EgoVerse:一个为机器人学习的来自世界各地自我为中心人类数据集
26年3月来自佐治亚理工学院、斯坦福大学、加州大学圣地亚哥分校、苏黎世联邦理工学院、麻省理工、Meta、Mecka AI和Scale AI的论文“EgoVerse: An Egocentric Human Dataset for Robot Learning from Around the World”。
机器人学习越来越依赖于庞大且多样化的数据,然而机器人数据的收集仍然成本高昂且难以规模化。以自我为中心的人类数据通过捕捉日常环境中丰富的操作行为,提供一种很有前景的替代方案。然而,现有的人类数据集通常范围有限、难以扩展,并且分散在各个机构中。EgoVerse,是一个用于人类数据驱动机器人学习的协作平台,它将数据收集、处理和访问统一到一个共享框架下,从而支持个人研究人员、学术实验室和行业合作伙伴的贡献。当前版本包含 1362 小时(8 万个片段)的人类演示数据,涵盖 1965 个任务、240 个场景和 2087 位不同的演示者,并采用标准化格式、与操作相关的标注以及用于下游学习的工具。除了数据集之外,还开展一项大规模的人机迁移研究,在共享协议下,在多个实验室、任务和机器人实例中重复进行实验。策略性能通常会随着人类数据的增加而提高,但有效的规模化取决于人类数据与机器人学习目标的一致性。
EgoVerse如图所示:

机器人从人类数据中学习。人类数据为机器人学习提供两大主要机遇:大量的未标注在线视频和精心整理的标注演示[1, 31, 50, 56]。网络视频虽然丰富,但需要通过逆动力学模型[7, 14, 59]、Affords模型[2, 48]或点跟踪[5, 46, 54]对动作进行伪标注,以进行策略训练,这构成一些基础模型的基[9, 41, 42, 58],但通常仍然需要域内的机器人数据。另一种方法是将标注的人类演示与机器人数据进行联合训练,作为策略学习[23, 31, 34, 38, 45, 63]、后训练[8, 32]和世界建模[19, 25]的不同载体。这些研究表明,这种做法可以增强鲁棒性和场景理解能力。然而,此类研究成果仍局限于有限的规模和单一机器人形态,对于多种机器人形态和多样化的人类数据来源等关键问题,仍未得到充分探索。
