我把 Anthropic 的 Harness 工程思想做成了一个 Skill
用 AI 写代码有多难?不是写不出来难,是让它稳定交付可用的东西很难。这篇文章说说 Anthropic 工程团队的解法,以及我怎么把它落成了一个可以复用的 Skill。
2026 年 3 月 24 日,Anthropic 工程博客发了一篇文章:《Harness design for long-running application development》[1]。
作者 Prithvi Rajasekaran 在开头说了一句话:
Harness design is key to performance at the frontier of agentic coding.
框架设计,是 AI 代码能力前沿的核心。
读完之后,我花了几天把这套思想落地成一个可以直接用的 WorkBuddy Skill,开源在 GitHub:Drrreistein/web-harness[2]。这篇文章说说我的理解和做法。
01 Anthropic 发现了什么问题
用过 AI 辅助编程的人都知道。
不是代码写不出来——现在随便一个 AI 工具,给它一句话,几分钟就能吐出几百上千行代码。但真正让人抓狂的是:宣称完成的功能,一跑发现根本不能用。
列表不刷新,需要手动 F5。点了保存,数据库没写进去。错误状态没有任何提示。设计看着像所有 AI 项目的母版——白卡片、紫色渐变、一眼就认出来的"机器审美"。
更麻烦的是,AI 很善于说"好的,修好了",然后下一轮又出现同样的问题。
Anthropic 工程团队在用 Claude 做长周期 web 应用开发时,系统性地遇到了同样的问题。
他们把这个现象总结得很准:AI 在执行长任务时,最核心的挑战不是能力,是可靠性。上下文溢出、自评估失真、状态传递断裂——每一个都能让你的开发流程在关键时刻崩掉。
让同一个 Agent 又写代码、又评估自己写的代码,结果是"自评估放水"——代码质量描述得很好,实际功能跑不通。单 Agent 在复杂任务下还容易出现上下文溢出、方向跑偏、表面完工等典型失败模式。
他们的解法从 GAN(生成对抗网络)中找到了灵感:把生成和评估彻底分离。
一个 Agent 负责生成,另一个 Agent 负责挑毛病。两者之间有明确的"合同"(Sprint Contract)约束交付标准,评估器通过 Playwright 实际跑端到端测试,而不是看代码猜结论。
⚡ 核心洞察
将执行者和评判者分离,是解决自评估失真的有力杠杆。 *Separating the agent doing the work from the agent judging it proves to be a strong lever to address this issue.*
02 我如何把它变成一个可复用的 Skill
Anthropic 文章里讲的是设计原则,没有直接给出可执行的工具。我做的事情是:把这套原则编码成约束,并结合其他用于规划、前端设计、开发等Skills,打包成一个 WorkBuddy Skill,让 AI 在任何新项目里都能遵循这套工作流。
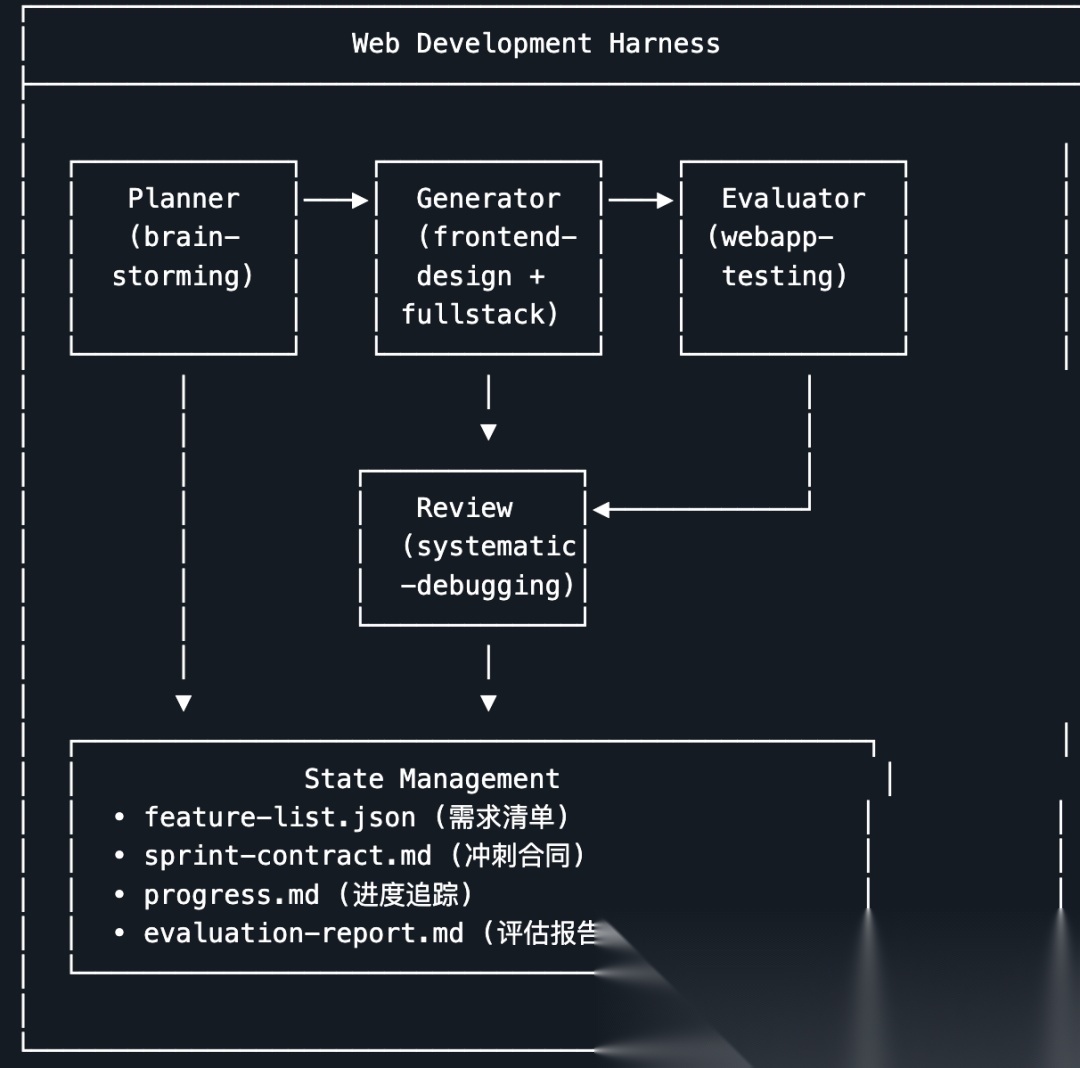
核心是三个角色:
Planner(规划者):用 brainstorming + writing-plans skill,把用户 1-4 句话的需求扩展成完整的 Product Spec,然后拆成 JSON 格式的 feature list。每个 feature 包含描述、优先级、端到端测试步骤和初始状态 passes: false。
