万字拆解 LLM 运行机制:Token、上下文与采样参数
AI 应用开发和 AI Coding 相关的内容目前正在持续更新中:https://javaguide.cn/ai/ 。

大模型(LLM)到底在做什么
一句话理解大模型
当你在输入法里打“今天天气真”,它会自动建议“好”——大模型做的事情本质上一样,只不过它看的不是前面几个字,而是前面几千甚至几十万个字,且每次只“补”一个 Token(文本碎片),然后把刚补的内容也加入上下文,再预测下一个,如此循环,直到生成完整回答。
这个过程叫做自回归生成(Autoregressive Generation)。
理解了这一点,后面所有概念都有了根基:
- Token:模型每一步“补”的那个文本碎片,就是一个 Token。
- 上下文窗口:模型在“补”之前能看到的最大文本量。
- Temperature / Top-p:模型在多个候选碎片中“选哪个”的策略。
- Max Tokens:你允许模型最多“补”多少步。
有了这个心智模型,我们再逐一展开。
全局概念地图
在深入每个概念之前,先看一张完整的调用流程图,帮你在 30 秒内建立全局认知:
用户输入
↓
[Tokenizer] → Token 序列
↓
塞入上下文窗口(System Prompt + User Prompt + 历史 + RAG 片段)
↓ ↑
模型推理(自注意力机制) [Embedding + 向量检索]
↓ 从知识库召回相关片段
logits → [Temperature/Top-p/Top-k] → 采样出下一个 Token
↓
重复直到 EOS 或 Max Tokens
↓
结构化输出解析 & 校验
↓
业务消费
后续每个小节都能在这张图上找到对应位置。
Token:模型的“阅读单位”
你可以把 Token 理解为“模型的阅读单位”。我们人类读中文是一个字一个字地看,读英文是一个词一个词地看;但模型既不按字、也不按词——它用一套自己的“拆字规则”(叫 Tokenizer)把文本切成大小不等的碎片,每个碎片就是一个 Token。
为什么不直接按字或按词切? 因为模型需要在“词表大小”和“序列长度”之间取平衡:
- 如果每个汉字都是一个 Token,词表小、但序列长(模型要“补”更多步);
- 如果每个词都是一个 Token,序列短、但词表会爆炸(中文词组太多了)。
所以实际使用的是一种折中方案——子词切分算法(如 BPE、Unigram),它会把高频词保留为整体,把低频词拆成更小的片段。
💡 一个直觉:你可以把 Token 想象成乐高积木——常用的“积木块”比较大(比如“你好”可能是一个 Token),不常用的词会被拆成更小的基础块拼起来。
Token 不是“一个字”或“一个词”的严格等价物:
- 英文可能一个单词被拆成多个 Token;
- 中文可能一个词被拆成多个 Token,也可能多个字合并成一个 Token(取决于词频与词表)。
因此,工程上通常只用 经验估算 做容量规划,而用 实际 API 返回的 usage(若供应商提供)做精确计费与监控。
经验估算(仅用于粗略规划):
