从零实现 Llama 3:架构拆解与实现细节
本文参考以下英文教程撰写:https://pub.towardsai.net/build-your-own-llama-3-architecture-from-scratch-using-pytorch-2ce1ecaa901c
第一次看到有人把 Llama 3 从零实现一遍,我就知道这件事值得认真做一次。因为只有真正写出来,才能体会到每一个设计选择背后的逻辑——为什么 Norm 放在前面而不是后面,为什么 KV Cache 只缓存 K 和 V 而不包括 Q,为什么 RoPE 要转成复数域再做乘法……这些问题,看论文能得到答案,但只有自己写代码才能真正把它们变成直觉。
这篇笔记的目标是:把 Llama 3 的每一个模块,从设计动机到公式推导到代码实现,都讲清楚。所有技术细节来自 Meta 官方论文,所有代码都可以独立运行。我们用 Tiny Shakespeare 数据集来做演示训练,因为它足够小,能快速看到结果,同时又足够有趣,让你感受到语言模型在学什么。
先看全局
Llama 3 本质上是一个标准的 decoder-only transformer,但 Meta 在几个关键位置做了精准的替换。架构本身不复杂,复杂的是每个替换背后的权衡。
整个前向传播可以分成三段:输入块 → 解码器块(×N层)→ 输出块。
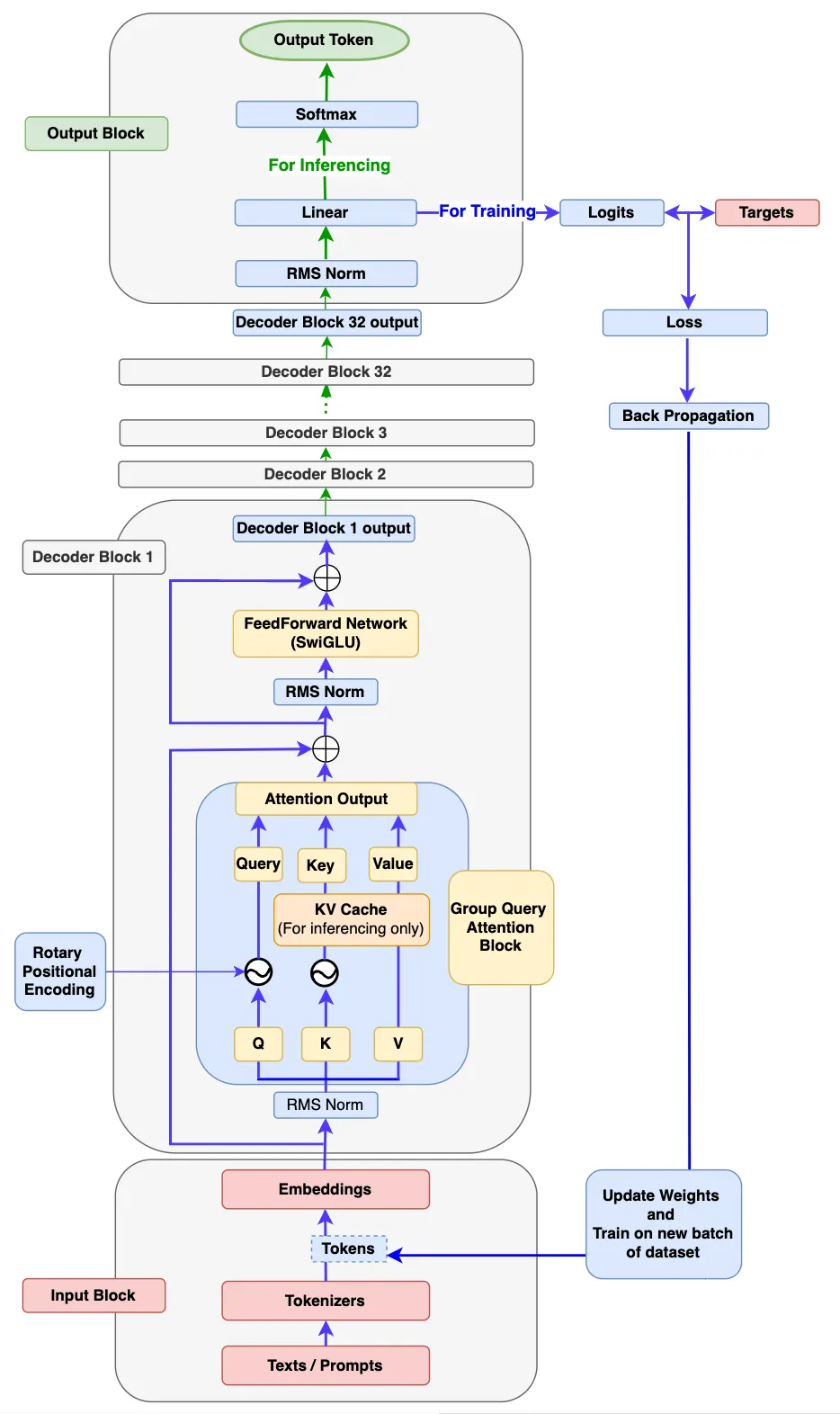
一、Llama 3 整体架构:三个关键杠杆
在深入每个模块之前,先把 Llama 3 的全貌说清楚。
Llama 3 是一个标准的稠密 Transformer 解码器(dense Transformer decoder)架构,论文明确说没有采用混合专家模型(MoE),主要原因是为了最大化训练稳定性、降低复杂度。
论文指出了驱动 Llama 3 性能的三个核心杠杆:
数据(Data):预训练语料从 Llama 2 的 1.8T tokens 提升到 15T tokens,增幅超过 8 倍。数据质量也大幅提升,引入了多轮清洗和领域分类策略。最终的数据配比是:约 50% 通用知识、25% 数学与推理、17% 代码、8% 多语言内容。
规模(Scale):最大模型 405B 参数,用 3.8×10²⁵ FLOPs 训练,是 Llama 2 最大版本的约 50 倍算力。论文按照 Chinchilla 缩放定律推算出计算最优点在 402B 参数和 16.55T tokens,最终选择了 405B。
复杂度管理(Managing Complexity):Post-training 阶段采用 SFT + 拒绝采样(RS)+ DPO 的组合,而非更复杂的 RL 算法,理由是复杂算法更难稳定扩展。
整个模型在架构层面继承了 Llama 2 的基本骨架,但有四处关键修改:GQA 的 KV head 数量固定为 8、词表从 32K 扩充到 128K、RoPE base frequency 从 10000 提升到 500000、以及引入跨文档注意力 mask。下面逐一讲。
二、输入块(Input Block)
输入块包含三个组件:文本/提示词、分词器、嵌入层。
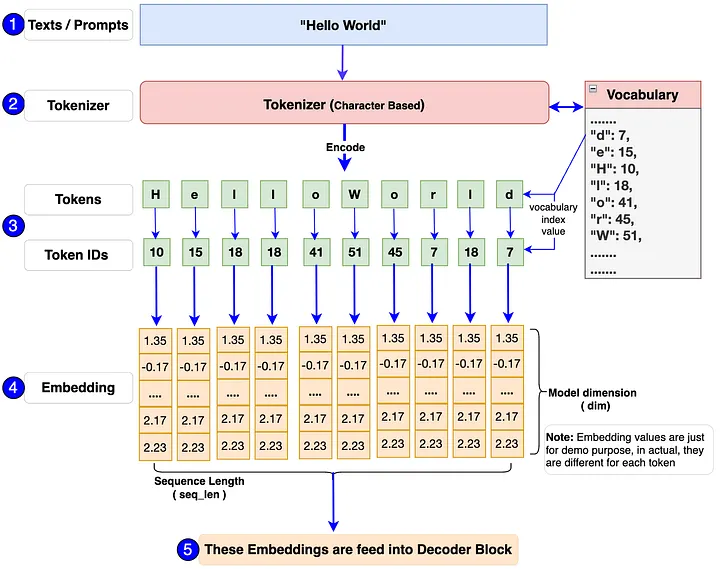
1.1 分词器:从字符到 token 的映射
Llama 3 在生产环境中使用 TikToken 作为分词器,这是一个子词(subword)级分词器,词表大小 128,000,由 100,000 个来自 tiktoken 的基础 token 加上 28,000 个额外的非英语语言 token 组成。
相比 Llama 2 的 SentencePiece 分词器(词表 32K),这次扩充带来的直接收益是压缩率提升——同样一段英文文本,Llama 3 平均每个 token 能表示 3.94 个字符,而 Llama 2 只有 3.17 个字符。这意味着在相同计算量下,Llama 3 能"读到"更多文本。
为什么词表变大能提升压缩率?本质是因为更大的词表可以把更多常见词组和词缀直接存成一个 token,而不是拆成多个子词。比如 "generating" 如果本身在词表里,就是 1 个 token;如果不在,可能被拆成 "generat" 和 "ing" 两个 token。词表越大,整体需要的 token 数越少,序列越短,注意力计算成本越低。
特殊 token 方面,Llama 3 定义了 <|begin_of_text|>、<|end_of_text|>、<|eot_id|>(turn 结束)、<|start_header_id|> 和 <|end_header_id|> 等,这些在对话场景下有重要的结构化作用。
在我们的从零实现中,用字符级分词器来代替 TikToken,目的是让整个 encode/decode 流程完全透明可控:
with open('tiny_shakespeare.txt', 'r') as f:
data = f.read()
vocab = sorted(list(set(data)))
vocab.extend(['<|begin_of_text|>', '<|end_of_text|>', '<|pad_id|>'])
vocab_size = len(vocab)
itos = {i: ch for i, ch in enumerate(vocab)}
stoi = {ch: i for i, ch in enumerate(vocab)}
def encode(s):
return [stoi[ch] for ch in s]
def decode(l):
return ''.join(itos[i] for i in l)
token_bos = torch.tensor([stoi['<|begin_of_text|>']], dtype=torch.int, device=device)
