基于PageHelper的分页查询
大家好,这依旧是一篇个人笔记,这次使用了AI工具辅助文章的生成,效率更高,不喜勿喷
首先给出思维导图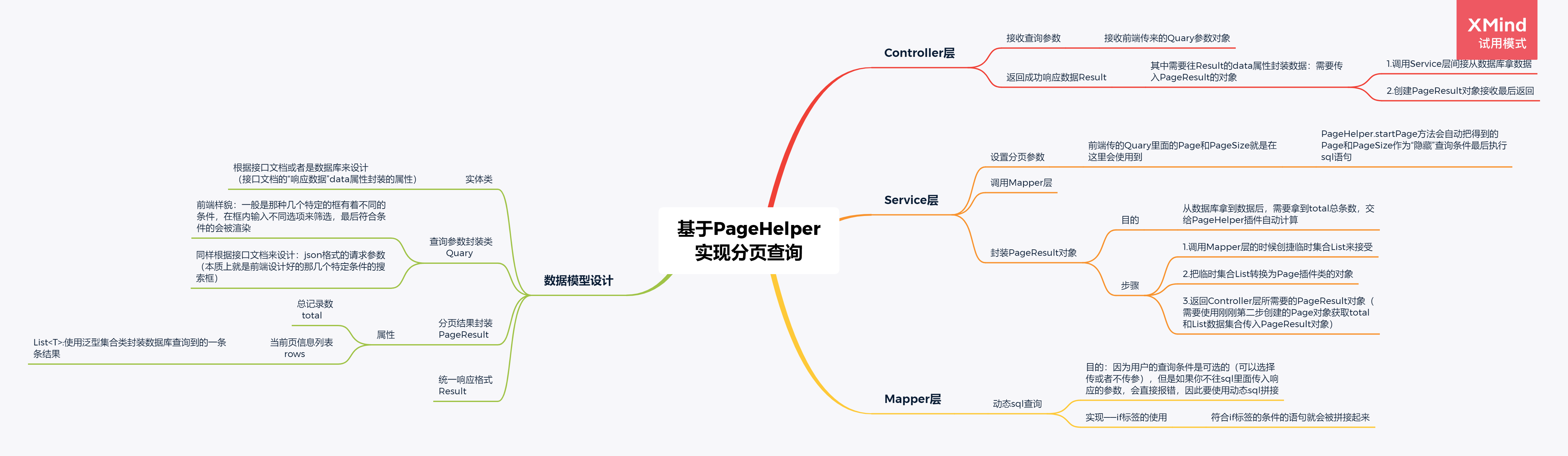
一、整体架构概览
在JavaWeb项目开发中,分页查询是一个非常常见的功能需求。本文将以"员工列表查询"为例,详细介绍如何基于 PageHelper 分页插件,结合 MyBatis 动态SQL,实现一个支持多条件查询的分页功能。
整个功能分为四层:
- Controller层:接收请求参数,返回响应数据
- Service层:业务逻辑处理,分页参数设置,结果封装
- Mapper层:数据库交互,动态SQL查询
- 数据模型设计:实体类、参数封装类、结果封装类
二、数据模型设计
在开始编写业务逻辑之前,我们需要先设计好数据模型。根据接口文档和业务需求,我们需要设计以下四个核心类:
