论文精读:NeurIPS 2025 的最佳论文-《Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Bey
论文下载地址:
https://arxiv.org/pdf/2510.22954
这篇论文名为《Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)》(可译为《人工蜂群思维:语言模型在开放式生成中的同质化及更深远影响》)
很多人担心大模型,首先想到的是“会不会胡说”“会不会答错”。但这篇论文担心的是另一种更隐蔽的风险:模型不一定答错,甚至经常答得不错,但它们可能在开放式问题上越来越像,最后形成一种“人工蜂群思维”。
这篇论文想说的是:
现在的大模型,看起来很多、品牌很多、参数很多,但在很多“没有标准答案”的开放式问题上,它们给出的想法、比喻、创意、措辞,常常会收敛到少数几种模式。
这不只是“一个模型有点重复”这么简单,而是更大的问题:
不同模型也可能像在共享一个“大脑习惯”一样,越来越趋同。
接下来我们开始讲解吧
第一部分:背景
1. 拆解标题:什么是“人工蜂群思维”?
要看懂这篇论文,我们先从它极具隐喻性的标题入手:
-
Artificial Hivemind (人工蜂群思维): 想象一下蜂巢里的蜜蜂,它们没有独立的思想,所有蜜蜂都仿佛共享同一个“大脑”,做着整齐划一的动作。作者用这个词来形容现在的 AI 大模型(比如 ChatGPT、Claude、DeepSeek 等):虽然它们看起来是不同公司开发的独立 AI,但它们的“思想”正在变成同一个模子刻出来的。
-
Open-Ended (开放式问题): 比如我问“北京首都是哪”,这是有标准答案的封闭问题。但如果我问“请帮我写一封辞职信”或者“讲一个关于星际穿越的科幻故事”,这就是开放式问题。这类问题本该有无数种天马行空、各具特色的回答。
-
Homogeneity (同质化): 意思就是“千篇一律”、“大家变得越来越像”。
当我们让 AI 去做那些需要创造力、没有标准答案的“开放式任务”时,现在市面上的所有 AI 模型都失去了个性。它们给出的回答越来越像,仿佛共享着同一个“蜂巢大脑”。
2. 论文“实锤”的两个可怕现象
为了证明这个观点,研究人员耗费巨大精力测试了市面上 70 多个大语言模型,并发现了两个非常明显的“同质化”现象:
-
现象一:模型内重复 (Intra-model repetition) —— “自己抄自己”
-
小白解释: 假设你把同一个开放式问题(比如“帮我想个有创意的独立咖啡馆名字”)抛给同一个 AI 模型 10 次。你原本期望它像人类头脑风暴一样,给你 10 个完全不同方向的灵感。但结果是,它每次给的思路、语气、甚至取名的套路都差不多。它陷入了某种固定的“舒适区”,失去了发散性思维。
-
-
现象二:模型间同质化 (Inter-model homogeneity) —— “大家互相抄”
-
小白解释: 这是更令人担忧的一点。研究人员把同一个问题分别发给 OpenAI、阿里、DeepSeek 等不同公司开发的、理应互不干涉的模型。结果发现,它们生成的回答平均相似度竟然高达 71% 到 82%!甚至在某些复杂的商业文案中,不同的模型竟然逐字逐句生成了一模一样的句子(比如都不约而同地使用了“流畅设计,不妥协于功能”这种套话)。它们明明是不同架构养大的,却长了一模一样的“嘴”。
-
3. 为什么我们要警惕?(论文的深远影响)
你可能会问:只要 AI 回答得通顺好用就行了,千篇一律有什么大不了的?