token_eos = torch.tensor([stoi['<|end_of_text|>']], dtype=torch.int, device=device)
token_pad = torch.tensor([stoi['<|pad_id|>']], dtype=torch.int, device=device)1.2 模型超参数
在进入解码器之前,先把本次实现用到的所有参数集中定义好。注意这里为了让训练快速出结果,把 dim 调小到 512,实际 Llama 3 8B 的 dim 是 4096:
@dataclass
class ModelArgs:
dim: int = 512
n_layers: int = 8
n_heads: int = 8
n_kv_heads: int = 4 # 对应论文里 GQA 的 KV heads = 8(这里按比例缩小)
vocab_size: int = len(vocab)
multiple_of: int = 256
ffn_dim_multiplier: Optional[float] = None
norm_eps: float = 1e-5
rope_theta: float = 500000.0 # 论文把这个值从 10000 提升到了 500000
max_batch_size: int = 10
max_seq_len: int = 256
epochs: int = 2500
log_interval: int = 10
device: str = 'cuda' if torch.cuda.is_available() else 'cpu'这里有一个细节值得单独说:rope_theta = 500000.0。这是 Llama 3 相比 Llama 2 的四大架构改动之一。原论文指出,将 RoPE 的 base frequency 从默认的 10000 提升到 500000,能让模型有效处理更长的上下文——论文引用的研究表明这个值对 32768 长度的上下文有效,而在后续的长上下文继续预训练阶段,上下文长度进一步扩展到了 128K tokens。
三、解码器块(Decoder Block)
解码器块是 Llama 3 的核心。每个解码器块包含六个子组件:RMSNorm、RoPE、KV Cache、GQA、FeedForward Network,以及把它们组装在一起的 TransformerBlock。我们逐一深入。
3.1 RMSNorm:比 LayerNorm 更高效的归一化
为什么需要归一化? embedding 向量在各个维度上的数值范围差异很大,直接送入后续计算会导致梯度爆炸或消失,训练不稳定。归一化把这些值拉到一个合适的范围,让梯度的量级更一致,训练更稳。
为什么用 RMSNorm 而不是 LayerNorm? 这是 Llama 系列从第一代就继承下来的选择。LayerNorm 需要计算均值(mean)和方差(variance):
而 RMSNorm 完全省掉了均值的计算,只保留 RMS(Root Mean Square,均方根)这一步:
这意味着:第一,少了均值计算,计算开销降低;第二,没有偏移参数 β,参数更少;第三,论文作者的实验表明性能相当甚至更好。直觉上,归一化的关键作用是控制量级(scale),而均值中心化对这个目标的贡献有限,省掉它代价不大。
同时要注意,Llama 3 采用 Pre-Norm 结构,即在注意力和前馈网络之前做归一化,而不是之后。Pre-Norm 相比 Post-Norm 训练更稳定,这一点已经被大量工作证明。
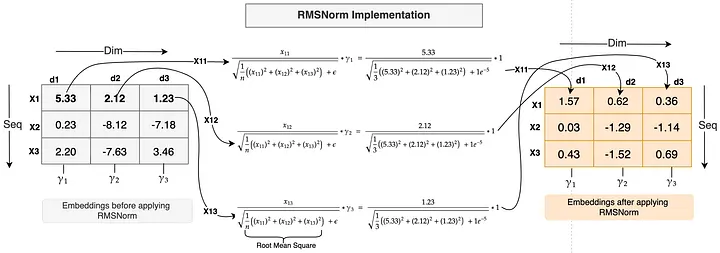
class RMSNorm(nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim).to(device))
def _norm(self, x):
# x.pow(2).mean(dim=-1, keepdim=True) 是对最后一个维度(embedding dim)求均方
# rsqrt = 1 / sqrt,整体就是 x / RMS(x)
return x * torch.rsqrt(x.pow(2).mean(dim=-1, keepdim=True) + self.eps).to(device)
def forward(self, x):
# Shape: x[bs, seq, dim] -> output[bs, seq, dim]
output = self._norm(x.float()).type_as(x)
return output * self.weight3.2 旋转位置编码(RoPE):用旋转矩阵编码绝对位置和相对位置
问题:Transformer 的自注意力机制本质上是置换不变的(permutation invariant)——把输入序列的顺序打乱,注意力得分的模式不会变。但语言显然是有顺序的,"我爱你"和"你爱我"意思截然不同。所以必须想办法把位置信息注入 embedding。
Llama 1/2/3 都用 RoPE(Rotary Positional Encoding),而不是原始 Transformer 里的正弦绝对位置编码,也不是可学习的绝对位置编码。RoPE 的核心思路是:用旋转矩阵对 Q 和 K 的 embedding 进行旋转,使得旋转角度正比于 token 的绝对位置。
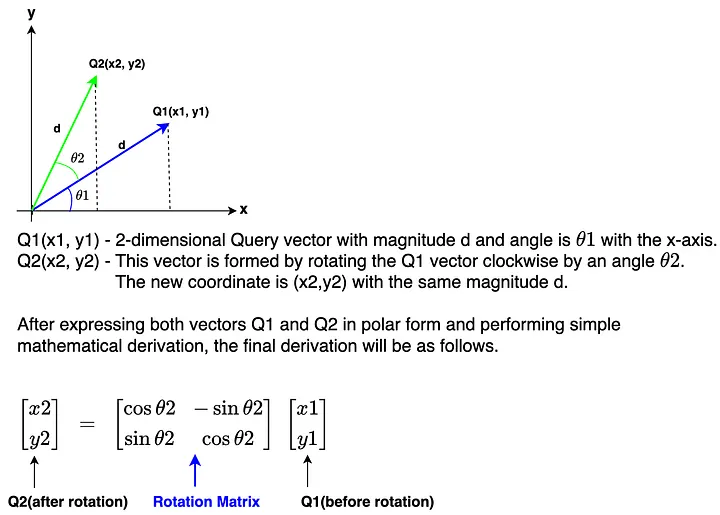
这样做的妙处是:注意力分数 Q·K^T 在经过旋转之后,只跟两个 token 的相对位置有关,与它们的绝对位置无关——因为旋转是线性变换,两个旋转矩阵相乘的结果只取决于它们的旋转角度之差,即 m-n(m 和 n 分别是两个 token 的绝对位置)。这就同时实现了绝对位置编码和相对位置感知。
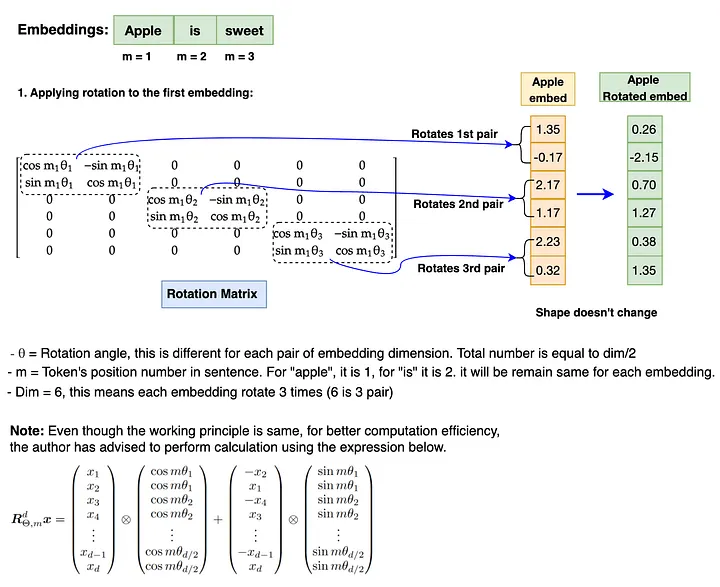
RoPE 的数学实现:
对于位置 m 的 token,每对相邻维度 (2i, 2i+1) 按角度 m × θᵢ 旋转,其中:
这里 base 就是 rope_theta。Llama 3 把 base 从 10000 改成了 500000,使得高频分量(小 θ)变化更缓慢,能更好地处理长序列中遥远位置之间的相对关系。
旋转操作在实数域是矩阵乘法,但在复数域只是点乘,所以实现上会先把 embedding 转成复数,乘以旋转因子,再转回实数:
def precompute_freqs_cis(dim: int, seq_len: int, theta: float = 500000.0):
device = ModelArgs.device
# 计算每对维度的 theta 值:θᵢ = 1 / (theta^(2i/dim))
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2, device=device)[:(dim // 2)].float() / dim))
# 计算序列中每个位置 m 的值
t = torch.arange(seq_len, dtype=torch.float32, device=device)
# outer product 得到每个位置每个维度对的旋转角度:m × θᵢ
freqs = torch.outer(t, freqs).to(device)
# 转成极坐标形式(模=1,角度=freqs),即 e^(i·m·θ) 的复数表示
freqs_cis = torch.polar(torch.ones_like(freqs).to(device), freqs).to(device)
return freqs_cis
def reshape_for_broadcast(freqs_cis, x):
ndim = x.ndim
assert freqs_cis.shape == (x.shape[1], x.shape[-1])
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return freqs_cis.view(*shape)
def apply_rotary_emb(xq: torch.Tensor, xk: torch.Tensor, freqs_cis: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
device = ModelArgs.device
# 把最后一维两两配对,视作复数:[bsz, seq_len, n_heads, head_dim/2]
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2)).to(device)
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2)).to(device)
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
# 复数乘法 = 旋转,然后转回实数并展平最后两维
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3).to(device)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3).to(device)
return xq_out.type_as(xq), xk_out.type_as(xk)特别注意:RoPE 只施加在 Q 和 K 上,不施加在 V 上。这是因为 RoPE 的目的是让注意力分数(Q·K^T)感知相对位置关系,而 V 是被注意力加权聚合的值,不需要位置旋转。
3.3 KV Cache:推理时空间换时间的关键优化
KV Cache 只在推理阶段启用,训练时不需要。理解它的必要性需要先理解自回归生成的过程。
在推理时,模型每次只生成一个 token,但每次生成都要做完整的注意力计算。假设当前已经生成了 t 个 token,要生成第 t+1 个:
没有 KV Cache 的情况: 对 t+1 个 token 做完整的 QKV 计算,每次都要对所有历史 token 重新计算 K 和 V。这些历史 token 的 K 和 V 在上一步已经算过了,完全是重复计算。矩阵乘法的规模是 (t+1) × (t+1),随着序列变长计算量呈平方增长。
有 KV Cache 的情况: 把每一步计算出来的 K 和 V 存下来,下一步直接复用。当前步只需要用最新的一个 Q token,与缓存里所有历史的 K、V 做注意力计算,矩阵乘法变成 1 × (t+1),大幅降低计算量。
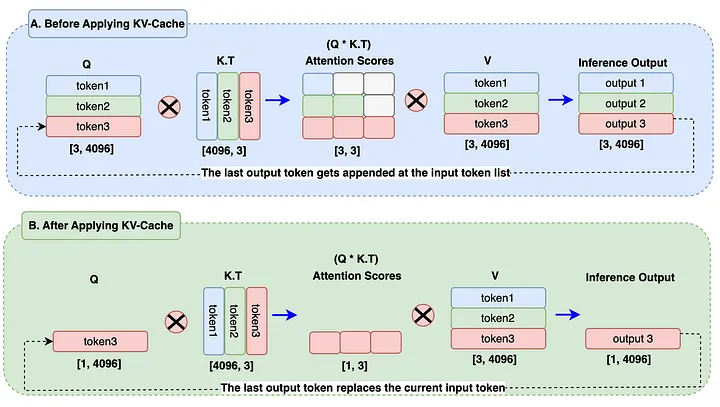
Q 不需要缓存的原因:每一步我们只用当前位置的 Q 来查询,它不会被未来的步骤复用。
# 在 Attention.__init__ 里初始化 KV Cache
self.cache_k = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_kv_heads, self.head_dim), device=args.device)
self.cache_v = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_kv_heads, self3.4 分组查询注意力(GQA):在精度与效率之间找到最优平衡点
Llama 3 把 GQA 从 Llama 2 仅在 70B 模型上使用,扩展到了所有规模(8B、70B、405B)都使用,且不管模型大小,KV heads 数量统一固定为 8。
理解 GQA 需要先理解三种注意力机制的区别:
Multi-Head Attention(MHA):Q、K、V 各有相同数量的 head(比如 32 个)。每个 Q head 都有自己对应的独立 K head 和 V head。KV Cache 大小正比于 head 数量。
