深度学习] 大模型学习7-多模态大模型全景解析
多模态(Multimodality)是指融合并处理两种或两种以上类型信息或数据的方法与技术。在机器学习和人工智能领域,常见的数据类型包括文本、图像、视频、音频及传感器数据等。多模态系统旨在利用多种模态的信息,以提升任务性能、丰富用户体验,或实现更全面的数据分析。
事实上,人类在感知世界时总是依赖多种信息通道:看书时处理文字,遇到红灯时依赖视觉信号,听到警报声时依赖听觉。而过去的AI能力相对单一,更类似于单模态系统。例如,GPT-3仅支持文本输入,不具备原生视觉理解能力;ImageNet模型只能识别图像,如果问它这张图表达了什么情绪或趣味,它只能机械地输出标签和概率。多模态AI能实时融合文本、图像、视频、音频和传感器数据,能够像人一样理解场景、解读情绪并预测行为,让机器对复杂世界的感知更自然、更智能。
近年来,人工智能技术发展逐步迈入以多模态融合为核心的新阶段。大语言模型(Large Language Model,LLM)在自然语言处理领域取得突破性进展,研究重心也从单一模态智能转向能够同时理解和生成文本、图像、音频、视频等多种信息形式的统一模型。在这一背景下,多模态大语言模型(Multimodal Large Language Model,MLLM)成为人工智能的重要研究方向,并在智能交互、内容生成及复杂决策等任务中展现出巨大潜力。
目前,MLLM已能够处理图像、声音和文字,实现看、听、读的多模态感知。它能够将这些信息关联起来,完成跨模态关联的任务,如音视频联动分析、场景理解和图文内容描述。然而,现有模型距离真正理解人类世界仍有差距:它可以看到红烧肉的照片、读到菜谱、听到烹饪声音,却无法感受其味道,也缺乏真实的情感体验和生活经验。未来的MLLM需要逐步融合味觉、嗅觉、触觉等更多感官维度,同时提升对情感与经验的理解,才能更接近人类认识世界的方式。
目录
1 多模态大语言模型的发展与技术演进
1.1 多模态大语言模型简介
多模态技术的发展经历了长期探索与积累。早期具有代表性的工作是2021年提出的CLIP(Contrastive Language–Image Pre-Training)。该模型通过大规模图文对比学习,实现视觉与语言表示空间的有效对齐,为跨模态特征对齐与联合表示学习提供了关键技术支撑,典型应用包括图文检索、零样本分类等。然而,这一阶段的模型仍以特定任务为导向,缺乏统一的推理能力和通用泛化能力。
