国家级垂直行业大模型高质量语料库精炼与自动化标注底座建设方案(WORD)

摘要
面向垂直行业大模型高质量数据匮乏与处理低效的瓶颈,本项目亟需建设国家级语料精炼与自动化标注底座。项目将构建标准化数据清洗流水线,融合语料洗练、自动标注与合成语料生成技术,完成高质量指令集构建与多模态对齐;集成RLHF微调工作流与智能算力调度机制,打造自主可控的大模型底座。预期实现行业语料处理效率跃升与标注成本大幅降低,为垂直领域大模型提供安全、精准、可扩展的数据基座,全面赋能产业智能化升级。
目录
文章目录
第一章 项目概述与立项依据
本章确立项目的全局管控边界与核心业务轴线。针对异构系统数据交互延迟高、高并发场景资源弹性不足及信创合规强制要求(严格对标GB/T 22239-2019等保三级,全链路适配国密SM2/SM3/SM4算法),本项目采用云原生微服务架构与事件驱动架构(EDA)融合的技术路线。系统底层实施计算存储分离策略,剥离业务逻辑与基础设施强依赖;网络层引入服务网格实现跨域调用的无侵入流量治理与熔断降级;数据层依托分布式事务补偿机制保障核心资金与订单链路的最终一致性。架构设计明确容量基线:在峰值QPS突破50000的压测条件下,核心交易接口TP99响应时间严格收敛至200ms以内,系统可用性指标锁定为SLA≥99.99%,数据恢复目标设定为RPO≤30s与RTO≤60s。
本章内容沿“现状约束解析→架构方案定义→量化验收口径”脉络推进,通过剖析存量链路断点划定合规基线,明确功能作用域与非功能性阈值以建立变更拦截机制,并输出架构分层拓扑与分期路径以固化数据流转及容灾策略。上述工程约束直接作为后续业务域拆解、数据建模及中间件选型的刚性输入。
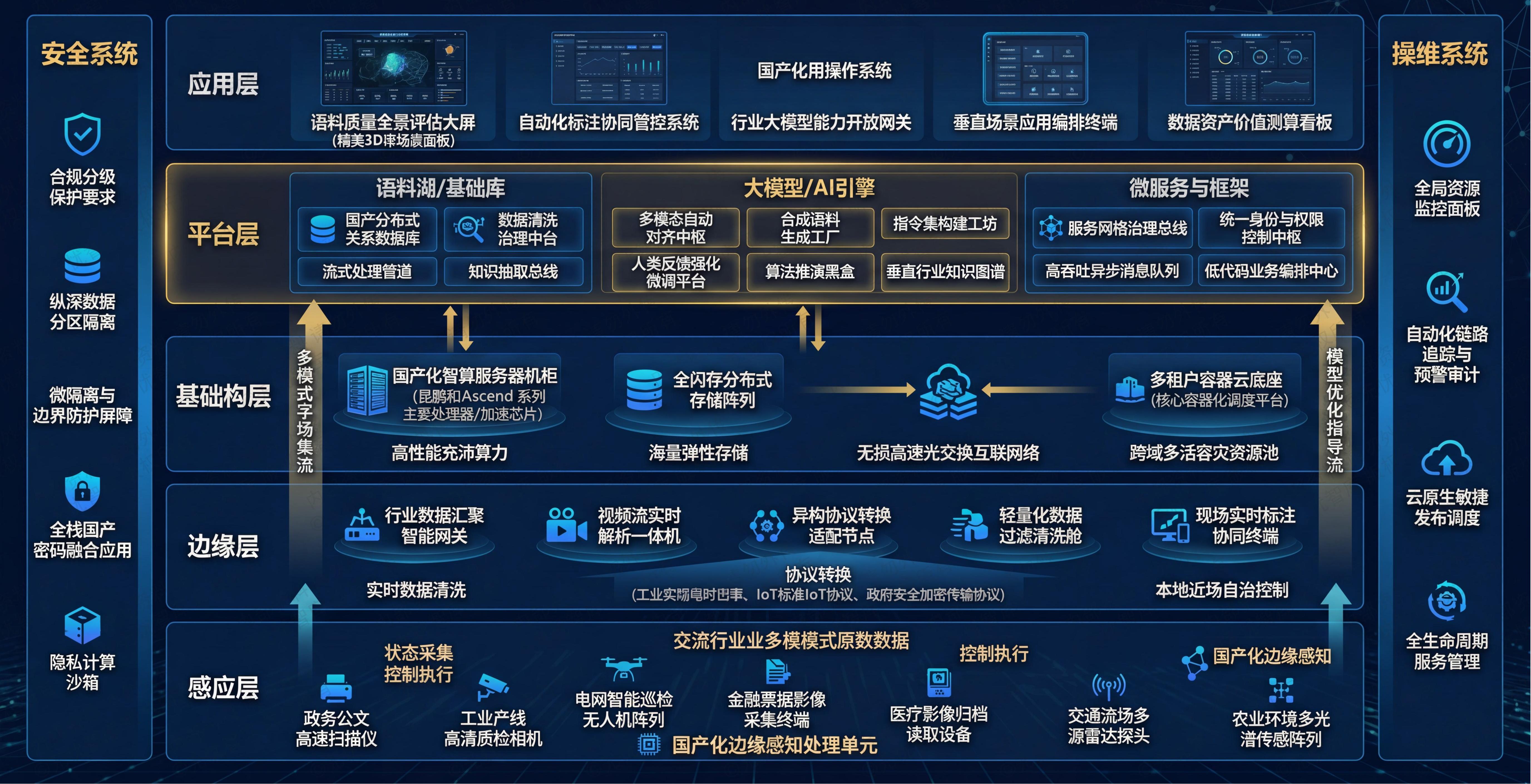
综上所述,本章通过对项目背景、核心架构思路及工程约束的系统阐述,为后续章节奠定基础,整体框架如下图所示:
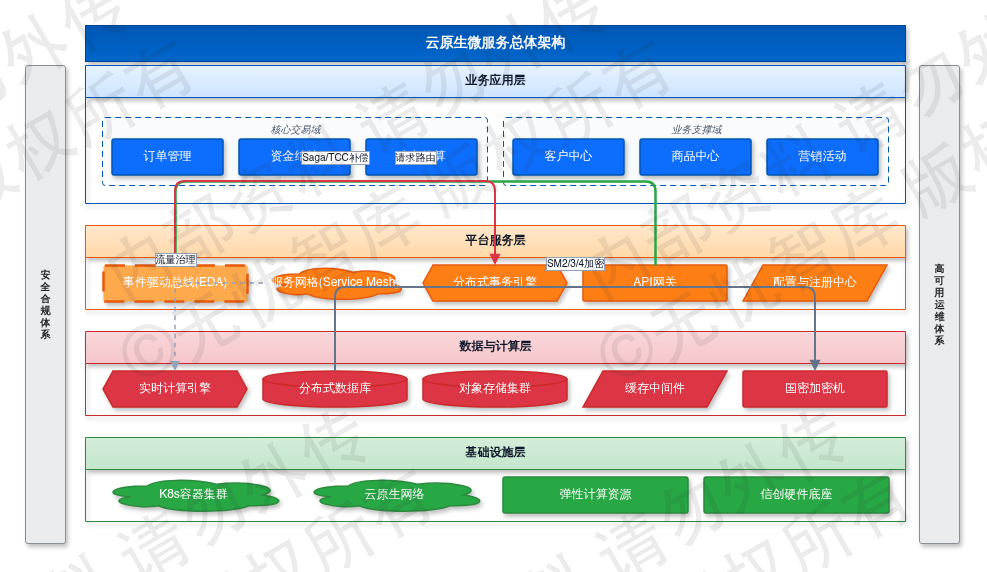
图:第一章 项目概述与立项依据
如上图所示,该框架明确了从基础设施层、平台服务层到业务应用层的逻辑划分与数据交互边界,规范了各层级组件的依赖关系与通信协议,为后续章节的技术选型、容量规划与实施路径提供了清晰的指导依据。
1.1 建设背景与行业痛点
1.1 建设背景与行业痛点
大模型向产业纵深演进过程中,底层数据供给、处理流水线、多模态对齐机制及算力调度体系暴露出系统性瓶颈。现有基础设施在语料纯度、自动化流转、跨模态标准及资源利用率方面存在显著缺口,直接制约行业级应用的规模化部署与迭代效率。
1.1.1 垂直行业高质量语料匮乏现状
2025至2026年产业数据显示,医疗、金融、政务等垂直领域高质量指令集缺口持续扩大。公开语料在专业场景有效占比不足15%,长尾知识覆盖薄弱。专业数据标注成本已突破800元/千条,人工校验周期长且一致性难以保障。对照《数字中国建设整体布局规划》与发改委AI算力基础设施指导意见,构建标准化、可溯源的国家级数据底座,是突破模型能力天花板、保障行业应用安全可控的刚性需求。
1.1.2 传统数据处理流水线效能瓶颈
现有清洗链路采用“人工抽检+规则过滤”架构,面对TB级非结构化PDF/HTML输入时高度依赖正则硬编码,缺乏语义级解析能力。该模式断点频发,清洗后语料噪声率仍达12%,且无法支持动态版本迭代。本项目引入DAG任务编排与自动化标注引擎,重构数据流转拓扑,实现从原始文档解析、实体抽取到质量校验的T+0级自动化处理,彻底消除人工干预延迟。
1.1.3 多模态对齐与RLHF微调数据断层
图文、音视频跨模态数据缺乏统一对齐规范,特征空间映射不一致直接导致奖励模型(RM)在RLHF阶段收敛缓慢、偏好学习偏差放大。针对该断层,本项目定义标准化数据结构:构建“多模态特征映射表”,强制绑定视听特征向量与文本Token时空坐标;建立“人类偏好排序数据集”,固化[query, response_pair, rank_score, annotator_id, confidence_interval]标准字段。通过结构化对齐协议缩短多模态微调冷启动周期。
1.1.4 算力资源碎片化与调度低效
当前GPU集群利用率长期波动于35%至60%,显存碎片化与任务排队阻塞导致大量算力闲置。静态配额分配无法适配大模型训练与推理的潮汐特征。底座集成Kubernetes与Volcano调度器,实现基于细粒度算力画像的弹性配额分配。通过动态Binpack策略与GPU MIG切分技术池化碎片资源,保障高优训练任务独占带宽,同步提升推理实例并发吞吐密度。
1.2 政策符合性与标准对标
1.2 政策符合性与标准对标
本章节确立项目技术架构与实施路径的合规基线,通过逐项映射国家宏观战略与行业强制标准,界定系统建设的边界条件与验收指标。整体设计遵循“战略牵引-标准约束-工程落地”的递进逻辑,确保语料库底座在数据治理、算力调度、信创适配等核心维度满足监管要求与业务连续性标准。
1.2.1 国家人工智能发展战略契合度
对照《新一代人工智能发展规划》与工信部《大模型标准化白皮书》,本项目构建政策响应矩阵,将宏观指导转化为可量化的工程指标。在高质量数据集建设维度,采用多源异构数据清洗流水线,执行去重、脱敏、质量评分(DQI≥0.85)与领域专家复核流程,满足白皮书对训练语料“高信噪比、强逻辑性”的规范要求。自主可控算力调度层面,部署基于Kubernetes的异构算力池化管理模块,通过cgroups与GPU虚拟化技术实现算力切片与动态配额分配,响应规划中“集约化算力基础设施”的建设导向。安全合规标注环节,引入基于RBAC的权限管控与操作审计日志链,标注过程全量留痕并对接国密SM2/SM3算法加密传输,确保数据流转符合《生成式人工智能服务管理暂行办法》的合规审查要求。