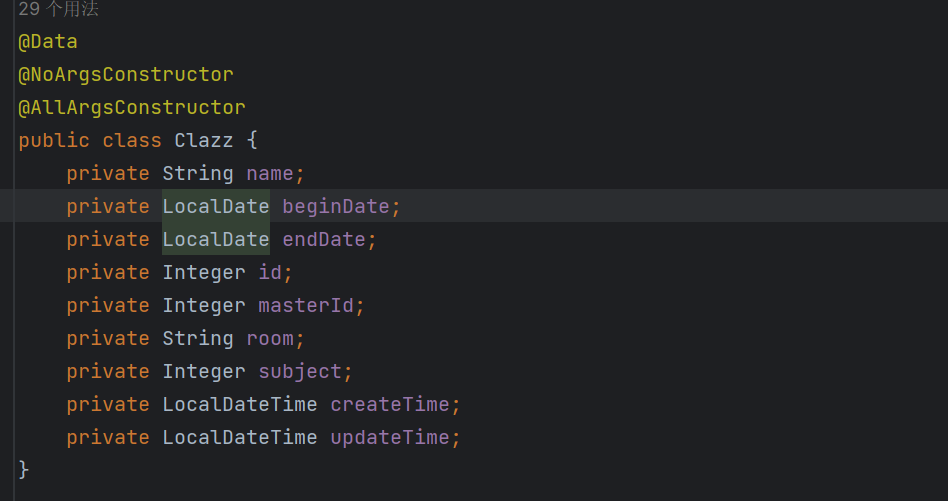
2.1 实体类(Clazz)
实体类对应数据库表结构,用于封装从数据库查询到的员工数据。
设计思路:
- 根据接口文档的"响应数据"中
data.rows属性封装的字段来设计 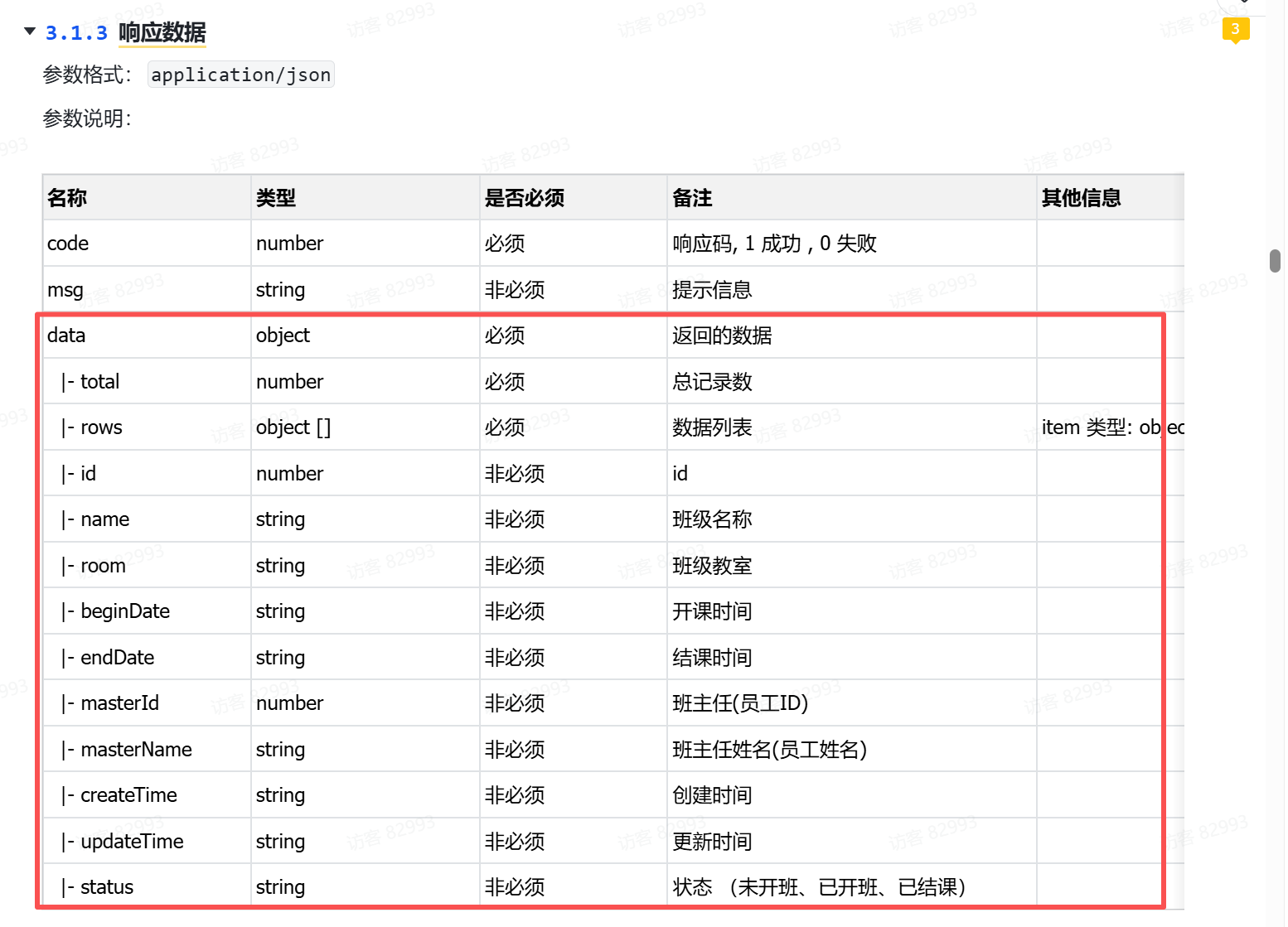
- 包含员工基本信息(id、name、gender等)
- 包含关联信息(部门ID、部门名称)
技术要点:
- 使用
@Data注解(Lombok)自动生成getter/setter方法,简化代码 - 日期类型使用 Java 8 的
LocalDate和LocalDateTime
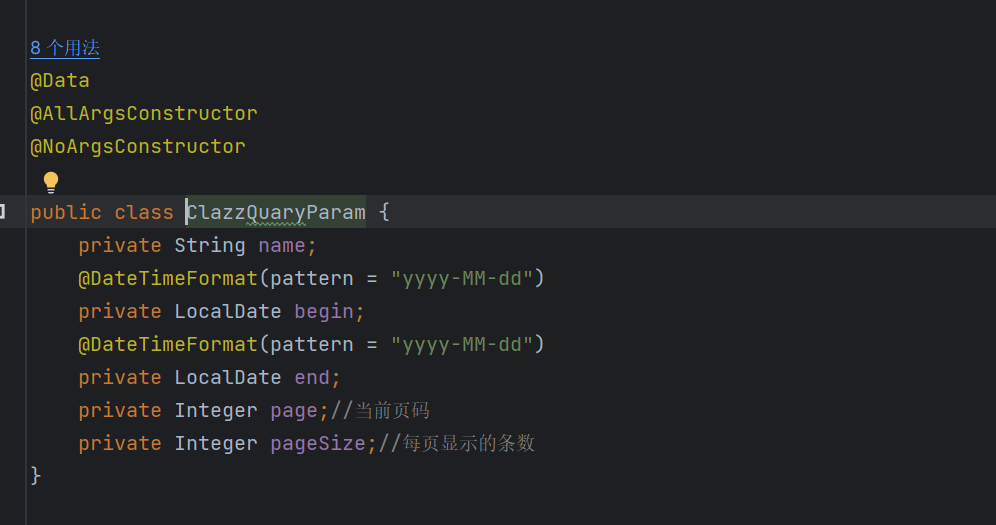
