主流大模型介绍(GPT、Llama、ChatGLM、Qwen、deepseek)
GPT系列模型
一、ChatGPT 的本质
-
发布者:OpenAI(2022年11月30日)
-
类型:聊天机器人模型,基于自然语言处理技术
-
核心能力:理解语言、生成对话、撰写邮件/文案/代码、翻译等
-
增长数据:2个月用户破1亿,日活约1300万
二、GPT 系列模型演进对比
| 模型 | 发布时间 | 参数量 | 核心创新 | 主要局限 |
|---|---|---|---|---|
| GPT-1 | 2018.06 | 1.17亿 | 引入生成式预训练 + Transformer Decoder | 语言模型单向;需微调才能泛化 |
| GPT-2 | 2019.02 | 15亿 | 多任务学习 + Zero-shot 能力 | 无监督能力仍有限 |
| GPT-3 | 2020.05 | 1750亿 | Few-shot 学习 + Sparse Attention | 成本高、长文本不稳定、内容不可控 |
| ChatGPT | 2022.11 | 基于GPT-3 | 引入 RLHF(人类反馈强化学习) | 服务不稳定、可能生成错误信息 |
三、核心技术点回顾
1. GPT-1
-
使用单向 Transformer Decoder(去掉了 Encoder-Decoder Attention)
-
擅长:自然语言生成(NLG)
-
不擅长:自然语言理解(NLU,相比BERT)
2. GPT-2
-
结构微调:Layer Normalization 前置、增加序列长度到1024
-
核心理念:无监督多任务学习
-
贡献:验证了大模型 + 大数据的迁移能力
3. GPT-3
-
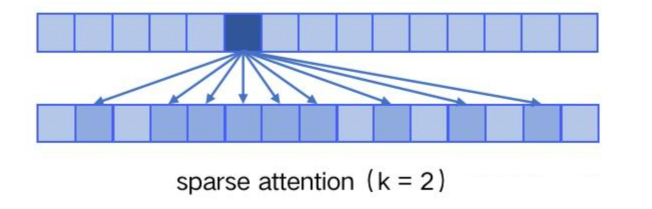
引入 Sparse Attention,降低复杂度 O(n²) → O(n log n)
-
-
Sparse Attention 稀释注意力,Sparse Attention 通过只让每个 token 关注局部邻居和部分远距离 token,将注意力计算复杂度从 O(n²) 降到 O(n·log n),使 GPT-3 能够高效处理长序列文本,大幅增强了长文本处理能力,节省了计算资源用来处理更长的文本。
-
-
支持 Few-shot / One-shot / Zero-shot
-
不再对每个任务进行微调(降低成本)
4. ChatGPT
-
解决“模型能力不一致”问题(即训练好但实际表现不符合人类预期)
-
方法:RLHF(人类反馈强化学习)
-
人类对模型输出进行排序
-
训练奖励模型
-
使用强化学习优化生成策略
-
-
RLHF >> SFT、RM、PPO
SFT >> Supervised Fine-Tuning 监督微调,使用人工标注引导模型学习人类偏好
RM >> Reward Model 训练奖励模型
PPO >> 用 PPO 算法更新模型,让SFT模型根据奖励模型的反馈不断改进
1. SFT 阶段:人类通过标注理想答案,监督微调大模型,让其初步学习人类偏好
2. RM 阶段:人类对模型生成的多个答案进行排序,用这些排序数据训练一个奖励模型
3. PPO 阶段:用奖励模型打出的分数作为反馈信号,通过强化学习让大模型不断优化人类标注 → SFT 微调 → 人类排序 → RM 奖励模型 → PPO 强化学习 → ChatGPT
后序RLHF 因人工标注成本问题进阶RLAIF >> 基于AI反馈的强化学习 LLM有这个能力
四、GPT vs BERT 本质区别
| 维度 | GPT | BERT |
|---|---|---|
| 架构 | Transformer Decoder | Transformer Encoder |
| 注意力方向 | 单向(从左到右) | 双向 |
| 擅长任务 | 文本生成(NLG) | 文本理解(NLU) |
五、ChatGPT 优缺点总结
✅ 优点
-
回答更理性、全面、多角度
-
降低学习与内容创作成本
❌ 缺点
-
服务不稳定
-
可能“一本正经地胡说八道”
六、GPT总结
ChatGPT 的成功并非一蹴而就,而是 GPT 系列模型四年演进的集大成者。从 GPT-1 的单向生成,到 GPT-2 的多任务尝试,再到 GPT-3 的规模爆发,最后通过 RLHF 实现人类对齐 —— 这是一条从“模型能力”走向“人类价值对齐”的技术路径。ChatGPT 的真正突破,不只是大,而是学会了“听人话,说人话”。
LLM 主流开源大模型
一、主流大模型概览
| 模型 | 开发者 | 特点 | 开源协议 |