自2022年起,LLM的快速发展为多模态研究带来了新的技术范式。以GPT-3(Generative Pre-trained Transformer)和LLaMA(Large Language Model Meta AI)为代表的模型展现出强大的语言理解、推理和对话能力,使研究者开始探索以LLM作为通用智能系统核心的可能性。通过引入视觉编码器等模块,将图像等非语言模态映射到语言语义空间,从而构建具备视觉理解能力的多模态系统。
进入2023年,随着LLM能力的持续提升,多模态研究逐渐进入以MLLM为核心的发展阶段。该阶段的模型通常以强大的LLM为中心,通过视觉、音频等编码器扩展输入模态,使模型能够在统一框架下完成多模态理解与生成任务。代表性模型包括GPT-4V,其支持图像与文本的联合输入,展现出卓越的视觉理解与推理能力。关于MLLM的更多基础原理介绍,可参考:Multimodal LLMs Basics。
同时,开源模型如LLaVA(Large Language and Vision Assistant)和Qwen-VL系列通过引入指令微调(Instruction Tuning)机制,大幅降低多模态模型的训练与部署门槛,使模型能够更自然地理解人类指令并执行复杂任务。2024年发布的GPT-4o进一步实现了文本、图像、音频与视频等多模态的实时协同处理,标志着多模态交互向实时化迈进。
进入2025年,MLLM的发展从统一能力阶段迈向全模态智能阶段。这一年涌现出多个具有代表性的工作,其中阿里巴巴发布的Qwen3-Omni备受关注。该模型在单一原生架构中实现文本、图像、音频与视频等多模态的统一建模,并支持实时语音交互与跨模态推理,在多模态理解与生成性能方面达到领先水平。
构建多模态模型的核心问题在于如何实现有效的模态融合。早期方法多采用简单融合策略,如点乘或拼接:即分别通过NLP与视觉预训练模型获得文本和图像的嵌入表示后直接组合。这类方法实现成本低,但由于缺乏跨模态的深层交互建模,难以充分挖掘不同模态之间的语义关联。为弥补这一不足,研究逐步转向基于Transformer的交叉融合方法。该类方法通过注意力机制在统一框架中建模图文特征之间的交互关系,从而显著提升多模态表示的表达能力,已成为当前主流范式。
在融合能力不断增强的同时,一个关键现象是,这类模型仍然被称为语言模型。这源于其整体架构仍以语言模型为核心,即在保留原有语言理解与生成能力的基础上,将视觉、音频等模态纳入统一建模框架。非文本模态首先通过各自编码器转换为与语言空间对齐的表示,随后与文本共同输入语言模型,参与统一的上下文建模与自回归生成过程。因此,模型虽具备多模态输入与输出能力,但其推理与交互机制本质上仍围绕语言展开。
由此可以理解,目前所谓多模态大模型,本质上是以语言模型为核心扩展得到的MLLM,其理解、推理与生成主要发生在语言空间之中,而多模态能力则来源于对非文本信息的映射与对齐。沿着这一发展路径,未来的研究可能进一步突破以语言为中心的建模方式,探索更原生的跨模态统一表示与推理机制,以构建更加灵活、高效且具备更强通用性的多模态智能系统。