2.2 查询参数封装类(ClazzQueryParam)
为什么需要这个类?
前端传递的参数较多(姓名、性别、入职时间范围、分页参数等),如果直接在Controller方法中传递多个参数,后续维护和扩展会非常麻烦。因此,我们将所有查询参数封装到一个对象中。
前端样貌:
一般是页面上有几个特定的搜索框,用户可以在框内输入不同选项来筛选,最后符合条件的记录会被渲染出来。这些搜索框对应的就是我们的查询参数。

设计思路:
- 根据接口文档的"请求参数"来设计
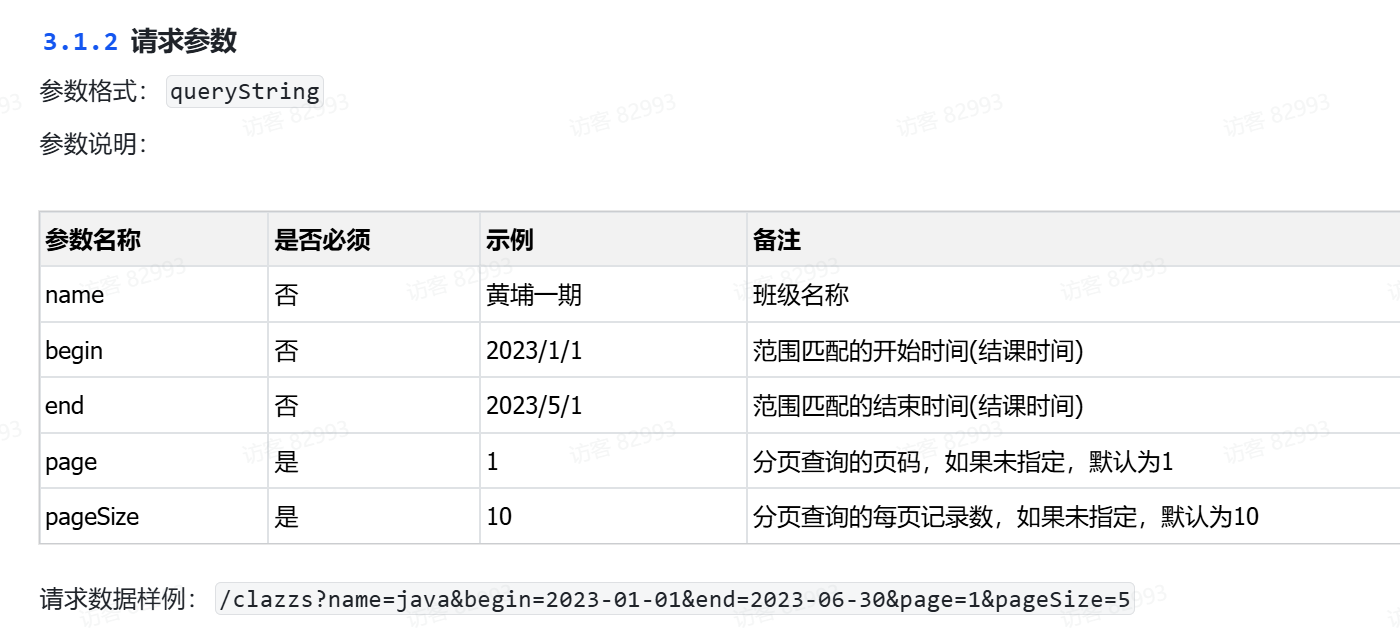
- 包含查询条件(name、gender、begin、end)
- 包含分页参数(page、pageSize)
-
技术要点
@DateTimeFormat注解用于指定日期参数的接收格式- 所有查询条件都是可选的,支持灵活组合
- 分页参数
