AGI 主要技术路径及核心技术:归一融合及未来之路3

具身智能
四、具身智能路径
具身智能路径与前三者有根本性哲学差异的路径,具身的核心观点是认为智能无法脱离与物理世界的实时、动态交互而独立存在。
(一)核心思想:具身性、情境性与生成性
具身智能的核心论点可以概括为:智能起源于拥有一个身体的智能体,在适应复杂物理和社会环境的过程中,通过感知-行动循环而进化出来的能力。
1. 具身性: 智能不是发生在一个孤立的大脑(或服务器)中的纯粹计算。身体形态、感官和运动能力塑造了认知本身。例如,一个拥有抓握能力的手的智能体,其对于“可抓握物体”概念的理解,与一个没有手的智能体截然不同。
2. 情境性: 智能体处于一个具体、动态变化的环境中。认知是实时的,必须处理部分可观测、充满不确定性的信息流,并做出时间紧迫的决策。这迫使智能发展出注意、预测和快速适应能力。
3. 生成性: 智能体不是被动的观察者,而是主动的行动者。它通过行动来影响环境,从而为自己生成新的感知数据和需要解决的问题(“主动感知”)。行动是获取知识、测试假设和理解因果关系的最根本方式。
一句话总结: 具身路径认为,“To learn is to do, and to understand is to interact.” (学习即行动,理解即交互)。真正的通用智能,必须在与世界的“博弈”中练就。
(二)与其他路径的根本区别
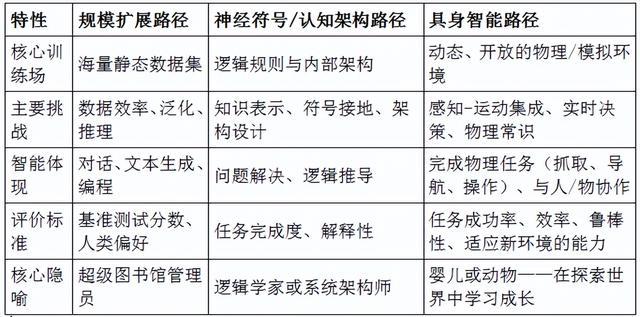
具身智能路径与其他路径的区别
(三)关键争论点:符号接地问题
这是具身路径对符号主义和纯神经路径最深刻的批评。一个从纯文本中学会“苹果”一词的AI,它与一个通过看、摸、闻、尝,甚至抓握、投掷过苹果的机器人,对“苹果”的理解是同一回事吗?前者是空洞的符号关联,后者是** grounded (接地)的、丰富的多模态概念**。具身路径认为,没有具身体验,AI的“理解”是无根的浮萍。
(四)主要研究领域与技术栈
具身智能的实现是一个系统工程,涉及多个层面:
1 感知: 不仅仅是识别物体,还包括理解物体的物理属性(质量、硬度、摩擦力)、空间关系(遮挡、支持)和功能(可坐、可倾倒)。
技术: 多传感器融合(RGB-D相机、激光雷达、触觉、力觉)、三维场景理解、动态目标跟踪。
2 运动控制与规划:
低级控制: 如何让机械臂或双腿平稳、精确地运动?涉及动力学、运动学、强化学习。
高级规划: 如何将一个高层目标(“做一顿早餐”)分解为一系列物理上可执行的动作序列(走向冰箱、开门、取出鸡蛋……)?通常需要结合任务和运动规划。
3 学习范式:
强化学习: 是核心学习范式。智能体通过试错,从环境反馈(奖励/惩罚)中学习策略。但样本效率极低,且现实世界探索成本高、风险大。
模仿学习: 通过观察人类演示来学习技能,大幅提升学习效率。
世界模型学习: 让智能体在内心建立对环境的动态预测模型,从而能进行“想象”和规划,减少真实试错。
4 仿真与 Sim2Real:
作用: 由于现实实验成本高昂,绝大多数研究先在高度逼真的物理仿真器中进行(如NVIDIA Isaac Sim, Unity, MuJoCo)。
核心挑战: Sim-to-Real Gap —— 如何让在仿真中学到的策略,能够迁移到现实世界中?这是该领域的关键技术难题。
5 人机交互与社会智能:
高级的具身智能需要理解人类意图、手势、语言,并能进行物理协作(如共同搬运物体)和社会互动。这引向了具身多模态交互的研究。
(五)为什么具身智能对AGI至关重要?