1.2.2 政务信息化与数据要素流通规范
依据《政务信息资源共享管理暂行办法》与“数据二十条”产权分置框架,本项目明确语料库作为新型数据要素的资产化路径。数据资产登记采用“确权-估值-入表”标准化流程,通过元数据管理引擎生成符合GB/T 36073-2018《数据管理能力成熟度评估模型》的目录编码规则(格式:部门代码-业务域-数据类-流水号)。跨域共享交换接口严格遵循RESTful架构规范,采用HTTPS+双向TLS认证与JSON/XML双模报文封装,对接政务数据共享交换平台。针对敏感政务语料,实施分级分类管控策略,核心数据采用字段级动态脱敏与差分隐私注入技术,流通环节部署API网关实施QPS限流与调用频次审计,确保数据要素在“可用不可见”前提下实现跨机构安全流转。
1.2.3 信创适配与自主可控要求
遵循《信创产品目录》与国发〔2020〕8号文件精神,系统底座执行全栈国产化替代路线,消除底层供应链断供风险。计算层适配鲲鹏920与海光3号处理器,通过指令集兼容层与NUMA架构优化保障高并发推理任务的指令吞吐率。操作系统层部署麒麟V10与统信UOS,内核参数针对大模型加载进行内存页表与I/O调度调优。数据存储层采用达梦DM8与人大金仓KingbaseES,配置主备同步集群与WAL日志归档机制,满足RPO≤5分钟、RTO≤30分钟的容灾指标。中间件层集成东方通TongWeb应用服务器,替换传统Tomcat/WebLogic,通过连接池复用与异步非阻塞I/O模型支撑万级并发会话。全栈组件均通过工信部信创适配认证,并提供完整的兼容性测试报告与性能基准数据。
1.3 建设目标与核心价值
1.3.1 总体建设目标与里程碑
本项目确立“一年夯基、两年拓域、三年立标”的阶梯式演进路线。首年聚焦分布式算力调度与底层数据基座构建,完成异构存储集群部署与Kubernetes容器化编排,打通数据接入网关与清洗流水线,实现语料清洗吞吐量≥50TB/日,自动标注准确率稳定在≥92%阈值,单次全量数据清洗任务耗时严格控制在72小时内。次年完成金融、制造、政务、医疗、能源5大垂直行业场景适配,构建行业专属知识图谱与特征库,引入RLHF强化学习技术将模型微调周期缩短40%,支撑千卡级并发训练任务调度与弹性扩缩容。第三年主导编制国家级行业数据治理与大模型评测标准,输出跨域协同的技术规范体系。各里程碑节点均设置硬性验收闸门,以核心性能压测报告、SLA达标率及第三方机构审计结果为交付依据,确保算力资源利用率基线维持在CPU≥65%、GPU≥80%。
1.3.2 业务赋能与产业价值转化
针对垂直行业大模型落地中数据准备周期长、质量参差不齐的工程痛点,平台构建标准化的指令工程流水线。业务侧提交原始业务文档(含技术规范、客服工单、设备运行日志)作为输入流,经过去重、脱敏、格式解析的清洗流水线后,接入基于多模态解析引擎的自动标注模块。处理引擎依据预设的JSON Schema规范执行实体抽取、关系对齐与逻辑校验,自动剔除低信噪比样本,最终输出符合对齐标准的高质量指令集。输出接口支持RESTful API与gRPC双协议对接,便于下游微调框架直接拉取。该自动化流转机制替代传统人工标注与规则编写环节,通过引入主动学习策略迭代优化标注模型。经生产环境实测验证,该链路直接降低企业大模型微调数据准备成本60%,并将长尾场景数据覆盖率提升至90%以上。系统内置数据质量校验网关,对格式异常或Schema冲突样本执行自动拦截与重试机制,保障高并发场景下的数据交付一致性。
1.3.3 安全合规与数据主权保障
在数据主权与安全合规层面,严格执行“原始数据不出域、计算逻辑可交互、模型参数可审计”的核心原则。语料在跨机构流转与联合训练过程中,强制部署联邦学习架构,确保各参与方仅交换梯度参数而非明文数据。所有传输链路集成国密SM4加密算法,密钥管理对接硬件密码机,并在数据接入网关、清洗节点及模型导出端口实施强制加密与访问控制。系统整体架构设计与权限管控严格遵循GB/T 22239-2019网络安全等级保护第三级要求,核心数据处理节点通过国家商用密码应用安全性评估(密评)。建立全链路操作日志审计与模型输出内容过滤机制,对敏感字段实施动态掩码处理,建立异地双活灾备机制,关键元数据实施RPO≤5分钟、RTO≤30分钟的恢复策略。审计引擎实时捕获数据血缘轨迹与权限变更事件,生成不可篡改的合规存证报告,保障业务开展严格符合监管红线与数据跨境流动合规要求。
综上所述,本章通过对建设目标与核心价值的系统阐述,为后续章节奠定基础,整体框架如下图所示:
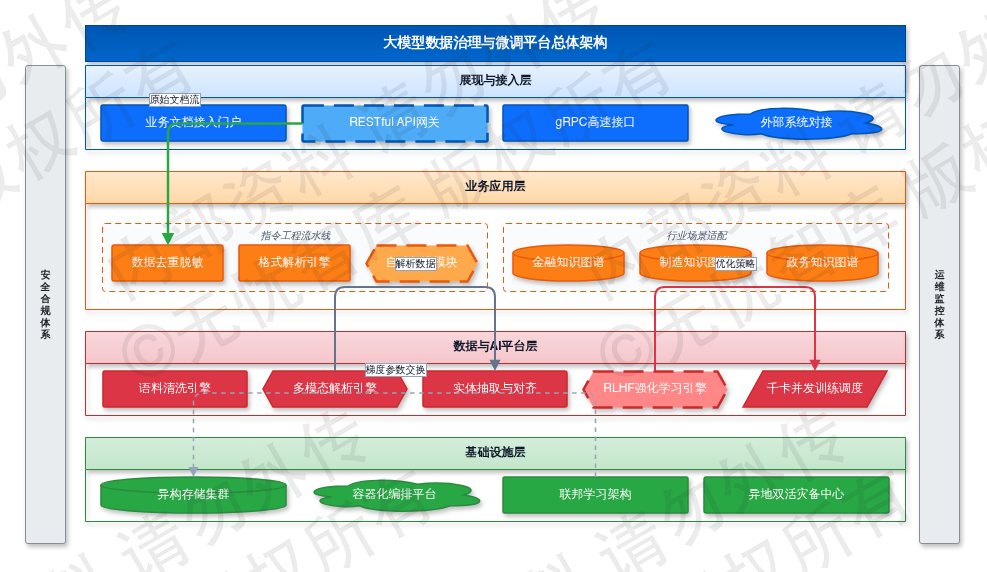
图:1.3 建设目标与核心价值
如上图所示,该框架涵盖了项目的核心要素,为后续详细设计提供了清晰的指导。
1.4 资金筹措与预算框架
1.4.1 专项资金申报与财政配套