- 英文:1 Token 大约对应 3~4 个字符(与文本类型相关)。
- 中文:1 Token 常见在 1~2 个汉字上下波动(与混排比例强相关)。
以 DeepSeek 官方数据为例:1 个英文字符约消耗 0.3 Token,1 个中文字符约消耗 0.6 Token。换算过来,1 个 Token 约等于 3.3 个英文字符或 1.7 个中文字符,与上述经验值吻合。
💡 成本趋势提示:Token 成本与编码器(Tokenizer)版本强相关。早期模型(如 GPT-3.5)中文压缩率较低(约 1 字 1.5~2 Token)。GPT-4o 使用 o200k_base Tokenizer(词表约 20 万),相比前代 cl100k_base 对中文的压缩率有进一步提升;Qwen2.5 词表约 15 万,对中文常用词同样有优化。实测数据因文本类型而异:新闻类文本约 1.5 字/Token,技术文档约 1.2 字/Token。“趋近 1 字 1 Token”仅适用于高频词汇,不建议作为成本估算基准。在做成本预算时,请务必查阅当前模型版本的官方 Tokenizer 演示,勿沿用旧模型经验。
Token 划分的精细度会直接影响模型的理解能力。特别是在中文处理时,分词歧义(同一字符序列的多种切分方式)和生僻字/低频专业术语的切分粒度,会直接影响模型的语义理解效果。
Token 化过程示例:
- 原文:
你好,我是 Guide。 - 切分:
[你好][,][我是][Guide][。] - 统计:原文 12 字符 → Token 数 5 个 → 压缩比约 2.4 倍
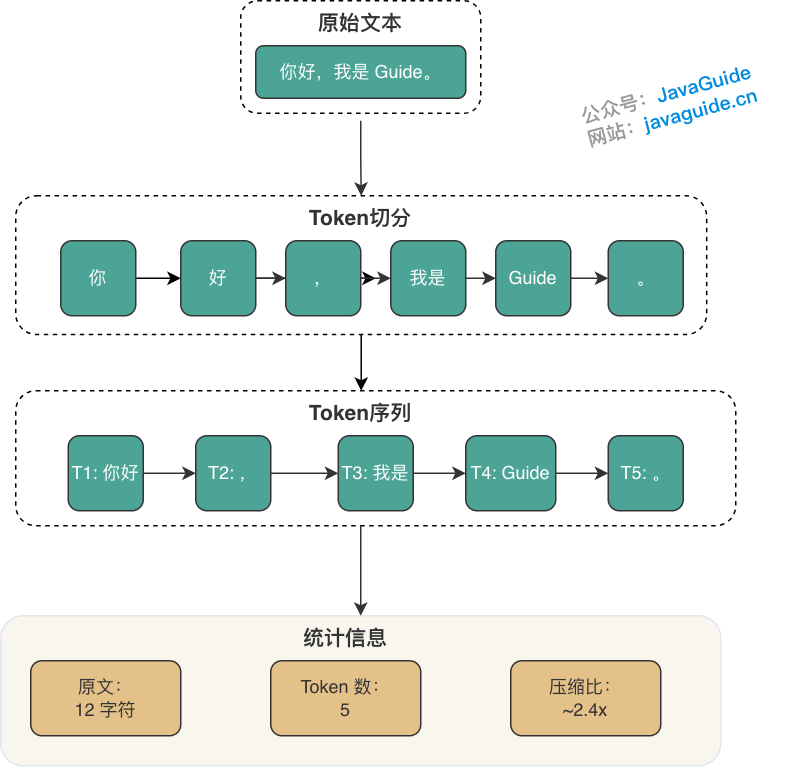
⚠️ 注意:实际的 Token 切分由模型供应商的 Tokenizer 实现,不同供应商对相同文本可能产生不同的 Token 序列。生产环境中应使用对应供应商的 Tokenizer 工具进行精确计数。
特殊 Token:除了文本内容对应的 Token,模型内部还会使用一些特殊标记,这些也会计入 Token 总数:
| 特殊 Token | 用途 | 示例 |
|---|---|---|
| BOS(Beginning of Sequence) | 标记序列开始 | <s> |
| EOS(End of Sequence) | 标记序列结束 | </s> |
| PAD(Padding) | 批处理时填充短序列 | <pad> |
| 工具调用标记 | Function Calling 场景的边界标记 | <tool_call/> |
这些特殊 Token 通常对用户不可见,但会占用上下文窗口。在精确计数时,建议使用官方 Tokenizer 工具而非手动估算。
多模态 Token:图片也会消耗 Token
GPT-4o、Claude 3.5、Gemini 等模型已支持图片输入。图片不是“零成本”的——它会被转换成一批 Token,同样占用上下文窗口。
粗略估算规则:
| 模型 | 图片 Token 计算方式 | 一张 1024×1024 图片约等于 |
|---|---|---|
