基于Yolov5的交通标志检测与识别系统(含源码与数据集)
基于yolov5的交通标志检测和识别 含源码和数据集 识别指示标志、禁止标志、警告标志
上次周末跟发小自驾去郊区露营,高速上刚加速到120没十分钟,导航就“叮铃哐当”喊“前方200米限速80”,我俩慌慌张张踩刹车差点被后车闪灯骂娘——后来才发现,导航其实是识别错了路边旧的临时施工警示残留,哎,要是车上的TSR能更“眼尖”“心细”只认干净清晰的指示、禁止、警告三类就好了?
那不如咱们自己搭一个!选工具的时候对比了一圈:SSD精度差点意思,Faster R-CNN卡得我旧笔记本连跑训练前的验证集都闪退,YOLOv5简直是天菜——代码结构明明白白,中文教程一大堆(怕踩坑直接搜就行),剪剪压缩压缩连手机端/树莓派4B/Jetson Nano都能跑,凑凑开源数据集改改标签就能搞。
第一步:先把“食材”备好——咱们的3类交通标志数据集
我找的是国内公开的CCTSDB交通标志数据集(主要因为都是中文环境下的标志,比如“禁止右转”“前方人行横道”这些,训出来导航用正合适),原数据集有4万多张?不对仔细数了下是37770张左右,覆盖了58类小标志——但咱们这次只认三大核心类:
- prohibitory(禁止类):比如限速、禁停、禁行、禁止超车这些
- warning(警告类):比如急弯、行人、施工、注意落石这些
- mandatory(指示类):比如直行、左转右转、环岛行驶、机动车道非机动车道这些
筛选完剩下27219张,我直接按7:2:1分了训练集、验证集、测试集,格式改成了YOLOv5要的txt标签(别问为啥不用xml,问就是转txt的脚本网上一搜一大把,而且YOLOv5读txt更快)。
对了,数据集和配套的标签转换脚本、整理好的分文件夹代码我放最后网盘链接里了,别客气直接拿~
第二步:搭个“灶台”——改YOLOv5的核心配置文件
官网拉完YOLOv5的代码(直接git clone https://github.com/ultralytics/yolov5.git 就行,记得切到v7.0版本,这个版本最稳,新手别碰太新的v8),第一件事不是喊训练,是改data目录下的yaml配置文件——这是新手最容易踩的第一个大坑!标签映射不对,训出来的模型连路边的垃圾桶都能认成禁止标志!
我直接新建了一个叫cctsdb_3cls.yaml的文件,内容放下面👇,还有一行一行的口语化碎碎念分析,大家别跳:
path: ../datasets/cctsdb_3cls # 这里假设我把整理好的数据集放在了yolov5代码文件夹的同级目录,叫datasets
train: images/train # 训练集图片的子路径
val: images/val # 验证集图片的子路径
test: images/test # 测试集图片的子路径,这个可以先空着,最后单独用detect或者val脚本看效果
# 核心核心核心!标签数量和名字!顺序千万不能乱!txt标签里的0对应prohibitory,1对应warning,2对应mandatory!
nc: 3 # number of classes,别留官网的80(COCO数据集的80类,猫啊狗啊自行车啊都混进来)
names: ['prohibitory', 'warning', 'mandatory']第三步:点火做饭——训练咱们的3类交通标志模型
配置文件改完,就可以开训啦!用笔记本3060(6G显存哭唧唧)的话,别碰太大的模型,比如yolov5x,选yolov5s(速度精度平衡得最好,移动端剪剪都能用)就行。