本文工作通过大规模的人类数据集和设计的大规模研究,弥补这些根本性的空白。EgoVerse,是一个大规模的协作框架,旨在创建一个不断增长的自我为中心人类演示数据集,专门用于机器人学习,并系统地研究能够从各种人类数据源有效进行跨具身迁移的关键因素。
EgoVerse 数据集是一个来自世界各地用于机器人学习的人类数据集。
人类数据采集设置
学术合作伙伴使用 Project Aria 眼镜作为 EgoVerse-A 的标准设备。行业合作伙伴为 EgoVerse-I 贡献定制的设备,以实现可扩展性和易于部署。还引入一个基于手机的采集系统,供更广泛的社区使用。如图展示这些设置:
Project Aria 眼镜用于人类数据采集。根据之前的研究 [31, 37, 44, 63],采用 Project Aria 眼镜(第一代)作为 EgoVerse-A 的标准化采集平台。Project Aria 眼镜是一款轻便(75 克)的头戴式设备,配备一个广角 RGB 摄像头和两个同步的单色场景摄像头,用于 SLAM 和手部追踪(如上图)。即使手部超出前视 RGB 摄像头的视野范围,侧面摄像头也能持续捕捉手部运动。
行业合作伙伴数据采集设置。EgoVerse-I 数据流汇总使用定制可穿戴传感器平台在各种室内环境中采集的演示数据。这些设备通常配备轻便的头戴式摄像头和同步传感模块。大多数系统使用立体鱼眼 RGB 摄像头来实现精确的手部姿态估计。数据包括自视 RGB 视频,以及(如有)深度数据流,并结合惯性传感来重建摄像头运动。
基于手机的数据采集系统。为了扩大数据采集设备的使用范围,还提供一套基于普通智能手机的方案,作为 EgoVerse 生态系统的一部分。该系统使用安装在头带上的 iPhone,其超广角摄像头以 1080p 和 30 FPS 的帧率录制以用户为中心的 RGB 视频。采集的视频上传到云端处理流程,该流程通过视觉跟踪恢复 6 自由度头部姿态,并使用每只手 21 个关键点估计 3D 手部姿态。
人体数据标注
EgoVerse 通过为机器人策略学习量身定制的结构化标注来增强以用户为中心的人体演示。对于每一帧,用相机帧中每只手 21 个关键点来估计双手的 3D 手部姿态,并将其与通过视觉惯性 SLAM 获取的标定后 6 自由度头部姿态相匹配。学术合作伙伴使用 Project Aria 的机器感知服务 (MPS) 进行跟踪和自我运动,而行业数据集则结合合作伙伴的 SLAM、基于模型的姿态估计和后处理技术,以确保轨迹的一致性。