Multi-Query Attention(MQA):Q 有多个 head,但所有 Q head 共享同一组 K 和 V(只有 1 个 KV head 对)。KV Cache 大幅缩减,但不同 Q head 之间的表示多样性受限,可能损失模型质量。
Grouped Query Attention(GQA):介于两者之间——Q head 分成若干组,同一组内的 Q head 共享一对 K/V head。Llama 3 8B 有 32 个 Q heads、8 个 KV heads,分组数 = 32/8 = 4,每 4 个 Q head 共享一对 KV head。
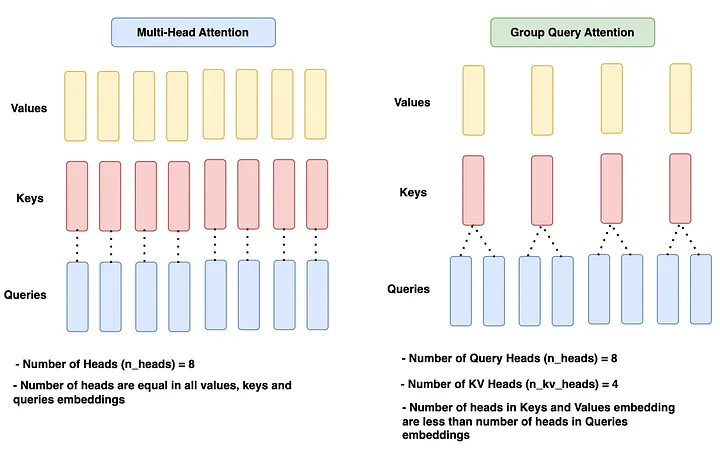
这样做的好处是:KV Cache 从 MHA 的 32× 降到 8×,显存占用大幅减少;但保留了 32 个独立的 Q heads,注意力表达能力不受影响。实验数据表明这个设计在质量和效率之间取得了很好的平衡。
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.args = args
self.dim = args.dim
self.n_heads = args.n_heads
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
self.head_dim = args.dim // args.n_heads
# 每个 KV head 需要被几个 Q head 共享
self.n_rep = args.n_heads // args.n_kv_heads
# Q 的输出维度:n_heads × head_dim
# K/V 的输出维度:n_kv_heads × head_dim(更小)
self.wq = nn.Linear(self.dim, self.n_heads * self.head_dim, bias=False, device=device)
self.wk = nn.Linear(self.dim, self.n_kv_heads * self.head_dim, bias=False, device=device)
self.wv = nn.Linear(self.dim, self.n_kv_heads * self.head_dim, bias=False, device=device)
self.wo = nn.Linear(self.n_heads * self.head_dim, self.dim, bias=False, device=device)
self.cache_k = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_kv_heads, self.head_dim), device=args.device)
self.cache_v = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_kv_heads, self.head_dim), device=args.device)
def forward(self, x: torch.Tensor, start_pos, inference):
bsz, seq_len, _ = x.shape
mask = None
xq = self.wq(x)
xk = self.wk(x)
xv = self.wv(x)
# reshape 到 [bsz, seq_len, n_heads, head_dim]
xq = xq.view(bsz, seq_len, self.n_heads, self.head_dim)
xk = xk.view(bsz, seq_len, self.n_kv_heads, self.head_dim)
xv = xv.view(bsz, seq_len, self.n_kv_heads, self.head_dim)
if inference:
# 推理模式:启用 KV Cache,rope_theta 用论文值 500000
freqs_cis = precompute_freqs_cis(dim=self.head_dim, seq_len=self.args.max_seq_len * 2,
theta=self.args.rope_theta)
freqs_cis = freqs_cis[start_pos: start_pos + seq_len]
xq, xk = apply_rotary_emb(xq, xk, freqs_cis)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos:start_pos + seq_len] = xk
self.cache_v[:bsz, start_pos:start_pos + seq_len] = xv
keys = self.cache_k[:bsz, :start_pos + seq_len]
values = self.cache_v[:bsz, :start_pos + seq_len]
# 把 KV heads 扩展到和 Q heads 一样多,以便做矩阵乘法
keys = repeat_kv(keys, self.n_rep)
values = repeat_kv(values, self.n_rep)
else:
# 训练模式:不用 KV Cache,直接对整个序列做注意力
freqs_cis = precompute_freqs_cis(dim=self.head_dim, seq_len=self.args.max_seq_len,
theta=self.args.rope_theta)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis)
