长程智能体入门基础教程(非常详细),反思经验驱动新范式全拆解,收藏这一篇就够了!
UCSD、上海交通大学、南京大学联合提出 LEAFE 框架,通过反思式回溯探索与经验蒸馏,将环境反馈内化为模型的纠错能力,在长程交互任务中 Pass@128 提升最高达 14%,显著超越 GRPO 等主流 RLVR 方法。
当前 LLM Agent 的后训练,主流路线是 RLVR(Reinforcement Learning with Verifiable Rewards)—— 让模型在环境中采样多条轨迹,拿最终的成功/失败信号做策略梯度更新。这条路在短程推理任务上表现不错,但放到长程交互场景中就暴露出一个根本性的问题:终端标量奖励提供的监督信号太稀疏了。大量「部分正确但最终失败」的轨迹被直接丢弃,模型只学到了「复读已有的成功模式」,而没有真正习得「出错后如何纠偏」的能力。
这篇来自 UCSD 的 Hao Zhang 团队(一作 Rui Ge,联合上海交大、南京大学)的工作,正是瞄准了这个痛点。论文标题叫 Internalizing Agency from Reflective Experience,提出了一个名为 LEAFE(Learning Feedback-Grounded Agency from Reflective Experience)的两阶段框架。核心思想简洁而优雅:与其只奖励成功的轨迹,不如让模型主动反思失败,找到出错的关键决策点,回溯到那个节点,用总结出的经验指导新的探索分支,然后再把这种「经验引导下的纠偏能力」蒸馏回模型权重里。
论文在 CodeContests、WebShop、ALFWorld、ScienceWorld、Sokoban 五个长程交互基准上做了广泛实验。结果很有说服力:LEAFE 不仅提升了 Pass@1,更关键的是在大采样预算下(Pass@128)展现出持续增长的优势,最高提升达 14%。相比之下,GRPO 的 Pass@k 曲线很快趋于饱和 —— 这恰恰印证了论文的核心论点:outcome-driven training 本质上是分布锐化(distribution sharpening),而 LEAFE 做的是能力边界的真正拓展(agency internalization)。
从技术视角看,这篇文章的贡献在于提出了一种结构化的「failure → reflection → rollback → correction」探索范式,并配合一个反事实蒸馏(counterfactual distillation)机制完成经验内化。实验设计比较全面,消融分析也比较扎实。作为一篇 2026 年 3 月的 preprint,写作质量和实验覆盖度都值得一读。
● ● ●
- Introduction
LLM Agent 的核心能力不是一次做对,而是「出错后还能爬起来」—— 但当前的训练方法恰恰忽略了这一点。
1.1 从「被动回答者」到「自主行动者」
大语言模型正在经历一场身份转变:从被动的文本生成器,变成能够在复杂环境中规划、执行、纠错的自主智能体。
在 Web 导航、代码生成与调试、长程任务规划这些交互式场景里,Agent 的成功不再取决于单轮回答的质量,而取决于一种更底层的能力 —— agentic behavior:做出一系列决策,观察每个决策的后果,然后从错误中恢复。
更重要的是,这些环境会提供丰富的结构化反馈(structured feedback)。比如:
● 无效的动作指令
● 状态转移信息
● 编译器报错
这些反馈远比简单的「成功/失败」信号有用 —— 它们往往直接告诉你为什么轨迹偏离了正轨,以及该如何纠正。
💡LLM Agent 的核心承诺不是 one-shot correctness,而是 robust decision-making under feedback:检测轨迹何时正在失败,并据此更新后续动作。
1.2 RLVR 的困境:分布锐化
当前 Agent 后训练的主流范式是 RLVR(Reinforcement Learning with Verifiable Rewards):模型采样多条轨迹,拿最终的成功/失败标量奖励做策略梯度优化。代表性算法包括 PPO、GRPO 等。
但在长程交互场景下,这种 outcome-driven 的方式有一个根本缺陷:
⚠终端标量奖励只在轨迹级别提供监督。在大量 rollout 中,只有极少数最终成功,梯度更新被少数已经「做对了」的轨迹主导,大部分「部分正确的失败」轨迹几乎不贡献任何学习信号。
结果就是,RLVR 本质上在做 distribution sharpening(分布锐化):
● 它把概率质量集中到一小组已经存在于基础模型长尾区域的成功行为上
● Pass@1 提升了,但 Pass@k(k 很大时)提升有限甚至为负