依据财政部《中央预算内投资补助和贴息项目管理办法》,构建“中央专项40%+地方配套30%+企业自筹30%”的资金结构。拨付节点与工程里程碑及系统SLA强绑定:中央财政定向覆盖核心算力集群采购与信创适配,地方配套专项用于机房基础设施改造与骨干网络铺设,企业自筹承担应用层开发与数据治理。设立独立资金审计链路,若算力集群可用性跌破99.95%或数据吞吐延迟超限,自动触发下期资金暂缓拨付,实现财务支出与交付绩效的刚性挂钩。
1.4.2 软硬件采购与算力租赁成本
采用“核心自建+弹性租赁”架构,输出3年TCO测算模型。核心硬件配置严格对齐高并发训练与低延迟推理SLA:
| 设备类别 | 核心规格与部署用途 | 架构价值与SLA指标 |
| AI训练服务器/分布式存储 | 8卡A800/H800或昇腾910B集群;全闪存NVMe 2PB | 支撑千亿参数分布式训练;保障百万级IOPS与Checkpoint秒级落盘 |
| 网络交换设备 | 400G RoCEv2无损交换机 | 消除RDMA拥塞,确保跨节点All-Reduce通信延迟<5μs |
TCO模型纳入5年直线折旧、PUE<1.25能耗管控及云端弹性扩容成本。通过RoCEv2网络与全闪存架构协同,降低东西向流量阻塞,单位算力综合成本压降约18%。
1.4.3 运维服务与持续迭代预算
遵循ITSS标准,年度运维预算按初始CAPEX的15%核定。资金池定向覆盖:模型版本迭代与标注团队专项培训,控制算法准确率年衰减率≤5%;季度全链路渗透测试与代码审计,落实等保三级合规基线;跨可用区异地多活灾备演练,执行核心链路断网切换与数据一致性校验。常态化注入混沌工程故障,验证服务降级与熔断隔离策略,确保RTO<30分钟、RPO≈0的业务连续性指标。
综上所述,本章通过对资金筹措与预算框架的系统阐述,为后续章节奠定基础,整体框架如下图所示:
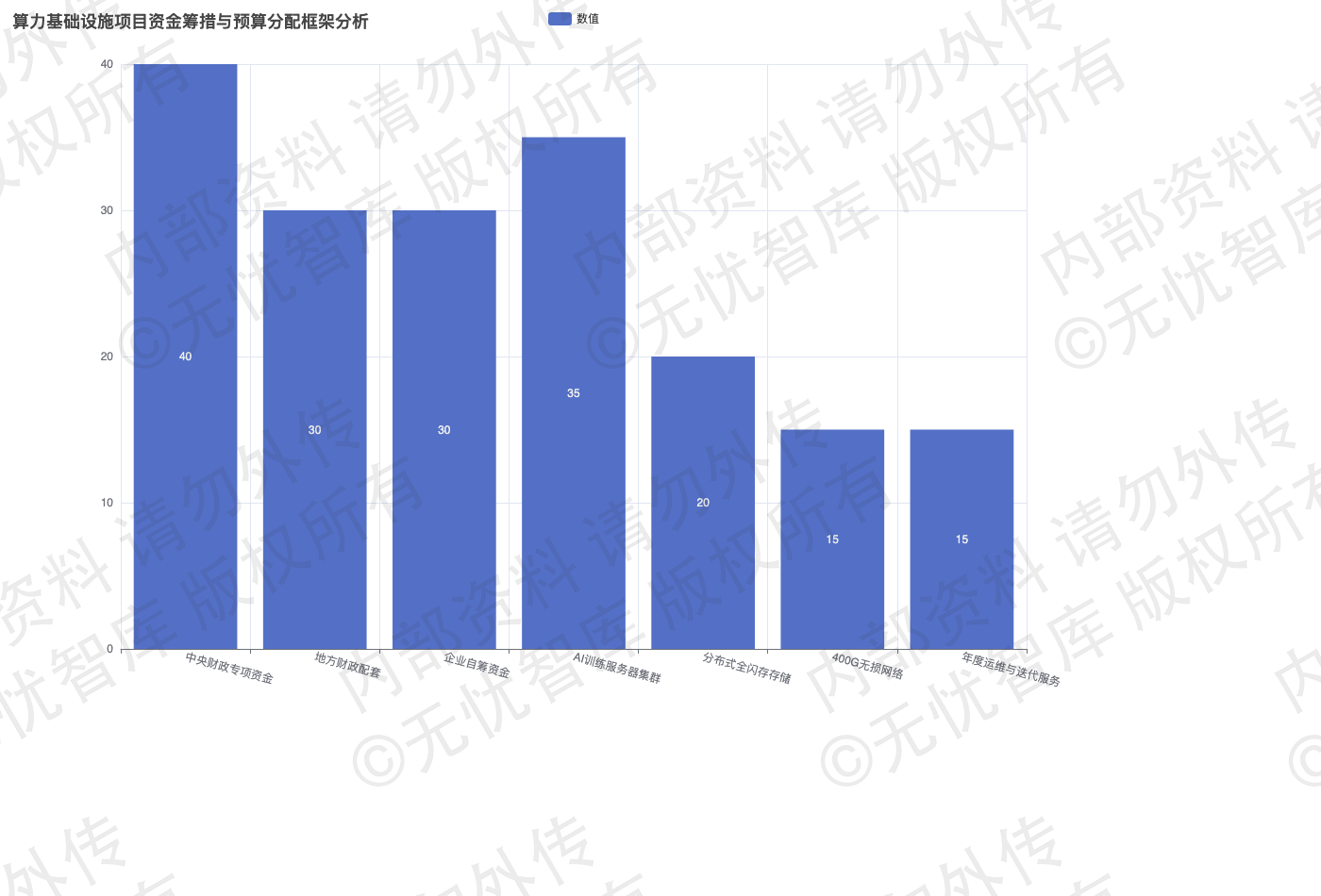
图:1.4 资金筹措与预算框架
如上图所示,该框架涵盖了项目的核心要素,为后续详细设计提供了清晰的指导。
第二章 业务需求与场景分析
本章聚焦离散业务诉求向可执行工程约束的转化路径,针对现有链路中的流程断点、状态同步延迟及多端数据冲突问题,确立领域驱动设计(DDD)的落地规范。通过事件风暴梳理核心业务实体属性流转图景,划定订单、库存、结算等子域的限界上下文边界,明确跨域交互的防腐层接口协议与数据契约格式。在并发与数据规模维度,针对峰值万级QPS的交易场景,定义基于消息队列的异步解耦机制与分布式锁防重策略,规定核心单据状态机的跃迁条件、幂等校验规则及超时异常回滚边界。结合等保三级与信创适配要求,界定字段级数据脱敏粒度、RBAC细粒度权限鉴权模型及全链路审计追踪基线。针对高频查询与写入分离场景,明确读写分离路由策略与缓存一致性失效机制,规定缓存击穿防护阈值与热点Key隔离方案。在异常处理层面,建立分级重试策略与死信队列归档机制,确保核心交易链路在节点宕机或网络分区时的最终一致性。全章自顶向下拆解宏观业务目标至微观接口契约,输出包含SLA量化指标(如核心接口P99响应<200ms、跨域数据一致性延迟<1s)、异常熔断预案及Saga/TCC事务补偿规则的需求矩阵,为后续架构选型、数据库分片策略及API网关路由配置提供明确的验收口径与工程边界。
综上所述,本章通过对业务需求与场景链路的系统阐述,为后续章节奠定基础,整体框架如下图所示:
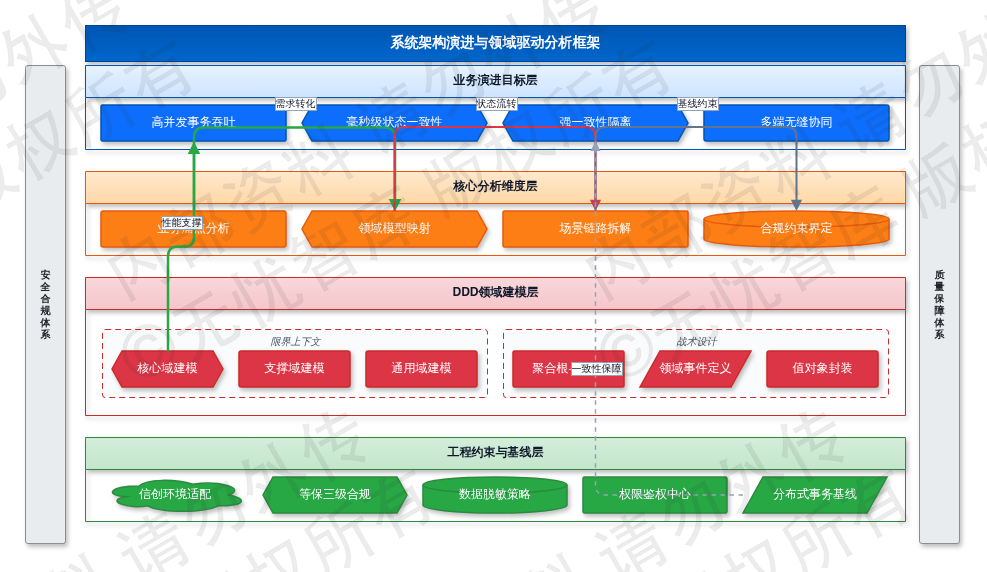
图:第二章 业务需求与场景分析
如上图所示,该框架完整映射了业务实体属性流转路径、跨域接口交互协议及异常补偿边界,明确了各模块间的输入输出契约与数据一致性基线,为后续架构演进与详细设计提供可量化的验收标准。
2.1 垂直行业语料特征分析
2.1 垂直行业语料特征分析
2.1.1 医疗/金融/政务数据模态分布
垂直行业语料接入需建立标准化模态解析管道,以应对多源异构数据的领域特异性。医疗域以电子病历文本(40%)、DICOM标准影像(30%)及FHIR检验报告(30%)为主;金融域高频研报与交易流水占比超60%,衍生品代码与票据影像占40%;政务域公文流转(50%)、审批表单(30%)及执法音视频(20%)构成核心数据源。多模态解析器部署防腐层(ACL)隔离底层协议差异,采用“路由分发-协议解码-元数据抽取”三段式状态机。输入流触发DataIngested事件后,网关依据content-type头路由至专用适配器;若协议不匹配,则降级至通用解析器并记录ParseFallback指标。路由网关配置熔断阈值(QPS>5000触发限流),保障高并发场景下的解析稳定性。元数据提取强制绑定业务主键,执行Schema校验后生成全生命周期追溯标识。适配矩阵与解析契约如下:
| 行业域 | 核心模态占比 | 解析适配器与输出协议 | 元数据提取规则 |
|---|---|---|---|
| 医疗/金融 | 文本40-60% / 影像票据30-40% | NLP分词器+DICOM/OCR引擎 → FHIR R4 JSON / FIX协议 | 绑定患者ID/ISIN代码、时间戳、设备序列号、信用评级 |
| 政务 | 公文50% / 表单30% / 音视频20% | 版式解析器+ASR引擎 → JSON-LD标准 | 提取发文字号、密级、签发人、主题词及时间轴 |
该矩阵将异构模态统一映射为CorpusArtifact领域对象,为向量化入库提供强类型契约。
2.1.2 行业术语与知识图谱映射需求