在此语境下,模态指MLLM的输入形式及表征来源。文本模态仍为核心,承担主要的语义理解与推理任务。其他主要模态包括:视觉模态(图像与视频,应用最广)、音频模态(语音、音乐及各类声音事件)、动作模态(用于具身智能与机器人系统),以及面向专业应用的三维表示、热成像、图表等多样化模态。在多模态场景中,任务通常分为理解任务和生成任务:前者以多模态数据为输入输出文本信息,后者以多模态数据为输入生成多模态数据,且通常更复杂、难以建模。
接下来,后面内容将对本节提到的MLLM建模方法进行详细介绍。关于相关MLLM架构的演进详情,可参阅:多模态大模型主流架构介绍。
1.2 模态融合的奠基阶段
MLLM的发展源于深度学习在自然语言处理与计算机视觉领域的独立突破。2017年提出的Transformer架构凭借强大的并行计算能力和长距离依赖建模能力,重塑了自然语言处理的技术范式,并迅速被研究者扩展至跨模态任务,开启了MLLM的早期探索阶段。此阶段的核心问题在于如何将Transformer的语言理解能力与视觉特征进行有效融合。
2020年提出的Vision Transformer进一步推动了视觉模型与语言模型在结构上的统一,为跨模态融合奠定了重要基础。该时期主流的视觉-语言模型通常采用双流架构,即为图像和文本分别构建独立的Transformer编码器,在充分学习各自模态特征后,再进行跨模态交互。相关模型的介绍见:多模态技术梳理:ViT系列。
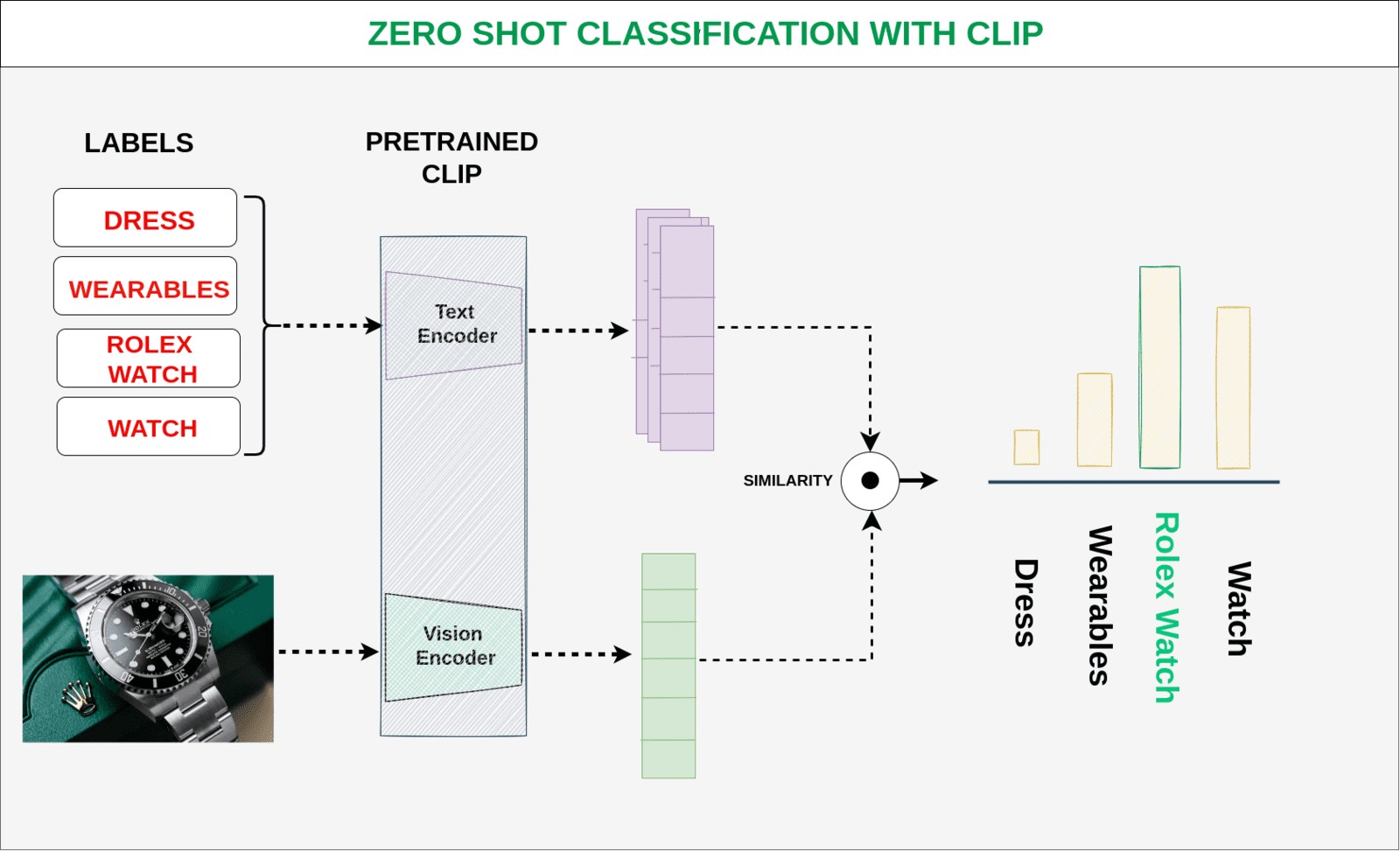
2021年初,OpenAI提出的CLIP模型在多模态研究中产生了深远影响。CLIP利用约4亿规模的图文对数据,通过对比学习构建统一的跨模态语义嵌入空间。模型由独立的图像编码器和文本编码器组成。在训练过程中,对于一个批次中的N组图文对,目标是最大化正确图文对的特征相似度,同时最小化其余N²−N组非匹配对的相似度,从而实现视觉特征与自然语言语义的深度对齐。换言之,在包含N张图像与N条文本描述的批次中,模型需要在N²种可能的配对关系中识别出真正匹配的N对。
更形象地说,CLIP进行类似连连看的训练:如果把一张狗的图片与描述猫的文字配对,就会受到惩罚;反之,匹配正确则获得奖励。经过4亿个图文对的训练,模型逐渐理解了长着耳朵、四条腿、会奔跑的动物叫狗,从而实现图像世界与文字世界的深度对齐。