论文指出,这是一个巨大的隐患:它会带来人类思想的同质化。 现在越来越多的人依赖 AI 来写文章、做企划、头脑风暴甚至寻求决策建议。如果所有的 AI 都在输出同一种语气、同一种比喻(比如一写时光流逝就是“时间是一条河流”)、同一种结构,那么长此以往,人类自己独特的创造力、多元化的视角和个性的表达,都会在潜移默化中被 AI 抹平。最终,我们所有人写出来的东西、想出来的创意,都会变得像这群 AI 一样“中规中矩且无聊”。
论文一开头给了一个特别直观的例子:
让不同模型回答:“Write a metaphor about time(写一个关于时间的隐喻)”
按理说,这种题应该很开放,答案空间极大。
你可以把时间写成:
-
风
-
沙漏
-
火焰
-
树轮
-
波浪
-
雨
-
织布机
-
雕刻师
-
钟摆
-
光
理论上空间非常大。
但论文发现,25 个模型各自生成 50 个回答后,答案在语义空间里主要只形成了两个大簇:
-
一个大簇围绕 “time is a river(时间像河流)”
-
另一个较小簇围绕 “time is a weaver(时间像织者/织布者)”
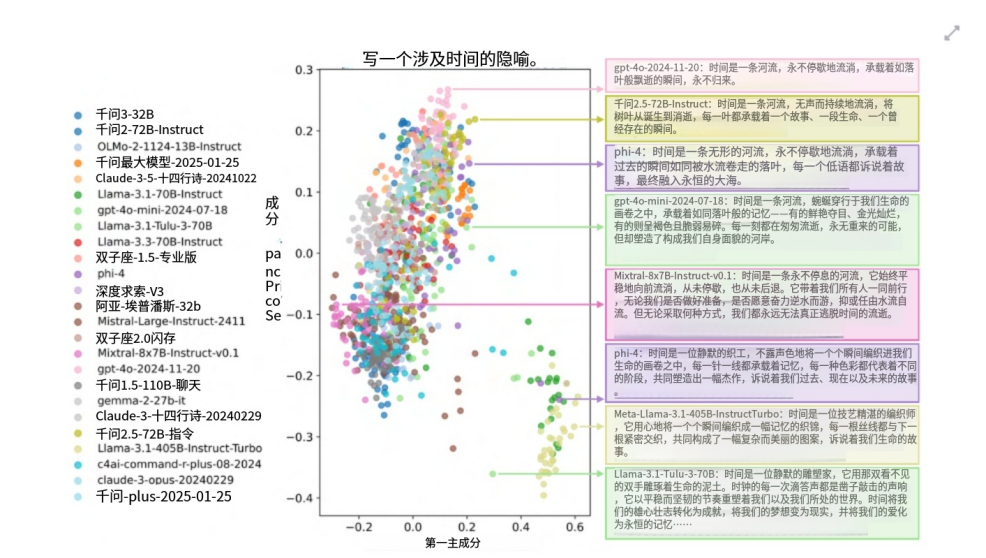
这就是一个非常震撼的现象。
因为这不是事实问答,不是数学题,不是标准答案题。
这是一个创意题。
可即便如此,模型们还是会大量收敛到同样的隐喻中心。
模型虽然输出不同句子,但底层的想法空间并没有我们想象得那么大。
第一部分的背景和核心概念我们就先聊到这里。这篇论文为了证明上述观点,还专门构建了一个名为 INFINITY-CHAT 的超级测试集,并揭示了为什么 AI 的“裁判机制”也在助长这种同质化。
先把几个术语讲明白,不然后面会绕晕
1. Mode collapse(模式坍缩)
这原本是生成模型领域常见的词。意思很简单:
本来应该能生成很多不同样式,结果只会反复落到少数几个模式里。
比如让模型写 100 个比喻,理论上应该五花八门;但它总写成“时间像河流”“人生像旅程”“记忆像碎片”这种固定套路。这就是模式坍缩。
2. Intra-model repetition(模型内重复)
同一个模型内部的重复。比如你问同一个模型 50 次“写一个关于时间的隐喻”,它虽然每次字不完全一样,但核心意思总围着几种套路打转。
3. Inter-model homogeneity(模型间同质化)
不同模型之间也很像。这就更严重了。
因为你本来会以为:
OpenAI 一个风格
Anthropic 一个风格
Qwen 一个风格
DeepSeek 一个风格
Llama 一个风格
但论文发现:
很多时候它们不是“各有各的脑子”,而是“换着牌子说相似的话”。
4. Calibration(校准)
这个词在后半篇论文里很重要。意思是:模型给出的评分或判断,和人类真实偏好到底对不对得上。
比如两篇文案,人类觉得都不错、差不多;但模型评分系统却极度偏爱其中一个,把另一个压得很低。这就叫校准不好。
第二部分:数据集与实验
你可以把作者的工作想成 4 个连续步骤:
第 1 步:找真实世界里的开放式问题
他们不是自己拍脑袋编题,而是从 WildChat 这类真实用户和聊天模型的交互里,筛选真正“开放式”的用户提问。
第 2 步:给这些开放式问题分类
作者整理出一个 taxonomy,也就是“问题类型地图”,想知道现实里大家到底在问哪些开放式问题。最后他们得到 6 个大类、17 个细类。
第 3 步:拿很多模型来答这些题
他们选了 70 多个模型做大规模分析,正文重点展示 25 个代表模型。然后对同一个问题反复采样很多次,看一个模型自己会不会重复,也看不同模型之间会不会撞到同样的想法。
第 4 步:收集人类评分,再和模型评分比较
作者额外做了 31,250 条人工标注,比较“人类怎么看答案”和“模型评委怎么看答案”是否一致,尤其关注那种多个答案都不错、但不同人喜欢不同风格的情况。
数据集:
这篇论文最重要的不是某个公式,而是这个新数据集:Infinity-Chat。论文把它定义为一个大规模、真实世界、开放式 user query 数据集,专门拿来研究“一个问题本来就可能有很多合理答案”的场景。
所以它为什么要新造一个数据集?