| GPT-4o | 按分辨率 + 细节模式 | 低细节 ~85 tokens,高细节 1105765 tokens(取决于裁剪) |
| Claude 3.5 | 固定 ~5 tokens(缩略图)或 ~85 tokens(全图) | 取决于图片模式 |
| Gemini | 按分辨率计算 | ~258 tokens(标准) |
工程启示:
- 做多模态 RAG 时,要把图片 Token 也纳入预算
- 批量处理图片时,注意首字延迟(TTFT)会显著增加
- 如果只需要 OCR,考虑先用专门的 OCR 服务提取文字,再以纯文本形式送入模型
⭐上下文窗口(Context Window)
上下文窗口(或称“上下文长度”)是 LLM 的“工作记忆”(Working Memory)。它决定了模型在任何时刻可以处理或“记住”的文本量(以 Token 为单位)。
- 对话连续性:它决定了模型能进行多长的多轮对话而不遗忘早期细节。
- 单次处理能力:它决定了模型一次性能够处理的最大文档、代码库或数据样本的大小。
“模型支持 128K/200K/1M”指的是 一次调用里能放进模型的总 Token 上限。大多数模型的上下文窗口包含输入与输出的总和,但部分供应商(如 Google Gemini)对输入和输出分别设限,请查阅具体 API 文档。此外,上下文窗口往往被隐形成本占用:
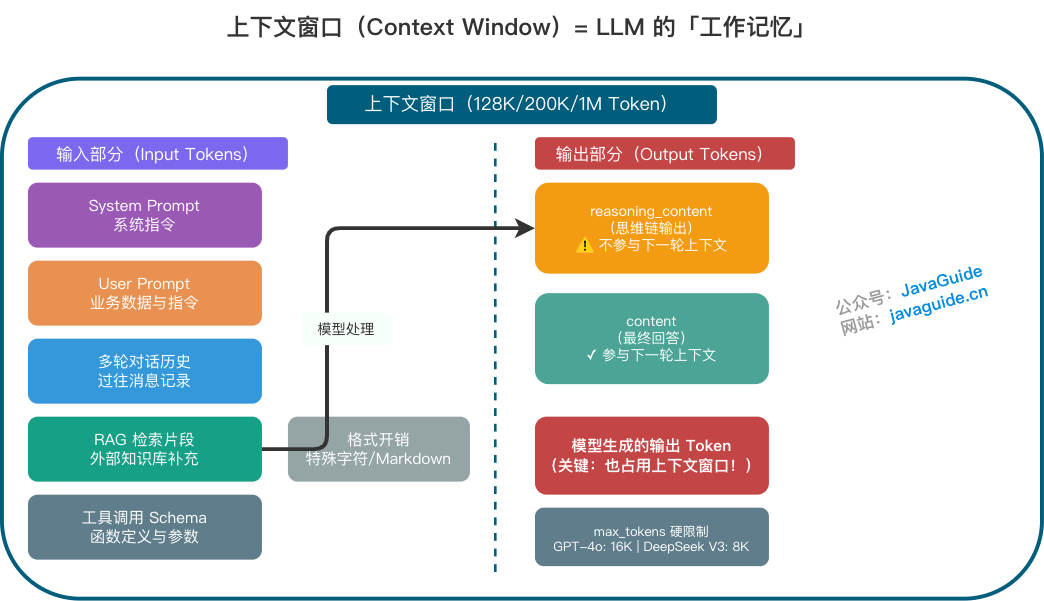
- System Prompt:调节模型行为的系统指令(通常对用户隐藏,但占用窗口)。
- User Prompt:业务数据与指令。
- 多轮对话历史:过往的消息记录。
- RAG 检索片段:从外部知识库检索到的补充信息。
- 工具调用 Schema:函数定义与参数结构。
- 格式开销:特殊字符、换行符、Markdown 标记等。
- 模型生成的输出 Token:(关键) 输出也占用上下文窗口。
因此,你真正能塞进 Prompt 的“有效业务内容”往往远小于标称上限。
⚠️ 注意输出硬限制:上下文窗口(Context Window)≠ 最大生成长度。许多模型支持 128K 甚至 1M 输入,但单次输出上限因 API 而异:OpenAI Chat Completions API 使用 max_tokens 参数(GPT-4o 最大 16K 输出),部分新模型支持 max_completion_tokens(如 o1 系列),DeepSeek V3 最大输出 8K。使用前需查阅具体模型的 API 文档。
思维链模式的多轮对话处理:在多轮对话场景中,思维链模型(如 DeepSeek-R1)的 reasoning_content(思考过程)通常不会被自动包含在下一轮对话的上下文中。只有 content(最终回答)会参与后续对话。这意味着:
- 你无需为思考过程额外占用上下文窗口。
- 但如果后续对话需要参考之前的推理过程,需要手动将
reasoning_content拼接到消息历史中。 - 部分供应商的 SDK 会自动处理这一差异,建议查阅具体文档确认行为。
⭐上下文窗口为什么会有上限?
