大模型入门到放弃?这篇文章帮你理清所有核心概念
别再被“炼丹”、“AGI”、“对齐”这些词唬住了。这篇文章我们基于人工智能的核心要素:RAG、Prompt、Agent、Function call、Embedding、Fine tuning、Skills 对于大模型训练而言是一种什么关系。
前言
“训练大模型”,听起来像是顶尖科学家在实验室里做的事情。
高深的数学公式、神秘的神经网络、动辄上万张GPU……这一切似乎离普通开发者很远。但真的是这样吗?
今天,我想告诉你一个可能反直觉的结论:训练大模型,正在从“科学研究”快速演变为“工程设计”。
这意味着什么?意味着它不再是少数人的专利,而正在变成一项可以系统学习、有成熟方法论的工程技能。
前几天和一位做产品的朋友聊天,他问我:“我想用AI做点东西,但听到的词太多了——RAG、Agent、Fine-tuning、Prompt……它们到底是什么关系?我该从哪开始?”
这个问题问得特别好。
过去两年,大模型领域爆发了太多新概念。每个人都在造词,每个人都声称自己抓住了未来。但说实话,能把这些概念讲清楚、讲明白它们之间关系的人,并不多。
今天,我想用一篇文章,帮你彻底理清这些概念。
这不是一篇技术文档,不会堆砌公式和代码。这是一张认知地图,帮你在大模型的世界里找到方向。
一、先记住一个核心比喻
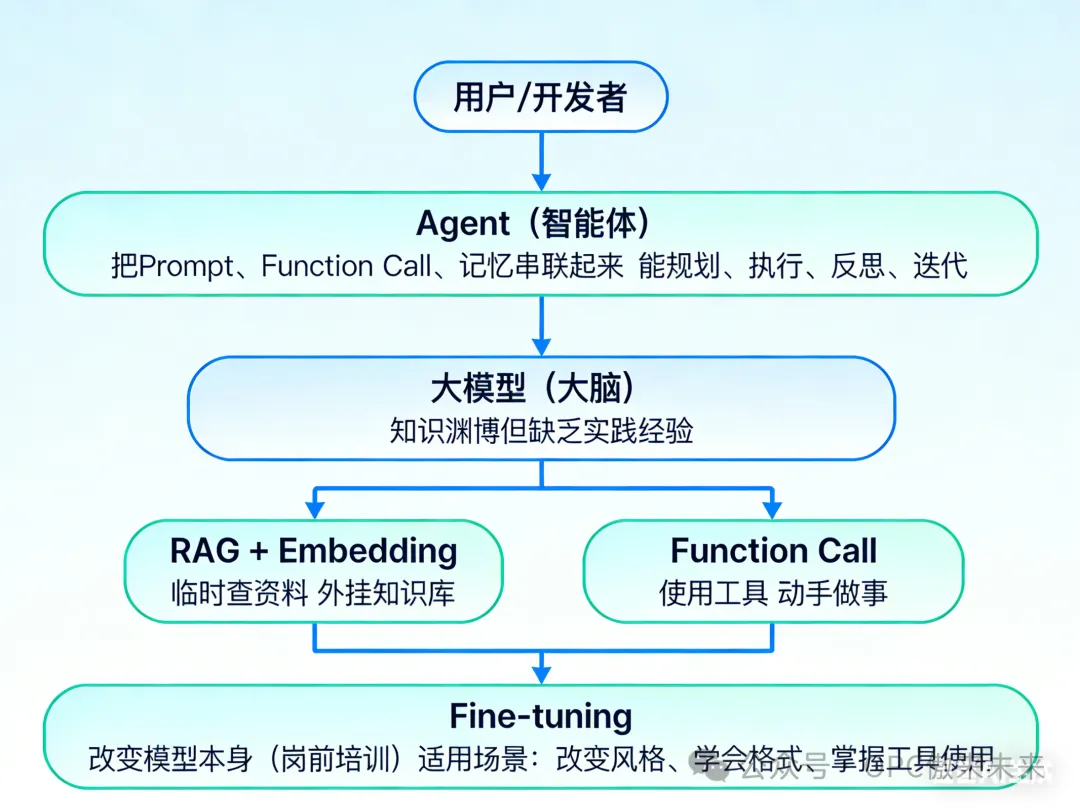
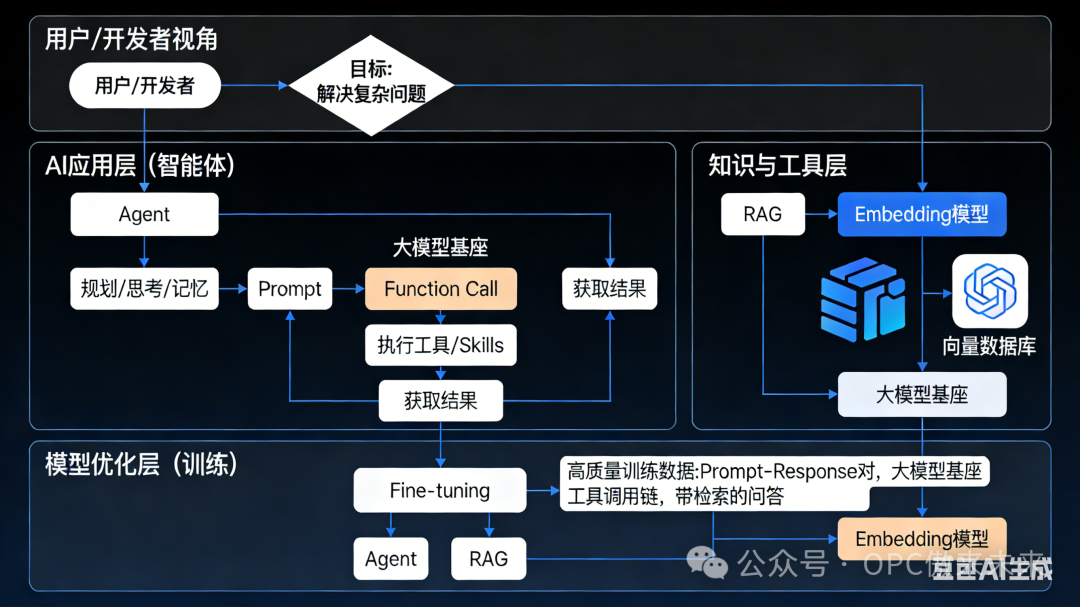
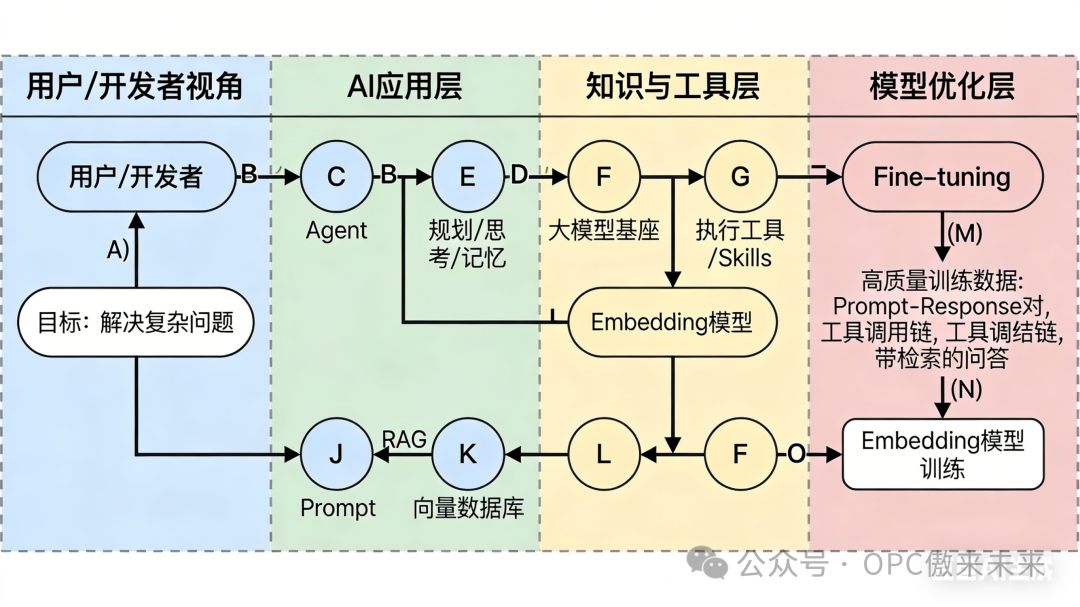
大模型是大脑,其他一切都是让这个大脑能活起来、被用起来、不断进化的神经系统、四肢和工具。
