Agent Skills:完整工作流(构建→测试→基准测试→迭代优化)
依据 Anthropic 与 OpenAI 2026 年最新官方指南整理
**一个技能本质就是一个文件夹。**文件夹内包含 SKILL.md 文件(YAML 前置元数据 + Markdown 指令),以及可选的 scripts/、``references/ 和 assets/ 目录。你只需教会一次工作流,智能体就能永久复用。
但构建技能只是开始。如果不做测试,你永远无法确定自己的修改是否真的提升了效果——还是仅仅改变了行为,直到悄悄出现退化(不触发、跳过步骤、生成冗余垃圾文件)。
而现在,这套流程迎来了非常实用的「2026 升级」:Claude 技能创建器可以帮你编写评估用例、做基准测试、A/B 对比、优化触发逻辑——无需自定义测试框架。
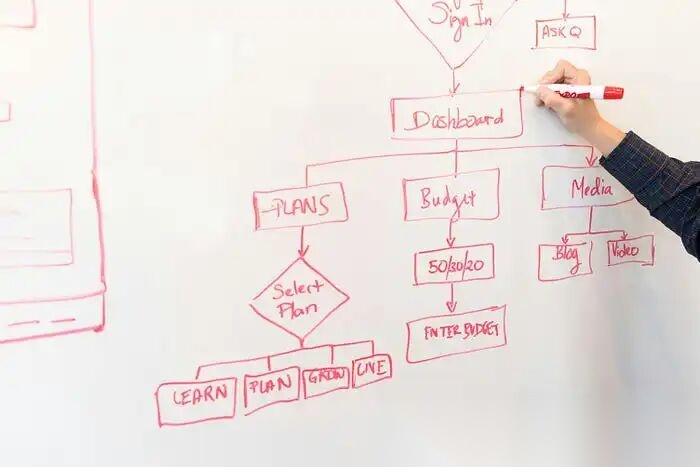
图 1:智能体技能本质上是引导特定工作流的指令
第 0 部分 —— 到底什么是智能体技能?
Anthropic 对技能的定义:一个打包好的指令文件夹,用于教会模型可重复执行的工作流,避免你每次都重复说明偏好与流程。
一个好记的心智模型:
-
工具 / MCP
= 厨房(能力底座)
-
技能
= 菜谱(工作流知识)
技能通常分为两类:
-
能力增强型技能:
帮助模型完成原本做不到或做不稳定的事情,编码了比单纯提示词更优的技巧或模式。
-
偏好编码型技能:
模型本身能完成各个子任务,但技能将它们按特定流程串联,适配你的业务流程与规范。
这两类技能**可能需要不同的测试方式,**不用担心,本文后续会详细说明!
第 1 部分 —— 构建一个技能(Anthropic 风格,可跨平台迁移)
(1) 文件夹结构
一个技能就是一个文件夹,包含:
-
SKILL.md(必需)
-
scripts/(可选;可执行代码,如 Python 或 Bash)
-
references/(可选;按需加载的文档)
-
assets/(可选;模板、图标、字体等资源)
(2) 「优雅架构」:三层渐进式披露
简单说:信息应该**分层展示,**而不是一次性全部塞给模型。
想象 Claude 或任何大模型都有有限的认知带宽。每次加载技能都会占用一部分**思考空间。**如果每个技能都把所有细节一次性塞进来,模型的「大脑」会迅速过载,效果反而下降。
为解决这个问题,技能采用三层结构设计,核心围绕 SKILL.md 文件(可理解为技能说明书)。
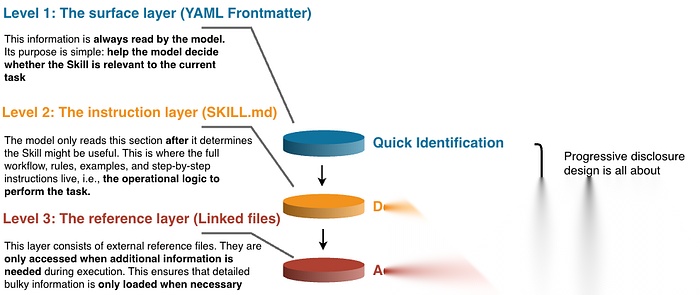
图 2:技能的三层渐进式披露架构
(3) 编写 SKILL.md 之前,先明确问题
最常见的失败:开发者做了很多功能,但描述模糊。结果 Claude 完全不知道什么时候该用它。
正确做法是先问自己几个简单问题:
**第一个问题:用户想要达成什么目标?**例如:「我想快速规划一次 Sprint」或「我需要从设计图生成前端代码」。目标要足够具体,10 句话内能讲清楚。
**第二个问题:包含哪些步骤?**是单步动作还是多步工作流?如果是多步,步骤之间有什么依赖?例如:必须先获取项目状态,才能创建 Sprint 任务——顺序很重要。
**第三个问题:需要用到哪些工具?**Claude 内置能力(如写 Markdown、执行代码)是否足够?还是需要调用 MCP 连接 Linear、Notion 等服务?
把这些写下来,你就得到了一份**用例定义。**简单格式示例如下:
(4) YAML 前置元数据:这不是「文档」

YAML 元数据是 Claude 判断是否加载该技能的依据。实际使用中,name(名称) 和 description(描述) 是技能触发与上下文注入的核心信号。
最小必需格式
---
name:
your-skill-name
description:
技能功能。当用户说【特定关键词】时使用。
---
必须遵守的规则(否则可能不触发)
- 文件名必须严格为
SKILL.md(区分大小写) - 文件夹名使用 **kebab-case,**并与技能名一致
- 描述必须包含 功能 + 触发时机
- 描述长度控制在 1024 字符以内
- 元数据中禁止使用尖括号
<或>(安全限制)
推荐描述结构:【功能】+【使用场景】+【核心能力】。
需要注意:名称和描述只是技能的最小要求。通常在元数据之后,还会用 Markdown 编写具体可执行的指令,说明必要步骤、预期结果、异常处理、资源引用等。
(5) 保持 SKILL.md 精简
如果技能响应变慢或输出质量下降,常见原因是「技能内容过大」或「启用技能过多」。官方建议:
-
SKILL.md字数控制在约 5000 词以内
-
核心指令留在
SKILL.md,细节移到references/ -
如果同时启用超过 20–50 个技能,考虑按需开关
第 1.5 部分 —— 快车道:Claude 技能创建器
Anthropic 2026 年 3 月更新的核心思路:
让技能编写也具备严谨的测试能力,且不需要用户写代码。
一张图看懂技能创建器
图 3:Claude 技能创建器模式与插件概览
第 2 部分 —— 系统化评估技能(OpenAI 风格,可通用)
评估存在的意义:我们不想靠「感觉」判断好坏。OpenAI 的定义最简洁清晰:
评估 = 提示词 → 捕获执行过程(轨迹 + 产物)→ 少量检查项 → 可长期对比的评分
他们强调一个核心点:技能迭代很难衡量,退化很容易悄悄发生(技能不触发、跳步、产生多余文件)。
步骤 1:修改技能前,先定义什么叫「成功」
把评估标准分成四类:
-
结果目标
(任务完成了吗?)
-
流程目标
(技能触发了吗?步骤遵守了吗?)
-
风格目标
(符合规范吗?)
-
效率目标
(无重复执行 / 无浪费)
步骤 2:先手动跑一遍,找出隐藏假设
手动触发技能,观察它在哪里出错。重点关注:
-
触发假设:
本该触发的场景没触发?不该触发却触发了?
-
环境假设:
技能是否假设运行在空目录?是否假设已安装
npm? -
执行假设:
是否因为默认依赖已安装而跳过
npm install?
