利用AI Agent搭建RAG系统
前言
之前基于txtai开源软件搭建RAG系统遇到了一些问题,可能是软件安装上的问题,觉得自己搭建太麻烦了,放弃。借助AI Agent重新开始。
用conda环境的好处是,每次重新开始只要新建一个env,不会影响到系统的软件配置,新建了一个rag_system的conda env,从头开始搭建RAG系统。
推荐的RAG技术栈
我的电脑环境有一个RTX4060,询问AI,获得的推荐技术栈如下:
- LLM 模型,建议Qwen2.5-7B-Instruct 或 Llama-3.2-3B-Instruct,7B模型需要 ~6-8GB VRAM(量化后),4060 可流畅运行,我想先验证简单功能,选择了一个较小的LLM模型:Qwen2.5-1.5B-Instruct;
- Embedding 模型,建议bge-m3 或 text2vec-large-chinese,我选择bge-m3 支持多语言,对IT术语友好;
- 向量数据库,建议ChromaDB 或 FAISS,轻量级,易上手;生产级可选 Qdrant,我选择ChromaDB;
- RAG 框架,建议LangChain 或 LlamaIndex 成熟生态丰富,我选择了LangChain;
- 部署方式,建议Ollama + AnythingLLM,最简方案,零配置运行,但是我想能够自己可控,所以不用建议的方案,而是选择使用 HuggingFace 方式直接加载本地模型。
环境准备
总结一下技术方案如下:
1.使用 HuggingFace 方式直接加载本地模型
2.conda 环境
3.LangChain
4.ChromaDB 向量数据库
5.下载的Embedding模型是D:\nxk\ai_models\bge-m3
6.下载的LLM模型是D:\nxk\ai_models\Qwen2.5-1.5B-Instruct
7.我的技术文档在D:\nxk\ai_doc
【注意】由于创建环境,安装软件等需要消耗比较多的Token,所以选择自己创建环境和安装软件,通过这个准备过程也可以有更多的了解。
操作步骤
# 1. 打开 Anaconda Prompt
# 2. 创建新环境(Python 3.11 稳定版)
conda create -n rag_system python=3.11 -y