Planner 有一条硬性规则:草稿完成后必须暂停,输出结构化摘要向用户确认。没有明确的"确认",不允许生成 feature list,不允许开始开发。方向跑偏是最贵的错误,在规划阶段就对齐,比开发到一半发现跑偏要便宜得多。
Generator(实现者):用 frontend-design + fullstack-developer + test-driven-development skill,按 TDD 节奏增量实现。每个 feature 独立一轮,六步不可跳过——选 feature、建 feat/ 分支、先写测试(让测试变红)、实现代码(让测试变绿)、E2E 验收、merge main 打 tag。
特别要说的是第三步:先写失败的测试,再写实现。这个 TDD 约束解决了"AI 写完代码说自己写完了"的问题——测试是红的,就是没完成;测试变绿,才算真的完成。
每轮开新的上下文窗口,不依赖对话历史传递状态,所有状态靠仓库文件(progress.md、feature-list.json、evaluation-report.md)来同步。
Evaluator(验收者):用 webapp-testing + agent-browser skill,完全独立地跑端到端测试、截图存证、四维度打分。四个维度是功能完整性(40%)、设计质量(25%)、代码质量(20%)、可用性(15%),任意一项低于 6 分直接 FAIL,不允许 Generator 自评。
这三个角色里,最关键的是 Evaluator 的独立性。Generator 自己觉得做好了不算,Evaluator 的截图和测试日志才算。
03 六条防线
把工作流跑通不难,难的是防止 AI 在各种情况下走捷径。框架里设计了六条防线,每条对应一个真实失败模式:
防线 1:上下文溢出。 多轮对话后,AI 开始"忘事",之前的决策和状态悄悄丢失。解法是每轮开新窗口,靠仓库文件传递状态,上下文从不积累。
防线 2:虚假完工。 AI 宣称功能完成,实际无法使用。解法是强制 E2E 测试,passes: true 必须由 Evaluator 签字,Generator 无权自行标记。
防线 3:自评估放水。 Generator 自己评价自己,标准自然会降低。解法是 Evaluator 完全独立,必须用 agent-browser 截图作为物证。
防线 4:设计模板化。 AI 生成的界面千篇一律,紫色渐变白卡片。解法是 frontend-design skill 加上"规避 AI 通用模板"的引导,要求有定制化细节。
防线 5:方向跑偏。 Planner 自行决定产品方向,到开发阶段才发现问题。解法是 Planner 草稿完成后强制 PAUSE,结构化摘要等用户明确确认。
防线 6:并行合并冲突。 多个 Generator Agent 同时开发,merge 时产生冲突。解法是三层机制——模块所有权划分(每个 Agent 只写自己的 scope)、接口契约冻结(共享文件开发期间禁止改签名)、串行合并队列(按依赖顺序 rebase + merge)。
04 实战结果
框架设计出来不算完,跑通一个真实项目才算验证。
我用这套框架完整走了一遍极简待办清单 Web App 的开发流程,React 18 + TypeScript + Vite 技术栈,纯 CSS 极简黑白灰设计,零 UI 库依赖。