在人机迁移研究中,这些信号作为人类末端执行器运动的,实现了跨载体的协同训练。除了姿态之外,不同数据集组件的标注粒度也存在差异。EgoVerse-A 遵循轻量级的逐集协议,附加任务描述、场景标识符、主要操作对象和演示者元数据,以支持受控的跨实验室分析。相比之下,EgoVerse-I 提供更密集的标注,包括细粒度(1-2 秒)的语言描述、主动手指示符(indicator)、静态/移动操作标记(flags),以及其他可用的上下文标签(tags)。
EgoDB:可扩展的数据管理系统
为了支持联盟范围内的协作和数据集的长期增长,开发 EgoDB,这是一个基于云的系统,用于持续摄取、处理和访问异构的人类和机器人数据(如图所示)。来自分布式数据源的数据被上传到 S3 支持的存储,并转换为统一的、可用于训练的格式,供 EgoVerse 生态系统共享。一个夜间运行的流水线执行标准化的预处理、验证和索引,以确保下游学习的一致性可用性。Episode元数据注册在集中式 SQL 数据库中,从而可以对任务、具身、场景、数据源和标注类型进行结构化查询。EgoDB 还提供一个基于 Web 的界面,用于浏览演示、检查标注和跟踪数据集的增长。对于本地训练,用户可以通过配置文件同步数据集的过滤子集,从而实现可复现的访问,而无需手动管理数据。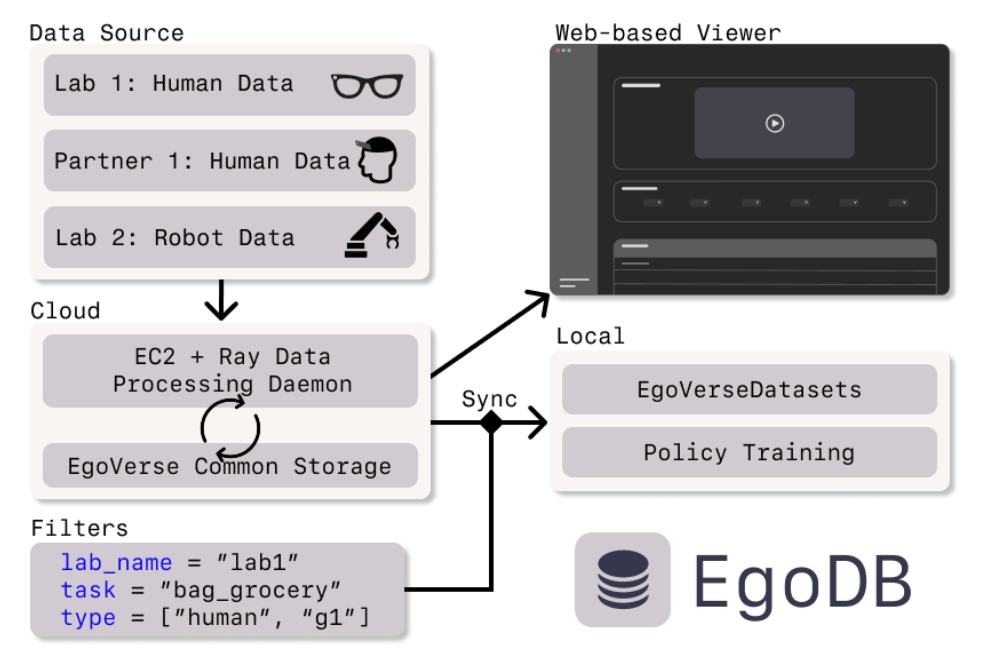
EgoVerse-A 数据集
收集协议和数据集单元。为了确保地理位置分散的站点之间数据采集的标准化,采用一种围绕数据集单元组织的共享协议。每个单元都遵循通用的指令格式,以确保各实验室任务执行的一致性,通常包含约 5 分钟的录制,每个任务可生成 5-10 个演示。实施基本的质量约束,以确保手部和操作物体的可见性,并记录关键元数据,例如演示者身份、场景和物体集合,以实现可追溯性。
旗舰任务。为了在控制任务语义的同时允许其他方面的变异,定义一组所有参与实验室共享的六项旗舰任务。
• 容器内物体:拿起物体,放入容器,倾倒,并持续重复 40 秒,物体-容器组合随机。单臂任务。
• 杯碟:将杯子从随机初始姿势调整方向,并将其放在碟子上。双手任务。
• 装袋-杂货:打开购物袋并装入 1-3 件商品。双手操作任务。