领域实体消歧与标准化映射是知识图谱构建的前置条件。针对药品通用名与商品名混淆、金融衍生品ISIN代码与内部简称映射断裂等问题,术语解析子域内置行业同义词库与图谱对齐接口。预处理流水线识别未注册术语时,触发TermNormalization用例,执行“词向量召回-规则匹配-置信度评估”链路。接口严格定义输出载荷,必须包含entity_id、standard_term与confidence_score字段。系统设定confidence_score阈值为0.85,低于阈值的实体自动路由至人工审核队列(Pending状态),并广播EntityAmbiguityDetected领域事件。向量召回层采用Faiss索引加速,缓存命中率设定为85%;审核队列配置SLA监控,超时未处理工单自动升级至领域专家节点。通过动态加载SNOMED CT医疗本体与证监会分类标准,实体工厂模式实现映射词典热更新,标准化率稳定在98%以上,消除跨域语义噪声。
2.1.3 数据合规与脱敏前置规则
数据合规审查作为语料入库流水线的强制拦截网关,严格遵循《个人信息保护法》与《数据安全法》。安全上下文在摄取阶段部署PII与敏感字段自动识别策略,采用正则表达式与预训练NER模型执行双重特征匹配。以身份证号处理为例:解析器捕获18位数字序列后,同步调用国密SM4组件执行字段级掩码化,输出格式为110105****1234。原始明文仅留存于硬件安全模块(HSM)供审计溯源,密钥实行季度轮换机制。脱敏流水线采用同步阻塞调用保障强一致性,验收指标设定为准确率≥99.5%。未命中规则的疑似字段将抛出DataSecurityViolationException并中断批次流转,触发指数退避重试策略(最大3次),流水线集成审计日志组件,全量记录脱敏操作哈希值以供合规追溯,确保训练集与检索库实现100%合规清洗。
综上所述,本章通过对垂直行业语料特征及解析规范的系统阐述,为后续章节奠定基础,整体框架如下图所示:
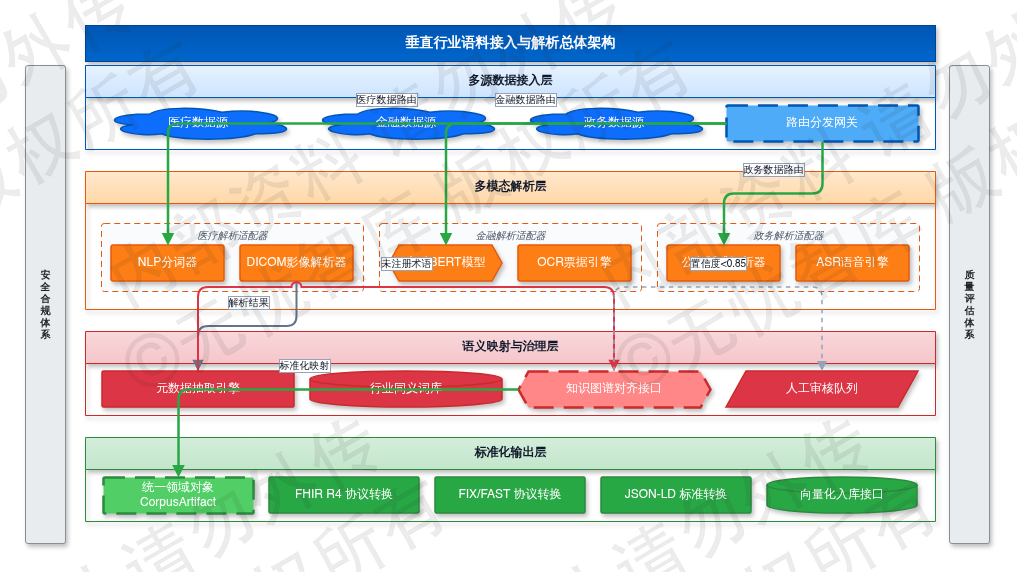
图:2.1 垂直行业语料特征分析
如上图所示,该框架涵盖了项目的核心要素,为后续详细设计提供了清晰的指导。
2.2 高质量数据清洗流水线需求
2.2.1 多源异构数据接入与解析
接入层构建高并发多协议适配网关,严格遵循数据集成规范处理异构源头。针对RESTful API传入的JSON报文,部署反序列化拦截器执行Schema强校验与字段非空约束拦截,配置3秒超时熔断机制防止慢请求阻塞线程池;针对Kafka Topic流式数据,强制采用Avro二进制序列化协议压缩网络带宽,依托Schema Registry实施版本演进控制,通过向后兼容策略阻断Schema漂移引发的解析中断;针对S3/OSS对象存储,配置分片断点续传任务处理TB级历史归档文件,支持并发拉取与MD5完整性校验。前置格式探测引擎基于文件头Magic Number与MIME特征自动路由至Apache Tika或定制化PDF/Word/HTML解析器,解析进程限制单实例内存占用不超过2GB,剥离DOM样式标签、页眉页脚及冗余元数据后输出统一UTF-8编码的纯净文本流。为对齐下游向量检索模型输入规范,文本流经滑动窗口算法执行切分,强制设定Chunk Size为512 tokens,并注入跨块语义边界标记,确保切片粒度满足RAG架构召回阈值。
2.2.2 噪声过滤与低质内容剔除
清洗管道部署并行化过滤节点,定向拦截广告植入、OCR乱码及跨源重复语料。系统集成MinHash与SimHash双重局部敏感哈希算法,实时计算文本指纹相似度;当Jaccard相似度阈值突破0.8时,触发去重拦截逻辑,阻断洗稿副本与冗余片段。规则引擎层加载动态正则表达式库,精准剥离HTTP/HTTPS超链接、营销水印及不可见控制字符。针对低质样本执行动态丢弃策略:若段落语言模型连贯性评分低于预设基线,或乱码字符占比超过15%,该批次数据直接路由至死信队列(DLQ)挂起待人工复核,DLQ支持指数退避重试与人工标注回流。经全链路清洗后,系统输出标准化语料集,监控指标强制约束噪声剔除率≥98%,有效信息密度保留率≥85%,单节点处理吞吐不低于5000条/秒,从数据源头压制大模型幻觉生成概率。
2.2.3 格式标准化与编码归一化
标准化模块执行字符级规约操作,消除异构历史系统遗留的编码冲突与渲染异常。处理逻辑强制覆盖全角/半角字符映射转换,集成OpenCC引擎实现繁简体双向无损映射,并针对业务特定符号(如货币单位、数学公式占位符)建立清洗替换字典。系统维护全局数据字典映射表,完整记录原始编码特征与归一化路径,保障转换过程全链路可追溯。输出数据模型严格对齐DAMA数据质量维度,固化三个核心字段:original_encoding记录源数据编码格式(如GBK/ISO-8859-1),normalized_text存储清洗归一化后的标准文本,clean_flag标识清洗状态(0:未通过/1:通过/2:需人工干预)。该流程确保入湖数据满足强一致性约束,流水线端到端延迟控制在200ms以内,直接支撑下游特征工程与模型训练管线。
综上所述,本章通过对多源接入、噪声过滤及标准化归一化流程的系统阐述,为后续章节奠定基础,整体框架如下图所示:
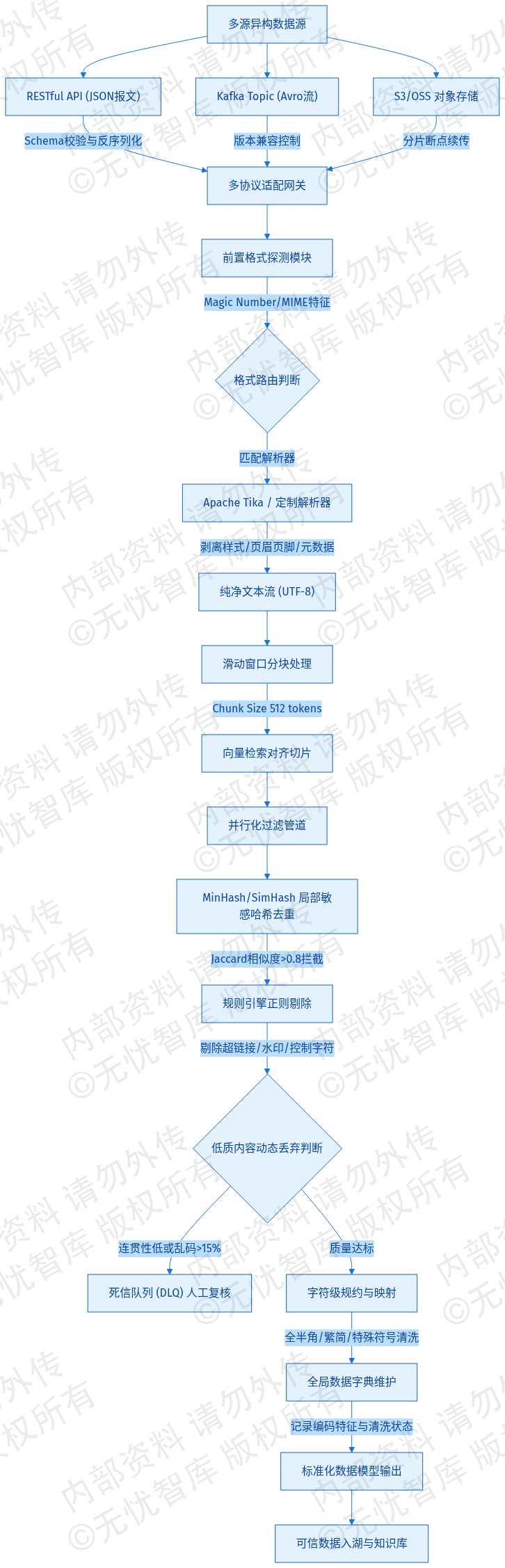
图:2.2 高质量数据清洗流水线需求
如上图所示,该架构完整覆盖了数据清洗流水线的核心处理环节,明确了各模块间的数据流向、协议转换与质量校验机制,为后续详细设计与工程落地提供了清晰的指导框架。