● 模型学会了更好地「复现」已有的成功模式,而没有真正拓展解题能力的边界
换句话说,RLVR 偏向于利用(exploit)已有能力,而非探索(explore)能力边界之外的行为。
这导致了一个实际后果:部署时必须依赖昂贵的 test-time computation(多次重试、sampling-and-voting、显式树搜索)来弥补模型自身纠错能力的不足。
1.3 核心区分:分布锐化 vs. 能力内化
论文在这里提出了一个非常重要的概念区分:
🔑Distribution Sharpening(分布锐化) vs. Agency Internalization(能力内化)
前者是让模型更擅长复现已有的成功轨迹;后者是训练模型习得一种与环境交互、解读结构化反馈、反思哪里出了错、并据此修正后续决策的内在能力(agency)。
GRPO 这类方法可以 upweight 成功轨迹,但它把丰富的交互反馈(无效动作、报错信息、测试失败)压缩成了一个 episode-level 的标量信号。这种方式提供的监督很弱 —— 它不告诉你轨迹在哪里出了问题,也不告诉你应该怎么改。
而真正的 robust agency 需要的是:把纠错过程本身内化到模型里 —— 识别导致失败的关键决策点,以反馈为条件进行定向修正,而不是依赖盲目重试或外部的树搜索。
Figure 1 直观地展示了这一点:在 CodeContests 上,LEAFE(红色曲线)的 Pass@k 随采样预算持续攀升,而 GRPO 的曲线在 base model 之上几乎没有明显提升。这说明 LEAFE 真正拓展了模型的能力边界,而不仅仅是锐化了现有分布。
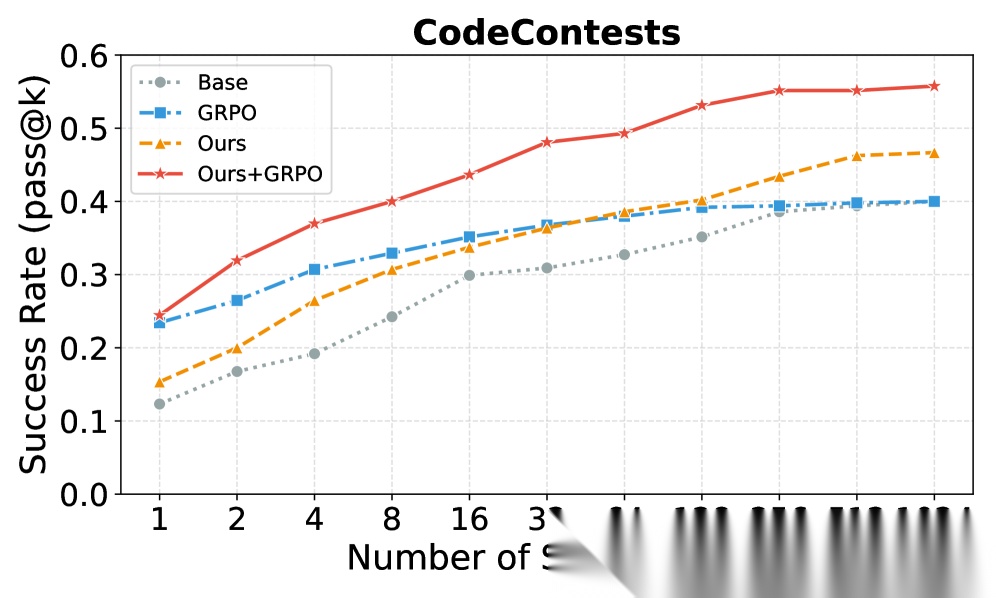
Figure 1: Internalizing feedback-grounded agency improves model capability (i.e., Pass@K) in long-horizon interaction, while outcome-only training (e.g., GRPO) yields limited gains beyond the base model.
1.4 LEAFE:从反思经验中学习
为了解决上述问题,论文提出了 LEAFE(Learning Feedback-Grounded Agency from Reflective Experience),一个两阶段的框架:
🔧Stage 1: Tree-Based Experience Generation with Rollback(基于树的经验生成与回溯)
Agent 在探索过程中周期性地进行反思(reflection),将环境反馈总结为可执行的经验(experience summary),回溯到更早的决策点,并在经验指导下探索替代分支。这样就生成了 failure → rollback → fix → success 形式的轨迹。
🔧Stage 2: Experience Distillation(经验蒸馏)
通过 experience-to-policy distillation,将 Stage 1 中经验引导下的纠偏决策蒸馏回模型权重。关键在于:训练时模型只看到原始历史(不含经验提示),但要求生成经验引导后的纠正动作。这样在推理时,模型无需显式的反思步骤,就能做出更好的纠偏决策。
1.5 实验验证
论文在五个长程交互基准上进行了全面评估:
● CodeContests(竞赛级编程,带执行反馈)
● WebShop(Web 导航购物)
● ALFWorld(文本化家务任务)
● ScienceWorld(科学实验模拟)
● Sokoban(推箱子规划)
在固定交互预算下,LEAFE 一致性地提升了 Pass@1,并在 Pass@k 上显著超越 GRPO 等 outcome-driven 方法和 EarlyExp 等 experience-based 方法,Pass@128 最高提升 14%。
📌核心结论(Central Takeaway)
“By enabling backtrack during exploration and learning from the resulting reflective experience turns environment feedback into actionable supervision, shifting the burden of competence from heavy test-time sampling to internalized, experience-driven agency.”
