【 Linux 进程:程序、进程、PCB 和 fork 到底是什么?】
一文搞懂 Linux 进程:程序、进程、PCB 和 fork 到底是什么?
很多人在刚学 Linux 系统编程时,都会把“程序”和“进程”混在一起。表面上看,它们都像是在执行一段代码;但从操作系统的视角看,这两个概念并不相同。程序更像是一份静态文件,而进程则是程序运行起来之后,操作系统为它创建的一套完整执行环境。
如果你也有这些疑问:
- 程序和进程到底有什么区别?
- PCB 是什么,为什么 Linux 能管理那么多进程?
fork()为什么调用一次,却像执行了两遍?
那么这篇文章可以把 Linux 进程最核心的入门框架讲清楚。建议先收藏,再往下看。
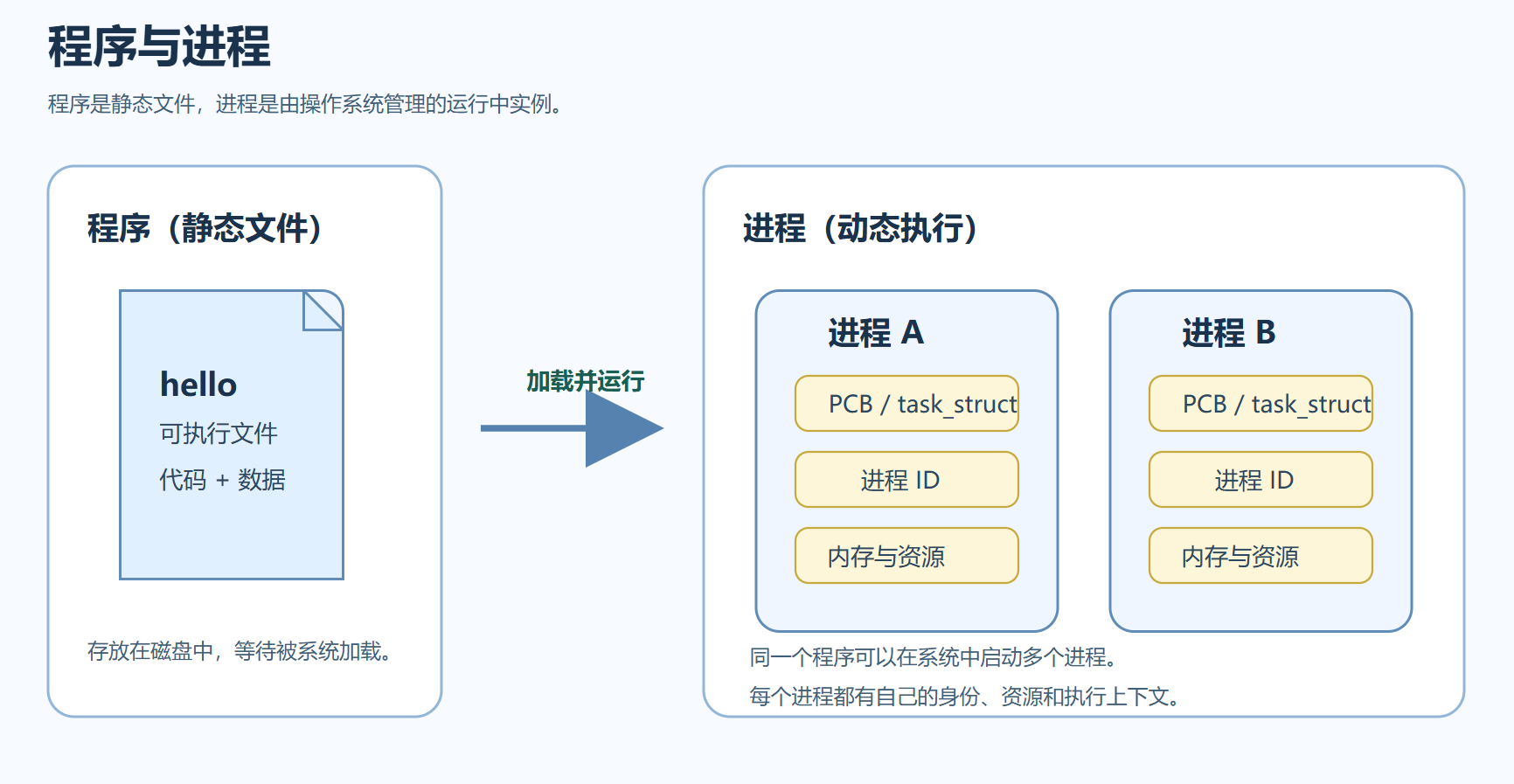
图 1:程序是静态文件,进程是程序运行后的动态实体。同一个程序可以在系统里对应多个不同进程。
一、程序和进程不是一回事
程序是静态的,比如磁盘上的一个可执行文件;进程是动态的,是程序被加载到内存、拿到 CPU 时间片并开始运行后的结果。
换句话说:
- 程序回答的是“这段代码是什么”
- 进程回答的是“这段代码现在由谁在运行、运行到哪里、占用了哪些资源”
同一个程序可以对应多个进程。最典型的例子就是你连续启动两个同样的可执行文件,它们运行的代码可能相同,但 PID、父进程、打开的文件、内存状态都可能不同,因此它们是两个独立进程。
二、操作系统为什么要引入进程
操作系统的核心任务之一,就是管理资源。CPU、内存、文件、设备,这些资源都不可能直接裸露给应用程序使用,否则系统很快会失控。
于是,操作系统引入了进程这个抽象:
- 让程序以“任务”的方式被统一管理
- 让多个程序能够并发执行
- 让 CPU 调度、内存分配、权限控制都有了管理对象
从这个角度看,进程并不是“程序的别名”,而是操作系统管理程序运行过程的基本单位。
三、PCB:进程之所以能被管理,是因为有它
进程能被调度、暂停、恢复,本质上依赖的是操作系统为它维护的一份数据结构,也就是 PCB(Process Control Block),进程控制块。