每一次手动修复,都可以成为未来评估用例——只有锁定预期行为,才能规模化评估。
步骤 3:用少量提示集就能发现回归问题
不需要大型基准集。10–20 条提示就足够,用 CSV 管理即可。
从四个角度测试:
-
显式调用(
test-01):直接点名技能,验证基础功能
-
隐式调用(
test-02):只描述场景,不提技能名,测试描述是否足够清晰
-
上下文调用(
test-03):加入业务上下文,测试在干扰信息下是否仍正确触发
-
负向控制(
test-04):明确不该触发的场景,避免误触发
遇到新失败案例就持续新增条目。这份 CSV 会成为技能必须通过的活文档。注意:在 Claude 技能创建器中不需要这份 CSV,它使用 evals/evals.json 作为标准测试存储文件!
步骤 4:先做确定性检查,再做评分表评估
OpenAI 推荐的递进顺序:
-
确定性检查:
预期命令/事件 + 预期产物(快速、可解释)
-
评分表评估:
对质量需求做结构化打分
OpenAI 的方案是用 codex exec --json 生成 JSONL 事件流,每次命令执行变成 item.* 事件,可直接用代码检查。一旦检查失败,打开 JSONL 就能看到完整流程,不用猜。
这些检查保持轻量,在加入基于模型的评分前,先提供快速、可解释的基础保障。
确定性检查回答:「它做对基础事情了吗?」但不回答:「它按你想要的方式做了吗?」
OpenAI 提出的方案是增加一步模型辅助评估:
- 运行技能(生成代码)
- 用另一个智能体做只读式评审
- 要求返回**结构化 JSON,**让评估框架能稳定打分
可参考 OpenAI 展示的评分表示例!
第 3 部分 —— Anthropic 与 OpenAI 的核心共识
对比两家方法论,可以清晰看到多处共识:
-
格式趋同:
都使用带 YAML 元数据的
SKILL.md,都强调name和description,都支持脚本与参考资料的渐进式加载。这不是巧合,而是实践中收敛出的结构。 -
触发至关重要:
两家都花大量篇幅讲「技能何时该触发、何时不该触发」。描述质量直接决定技能实用性。
-
评估不能靠感觉:
Anthropic 承认实践中存在「一定程度的主观判断」,但建议追踪量化指标。OpenAI 更进一步——把评估变成正式流程,用确定性检查和评分表打分,让「感觉更好」变成「可证明更好」。
-
实用建议一致:
先在单个困难任务上反复迭代直到可用,再提炼成技能。每一次手动修复都可以变成未来评估用例。
SKILL.md控制在 5000 词内。同时启用技能数量限制在 20–50 个左右。
第 4 部分 —— 以技能创建器为入口的全新端到端示例
这里用一个实例展示如何借助技能创建器完成全流程。
场景:给定一份实验 CSV 文件,创建一个名为 ab-test-triage 的技能,以统一格式输出可直接用于决策的报告(SRM + 数据检查 + 提升幅度/置信区间 + 建议)。
这属于典型的**偏好编码型技能:**模型本身能做统计和写作,但技能把流程按团队标准串联起来。
步骤 1:创建技能文件夹(创建模式)
通过 /skill-creator 调用技能创建器,它会引导你收集需求并创建测试用例。我使用的提示如下:
技能创建器的创建流程用于收集需求并生成初始结构。

结束后你会得到:
ab-test-triage/
SKILL.md
←
v0
草稿
scripts/
←
可选;初始可能为空
references/
←
可选
assets/
←
可选
evals/
←
下一步可添加(或由技能创建器生成)
步骤 2:添加评估脚手架(评估用例 + 测试数据)
接下来添加(或让技能创建器添加)仅用于开发的测试目录:
ab-test-triage/
evals/.