通过在探索中启用回溯、从反思经验中学习,LEAFE 将环境反馈转化为可执行的监督信号,把能力负担从昂贵的 test-time 采样转移到了内化的、经验驱动的 agency 上。
1.6 论文贡献
论文总结了三个核心贡献:
-
结构化探索(Structured exploration via feedback-to-experience):提出反思式回溯机制,将标量信号转化为 experience-guided branches(回溯 + 纠正),实现超越基础策略主导模式的定向探索。
-
更丰富的监督信号(Richer supervision than scalar rewards):经验轨迹提供了 decision-level 的 reflect → revise 监督,明确指出 rollout 在哪里出了错、如何修复,而非简单地对每条轨迹打一个终端奖励。
-
内化的纠错能力提升 Pass@k(Internalized recovery improves Pass@k):通过在 post-backtrack actions 上微调,将反馈驱动的 agency 内化到模型权重中,拓展行为覆盖面,在长程交互中 Pass@128 最高提升 14%。
本章小结
本章指出了当前 RLVR 范式在长程 Agent 训练中的根本局限 —— distribution sharpening:模型只学会了复现已有成功,却未习得从失败中恢复的能力。论文提出了 distribution sharpening 与 agency internalization 的核心区分,并引出了 LEAFE 框架的两阶段设计:Stage 1 通过反思式回溯生成经验引导的纠偏轨迹,Stage 2 通过反事实蒸馏将这种纠偏能力内化到模型权重。实验覆盖五个长程交互基准,核心指标是 Pass@k,旨在衡量模型的真实能力边界而非单次命中率。
- Learning From Reflective Experience
本章是全文的技术核心。LEAFE 框架分为两个阶段:Stage 1 通过反思式回溯构建经验引导的探索树,Stage 2 通过反事实蒸馏将经验内化到模型权重中。
Figure 2 给出了 LEAFE 框架的全景。
● Stage 1:在探索过程中,Agent 周期性地审视当前轨迹,识别出次优的决策点(图中红色标记的 ),生成可执行的经验摘要 ,然后回溯到该点并在经验指导下探索新分支。
● Stage 2:从成功轨迹中采样 rehearsal 数据保持基础能力,同时从分支点提取 counterfactual 数据(原始 prompt + 经验改进后的动作)来内化探索多样性。
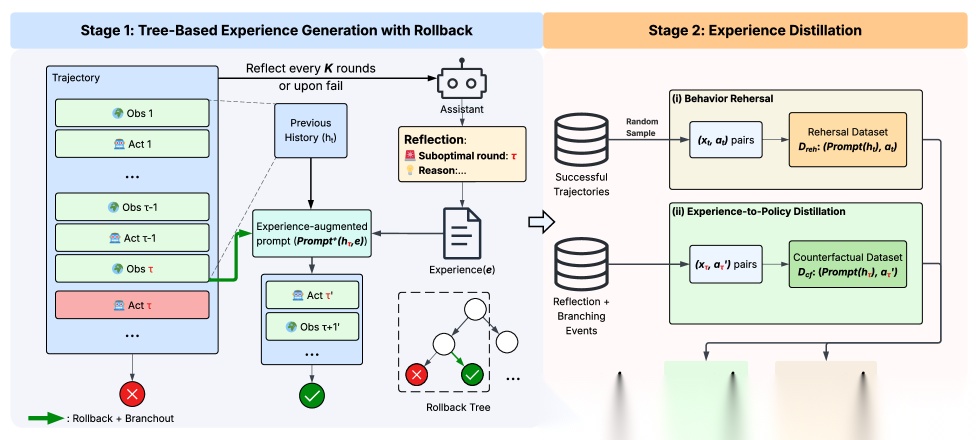
Figure 2: Illustration of the LEAFE framework. Stage 1: During experience collection, the assistant periodically reviews the current trajectory and identifies a suboptimal round (denoted as red-colored τ\tau). It then produces the actionable experience ee, which is concatenated with the restored history to facilitate subsequent attempts. Stage 2: During experience distillation, the model optimizes a joint loss using two datasets: randomly sampled rehearsal pairs to maintain capabilities, and counterfactual pairs (original prompts paired with experience-improved actions) to internalize diverse exploration. For simplicity, we depict one branching event from the rollback exploration tree.