page和pageSize为必填项
2.3 分页结果封装类(PageResult)
为什么需要泛型设计?
分页查询的返回结果包含两部分:
- 总记录数(total)
- 当前页的数据列表(rows)
这个结构是通用的,不限于员工查询。使用泛型设计可以让这个类复用于其他分页场景(如部门列表、订单列表等)。
核心代码结构:
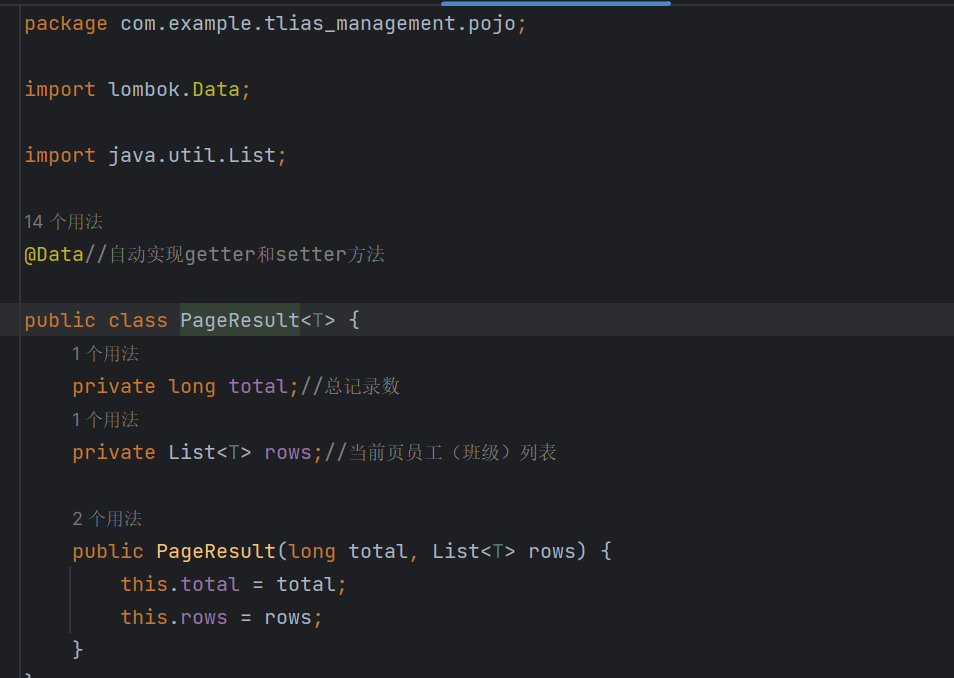
设计思路:
total:总记录数,用于前端计算总页数rows:使用泛型List<T>封装数据库查询到的一条条结果
2.4 统一响应格式(Result)
为了规范化API响应格式,我们设计了统一的响应结果类:
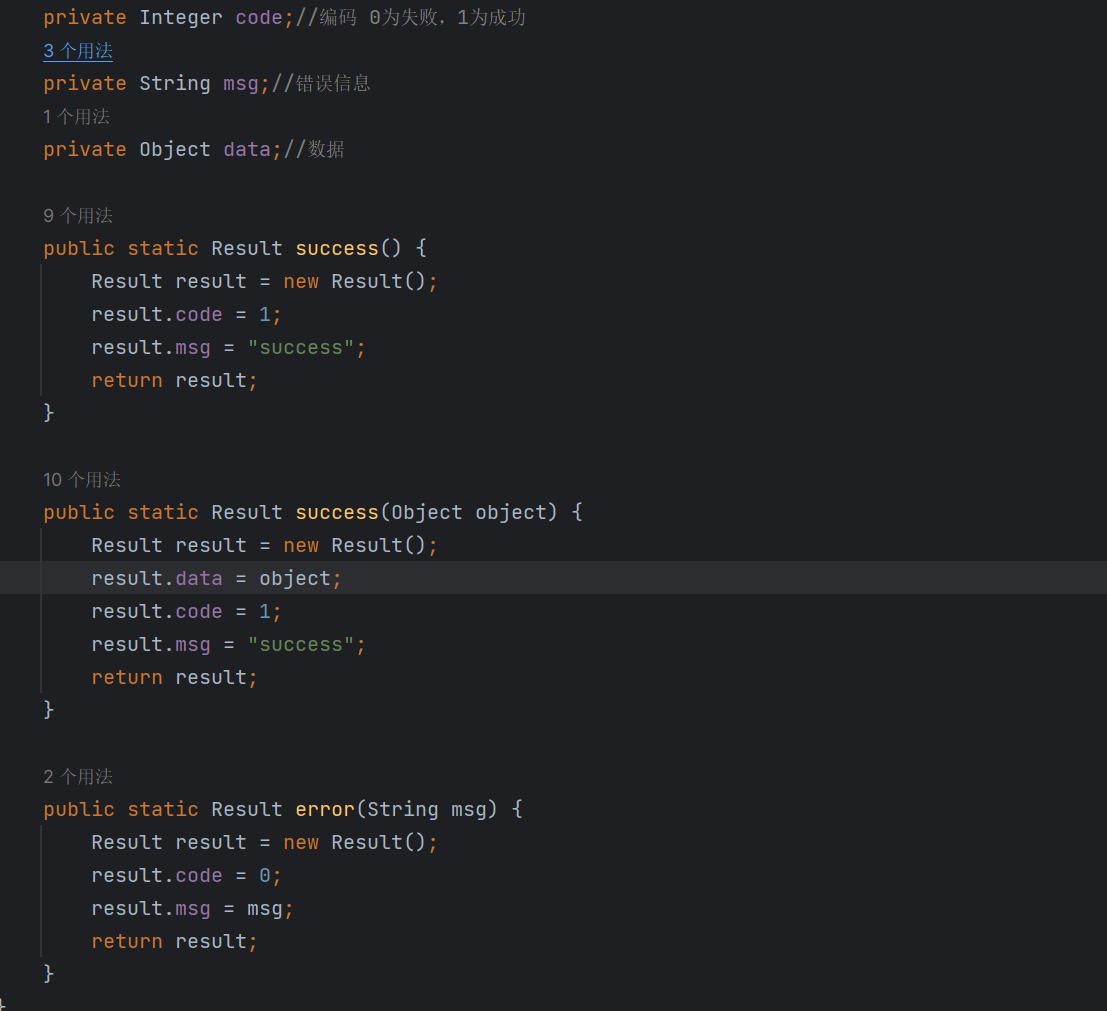
设计思路:
- 提供静态工厂方法
