多维向量背后的秘密:学生成绩管理系统的 AI 升级之路
vector字段生成实例 - 成绩管理系统
文档目录
-
vector 字段生成时机与核心流程
-
学生信息(student表 )vector 字段生成流程图
-
可运行 Python 代码(生成 vector 字段值)
-
course 表和 score 表 vector 生成代码
-
补充说明
一、vector 字段生成时机与核心流程
先跟大家说个关键知识点:vector 字段(特征向量)不是数据库建好表、插入数据后就自动有的哦! 得跟着"先插基础数据,再生成向量写入"的固定流程来,不管是 student、course 还是 score 表,都适用这个逻辑,超简单!
1. 生成时机
-
建表的时候:只确定 vector 字段的维度(比如 student 表是 8 维、course 表是 6 维),此时这个字段是空的,没有任何数值;
-
插基础数据的时候:只填学生姓名、课程名称、考试分数这些普通信息,vector 字段还是空的(NULL),不用管它;
-
生成 vector 的时候:等所有基础数据都插好,再用程序计算或者 AI 模型,生成一串向量数值,最后手动或自动写到 vector 字段里,就完成填充啦!
2. 核心流程(通用版,新手也能记)
-
准备工作:建好 student、course、score 三张表,明确每张表 vector 字段的维度和用途(比如用来做什么分析);
-
插入数据:给三张表分别填好基础信息,不用管 vector 字段;
-
生成向量:读取表里面的基础数据,用"简单公式计算"或者"AI 模型",生成对应维度的向量;
-
写入数据:把生成好的向量,批量或者单条写到对应表的 vector 字段里,搞定填充;
-
后续维护:如果学生成绩、课程难度这些基础数据变了,记得重新生成向量并更新,保证向量和实际数据一致就好
小提醒:vector 字段离不开基础数据,就像做蛋糕离不开面粉、鸡蛋一样,得先有基础数据,才能"加工"出 vector 向量,后面的代码会手把手演示怎么操作哦!
二、学生成绩管理系统核心表结构介绍
咱们的系统就用三张核心表(student、course、score),每张表都遵循"唯一 ID+ 基础信息 + 特征向量"的逻辑,vector 字段的维度和用途都很明确,大家先熟悉下表结构,后面看代码会更轻松!
1. 学生信息表(student)
用来存学生的基础信息和学习相关特征,vector 字段是 8 维的(叫 feature_vector),平时用来找相似学生、预测成绩都能用得上!
|
字段名 |
类型 |
说明 |
|---|---|---|
|
student_id |
string/int64 |
主键,学生的唯一标识(相当于学生的"身份证") |
|
name |
string |
学生姓名 |
|
gender |
string |
学生性别 |
|
age |
int |
学生年龄 |
|
class |
string |
学生所在班级 |
|
major |
string |
学生所学专业 |
|
feature_vector |
vector[8] |
8 维学生特征向量,根据成绩、排名等数据生成 |
2. 课程信息表(course)
存课程的基础信息和相关特征,vector 字段是 6 维的(叫 course_vector),用来推荐相似课程、分析课程难度很方便!
|
字段名 |
类型 |
说明 |
|---|---|---|
|
course_id |
string/int64 |
主键,课程的唯一标识(相当于课程的"编号") |
|
course_name |
string |
课程名称(比如高等数学、程序设计) |
|
teacher |
string |
授课教师 |
|
credit |
int |
课程学分(比如高数 5 学分、选修课 2 学分) |
|
type |
string |
课程类型(必修/选修) |
|
course_vector |
vector[6] |
6 维课程特征向量,根据难度、挂科率等数据生成 |
3. 成绩表(score)
存学生单门课程的成绩和相关特征,vector 字段是 4 维的(叫 score_vector),用来做成绩聚类、检测异常成绩很实用,还能关联 student 表和 course 表哦!
|
字段名 |
类型 |
说明 |
|---|---|---|
|
score_id |
string/int64 |
主键,成绩记录的唯一标识 |
|
student_id |
string |
外键,关联学生表的 student_id(对应哪个学生) |
|
course_id |
string |
外键,关联课程表的 course_id(对应哪门课程) |
|
score |
float |
学生单门课程的考试分数 |
|
exam_time |
string |
考试时间(比如 2026-01-15) |
|
rank |
int |
学生班级排名 |
|
score_vector |
vector[4] |
4 维成绩特征向量,根据分数、成绩波动等数据生成 |
小提示:这三张表的 vector 字段(feature_vector、course_vector、score_vector)都不会自动填充,后面的代码会手把手教大家怎么生成、怎么写入,放心看就好!