3.1 Tree-Based Experience Generation with Rollback(基于树的经验生成与回溯)
3.1.1 Setup and Notation(基本设定)
考虑一个带有最大时间步 的情节式交互环境 。
对于给定的任务指令 ,一个 episode 由一系列环境状态 刻画。每个时间步 ,Agent 接收观察 并生成动作 。
环境的状态转移由函数 定义:
即在状态 下执行动作 ,环境转移到 并返回观察 。当达到步数上限 或触发终止条件(成功或不可逆失败)时,episode 结束。
这里的关键点是:环境状态 是可回溯的 —— 可以通过重置环境并重放动作序列 来恢复任意历史点的状态。这为 rollback 机制提供了基础。
3.1.2 Periodic Reflection(周期性反思)
利用经验的一个根本挑战在于:语言反馈本质上是定性的、非结构化的,难以通过标准优化直接内化到模型权重中。
💡LEAFE 的处理思路:把经验当作一种 contextual intervention(上下文干预),通过将其注入输入上下文来引导策略转变(policy shift)。而不是试图直接通过梯度优化来处理自由文本形式的反馈。
受 rollback 机制的启发,每隔 步或失败时,Agent 会调用一个反思程序。给定交互历史和反思提示,策略生成一个回溯目标和一个经验摘要:
其中:
● 指向轨迹偏离正确路径的那个时间步
● 是一段自然语言的诊断 + 修复建议,用于指导后续的重新尝试
❓反思的触发时机是什么?
两种情况:(1) 每隔固定的 个交互步,周期性地发起反思;(2) 当 episode 以失败结束时,立即触发反思。具体的 值因任务而异:ALFWorld 和 ScienceWorld 用 ,WebShop 和 Sokoban 用 ,CodeContests 用 (因为最大 horizon 只有 4)。
3.1.3 Branching via Rollback(通过回溯进行分支)
有了回溯目标 之后,接下来的操作分三步:
第一步:状态恢复
重置环境并重放原始动作序列 ,恢复环境状态 和对应的交互历史 。
第二步:经验引导的动作生成
在经验 的指导下,策略生成一个修正后的动作:
注意,这里的条件中同时包含了原始历史 、任务指令 、以及经验摘要 。
第三步:分支执行
执行 使环境转移到新状态 ,有效地从原始的次优路径上分支出去。然后 Agent 从 继续 rollout,直到下一次周期反思或 episode 终止。
🔧树的构建策略:BFS 队列
分支请求通过一个基于队列的**广度优先搜索(BFS)**策略管理。通过迭代地从队列中选取目标并生成新轨迹,系统构建了一棵隐式的 rollback tree。探索持续进行,直到达到最大树深度或耗尽分配的尝试预算。
❓为什么用 BFS 而不是 DFS?
BFS 保证了各个分支点的探索宽度更均衡,不会过早地深入某一条分支而忽略其他可能性。这对于经验生成很重要 —— 我们需要多样化的纠偏经验,而不是只深挖某一个方向。
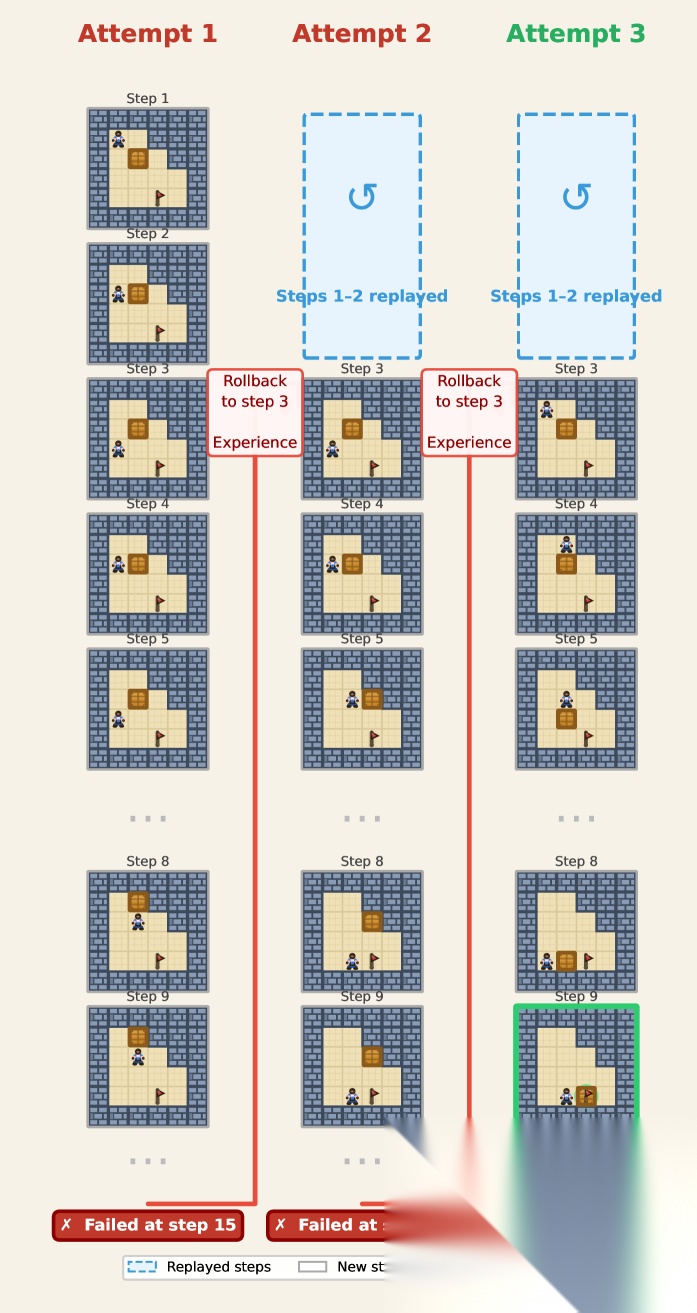
Figure 5: A example on Sokoban illustrating Stage 1 of LEAFE. Starting from a failed trajectory, the agent reflects on the interaction history, identifies an earlier suboptimal decision(step 3), and generates a compact experience summary for rollback-based revision. The environment is then reset to the selected step, the prior history is replayed(step 1-2), and a new branch is explored under the guidance of the reflected experience. Repeating this failure → reflection → rollback → correction process enables the agent to recover from early mistakes and eventually reach a successful solution.