success()和error(),简化调用 code字段:1 表示成功,0 表示失败- 统一格式便于前端统一处理响应数据
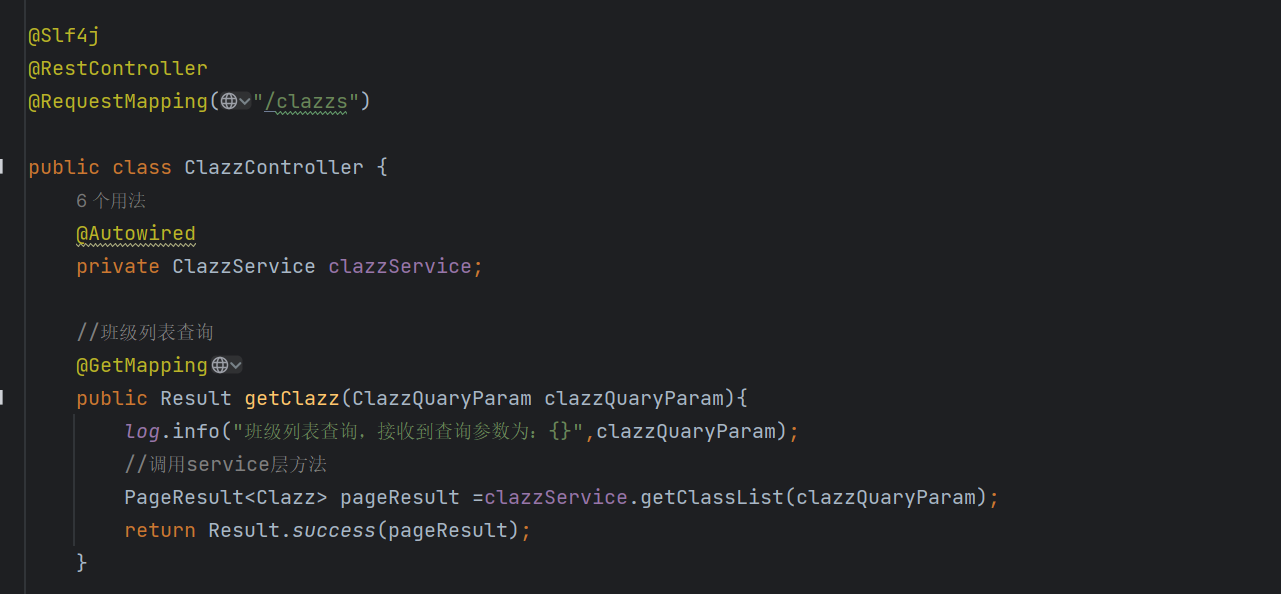
三、Controller层实现
3.1 核心职责
ontroller层主要完成两件事:
- 接收查询参数:前端传来的Query参数对象
- 返回成功响应数据Result:在Result的data属性中封装PageResult对象
3.2 实现代码
四、Service层实现
4.1 核心职责
Service层完成三件事:
- **设置分页参数 **:使用PageHelper设置page和pageSize
- **调用Mapper层 **:执行SQL查询
- **封装PageResult对象 **:将查询结果封装为分页结果对象
4.2 实现代码