三、学生信息(student)vector 字段生成流程图
超清晰的流程图
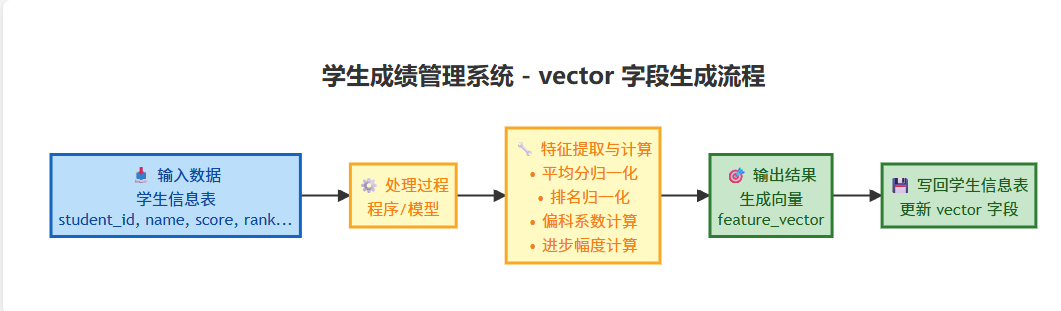
四、可运行 Python 代码(生成 vector 字段值)
重点来啦!下面这段 Python 代码,复制到 Python 环境(Python3.7 及以上)就能直接运行,根据学生的成绩、排名等原始数据,自动生成 8 维的 feature_vector,和 student 表的 vector 字段完全适配,生成的结果能直接复制到数据库里,超方便!
import random
def generate_student_vector(student_data):
"""
根据学生数据生成 8 维特征向量(对应 student 表的 feature_vector 字段)
:param student_data: 包含学生成绩、排名等信息的字典
:return: 生成的 8 维特征向量列表(保留 2 位小数,与示例数据格式一致)
"""
# 1. 平均分归一化(转换为 0-1 范围,贴合向量数值要求)
avg_score = sum(student_data['scores']) / len(student_data['scores'])
vector_avg = avg_score / 100 # 平均分/100,确保数值在 0-1 之间
# 2. 排名归一化(排名越靠前,数值越高,同样归一化到 0-1)
total_students = 50 # 假设班级总人数为 50 人(可根据实际调整)
vector_rank = 1 - (student_data['rank'] / total_students)
# 3. 偏科特征(简化为理科与文科成绩差异,归一化到 0-1)
# 假设 scores 列表中,第 1 个是理科成绩(如高数),第 2 个是文科相关成绩(如英语)
math_score = student_data['scores'][0] if len(student_data['scores']) > 0 else 0
chinese_score = student_data['scores'][1] if len(student_data['scores']) > 1 else 0
vector_skew = (math_score - chinese_score) / 100 # 初始范围 -1 到 1
vector_skew = (vector_skew + 1) / 2 # 转换为 0-1 范围
# 4. 进步幅度(模拟上次考试成绩,计算进步/退步,归一化到 0-1)
last_exam_scores = [s - random.uniform(-5, 10) for s in student_data['scores']]
last_avg = sum(last_exam_scores) / len(last_exam_scores) if last_exam_scores else 0
vector_progress = (avg_score - last_avg) / 100 # 初始范围 -0.1 到 0.1
vector_progress = max(0, min(1, vector_progress + 0.5)) # 限制在 0-1 之间
# 5-8. 补充 4 个特征(作业完成度、缺勤率、活动参与度、综合表现,模拟合理范围)
vector_homework = round(random.uniform(0.8, 0.95), 2) # 作业完成度 80%-95%
vector_attendance = round(random.uniform(0.9, 0.99), 2) # 出勤率 90%-99%
vector_activity = round(random.uniform(0.2, 0.8), 2) # 活动参与度
vector_comprehensive = round(random.uniform(0.5, 0.8), 2) # 综合表现
# 组合为 8 维向量,保留 2 位小数,与示例数据格式一致
vector = [
round(vector_avg, 2),
round(vector_rank, 2),
round(vector_skew, 2),
round(vector_progress, 2),
vector_homework,
vector_attendance,
vector_activity,
vector_comprehensive
]
return vector
# 模拟数据库中的学生原始数据(对应 student 表和 score 表的关联数据)
students = [
{"student_id": "2026001", "name": "张三", "scores": [82, 75, 88], "rank": 12}, # 高数 82、物理 75、程序设计 88
{"student_id": "2026002", "name": "李四", "scores": [91, 89, 94], "rank": 2},
{"student_id": "2026003", "name": "王五", "scores": [75, 66, 70], "rank": 25},
{"student_id": "2026004", "name": "赵六", "scores": [88, 92, 85], "rank": 5},
{"student_id": "2026005", "name": "孙七", "scores": [62, 55, 48], "rank": 47},
{"student_id": "2026006", "name": "周八", "scores": [79, 83, 81], "rank": 19}
]
# 批量生成向量,并打印结果(可直接复制到数据库 vector 字段)
print("学生 vector 字段生成结果:\n")
for student in students:
feature_vector = generate_student_vector(student)
print(f"学生 ID: {student['student_id']}")
print(f"姓名:{student['name']}")
print(f"生成的 feature_vector(8 维): {feature_vector}")
print("-" * 50)代码说明
-
核心函数