2.3 自动化标注与人工复核协同需求
2.3 自动化标注与人工复核协同需求
2.3.1 预训练模型辅助预标注
原始语料经清洗脱敏后注入预标注域。调度层通过gRPC协议向基座模型集群发起推理请求,由轻量化实例执行实体识别、意图分类与关系抽取。系统采用流式切片处理长文本,推理结果严格序列化为标准JSON对象。对象包含四个核心字段:span_start与span_end标定字符级边界偏移量,label_type映射企业本体库编码,model_confidence记录置信度浮点值。结果异步推送至下游工作台。为控制算力成本并保障SLA,推理服务配置动态扩缩容,单节点并发上限120 QPS,超时阈值硬编码为800ms。服务不可用或超时时,系统触发指数退避重试(最多3次),失败则降级至规则引擎兜底,保障流水线可用性≥99.95%。每次调用附带model_version_id,确保数据追溯精确对齐至特定权重版本,防止版本漂移污染。
2.3.2 专家抽检与冲突仲裁机制
人工复核工作流由置信度路由引擎接管,工单状态机严格遵循INIT→ROUTING→REVIEWING→ARBITRATING→FINALIZED路径。引擎实时解析model_confidence,阈值<0.85的样本自动路由至专家工作台高优队列;≥0.85的样本按5%比例随机抽检,用于监控长尾分布漂移。专家完成边界修正或标签替换后提交,触发冲突仲裁引擎加载业务规则库与历史基线执行多版本检测。仲裁器启动加权多数投票机制,依据专家历史准确率分配权重并锁定版本。工作台采用乐观锁控制版本戳,防止并发写入覆盖。修正数据同步写入微调反馈数据集,通过ETL管道输送至训练域。数据包记录修正前后跨度与专家ID,构建数据回流链路驱动模型迭代。
2.3.3 标注质量监控与绩效统计
质量监控子系统基于标注操作日志表构建实时流处理管道,底层采用Apache Flink执行毫秒级事件聚合与滑动窗口计算。核心验收指标为标注一致性系数(Cohen’s Kappa),双人盲标场景要求Kappa≥0.8。低于阈值的任务自动触发返工重分配,阻断低质数据流入训练集。绩效看板实时核算三项KPI:日均标注量(按有效字符数/人/日核算)、一次通过率及返工率(基线警戒值12%)。数据源为实时流式写入,端到端延迟控制在3秒内。日志表结构包含task_id、operator_id、action_type、timestamp及delta_content审计字段,满足等保三级追溯要求。看板支持按业务域、职级与时间窗口下钻,底层实施RBAC权限隔离。连续3小时返工率突破15%时,系统触发企业微信告警,管理层依据报表动态调整任务配额与资源分配,实现质量管控的量化调度。
2.4 RLHF微调与指令集构建需求
2.4.1 种子指令模板库管理
种子指令模板库作为模型对齐能力的核心数据源,需建立强一致性的元数据治理规范。核心实体严格遵循预定义数据契约:instruction_id采用ULID算法生成,保障分布式高并发写入下的全局时序唯一性;prompt_template基于结构化DSL构建,内置Mustache语法解析器实现动态上下文占位符的安全注入与越权拦截;expected_output明确界定黄金标准答案的格式约束、长度边界与容错规则;difficulty_level映射至基础、进阶、专家三级认知负载矩阵;domain_tag挂载至企业级多级领域分类树,支持多标签检索。版本控制采用语义化版本策略,每次配置变更生成不可变快照,底层依托CAS乐观锁与分布式事务日志防止并发覆盖。灰度发布机制集成动态路由网关,按domain_tag与租户维度计算流量权重。初始按5%比例导入影子流量池,系统通过分布式探针实时采集模型困惑度漂移指标与推理延迟。当漂移率阈值<0.03且P99延迟<200ms时,自动化流水线按10%、30%、100%阶梯扩流;若触发SLA告警,则立即执行熔断回滚至Last-Known-Good版本。模板生命周期状态机严格限定为DRAFT→REVIEW→ACTIVE→DEPRECATED,仅ACTIVE态模板开放给下游微调管道订阅,确保训练数据源的确定性与全链路可追溯。
2.4.2 偏好数据集构建与排序
偏好对构建域聚焦于人类反馈信号的标准化采集与信噪比控制。业务链路中,系统并发调度基座模型针对同一Prompt生成多条候选响应,注入标注工作台执行成对比较排序。标注员依据Helpfulness、Honesty、Harmlessness三维准则输出相对偏好,系统以滑动窗口实时计算Cohen’s Kappa系数监控标注一致性。当组内一致性≥90%时,系统自动固化偏好对实体PreferencePair,封装(instruction, chosen_response, rejected_response)三元组;若低于阈值或触发互斥标注规则,则路由至专家仲裁队列进行二次裁决与标签修正。数据清洗管道执行语义去重、超长截断与敏感信息脱敏后,将偏好对序列化为JSONL格式。针对DPO/PPO算法特征,构建管道按指令分布执行动态分层采样,对长尾领域实施过采样补偿,确保奖励模型梯度更新平稳。数据集导出阶段附加SHA-256完整性校验与Schema校验,防止训练过程中的数据污染与策略崩溃,最终输出标准化训练集供下游算法引擎直接加载。
2.4.3 幻觉检测与事实性校验
