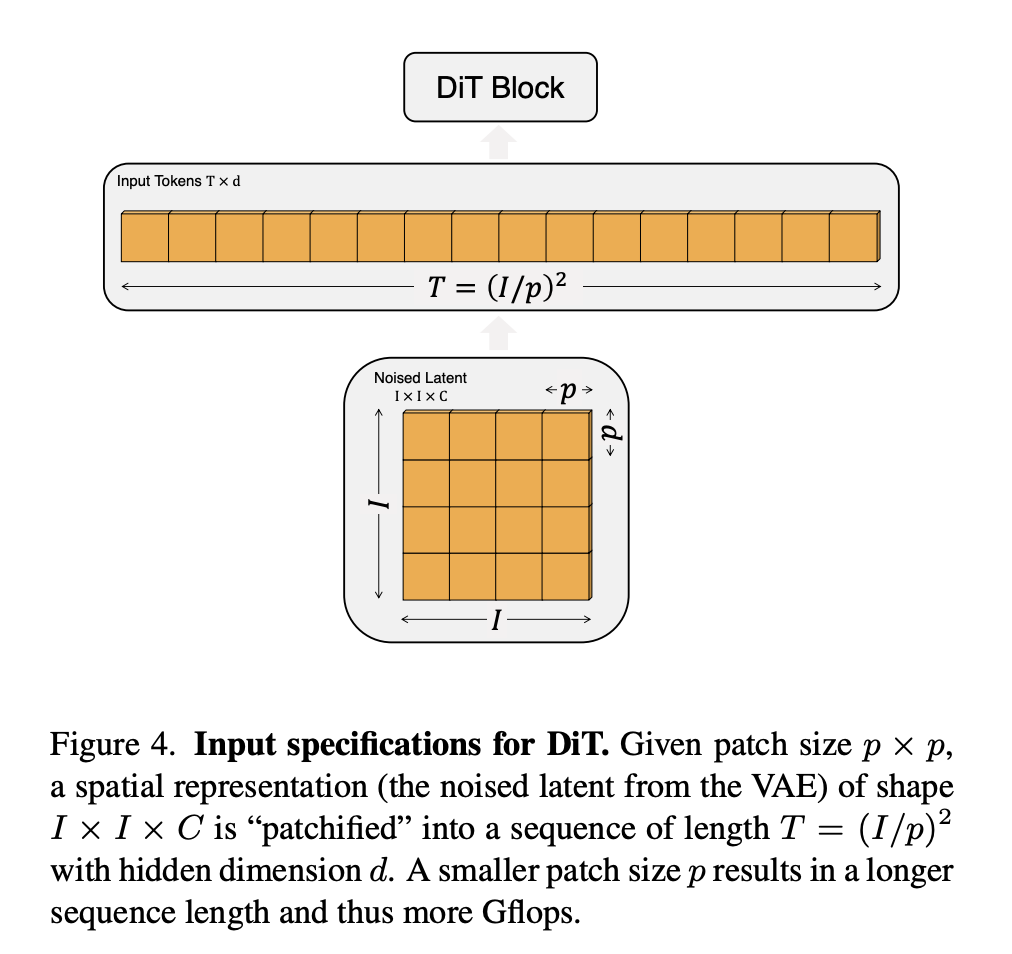
Patchify。DiT 的输入是空间表示 z z z(对于 256 × 256 × 3 的图像, z z z 的形状为 32 × 32 × 4)。DiT 的第一层是“patchify”,它将空间输入转换为 T T T 个 token 的序列,每个 token 的维度为 d d d,方法是将每个 patch 线性嵌入到输入中。patchify 之后,我们将标准的 ViT 基于频率的位置嵌入(正弦-余弦版本)应用于所有输入 token。patchify 生成的 token 数量 T T T 由 patch 大小超参数 p p p 决定。如图 4 所示,将 p p p 减半将使 T T T 变为原来的四倍,因此 Transformer 的总 Gflops 至少变为原来的四倍。虽然这会对 Gflops 产生显著影响,但请注意,改变 p p p 对下游参数数量没有实质性影响。
我们将 p = 2 , 4 , 8 p = 2, 4, 8 p=2,4,8 添加到 DiT 设计空间中。
DiT block design。在 patchify 之后,输入 token 由一系列 Transformer 模块进行处理。除了带噪声的图像输入外,扩散模型有时还会处理额外的条件信息,例如噪声时间步长 t t t、类别标签 c c c、自然语言等。我们探索了四种不同的 Transformer 模块变体,它们以不同的方式处理条件输入。这些设计对标准的 ViT 模块设计进行了细微但重要的修改。所有模块的设计如图 3 所示。
- In-context conditioning。我们简单地将 t t t 和 c c c 的向量嵌入作为两个额外的 token 添加到输入序列中,并像处理图像 token 一样处理它们。这类似于 ViT 中的 cls token,使我们能够直接使用标准的 ViT 模块而无需修改。在最后一个模块之后,我们从序列中移除条件 token。这种方法对模型的额外 Gflops 影响可以忽略不计。
- Cross-attention block。我们将 t t t 和 c c c 的嵌入向量连接成一个长度为 2 的序列,该序列与图像 token 序列分开。Transformer 模块经过修改,在多头自注意力模块之后增加了一个多头交叉注意力层,类似于 Vaswani et al. [60] 的原始设计,也类似于 LDM 用于基于类别标签进行条件化的层。交叉注意力为模型增加了最多的 Gflops,大约 15% 的开销。