CLIP的重要意义不仅在于证明了大规模弱监督对比学习能够有效实现跨模态对齐,更在于其展现出的跨任务零样本泛化能力。由于视觉概念与自然语言语义直接关联,模型无需额外微调即可执行新的视觉任务。例如,只需提供飞机或猫等文本描述作为类别提示,模型即可完成图像分类。这种摆脱任务特定数据集依赖的能力,结合高效的推理速度和良好的泛化性,使CLIP成为互联网图像理解系统的重要基础模型。
即使在近期研究中,CLIP仍然具有重要影响。例如,同济大学团队提出的LLM2CLIP方法获得AAAI 2026杰出论文奖。该研究将LLM的语义理解能力引入CLIP框架,使模型能够更好地处理复杂和长文本描述,进一步提升跨模态语义理解能力。
尽管CLIP是多模态研究的重要里程碑,但其局限也十分显著:它仅支持判别式任务,如图文匹配与图像分类,并不具备生成能力;其对比学习侧重全局语义对齐,缺乏对局部特征与文本片段的细粒度建模,因此难以应对视觉定位等精细跨模态任务。如何从全局语义对齐进一步发展到细粒度跨模态交互,成为后CLIP时代的重要研究方向。
1.3 LLM主导多模态时代
在ChatGPT于2022年末发布之后,LLM展现出强大的零样本学习、指令理解和上下文推理能力,推动了人工智能领域的深刻变革。多模态研究迅速抓住这一机遇,研究重点从设计复杂的跨模态系统,转向将现有的LLM应用于图像、视频等多模态信息处理。这一阶段的显著特征是:LLM成为多模态智能的核心,多模态指令微调成为主流方法,通过教会LLM理解视觉信息来扩展多模态任务,而无需从零构建复杂模型。关于相关模型的详细介绍见:多模态大模型技术报告。
1.3.1 早期探索
早期,研究者尝试了“外部专家集成”架构:以LLM为调度中心,调用各类单模态专家模型完成协作任务。代表性工作包括2023年的Visual ChatGPT和HuggingGPT。这类方法能够快速落地并复用高质量单模态专家模型,但在深层次的多模态融合能力上存在局限,因此在许多任务中逐渐被端到端一体化建模方法取代。不过,工具调用与专家集成的理念并未消失,而是以插件或功能接口等形式持续存在于现代多模态系统中。
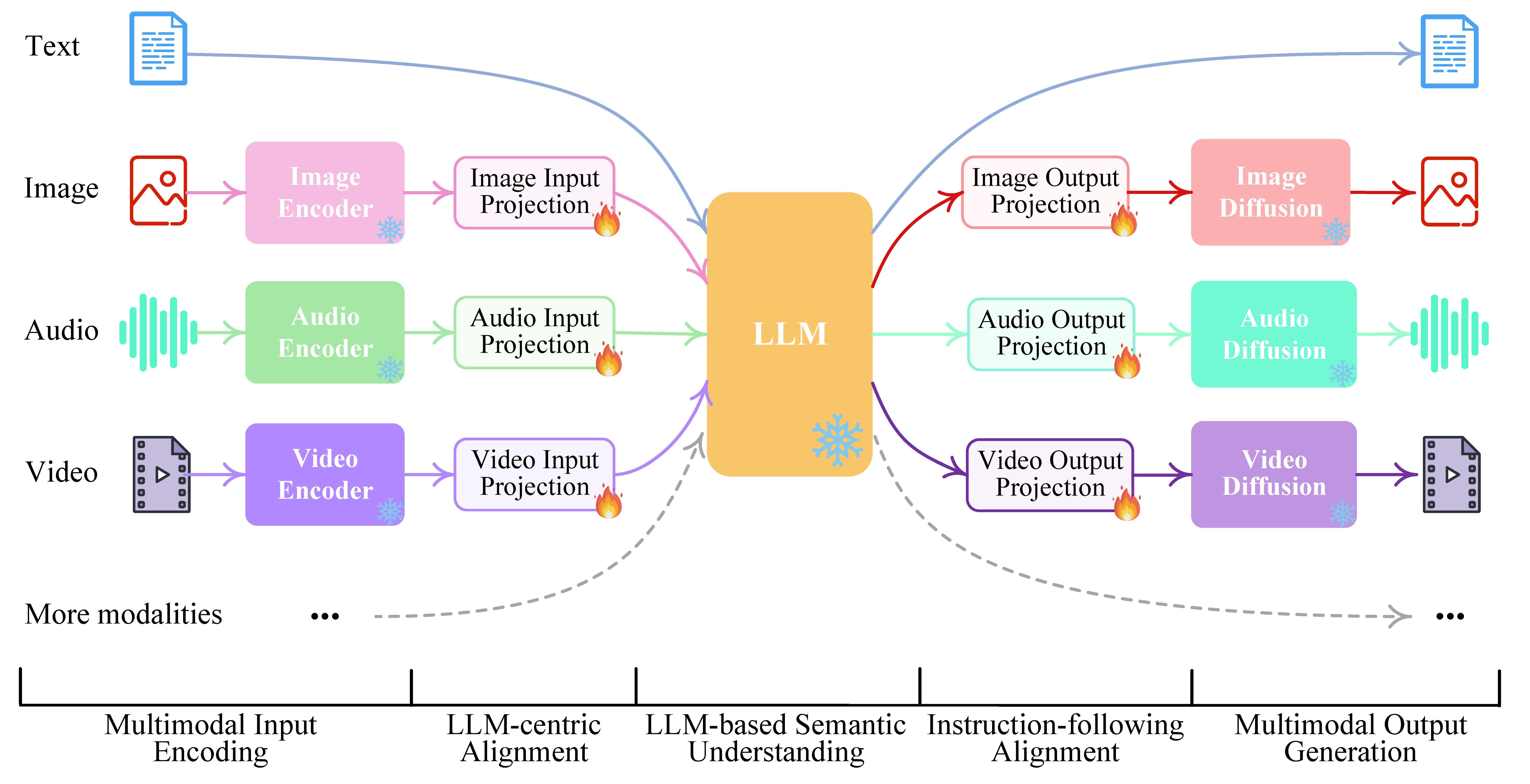
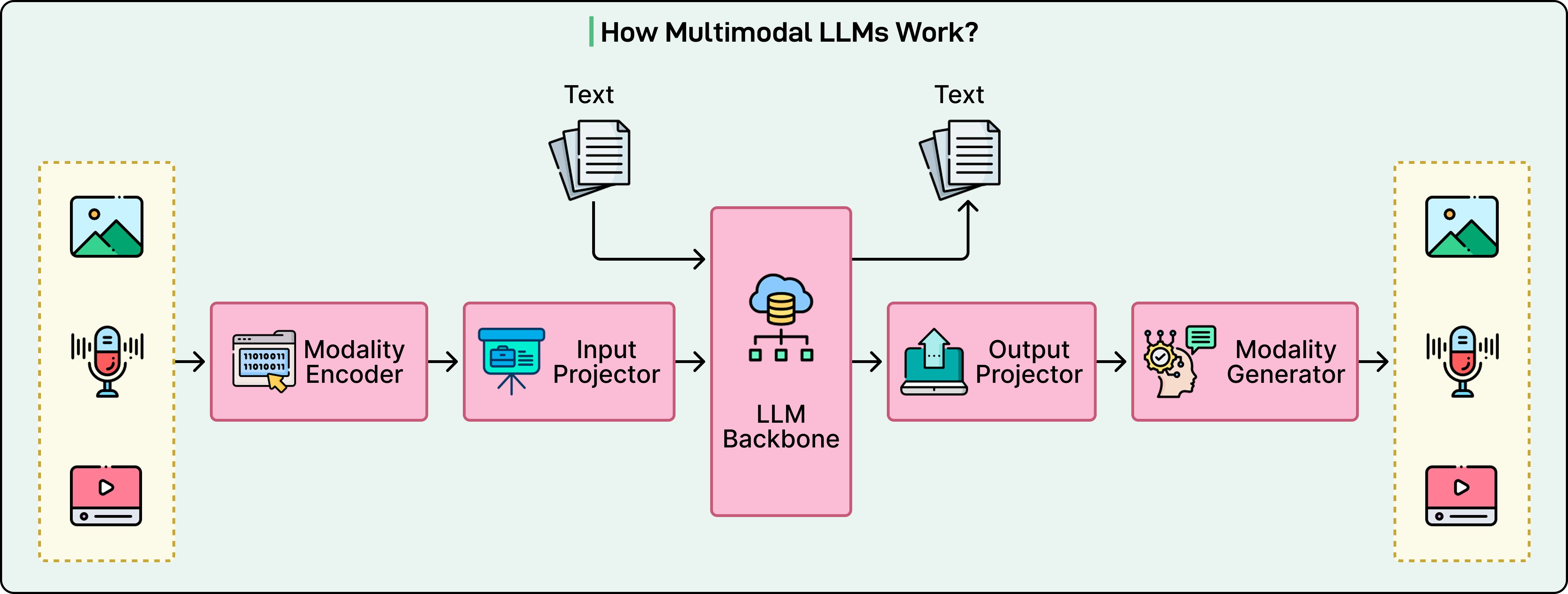
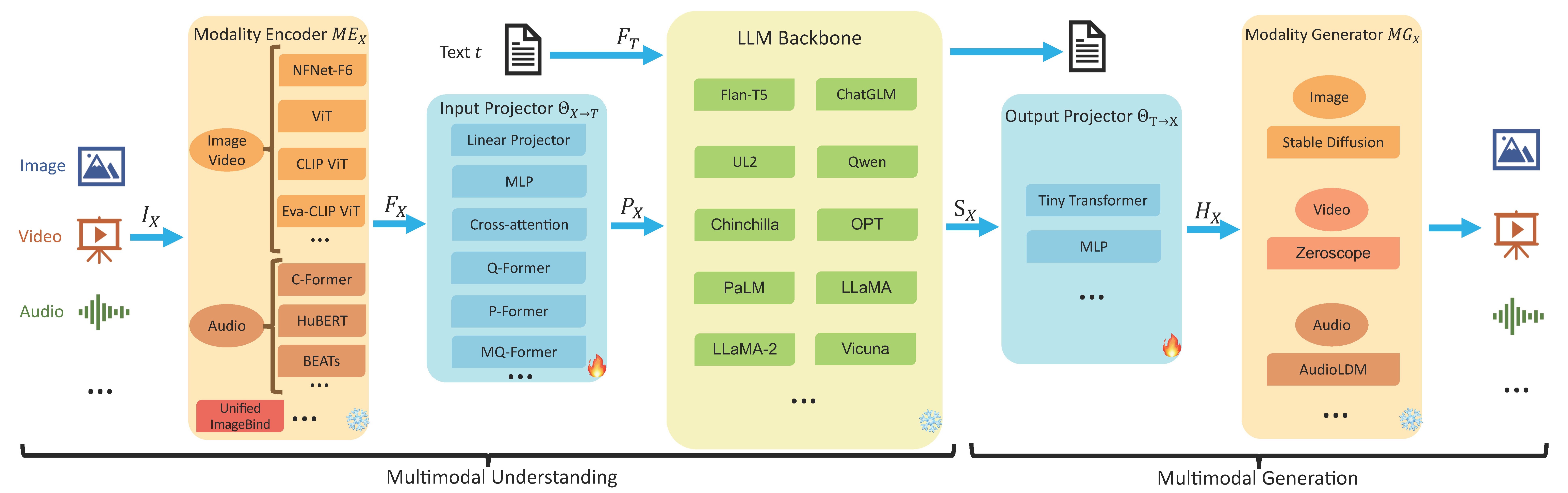
当前,大多数主流MLLM可以抽象为三位一体的架构,类似于一套完整的感知与认知系统。以视觉语言模型为例,该架构主要包含三部分:
- 视觉编码器:相当于系统的感知前端,将输入图像转化为具有语义信息的特征表示。扩展到视频时,通常需引入时序建模机制。
- LLM:系统的认知中枢,负责语义理解、推理与文本生成。
- 连接器:桥梁组件,将视觉特征映射到语言模型的表示空间,实现不同模态间的对齐与信息交互。
