从RNN到LSTM再到BiLSTM:一篇文章彻底讲清序列模型的演化逻辑
引言
NLP-AHU-030
我们每天都在和序列打交道:开口说的一句话、耳机里的一段旋律、股票的每日涨跌,甚至脑海里闪过的一串念头,都是按时间顺序排列、前后强关联的序列信息。但在循环神经网络诞生之前,传统的前馈神经网络始终没法真正理解这类数据 —— 它们默认所有输入彼此独立,就像一个只会孤立看单个汉字的孩子,没法把前后内容联系起来,更记不住几秒前看到的信息。
本文会从设计启发、结构设计、算法细节、数学表达四个核心维度,完整拆解 RNN、LSTM、BiLSTM 三个经典序列模型的演化逻辑,讲清每个模型「为什么这么设计、到底怎么工作、数学原理是什么」,同时分享我对序列建模的学习思考。
本文在写作过程中参考了多篇优质学术文献与技术博客,在此向所有原创者致以诚挚的感谢,完整参考文献见文末。
一、RNN—— 给神经网络装上第一份 “记忆”
1.1 设计启发
RNN 的诞生,本质上是对传统前馈神经网络底层缺陷的突破,也是对人类认知逻辑的朴素复刻。在 RNN 出现之前,传统前馈神经网络始终无法适配序列数据的特性,存在三个无法解决的致命痛点:
第一,输入长度必须固定,无法处理现实中长短不一的序列数据,比如不同字数的句子、不同时长的音频;
第二,无法捕捉时序依赖关系,默认所有输入数据彼此独立,完全违背了人类理解序列时 “用前文辅助理解当下内容” 的认知逻辑;
第三,参数爆炸问题,若用前馈网络处理长序列,需要为每个序列位置单独设置一套权重,参数量会随着序列长度指数级增长,完全不具备实用性。
1990 年 Jeffrey Elman 提出的简单循环网络(Elman RNN),正是为了打破这些限制,它的核心设计启发就是:给神经网络装上 “记忆”,让网络的每一步输出,同时取决于当前输入和之前积累的历史信息,再通过 “权重共享” 的设计解决参数爆炸的问题,让神经网络真正具备处理序列数据的能力。
1.2 结构设计
RNN 最核心的创新,就是循环结构与权重共享,很多初学者会被结构里的循环箭头搞晕,我们可以通过 “循环结构→时间维度展开” 的方式,直观理解它的完整结构。
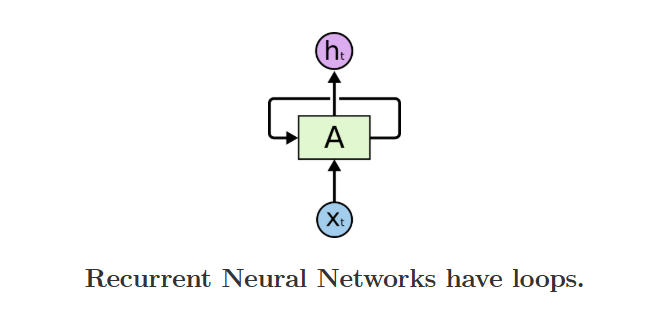
图注:RNN 的基础循环结构示意图,直观展示 “循环” 的核心设计
只要把这个循环结构沿着时间轴展开就会发现,它本质上是一个由完全相同的网络层串联起来的结构,序列有多长,这个串联的网络就有多少层。
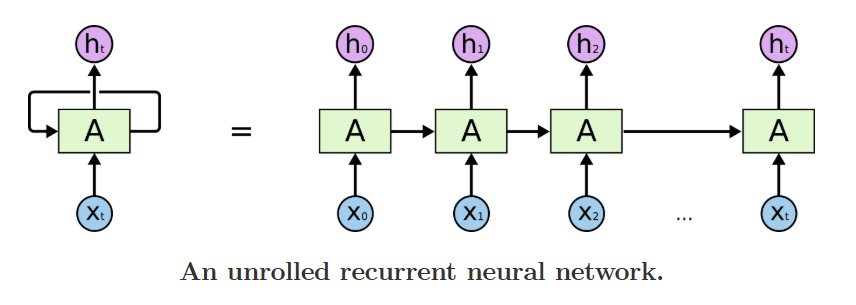
图注:RNN 循环结构(左)与时间维度展开图(右),清晰展示信息在时间步之间的传递逻辑
这个结构最关键的设计是:所有时间步的网络层,共享完全相同的一套权重参数。这就像我们学习语言时,不管长句短句,用的都是同一套语法规则,不会为每一种长度的句子单独学习一套逻辑。这个设计带来了两个颠覆性的优势:一是模型的参数量不会随着序列长度的增加而爆炸,二是模型具备了处理任意长度序列的能力。
而承载 “记忆” 的核心,就是 RNN 的隐藏状态,它贯穿整个串联的网络层,是信息在时间步之间传递的载体,我们可以通过 RNN 的内部重复模块,清晰看到它的基础结构。
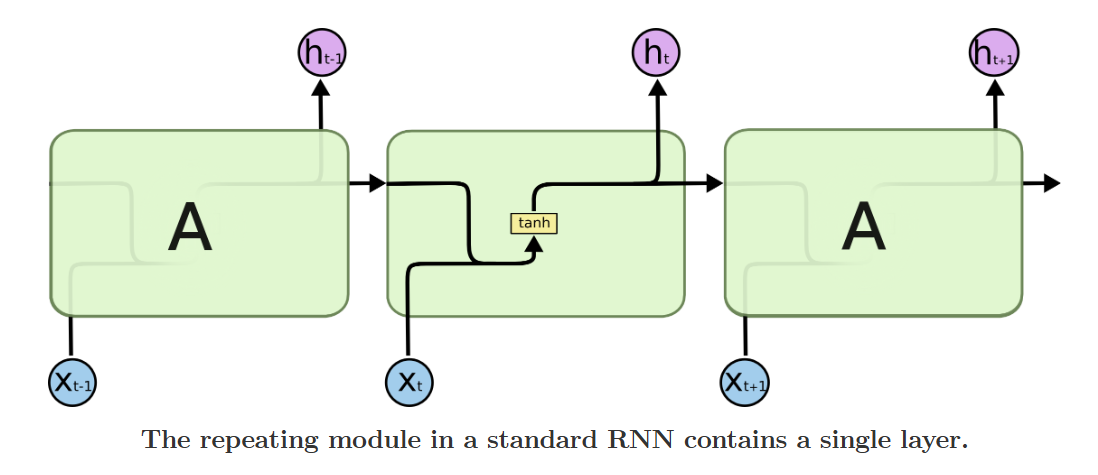
图注:标准 RNN 的重复模块结构,仅包含单个 tanh 神经网络层
标准 RNN 的重复模块里,只有一个简单的 tanh 神经网络层,所有的信息更新都在这个模块里完成,结构简单但也为后续的长距离依赖问题埋下了隐患。