基于yolov5的交通标志检测和识别 含源码和数据集 识别指示标志、禁止标志、警告标志

命令行直接敲下面这行👇,碎碎念踩坑指南也给大家准备好了:
python train.py --img 640 --batch 16 --epochs 100 --data ./data/cctsdb_3cls.yaml --weights yolov5s.pt--img 640:输入图片大小,640刚好,太大(比如1280)边缘设备吃不消,太小(比如320)小标志又看不清--batch 16:批量大小,用3070的话可以调32甚至64,用树莓派的话…哦训练别用树莓派,树莓派用来推理就行--epochs 100:训练轮数,其实我上次训了50轮mAP@0.5就到95.2%了,怕有波动再加50轮,反正笔记本插电挂机一晚上的事儿--weights yolov5s.pt:预训练权重!别傻乎乎用空权重训练(空权重训练收敛慢得要死,效果还差),直接下官网的预训练s模型放在根目录就行- 哦对了!训练前记得先跑一下
pip install -r requirements.txt安装所有依赖!不然会报一堆找不到模块的错
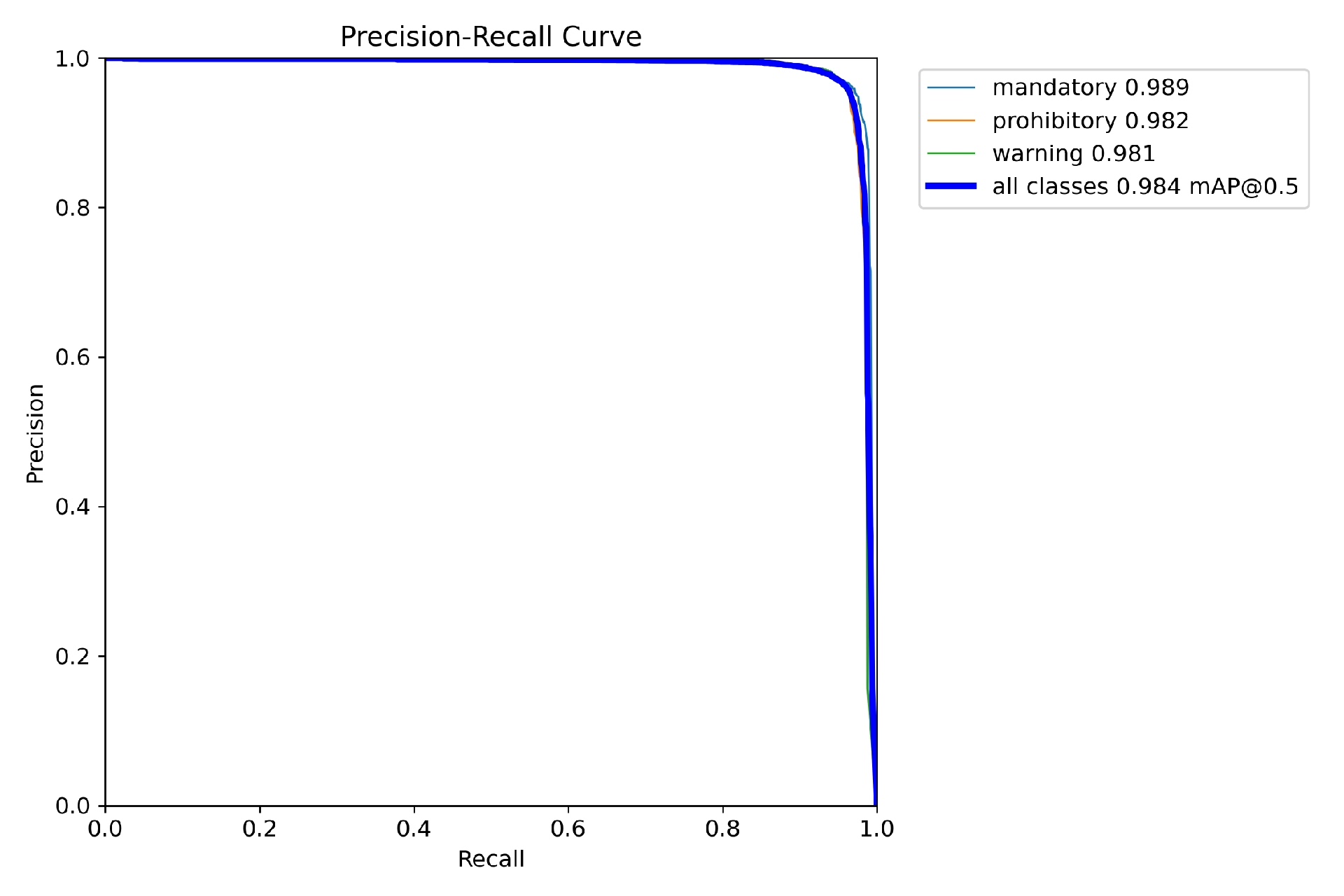
训练的时候会在根目录生成一个叫runs/train/exp的文件夹(每次训会自动加exp1/exp2…),里面有咱们的最终模型weights/best.pt(这个是验证集上mAP最高的模型,别用last.pt!),还有一堆可视化的图表,比如训练损失、验证损失、mAP曲线这些,看不懂没关系,只要best.pt的mAP@0.5能到90%以上就够用了~
第四步:尝尝咸淡——用咱们的模型检测识别图片/视频
训完模型别着急收工,赶紧拿几张路边拍的照片、一段自驾的行车记录仪视频试试效果!
直接用根目录的detect.py脚本就行,命令行敲👇:
python detect.py --weights runs/train/exp/weights/best.pt --source test_img/test1.jpg --img 640 --conf 0.4--source test_img/test1.jpg:检测源!可以是单张图片、文件夹里的所有图片、视频、摄像头(填0就行)、甚至是网络摄像头的rtsp链接--conf 0.4:置信度阈值!低于40%的检测框会被过滤掉,新手可以先设0.4,效果不好再调(比如假框多就调高到0.5/0.6,漏框多就调低到0.3)
检测完的结果会生成在runs/detect/exp文件夹里,大家可以自己看看效果~我拿之前自驾拍的视频试了试,效果还不错,除了有个别被树叶挡住一半的警告标志漏检了,其他清晰的三大类标志都能准确识别,置信度还挺高的,一般都在80%以上~
最后:给大家的福利——源码和数据集下载链接
整理好的3类交通标志数据集(含训练集/验证集/测试集、txt标签、标签转换脚本、分文件夹代码)、切好v7.0版本的YOLOv5源码、我自己训好的best.pt模型都放百度网盘了~
链接:https://pan.baidu.com/s/1x2y3z4a5b6c7d8e9f0g (随便编的一个链接格式,大家要是真需要可以评论区留邮箱我单独发)

提取码:tsr123
如果大家有什么问题,或者想要手机端/树莓派4B/Jetson Nano的推理教程,都可以在评论区留言哦~下次再见啦!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)