在模型推理过程中,视觉编码器将图像编码为包含丰富信息的特征序列后,连接器将这些特征映射到语言模型的表示空间,并与问题或提示文本序列结合,形成多模态输入。随后,LLM的自回归生成机制启动,其本质与纯文本生成相同:模型根据当前全部上下文(包括视觉特征和已生成文本)预测下一个最可能的词元。
生成过程类似滚雪球迭代:
- 模型根据视觉序列和问题序列预测第一个答案词元,例如“狗”。
- 将“狗”追加到输入序列末尾,形成新的上下文。
- 模型再根据视觉序列、问题序列和已生成词元预测下一个词元,例如“正在”。
- 继续迭代,直到生成特殊终止符
<EOS>或达到最大长度限制。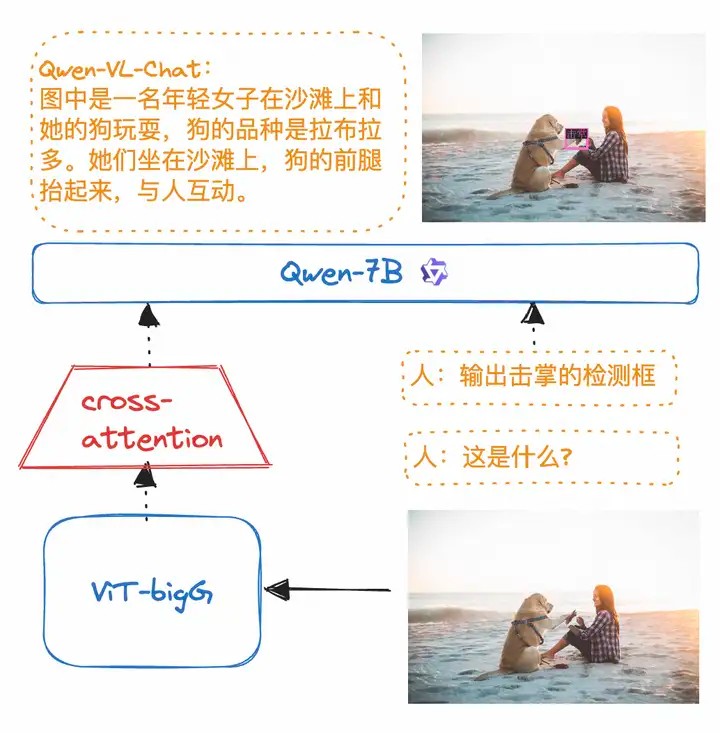
1.3.2 深层融合
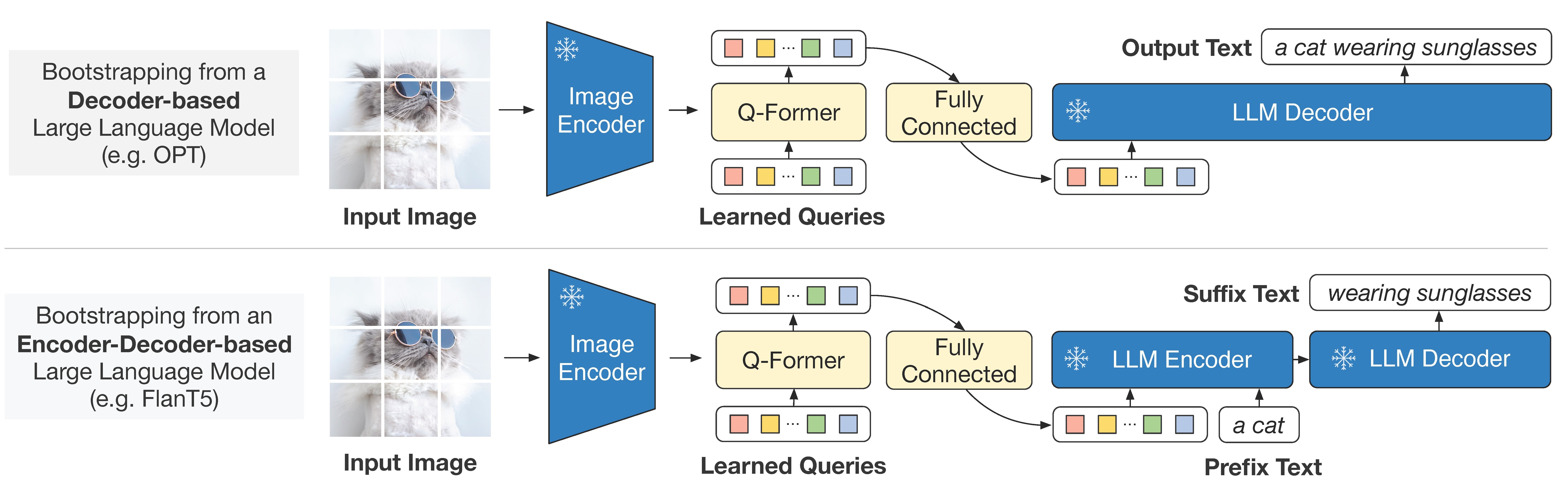
在向更深层融合演进的技术路线上,BLIP系列研究发挥了关键作用。BLIP首次系统性解决了图文数据中的对齐噪声问题,为视觉语言预训练提供了高质量的数据基础。2023年提出的BLIP-2引入轻量级Q-Former模块,作为图像编码器与LLM之间的桥梁,将视觉特征转化为LLM可理解的语义向量。这种通过可学习查询向量压缩视觉特征的设计,成为模块化联合建模的早期典范。
借助Q-Former,BLIP-2能够响应自然语言指令生成图像描述,支持视觉知识推理、常识推理和视觉对话等任务,同时兼容两类主流LLM架构:
- Decoder-only架构:冻结图像编码器和LLM,将图像特征经Q-Former转化为视觉提示特征后,直接输入LLM进行自回归生成。
- Encoder-Decoder架构:将文本划分为前缀和后缀,前缀文本与Q-Former输出的视觉特征共同输入编码器,解码器据此生成后缀文本。
尽管Q-Former在现阶段显得冗余且性能有限,但其跨模态对齐思路仍具参考价值。后续主流模型在此基础上将Q-Former简化为MLP映射层并转向Decoder-only架构,或者摒弃外挂式视觉编码器,将不同模态数据编码为同构token序列输入同一网络,实现端到端联合预训练。
人工智能面临的一个核心挑战是:如何让模型不仅理解文本,还能理解图像,并用自然语言与人类交互。为此,2023年4月,LLaVA(Large Language and Vision Assistant)提出高效的多模态训练方法,将LLM指令微调首次引入视觉-语言任务,使MLLM模型通过指令学习理解图像内容并生成符合人类期望的回答。关于LLaVA的详细介绍,可参考:一篇文章搞懂LLaVA。