1.3 算法细节
RNN 的算法流程分为前向传播和反向传播训练两个核心部分,我们可以完整拆解它的运行逻辑。
在前向传播阶段,RNN 会按时间步依次处理序列中的每个输入,核心是隐藏状态的更新:在每一个时间步,模型都会把当前的输入和上一步的隐藏状态结合,更新出当前的新隐藏状态。这个新的隐藏状态既包含了当前输入的新信息,也保留了之前的旧记忆,会继续传递到下一个时间步,就像我们读句子时,把刚读到的内容和之前的记忆结合,更新自己对这句话的理解。基于更新后的隐藏状态,模型会输出当前时间步的预测结果,比如词预测任务里的下一个词、分类任务里的类别概率。
在训练阶段,RNN 采用随时间反向传播(Backpropagation Through Time, BPTT)算法更新参数,核心逻辑是把展开后的 RNN 当成一个深度前馈网络,每一层对应一个时间步,然后用标准的反向传播算法,从序列的最后一个时间步,沿着时间轴反向计算每个参数的梯度,最终完成参数更新。
但正是这个训练逻辑,暴露了 RNN 的致命缺陷 —— 长距离依赖失效。在反向传播的过程中,梯度需要经过几十甚至上百个时间步的连乘,很容易出现指数级衰减(梯度消失)或者指数级放大(梯度爆炸)。
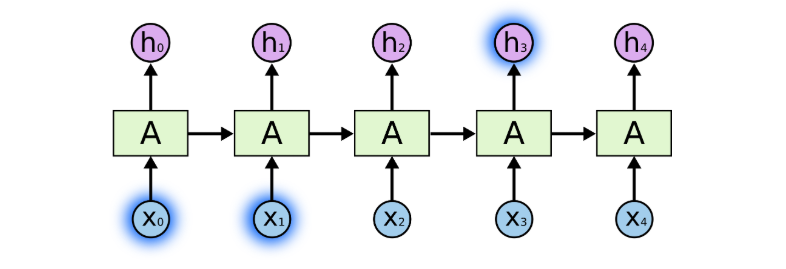
图注:RNN 序列展开后的信息传递示意图,序列前端的输入信息(蓝色高亮)在向后传递的过程中,影响力逐步衰减
梯度消失意味着,序列开头的关键信息,经过多步传递后,对后续时间步的影响几乎完全消失,模型根本没法捕捉长距离的依赖关系。
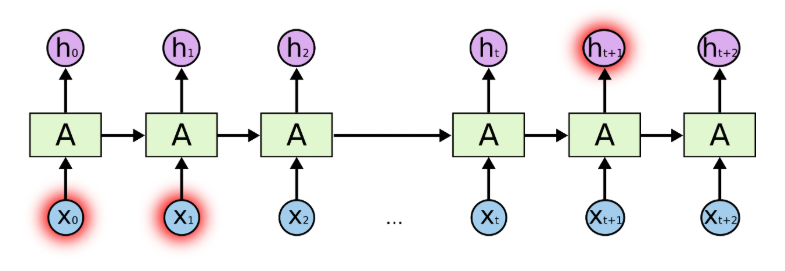
图注:RNN 长距离依赖问题的直观展示,序列最前端的关键输入(红色高亮),经过多步传递后,对后续时间步的影响几乎完全消失
比如面对 “我十年前在伦敦的二手书店淘到了一本绝版诗集,直到今天我依然珍藏着那本____”,RNN 根本没法把空格处的内容和前文的 “诗集” 联系起来。更本质的问题是,RNN 的记忆是 “无选择的”,它不会判断什么信息该记住、什么该遗忘,只会机械地叠加信息,最终重要的内容一定会被无关信息稀释。
1.4 数学表达
我们可以用严谨的数学公式,完整还原 RNN 的算法逻辑,以下针对序列中第 个时间步,拆解 RNN 前向传播与反向传播的核心数学原理。
隐藏状态更新公式(前向传播核心):
RNN 的核心是隐藏状态的迭代更新,也就是模型 “记忆” 的传递与刷新。在每一个时间步,模型都会把当前输入和上一步的隐藏状态结合,生成新的隐藏状态 —— 这个新状态既包含了当前输入的新信息,也保留了之前的历史记忆,并会继续传递到下一个时间步。对于序列中第 个时间步 的隐藏状态更新公式为:
公式中各符号的含义与作用如下:
:当前时间步的输入向量(如文本任务中,对应当前词的词向量);
:上一个时间步的隐藏状态,也就是模型积累的历史记忆;
:当前时间步更新后的隐藏状态,是模型当前的 “记忆快照”;
:输入到隐藏层的权重矩阵,负责把当前输入的信息编码到隐藏状态的维度中;
:隐藏状态之间的权重矩阵,负责控制上一步的历史记忆有多少能传递到当前时刻;
:隐藏层的偏置项;
:双曲正切激活函数,会把输出值压缩到 - 1 到 1 之间,避免数值在循环传递中不断放大,同时让隐藏状态的数值分布更稳定。
输出计算公式:
基于更新后的隐藏状态,我们可以得到当前时间步的模型输出。以文本分类、词预测这类分类任务为例,我们通过 激活函数将隐藏状态映射为对应类别的概率分布,输出公式为:
公式中:
:当前时间步的输出向量,对应分类任务中各个类别的预测概率;
:隐藏层到输出层的权重矩阵;
:输出层的偏置项;
: 激活函数,会将隐藏状态的输出映射为概率分布,保证所有类别的概率之和为 1,方便我们得到最终的预测结果。
梯度消失的数学原理:
RNN 无法处理长序列的核心缺陷,本质上是反向传播过程中的梯度消失问题,我们可以通过数学推导清晰解释其根源。
RNN 的训练采用随时间反向传播(BPTT)算法,梯度需要从序列的最终时刻 ,沿着时间轴反向传递到序列初始时刻。序列初始时刻的隐藏状态
,对最终时刻
的隐藏状态
的偏导,需要经过
次隐藏层权重矩阵的连乘。忽略激活函数的非线性影响,其近似表达式为:
从公式可以清晰看到:
如果权重矩阵 的最大特征值
,经过
次连乘后,梯度会指数级衰减到趋近于 0,即梯度消失——模型完全无法学习到序列开头的关键信息;
如果 ,梯度会指数级放大,即梯度爆炸,会直接导致训练过程崩溃。
这就是 RNN 无法处理长序列、无法捕捉长距离依赖的数学本质。
二、LSTM—— 从 “被动记忆” 到 “主动管理记忆”
2.1 设计启发
为了彻底解决 RNN 的梯度消失与长距离依赖问题,1997 年 Hochreiter 和 Schmidhuber 提出了长短期记忆网络(Long Short-Term Memory, LSTM),它的设计灵感来自两个核心逻辑:
第一是人类的记忆管理规律:我们不会把所有看到的信息都记下来,而是会选择性地遗忘无关内容、长期保留重要信息、在需要的时候精准提取记忆,而不是像 RNN 那样无差别地叠加所有信息;
第二是计算机的门控机制:用可学习的 “开关” 控制信息的流动,而不是让信息被动地在循环中被覆盖、衰减,通过独立的门控开关,分别实现 “遗忘、写入、提取” 三个记忆管理动作。
如果说 RNN 是一个只会把所有东西都塞进记忆里的孩子,LSTM 就是一个会整理记忆、分类收纳、按需取用的成年人,这也是它能解决长距离依赖问题的核心。
2.2 结构设计
我们先对比 RNN 和 LSTM 的核心结构差异,就能一眼看懂 LSTM 的重构思路:标准 RNN 的重复模块里,只有一个简单的 tanh 神经网络层,而 LSTM 对这个重复模块做了彻底的重构,核心是两个创新设计:
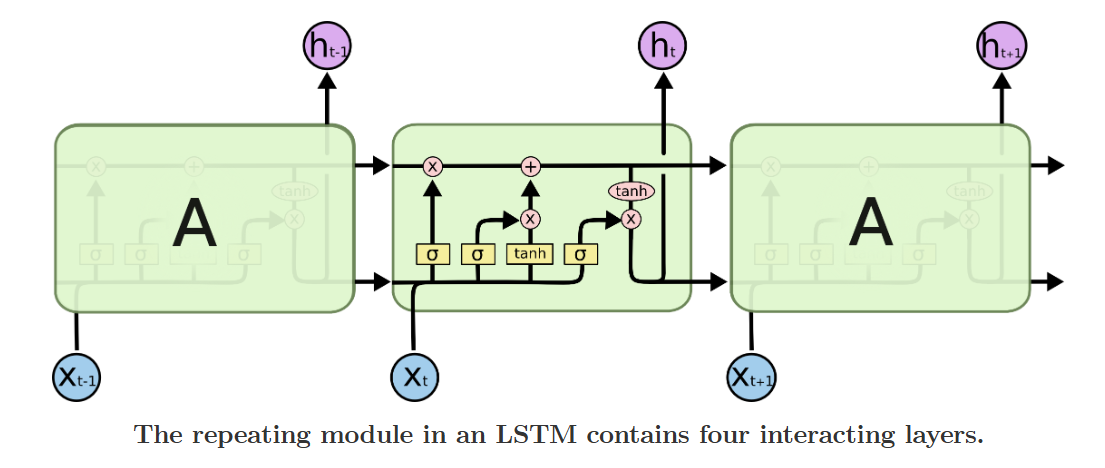
图注:LSTM 的重复模块结构,包含四个交互层,与 RNN 的简单结构形成鲜明对比
第一个核心设计是细胞状态(Cell State):这是一条贯穿所有时间步的 “信息高速公路”,信息在上面只会发生少量的线性交互,不会像 RNN 的隐藏状态那样每一步都经过非线性变换,从根本上解决了梯度消失的问题。
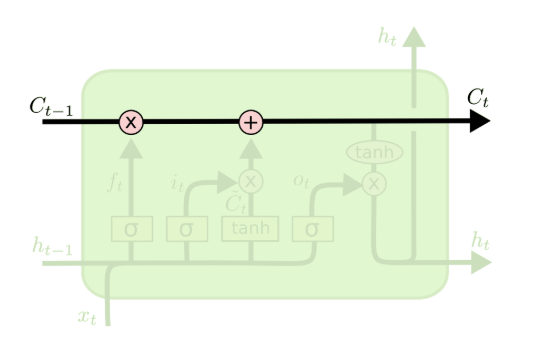
图注:LSTM核心结构全景图,贯穿模块的黑色箭头为细胞状态信息高速通道
为了控制细胞状态里的信息流动,LSTM 设计了三个可学习的 “门控开关”,分别是遗忘门、输入门和输出门。所谓的 “门”,本质上是一个控制信息通过比例的结构,它的基础组成如下:
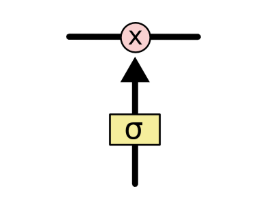
图注:LSTM中“门控单元”的基础结构,通过sigmoid层输出控制系数,实现对信息流动的管控