- Adaptive layer norm (adaLN) block。鉴于自适应归一化层在生成对抗网络(GAN)和基于 U-Net 骨干网络的扩散模型中的广泛应用,我们探索了用自适应层归一化(adaLN)替换 Transformer 模块中的标准层归一化层。我们并非直接学习维度尺度和位移参数 γ γ γ 和 β β β,而是通过回归 t t t 和 c c c 的嵌入向量之和来获得它们。在我们探索的三种模块设计中,adaLN增加的Gflops最少,因此计算效率最高。它也是唯一一种对所有 token 应用相同函数的条件化机制。
- adaLN-Zero block。先前关于残差网络(ResNet)的研究表明,将每个残差块初始化为恒等函数是有益的。例如,Goyal et al. 发现,在每个残差块中将最终批归一化尺度因子 γ γ γ 初始化为零,可以加速监督学习环境下的大规模训练。扩散 U-Net 模型采用了类似的初始化策略,即在建立任何残差连接之前,将每个残差块中的最终卷积层初始化为零。我们探索了一种改进的 adaLN DiT 块,该改进也采用了相同的策略。除了回归 γ γ γ 和 β β β 之外,我们还回归了维度缩放参数 α α α,这些参数在DiT块内的任何残差连接之前立即应用。我们将多层感知器(MLP)初始化为输出所有 α α α 的零向量;这使得整个 DiT 块初始化为恒等函数。与原始adaLN块一样,adaLNZero对模型的Gflops增加微乎其微。
我们在 DiT 设计空间中加入了上下文相关、交叉注意力、自适应层归一化和 adaLN-Zero 模块。
Model size。我们应用一系列 N N N 个 DiT 模块,每个模块的隐藏维度大小为 d d d。遵循 ViT 的思路,我们使用标准的 Transformer 配置,这些配置可以联合扩展 N、d 和注意力头。具体来说,我们使用了四种配置:DiT-S、DiT-B、DiT-L 和 DiT-XL。它们涵盖了从 0.3 到 118.6 Gflops 的广泛模型规模和浮点运算分配范围,使我们能够评估扩展性能。表 1 给出了这些配置的详细信息。
我们在 DiT 设计空间中添加了 B、S、L 和 XL 配置。
Transformer decoder。在最后一个 DiT 模块之后,我们需要将图像 token 序列解码为输出噪声预测和输出对角协方差预测。这两个输出的形状都与原始空间输入相同。我们使用标准的线性解码器来实现这一点;我们应用最后一层的归一化(如果使用 adaLN,则应用自适应范数),并将每个 token 线性解码为 p × p × 2 C p×p×2C p×p×2C 张量,其中 C C C 是 DiT 的空间输入通道数。最后,我们将解码后的 token 重新排列回其原始空间布局,从而得到预测的噪声和协方差。
我们所探索的完整 DiT 设计空间包括 patch 大小、transformer 模块架构和模型大小。
4.Experimental Setup

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)