Claude Code扒累了,Qwen的Skill生成同样不可错过
在AI代理(Agent)日益复杂的今天,为它们配备特定领域的技能至关重要。但手动编写技能耗时费力,而自动生成的技能往往碎片化、不通用。最近,来自阿里Qwen团队、ETH苏黎世、北大等机构的研究者提出了一种名为 Trace2Skill 的新框架,它通过并行分析大量执行轨迹,并归纳推理出通用模式,从而生成可迁移、高质量的技能。
这项工作挑战了“经验必然与模型或任务绑定”的传统观念,证明经验可以被蒸馏成与模型无关的声明式技能,甚至能让小模型(如35B参数)生成的技能提升大模型(如122B参数)的性能。
传统技能生成的瓶颈
当前LLM代理的技能生成主要面临两个挑战:
- 手动编写 scalability 差:随着应用场景复杂化,人工编写和维护技能成为瓶颈。
- 自动生成质量低:基于参数知识生成的技能缺乏领域细节;而在线顺序更新(如根据新轨迹不断修改技能)容易过拟合,导致技能碎片化。
研究者观察到,人类专家编写技能时,会先广泛分析领域经验,再提炼成单一、全面的指南。而现有方法要么是“见一个改一个”(顺序更新),要么生成一堆小技能(碎片化),都与人类专家的做法相悖。
Trace2Skill框架
Trace2Skill的核心思想是模拟人类专家的技能编写过程:先并行分析大量执行轨迹,再归纳出通用规则,最终生成一个统一、无冲突的技能文档。
1. 三个阶段流程
Trace2Skill的流程分为三个阶段:
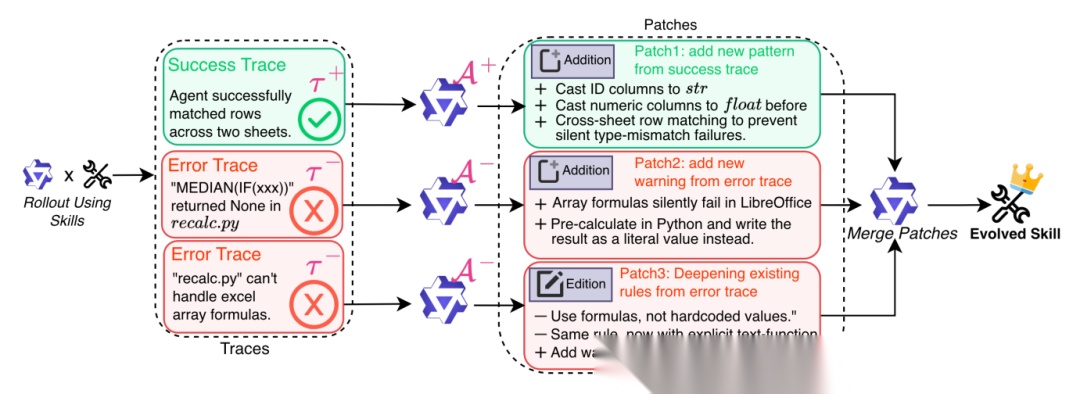
- 阶段1:轨迹生成使用初始技能(S0)让代理在并行任务上执行,收集成功(T+)和失败(T-)的轨迹。这一步完全可并行化,效率很高。
- 阶段2:并行多代理补丁提议分配一组“分析师”子代理,每个独立分析一条轨迹,提出技能修改补丁(Patch)。
- 成功分析师(A+):单次调用,从成功轨迹中提取通用行为模式。
- 错误分析师(A-):采用多轮交互式诊断(ReAct循环),深入排查失败根因,确保补丁基于验证过的原因。 所有分析师并行工作,互不干扰,保留多样性。
- 阶段3:无冲突整合将所有补丁通过分层合并(类似二叉树合并)整合成一个统一的技能更新。合并过程会:
- 去重、解决冲突(如同文件同范围的编辑)。
- 归纳推理:只保留高频出现的模式,认为其更可能通用;低频补丁则移至参考资料。 最终生成新技能(S*),可直接使用,无需检索模块。
2. 两种工作模式
- 技能深化:基于现有高质量人工技能(如Anthropic官方xlsx技能),用轨迹经验进一步优化。
- 技能创建:从零开始,基于参数知识生成的粗糙技能,通过轨迹经验蒸馏出实用技能。
小模型生成的技能,大模型也能用!
研究者在多个领域验证了Trace2Skill的效果:
1. 电子表格任务(SpreadsheetBench)
- 技能深化:用122B模型生成的技能,让35B模型的性能提升27个百分点(验证集)。
- 技能创建:用35B模型从零生成的技能,让122B模型在WikiTableQuestions(OOD任务)上提升57.65个百分点!
- 对比基线:Trace2Skill显著优于人工技能(跨模型时可能失效)和纯参数知识技能。
2. 数学推理(DAPO-Math & AIME)
- 技能在数学领域同样有效,且能跨模型迁移(35B生成的技能提升122B模型性能)。
3. 视觉问答(DocVQA)
- 122B模型生成的技能,对35B模型也有显著提升,说明技能编写能力与任务执行能力可分离。
4. 与传统方法对比
- 并行 vs. 顺序更新:并行整合效率更高(3分钟 vs. 60分钟),且避免顺序过拟合。
- 蒸馏技能 vs. 检索记忆库:Trace2Skill生成的单一技能文档,比基于检索的经验银行(ReasoningBank)更通用,尤其在跨任务时。
- 交互式错误分析 vs. 单次LLM调用:A-代理的多轮诊断能更准确定位根因,生成的技能迁移性更强。
为什么有效?
Trace2Skill成功的核心在于归纳推理:
- 从大量轨迹中提取高频模式(如“公式重算后必须验证”),编码为通用规则。
- 低频或特定案例的补丁被移至参考资料,保持主技能简洁。
- 分层合并机制自动形成“主文档+参考资料”的层次结构,模仿人类专家的知识组织方式。
总结与展望
Trace2Skill证明了:
- 经验可以蒸馏:即使基于小模型的轨迹,也能生成可跨模型、跨任务迁移的技能。
- 并行分析优于顺序更新:更高效,避免过拟合。
- 声明式技能优于检索记忆:无需外部模块,直接集成到代理中。
未来工作可包括:量化每个补丁的因果效应,进一步优化合并策略。
一句话总结:Trace2Skill让AI代理像人类专家一样,从大量经验中“举一反三”,提炼出通用技能,且小模型也能教大模型!
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献207条内容
已为社区贡献207条内容

所有评论(0)