• 折叠-衣物:将一件初始状态随机的 T 恤折叠三层。双手操作任务。
• 舀取-颗粒:舀取颗粒状物料(例如豆类)并将其放入容器中直至装满。单臂操作任务。
• 分类-餐具:拾取餐具并将其分类放入指定的容器中。单臂操作任务。
这些任务涵盖多种操作模式,包括单臂和双手协调、精细的物体放置以及长时程行为,同时适用于常见的机器人操作平台。
结构化多样性轴。EgoVerse-A 旨在捕捉多样性,同时保持可控的任务语义和数据质量。人类数据收集围绕三个主要轴进行组织:任务、场景和演示者。
场景和物体多样性。每个旗舰任务在每个实验室的 8-12 个场景中进行,每个场景采集 1-10 个数据集单元,以捕捉环境内部的变化。演示在约 40cm × 60cm 的工作空间内进行录制,物体位置在每次试验中随机排列。
演示者多样性。每个实验室收集 1 至 8 名演示者的数据。尽管指导语相同,但不同实验室的演示者在动作模式、时间安排、协调策略和手部轨迹方面均表现出一致的差异。由于身高、姿势和工作空间配置的差异,这自然会导致人体形态和自我为中心视角的变化。先前的研究表明,这种人体变异性会显著影响策略学习和跨具身对齐 [31, 38, 44]。其并未消除这种变异性,而是将其视为可扩展人类数据的固有属性。
受控多样性子集。虽然跨实验室聚合提供真实的多样性,但也导致场景和演示者之间的覆盖不均。为了研究受控条件下多样性的影响,一个实验室使用固定的 16 名演示者和 16 个场景,收集杯碟叠放和衣物折叠的辅助数据集。数据通过结构化分配矩阵进行分配(每个演示者-场景对的数据量为 3.75 分钟至 2 小时;每个场景 ≥1 小时),并分为三个实验方案:
• 单场景演示者扩展。在固定的 2 小时数据预算下,单个场景中演示者的数量从 1 增加到 16,以研究演示者多样性对单个场景的影响。
• 多场景交互效应。使用场景 1-8 研究演示者在不同环境下的扩展性,演示者的数量从 4 到 12 不等,数据预算固定为 8 小时。
• 场景多样性扩展。场景 1-16 的数据采集使用固定的演示者池,从而将场景多样性和数据量解耦。
通过控制变异来源,该子集允许独立地扩展和研究场景多样性和演示者多样性。
EgoVerse-I 数据集