因为作者认为,以前很多测“模型多样性”的基准都太窄了,比如:
-
随机数生成
-
名字生成
-
很特定的诗歌或修辞任务
-
风格化得很强的小任务
这些任务不能代表现实中的聊天使用场景。现实中用户经常问的是:
-
帮我想创意
-
给我多个表达版本
-
帮我解释一个概念
-
帮我头脑风暴
-
给我建议
-
写一个有风格的内容
这些都不是只有一个标准答案的问题。作者觉得,如果不研究这些真实开放式提问,那你就没法真正回答“模型到底会不会让思维变窄”。
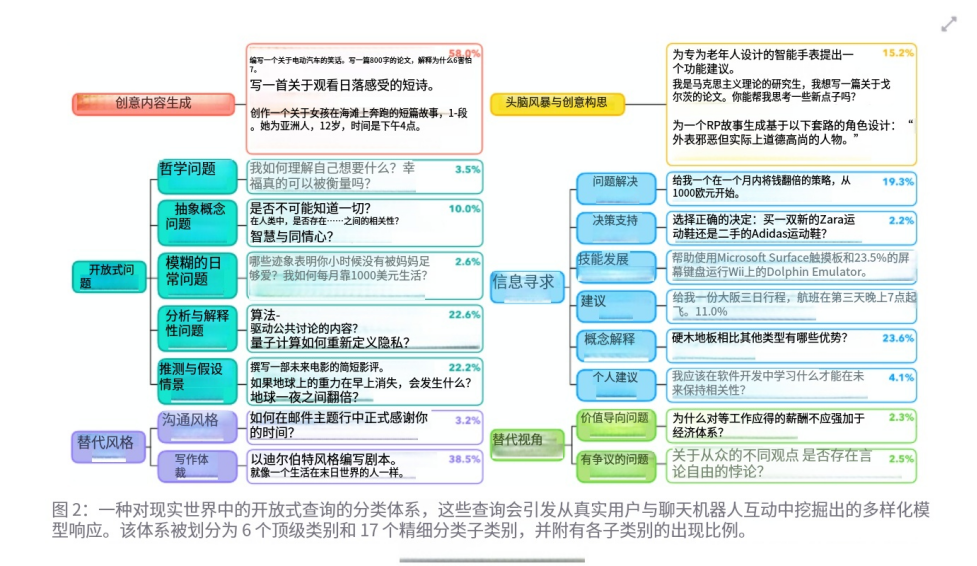
这篇论文还有一个很重要的贡献:它不仅搜集开放式问题,还整理了一个问题类型地图。论文说他们最终得到 6 个顶层类别、17 个细分类别,并用 GPT-4o 扩展标注到整个数据集。
这 6 大类可以粗略理解成:
1. Creative Content Generation
就是创意内容生成。比如:
-
写诗
-
写广告
-
写短文
-
写笑话
这是比例最大的类别,论文报告它占 58.0%。
2. Brainstorming & Ideation
就是头脑风暴、想点子、想方案。比如:
-
帮我想 thesis idea
-
给智能手表想一个功能
它占 15.2%。作者特别强调这一点,因为这说明很多用户真的在把模型当“灵感来源”。
3. Open-Endedness / 抽象思辨类
这里包含像:
-
Philosophical Questions(哲学问题)
-
Abstract Conceptual Questions(抽象概念问题)
-
Ambiguous Everyday Questions(模糊日常问题)
-
Analytical & Interpretive Questions(分析解释问题)
-
Speculative & Hypothetical Scenarios(假设场景问题)
比如“生命是什么”“如果空气里氧气翻倍会怎样”“算法内容分发会如何影响公共讨论”等。
4. Alternative Perspectives
就是带立场、多观点的问题。比如:
-
Value-Laden Questions
-
Controversial Questions
也就是不一定有唯一立场,而是可能有多个可辩护视角。
5. Alternative Styles
比如:
-
Alternative Communication Styles
-
Alternative Writing Genres
也就是“同一个内容,用不同风格、不同体裁写出来”。例如写邮件、写 tweet、模仿某种文风。
6. Information-Seeking
这个很有意思。作者认为,很多“信息查询”其实也是开放式的,比如:
-
Problem Solving
-
Decision Support
-
Skill Development
-
Recommendations
-
Concept Explanations
-
Personal Advice
这些并不总有唯一最优答案。比如“学 Python 买什么二手电脑”“给我一个 3 天大阪行程”“如何学会某个技能”,这些都可能有很多合理版本。
实验:
对大模型的单独实验:
作者从 Infinity-Chat 里再挑出一个代表性子集,叫 Infinity-Chat100,也就是 100 个代表性的开放式问题,并用它作为主要评测集。然后他们让许多模型回答这些问题。
实验设置是什么?