上下文窗口并非越大越好,它受限于 Transformer 架构的自注意力机制(Self-Attention):
- 计算成本平方级增长:计算需求与序列长度呈平方级关系(O(N²))。输入 Token 翻倍,处理能力需求可能变为 4 倍。这意味着更长的上下文 = 更高的成本 + 更慢的推理速度。
- 推理延迟增加:随着上下文变长,模型生成每个新 Token 时需要关注的所有历史 Token 变多,导致输出速度逐渐变慢(尤其是首字延迟 TTFT 会显著增加)。
- 安全风险增加:更长的上下文意味着更大的攻击面,模型可能更容易受到对抗性提示“越狱”攻击的影响。
工程优化手段:实践中,FlashAttention(IO-aware 精确注意力)、GQA/MQA(分组/多查询注意力)、Sliding Window Attention(如 Mistral)、Ring Attention 等技术已显著降低长上下文的实际计算和显存开销。但 O(N²) 的理论复杂度仍是上限扩展的根本瓶颈。
上下文溢出的真实表现
当上下文接近上限或内容过长时,常见现象包括:
- 模型忽略早期约束:System Prompt 里要求“必须输出 JSON”,但因距离生成点太远,注意力不足导致被忽略。缓解策略:将关键约束在 User Prompt 末尾重复强调,或使用 Structured Outputs 的 Strict Mode 从解码层面强制约束。
- “中间丢失”现象(Lost in the Middle)(Liu et al., 2023):即使在 1M 窗口模型中,模型对开头和结尾的信息最敏感,对中间部分的信息召回率显著下降。
- 回答漂移:前半段还围绕问题,后半段开始总结/扩写/跑题。
- RAG 失效:检索文档过多,关键信息被稀释;或被截断导致证据链断裂。
- 成本与延迟激增:1M 上下文会导致首字延迟(TTFT)显著增加,且 Token 成本呈线性增长。
在本项目里,你能看到两个典型的“上下文控制”手段:
- 智能截断:不要简单粗暴地截断字符串。例如把简历内容做 摘要提取 或 关键信息抽取,避免把长文本原封不动塞进评估 prompt。
- 分批处理和二次汇总:长面试评估按 batch 分段评估,再做二次汇总,避免单次调用 Token 过大。
即使拥有 1M 窗口,也建议设置 软性预算上限(如 128K)。除非必要,否则不要全量输入,以平衡成本、延迟与准确性。
计费差异:输入 Token ≠ 输出 Token
大多数供应商对输入 Token和输出 Token采用不同的计费标准,通常输出价格是输入的 2~4 倍:
| 模型 | 输入价格(/1M Tokens) | 输出价格(/1M Tokens) | 输出/输入比 |
|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | 4x |
| Claude 3.5 Sonnet | $3.00 | $15.00 | 5x |
| DeepSeek V3 | ¥0.5 | ¥2.0 | 4x |
| DeepSeek-R1 | ¥4.0 | ¥16.0 | 4x |
工程启示:
- 长 Prompt + 短输出 = 更经济的调用方式
- RAG 场景要控制检索片段数量,避免输入 Token 激增
- 思维链模型的 reasoning tokens 通常按输出价格计费,成本更高
Prompt Caching:重复前缀的成本救星
当你的请求中存在大量重复的固定前缀(如 System Prompt、长 RAG Context),可以用 Prompt Caching(提示词缓存)显著降低成本。
原理:供应商会缓存你请求中“可复用的前缀部分”。下次请求如果前缀相同,这部分就不重新计费,只收“缓存读取”的费用(通常是正常价格的 10%~50%)。
典型适用场景:
- 多轮对话(System Prompt + 历史 Message 不变)
- RAG 应用(检索片段重复率高)
- 批量评估(同一份 System Prompt,不同的简历/文章)
各供应商支持情况:
| 供应商 | 功能名称 | 缓存时长 | 缓存命中折扣 |
|---|---|---|---|
| OpenAI | Prompt Caching | 5~10 分钟 | 输入价格约 50% |
| Anthropic | Prompt Caching | 5 分钟 | 输入价格约 10% |
| DeepSeek | Context Caching | 10~30 分钟 | 输入价格约 25% |
工程建议:
- 把不变的内容放前面(System Prompt、工具定义、RAG Context),把变化的内容放后面(User Prompt)
- 监控
cache_read_tokens和cache_creation_tokens指标,验证缓存命中率 - 批量任务尽量在缓存时间窗口内完成
即使拥有 1M 窗口,也建议设置 软性预算上限(如 128K)。除非必要,否则不要全量输入,以平衡成本、延迟与准确性。
一次调用的 Token 预算怎么做
把“上下文窗口”当成一个固定容量的桶,下图展示了一个典型调用的 Token 预算分配:
38%31%13%9%9%"16K 上下文窗口典型分配(结构化输出场景)"User Prompt(业务数据)输出预留(Max Tokens)历史消息(多轮对话)System Prompt(含 Schema)安全边际(供应商开销)
此分配仅为示意,实际比例需根据业务场景动态调整。
最实用的预算方式是:
window ≥ input_tokens + max_output_tokens
对于思维链模型,公式应调整为:
window ≥ input_tokens + reasoning_tokens + max_output_tokens
其中 reasoning_tokens(思考链 Token 数)难以精确预估,建议按 max_output_tokens 的 2~3 倍预留。
其中 input_tokens 至少包含:
- system prompt(含 schema / 工具定义)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)