EgoVerse-A 数据集在受控轴上密集覆盖旗舰任务,但缺乏训练通用策略所需的任务多样性。为了解决这个问题,引入 EgoVerse-I,这是迄今为止最大的自我为中心、带有动作标注的人类数据集,包含近 1400 小时的数据,涵盖近 2000 个任务、240 个场景和 2087 位示范者(如图所示)。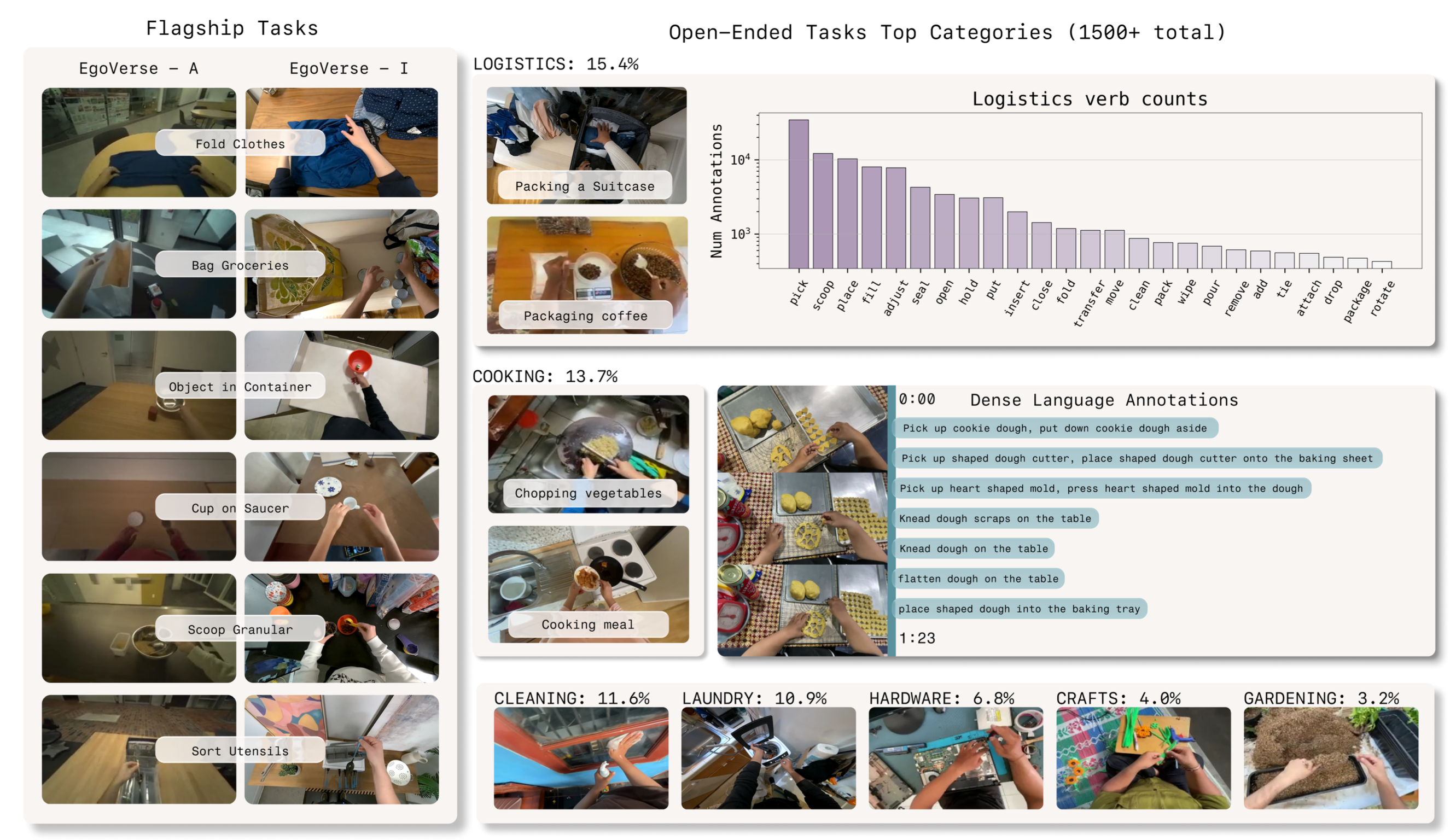
EgoVerse-I 的设计旨在最大限度地用于机器人学习,其特点包括:强调操作密集型任务分布、要求示范者保持双手可见,以及应用人工质量控制,仅保留操作密集型片段。此外,EgoVerse-I 还包含密集的语言标注,使其适用于训练语言条件策略,例如 VLA。上图对比 EgoVerse-A 和 EgoVerse-I 中的旗舰任务示例,并展示 EgoVerse-I 中开放式任务的代表性语言标注和动词统计数据。
视觉多样性案例研究。为了比较不同数据源的视觉多样性,对来自三个数据源的折叠衣物任务的 DINOv3 词嵌入应用 UMAP 算法:来自同一实验室的机器人数据、EgoVerse-A 中的人类数据以及 EgoVerse-I 中的人类数据。如图所示,尽管任务语义相同,但 EgoVerse-I 显著扩展视觉覆盖范围。这种多样性的提升对于学习能够超越特定实验室外观统计数据的泛化策略至关重要。
本文开展一项大规模的系统性研究,旨在探究能够有效将多样化的人体具身数据迁移到机器人操作策略的因素。实验设计优先考虑可重复性:机器人实验在多个实验室中使用不同的平台、控制器和环境进行重复。这种多实验室、多具身设置能够识别出在不同硬件和传感配置下都一致的研究结果,从而确保结论超越特定系统的影响。通过使用共享的协议和评估标准,研究人体数据的规模和多样性如何影响人机迁移。
机器人平台
实验在三个具有不同运动学、传感配置和控制界面的独特机器人平台上进行。这能够评估哪些研究结果在不同系统间具有一致性,而不是仅限于单个机器人(如图所示)。
机器人 A:该系统由两个带有平行爪夹持器的 6 自由度 ARX5 机械臂组成。机械臂垂直安装。主摄像头为 Aria Glasses,腕部安装有两个 Intel RealSense D405 摄像头。
机器人 B:与机器人 A 不同,其两个 ARX5 机械臂侧装在定制的 3D 打印肩部结构上,以模拟人类的工作空间 [57]。该机器人配备了头戴式 Aria 眼镜和腕部安装的 Logitech 网络摄像头,每个末端执行器上都装有摄像头。