keys = repeat_kv(xk, self.n_rep)
values = repeat_kv(xv, self.n_rep)
# 因果 mask:上三角填 -inf,防止当前 token 看到未来 token
mask = torch.full((seq_len, seq_len), float("-inf"), device=self.args.device)
mask = torch.triu(mask, diagonal=1).to(self.args.device)
# Transpose to [bsz, n_heads, seq_len, head_dim]
xq = xq.transpose(1, 2)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
# 注意力分数 = Q·K^T / √d_k,然后 softmax,然后加权 V
scores = torch.matmul(xq, keys.transpose(2, 3)).to(self.args.device) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values).to(self.args.device)
# 把所有 head 的输出拼回来:[bsz, n_heads, seq_len, head_dim] -> [bsz, seq_len, dim]
output = output.transpose(1, 2).contiguous().view(bsz, seq_len, -1)
return self.wo(output)
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""把 KV head 的数量扩展到和 Q head 一样多"""
bsz, seq_len, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (
x[:, :, :, None, :]
.expand(bsz, seq_len, n_kv_heads, n_rep, head_dim)
.reshape(bsz, seq_len, n_kv_heads * n_rep, head_dim)
)这里有一个很容易忽视的细节:因果 mask 在训练时是必须的,因为训练时整个序列一次性并行处理,模型必须被阻止看到未来的 token。而在推理时,因为 KV Cache 的存在,每次只处理一个新 token,天然没有"未来信息泄露"的问题,所以 mask 不需要了。
3.5 前馈网络(FeedForward with SwiGLU)
前馈网络在每个注意力块之后,负责对每个 token 的表示做非线性变换,让模型能学到更复杂的特征。
Llama 3 使用 SwiGLU 激活函数,而非原始 Transformer 里的 ReLU 或 GeLU。SwiGLU 全称是 Swish-Gated Linear Unit,它的前馈计算公式是:
其中 SiLU(x) = x · σ(x)(σ 是 sigmoid),⊙ 是逐元素乘法。和标准的两层 FFN 不同,SwiGLU 用了三个线性变换矩阵(W₁、W₂、W₃),其中 W₁ 的输出经过 SiLU 激活后,作为"门"对 W₃ 的输出进行过滤。
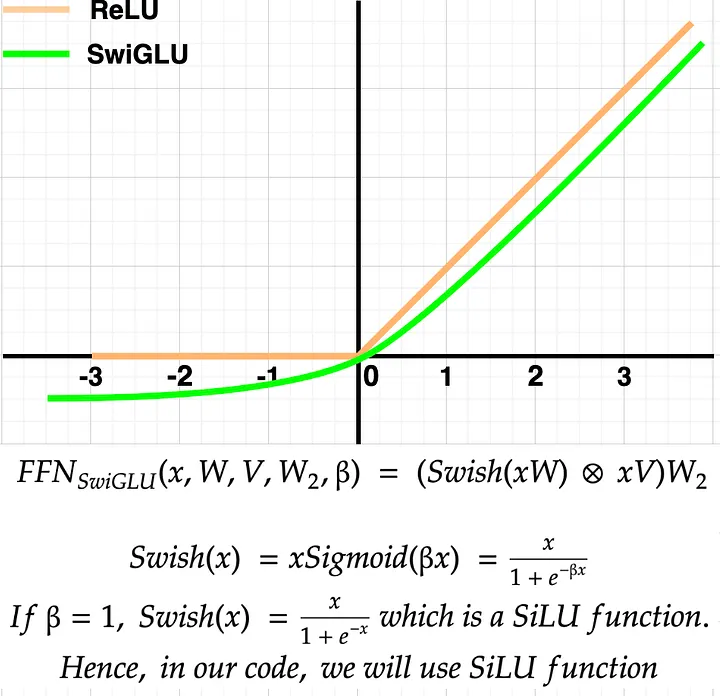
为什么 SwiGLU 比 ReLU 好? 关键在于 ReLU 在负数区域输出全为 0(hard gate),而 SwiGLU 在负数区域有平滑的非零输出,梯度更连续,也保留了一定的负数信息。这种"软门控"机制让模型的表达能力更强,同时训练更稳定。
由于多了 W₃ 这个矩阵,FFN 的参数量相比 ReLU 版本多了约 50%。为了保持总参数量不变,Llama 3 对隐层维度做了调整,论文里用的隐层维度计算公式是 int(2 * hidden_dim / 3) 并取 256 的倍数:
class FeedForward(nn.Module):
def __init__(self, dim: int, hidden_dim: int, multiple_of: int, ffn_dim_multiplier: Optional[float]):
super().__init__()
self.dim = dim
# 按 Meta 的隐层维度计算公式:先缩到 2/3,再取 256 的整数倍
hidden_dim = int(2 * hidden_dim / 3)
if ffn_dim_multiplier is not None:
hidden_dim = int(ffn_dim_multiplier * hidden_dim)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = nn.Linear(self.dim, hidden_dim, bias=False, device=device) # gate 路径
self.w2 = nn.Linear(hidden_dim, self.dim, bias=False, device=device) # 输出投影
self.w3 = nn.Linear(self.dim, hidden_dim, bias=False, device=device) # value 路径
def forward(self, x):
# SwiGLU: SiLU(W₁x) ⊙ W₃x,然后过 W₂
return self.w2(F.silu(self.w1(x)) * self.w3(x))从论文给出的具体数字来看,Llama 3 8B 的 FFN 隐层维度是 14,336,70B 是 28,672,405B 是 53,248。
3.6 解码器块(TransformerBlock):把所有子模块组装起来