Figure 5 给出了一个 Sokoban 上的具体示例:
● Attempt 1:Agent 从初始状态开始执行,在 Step 3 做出了一个次优决策,最终在 Step 15 失败
● 反思:Agent 审视交互历史,识别出 Step 3 是关键的次优决策点,生成经验摘要
● Attempt 2:环境重置到 Step 3(重放 Step 1-2),在经验指导下生成新的 Step 3 动作,但仍然失败
● Attempt 3:再次反思和回溯,这次成功找到解法
整个过程展示了 failure → reflection → rollback → correction 的循环,每次循环都在利用之前的失败经验来指导新的探索。
3.1.4 整体流程总结
把 Stage 1 的整体流程串起来:
-
对每个任务,从初始状态开始 rollout
-
每隔 步或失败时,触发反思,生成
-
将 加入 BFS 队列
-
从队列取出目标,回溯 + 分支,形成新轨迹
-
新轨迹中可能又触发新的反思,产生更多分支
-
直到达到最大树深度或尝试预算耗尽
整个过程构建了一棵隐式的 rollback tree,其中每个节点对应一个反思-回溯事件,边对应经验引导下的新轨迹。
3.2 Experience Distillation(经验蒸馏)
Stage 1 生成了经验引导下的改进轨迹,但这些改进依赖于显式的经验提示 。Stage 2 的目标是:把这些经验引导的改进内化到模型参数中,让模型在推理时无需显式经验就能做出更好的决策。
这里构建了两种类型的监督数据,进行标准的 next-token likelihood 训练。
(i) Behavior Rehearsal(行为彩排)
为了缓解灾难性遗忘(catastrophic forgetting)并保持 Agent 的基本任务解决能力,论文引入了一个 rehearsal set ,从成功的 episode 中采样。
受 reject sampling 的启发,把成功的 rollout(包括通过分支生成的)视为高质量示范。对每条成功轨迹,提取状态-动作对 ,优化 rehearsal 损失:
这个损失的本质是:最大化导致最终成功的动作的似然性,确保策略在适应新经验的同时保持稳定的基线性能。
❓为什么需要 Behavior Rehearsal?
如果只用 counterfactual 数据做 SFT,模型可能会「忘记」它本来就会的那些基本技能。Rehearsal 起到了一个「锡纸」的作用,保证新学到的纠偏能力不会以牺牲基础能力为代价。论文实际上只随机采样了 20% 的成功 rollout 来组成 rehearsal set。
(ii) Experience-to-Policy Distillation(经验到策略的蒸馏)
这是 LEAFE 的核心监督信号。
当经验 在第 轮注入后产生了改进的动作 时,论文将其视为原始历史(不含经验)下的一个 counterfactual target(反事实目标)。
🔑反事实蒸馏的核心思想:在训练时,模型只看到原始历史 (不提供经验 ),但要求生成经验引导后才能做出的纠正动作 。这样就把「经验引导下的策略转变」内化到了模型权重中。
具体来说,对于 中的每个分支事件,最大化纠正动作 在只给原始历史和指令条件下的似然性:
这个损失的精妙之处在于:它把经验增强后的决策映射回了无经验的上下文。这样就有效地拓展了模型的策略空间 —— 让 Agent 在遇到次优状态时,能够在其内在策略下做出纠正动作,从而提升 Pass@k,而无需在推理时额外的反思步骤。
❓为什么不直接在推理时保留经验提示?