为训练模型,LLaVA团队构建了LLaVA-Instruct-158K数据集。该数据集以COCO图像标注为基础,通过GPT-4将其转化为多轮对话形式的指令数据。例如,对于一张描绘小猫蜷在沙发上看窗外的图片,GPT-4不仅提问“图中有什么”,还进一步追问“小猫在看什么、窗外可能有什么、它的状态如何”。这种设计模拟了人类观察图片时的自然好奇心,为模型提供丰富多样的指令信号。
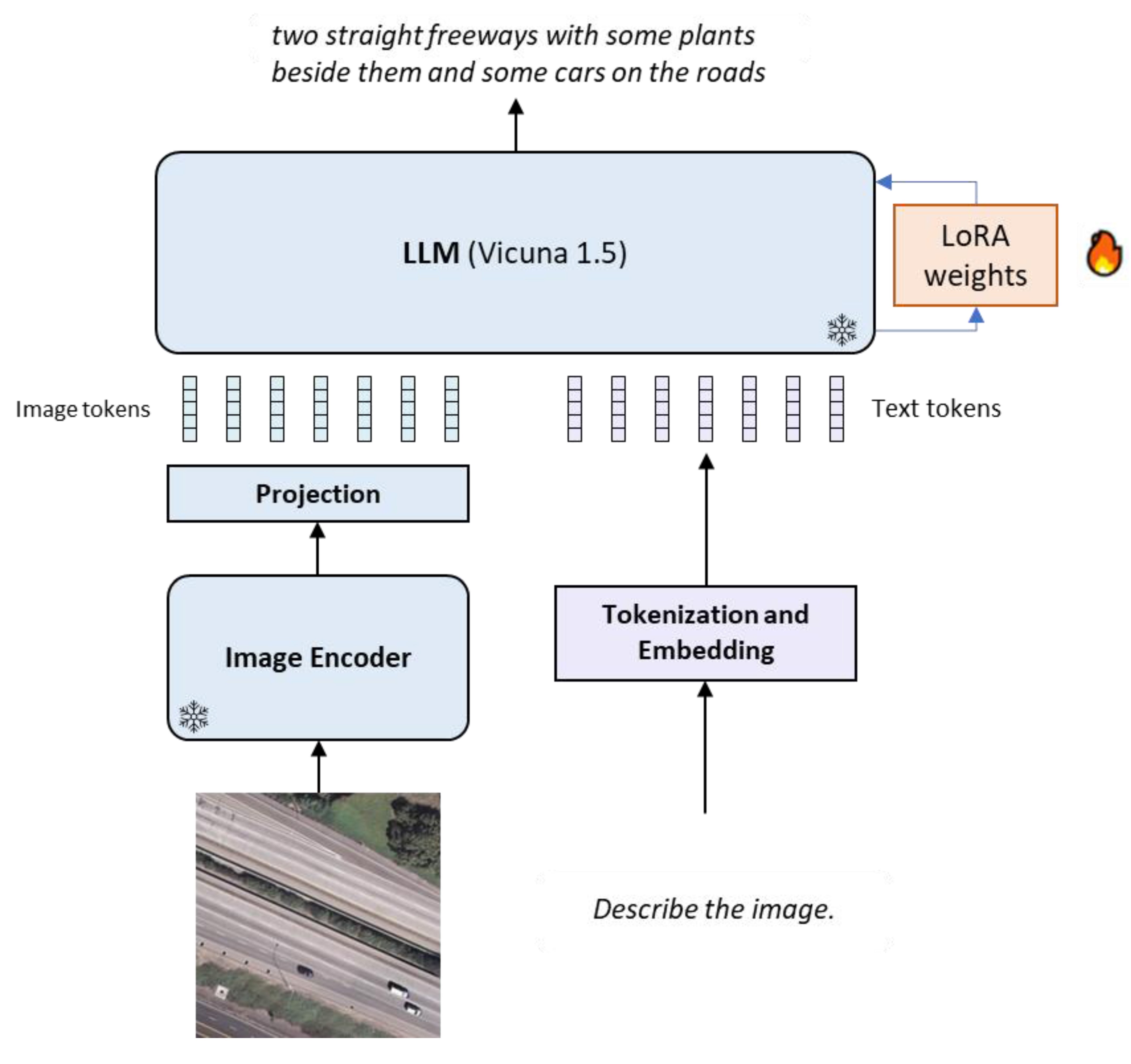
在模型架构上,LLaVA以Vicuna作为语言核心模型,其由LLaMA微调得到。图像特征首先由CLIP提取,经投影层映射至与文本特征一致的表示空间,随后与文本token拼接为统一序列,并输入Vicuna进行处理。训练分两步进行:
- 特征对齐阶段:冻结语言模型和视觉编码器,仅训练投影层,使视觉特征与文本嵌入对齐。
- 端到端微调阶段:冻结视觉编码器,联合微调投影层和语言模型,利用多轮指令数据,使模型能够流畅理解图像并进行多轮交互。
通过指令微调,LLaVA使LLM具备图像描述与视觉问答等多模态能力,以较低成本拓展了LLM的视觉交互边界。受此启发,InstructBLIP、MiniGPT-4等研究相继涌现,推动多模态指令微调技术持续发展与成熟。
1.4 多模态理解与生成的统一突破
1.4.1 理解与生成的融合突破
随着多模态指令微调技术的成熟,自2024年起,MLLM的研究重心已转向在单一模型中统一理解与生成任务。为突破任务壁垒,构建兼具感知、理解与生成能力的统一模型,业界主要探索了三大方向:早期融合架构、混合生成范式以及全模态统一模型。
这些探索催生了多款代表性模型,展示了多模态统一的不同技术路径。例如:
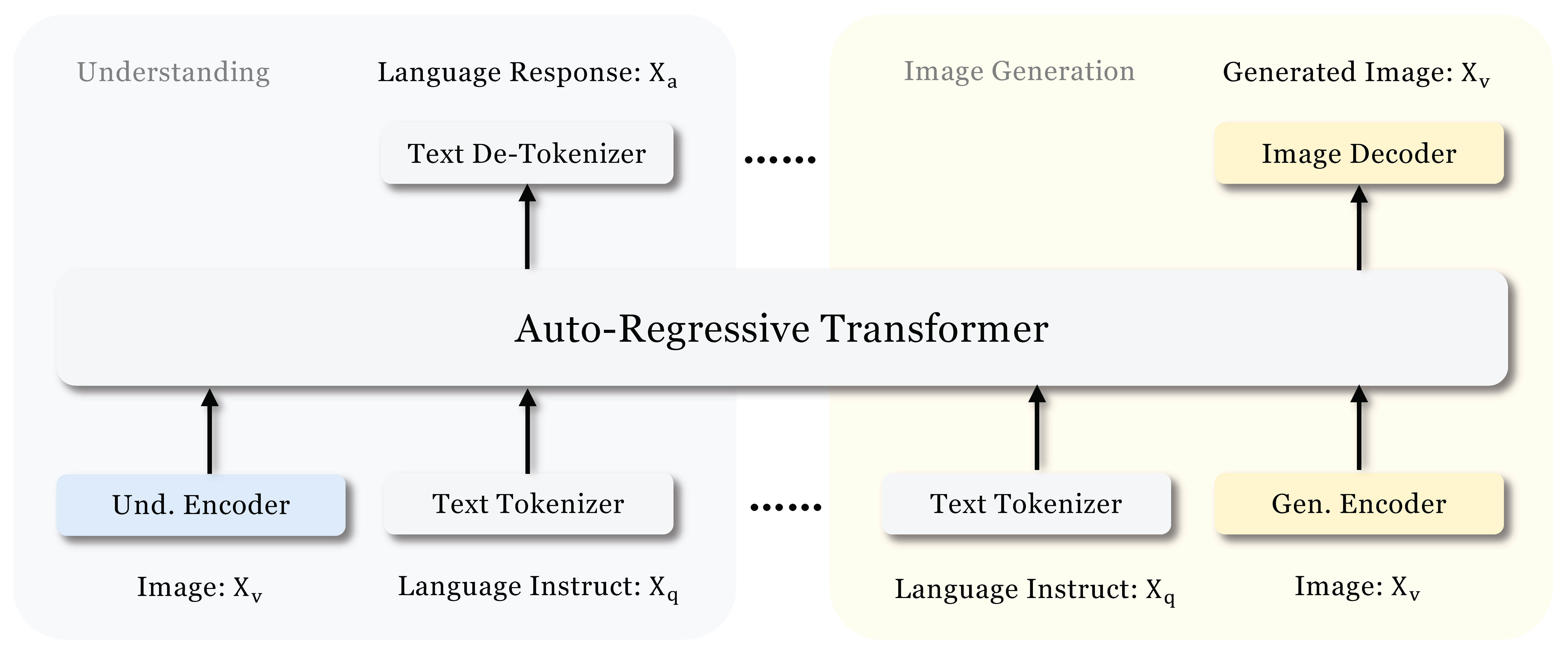
- Chameleon模型(Meta,2024)采用早期融合策略,通过创新的图像分词器将图像转化为离散Token,使图像与文本在同一序列中被LLM统一处理。输入层的融合将多模态数据对齐到共享表示空间,实现跨模态推理与生成,无需额外的图像编码器或任务专用解码模块。其训练过程通过自回归方式预测序列中下一个Token,学习图文间的跨模态映射。
- VITRON是面向像素级视觉任务的统一MLLM,采用经典的Encoder–LLM–Decoder架构。前端视觉编码器提取图像或视频的像素级特征,中间的LLM基于Vicuna-7B,对视觉特征进行理解,并结合用户指令完成推理与任务决策,后端调度专家模块(生成、分割、编辑)执行具体任务。通过前端特征提取、LLM决策和后端执行的协作流程,VITRON在单一框架下实现了高级语义理解与像素级处理的统一,对多种视觉任务提供通用处理能力。