一个完整的 TransformerBlock 按照以下顺序执行:
- 输入 x 先过 RMSNorm(Pre-Norm),再进入注意力层
- 注意力输出和原始 x 做残差连接(Residual Connection)
- 残差连接结果再过 RMSNorm,进入 FFN
- FFN 输出再次做残差连接
用公式写就是:
残差连接是 Transformer 稳定深度训练的关键。没有残差连接,梯度在穿过几十层之后会彻底消失,完全无法训练。残差连接提供了一条高速路,让梯度可以直接从输出层流回输入层。
class TransformerBlock(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.attention_norm = RMSNorm(dim=args.dim, eps=args.norm_eps)
self.attention = Attention(args)
self.ff_norm = RMSNorm(dim=args.dim, eps=args.norm_eps)
self.feedforward = FeedForward(args.dim, 4 * args.dim, args.multiple_of, args.ffn_dim_multiplier)
def forward(self, x, start_pos, inference):
# Pre-Norm + Attention + Residual
h = x + self.attention(self.attention_norm(x), start_pos, inference)
# Pre-Norm + FFN + Residual
out = h + self.feedforward(self.ff_norm(h))
return outLlama 3 的三个规模对应不同的解码器层数:8B 模型有 32 层,70B 模型有 80 层,405B 模型有 126 层。每一层的结构完全相同,只是宽度(dim)不同。
四、输出块(Output Block)与完整模型
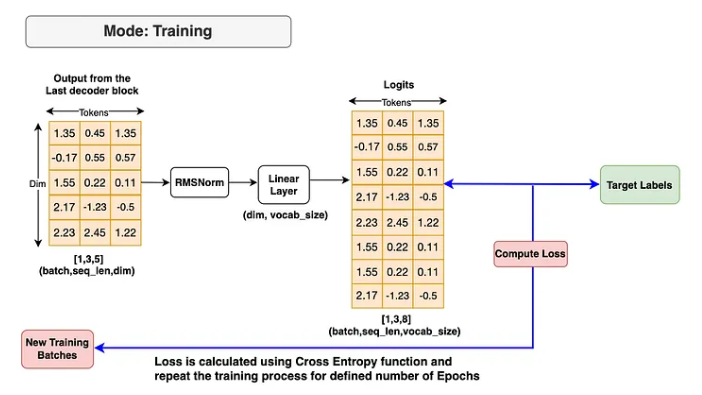
所有解码器块处理完之后,最后的 hidden states 流入输出块:先过一次 RMSNorm,再过一个线性层,把 embedding 维度映射到词表大小,输出 logits。
logits 的每个维度对应词表里的一个 token,softmax 之后就是模型预测下一个 token 的概率分布。
训练时:把 logits 和真实 target labels 传入交叉熵损失函数,反向传播更新所有参数。
推理时:从 logits 对应的概率分布中采样,得到下一个生成的 token。
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
super().__init__()
self.params = params
# 输入层:token id -> embedding vector
self.tok_embeddings = nn.Embedding(params.vocab_size, params.dim)
# 解码器堆叠:n_layers 个 TransformerBlock
self.layers = nn.ModuleList()
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(args=params))
# 输出层
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = nn.Linear(params.dim, params.vocab_size, bias=False)
def forward(self, x, start_pos=0, targets=None):
# x: [bsz, seq_len] -> h: [bsz, seq_len, dim]
h = self.tok_embeddings(x)
inference = targets is None
for layer in self.layers:
h = layer(h, start_pos, inference)
h = self.norm(h)
# h: [bsz, seq_len, dim] -> logits: [bsz, seq_len, vocab_size]
logits = self.output(h).float()
loss = None
if targets is not None:
loss = F.cross_entropy(logits.view(-1, self.params.vocab_size), targets.view(-1))
return logits, loss五、训练
在训练流程上,我们用 80% 的数据做训练,10% 做验证,10% 做测试。每次随机采样一个 batch,输入是从 <|begin_of_text|> 开始的序列,目标是把这个序列向右移动一位(即每个位置预测下一个 token)。
dataset = torch.tensor(encode(data), dtype=torch.int).to(ModelArgs.device)
def get_dataset_batch(data, split, args: ModelArgs):
seq_len = args.max_seq_len
batch_size = args.max_batch_size
device = args.device
train = data[:int(0.8 * len(data))]
val = data[int(0.8 * len(data)): int(0.9 * len(data))]
test = data[int(0.9 * len(data)):]