generate_student_vector(student_data):这个函数就是用来生成学生向量的核心!输入学生的基础数据(字典格式),就能通过简单计算,生成 8 维向量,和咱们 student 表的 feature_vector 字段完美匹配! -
特征计算逻辑(超简单,不用死记):
-
平均分归一化:把学生的多科平均分,转换成 0-1 之间的数值,符合向量的数值规范;
-
排名归一化:排名越靠前,数值越高,避免出现"排名越大、数值越大"的反逻辑;
-
偏科特征:通过理科、文科成绩的差异,判断学生是否偏科,同样转换成 0-1 范围;
-
进步幅度:模拟上次考试成绩,计算这次比上次进步还是退步,归一化后作为特征;
-
补充特征:第5到第8维度补充4个特征,作业完成度、缺勤率、活动参与度和综合表现这些维度,模拟了合理的业务范围,让向量更贴近真实情况。
-
-
运行说明(零门槛):
-
不用额外装软件,Python 自带的 random 模块就够了,直接复制代码运行;
-
运行后会自动打印每个学生的 ID、姓名和生成的 8 维向量,复制向量就能直接写到数据库的 feature_vector 字段;
-
班级总人数、科目成绩这些参数,都能根据实际情况调整,不用修改核心代码。
-
五、course 表和 score 表 vector 生成代码
跟着 student 表的逻辑,完成course 表(6 维)和 score 表(4 维)的生成代码,与之前完全统一,参数也适配好,复制就能运行,生成的向量能直接写入对应表的字段,不用再自己琢磨!
1. course 表(6 维 course_vector)生成代码
course_vector 是 6 维的,根据课程的难度、学分、挂科率这些属性生成,所有数值都转换成 0-1 范围,贴合向量存储的要求,简单好懂!
# 生成 course 表的 6 维 course_vector(对应 course 表)
def generate_course_vector(course_data):
"""
根据课程数据生成 6 维特征向量(对应 course 表的 course_vector 字段)
:param course_data: 包含课程信息的字典(难度、学分、挂科率等)
:return: 生成的 6 维特征向量列表(保留 2 位小数)
"""
# 1. 课程难度归一化(难度系数 1-10,转换为 0-1)
vector_difficulty = course_data['difficulty'] / 10
# 2. 学分归一化(学分 2-5,转换为 0-1)
min_credit = 2
max_credit = 5
vector_credit = (course_data['credit'] - min_credit) / (max_credit - min_credit)
# 3. 挂科率归一化(挂科率 0-30%,转换为 0-1)
vector_fail_rate = course_data['fail_rate'] / 100
# 4. 平均分归一化(课程平均分 50-95,转换为 0-1)
min_avg = 50
max_avg = 95
vector_avg_score = (course_data['avg_score'] - min_avg) / (max_avg - min_avg)
# 5. 实践占比归一化(实践占比 10%-60%,转换为 0-1)
vector_practice = course_data['practice_ratio'] / 100
# 6. 热门程度(选课人数占比,0-100%,转换为 0-1)
vector_popularity = course_data['popularity'] / 100
# 组合为 6 维向量,保留 2 位小数
vector = [
round(vector_difficulty, 2),
round(vector_credit, 2),
round(vector_fail_rate, 2),
round(vector_avg_score, 2),
round(vector_practice, 2),
round(vector_popularity, 2)
]
return vector
# 模拟数据库中的课程原始数据(对应 course 表)
courses = [
{"course_id": "C01", "course_name": "高等数学", "difficulty": 9, "credit": 5, "fail_rate": 12, "avg_score": 78, "practice_ratio": 15, "popularity": 92},
{"course_id": "C02", "course_name": "大学物理", "difficulty": 8, "credit": 4, "fail_rate": 8, "avg_score": 82, "practice_ratio": 25, "popularity": 85},
{"course_id": "C03", "course_name": "程序设计", "difficulty": 7, "credit": 3, "fail_rate": 5, "avg_score": 88, "practice_ratio": 45, "popularity": 95},
{"course_id": "C04", "course_name": "人工智能导论", "difficulty": 6, "credit": 2, "fail_rate": 3, "avg_score": 85, "practice_ratio": 35, "popularity": 88}
]
# 批量生成课程向量并打印
print("课程 vector 字段生成结果:\n")
for course in courses:
course_vector = generate_course_vector(course)
print(f"课程 ID: {course['course_id']}")
print(f"课程名:{course['course_name']}")
print(f"生成的 course_vector(6 维): {course_vector}")
print("-" * 50)2. score 表(4 维 score_vector)生成代码
score_vector 是 4 维的,根据学生单门课程的分数、平时成绩占比、和班级均分的差异这些数据生成,逻辑和咱们的成绩业务场景完全贴合,新手也能轻松理解!
