yolov3学习之检测原理
目录

为啥网络结构中neck部分(特征金字塔网络(FPN))只有3个呢?和其原理或者说设计有关系:
YOLOv3 最核心的改进之一就是YOLOv3设计了3个尺度,以及9种不同大小的先验框(大、中、小各3个)——Anchor Box。
1 3个尺度
3个尺度是什么呢?3个尺度= 3个特征图(13×13、26×26、52×52)。
所以其neck部分就设计为了3个尺度:
大网格(13×13):专门负责检测大物体。这里用的是 3 把大尺子。
中网格(26×26):专门负责检测中物体。这里用的是 3 把中尺子。
小网格(52×52):专门负责检测小物体。这里用的是 3 把小尺子。
所以neck部分就根据这个检测大中小物体的理念设计出了3个特征图,这就是neck设计为3个输出的原因!
然后说的“3把大尺子”、“3把中尺子”、“3把小尺子”,说的就是大中小3个网络的每个网络(特征图),都有3个先验框Anchor Box。
模型预测是怎么预测呢?就是对neck的3个特征图的每个网格都根据先验框预测3种框(大、中、小)。
2 框的属性
每个框的属性:
位置偏移(x, y, w, h):xy相对于该网格中心的偏移量,wh相对于 Anchor 的比例。
置信度:这个框里有物体的概率。
类别概率:这个物体是什么(比如人、车、狗)。
其中Anchor说的就是这3种框的先验框。你预测该网格的大、中、小目标,那么Anchor就对应该特征图的大、中、小的先验框——每个特征图共用一套先验框(大中小共3个,所以yolov3有3个特征图,共3x3=9个先验框)。
所以呢,yolov3就设计出了9个先验框。
3 先验框Anchor Box
什么是先验框Anchor Box呢?先验框(Anchor Boxes)就是针对不同数据集“量身定制”的“参考尺码”。
它是一个预设的固定大小的只有宽高参数的矩形框。——不是训练出来的,而是在训练前通过聚类(K-means)从训练集的真实框(Ground Truth)中提取出来的“典型尺寸”。
先验框就2个数值。这两个数值代表的是宽(width)和高(height),通常以像素为单位。
为什么只有宽高,没有位置?因为先验框是形状模板,不是具体的框。它的位置是由网格(Grid)决定的。模型在预测时,会把这个“模板”放在网格的某个位置上,然后根据预测的偏移量(x, y)去微调位置。
3.1 先验框举例
YOLOv3 在 COCO 数据集上聚类出了 9 个 Anchor(3种尺度 × 3种长宽比),如下数值:
大尺子(13×13网格用):(116, 90), (156, 198), (373, 326)—— 用来框大象、公交车等大物体。
中尺子(26×26网格用):(30, 61), (62, 45), (59, 119)—— 用来框人、狗等中等物体。
小尺子(52×52网格用):(10, 13), (16, 30), (33, 23)—— 用来框杯子、手机等小物体。
假如我要在小尺子(52x52)的某个网格上预测,先预测基于先验框是 (10, 13)的小目标框(这代表一个宽10像素、高13像素的矩形),再预测基于(16, 30), (33, 23)这两个先验框再预测2个目标框,这样一个网格预测3个框。
来看基于先验框(10, 13)是怎么预测的:如果模型在该网格预测的xy偏移量是 (0.5, 0.5),那么最终框的位置就会在该网格中心点的基础上移动;如果模型预测的缩放量wh是 (1.2, 1.5),那么最终框的大小就会变成 (10 * 1.2, 13*1.5) = (12, 19.5)。
同样的操作,还要预测该网格的其他两类目标——先验框为(16, 30), (33, 23)的中目标,大目标。
这才完成了小尺子(52x52)一个网格的预测,也就是说每个网格可以预测3个框,那么小尺子(52x52)总共要预测52x52x3=8112个框。
同样大尺子13x13,中尺子26x26也是这样的。
基于此,咱们可以分析下对于coco数据集下的Prediction部分的最终输出。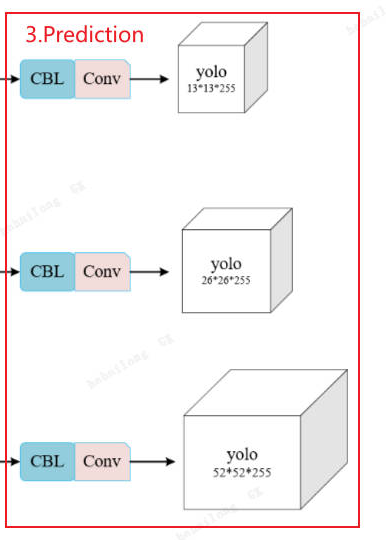
图中 Prediction 部分输出的是:
13×13×255
26×26×255
52×52×255
这个 255 是怎么来的?