对每个模型、对每个 query:
-
生成 50 个回答
-
用高随机性采样设置
-
再比较这些回答彼此有多像。
论文说,他们在整体分析中覆盖了 70+ 个开源和闭源模型,正文重点展示其中 25 个代表模型。
“有多像”怎么量化?
作者不是靠人工肉眼去看“像不像”,而是把每个回答转成句向量 embedding,然后计算这些向量之间的相似度。具体地说,论文写到他们使用了 OpenAI text-embedding-3-small 的 sentence embedding。
你可以把这一步想成:
每个回答都被压缩成一个“语义坐标点”。如果两个回答很接近,就表示它们语义上很像。如果很多回答都挤在一起,就说明模型虽然换了字,但“意思差不多”。
同时对每个模型、每个 query 的 50 个回答,两两比较语义相似度,然后求平均。最后看这些 query 大多落在哪些相似度区间。
论文报告说,在高随机性采样下,79% 的情况下,同一个模型对同一个开放式问题生成的回答平均相似度仍然超过 0.8。同时作者给了一个基线:如果是从全局随机抽两条无关回答,它们几乎都会落在很低的相似区间。
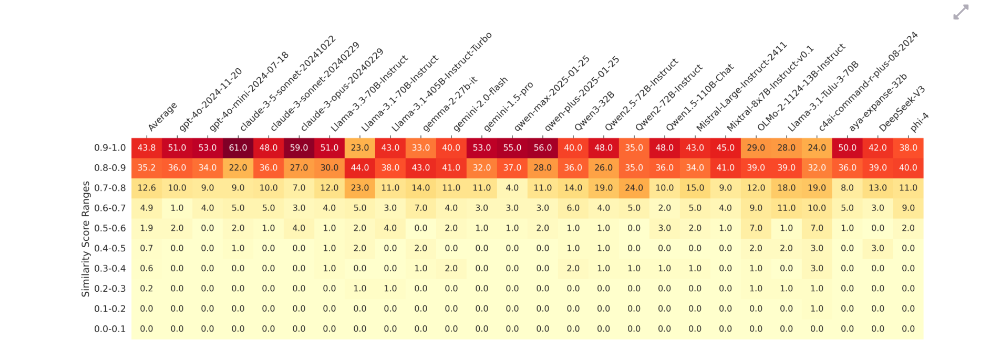
这说明什么?
这说明很多时候:
-
模型不是“真的想到了很多不同的答案”
-
而是“围绕一个核心思路,写出了很多改写版”
像你让同一个人写 50 个广告词,表面上每个都不同,但实际上都绕着两三个套路打转。这就是模型内重复。
作者没有停在“普通采样会重复”。他们进一步测试了一种主打提升多样性的解码方法:min-p decoding。
结果是:
-
它确实能减少最极端的重复
-
但总体上,回答之间仍然常常非常相似
-
也就是说,只靠解码策略,不足以根治模式坍缩。
这一步为什么重要?
因为一个自然反驳会是:
“那就把 temperature 开大一点、换个采样策略,不就行了吗?”