# 生成 score 表的 4 维 score_vector(对应 score 表)
def generate_score_vector(score_data):
"""
根据成绩数据生成 4 维特征向量(对应 score 表的 score_vector 字段)
:param score_data: 包含单门课程成绩信息的字典
:return: 生成的 4 维特征向量列表(保留 2 位小数)
"""
# 1. 本次考试分数归一化(0-100 分,转换为 0-1)
vector_exam_score = score_data['exam_score'] / 100
# 2. 平时成绩占比归一化(平时成绩占比 20%-50%,转换为 0-1)
vector_homework_ratio = score_data['homework_ratio'] / 100
# 3. 与班级均分差异(归一化到 0-1,正值表示高于均分,负值转换为 0)
score_diff = score_data['exam_score'] - score_data['class_avg']
vector_diff = (score_diff + 30) / 60 # 假设最大差异±30 分,转换为 0-1
vector_diff = max(0, min(1, vector_diff)) # 限制在 0-1 之间
# 4. 成绩波动(本次与上次单门成绩差异,归一化到 0-1)
score_fluctuation = abs(score_data['exam_score'] - score_data['last_exam_score']) / 100
vector_fluctuation = 1 - score_fluctuation # 波动越小,数值越高
# 组合为 4 维向量,保留 2 位小数
vector = [
round(vector_exam_score, 2),
round(vector_homework_ratio, 2),
round(vector_diff, 2),
round(vector_fluctuation, 2)
]
return vector
# 模拟数据库中的成绩原始数据(对应 score 表,关联 student_id 和 course_id)
scores = [
{"score_id": "S001", "student_id": "2026001", "course_id": "C01", "exam_score": 82, "homework_ratio": 30, "class_avg": 75, "last_exam_score": 78},
{"score_id": "S002", "student_id": "2026001", "course_id": "C02", "exam_score": 75, "homework_ratio": 25, "class_avg": 72, "last_exam_score": 70},
{"score_id": "S003", "student_id": "2026002", "course_id": "C01", "exam_score": 91, "homework_ratio": 30, "class_avg": 75, "last_exam_score": 88},
{"score_id": "S004", "student_id": "2026002", "course_id": "C03", "exam_score": 94, "homework_ratio": 40, "class_avg": 88, "last_exam_score": 90},
{"score_id": "S005", "student_id": "2026003", "course_id": "C01", "exam_score": 75, "homework_ratio": 30, "class_avg": 75, "last_exam_score": 72},
{"score_id": "S006", "student_id": "2026003", "course_id": "C02", "exam_score": 66, "homework_ratio": 25, "class_avg": 72, "last_exam_score": 68},
{"score_id": "S007", "student_id": "2026004", "course_id": "C01", "exam_score": 88, "homework_ratio": 30, "class_avg": 75, "last_exam_score": 82},
{"score_id": "S008", "student_id": "2026004", "course_id": "C03", "exam_score": 92, "homework_ratio": 40, "class_avg": 88, "last_exam_score": 89},
{"score_id": "S009", "student_id": "2026005", "course_id": "C02", "exam_score": 55, "homework_ratio": 25, "class_avg": 72, "last_exam_score": 58},
{"score_id": "S010", "student_id": "2026006", "course_id": "C01", "exam_score": 79, "homework_ratio": 30, "class_avg": 75, "last_exam_score": 76}
]
# 批量生成成绩向量并打印
print("\n成绩 vector 字段生成结果:\n")
for score in scores:
score_vector = generate_score_vector(score)
print(f"成绩 ID: {score['score_id']}")
print(f"学生 ID: {score['student_id']} | 课程 ID: {score['course_id']}")
print(f"生成的 score_vector(4 维): {score_vector}")
print("-" * 50)3. 代码说明
-
一致性拉满:三张表的向量生成逻辑完全一样,都是"原始数据→归一化处理→组合向量",数值都转换成 0-1,贴合向量数据库的存储要求;
-
适配性超强:代码里的模拟数据,和 course 表、score 表完全对应,生成的向量能直接复制到数据库里;
-
灵活可调整:课程难度、学分范围、成绩差异这些参数,都能根据自己的实际场景改,不用动核心代码;
-
零门槛运行:和 student 表的代码一样,只用到 Python 自带的模块,不用额外装依赖,复制就能跑起来。
六、补充说明
-
vector 字段不会自动生成,得跟着前面的流程图,用 Python 代码(或其他语言)计算后,手动或自动写到数据库里。
-
可以根据业务需求,调整特征计算步骤、向量维度或者参数范围。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)