batch_data = train
if split == "val":
batch_data = val
if split == "test":
batch_data = test
ix = torch.randint(0, len(batch_data) - seq_len - 3, (batch_size,)).to(device)
# x:<|begin_of_text|> + 正文前 seq_len-1 个字符
x = torch.stack([torch.cat([token_bos, batch_data[i:i + seq_len - 1]]) for i in ix]).long().to(device)
# y:正文后 seq_len-1 个字符 + <|end_of_text|>(即 x 右移一位)
y = torch.stack([torch.cat([batch_data[i + 1:i + seq_len], token_eos]) for i in ix]).long().to(device)
return x, y
@torch.no_grad()
def evaluate_loss(model, args: ModelArgs):
out = {}
model.eval()
for split in ["train", "val"]:
losses = []
for _ in range(10):
xb, yb = get_dataset_batch(dataset, split, args)
_, loss = model(x=xb, targets=yb)
losses.append(loss.item())
out[split] = np.mean(losses)
model.train()
return out
def train(model, optimizer, args: ModelArgs):
epochs = args.epochs
log_interval = args.log_interval
device = args.device
losses = []
start_time = time.time()
for epoch in range(epochs):
optimizer.zero_grad()
xs, ys = get_dataset_batch(dataset, 'train', args)
xs = xs.to(device)
ys = ys.to(device)
logits, loss = model(x=xs, targets=ys)
loss.backward()
optimizer.step()
if epoch % log_interval == 0:
batch_time = time.time() - start_time
x = evaluate_loss(model, args)
losses += [x]
print(f"Epoch {epoch} | val loss {x['val']:.3f} | Time {batch_time:.3f}")
start_time = time.time()
print("validation loss: ", losses[-1]['val'])
return pd.DataFrame(losses).plot()
model = Transformer(ModelArgs).to(ModelArgs.device)
optimizer = torch.optim.Adam(model.parameters())
train(model, optimizer, ModelArgs)在 Google Colab 的免费 GPU 上,2500 个 epoch 大约需要 10 分钟,最终 validation loss 在 2.19 左右。这个数字并不算低,原因是我们只用了 Tiny Shakespeare 这个小数据集,且没有做任何超参数调优。真实的 Llama 3 在 15T tokens 上训练,差距是数量级的。
六、推理
推理的核心是自回归生成(autoregressive generation):每次预测一个 token,把这个 token 追加到输入序列,再继续预测下一个,直到生成了最大长度或遇到结束符。
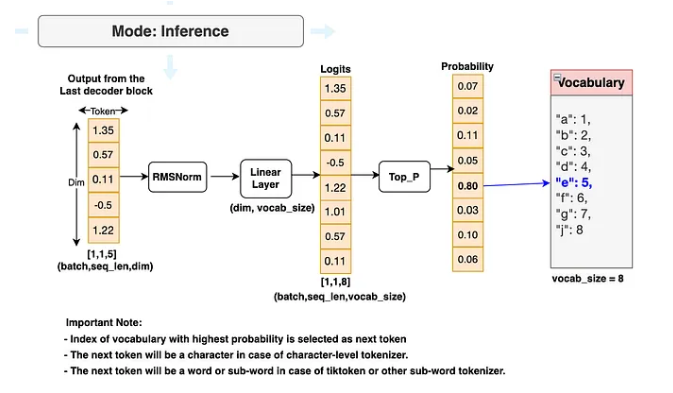
采样策略使用 Top-p(Nucleus)Sampling:按概率降序排列所有 token,找到累积概率刚好超过 p 的最小集合,只从这个集合里随机采样。这比直接取最大概率(贪心解码)生成的文本更有多样性,比完全随机采样又更有质量保证。
Temperature 参数控制分布的"尖锐程度":temperature < 1 会让分布更集中(更保守),temperature > 1 会让分布更平坦(更随机)。
def generate(model, prompts: str, params: ModelArgs, max_gen_len: int = 500,
temperature: float = 0.6, top_p: float = 0.9):
bsz = 1
prompt_tokens = token_bos.tolist() + encode(prompts)
assert len(prompt_tokens) <= params.max_seq_len
total_len = min(len(prompt_tokens) + max_gen_len, params.max_seq_len)
tokens = torch.full((bsz, total_len), fill_value=token_pad.item(), dtype=torch.long, device=params.device)