这篇论文的回答大致是:
只能缓解,不能彻底解决。
问题可能不只在采样,而在模型训练、对齐、数据分布、奖励机制这些更深的地方
论文发现,不只是“一个模型自己会重复”,而是不同模型之间也有明显语义重合。作者还给了非常具体的例子:在一个 iPhone 手机壳文案 query 上,不同模型出现了明显重叠的短语;在一个关于“成功、财富、自助”的社媒口号任务上,两个 Qwen API 模型甚至给出了一模一样的句子。
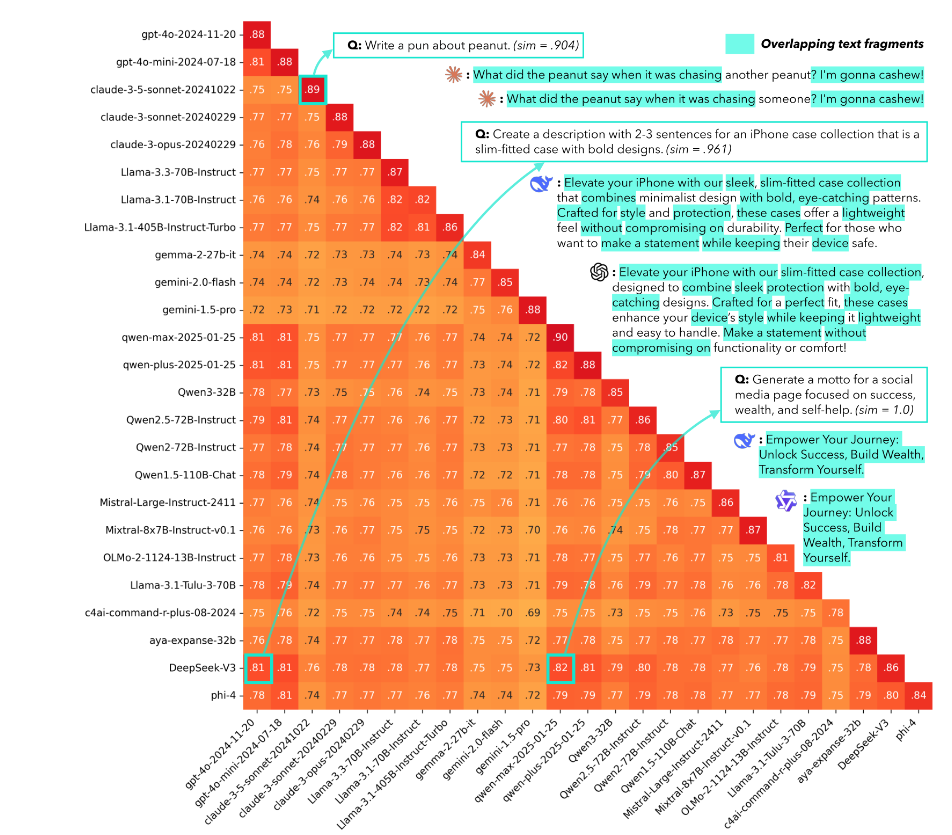
测试大模型能不能理解人类对回答的多元包容性:
Infinity-Chat 不只是一套 query。作者还额外收集了 31,250 条人工标注,并且每个例子有 25 位独立标注者。这点非常重要,因为它让作者不只是看到“平均分”,还能看到“人和人之间到底有多分歧”。
他们收两种标注:
1. Absolute rating(绝对评分)
给单个回答打分,类似 1–5 分。
也就是问:
-
这个回答整体质量怎么样?
2. Pairwise preference(成对偏好)
把两个回答放一起,让人判断:
-
A 更好
-
B 更好
-
或者两者差异不大/偏好很弱
论文里对 pairwise 设置是每个 prompt 采 10 对回答,每个三元组 (query, response1, response2) 收集 25 个标注。
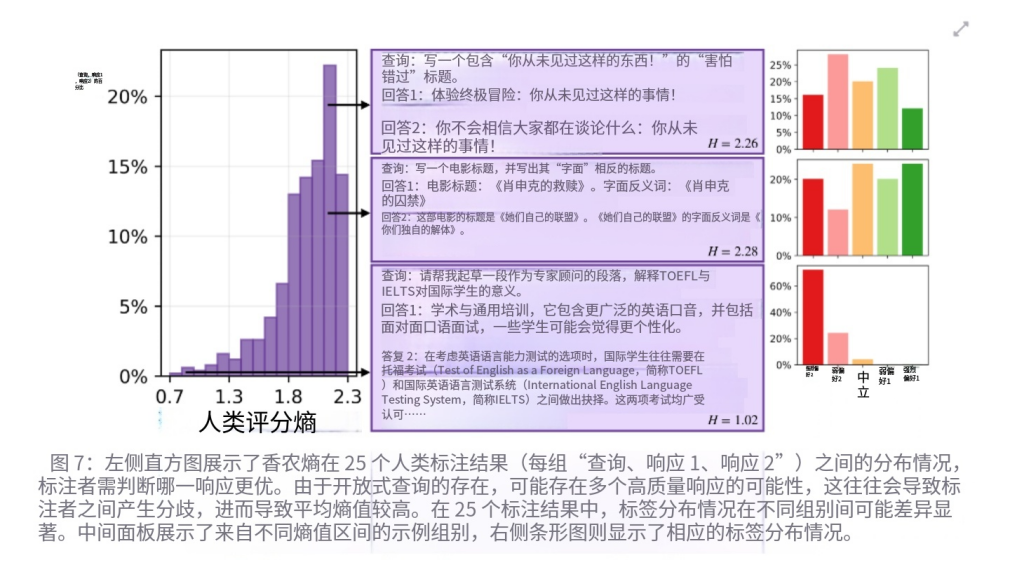
上图看的是成对偏好里的熵
对于一组 (query, 回答A, 回答B),25 个标注者到底一致不一致。论文说,开放式 query 下,很多 triplet 会出现比较高的 Shannon entropy,说明标注者经常分歧很大。
下图绝对评分里的熵。
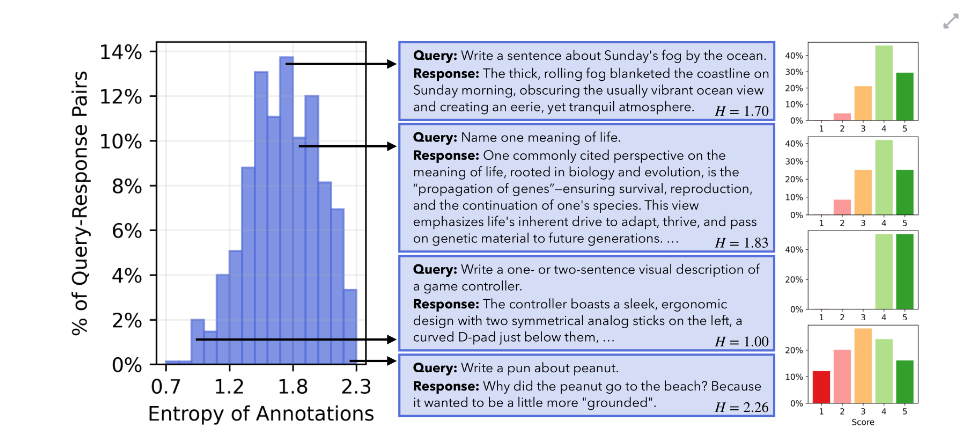
也就是对同一个 (query, response),25 个人打分是否一致。论文同样发现,不同人给分经常差异明显。
你怎么理解“高熵”?
-