想象你训练了一个大模型,它就像一个刚刚毕业的、知识渊博但缺乏实践经验的大学生:
-
大模型本身:他的大脑,装满了课本知识
-
Prompt:你跟他说的话,你的问题或指令
-
Function Call / Skills:他能使用的工具(计算器、搜索引擎)
-
RAG / Embedding:他可以临时查阅的参考书
-
Fine-tuning:对他进行岗前培训,改变他的固有习惯
记住这个比喻,后面的所有概念都会变得清晰。
二、七个核心概念,逐个拆解
1. Prompt(提示词)—— 你和AI说话的方式
是什么:你输入给模型的那段文字。
有多重要:这是最基础、最常用、成本最低的交互方式。80%的问题,一个好的Prompt就能解决。
一个例子:
-
差劲的Prompt:「写个方案」
-
好的Prompt:「你是一名拥有10年经验的营销专家,请为一款面向25-35岁女性的智能手表写一份产品发布方案,预算500万,周期3个月」
训练角度:大模型学习的本质,就是海量的(Prompt,回答)对。训练的目标,就是让模型在看到任何Prompt时,能生成最合适的回答。
入门建议:不要一上来就学复杂的Prompt技巧。先学会「把话说清楚」。
2. RAG(检索增强生成)—— 让AI能“查资料”
是什么:让模型在回答问题前,先去你的知识库里搜索相关信息,然后基于搜到的内容回答。
解决什么问题:
-
模型不知道你公司的内部信息
-
模型的知识可能过时(比如不知道今天的新闻)
-
模型会“幻觉”(编造不存在的东西)
一个例子:
你问:「我们公司的年假政策是什么?」
没有RAG:模型可能随便编一个政策