第二个核心设计是三门控机制:用遗忘门、输入门、输出门三个可学习的门控开关,精细化控制细胞状态里的信息流动,实现对记忆的主动管理。所谓的 “门”,本质上是一个控制信息通过比例的结构,它由一个 sigmoid 神经网络层和一个逐点乘法操作构成,sigmoid 层会输出 0 到 1 之间的数值:0 代表完全关闭,不让任何信息通过;1 代表完全打开,让所有信息通过。
在拆解细节之前,先明确 LSTM 结构中的算子符号含义:
图注:LSTM 结构中的算子图例,从左到右依次为:神经网络层、逐点操作、向量传递、向量拼接、向量复制
三个门控各司其职,共同完成对记忆的管理,整个结构的信息流动完全围绕 “细胞状态更新” 展开,逻辑清晰且稳定。
2.3 算法细节与数学表达
LSTM 的计算分为四个核心步骤,我们按计算顺序逐一拆解:
第一步:遗忘门 —— 筛选并丢弃无效旧信息
第一步是遗忘门计算,这是 LSTM 处理信息的第一步,它的作用是决定要从细胞状态里丢弃哪些旧信息。比如当我们在句子里遇到一个新的主语时,遗忘门就会把之前的旧主语信息从细胞状态里清除,避免无关信息干扰后续的理解。它会接收当前输入和上一个时间步的隐藏状态,输出一个 0-1 之间的控制向量,作用到细胞状态上,完成旧信息的筛选。
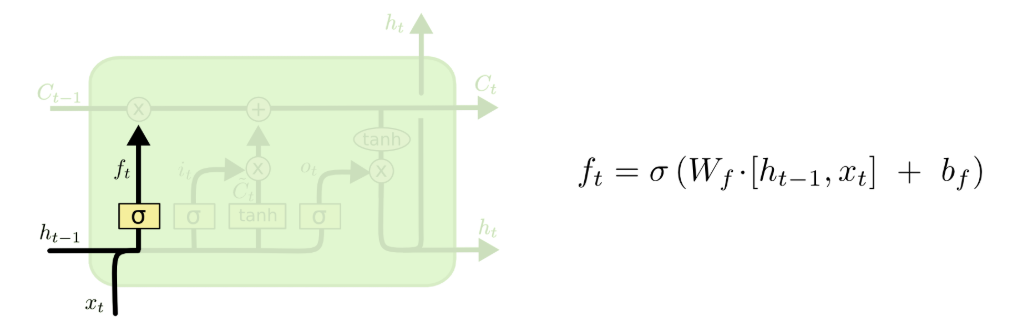
图注:LSTM遗忘门结构与计算公式,负责筛选并丢弃细胞状态中的无效旧信息
其中:
是
激活函数,会把输出值压缩到 0 到 1 之间:0 代表完全关闭,不让任何信息通过;1 代表完全打开,让所有信息通过;
是遗忘门的权重矩阵,
是遗忘门的偏置项;
代表把两个向量拼接在一起。
第二步:输入门 —— 筛选需要写入的新信息
第二步是输入门计算,它负责决定哪些新的信息要被存入细胞状态。这个过程分为两个部分:先用 sigmoid 层决定细胞状态里哪些位置的信息需要更新,再用 tanh 层生成候选的新记忆内容,最终只把需要更新的信息写入细胞状态,实现新信息的筛选。
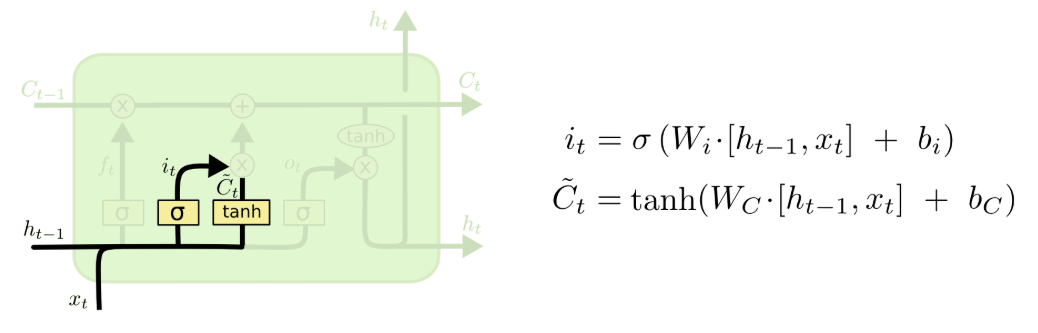
图注:LSTM输入门结构与计算公式,负责筛选需要写入细胞状态的新信息
其中:
是输入门的控制向量,决定了哪些新信息需要被写入;
是候选细胞状态,包含了所有可能被加入细胞状态的新内容。
第三步:细胞状态更新 ——LSTM 的核心灵魂
第三步是细胞状态更新,这是 LSTM 的核心灵魂,也是它解决梯度消失的关键。我们先把上一个时间步的细胞状态和遗忘门的输出相乘,丢掉需要遗忘的信息,再加上输入门控制的新信息,就得到了当前的细胞状态。整个更新过程是线性的加法操作,没有复杂的非线性变换,梯度在反向传播时,可以沿着这条细胞状态的通道,几乎无损地传递到序列最开头,彻底解决了长距离梯度消失的问题。
这一步是 LSTM 解决梯度消失的关键,也是它和 RNN 最核心的区别。我们先把上一个时间步的细胞状态和遗忘门的输出相乘,丢掉需要遗忘的信息,再加上输入门控制的新信息,就得到了当前的细胞状态
。
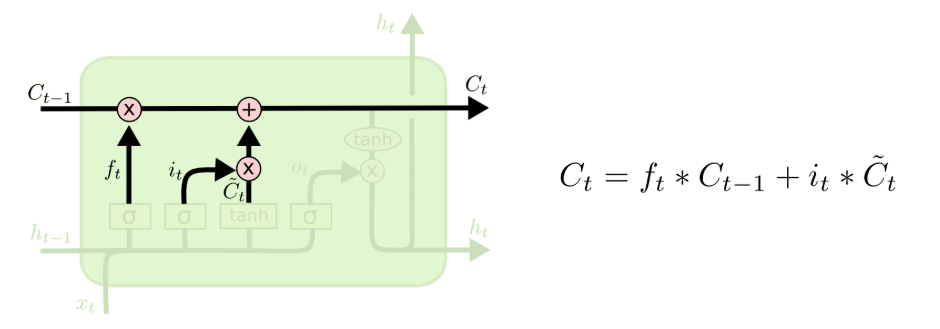
图注:LSTM细胞状态更新流程与计算公式,线性加法结构是解决梯度消失的核心
这里的 * 代表逐点乘法(Hadamard Product),整个更新过程是线性的加法操作,没有复杂的非线性变换,梯度在反向传播时,可以沿着这条细胞状态的通道,几乎无损地传递到序列最开头,彻底解决了长距离梯度消失的问题。
第四步:输出门 —— 决定对外输出的隐藏状态