低熵:大家意见很统一
比如 25 个人都觉得“A 明显更好” -
高熵:大家意见很分散
比如有人喜欢 A,有人喜欢 B,还有人觉得差不多
在开放式任务里,高熵其实不是坏事,反而说明:
答案空间本来就有多元性,人类偏好本来就不是一个模板。
作者接着测:模型当“评委”时,和人类对得上吗?
论文比较了三类模型评分和人类评分的关系:
1. LM scores
也就是语言模型自己的打分信号,论文这里用的是 perplexity-based score。简单理解成:模型觉得一个回答“顺不顺、像不像它会写出来的东西”。
2. Reward model scores
奖励模型输出的分数。
这类模型一般是在对齐流程中学“哪个回答更优”的。
3. LM judge scores
把大模型本身当裁判,让它去打分或比较两个回答。
然后作者把这些模型分数和人类平均评分做相关性比较。
所以完整流程就是:
第一步:找题
从真实用户 query 里,筛出真正开放式的问题。
第二步:分题型
把开放式 query 归类,证明现实用户问的开放式问题很多样,不只是写诗。
第三步:测生成
让很多模型对这些题反复作答,看:
-
一个模型自己会不会重复
-
不同模型之间会不会撞车
第四步:测偏好
让很多人来打分,再看模型当“裁判”时,能不能理解“多个答案都不错、不同人会喜欢不同答案”这种现实。
结语
如果只用一句话概括这篇论文,我会说:
它讨论的不是大模型会不会替代人类,而是大模型会不会先把人类的表达与想象,悄悄训练成更相似的样子。
这也是我觉得《Artificial Hivemind》值得细读的原因。它把一个关于技术性能的问题,推进成了一个关于创造力、多样性和长期认知风险的问题。未来我们评价大模型,可能不能只问“它是否更强”,还得问一句:它是否也让世界变得更窄。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 15
15 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)