两个原因:(1) 推理时的经验需要额外的反思步骤和环境回溯,增加了延迟和复杂度;(2) 通过蒸馏,经验被压缩进模型权重,模型可以在单次 rollout 中就做出更好的决策,从根本上减少了对 test-time 计算的依赖。这正是「内化」的精髓所在。
训练目标(Training Objective)
最终的训练目标联合优化反事实蒸馏和行为彩排:
其中 是控制 rehearsal 强度的超参数。
这个多任务损失的设计逻辑很清晰:
● 负责注入新能力 —— 将经验引导的纠偏策略内化到模型中
● 负责保持旧能力 —— 缓解灾难性遗忘,维持基线任务性能
📌经验蒸馏的效果
通过将经验引导的替代行为注入到策略的内在动作分布中,LEAFE 增强了探索多样性,并显著提升了有限 test-time 采样下的 Pass@k。模型不再只会单一的成功模式,而是拥有了更丰富的行为覆盖面。
本章小结
LEAFE 的技术核心分为两阶段。Stage 1 通过周期性反思生成回溯目标和经验摘要,并通过 BFS 队列管理的回溯分支机制构建经验探索树,将环境反馈转化为结构化的 failure → rollback → fix → success 轨迹。Stage 2 则通过双损失设计完成内化: 将经验引导下的纠偏动作映射回无经验上下文(反事实蒸馏), 通过成功轨迹的重放缓解灾难性遗忘。最终,模型在推理时无需显式反思,就能在其内在策略分布中注入了更多样化的纠偏行为,从而提升长程交互场景下的 Pass@k。
- Experiment
本章是全文的实验验证部分。论文在五个长程交互基准上全面评估 LEAFE,从主结果、能力缩放、有效性分析、消融实验多个角度展示 LEAFE 的优势。
实验设置
模型选择
论文使用了两个主流开源模型系列:
● Qwen2.5 系列:7B / 14B / 32B / 72B
● Llama3/3.1 系列:8B / 70B
这些模型被选中是因为它们在 RLVR 和 agentic reasoning 研究中被广泛采用为标准化基准。它们强大的推理和指令跟随能力为展示 LEAFE 的效果提供了严格的基线。
数据集
五个基准任务,覆盖了从 Web 导航到竞赛编程的广泛场景:
-
WebShop:模拟在线购物,需要在超过一百万个产品中通过多跳搜索和属性匹配导航
-
ALFWorld:文本化家庭任务,测试模型的 grounded common-sense reasoning
-
ScienceWorld:科学实验模拟环境,需要操作物体、圴具并遵循程序约束
-
Sokoban:推箱子拼图,需要精确的顺序操作和有效的错误纠正
-
CodeContests:竞赛级编程,带执行反馈的测试用例验证
基线方法
论文与四个基线进行了对比:
● Base:指令模型,无任务特定微调
● GRPO-RLVR:基于可验证奖励的 outcome-supervised RL
● EarlyExp:无奖励的 Agent 学习,将早期交互经验转化为监督
● ACE:无训练的、基于 prompt 的方法,通过构建 evolving playbook 来改进 Agent
指标
● Pass@1:单次尝试通过率,衡量 exploitation 能力
● Pass@128:128 次采样下的 best-of-k 表现,作为模型 exploration capacity 和能力边界的代理指标
所有 Pass@128 都是从训练后的策略的独立推理采样中计算的(不使用 Stage 1 的 rollback 或经验引导分支)。
4.1 Main Results(主结果)
四个交互式 Agent 基准
Table 1 展示了在 WebShop、ALFWorld、ScienceWorld、Sokoban 上的全面结果。全景看下来,几个核心观察:
📌LEAFE 的优势在大 k 时最为显著。 虽然 GRPO 在部分设定下的 Pass@1 可以匹敌甚至超越 LEAFE,但随着 k 增大,这些优势迅速见顶。相比之下,LEAFE 不仅提升 Pass@1,更在更高采样预算下持续产生更大提升。
具体来看各个基准:
WebShop:
● Qwen2.5-7B:GRPO 在 Pass@1 上更高(67.45% vs 66.50%),但 LEAFE 在 Pass@128 上反超(87.80% vs 85.40%)
● Llama3.1-8B:LEAFE 在两个指标上都最优(56.25% / 81.00%)
ALFWorld:
● LEAFE 在 Pass@128 上全面领先,Qwen2.5-7B 达 94.29%,Llama3.1-8B 达 96.43%
ScienceWorld:
● LEAFE 在 Pass@128 上全面最优,Qwen2.5-7B 达 62.00%,Llama3.1-8B 达 59.33%
● ACE 在 Pass@1 上表现最好,但 Pass@128 被 LEAFE 超越
Sokoban:
● LEAFE 优势最为明显,Qwen2.5-7B Pass@128 达 78.40%(GRPO 仅 68.00%),Llama3.1-8B Pass@128 达 77.20%(GRPO 仅 73.40%)
❓为什么 GRPO 在某些场景的 Pass@1 更高,但 Pass@128 不如 LEAFE?