有RAG:系统先去公司文档里搜到「年假政策」,把搜到的内容连同问题一起给模型,模型基于真实政策回答
关键点:RAG不需要训练模型。你只需要准备好文档库,模型就能用。这是最实用的技术,没有之一。
3. Embedding(向量化/嵌入)—— RAG的基石
是什么:把文字转换成一串数字(向量),让计算机可以“计算”文字之间的相似度。
为什么需要它:计算机不懂“意思”,但它懂数字。通过Embedding,我们可以让计算机找到“意思相近”的文档。
一个例子:
「苹果很好吃」和「我喜欢吃水果」——这两句话意思相近,它们的向量在空间里离得近。
「苹果很好吃」和「iPhone很贵」——这两句话意思不同,向量离得远。
训练角度:训练Embedding模型是一门独立的学问(叫对比学习),和大模型训练不同,但两者经常配合使用。
4. Fine-tuning(微调)—— 给AI“开小灶”
是什么:用你自己的数据,对已有模型进行额外训练,改变它的一部分参数。
和RAG的区别(这是最常见的困惑):
-
RAG:模型不改变,只是临时查资料。像给大学生一本参考书。
-
微调:模型本身被改变了。像给大学生做岗前培训。
什么时候用微调:
-
✅ 想让模型学会某种说话风格(客服语气、技术文档风格)
-
✅ 想让模型学会输出特定格式(JSON、Markdown)
-
✅ 想让模型学会某种行为模式(先思考再回答)
什么时候别用微调:
-
❌ 想注入大量新知识(用RAG,便宜、效果好、随时更新)
一个残酷的事实:大多数场景下,你不需要微调。先试试Prompt,不行就加RAG,还不行再考虑微调。这是成本和效果的黄金顺序。
5. Function Call(函数调用)—— 让AI能“用工具”