创建一个conda环境为rag_system,Python版本为3.11
# 3. 激活环境
conda activate rag_system
# 4. 安装 PyTorch
应该安装cu124,如下:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
【注意】需要科学上网才能安装,且torch 不能用清华源 / 豆瓣源这些普通 PyPI 镜像!
之前安装了旧版本,这样安装的torch版本是2.5.1,不是2.6,加载Embedding模型有问题,要卸载了重新安装
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# 如果之前已经安装错了,先卸载旧版本
pip uninstall torch torchvision torchaudio -y
# 5. 安装 其他软件
pip install langchain langchain-community langchain-huggingface
pip install llama-index llama-index-llms-huggingface llama-index-embeddings-huggingface
pip install chromadb sentence-transformers
pip install pypdf tiktoken python-dotenv
pip install bitsandbytes #4bit量化需要额外安装这个
pip install pypdf unstructured #LangChain的Doc loader
pip install python-docx #LangChain的Doc loader
【参考】:
可以选择利用镜像安装以加快速度,比如单次设置:
pip install chromadb -i https://pypi.tuna.tsinghua.edu.cn/simple
或者全局设置镜像源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
取消全局设置:
pip config unset global.index-url
验证环境
安装完成之后,最好先提前验证一下,有如下验证项目:
验证项 命令/方法
GPU 可用 python -c "import torch; print(torch.cuda.is_available())"
Embedding 模型加载 加载 bge-m3 并测试 encode 一句话
LLM 模型加载 加载 Qwen2.5-1.5B-Instruct 并测试一次推理
ChromaDB 可用 python -c "import chromadb; print('OK')"
文档读取 用 LangChain 的 loader 读取一篇文档
验证结果如下:
(rag_system) PS C:\Users\37995> python -c "import torch; print(f'torch: {torch.__version__}')"
torch: 2.6.0+cu124
(rag_system) PS C:\Users\37995\miniconda3\envs\rag_system\nxktest> python -c "import chromadb; print('OK')"
OK
以下这些测试代码,询问AI都可以给出,具体内容不一样,大同小异:
Mode LastWriteTime Length Name
-a---- 2026/4/3 12:28 695 testdoc_loader.py
-a---- 2026/4/2 12:08 1060 testembed.py
-a---- 2026/4/2 11:57 200 testgpu.py
-a---- 2026/4/3 11:53 2350 testllm.py
举例:
(rag_system) PS C:\Users\37995\miniconda3\envs\rag_system\nxktest> python testgpu.py
CUDA available: True
GPU: NVIDIA GeForce RTX 4060 Laptop GPU
VRAM: 8.0 GB
代码框架规划
先在ask模式让AI给出一个大致规划,看一下跟自己的预期是否类似,再转Agent模式比较安全,当然最后实现的跟这个其实有差异,可以对比后面的系统架构