|---|---|---|---|
| LLaMA | Meta | 开源先驱,Llama 3 支持商用 | Llama 协议(巨头需单独授权) |
| ChatGLM | 清华 | 中英双语,6B 可跑消费级显卡 | 开源 |
| Qwen | 阿里 | 多语言,Qwen2.5 支持 1M 上下文 | Apache 2.0 |
| Baichuan | 百川智能 | 中英双语,可商用 | 开源 |
| Yi | 零一万物 | 中英双语,34B 性能对标 LLaMA-2 | 开源 |
| DeepSeek | 深度求索 | MoE 架构,671B 参数,MIT 协议 | MIT(最宽松) |
二、各模型核心亮点
🦙 LLaMA(Meta)
SwiGLU + RMSNorm + RoPE
SwiGLU >> ff前馈连接层替换relu,门控机制增强非线性能力,避免神经元死亡,收敛更快
非线性特征信息提取能力+++
RMSNorm >> 层归一化前置,只计算方差不计算均值,去掉了bias计算,参数量降一倍
RoPE >> 绝对位置编码➕相对位置编码,通过在Attention计算中注意旋转矩阵实现
-
迭代:Llama 1(研究用)→ Llama 2(免费商用)→ Llama 3(405B 超大)
-
核心改进:SwiGLU + RMSNorm + RoPE
-
衍生模型:Alpaca、Vicuna、BELLE、Chinese LLaMA
🇨🇳 ChatGLM(清华)
Prefix-Decoder
本质是利用decoder实现 (encoder中双向注意力机制➕MLM机制)➕decoder中单向预测
输入序列Prefix 前缀部分使用双向注意力➕MLM, 预测序列Generation使用单向注意力
结合Bert双向理解 ➕ GPT 单向生成
-
特点:中英双语,6B 可在消费级显卡运行
-
迭代:GLM-130B → ChatGLM-6B → GLM-4(128K 上下文)
-
技术:Prefix-Decoder(双向注意力)
☁️ Qwen(阿里)
Llama的SwiGLU➕RMSNorm➕RPPE
Deepseek的MOE混合专家机制Plus版(激活率3.7%)➕量化优化
独创的混合注意力机制
-
迭代:Qwen1.5(32K)→ Qwen2(128K)→ Qwen2.5(1M 上下文)→ Qwen3(235B MoE)
-
特色:支持百万 token 上下文,多模态版本 Qwen2.5-VL
🔥 DeepSeek(深度求索)
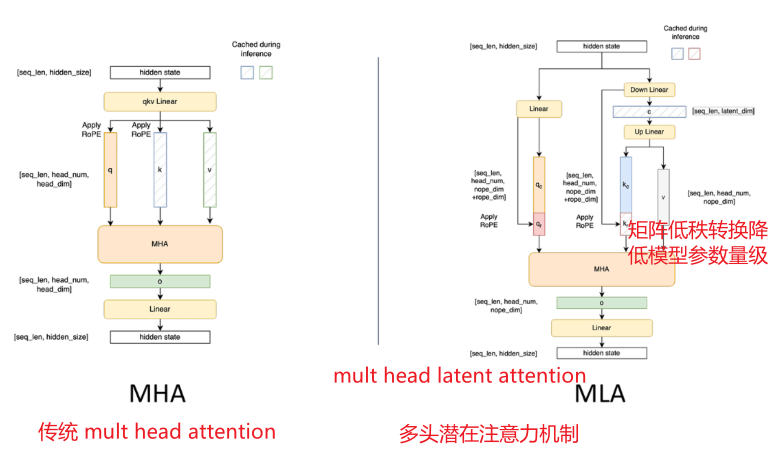
MLA 多头潜在注意力,利用低秩压缩技术,将模型参数压缩到极致
MOE 混合专家机制,ff前馈连接层整体分为N个专家主导,利用linear层加权求和的方式算出专家的得分logits,利用softmax算出专家的权重比例,topk选择排名靠前的专家进行激活计算,抓重点,专业的事交给专业的部分搞定,大幅节省算力(激活率 5.5%)
FP8 采用FP8精度,量化压缩50%
RLAIF AI强化学习,节省人工标注成本,让模型更懂人性,听人话AI标注>>有监督微调>>排序实现奖励模型>>PPO强化学习>>反向促进模型成长
Deepseek Sparse Attention 稀疏注意力机制,抓重点部分做计算,节省半数算力
DSA是通过linear层不断更新参数,不断学习如何筛选更优质的注意力部分

混合专家机制MOE专项理解:
混合专家模式MOE的意义从来不是像MLA或者DSA这样直接的节省参数计算量,反而分配多个专家会导致算力消耗翻倍,但是收益确实指数级增长的,利用低算力的成本,敲动高算力成果
处理层级是ff前馈连接层,假定100个专家,我们给这100个专家均配备标准的ff层用以反向梯度更新参数,重点是我们提前对输入维度经过linear层输出到100个logits(对应100个专家),经过softmax(logtis)得到相应的专家权重分布比例,经过topv可以得到权重靠前的5个专家,我们通过激活靠前的5个专家来更新他们的参数,从而达到用5倍算力撬动100倍算力的杠杆效果,激活率5%
激活专家的方式是通过将专家权重矩阵中不需要计算的专家权重置为0,来规避他们的更新,同时我们引入惩罚系数,强制模型雨露均沾,避免一些专家饿死,让他们都能得到参数的更新,这就是deepseek的负载均衡机制(惩罚系数)
MOE源码剖析
# 共享+路由专家模型
import torch
import torch.nn as nn
import torch.nn.functional as F