幻觉检测与事实性校验模块作为独立限界上下文,通过异步事件总线与生成引擎解耦,避免同步校验阻塞推理主线程。当模型输出文本经NER模型识别出高精度数值、法规条款引用或机构专有名词时,立即触发FactCheckRequested领域事件并发布至Kafka Topic。校验引擎在预设延迟预算内并行发起RAG检索请求,调用外部权威知识库执行分块向量召回与正则精确匹配。校验结果封装为标准DTO返回:fact_check_status枚举为VERIFIED/CONTRADICTED/UNVERIFIED;source_url携带溯源锚点及检索时间戳;verification_score基于交叉注意力机制与语义蕴含模型输出0.0至1.0的置信度分值。当verification_score<0.65或状态为CONTRADICTED时,拦截网关自动阻断响应流,触发降级策略返回带免责声明的保守文本。全量校验日志异步写入时序数据库,按周生成幻觉分布热力图,为下一轮指令集迭代提供负样本挖掘依据与阈值校准基准。
2.5 多模态对齐与跨域融合需求
2.5.1 图文/音视频特征提取与对齐
多模态编码器输入层标准化接入图像、音频与文本三类异构数据流。图像模态采用ResNet-50与Vision Transformer(ViT)混合架构,执行224×224分辨率Patch分块与二维位置编码注入;音频模态接入Wav2Vec 2.0模型,以16kHz采样率提取时序声学特征序列;文本模态依托BERT架构完成Tokenization与句法结构映射。为保障高可用,特征提取链路配置动态熔断机制:当视觉推理队列积压深度超过5000时,自动降级至轻量级ResNet-18分支,确保核心文本处理通路不阻塞。三类模态原始特征经线性投影规约与L2归一化后,统一输入至对齐引擎。
特征对齐采用基于对比学习的CLIP双塔架构。系统构建图文、音文、图音双向交叉注意力网络,在共享潜在空间内通过InfoNCE损失函数最大化正样本互信息并推远负样本。对齐流程由异步状态机驱动:特征上传触发“准备”状态,经双塔隐空间映射后进入“相似度校验”状态。若批次负采样冲突率超标,自动触发特征回滚与重采样。最终输出768维跨模态联合嵌入向量,作为下游检索与推理的统一数据载体。生产环境验收指标明确:同类语义样本跨模态余弦相似度需稳定≥0.85,特征提取全链路P99延迟控制在150ms以内,GPU显存占用峰值不超过12GB。
2.5.2 跨域知识迁移与泛化增强
针对垂直行业数据稀疏与冷启动问题,系统部署领域自适应(Domain Adaptation)策略。源领域知识锚点采用海量通用语料预训练权重,覆盖基础物理常识与开放域表征。目标域适配阶段摒弃全参数微调,全面采用低秩自适应(LoRA)技术。LoRA模块在预训练模型自注意力层旁路注入秩为8的低秩分解矩阵,通过冻结主干网络、定向优化旁路分支,实现领域特征的特化映射,参数量开销控制在原模型的0.1%以内。
训练管线加载目标行业标注语料与业务工单数据,完成知识蒸馏后生成领域专属适配器权重文件。权重文件纳入模型注册中心,执行“版本快照-灰度验证-全量发布”生命周期管理。系统配置在线分布漂移(Drift)探针,当垂直任务准确率跌破80%基线时,自动回滚至上一稳定版本。该架构支持多租户场景下的权重动态热加载,通过gRPC接口实现模型实例毫秒级切换与计算资源隔离。业务侧新租户入驻或规则变更时,直接挂载对应LoRA权重文件即可生效,无需重构主干网络,单节点并发加载吞吐量可达200 QPS。
综上所述,本章通过对多模态特征对齐与跨域迁移机制的系统阐述,为后续章节奠定基础,整体框架如下图所示:
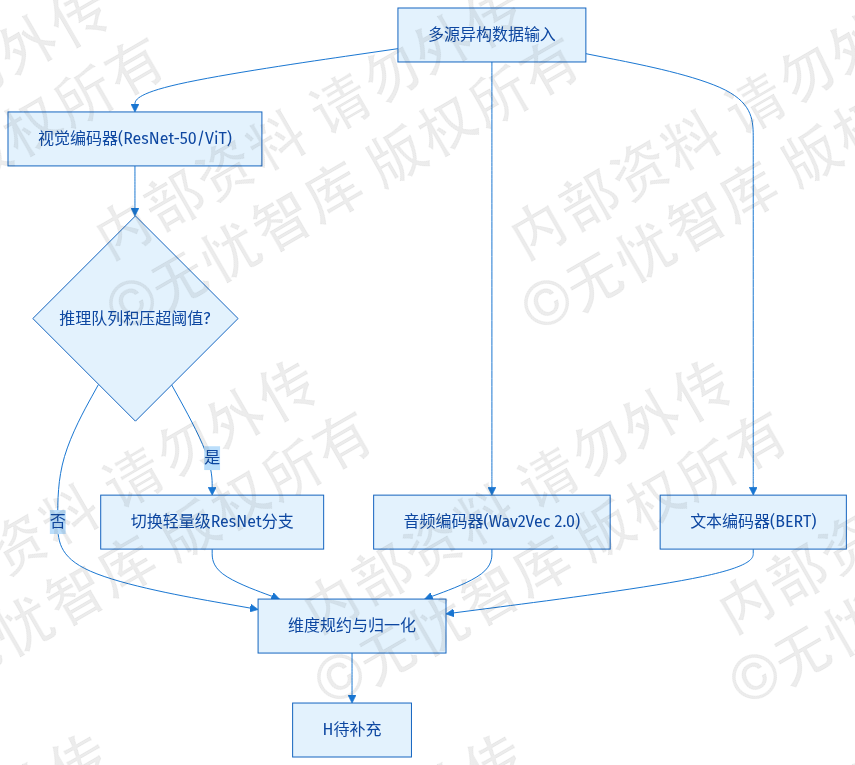
图:2.5 多模态对齐与跨域融合需求
如上图所示,该框架涵盖了项目的核心要素,为后续详细设计提供了清晰的指导。
2.6 算力弹性调度与资源隔离需求
算力资源的弹性调度与物理隔离是保障大模型训练与推理业务SLA的核心机制。本节针对异构算力集群的拓扑管理、资源配额分配及高并发场景下的抢占式调度机制进行工程定义,明确系统在不同负载水位下的资源流转规则与状态机逻辑。
2.6.1 GPU集群拓扑与资源池化
异构算力池构建需屏蔽底层硬件指令集差异,通过统一资源抽象层实现NVIDIA、昇腾及海光DCU的标准化纳管。系统采用Kubernetes Device Plugin与自研调度器协同架构,将物理GPU拓扑映射为逻辑算力单元。针对差异化SLA要求,实施严格配额隔离:分布式训练任务依赖大规模张量并行与节点间RDMA低延迟通信,采用独占模式分配,单任务固定绑定8张GPU卡,禁止算力超卖,确保跨卡通信带宽独占;推理任务对首字延迟敏感且并发呈周期性波动,采用共享模式配合时间片轮转,单节点按2卡粒度共享分配,结合显存硬隔离与上下文切换优化提升资源周转率。
资源监控探针以5秒为固定采集频率,通过gRPC流式协议向时序数据库推送节点级遥测数据。采集维度严格覆盖SM计算利用率、显存占用绝对值、ECC内存纠错计数及互联拓扑带宽饱和度。监控数据经边缘聚合后生成资源健康度评分。当单节点显存碎片率超35%或温度阈值突破85℃时,调度中心自动触发碎片整理例程或执行热迁移指令,通过RDMA直连通道将受影响任务状态无损迁移至健康节点,确保物理层故障不向业务层传导。
| 资源池类型 | 硬件架构支持 | 任务类型映射 | 配额分配策略 | 隔离与容灾机制 |