d:\nxk\cursor1\rag1\ # 项目根目录
├── .env # 环境变量配置
├── requirements.txt # 依赖清单
├── src/
│ ├── config.py # 配置加载
│ ├── document_loader.py # 文档加载与分块
│ ├── vector_store.py # ChromaDB 向量库管理
│ ├── embedding_model.py # Embedding 模型封装
│ ├── llm_model.py # LLM 模型封装
│ └── rag_chain.py # RAG 链(检索+生成)
├── data/
│ └── chroma_db/ # ChromaDB 持久化目录
└── tests/
└── test_basic.py # 基础功能测试脚本
启动Agent
【注意】启动前,先设置一下Agent的行为模式,做一些限制。
不同的人需求不同,从安全角度考虑,我这里对Agent的设置限制比较多,主要是下面2个:
- 不允许Agent删除文件
- 每次Agent要执行命令时,都需要问我才能执行
更换为Agent模式,给Agent的提示词如下:
我想做一个IT技术类的RAG系统,本地有RTX4060,采用离线模型。之前讨论的方案是
1.使用 HuggingFace 方式直接加载本地模型
2.conda 环境
3.LangChain
4.ChromaDB 向量数据库
5.下载的Embedding模型是D:\nxk\ai_models\bge-m3
6.下载的LLM模型是D:\nxk\ai_models\Qwen2.5-1.5B-Instruct
7. 我的技术文档在D:\nxk\ai_doc
打算在conda环境中进行调试,我在C:\Users\37995\miniconda3\envs\rag_system已经创建了一个conda环境为rag_system,Python版本为3.11,软件也已经安装且验证成功,请帮我做一个RAG系统,谢谢
Agent工作流程记录
AI Agent就开始工作了,Agent会默认检查环境,安装软件等,在安装软件的询问中,我就选择拒绝,然后Agent会检查一下软件是否都安装成功,然后一步步进行操作。