这恰恰印证了 distribution sharpening 的理论。GRPO 把概率质量集中到少数已知的成功轨迹上,提升了单次采样命中的概率,但行为覆盖面并未拓展。LEAFE 则通过经验蒸馏注入了更多样化的纠偏行为,在大量采样时能覆盖更广的解空间。
CodeContests 结果
在更大规模的模型上,对比更为鲜明:
● Qwen2.5-72B:GRPO Pass@1 领先(20.45% vs 17.12%),但 LEAFE Pass@128 大幅超越(47.88% vs 36.97%,提升近 11 个百分点)
● Llama3-70B:类似模式,LEAFE Pass@128 达 33.94%(GRPO 仅 27.88%)
📌CodeContests 上的 Pass@128 提升最高达 +14%(相对于 base model),充分说明在需要迭代纠错的领域,内化 feedback-grounded agency 的价值尤为显著。
这里值得注意的是,EarlyExp 和 ACE 在 CodeContests 上未报告结果,因为它们是为交互环境设计的,不能直接应用于代码执行反馈场景。
4.2 Capability Scaling: Pass@k Analysis(能力缩放分析)
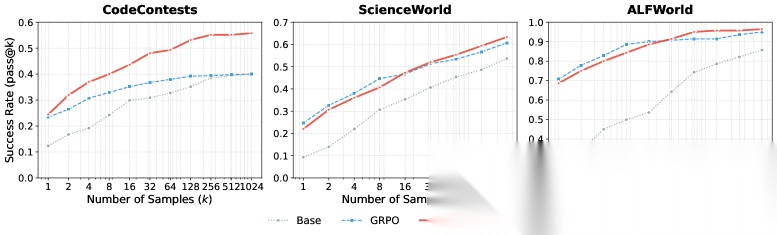
Figure 3: Scaling results on different benchmarks. We plot the Pass@kk success rate as a function of the number of samples kk. Our method (red) consistently achieves higher efficiency and performance ceilings across all tasks compared to the baselines.
Figure 3 绘制了 Pass@k 随采样预算 增加时的缩放曲线,分别在 CodeContests(k 上限 1024)、ScienceWorld(k 上限 512)、ALFWorld(k 上限 256)上展示。
两个核心发现:
📌更高的能力天花板(Higher upper bound)
在所有三个基准上,LEAFE 在大 k 区间一致地达到最佳表现,表明模型的能力天花板得到了真正提升。在 CodeContests 上优势尤为突出,即使在最大采样预算下差距仍然显著。
📌更高的采样效率(Better sample efficiency)
LEAFE 能用更少的采样达到相同的准确率阈值,并在中等预算之后以相同的 k 保持更高的成功率。换句话说,它在某个点之后主导了整个 scaling curve。
这说明 LEAFE 不仅提高了可达到的性能天花板,还提升了将额外采样转化为更高成功率的效率。
本章小结
实验全面验证了 LEAFE 的有效性。主结果显示,LEAFE 在五个基准上 Pass@128 全面领先,尤其在 CodeContests 上提升高达 14%。Pass@k 缩放分析确认 LEAFE 同时提升了能力天花板和采样效率。有效性分析证明了 Stage 1 的树搜索策略优于独立采样和线性精化,Stage 2 中 是内化纠偏能力的关键。消融实验进一步显示:LEAFE 随模型规模稳健缩放、在 OOD 场景下比 GRPO 更具鲁棒性,且与辅助方法组合时不会牺牲探索容量。局限性主要在于对环境反馈质量和可回溯性的依赖。
- Conclusion
📌LEAFE 将环境反馈转化为可执行的监督信号,把能力负担从 test-time 采样转移到内化的、经验驱动的 agency 上。
具体来说,LEAFE 的两阶段设计解决了 RLVR 在长程交互场景下的两个根本局限:
Stage 1(Tree-Based Experience Generation with Rollback) 解决了探索不足的问题:
● 通过周期性反思识别次优决策点
● 将环境反馈总结为可执行的经验摘要
● 通过环境回溯和经验引导的分支探索,生成 failure → rollback → fix → success 形式的结构化轨迹
● 使用 BFS 队列管理多分支探索,保证探索的广度和多样性
Stage 2(Experience Distillation) 解决了能力内化的问题:
● 通过反事实蒸馏(),将经验引导下的纠偏动作映射回无经验上下文,让模型在推理时无需显式反思即可做出更好决策
● 通过行为彩排(),保持模型的基线能力,避免灾难性遗忘
实验在五个长程交互基准上全面验证了 LEAFE 的有效性:Pass@128 最高提升 14%,Pass@k 曲线持续攀升而非饱和,OOD 泛化优于 GRPO,且随模型规模稳健缩放。
💡从更宏观的视角看,LEAFE 代表了一种从「outcome-driven training」到「process-driven learning」的范式转变。它不是在问「哪条轨迹成功了」,而是在问「轨迹在哪里出了问题、为什么出了问题、以及如何修复」。这种更精细的学习信号,正是让 Agent 从「会做题」进化到「会纠错」的关键。