机器人 C:该系统为 Unitree G1 机器人,配备 7 个自由度机械臂,每个机械臂都配备一个 6 自由度灵巧型 Inspire 手。主中心相机为 ZED 2 立体相机。
人机数据对齐
机器人动作表示。对于机器人 A,通过正向运动学从指令关节角度计算基坐标系下的 SE(3) 动作,使用外参投影到中心相机坐标系,并表示为 6 自由度欧拉姿态 (x, y, z, yaw, pitch, roll),每个机械臂都有一个夹爪状态,从而得到 aR_t:t+k。机器人 B 遵循类似的流程,但它使用四元数 (x, y, z, q_x, q_y, q_z, q_w) 以及夹爪状态来表示姿态,最终得到 aR_t:t+k。对于机器人 C,腕部运动被建模为机器人基坐标系中的绝对 SE(3) 位姿轨迹,灵巧的手部控制通过相对于末端执行器的五个关键点位置来指定,这些关键点位置使用逆运动学求解器映射到关节指令。
人体动作表示。以人为中心的手部跟踪通常是相对于移动的相机坐标系进行的。根据先前的工作 [31, 45],为了统一人与机器人之间的参考系以进行联合策略学习,选择构建以相机为中心的稳定参考系。 SE(3) 手部姿态的原始轨迹为 [pH_t , pH_t+1 , pH_t+2 , …, pH_t+k],其中每个姿态 pH_t 均位于设备坐标系 Tdevice_t 中。通过将未来的手部位置投影到第 t 个设备坐标系中来构建动作 aH_t:t+k。因此,轨迹由以下公式构建:
aH_t:t+k = [(Tdevice_t)−1 · Tdevicet+i · pH t+i]
人机数据对齐。最近的跨具身研究 [31, 44, 52, 63] 表明,协同训练受益于对本体感觉和动作进行单独归一化。为了使归一化对异常值具有鲁棒性,采用分位数归一化。根据文献[11, 29]将特征分布的第1和第99百分位数映射到[-1, 1] 范围内。对于特征张量x,归一化输出xˆ的计算公式为xˆ = 2 · (x−q_0.01)/(q_0.99 −q_0.01) - 1。为了应对不同的相机传感器,在训练过程中进行随机图像裁剪和颜色抖动。
学习架构和算法