第四步是输出门计算,它决定了当前时间步要对外输出什么样的隐藏状态。隐藏状态就像是细胞状态的 “短期快照”,是模型当下能调用的记忆内容,输出门会先通过 sigmoid 层决定细胞状态的哪些部分需要被输出,再把细胞状态通过 tanh 函数处理后,和输出门的控制向量相乘,得到最终的隐藏状态,传递到下一个时间步。
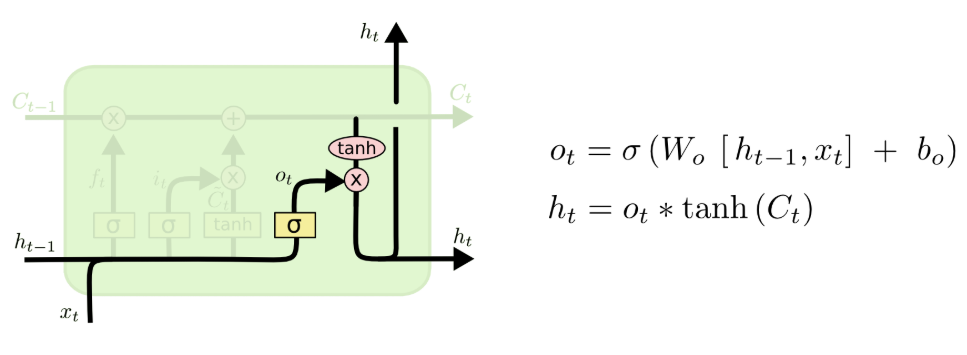
图注:LSTM输出门结构与计算公式,决定当前细胞状态对外输出的隐藏状态
输出门的控制向量 决定了细胞状态的哪些部分需要被输出,最终的隐藏状态
会作为当前时间步的输出,同时传递到下一个时间步。
2.4 经典变体:带窥视孔连接的 LSTM
除了基础版的 LSTM,研究者们也提出了很多优化变体,其中最经典的就是带窥视孔连接的 LSTM,它让门控单元可以直接接收细胞状态的输入,进一步提升了记忆管控的精度:
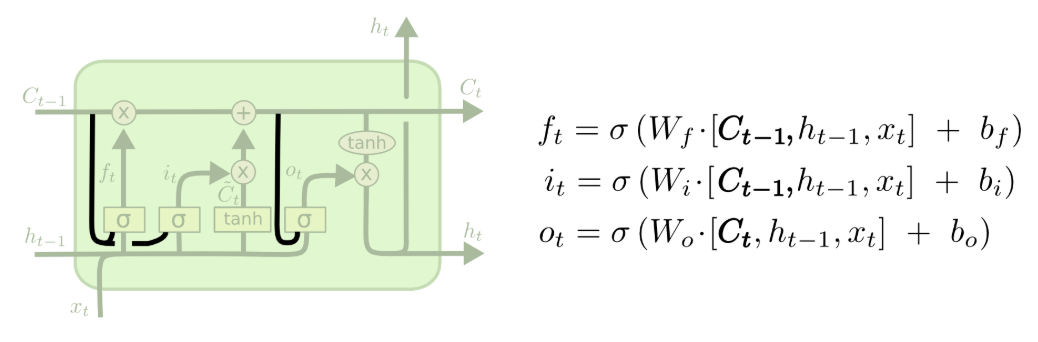
图注:带窥视孔连接(Peephole Connections)的LSTM变体,门控单元可直接接收细胞状态的输入
在此基础上,研究者进一步探索了 LSTM 的轻量化优化,其中最具代表性的就是将遗忘门与输入门合并的简化设计,这也是后续 GRU 的核心思想源头:
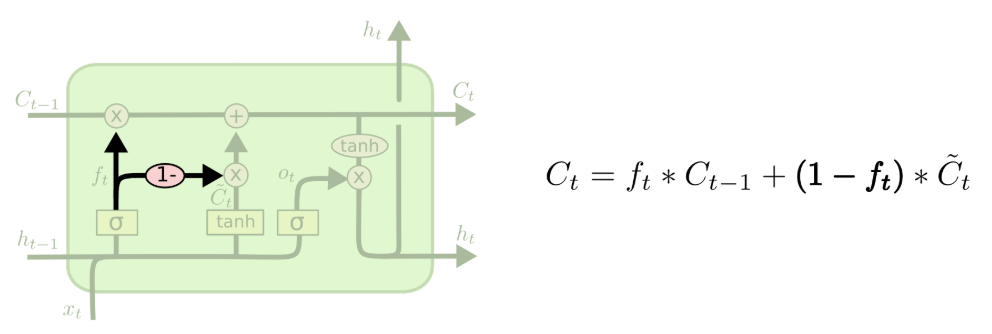
图注:GRU的前身——简化版LSTM结构与计算公式,将遗忘门与输入门合并为单一更新门的早期设计
LSTM 彻底改变了 RNN “被动记忆” 的模式,让模型学会了主动管理记忆。它不再是机械地叠加信息,而是可以自主决定 “什么该忘、什么该记、什么该用”,哪怕是上千步之前的关键信息,也能稳定地保存在细胞状态里,真正解决了长距离依赖的难题,也让语音识别、机器翻译等 NLP 任务取得了突破性的进展。
三、GRU:LSTM 的轻量化优化方案
在 LSTM 的基础上,Cho 等人于 2014 年提出了门控循环单元(GRU),它的核心目标是在保留 LSTM 长距离记忆能力的同时,大幅简化模型结构、减少参数量,提升训练与推理效率。GRU 彻底取消了 LSTM 的细胞状态,将遗忘门与输入门合并为一个更新门(Update Gate),同时新增了重置门(Reset Gate),用单一的隐藏状态完成记忆的传递与更新,结构更简洁、计算更高效。
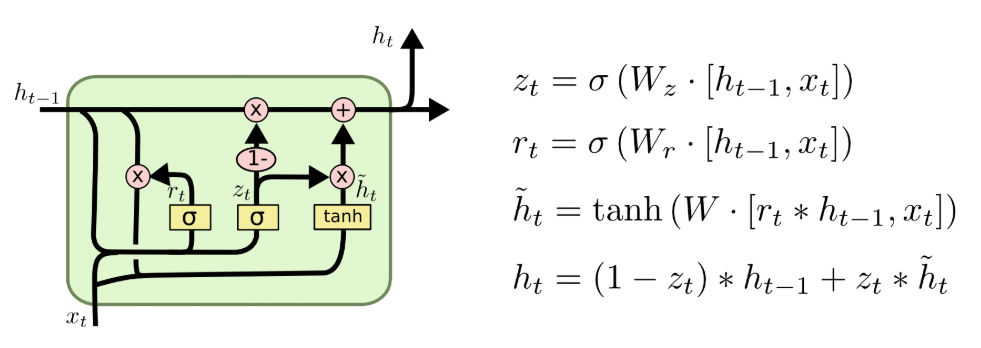
图注:GRU(门控循环单元)结构与计算公式,LSTM的轻量化优化变体
GRU 的完整计算流程分为四步:
1.更新门计算:决定保留多少历史记忆、融入多少新信息,公式为:
2.重置门计算:决定遗忘多少历史记忆,公式为:
3.候选隐藏状态计算:生成当前时间步的候选新记忆,公式为:
4.最终隐藏状态更新:融合历史记忆与新信息,得到当前时间步的输出,公式为:
GRU 的结构比 LSTM 更简单,参数量减少约 30%,训练速度更快,同时在绝大多数任务上的性能与 LSTM 相当,甚至在小样本场景下表现更优,因此成为了 LSTM 的主流轻量化替代方案,广泛应用于资源受限的嵌入式场景、实时时序预测等领域。
四、BiLSTM:让模型 “同时看见过去与未来”
4.1 设计启发
LSTM 虽然成功解决了长距离依赖问题,但它仍然是一个单向时序模型,只能按照从左到右的顺序处理序列,只能利用当前时间步之前的上文信息,无法获取后续的下文信息。然而在人类理解语言的过程中,上下文往往是双向的,很多语义、实体边界、角色关系都必须结合后文才能准确判断。例如句子 “他____地站在雨里,浑身都湿透了”,仅依靠前文很难推断空格内容,但后文 “浑身都湿透了” 可以直接给出答案;在命名实体识别这类任务中,实体的类型同样需要前后文共同确定,单向 LSTM 显然无法满足这种需求。