在 Linux 中,PCB 对应的核心结构通常就是 task_struct。你可以把它理解成操作系统给每个进程准备的一张“档案卡”,里面至少会记录这些信息:
- 进程标识信息,比如 PID、PPID
- 进程当前状态,比如运行、睡眠、停止
- 调度相关信息,比如优先级
- 内存相关信息
- 打开的文件和 I/O 资源
- 信号、权限、时间统计等运行上下文
进程本身并不是一个孤立概念,它真正可被管理的原因,就是因为内核里有 PCB。
四、如何在 Linux 中观察一个进程
理解概念之后,最好马上落到工具上。Linux 提供了几种非常常见的进程观察方式。
第一种是 /proc 文件系统。它本质上是内核暴露给用户空间的一组接口,每个进程通常会对应一个以 PID 命名的目录,比如:
ls /proc/1
这类目录里可以看到进程状态、内存映射、命令行参数等很多信息。
第二种是 ps 和 top:
ps aux
top
ps 更适合静态查看某一时刻的进程信息,top 更适合动态观察系统运行状态。
五、PID 和 PPID 是理解进程关系的第一步
每个进程都有一个 PID,也就是进程 ID。同时,大多数进程还有一个 PPID,也就是父进程 ID。
通过下面这个小程序,我们就能看到一个进程自己的 PID 和父进程的 PID:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("pid: %d\n", getpid());
printf("ppid: %d\n", getppid());
return 0;
}
这两个编号非常重要,因为 Linux 中很多进程关系问题,本质上都和“父子进程”有关,比如后面要讲的 fork、僵尸进程和孤儿进程。
六、fork:创建进程最经典的系统调用
在 Linux 系统编程里,fork() 是最经典、也最值得反复理解的系统调用之一。它的作用是创建一个新进程。
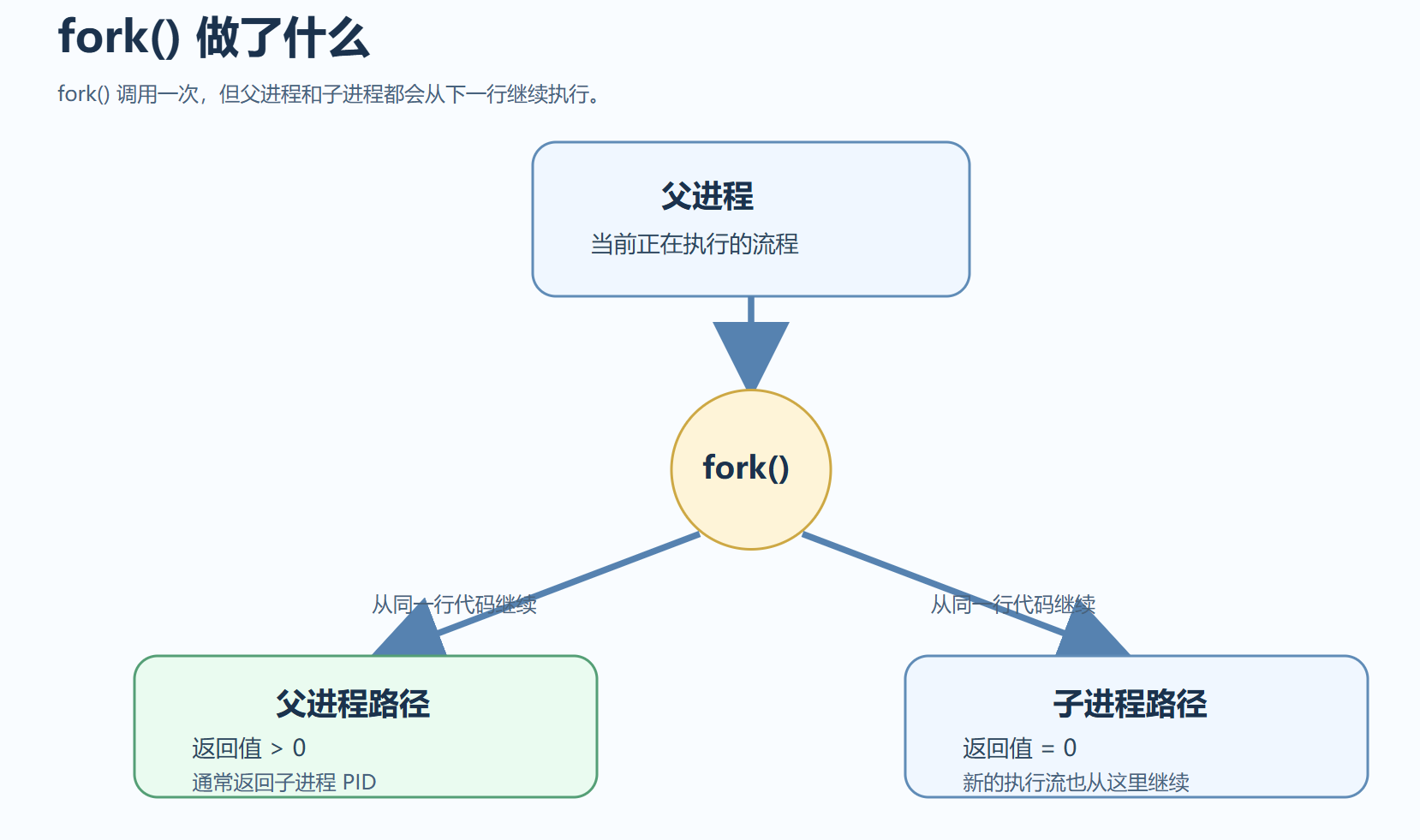
图 2:
fork()调用一次,但父进程和子进程都会从fork()之后的位置继续执行,只是返回值不同。