策略架构。为了实现跨不同载体的联合训练,采用一种具有浅层、模态特定分支的编码器-解码器架构[53]。图像观测由ResNet-18[24]骨干网络处理,而本体感觉输入则由多层感知器(MLP)编码,然后通过学习的查询注意机制被token化到共享空间。共享的视觉分支处理来自人类和机器人载体的以自我为中心RGB观测,而单独的分支则处理机器人特定的腕部摄像头和本体感觉。生成的token被连接起来,并与一组可学习token一起通过共享的Transformer编码器f_φ。这些可学习token关注多模态输入,以提取与任务相关的特征并调节动作解码器。
流匹配动作解码器。动作解码器π_θ由一个使用流匹配目标训练的多块Transformer解码器参数化。初始化对应于动作序列的T个可学习token。时间步长τ ∼ Beta(1.5, 1.0) 被位置嵌入并沿隐维度连接到可学习token。通过交替的自注意块和交叉注意块,将来自编码器的编码上下文注入到动作解码器中。使用线性层将可学习token解码到动作维度。
根据输出动作空间,初始化共享或特定于具身的动作解码器。如图所示基于 Transformer 的跨-具身策略主干示意图: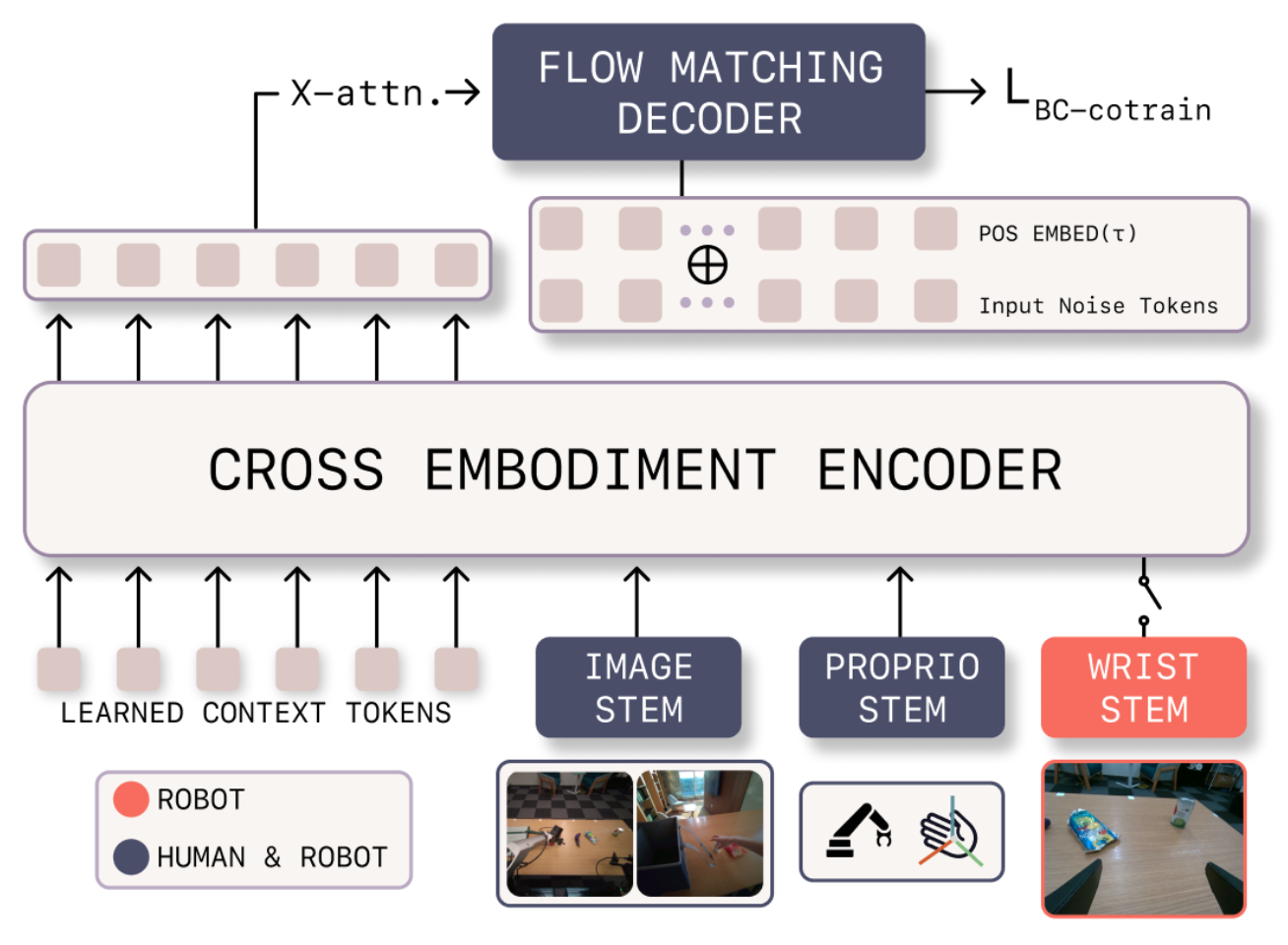
训练目标。编码器 f_φ 和解码器 π_θ 与 BC 协同训练损失联合优化。BC 协同训练损失是跨具身策略学习的常用方法,它在聚合的人类和机器人数据集上计算标准的行为克隆 (BC) 损失 L_BC-cotrain。实际上,在每个训练步骤中,对于每个具身 e ∈ {机器人, 人类},在人类和机器人样本的小批量上计算条件流匹配 (CFM) 损失:
L_BC-cotrain = Lrobot_CFM + Lhuman_CFM
评估设置
展开评估协议。评估在如图所示的四个具有代表性旗舰任务上进行。评估域内 (ID) 设置(其中任务布局与机器人训练数据匹配)和域外 (OOD) 设置(其中包含未见过的对象和环境)。对于每种方法,针对每个任务分别进行 20 次 ID 测试和 20 次 OOD 测试,初始条件随机化。性能评估采用任务特定的子任务指标,包括抓取、放置、中间操作和任务完成情况。为了便于比较,报告汇总所有测试结果的标准化分数。
机器人数据采集。对于每个任务,采集大约 150-300 次演示,每次演示中物体在工作空间内的位置、方向和组合均随机化。对于每个任务,从 EgoVerse-A 中记录的物体中选择 4-8 个物体用于演示。
人类数据能否提升机器人性能?