# ===================== 专家网络定义 =====================
class Expert(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super().__init__()
# 第一层全连接层,将输入维度映射到隐藏层维度
self.fc1 = nn.Linear(input_dim, hidden_dim)
# 第二层全连接层,将隐藏层映射到输出维度
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# 先经过第一层并激活
x = F.relu(self.fc1(x))
# 再经过第二层输出
return self.fc2(x)
# ===================== 路由门控网络定义 =====================
class RoutingGate(nn.Module):
def __init__(self, input_dim, num_routed_experts, k=2):
super().__init__()
# 全连接层输出每个专家的分数
self.fc = nn.Linear(input_dim, num_routed_experts)
self.k = k # Top-k,表示每个输入只选择k个专家
def forward(self, x):
# logits: [batch, num_routed_experts],每个专家的分数
logits = self.fc(x)
# 取Top-k分数及其索引
topk_val, topk_idx = torch.topk(logits, self.k, dim=-1)
# 对Top-k分数做softmax,得到归一化权重
weights = F.softmax(topk_val, dim=-1)
print("weights:", weights)
# 构造与logits同形状的全零权重
routed_weights = torch.zeros_like(logits)
# 将Top-k权重填入对应位置,其余为0
routed_weights.scatter_(-1, topk_idx, weights)
print("Routed weights:", routed_weights)
return routed_weights # [batch, num_routed_experts]
# ===================== MoE主结构:包含路由专家和共享专家 =====================
class MoEWithRouting(nn.Module):
def __init__(
self,
input_dim,
hidden_dim,
output_dim,
num_routed_experts,
num_shared_experts,
k=2,
):
super().__init__()
# 路由专家列表,每个专家是一个Expert实例
self.routed_experts = nn.ModuleList(
[
Expert(input_dim, hidden_dim, output_dim)
for _ in range(num_routed_experts)
]
)
# 共享专家列表
self.shared_experts = nn.ModuleList(
[
Expert(input_dim, hidden_dim, output_dim)
for _ in range(num_shared_experts)
]
)
# 路由门控网络
self.routing_gate = RoutingGate(input_dim, num_routed_experts, k)
# 共享专家的权重参数(可学习),初始均分
self.shared_weights = nn.Parameter(
torch.ones(num_shared_experts) / num_shared_experts, requires_grad=True
)
def forward(self, x):
# ========== 路由专家部分 ==========
# 计算每个输入分配到各个路由专家的权重 [batch, num_routed_experts]
routed_weights = self.routing_gate(x)
print("routed_weights:", routed_weights)