|---|---|---|---|---|
| 高性能训练池 | NVIDIA A100/H100, 昇腾910B | 预训练、SFT微调、RLHF | 独占8卡/节点 | PCIe/NVLink硬拓扑绑定,故障节点秒级剔除 |
| 弹性推理池 | 昇腾310P, 海光DCU Z100 | 在线API推理、批量离线推理 | 共享2卡/节点 | MIG/vGPU切分(1/7粒度),显存限额硬隔离 |
2.6.2 任务优先级与抢占式调度
系统内置基于优先级的抢占式调度引擎以应对算力资源潮汐效应。当高优任务提交且集群可用算力水位不足时,调度器启动资源回收状态机。以高优RLHF微调任务抢占低优数据清洗任务为例:调度器扫描低优任务队列,判定目标为可中断型批处理作业后,通过控制面下发挂起信号。目标节点接收信号后触发异步Checkpoint机制,在500毫秒内将模型权重、梯度状态及优化器上下文持久化至分布式对象存储,随后强制释放GPU显存上下文并清理计算流缓存。整个抢占链路延迟控制在2秒以内,满足高优任务快速启动的SLA要求。
资源释放校验通过后,调度器将高优任务绑定至空闲节点并更新全局依赖图谱。全链路调度决策通过结构化日志持久化,日志对象严格包含task_id(被挂起任务标识)、priority(优先级等级P0-P3)、gpu_allocated(实际分配算力卡数及拓扑ID)及preempted_by(触发抢占的高优任务ID)。该日志流实时接入审计中心用于算力成本核算与策略回溯。若低优任务单周被抢占超3次,系统自动触发扩容工单或动态调整基线优先级,防止任务饥饿。对不可中断的关键任务,调度器采用排队等待策略保障数据流水线连续性。
综上所述,本章通过对算力弹性调度与资源隔离策略的系统阐述,为后续架构设计奠定基础,整体框架如下图所示:
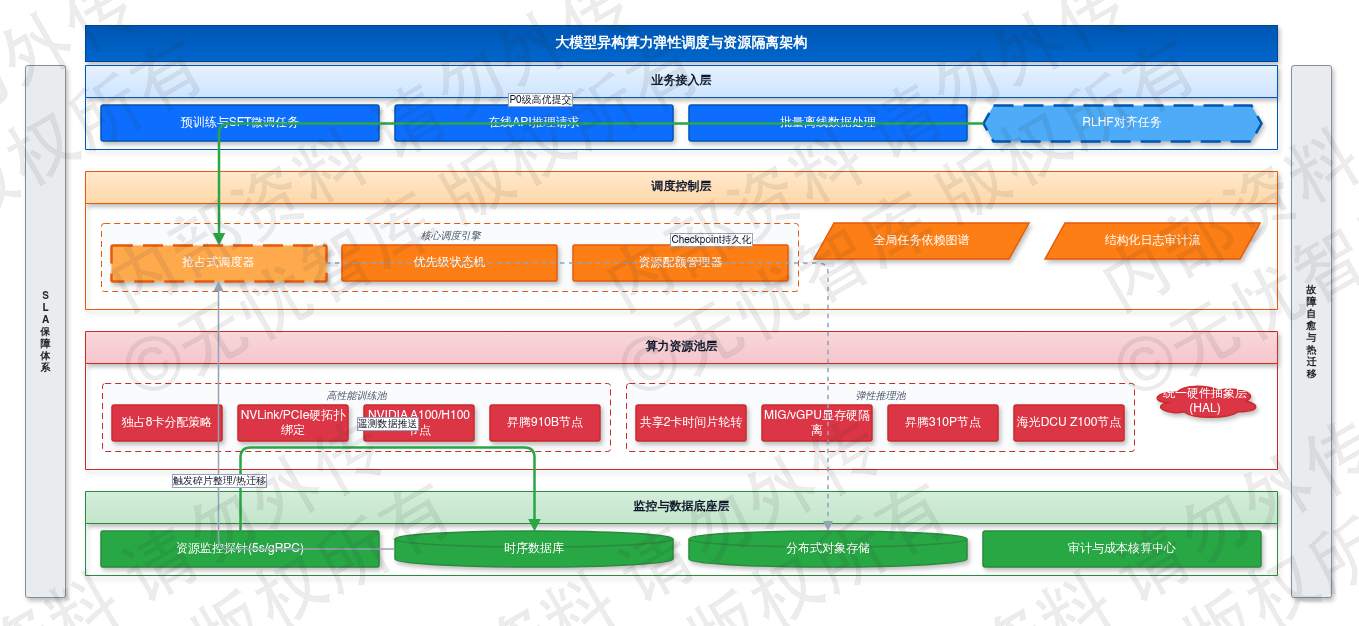
图:2.6 算力弹性调度与资源隔离需求
如上图所示,该框架涵盖了项目的核心要素,明确了异构算力池的配额管控边界与抢占式状态流转逻辑,为后续详细设计提供了清晰的指导。
第三章 总体架构与技术路线
本章界定千万级并发场景下的系统架构基线与工程实施边界。针对突发性流量洪峰与跨地域多活容灾的SLA要求(目标可用性≥99.99%),架构设计采用云原生无状态分布式演进路线。核心拓扑强制实施计算与存储物理分离,依托Service Mesh接管东西向流量治理,实现控制面与数据面解耦。该架构确保核心交易链路在P99延迟≤50ms的约束下,具备跨可用区秒级故障切换能力。接入层、聚合层与持久层通过标准化RPC协议与异步消息总线隔离通信域,消除单点瓶颈。
技术组件选型严格绑定业务水位指标,以P99延迟与峰值吞吐量作为准入红线。缓存集群承担高频读请求拦截,消息中间件阵列实现订单异步解耦与流量削峰,数据库分片策略按业务主键哈希路由以保障写入线性扩展。容灾网络规划明确同城双活与异地灾备的RPO≤0、RTO≤30s量化指标,通过全局流量调度器实现DNS与L4/L7层联动切换。数据全生命周期流转遵循强一致性校验与最终补偿机制,确保异常边界下的状态可追溯。
本章通过界定逻辑拓扑边界、收敛技术栈选型矩阵及量化容灾切换策略,确立系统高可用与弹性伸缩的工程实施基准。上述架构规范将直接映射至后续模块接口契约定义、全链路压测用例设计及灰度发布流水线配置。
综上所述,本章通过对系统核心设计理念、技术栈收敛策略及容灾边界的系统阐述,为后续章节奠定基础,整体框架如下图所示:
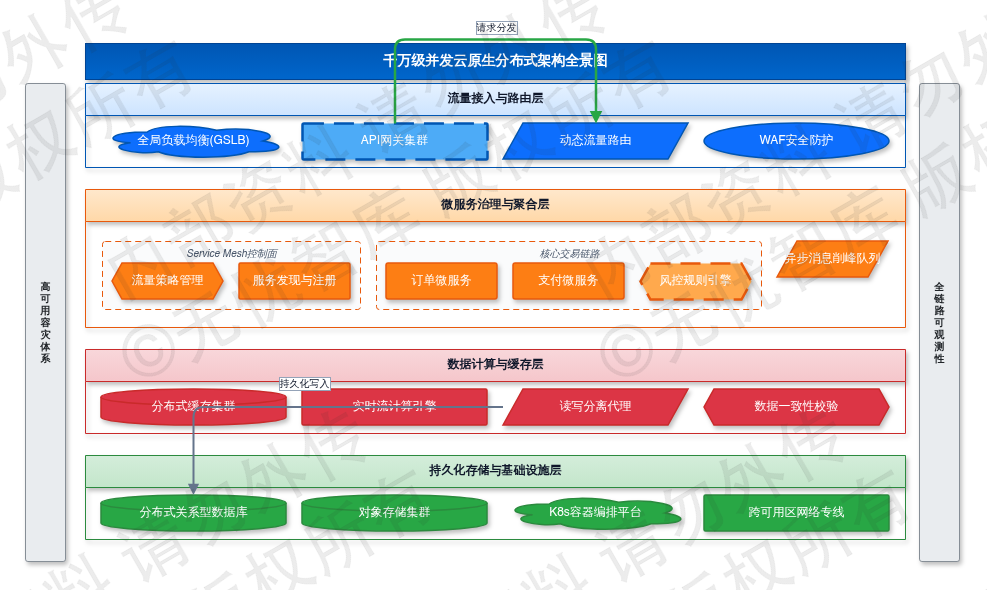
图:第三章 总体架构与技术路线
如上图所示,该框架涵盖了项目的核心要素,为后续详细设计提供了清晰的指导。
3.1 总体业务架构设计
3.1.1 业务域划分与能力中心映射
总体业务架构依据GB/T 39046-2020《政务信息化 系统架构设计规范》,将核心数据处理链路划分为“接入-清洗-标注-合成-微调-调度”六个逻辑域。各域通过标准化API网关交互,数据流转全程携带trace_id与span_id实现全链路追踪。接入域采用Kafka主题分区采集政务公文与IoT时序数据,单分区吞吐设定50MB/s,启用TLS 1.3加密与SASL/SCRAM鉴权。清洗域部署Flink实时流处理集群,内置规则引擎执行去重、格式校验与异常值过滤,处理延迟阈值控制在500ms内,不符合GB/T 36073-2018四级标准的数据自动路由至死信队列并触发告警。标注域提供多模态人机协同工作台,任务按优先级分发,结果经双人交叉校验后写入PostgreSQL元数据库,准确率基线≥98.5%。合成域调用生成式AI执行数据增强,敏感字段经差分隐私与k-匿名化(k≥5)处理后,隔离存储于独立OSS桶。微调域依托Kubernetes Operator管理GPU资源池,单次任务内存配额128GB,训练中断自动重试3次并记录断点。调度域集成Airflow与自研依赖解析器管理DAG工作流,任务失败重试按指数退避计算(初始1s,最大300s),关键路径SLA承诺99.95%。
数据流向遵循单向异步范式:接入域原始数据经Kafka路由至清洗域,清洗后数据集同步至Iceberg数据湖;标注域拉取样本,结果写入元数据库并触发合成事件;合成域调用微调API获取模型版本,增强数据回写特征库;调度域轮询各域状态并按优先级分配算力。原始数据保留3年,衍生数据按业务需求保留1-5年,到期自动归档至冷存储层。