下面是Agent工作过程的一些关键记录:
首先列出12项全局工作内容,然后一项项完成:
- 创建 RAG 系统目录结构
- 编写 config.py 全局配置
- 编写 document_loader.py 文档加载模块
- 编写 text_splitter.py 文本分块模块
- 编写 embedding_model.py Embedding 模型封装
- 编写 vector_store.py 向量数据库模块
- 编写 retriever.py 检索模块
- 编写 llm_model.py LLM 模型封装
- 编写 rag_chain.py RAG 主流程链
- 编写 main.py 入口程序
- 编写 requirements.txt 依赖文件
- 安装依赖并调试运行
目录结构已创建。现在开始编写各个模块文件。让我批量创建所有文件。
目录创建成功。现在批量编写所有模块文件。
现在批量创建所有模块文件。
现在批量编写核心模块。
现在编写检索器、RAG 链、日志工具和入口程序。
。。。。。 一系列的代码生成过程,太多了就只选了几个。。。。。
然后检查环境是否满足:
All the required packages are already installed. Let me verify:
langchain: ✅ 1.2.14
langchain-core: ✅ 1.2.24
langchain-community: ✅ 0.4.1
chromadb: ✅ 1.5.5
sentence-transformers: ✅ 5.3.0
transformers: ✅ 4.57.6
torch: ✅ 2.6.0+cu124
bitsandbytes: ✅ 0.49.2
accelerate: ✅ 1.13.0
pypdf: ✅ 6.9.2
unstructured: ✅ 0.22.12
numpy: ✅ 2.4.3
tqdm: ✅ 4.67.3
所有依赖已安装。现在验证代码语法正确性。
所有模块语法正确。再创建一个 README 和一个快速验证脚本。
系统架构
main.py # 入口程序,交互式问答界面
└── rag_system/
├── config/ # 全局配置(路径、参数)