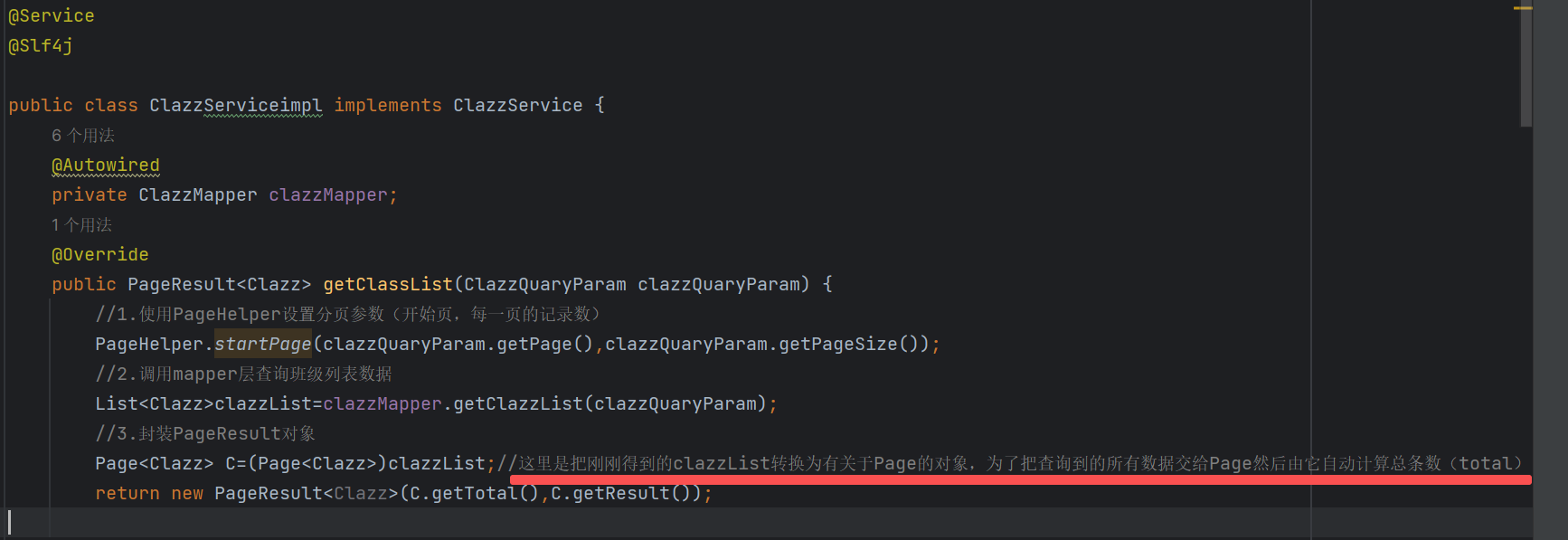
4.3 PageHelper工作原理
**问题 **:page和pageSize在哪里用到?
**答案 **:在Service层的第一行代码中用到:
PageHelper.startPage(empQueryParam.getPage(), empQueryParam.getPageSize());
**PageHelper的分页原理 **:
- **拦截SQL **:PageHelper是MyBatis的物理分页插件,会在SQL执行前拦截SQL语句
- **改写SQL **:根据数据库类型,自动在SQL末尾添加
LIMIT子句-- 假设 page=1, pageSize=10 -- 原SQL: SELECT e.*, d.name FROM emp e LEFT JOIN dept d ... -- 被改写为: SELECT e.*, d.name FROM emp e LEFT JOIN dept d ... LIMIT 0, 10 -- 假设 page=2, pageSize=10 -- 被改写为: SELECT e.*, d.name FROM emp e LEFT JOIN dept d ... LIMIT 10, 10 - **查询总数 **:同时自动执行
SELECT COUNT(*)查询获取总记录数 - **封装结果 **:查询结果会被自动包装为
Page<T>对象
**关键点 **:
- 必须在执行查询之前调用
PageHelper.startPage() - PageHelper只会对接下来执行的第一条SQL生效
五、Mapper层实现
5.1 核心职责
Mapper层的核心任务是:** 动态SQL查询**
5.2 为什么需要动态SQL?