为了弥补这一缺陷,双向长短期记忆网络(BiLSTM)应运而生,它的设计灵感直接来源于双向循环神经网络(BiRNN)。既然单向 LSTM 只能看到过去的信息,那么我们可以再训练一个独立的反向 LSTM 用来 “看到未来”,再将两个方向的信息融合,使模型在每一个时间步都能获得完整的上下文。
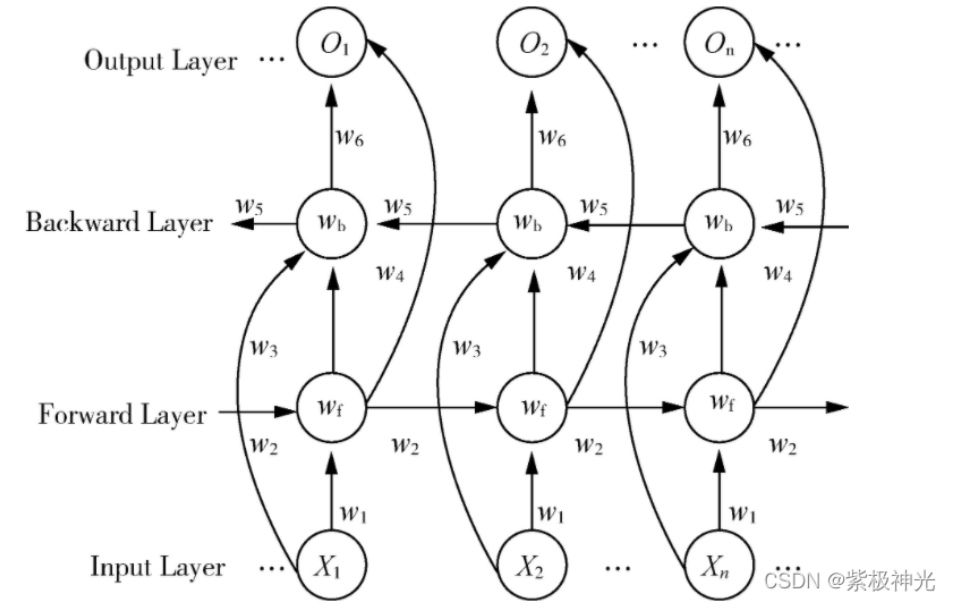
图注:双向RNN基础架构,BiLSTM是将双向RNN的隐藏层替换为LSTM单元后的优化版本
BiLSTM 正是在双向 RNN 的架构基础上,将简单的 RNN 循环单元替换为具备门控记忆能力的 LSTM 单元,既保留了双向上下文建模的优势,又解决了普通 RNN 难以处理的梯度消失与长距离依赖问题,最终成为双向序列建模的标准方案。
从更深层的理论来看,BiLSTM 的设计并非凭空提出,它的思想可以追溯到隐马尔可夫模型(HMM)中的前向‑后向算法。在 HMM 中,我们需要通过前向递推得到从起点到当前时刻的概率,同时通过后向递推得到从当前时刻到终点的概率,两者结合才能得到完整的序列分布。BiLSTM 将这种双向推理的思想迁移到深度学习中,用可学习的神经网络替代传统统计模型,实现了更灵活、更强大的双向上下文端到端建模。
4.2 结构设计
BiLSTM 的结构非常清晰,它由两个完全独立、方向相反的 LSTM 层构成,分别是正向 LSTM 层和反向 LSTM 层。
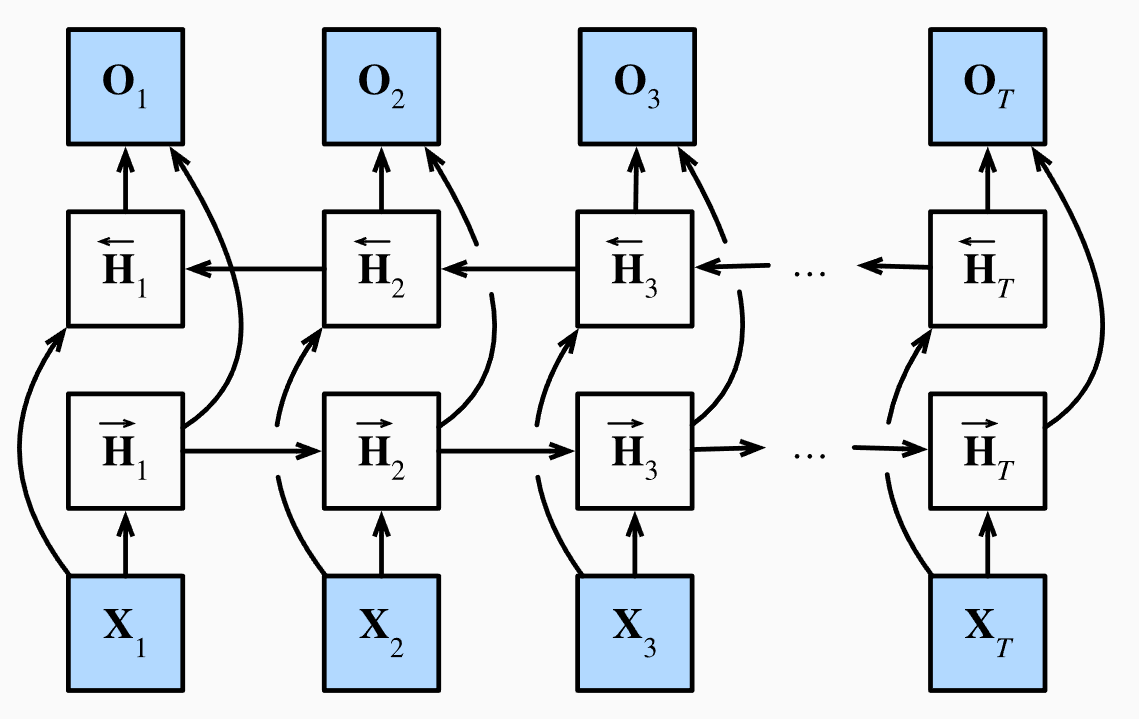
图注:标准 BiLSTM 结构示意图,由正向 LSTM 与反向 LSTM 组成,同时编码过去与未来的上下文信息
正向 LSTM 层按序列从左到右的顺序处理,负责捕捉历史上下文信息;反向 LSTM 层按序列从右到左的顺序处理,负责捕捉未来上下文信息。两个 LSTM 层互不干扰、不共享权重,分别学习正向和反向的时序依赖,最终在每个时间步,把两个方向的隐藏状态拼接起来,作为该位置的最终特征表示。
我们可以用 “我爱中国” 这句话,直观理解 BiLSTM 的结构逻辑:前向的 LSTM 从左到右依次处理 “我、爱、中、国”,编码前文信息;后向的 LSTM 从右到左依次处理 “国、中、爱、我”,编码后文信息,最终在每个字的位置,把两个方向的特征拼接,得到这个字同时包含上下文的完整特征。
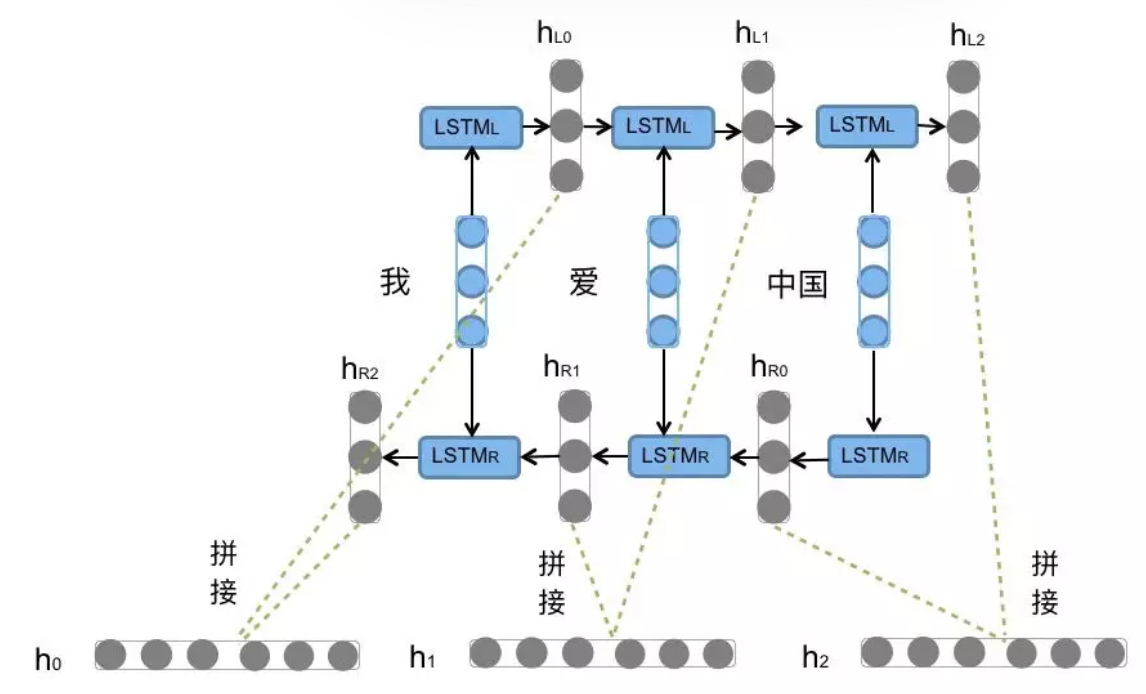
图注:BiLSTM对“我爱中国”句子的编码过程,前向LSTM(LSTML)从左到右编码,后向LSTM(LSTMR)从右到左编码,最终拼接得到每个字的完整上下文特征
这种双向融合的特征,不仅能用于单字级的序列标注任务,也可以将全局拼接后的特征送入分类层,完成句子级的情感分类等任务,充分利用了双向上下文的信息增益。
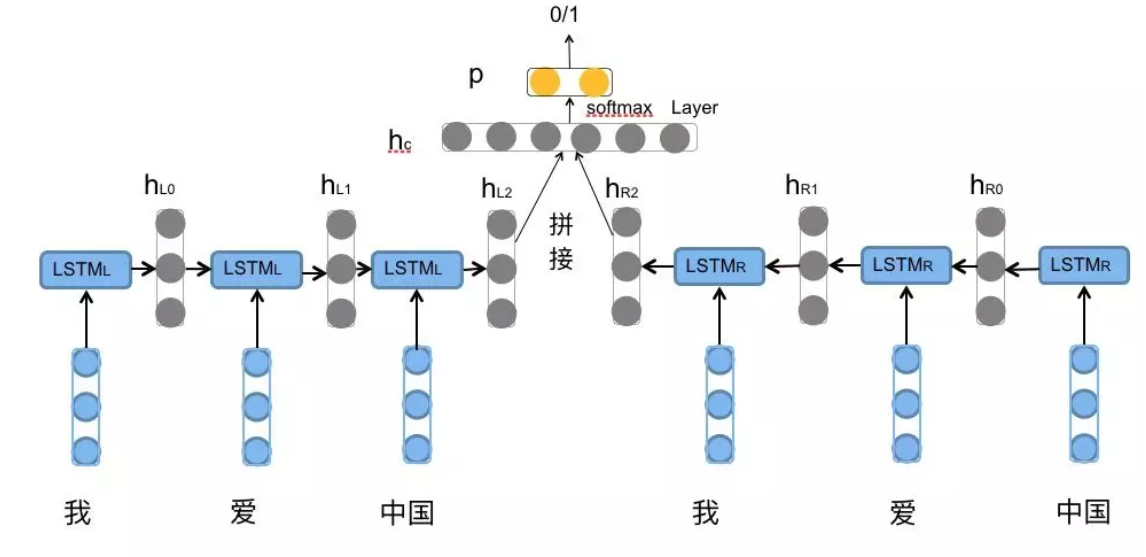
图注:BiLSTM拼接后的全局特征用于情感分类任务,融合双向信息后通过softmax输出分类结果
4.3 算法细节
BiLSTM 并没有改变 LSTM 内部的门控机制,只是在时序方向上做了扩展,它的算法流程分为三个核心步骤:
第一步是正向 LSTM 的前向传播,正向 LSTM 按时间步从左到右依次处理序列,每一步的计算和标准单向 LSTM 完全一致,依赖当前输入和上一时刻的正向隐藏状态,更新得到当前时刻的正向隐藏状态,完整保留序列的历史信息。