研究以人类为中心的数据能否可靠地提升机器人学习能力,以及性能是否会随着人类数据量的增加而提升。其并非针对单个系统进行优化,而是在多个机器人、实验室以及三个旗舰任务(单臂容器取物、精细化双手操作的杯碟放置和长时域双手操作的购物袋搬运)上测试结果的可复现性。用 EgoVerse-A 数据集的一个子集对所有模型进行联合训练,该子集包含各种特定任务的数据和域内人类数据。域内人类数据是在与机器人远程操作相同的任务定义下收集的,但在具身性、感知和运动执行方面有所不同。
与 EgoVerse-A 数据集联合训练可以提升机器人的性能和泛化能力。EgoVerse-A 数据集的存在始终能够将域内和域外 (OOD) 设置下的性能提升高达 30%。值得注意的是,演示速度和重置范围在不同的操控设置下有所不同。因此,比较添加人类数据带来的相对改进比比较绝对分数更有意义。虽然结果在大多数实例和任务中都表现稳健,但机器人 B 在购物袋任务中性能有所下降,而机器人 A 和机器人 C 的性能则有所提升。这种差异源于机器人 B 的特定实例限制,这迫使机器人演示偏离 EgoVerse-A 中的人类策略。
域对齐的数据能够实现从不同数据中迁移。此外,还研究机器人性能是否会随着 EgoVerse-A 中每个任务的人类数据多样性而扩展。对域内人类数据和不同域的人类数据进行扩展,而机器人数据保持不变。为了使扩展有效,该策略必须从不同的人类行为中提取可迁移的结构。
人类数据的多样性如何影响泛化能力?
上述实验依赖于来自多个实验室的自然聚合数据,这引入了不受控制且可能不平衡的多样性。先前的研究表明,机器人数据集中不同来源的多样性(例如环境和视角)可能对泛化能力产生不均衡的影响 [33, 36, 47, 62]。受这些发现的启发,开展对照研究,以分离场景和演示者多样性对人类数据采集环境的影响。主要报告基于人类的评估环境中的离线平均均方误差(Avg-MSE)指标。虽然该指标不能直接衡量下游机器人的性能,但它提供一个稳定的信号,用于比较不同多样性和数据规模下的泛化能力[51]。
演示者多样性扩展。在控制任务和场景的情况下改变人类演示者的数量。研究两种设置:(1)单场景,其中模型在固定的2小时预算内使用{1, 2, 4, 8, 16}个演示者进行训练,并在同一场景中对一个预留的演示者进行评估; (2) 多场景训练:在固定的 8 小时训练预算下,使用 {4, 8, 12} 个演示样本在 8 个场景中训练模型,并在相同环境下使用预留的演示样本进行评估。随着演示样本多样性的增加,训练集和验证集之间的重叠度也随之增加。
场景多样性扩展。在保持演示样本数量不变的情况下,改变训练场景的数量 {1, 2, 4, 8, 16},并在未见过的场景上进行评估。随着场景多样性的增加,模型的泛化性能在数据预算范围内得到提升。一旦数据量达到一定水平,增加数据密度带来的收益就会递减,而扩大场景覆盖范围则能带来显著的性能提升。这表明,在超过一定尺度后,环境多样性在概括过程中比在单个场景内收集的额外数据发挥着更为关键的作用。
多场景交互效应。最后,联合调整场景和演示器多样性,以反映真实的EgoVerse数据采集情况。在固定的4小时预算下,分别改变训练场景数{4, 5, 6, 7, 8}和演示器数{4, 8},并在未见过的场景和演示器上进行评估。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 17
17 0
0- 0



 已为社区贡献131条内容
已为社区贡献131条内容

所有评论(0)