←
仅本地使用
evals.json
files/
exp_valid.csv
exp_srm.csv
exp_mismatch.csv
应将测试用例保存在 evals/evals.json 中。evals/files/ 只存放运行测试所需的最小测试数据(小 CSV、短文档等),在 evals.json 中用相对路径引用。
步骤 3:编写评估用例(你的「评估提示集」放在这里)
evals/evals.json 是存储以下内容的标准位置:
- 提示词
- 文件(测试数据)
- 预期结果(确定性检查清单 + 评分规则)
精简示例(基于标准结构):
{
"evals"
:
[
{
"id"
:
"srm-should-stop"
,
"prompt"
:
"这是一份 A/B 实验汇总 CSV。判断结果是否可安全解读。生成 artifacts/summary.md 和 artifacts/verdict.json。"
,
"files"
:
[
"evals/files/exp_srm.csv"
]
,
"expectations"
:
[
"verdict.json 存在且为合法 JSON"
,
"verdict.json 包含顶层 key `decision`,取值为 {\"stop\",\"rerun\",\"ship\",\"needs-more-data\"}"
,
"summary.md 明确标记样本比例不匹配(SRM)并建议停止实验或检查埋点"
,
"summary.md 包含 SRM p 值(或明确说明无法从提供数据计算)"
]
}
]
}
在 evals/files 中,我手工创建了示例 exp_srm.csv,用于测试技能能否检测出 SRM 问题,并在 SRM 异常时不会盲目建议上线。 评估用的测试数据建议先手工构造,保证极小且确定性,当然也可以用脚本生成。
experiment_id,metric_name,variant,n,mean,std
exp_srm_001,conversion_rate,control,700,0.120,0.324
exp_srm_001,conversion_rate,treatment,300,0.135,0.342
步骤 4:运行评估模式
通过 /skill-creator → Eval 切换到评估模式,使用类似提示: 「对我的 ab-test-triage 技能运行评估。」
底层逻辑:技能创建器使用执行器 + 评分器运行提示并按预期校验。
它会生成:
ab-test-triage-workspace/
←
仅本地使用
iteration-1/
srm-should-stop/
with_skill/
outputs/
summary.md
verdict.json
grading.json
timing.json
<技能名>-workspace/iteration-N/评估ID/... 是技能创建器标准的运行结果存储结构。
规范定义的运行产物包括:
-
grading.json(评分器输出)
-