第二步是反向 LSTM 的前向传播,反向 LSTM 按时间步从右到左逆序处理序列,每一步的计算同样遵循标准 LSTM 的逻辑,只是它依赖的是当前输入和下一时刻的反向隐藏状态,更新得到当前时刻的反向隐藏状态,完整保留序列的未来信息。
第三步是特征拼接与输出,在序列的每一个时间步,将同一位置对应的正向隐藏状态和反向隐藏状态进行拼接,得到当前时间步的最终隐藏状态。这个拼接后的特征,同时包含了当前位置的上文信息和下文信息,能为下游任务提供更完整的序列表征,大幅提升模型的理解能力。
在训练阶段,BiLSTM 依然采用 BPTT 算法,只是需要分别对正向 LSTM 和反向 LSTM 进行独立的反向传播,计算各自的梯度并更新参数,两个方向的参数互不影响,保证了模型的稳定性。
4.4 数学表达
我们可以用严谨的数学公式,完整表达 BiLSTM 的计算逻辑。首先对序列中第 个时间步的变量做统一定义:
输入层:序列输入,同时输入正向与反向 LSTM 层;
正向隐藏层:正向隐藏状态序列为,按
的顺序从左到右计算,
仅依赖当前输入
与 上一时刻的正向隐藏状态
;
反向隐藏层:反向隐藏状态序列为,按
的顺序从右到左计算,
仅依赖当前输入
与下一时刻的反向隐藏状态
;
输出层:输出序列,每个时间步的输出由正向与反向隐藏状态拼接后计算得到,即
,其中
为输出层的映射函数。
BiLSTM 的计算分为三个核心步骤,每一步都严格遵循双向独立、最终融合的逻辑:
步骤 1:正向 LSTM 计算(历史信息编码)
正向 LSTM 按序列顺序从左到右处理,计算每个时间步的正向隐藏状态 ,其更新逻辑与标准单向 LSTM 完全一致,公式为:
其中为上一个时间步的正向隐藏状态,
初始化为零向量。
步骤 2:反向 LSTM 计算(未来信息编码)
反向 LSTM 按序列逆序从右到左处理,计算每个时间步的反向隐藏状态,公式为:
其中 为下一个时间步的反向隐藏状态,
初始化为零向量。
步骤 3:特征拼接与输出计算
将同一时间步的正向隐藏状态 与反向隐藏状态
进行拼接,得到当前时间步的最终隐藏状态
([;] 表示向量拼接操作):
最终通过输出层计算得到当前时间步的输出:
其中为隐藏层到输出层的权重矩阵,
为偏置项。
五、个人见解与思考
站在序列建模发展的视角看,RNN、LSTM、GRU、BiLSTM 构成了一条极其清晰的演化路径,每一步都精准地解决了上一代模型的核心痛点,也一步步逼近人类的认知逻辑:
-
RNN 解决了“神经网络有没有记忆”的从 0 到 1 的问题,第一次让模型能处理变长序列数据;
-
LSTM 解决了“模型能不能长期记住关键信息”的问题,通过细胞状态与门控机制,突破了长距离依赖的瓶颈;
-
GRU 在 LSTM 的基础上做了轻量化优化,在保留性能的同时大幅提升了效率;
-
BiLSTM 解决了“模型能不能利用全局上下文信息”的问题,让模型对序列的理解从单向局部升级为双向全局(注:BiLSTM 在训练时可同时利用过去与未来信息,但在实时推理场景下仍需完整序列才能工作)。
很多人说,现在 Transformer 已经成了 NLP 领域的绝对主流,RNN、LSTM、BiLSTM 已经过时了。但在我的学习过程中发现,事实并非如此。
首先,这三个模型是序列建模和 NLP 发展的绝对基石。它们提出的“记忆机制”“时序依赖建模”“上下文理解”的核心思想,是后来所有 NLP 模型的底层逻辑。哪怕是 Transformer 的自注意力机制,本质上也是为了更好地解决长距离依赖问题,只是用了不同的实现方式。如果连 RNN 和 LSTM 都没法理解透彻,那对 Transformer 的理解也只会停留在表面,根本抓不住序列建模的本质。