# 计算所有路由专家的输出,堆叠成 [batch, output_dim, num_routed_experts]
routed_outputs = torch.stack(
[expert(x) for expert in self.routed_experts], dim=2
)
print("routed_outputs:", routed_outputs)
# 按权重加权求和,得到路由专家的最终输出 [batch, output_dim]
routed_result = torch.sum(routed_weights.unsqueeze(1) * routed_outputs, dim=2)
print("routed_result:", routed_result)
# ========== 共享专家部分 ==========
# 计算所有共享专家的输出,堆叠成 [batch, output_dim, num_shared_experts]
shared_outputs = torch.stack(
[expert(x) for expert in self.shared_experts], dim=2
)
# 对共享专家权重做softmax归一化 [num_shared_experts]
shared_weights = F.softmax(self.shared_weights, dim=0)
# 按权重加权求和,得到共享专家的最终输出 [batch, output_dim]
shared_result = torch.sum(
shared_weights.unsqueeze(0).unsqueeze(1) * shared_outputs, dim=2
)
# ========== 融合输出 ==========
# 路由专家输出与共享专家输出相加,作为最终输出
output = routed_result + shared_result
return output
# ===================== 测试代码 =====================
# 定义各参数
input_dim = 10 # 输入特征维度
hidden_dim = 20 # 专家网络隐藏层维度
output_dim = 5 # 输出特征维度
num_routed_experts = 4 # 路由专家数量
num_shared_experts = 2 # 共享专家数量
k = 2 # Top-k,路由门控每次选择的专家数
seq_len = 8 # 输入序列长度(batch size)
# 实例化模型
model = MoEWithRouting(
input_dim, hidden_dim, output_dim, num_routed_experts, num_shared_experts, k
)
# 构造随机输入
x = torch.randn(seq_len, input_dim)
# 前向传播
output = model(x)
# 打印输出形状和内容
print("Output shape:", output.shape, output) # [seq_len, output_dim]
数据流转图示
"""
═══════════════════════════════════════════════════════════════════
输入数据 x
形状: [8, 10] (batch=8, dim=10)
═══════════════════════════════════════════════════════════════════
│
┌─────────────────┼─────────────────┐
│ │ │
▼ ▼ ▼
┌────────┐ ┌────────┐ ┌────────┐
│门控网络│ │路由专家│ │共享专家│
│ │ │ (4个) │ │ (2个) │
└────────┘ └────────┘ └────────┘
│ │ │
▼ ▼ ▼
┌────────┐ ┌────────────────────────────┐
│[8,4] │ │ 每个专家内部: │
│(权重) │ │ ┌────────────────────────┐ │
└────────┘ │ │ 输入: [8,10] │ │
│ │ │ ↓ │ │
│ │ │ fc1: Linear(10→20) │ │
│ │ │ ↓ │ │
│ │ │ ReLU │ │
│ │ │ ↓ │ │
│ │ │ fc2: Linear(20→5) │ │
│ │ │ ↓ │ │