metrics.json(执行器输出)
-
timing.json(耗时记录)
注意:测试定义放在 ab-test-triage/evals/evals.json,但测试结果放在 ab-test-triage-workspace/...。
步骤 5:切换到优化模式(迭代循环)
现在开始优化!
-
/skill-creator→ Improve
-
「根据迭代 1 中的评估失败优化我的技能」或「优化此技能;添加计算 SRM 的脚本并生成 validation.json;更新 SKILL.md 调用它」
这就是「紧凑循环」:检查失败 → 修复 SKILL.md / 脚本 → 重新运行 → 对比结果。 技能创建器明确支持迭代优化与对比智能体的盲测。
优化模式会修改什么?
- SKILL.md 更明确(「必须输出 verdict.json 结构」「发现 SRM 立即停止」等)
- 如果技能在确定性计算上持续出错,可添加小型脚本
- 可优化评分规则或更清晰的预期描述
步骤 6:基准模式(当你关心稳定性,而不只是「单次通过」)
当评估基本通过后,运行:
-
/skill-creator→ Benchmark
-
「在 10 次运行中做基准测试并展示波动」
基准模式定位为:修改技能或模型更新后可运行的标准化评估,追踪通过率、耗时、Token 消耗(本次更新特别强调波动与统计置信度)。
步骤 7:打包发布(以及为什么你的评估用例「消失」了)
将技能打包成 .skill 文件时,evals/ 会被排除。
这是设计意图:
- 发布的技能保持精简干净
- 测试套件留在本地 / 仓库 / CI 中
你发布的 SKILL.md 应该是至少经过一轮「评估→优化」循环后的结果,因为这个过程会帮你发现哪些步骤描述不足、输出在哪里漂移、评分器能稳定验证什么。
下面是技能创建器各模式的速查表,方便指导开发流程。
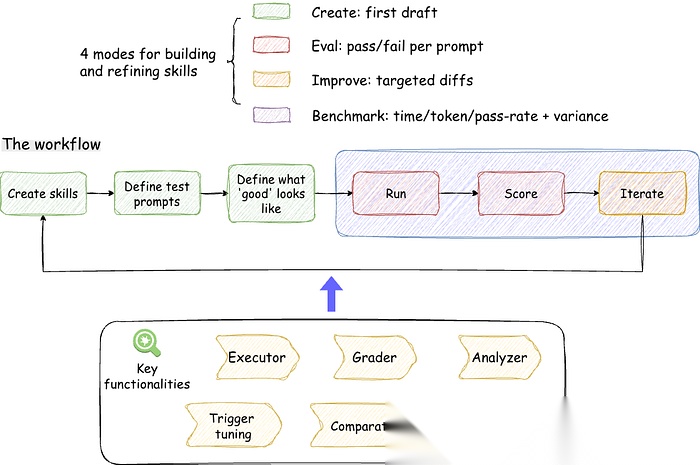
图4:技能创建器模式速查表
第 5 部分 —— 糟糕的技能长什么样
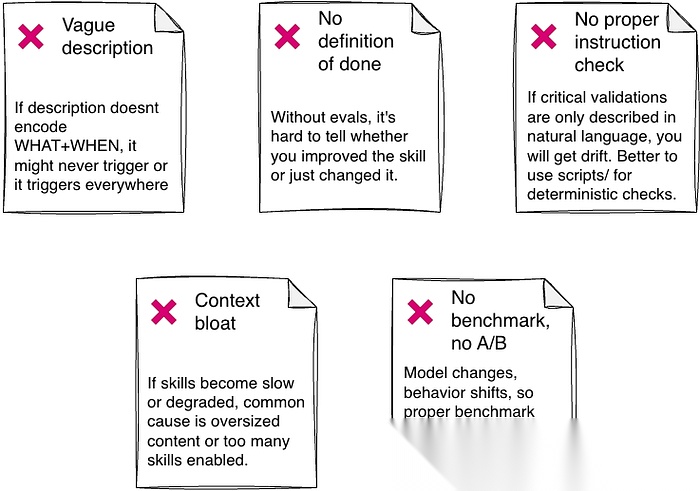
图 5:创建技能时要避免的错误
第 6 部分 —— 优秀的技能长什么样
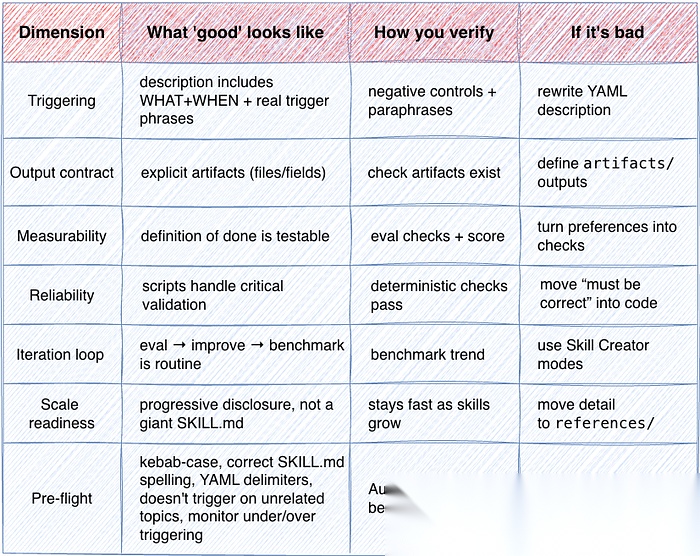
图 6:定义与衡量优质技能的指标
结语 —— 真正可规模化的工作流
如果你想要一套「完整可落地的工作流」,就是这个循环:
- 编写技能初稿(文件夹 +
SKILL.md) - 定义成功标准(结果 / 流程 / 风格 / 效率)
- 编写小型评估集(包含负向用例)
- 在干净环境中运行评估(可并行)
- 根据失败结果优化
- 基准测试(通过率 / 耗时 / Token)
- A/B 对比(v1 vs v2、有技能 vs 无技能)
- 优化触发逻辑(降低误触/漏触)
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献201条内容
已为社区贡献201条内容

所有评论(0)