最容易让初学者困惑的一点在于:fork() 调用一次,却会返回两次。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
int ret = fork();
if (ret < 0) {
perror("fork");
return 1;
} else if (ret == 0) {
printf("I am child : %d, ret: %d\n", getpid(), ret);
} else {
printf("I am parent: %d, ret: %d\n", getpid(), ret);
}
return 0;
}
它的返回规则是:
- 返回值小于 0,表示创建失败
- 返回值等于 0,当前代码运行在子进程中
- 返回值大于 0,当前代码运行在父进程中,返回的是子进程 PID
为什么一份代码会打印出两段不同的内容?因为 fork() 之后,系统里已经出现了两个执行流:父进程和子进程都会从 fork() 之后的位置继续执行,只是返回值不同。
七、理解 fork,关键不是“复制代码”,而是“复制执行上下文”
很多人第一次学 fork() 时,会把它理解成“把程序再复制一份”。这种说法不算错,但不够准确。
更准确的理解应该是:fork() 创建了一个新的进程,这个新进程拥有自己的 PCB、自己的进程身份,以及一份逻辑上独立的执行环境。它会从父进程当前的位置继续往下执行,所以看起来像是“同一段代码被执行了两遍”。
这也解释了为什么父子进程虽然来自同一段程序,但仍然是两个独立的进程。
八、总结
如果说程序是一份静态说明书,那么进程就是这份说明书被真正投入运行后的现场。操作系统通过 PCB 管理进程,通过 PID 组织进程关系,再通过 fork() 创建新的执行流,整个系统的运行秩序才得以建立。
最后用几句话总结本文:
- 程序是静态文件,进程是运行中的程序
- Linux 通过 PCB,也就是
task_struct管理进程 - PID 和 PPID 帮助我们理解进程之间的父子关系
fork()是创建子进程的经典系统调用,也是理解进程模型的关键入口

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)