│ │ │ 输出: [8,5] │ │
│ │ └────────────────────────┘ │
│ │ │
│ │ 4个专家各自输出: │
│ │ E0: [8,5] │
│ │ E1: [8,5] │
│ │ E2: [8,5] │
│ │ E3: [8,5] │
│ │ ↓ │
│ │ stack(dim=2) │
│ │ ↓ │
│ │ [8,5,4] ←────────────┐ │
│ │ │ │
│ └───────────────────────┼────┘
│ │
▼ ▼
┌─────────────────────────────────────────────────┐
│ 路由加权求和: [8,1,4] × [8,5,4] = [8,5,4] │
│ sum(dim=2) → [8,5] │
└─────────────────────────────────────────────────┘
│
▼
routed_result: [8,5]
│
│ ┌────────────────────────────┐
│ │ 共享专家 (2个): │
│ │ 每个专家内部: │
│ │ 输入: [8,10] │
│ │ ↓ │
│ │ fc1: Linear(10→20) │
│ │ ↓ │
│ │ ReLU │
│ │ ↓ │
│ │ fc2: Linear(20→5) │
│ │ ↓ │
│ │ 输出: [8,5] │
│ │ │
│ │ S0: [8,5] │
│ │ S1: [8,5] │
│ │ ↓ │
│ │ stack(dim=2) │
│ │ ↓ │
│ │ [8,5,2] │
│ └────────────────────────────┘
│ │
│ ▼
│ shared_weights: [2]
│ │
│ ▼
│ ┌─────────────────────────────┐
│ │ 共享加权求和: │
│ │ [1,1,2] × [8,5,2] = [8,5,2] │
│ │ sum(dim=2) → [8,5] │
│ └─────────────────────────────┘
│ │
│ ▼
│ shared_result: [8,5]
│ │
└──────┬───────┘
▼
┌─────────────────────────┐
│ 最终输出 = routed + shared │
│ [8,5] + [8,5] = [8,5] │
└─────────────────────────┘
│
▼
════════════════════════════
最终输出: [8, 5]
════════════════════════════
"""-
核心技术:
-
MLA(多头潜在注意力):减少记忆体 30%
-
MoE(混合专家):671B 总参数,仅激活 37B
-
FP8 混合精度训练:省资源、加速
-
-
开源协议:MIT(最宽松,可自由商用)
三、硬件配置参考(本地部署)
| 模型大小 | 推理显存 (FP16) | 推荐场景 |
|---|---|---|
| 7B | 10-14 GB | 中小企业应用 |
| 13B | 20-26 GB | 企业级应用 |
| 32B | 64-70 GB | 复杂 NLP 任务 |
| 70B | 140 GB+ | 超大规模任务 |
| 304B+ | 600 GB+(需量化) | 国家/科研级 |

参数 FP16,两倍打底
推理加三成,全量训练乘六倍
量化降一半,LoRA 省大头, 不训练全部参数,只训练“小插件”(低秩矩阵)
主要就是两个途径,1是通过量化压缩显存 2是通过低秩矩阵转换,减少参数量级(lora)
四、开源协议速查
| 协议 | 特点 | 代表模型 |
|---|---|---|
| MIT | 最宽松,可自由商用 | DeepSeek |
| Apache 2.0 | 含专利授权 | Qwen、Grok-1 |
| Llama 协议 | 月活超 7 亿需单独授权 | LLaMA 系列 |
| MCP | 模型上下文协议(Anthropic) | 标准化 AI 工具调用 |
五、一句话总结
LLaMA 是开源先驱
ChatGLM 中文友好
Qwen 长上下文最强
DeepSeek 架构最创新且协议最宽松。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 34
34 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)