这一时期,多模态技术正处于从分散探索走向统一建模的关键阶段。研究者通过早期融合与混合生成等方法,在单一模型中初步实现了理解与生成能力的统一,同时音频、视频等多模态的整合也开始落地。工业界的集中发力加速了这一进程:OpenAI发布的GPT-4V在复杂视觉推理、OCR和少样本学习中表现出卓越能力;Google推出的原生多模态模型Gemini旗舰版本在多项基准测试中达到甚至超越同类水平,形成闭源引领、开源追赶的格局,也凸显出多模态技术在商业化落地上的巨大潜力。不过,这些统一模型在架构设计、生成质量与计算效率上仍有优化空间。
1.4.2 从能力统一到流畅对话
随着MLLM朝着全能化与实时交互的方向演进,研究焦点逐步从实现单一模型中的统一理解与生成,转向高效整合主流模态并支持流畅实时交互。研究发现,简单的端到端统一建模在处理理解与生成任务时存在内在冲突:理解任务需要全局抽象语义,生成任务需要局部像素细节。
为此,2024年DeepSeek团队提出Janus模型,在MLLM中引入解耦的双路径视觉编码架构,在统一的LLM框架内为理解与生成分别设计独立编码路径,实现分而治之的统一处理。这一设计为构建高性能MLLM提供了重要参考,后续JanusFlow、NExT-OMNI等模型均受其启发。
Janus的核心洞察在于:视觉理解依赖全局抽象语义,而视觉生成需局部精细像素信息。若将二者耦合在同一视觉编码路径中,往往导致性能妥协。Janus通过双路径视觉编码设计解决该问题:
- 理解路径采用类似CLIP的视觉编码器,将图像编码为紧凑高层语义特征;
- 生成路径借助VQ-VAE等图像分词器,将图像转化为保留丰富空间细节的离散视觉标记。
两条路径输出共同输入LLM,LLM根据任务需求灵活选择关注的视觉信息。该设计使理解与生成能力独立优化,在两类任务上均取得领先性能。
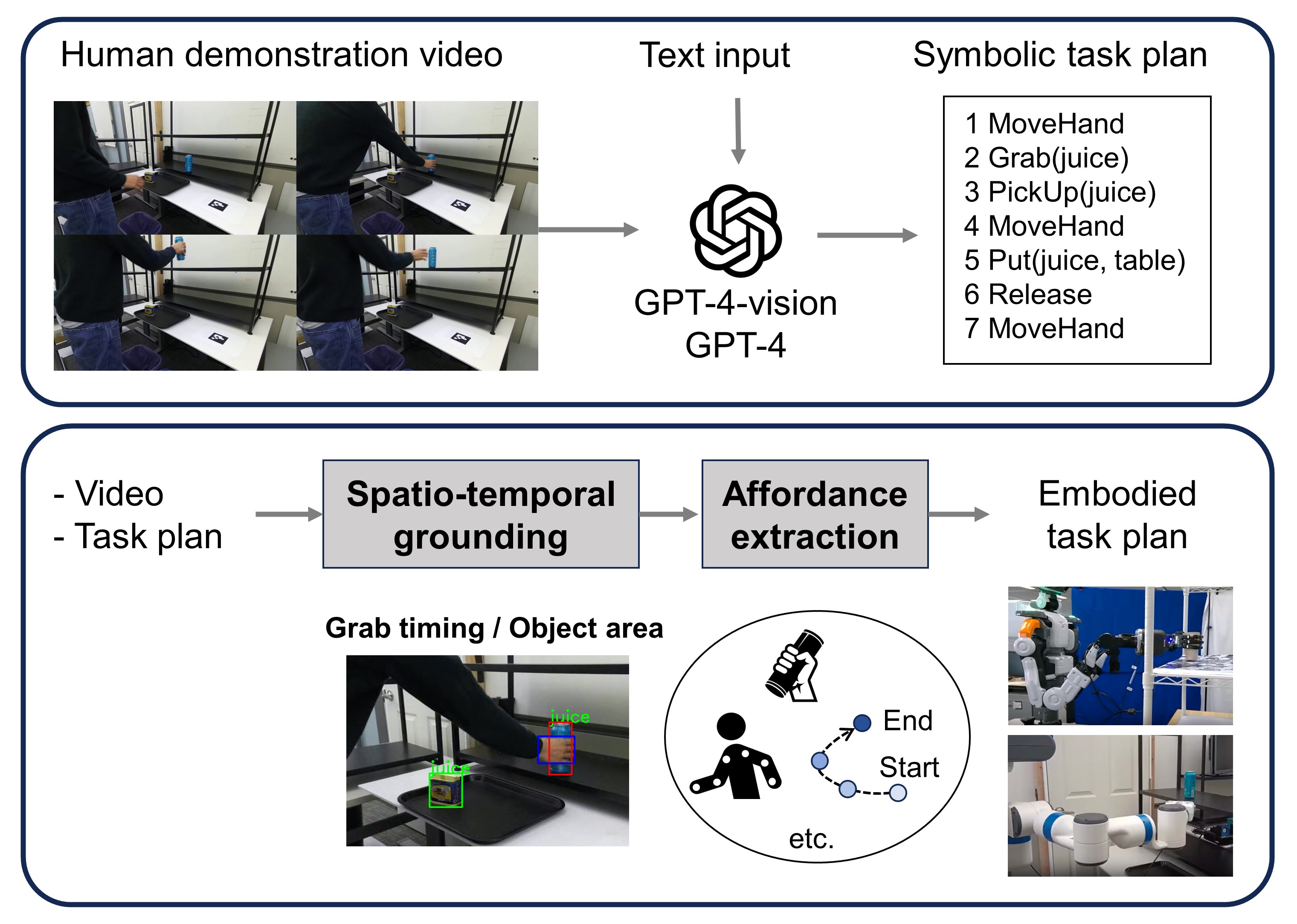
在这一时期,大多数开源MLLM仍主要聚焦图像与文本模态,与支持音频、图像和文本的专有模型(如GPT-4o、Gemini-Pro 1.5)相比存在差距。具备完整多模态交互能力的开源模型更为稀缺,需要进一步探索。尽管VITA-1.0尝试引入语音进行人机交互,但额外语音数据的整合会对原有多模态能力构成挑战,且语音生成依赖外部TTS系统,导致延迟较高,影响用户体验。
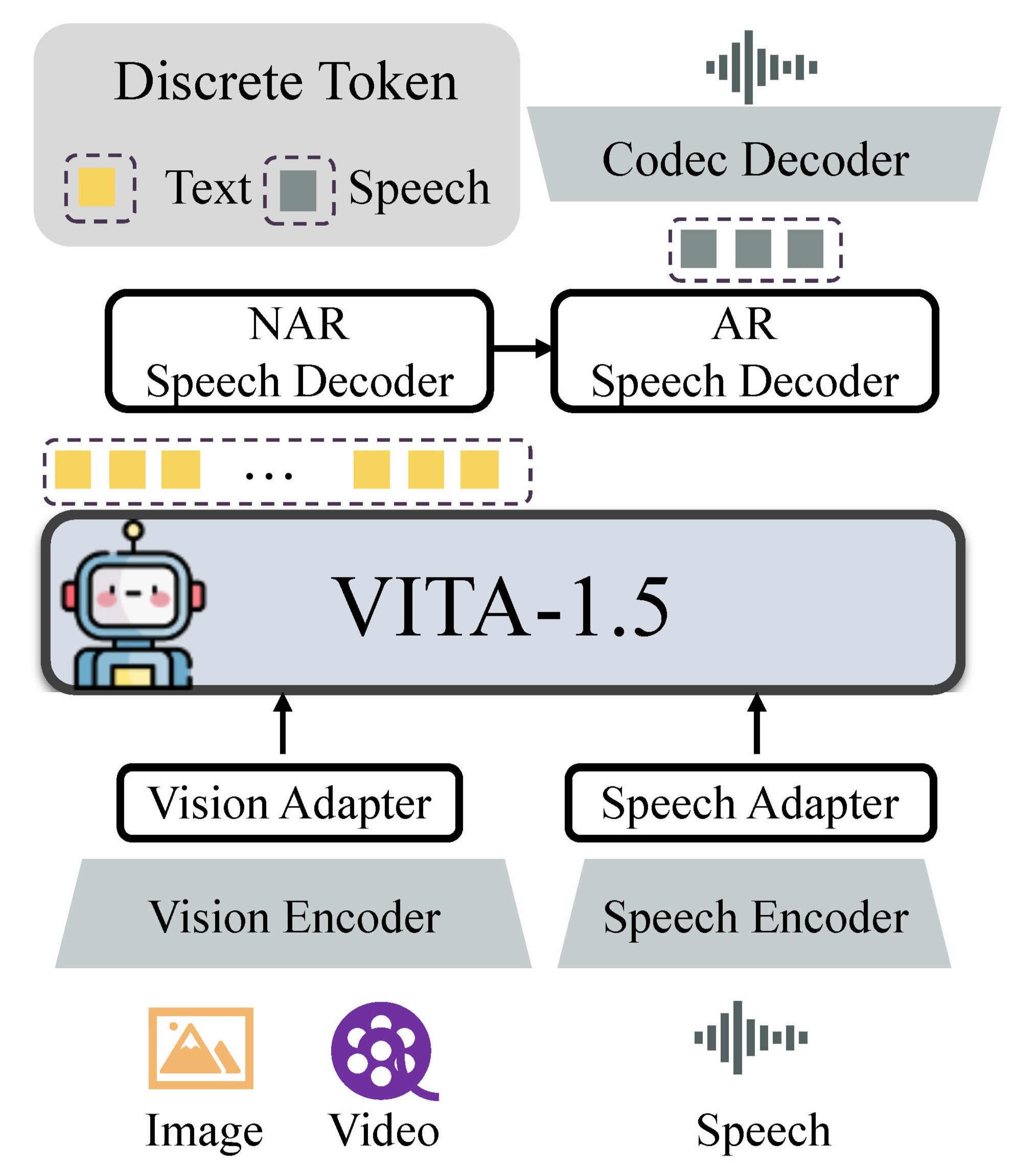