是什么:让模型不仅能“说话”,还能“动手”——调用外部工具,比如查天气、发邮件、算数学、调API。
一个例子:
你问:「北京今天天气怎么样?」
模型不会直接回答。它会输出一个指令:
调用“查天气”工具,参数:城市=北京系统执行这个工具,拿到结果(“晴,25度”),模型再把结果告诉你
训练角度:这是一种需要专门训练的高级能力。模型需要学会“什么时候该调用工具”、“调用什么工具”、“传什么参数”。
和Agent的关系:Function Call是Agent的“手”。没有Function Call,Agent只能想,不能做。
6. Agent(智能体)—— AI的“高阶玩法”
是什么:一个能自主规划、执行、反思的AI系统。它不是单次问答,而是一个循环:想 → 做 → 看结果 → 再想 → 再做。
一个例子:
你说:「帮我订一张明天去上海的机票,预算1000以内」
Agent会:
思考:需要查航班、比价格、选最便宜的
调用Function:查航班API
拿到结果:发现明天只有一班,价格1200
再思考:超出预算了,要不要问用户是否接受?
问你:「明天只有1200的,要订吗?」
注意:Agent不是一个独立的模型,而是一种架构模式,它把Prompt、RAG、Function Call、记忆等组合在一起。
现状:Agent很酷,但目前还不成熟。规划能力、长期记忆、稳定性都还有问题。可以关注,但不要All in。
7. Skills(技能)—— 以上概念的“封装”
是什么:一个比较宽泛的词,通常指把上面各种能力打包成一个“技能”,方便用户调用。
例子:
-
「写邮件技能」:背后是一个精心设计的Prompt
-
「计算器技能」:背后是一个Function Call
-