├── documents/ # 文档加载 + 文本分块
├── models/ # Embedding 模型 + LLM 模型
├── vectorstore/ # ChromaDB 向量库 + 检索器
├── rag_chain.py # RAG 主流程(加载→分块→检索→生成)
└── utils/ # 日志工具
数据流向
技术文档 (D:\xk\ai_doc)
↓
DocumentLoader (文档读取)
↓
TextSplitter (语义分块)
↓
BGEEmbeddings (生成向量)
↓
ChromaDB (向量存储)
↓
Retriever (相似度检索)
↓
QwenLLM (RAG Prompt + LLM 推理)
↓
最终回答
Agent总结
RAG 系统已全部完成,所有模块导入验证通过。以下是最终总结:


直接运行 python main.py 即可,有任何报错告诉我。
错误反馈
执行有问题,反馈给Agent,会自动修改代码,需要安装的软件会反馈给我来自行安装,可能是因为最初的软件安装我是拒绝的,所以Agent没有自动安装软件
比如识别docx文档时,还是需要补充安装了这个软件:
pip install python-docx
识别pdf文档时,遇到错误,反馈后Agent自行修改了软件,重新运行即可
运行效果
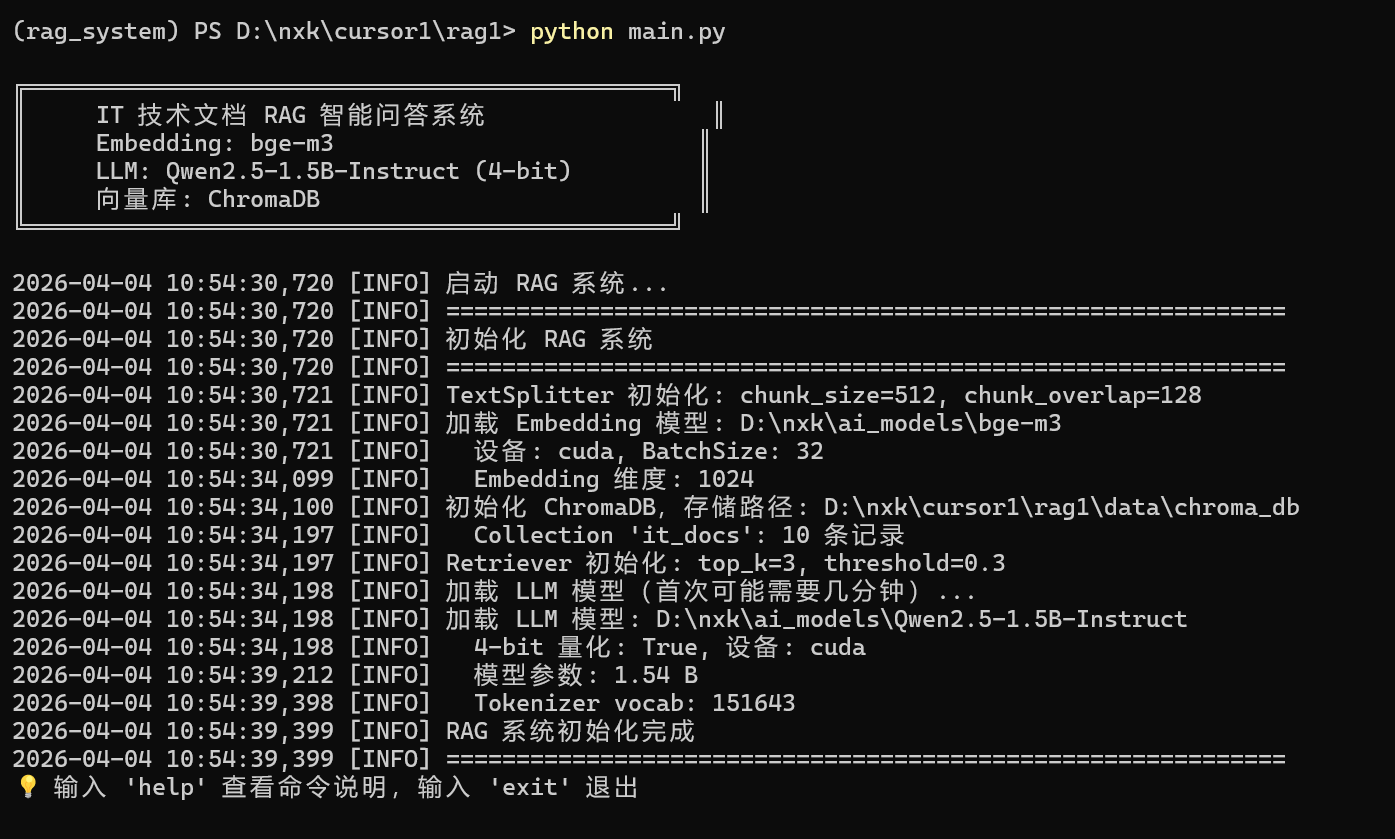
RAG前期初始化,加载模型
 根据私有文档创建向量数据库
根据私有文档创建向量数据库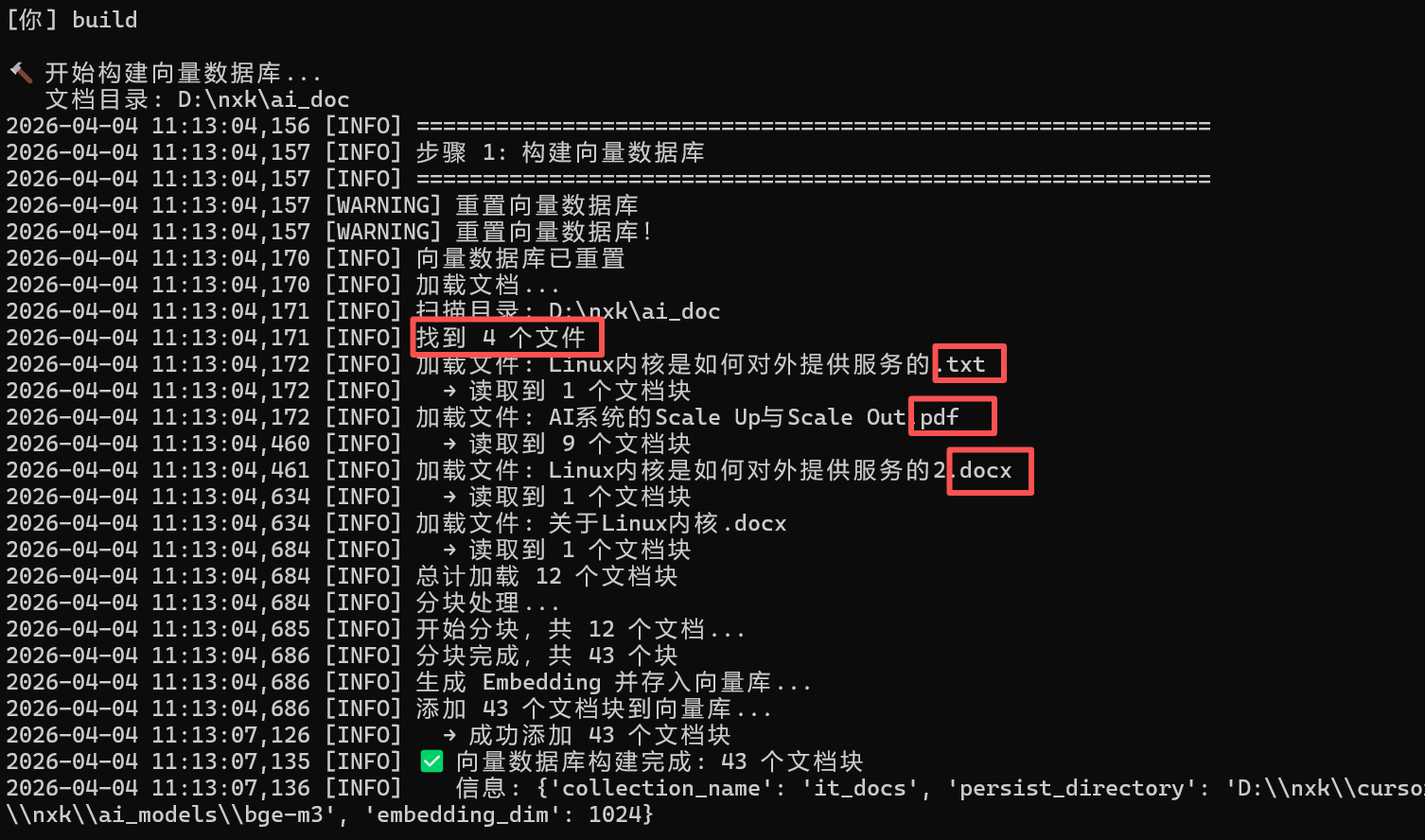
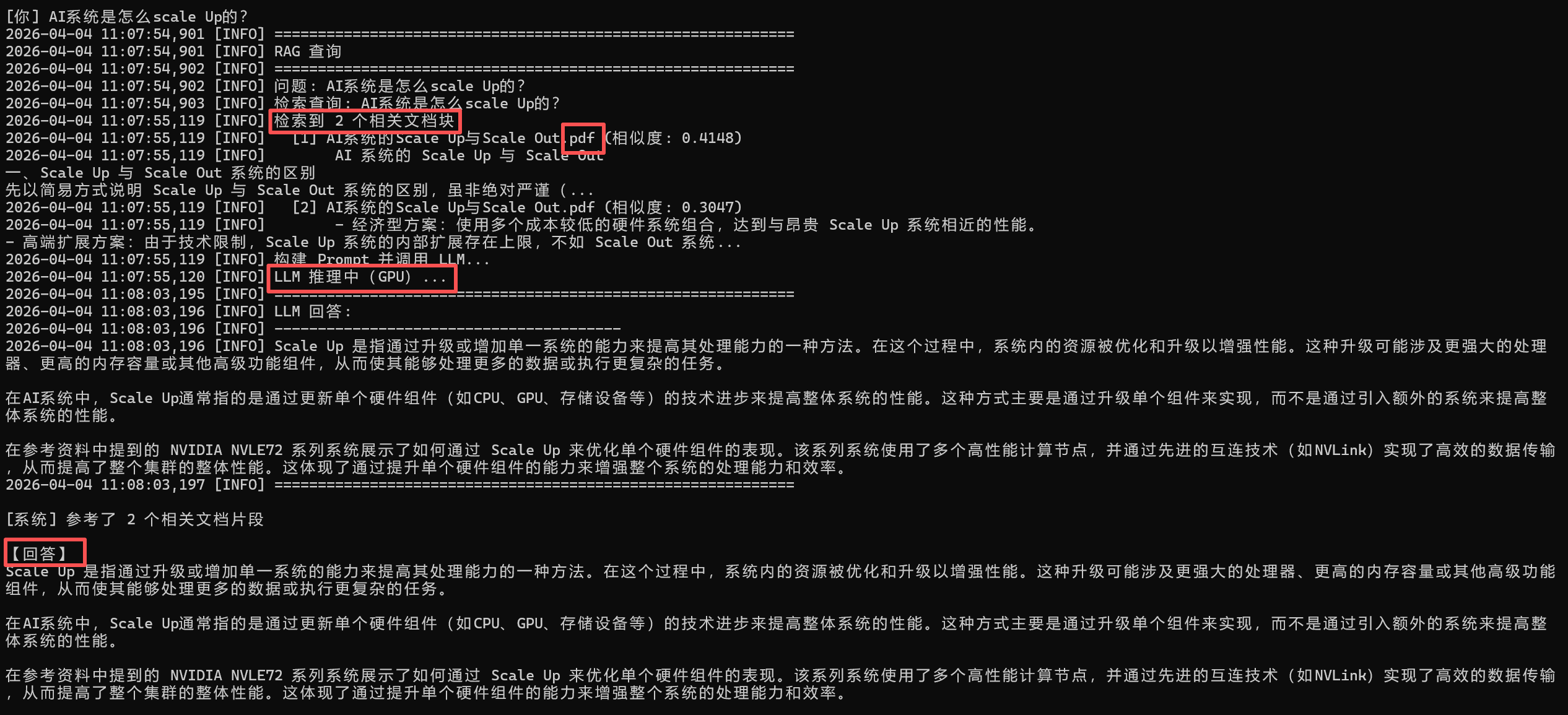
RAG问答测试1,验证pdf文档内容是否可以理解,验证成功
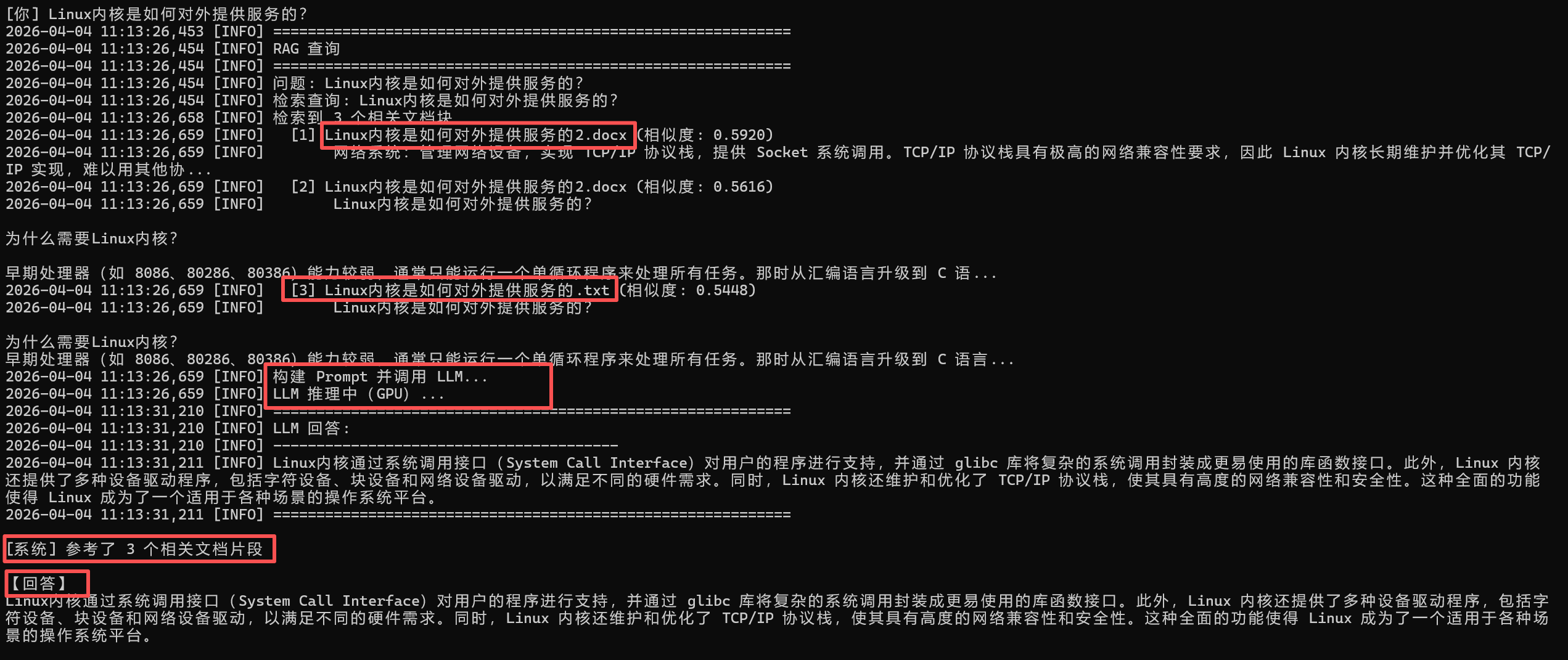
 RAG问答测试2,验证docx和txt文档内容是否可以理解,重复内容是否可以处理,验证成功
RAG问答测试2,验证docx和txt文档内容是否可以理解,重复内容是否可以处理,验证成功

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)