为实现流畅实时交互,VITA-1.5通过多阶段渐进式训练策略,将视觉与语音信息高效整合于单一LLM实现接近GPT-4o水平的实时视觉-语音交互。用户可流式输入语音指令,并配合摄像头捕捉实时画面,模型即时理解并生成低延迟语音回应。架构上,输入侧沿用多模态编码器-适配器-LLM配置,通过联合训练视觉/音频Transformer与多层连接器,实现对视觉、语言和音频的统一理解;输出侧采用自主研发端到端语音模块,摒弃外部TTS系统,从根本上解决延迟问题。该策略确保模型在感知视频、图像、文本和音频四种模态数据时表现优异,实现接近实时的交互体验。
1.5 全模态时代
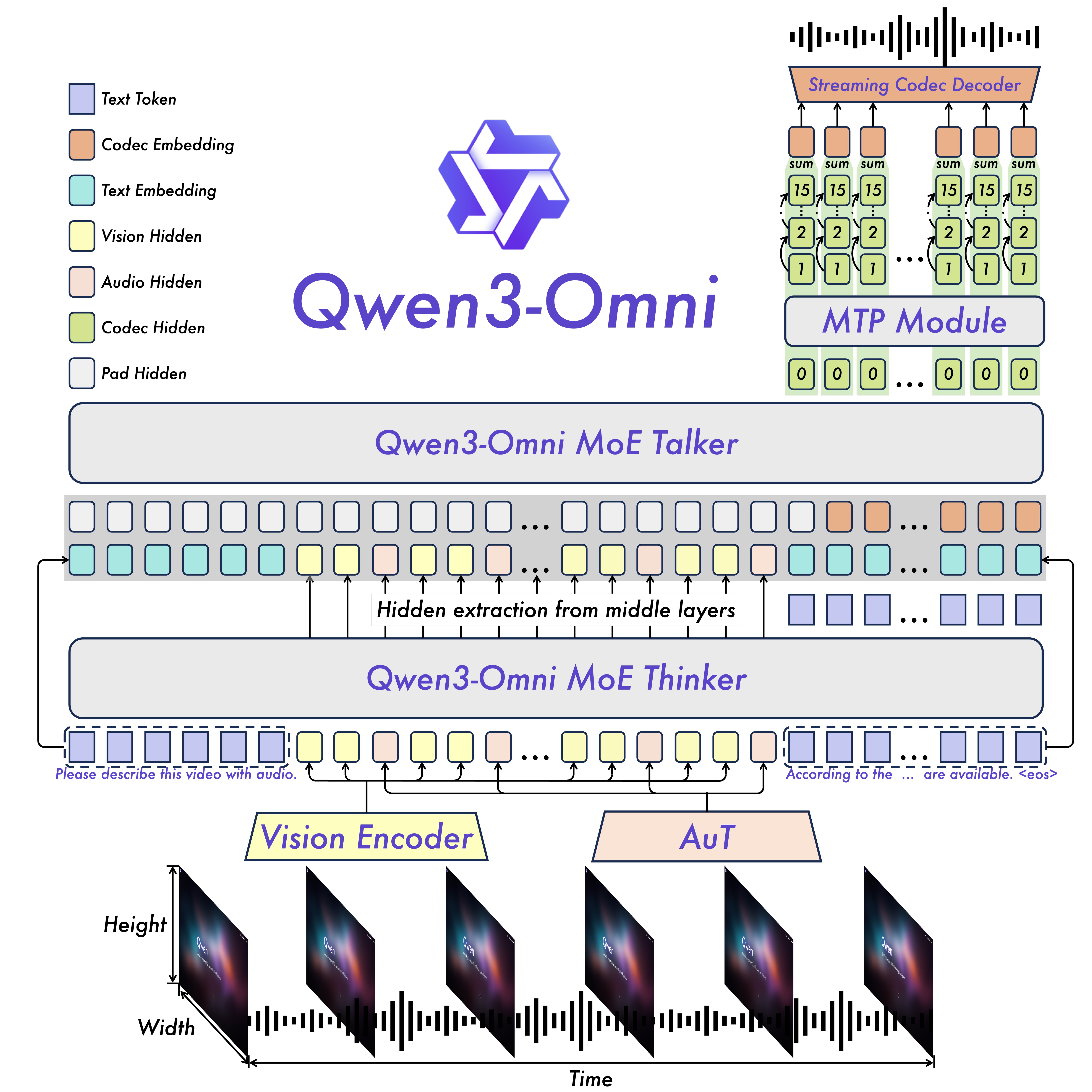
阿里巴巴于2025年9月正式发布了Qwen3-Omni,这是阿里云开源的端到端统一全模态MLLM,原生支持文本、图像、音频和视频等多模态的统一建模与交互。该模型具备跨模态理解与混合输入能力,能够同时完成多模态问答、音视频解析、语音对话以及图文音联动理解等任务,并支持实时语音交互。
不同于依赖外部工具或模块拼接的传统方案,Qwen3-Omni采用统一的端到端架构,原生处理多模态信息,无需设计专门接口或拼接流程。其核心技术路径在于通过在大规模、多样化的多模态数据上进行端到端训练,使标准Transformer自然习得跨模态信息的理解与生成能力。这不仅是技术架构上的突破,也标志着全模态AI已从理论探索迈向具备强大、可靠商业应用基础的实践阶段,代表了原生全模态模型发展的理想方向。
交错多模态生成是当前人工智能领域的另一个热点方向。字节跳动Seed团队推出的Mogao模型,在这一领域做出了开创性探索。它不仅能够处理纯文本或纯图像,还能直接生成图文并茂的内容(例如带插图的博客文章)。通过理解上下文关联的生成方式,Mogao无需额外训练即可编辑图像,并能根据需求组合生成新内容。在技术上,Mogao采用先进的视觉理解架构,结合创新的位置编码方法,能够同时处理图像的二维空间信息与图文混合的时序关系,从而生成质量更高、图文匹配度更佳的内容。
2 核心技术组件与训练方法
2.1 基础架构
MLLM的常用构造主要有两类:
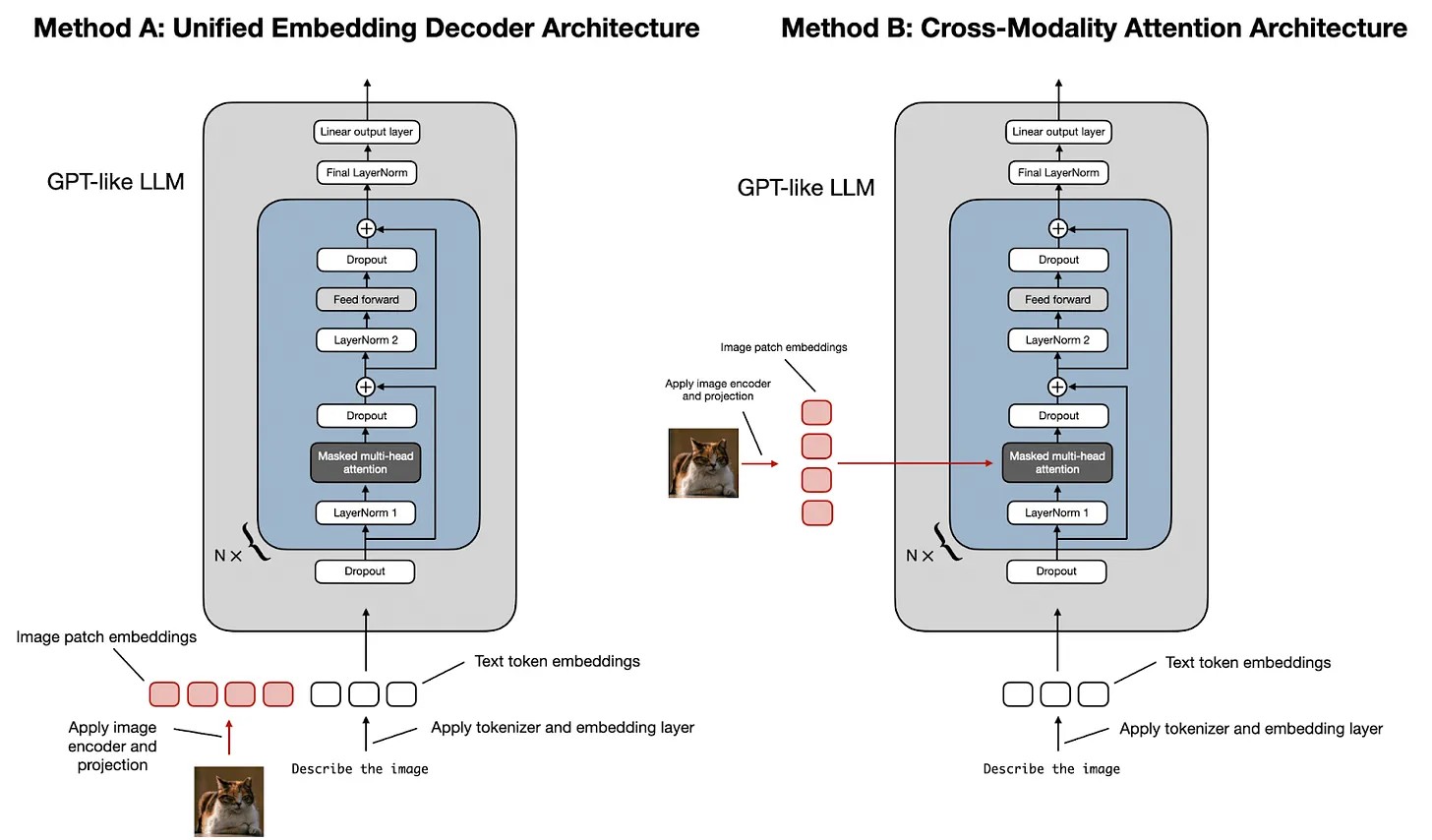
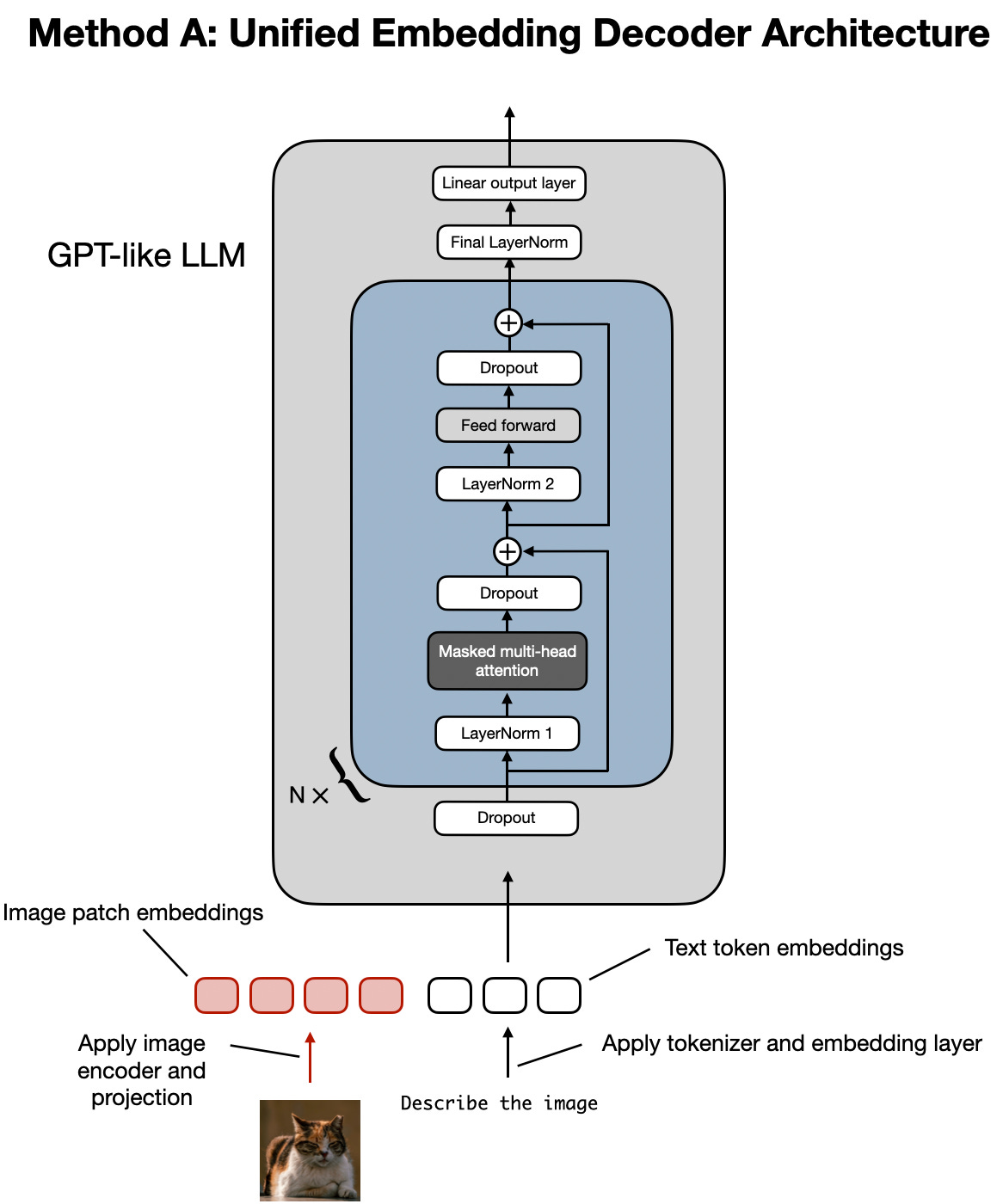
- 视觉编码器与LLM的拼接架构
这类方法在原有文本LLM的基础上扩展了图像理解能力,无需修改模型核心结构。通常流程为:先利用视觉编码器提取图像特征,再通过轻量级投影模块将其映射到文本嵌入空间,得到视觉嵌入序列。随后将视觉嵌入与文本嵌入在模型输入层拼接,共同送入LLM,使模型能够同时处理文本和图像信息。典型代表包括LLaVA-NeXT和Qwen-VL。此类模型通常通过改进视觉编码器或投影模块来提升对图像细节的感知能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)