「客服机器人技能」:背后是RAG + Fine-tuning + Agent
训练角度:没有独立的“Skills训练”,它更多是产品层面的封装。
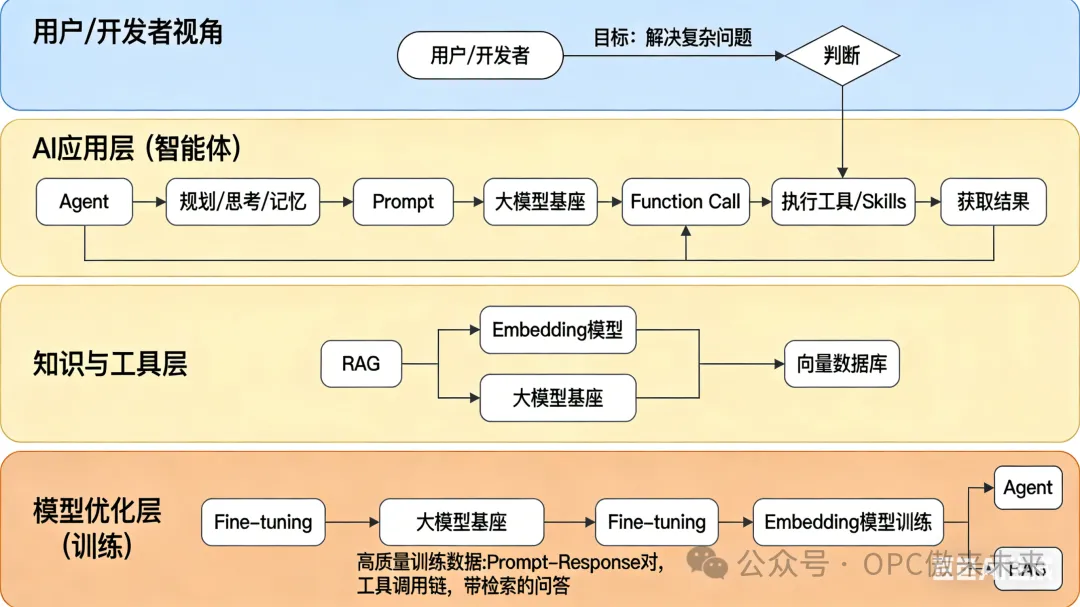
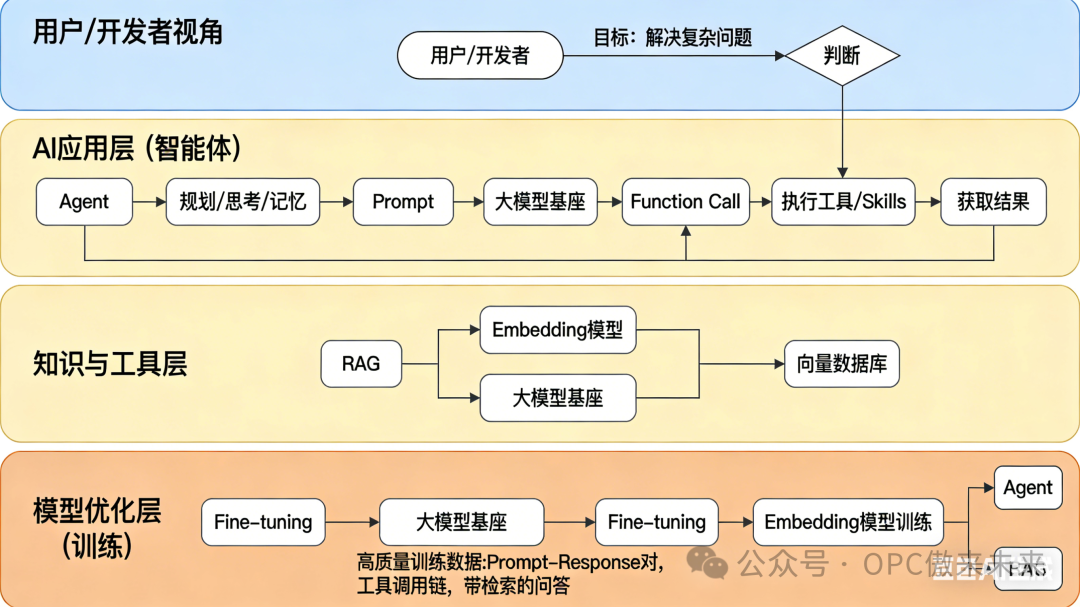
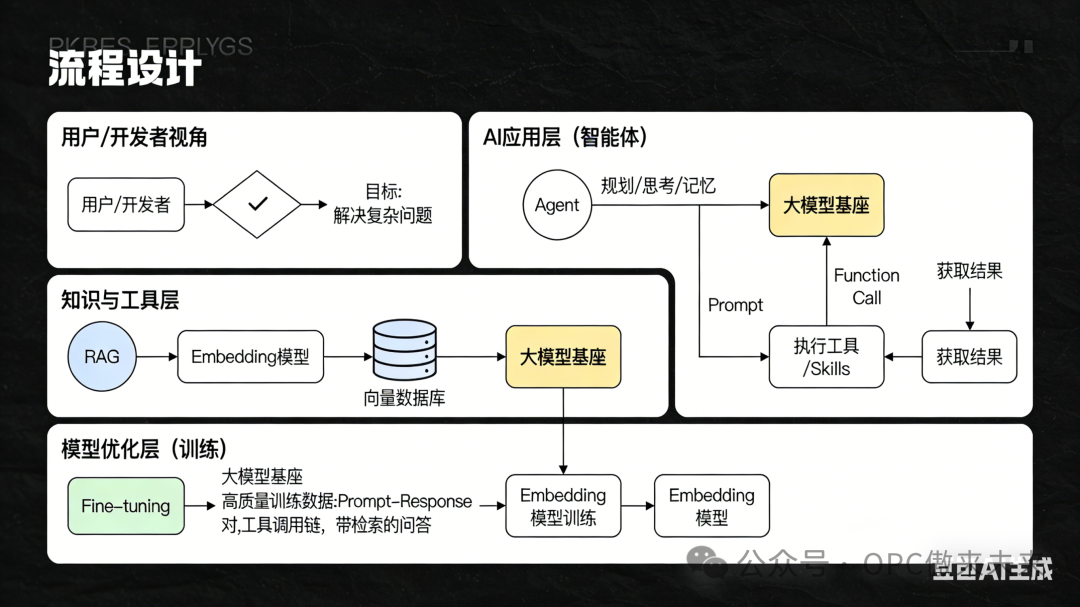
三、一张图看懂所有关系
四、给普通人的行动建议
如果你是产品经理/创业者
优先级排序:
-
Prompt:先学会把需求说清楚,解决80%的问题
-
RAG + Embedding:如果需要私有数据,这是第二优先级
-
Fine-tuning:只在需要统一输出风格或格式时才考虑
-
Function Call:如果需要AI操作外部系统
-
Agent:目前还不够成熟,保持关注即可
一句话建议:不要一上来就想着“训练模型”,大概率你只需要“用好模型”。
如果你是开发者
学习路径:
-
第1周:学会调用API,写清楚Prompt
-
第2-3周:搭建一个RAG系统(LangChain + 向量数据库)
-
第4周:尝试LoRA微调(单卡就能跑)
-
第5周起:根据需要学习Function Call和Agent
硬件门槛:一张RTX 3090/4090足够应付90%的学习场景。
如果你是决策者/投资人
几个判断标准:
-
这个项目需要“训练模型”吗? 如果答案是“是”,先问:能不能用RAG代替?90%的情况下能。
-
这个项目在追Agent风口吗? Agent是未来,但当下商业化落地还有很多坑。优先看有明确场景和收入的项目。
-
这个项目的技术壁垒是什么? 如果是“我们训练了自己的模型”,这大概率不是壁垒。真正的壁垒是:数据、场景、用户、网络效应。