-
获取物理常识的必由之路: 重力、惯性、物体的持久性、空间容纳关系等“常识”,对人类而言是与生俱来的,但对AI却是巨大空白。这些常识最自然的学习方式就是在物理互动中获得。
-
因果推理的试炼场: 物理世界是检验因果关系的终极考场。推一个积木,另一个会倒,这是最直接的因果教育。
-
通用能力的外在体现: 许多AGI必备能力(如规划、问题分解、工具使用、多任务协调)在具身任务中有最综合的体现。例如,“用工具组装家具”几乎考验了所有认知能力。
-
对齐与安全的重要测试平台: 一个在物理世界中行动的AI,其目标、行为的安全性和后果可以被更直观地观察和评估。
(六)挑战与瓶颈
-
巨大的复杂性与成本: 硬件制造、维护、实验周期长、成本极高。
-
数据稀缺与样本效率: 物理世界交互产生的数据量,与互联网文本数据相比是九牛一毛,且获取缓慢。如何高效学习是关键。
-
Sim-to-Real 迁移难题: 仿真永远无法完美复现现实的噪声和复杂性。
-
长视野任务规划: 在动态变化的环境中,规划并执行需要多步骤、长时间的任务极其困难。
-
安全性与鲁棒性: 在现实世界中,失败可能意味着硬件损坏甚至人身危险。
(七)当前趋势与未来:与规模扩展路径的融合
这是当前最激动人心的方向。具身智能路径正与强大的基础模型(尤其是大语言模型和视觉-语言模型)深度融合,形成大型具身模型范式:
1 大模型作为“大脑”:
任务规划与分解: 用户用自然语言下达指令(“把房间整理一下”),LLM理解后,将其分解为一系列机器人可执行的子任务(“先捡起地上的衣服,然后把书放进书架……”)。
常识与推理提供者: LLM提供丰富的世界知识(“牛奶通常放在冰箱里”、“玻璃杯是易碎的”),指导机器人的决策。
代码生成: LLM将高层指令直接生成控制机器人的底层代码或API调用序列。
2 具身智能作为“身体”与验证器:
将大模型的规划在物理世界中进行执行和验证,提供真实的反馈,形成闭环。产生高质量、多模态的具身数据,用于进一步训练和优化模型,使其知识“接地气”。
3 视觉-语言-动作模型:
研发端到端的、能从视觉观察和语言指令中直接输出动作的统一模型。这是将感知、理解、规划、控制整合进一个神经网络的前沿探索。
(八)结论与展望
具身智能路径不是要制造一个只会做家务的机器人,而是在为AGI构建一个不可绕过的、基于物理体验的“认知基础”。它坚持认为,脱离物理交互的智能是抽象且脆弱的。
未来的AGI很可能是一个“虚实结合”的混合体:它在虚拟空间中通过海量文本和视频进行“理论学习”,掌握知识和符号推理;它在仿真和物理世界中通过交互进行“实践学习”,获得物理常识、运动技能和因果理解。
大模型为其提供强大的认知先验和规划能力,而具身体验则不断夯实和修正这些知识,使其变得真实、可靠和可执行。
因此,具身智能路径或许不会单独产生AGI,但缺少了具身视角所强调的交互、体验和物理基础,任何AGI都可能是残缺和不完整的。它迫使AI研究者直面智能与世界的根本联系,是通往真正通用、可靠、能与人类共栖于同一世界的智能的必经之路。
神经网络
(未完待续)
【免责声明】本文主要内容均源自公开信息和资料,部分内容引用了Ai,仅作参考,不作任何依据,责任自负。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)