附录:算法与实现细节
Algorithm 1 给出了 LEAFE Stage 1(Tree-Based Experience Generation with Rollback)的完整流程:
javascript
Algorithm 1: LEAFE Stage 1 — Tree-Based Experience Generation with RollbackInput: Task q, Environment E, Policy π_θ, Reflection prompt p_refl, Max depth D, Max attempts per depth A, Rollback interval KOutput: Trajectory set T = {τ_1, τ_2, ...}1: Initialize BFS queue Q ← {(E_0, h_0, depth=0)}2: Initialize trajectory set T ← ∅3: while Q is not empty do4: (E_start, h_start, d) ← Q.dequeue()5: if d > D then continue6: for attempt = 1 to A do7: E_t ← E_start, h_t ← h_start8: for t = 1 to T_max do9: a_t ~ π_θ(· | h_t, q) // 生成动作10: E_{t+1}, o_{t+1} ← Step(E_t, a_t) // 环境执行11: h_t ← h_t ⊕ (a_t, o_{t+1}) // 更新历史12: if t mod K == 0 or episode_done then13: (τ, e) ~ π_θ(· | h_t, p_refl) // 反思:生成回溯点和经验14: E_τ ← Restore(E_0, a_{1:τ-1}) // 恢复环境状态15: h_τ ← truncate(h_t, τ) // 截断历史16: Q.enqueue((E_τ, h_τ ⊕ e, d+1)) // 加入 BFS 队列17: end if18: if episode_done then break19: end for20: T ← T ∪ {current trajectory}21: end for22: end while23: return T
❓算法的核心逻辑:外层是一个 BFS 循环(第 3-22 行),从队列中取出起始状态,进行最多 次尝试。每次尝试中(第 8-19 行),Agent 正常执行动作,每隔 步或 episode 结束时触发反思(第 12-17 行)。反思生成回溯目标 和经验 ,环境恢复到 ,新的 (状态, 历史+经验, 深度+1) 三元组入队。这样就构建了一棵隐式的探索树,每个节点是一个反思-回溯事件。
● ● ●
写在最后
这篇 LEAFE 论文给出了一个干净且有说服力的技术叙事:当前 RLVR 范式在长程 Agent 训练中的根本瓶颈不是算法不够好,而是监督信号太粗糙 —— 终端标量奖励只能告诉你「成功了还是失败了」,却不告诉你「在哪里出了问题」和「应该怎么修」。
LEAFE 的解法思路很自然:既然环境本身就提供了丰富的结构化反馈,那就让模型去反思这些反馈,找到出错的关键节点,回溯到那个点,在经验指导下探索新的分支,然后通过蒸馏把这种纠偏能力固化到权重里。整个流程 —— reflection → rollback → branching → distillation —— 逻辑链条清晰,每个模块都有明确的技术动机。
从实验结果看,LEAFE 的核心亮点不在于 Pass@1 的提升(这一点 GRPO 有时反而更好),而在于 Pass@k 的持续攀升。这直接回应了论文的核心论点:RLVR 做的是 distribution sharpening,LEAFE 做的是 capability expansion。前者让模型更擅长复现已知的成功模式,后者让模型真正拥有了更丰富的行为覆盖面。OOD 泛化实验更进一步印证了这一点 —— GRPO 学到的是数据集特定的捷径,LEAFE 学到的是更基础的纠错能力。
当然,论文也有其局限。对环境可回溯性的假设在真实部署场景中不一定成立(比如 API 调用通常不可逆);对反馈质量的依赖意味着在反馈模糊或误导性的环境中效果可能打折。此外,Stage 1 的树搜索需要额外的环境交互预算,这在某些高成本环境(如真实的 Web 交互)中可能是一个限制因素。
但总体而言,这篇论文提出了一个值得关注的研究方向:与其只让模型学「怎么做对」,不如同时让它学「出错了怎么修」。这种从「结果导向」到「过程导向」的转变,可能是 Agent 训练从「刷榜」走向「真正可靠」的关键一步。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献190条内容
已为社区贡献190条内容

所有评论(0)