tokens[:, :len(prompt_tokens)] = torch.tensor(prompt_tokens, dtype=torch.long, device=params.device)
input_text_mask = tokens != token_pad.item()
prev_pos = 0
for cur_pos in range(1, total_len):
with torch.no_grad():
logits, _ = model(x=tokens[:, prev_pos:cur_pos], start_pos=prev_pos)
if temperature > 0:
probs = torch.softmax(logits[:, -1] / temperature, dim=-1)
next_token = sample_top_p(probs, top_p)
else:
next_token = torch.argmax(logits[:, -1], dim=-1)
next_token = next_token.reshape(-1)
# 如果当前位置是 prompt 的一部分,不要覆盖它
next_token = torch.where(input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token)
tokens[:, cur_pos] = next_token
prev_pos = cur_pos
if tokens[:, cur_pos] == token_pad.item() and next_token == token_eos.item():
break
output_tokens, output_texts = [], []
for i, toks in enumerate(tokens.tolist()):
if token_eos.item() in toks:
eos_idx = toks.index(token_eos.item())
toks = toks[:eos_idx]
output_tokens.append(toks)
output_texts.append(decode(toks))
return output_tokens, output_texts
def sample_top_p(probs, p):
# 按概率降序排列
probs_sort, prob_idx = torch.sort(probs, dim=-1, descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
# 找到累积概率超过 p 的截断点,把截断点之后的概率置 0
mask = probs_sum - probs_sort > p
probs_sort[mask] = 0.0
# 重归一化后采样
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
next_token = torch.multinomial(probs_sort, num_samples=1)
next_token = torch.gather(prob_idx, -1, next_token)
return next_token
prompts = "Consider you what services he has done"
output_tokens, output_texts = generate(model, prompts, ModelArgs)
output_texts = output_texts[0].replace("<|begin_of_text|>", "")
print(output_texts)附:论文里的那些工程细节
上面的代码实现覆盖了 Llama 3 的核心架构,但论文里还有几个工程细节值得单独讲一讲,它们是真实生产训练里性能的关键保障,也是理解为什么 Llama 3 能在这么大的规模上稳定训练的原因。
1. 文档级别的 attention mask:论文提到在标准预训练阶段效果有限,但在长上下文继续预训练时至关重要。它的作用是:当多个文档被拼接成一个长序列时,阻止不同文档之间的 token 互相 attend。否则,文档 A 的最后一个 token 会"看到"文档 B 的第一个 token,这会注入本不应该存在的上下文关系,污染长距离依赖的学习。
2. 长上下文预训练:Llama 3 的标准预训练上下文长度是 8K tokens,但 Llama 3.1 的 405B 模型最终支持 128K tokens 的上下文。这不是一步到位的,而是分六个阶段逐步扩展,从 8K 到 128K,用了约 8000 亿 token 的继续预训练来让模型适应。
3. 退火(Annealing):在预训练的最后阶段,把学习率线性退火到 0,同时把高质量的数学和代码数据的权重调高。论文发现退火让 8B 模型在 GSM8k 上的准确率提升了 24%,在 MATH 上提升了 6.4%。这提示我们:数据质量在预训练的最后阶段比数量更重要。
4. 缩放定律实验:Meta 在确定 405B 这个参数规模之前,跑了大量从 40M 到 16B 参数的小模型实验,建立了 IsoFLOPs 曲线,用幂律关系 N*(C) = A × C^α 来预测最优参数规模。拟合出 α=0.53,A=0.29,据此推算出 3.8×10²⁵ FLOPs 对应的计算最优点约在 402B 参数,最终选择了 405B。这是把科学方法引入工程决策的典型例子。
论文链接:https://arxiv.org/abs/2407.21783
Meta 官方代码:https://github.com/meta-llama/llama3

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 17
17 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)