Planner 阶段把需求拆成 10 个 Feature,分 P0/P1/P2 三级优先级,每个 Feature 都有明确的端到端测试步骤。用户确认规格后,Generator 开始增量执行。
到最后,7 个核心 Feature 全部交付,Evaluator 跑了 17 条 E2E 测试全部通过,最终评分 10/10。
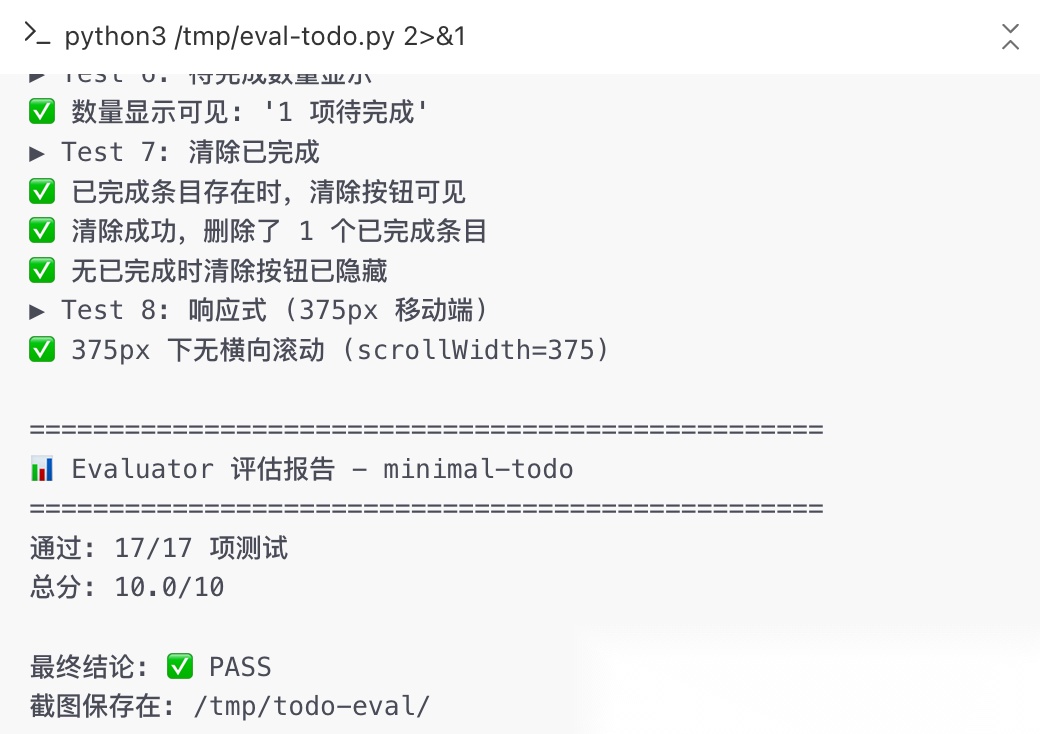
全程没有一次直接在 main 分支改代码,也没有靠对话历史传递状态。
实际体感是:每一轮的边界非常清晰。你知道这一轮做什么、做完的标准是什么、谁来确认。这种清晰感让 AI 的输出变得可预期,而不是"看运气"。
这是用 Harness 框架约束之后的结果,不是把需求一股脑扔给 AI 然后修修改改的结果——两种体验,差距非常大。
项目代码开源:Drrreistein/todos[3]
Skill 本身也开源:Drrreistein/web-harness[4]
05 Anthropic 文章里最值得记的两句话
第一句,关于工程本质:
The key insight is that long-running agent tasks are not just “bigger” versions of single-turn interactions. They require fundamentally different engineering primitives: state management, error recovery, progress tracking, and independent evaluation.
核心洞见在于,长时间运行的智能体任务并非只是单轮交互的 “放大版”。它们需要截然不同的基础工程原语:状态管理、错误恢复、进度跟踪以及独立评估。
长任务不是把单轮交互放大,而是完全不同的工程问题。状态管理、错误恢复、进度追踪、独立评估——缺一不可。
web-harness 做的事情,就是把这四个"工程原语"变成了 AI 开发时默认遵守的规则,而不是靠每次提示词去提醒。
第二句,关于未来:
The space of interesting harness combinations doesn’t shrink as models improve. Instead, it moves, and the interesting work for AI engineers is to keep finding the next novel combination.
随着模型不断优化,有价值的框架组合空间并不会缩减,反而会发生转移,而人工智能工程师的核心工作,便是持续探寻下一种新颖的组合方式。
随着模型能力提升,有趣的框架组合空间并不会缩小,而是会转移。AI 工程师的工作是持续寻找下一个新颖的组合。
最核心的判断
Harness 设计不是一次性的,每一代模型能力的跃升都会让原有框架的某些部分变得不必要,但同时开放出新的可能性。这是一个持续演进的工程方向,而不是一个可以一劳永逸的方案。
如果你正在用 AI 做全栈项目,并且遭遇过文章开头那些翻车场景,可以试试这套框架 👇
Drrreistein/web-harness: https://github.com/Drrreistein/web-harness
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献243条内容
已为社区贡献243条内容

所有评论(0)