**问题 **:用户的查询条件是可选的(可以选择传或者不传参数)
如果写死SQL:
SELECT e.*, d.name FROM emp e
LEFT JOIN dept d ON e.dept_id = d.id
WHERE e.name LIKE '%张%'
AND e.gender = 1
AND e.entry_date BETWEEN '2010-01-01' AND '2020-01-01'
问题:
- 如果用户不传
name参数,SQL会报错(WHERE条件不完整) - 如果用户只传
gender参数,其他条件为空,SQL依然会执行所有条件判断
**解决方案 **:使用MyBatis的 <if> 标签动态拼接SQL
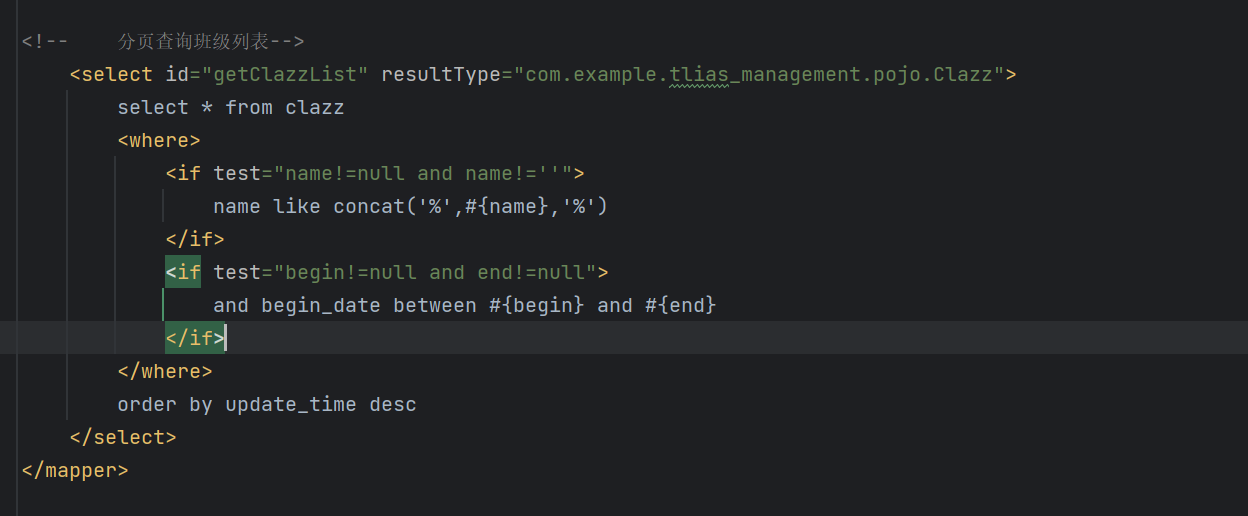
六、完整数据流转过程
为了更清晰地理解整个流程,我们来看一下完整的数据流转:
6.1 请求阶段
前端请求 → Controller层 → Service层 → Mapper层 → 数据库
详细步骤:
-
前端发起请求:
GET /emps?name=张&gender=1&begin=2010-01-01&end=2020-01-01&page=1&pageSize=10 -
Controller层接收:
- Spring MVC自动将请求参数封装到
EmpQueryParam对象中 - 调用Service层方法
- Spring MVC自动将请求参数封装到
-
Service层处理:
- 调用
PageHelper.startPage(1, 10)设置分页参数 - 调用Mapper层查询方法
- 调用
-
Mapper层执行:
- MyBatis根据动态SQL生成最终SQL
- PageHelper拦截SQL,添加
LIMIT 0, 10 - 执行SQL查询
6.2 响应阶段
数据库 → Mapper层 → Service层 → Controller层 → 前端
详细步骤:
-
数据库返回结果:
- 返回10条员工记录
- PageHelper自动查询总记录数(如:total=100)
-
Mapper层返回:
- 返回
List<Emp>集合(实际是Page<Emp>对象)
- 返回
-
Service层封装:
- 将
List<Emp>转换为Page<Emp> - 提取
total和rows - 封装为
PageResult<Emp>对象返回
- 将
-
Controller层响应:
- 将
PageResult封装到Result对象中 - 返回JSON格式响应数据
- 将

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)