255 = 3(Anchor数) × (5 + 80)
3:每个网格有基于 3 个 Anchor(先验框)预测的3个框。
每个框的属性(参数量):
5:4个坐标(x,y,w,h) + 1个置信度。
80:COCO 数据集有 80 个类别。
那么这么看来其预测的总框数为:(13×13 + 26×26 +52×52)x3 = 10647
每个框是85个参数(CoCo数据集),那么一共 10647 * 85 = 904995个参数——也就是顺模型要输出这么多值。
接着就送给后处理了,后处理把10647个候选框通过NMS等过滤出来有效的框。
3.2 不同数据集的先验框不一样
因为不同数据集中物体的“身材比例”不同。先验框是通过聚类算法(如K-means)从训练集的真实标注框(Ground Truth)中计算出来的。
COCO数据集:包含很多“人”,人通常是瘦高的,所以它的先验框里会有很多高大于宽的框(如 (10, 13))。
VOC数据集:包含很多“车”,车通常是扁长的,所以它的先验框里会有很多宽大于高的框。
3.3 先验框的核心作用:降低学习难度
没有先验框(Hard Mode):模型需要从零开始猜一个巨大的数字(比如框的像素坐标),这非常困难,容易学偏。
有先验框(Easy Mode):模型只需要学习“微调量”(偏移和缩放),学习任务变简单了,所以收敛速度确实会变快。
3.4 先验框的“天花板”效应
如果先验框的形状和你的数据集不匹配,模型性能会直接受限。
好例子:用COCO数据集(有很多瘦高的人)训练,如果先验框里没有瘦高的形状,模型再怎么努力也学不会把人框准。
坏例子:用检测二维码(正方形)的数据集,如果先验框全是扁长的,模型永远学不会画一个标准的正方形框。
模型确实学的是宽高缩放比例(t_w, t_h),理论上确实能通过缩放把任何形状的先验框变成任何形状的预测框。
但“天花板效应”指的是学习难度和收敛稳定性的问题,而不是数学上的“不可能”。
为什么会有“天花板效应”?(数学视角)
虽然公式 w = anchor_w * exp(t_w)在数学上无界,但在实际训练中,模型参数(t_w)的梯度和学习率是有限的。
极端缩放:如果先验框是 (1, 1)(正方形),而真实物体是 (100, 1)(极扁长),模型需要让 t_w变得非常大(exp(t_w) ≈ 100)。在有限的训练步数内,模型可能来不及把参数调整到那么大,或者梯度回传不稳定,导致收敛困难或震荡。
数值稳定性:指数函数 exp(t_w)在 t_w很大时,数值变化剧烈,容易导致梯度爆炸或消失。
为什么匹配的先验框更好?(工程视角)
匹配的先验框(如用 (10, 1)去拟合 (100, 1))相当于把缩放倍数从 100 倍降到了 10 倍。
学习任务变简单:模型只需要学习一个较小的偏移量(t_w较小),梯度更平滑,收敛更快、更稳。
避免极端值:避免了模型去学习那些“极端”的缩放比例,减少了训练过程中的数值风险。
3.5 换个数据集怎么搞先验框?
换数据集搞先验框,核心就两步:“算”和“改”。这就像给新员工配工位,得先量量他平时带多大的包,再给他配个合适的柜子。
(1) 怎么“算”?(聚类)
别自己瞎猜,用算法从你的新数据里“统计”出最合适的尺寸。推荐用 K-means 聚类(K=9)。
输入:你新数据集里所有真实标注框的 宽高(w, h)。
输出:9个最能代表你数据物体形状的 (宽, 高) 数值。
工具:通常训练框架(如 YOLO 官方代码)自带这个脚本,或者用 Python 的 scikit-learn库跑一下。
(2)怎么“改”?(配置)
算出来的 9 个数值,按大、中、小三组,填进模型的配置文件(如 yolov3.cfg)。
大框(对应 13x13 网格):放 3 个最大的数值。
中框(对应 26x26 网格):放 3 个中等的数值。
小框(对应 52x52 网格):放 3 个最小的数值。
4 检测原理综述
yolov3根据大中小目标检测思想设计了3个尺度,所以neck输出3个特征图,而每个特征图都有3个先验框,所以3个特征图共9个先验框,作为预测目标框的缩放比例的基准。
这样每个特征图的每个网格上都参照对应3个先验框进行预测3个框(xywh+置信度+类别数)。
因为如果让模型自己去预测,不用先验框,对它来说训练太复杂了,有先验框就只需要每个网格去预测3个框的偏移量就行了(也就是说每个网格去预测3个框,那么每个特征图的网格都可以计算出来,那么它能预测多少个都能计算出来了。比如13x13,那么就能预测13x13x3这么多候选框)。
然后再送给后处理进行去重。
5 模型的关键输入输出
模型就是输入输出的东西(人类也是)。
yolov3关键输入:
(1)图片数据,比如416x416x3的数据。
(2)9个先验框。neck的3个特征图的参考先验框——每个特征图有3个(大中小)先验框,共计3x3=9个先验框。
yolov3输出
3个特征图的每个网格输出3个预测框。每个框包含了位置信息、置信度和类别概率。
比如输入416x416x3的输出的框个数:
(13×13 + 26×26 +52×52)x3 = 10647
总参数:
13×13×255+26×26×255+52×52×255
以上就是输出。
接着会送给后处理——虽然计算出来有这么多框(10647个框),但并不是每个框都有效。在推理时,会通过置信度(Confidence)和非极大值抑制(NMS)进行筛选:
置信度:判断这个框里有没有物体。
NMS:去除重叠的冗余框。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)