其次,哪怕是在今天,RNN 系列模型依然有 Transformer 无法替代的优势:
-
极致的轻量性与低算力需求;
-
天然的流式处理能力(逐时间步计算,无需完整序列);
-
极强的可解释性。
在小样本场景、边缘设备部署、实时工业时序预测等场景中,LSTM 和 BiLSTM 依然是首选方案。
对于每一个想要踏入 NLP 和时序建模领域的人来说,读懂这三个模型,不仅是读懂了一段技术发展史,更是读懂了序列建模的底层逻辑——如何让机器拥有记忆、理解时间、读懂上下文。而这个底层逻辑,会成为我们在 AI 领域走得更远的坚实基础。
六、全文总结
从朴素的 RNN,到解决长距离依赖的 LSTM/GRU,再到能双向理解上下文的 BiLSTM,我们能清晰地看到 AI 领域模型演进的核心逻辑:我们一直在用技术,不断地贴近人类的认知规律。
技术的迭代从来都不是一蹴而就的,也从来没有绝对的“过时”一说。哪怕是在 Transformer 大行其道的今天,RNN、LSTM、BiLSTM 依然在很多领域发光发热。
对于每一个想要踏入 NLP 和时序建模领域的人来说,读懂这三个模型,不仅是读懂了一段技术发展史,更是读懂了序列建模的底层逻辑——如何让机器拥有记忆、理解时间、读懂上下文。而这个底层逻辑,会成为你在 AI 领域走得更远的坚实基础。
参考文献
学术文献
[1] Elman, J. L. (1990). Finding structure in time. Cognitive Science, 14(2), 179-211.
[2] Bengio, Y., Simard, P., & Frasconi, P. (1994). Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2), 157-166.
[3] Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780.
[4] Cho, K., van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. Proceedings of EMNLP, 1724-1734. (GRU 原始论文)
[5] Graves, A., & Schmidhuber, J. (2005). Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Networks, 18(5-6), 602-610.
[6] Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. (Chapter 10: Sequence Modeling: Recurrent and Recursive Nets)
参考博客与资料
Understanding LSTM Networks -- colah's blog
一幅图真正理解LSTM、BiLSTM_bilstm和lstm的区别-CSDN博客
00 预训练语言模型的前世今生(全文 24854 个词) - B站-水论文的程序猿 - 博客园
9.4. 双向循环神经网络 — 动手学深度学习 2.0.0 documentation

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)