五、三个最常见的误区
误区1:“我要训练自己的模型”
真相:你大概率不需要。开源模型已经很强了,你需要的是用好它,而不是重新发明它。
正确做法:选一个好用的开源模型(Qwen、Llama),用RAG注入私有知识,用Prompt和微调优化表现。
误区2:“微调可以让模型学会新知识”
真相:微调擅长改变“怎么说”,不擅长注入“新知识”。强行塞入大量新知识会导致灾难性遗忘。
正确做法:RAG负责知识,微调负责风格。两者结合,各司其职。
误区3:“Agent是银弹”
真相:Agent很酷,但还不成熟。规划能力、长期记忆、稳定性、成本都还是问题。
正确做法:保持关注,从简单场景开始尝试,不要All in。
六、写在最后
大模型领域正在经历一个有趣的转变:从科学研究变成工程设计。
这意味着什么?
意味着门槛在降低。一个本科生用开源代码和消费级显卡,一周内就能做出一个垂直任务上表现优异的模型。
意味着价值在转移。从“懂理论”转向“能落地”,从“发论文”转向“做产品”。
意味着机会在变大。不是每个人都有机会训练GPT-4,但每个人都有机会用GPT-4做出改变某个行业的应用。
所以,别再被那些高大上的词唬住了。
Prompt、RAG、Fine-tuning、Agent……它们不是玄学,而是一套可以学习、可以掌握、可以做出真正产品的工具。
你不需要成为AI科学家。
你只需要成为一个会用AI的人。
而会用AI的人,正在成为这个时代最稀缺、最有价值的人。
为了大家便于理解大模型 我给大家整理了几张图:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)