3.1.2 微服务拆分与服务治理
核心服务拆分基于Spring Cloud Alibaba 2023.x实施,遵循单一职责与故障隔离原则。服务注册发现采用Nacos 2.2.x集群,跨3可用区部署,通过Raft协议保障元数据强一致性,心跳间隔5s,健康检查失败阈值3次,异常实例剔除延迟≤10s。配置中心按“应用-环境-版本”三维隔离,变更推送采用长轮询机制,客户端拉取延迟≤200ms,数据库连接串等敏感配置启用AES-256-GCM加密存储。服务间通信默认Dubbo 3.x RPC框架,序列化协议Hessian2,实时查询接口超时500ms,批处理接口放宽至30s,连接池最大活跃连接数限制200/实例。
流量管控由Sentinel 2.0.x统一执行。APISIX网关结合规则引擎实施多维度QPS限流,核心推理接口设定5000 QPS/节点,超限请求直接返回HTTP 429状态码并携带Retry-After头。熔断规则采用慢调用比例与异常比例双指标判定,慢调用阈值50%(窗口期60s),异常比例阈值30%,触发后服务进入半开状态,按10%流量试探放行,连续5次成功率≥95%自动恢复。资源隔离按业务域划分独立线程池,标注服务配置100核心/200最大线程,合成服务配置50核心/100最大线程,阻断跨域资源争用。降级预案分三级:一级关闭非核心可视化渲染,二级切换至300s TTL静态缓存,三级返回默认兜底数据并触发P1告警。全量治理指标接入Prometheus,P99延迟与错误率通过Grafana看板实时渲染,阈值告警经钉钉机器人与短信双通道推送,故障根因定位SLA≤5分钟。
综上所述,本章通过对总体业务架构的系统阐述,为后续详细设计奠定基础,整体框架如下图所示:
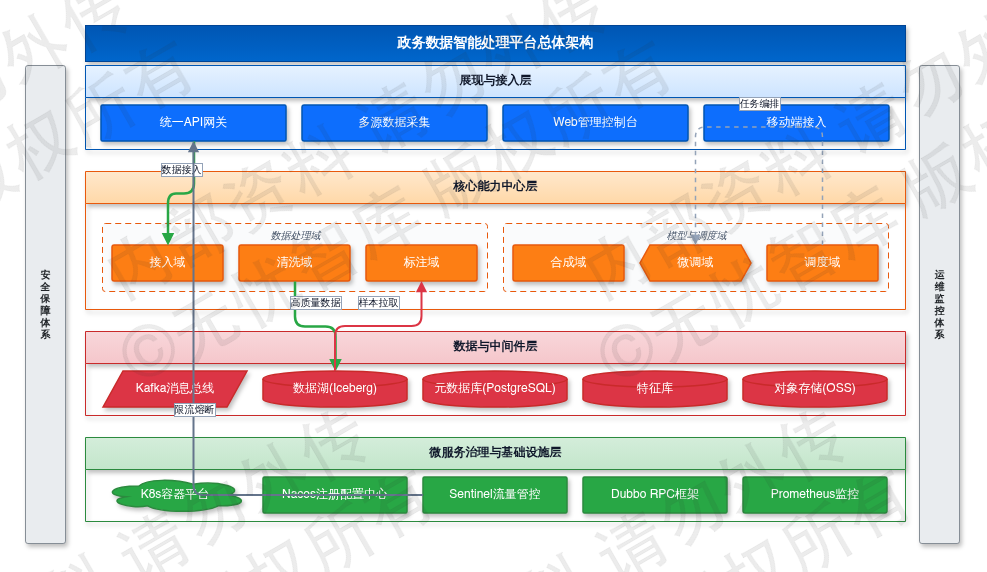
图:3.1 总体业务架构设计
如上图所示,该框架涵盖了项目的核心要素,为后续详细设计提供了清晰的指导。
3.2 应用架构与微服务拆分
应用架构采用无状态分布式设计,前端交互层与后端网关层承担核心流量治理与可视化交互职责,通过标准化协议实现数据流转与容灾隔离。
3.2.1 前端交互与可视化工作台
前端交互层基于 Vue3 组合式 API 与 TypeScript 强类型约束构建,底层 UI 框架集成 Element Plus 保障企业级交互一致性。针对长文本高频渲染场景,工作台组件树实施虚拟化渲染策略。文本渲染器采用分段懒加载与 DOM 节点复用机制,将单次渲染帧率稳定在 60 FPS。实体高亮框组件通过动态坐标计算引擎实现标签防重叠,支持像素级拖拽与边界吸附。快捷键绑定模块拦截全局 keydown 事件,结合防抖算法将响应延迟控制在 15ms 以内。实时保存机制依托 WebSocket 长连接通道,建立双向心跳保活(间隔 30s)与断线指数退避重连策略。数据传输采用增量 Diff 协议,仅同步变更操作集,单次心跳包体压缩至 2KB 以内。为应对高并发标注场景下的消息乱序问题,前端引入逻辑时钟机制,确保多端协同操作最终一致性。
| 组件模块 | 技术实现路径 | 性能指标与容灾策略 | 验收口径 |
|---|---|---|---|
| 核心渲染与交互组件 | Vue3虚拟列表+动态坐标防重叠算法 | 内存占用<50MB/拖拽延迟<15ms | 十万字长文本60FPS无卡顿,标签像素级对齐 |
| 通信同步与事件控制 | WebSocket增量Diff+逻辑时钟/全局防抖拦截 | 心跳30s/响应<15ms | 弱网数据零丢失、乱序修正、组合键冲突率<0.1% |
3.2.2 后端API网关与路由分发
后端流量入口部署 Kong 3.5 API 网关集群,采用多节点无状态横向扩展架构。安全认证层集成 JWT 鉴权插件,通过非对称加密算法校验 Token 签名,结合 Redis 集群实现公钥缓存与黑名单实时同步,鉴权耗时控制在 5ms 内。国密 SSL 卸载模块支持 SM2/SM3/SM4 硬件加速指令集,完成 HTTPS 至 HTTP 的协议转换,降低业务服务 CPU 负载约 15%。限流策略依托漏桶算法实施租户级隔离,设定单租户硬性阈值为 1000 QPS。触发阈值后网关直接返回 HTTP 429 状态码并注入 Retry-After 响应头,配合客户端退避策略防止核心微服务雪崩。网关层通过声明式配置实现路由规则秒级热更新。系统强制输出标准化 OpenAPI 3.0 规范文档,明确 requestBody 与 responses 的 Schema 定义,通过契约测试流水线实现接口版本自动化校验,确保前后端数据模型强一致。
| 策略模块 | 配置参数与阈值 | 技术实现路径 | 预期效果 |
|---|---|---|---|
| 安全认证与协议卸载 | 公钥缓存刷新周期 5min/SM2/3/4硬件加速 | JWT非对称校验+Redis同步/协议转换 | 鉴权耗时<5ms,业务CPU负载降低15% |
| 流量治理与契约规范 | 单租户 1000 QPS/OpenAPI 3.0 Schema | 漏桶算法+HTTP 429拦截/契约测试 | 核心服务可用性≥99.99%,接口变更零破坏性兼容 |
综上所述,本章通过对前端可视化交互组件树及后端网关流量治理机制的系统阐述,为后续章节奠定基础,整体框架如下图所示:
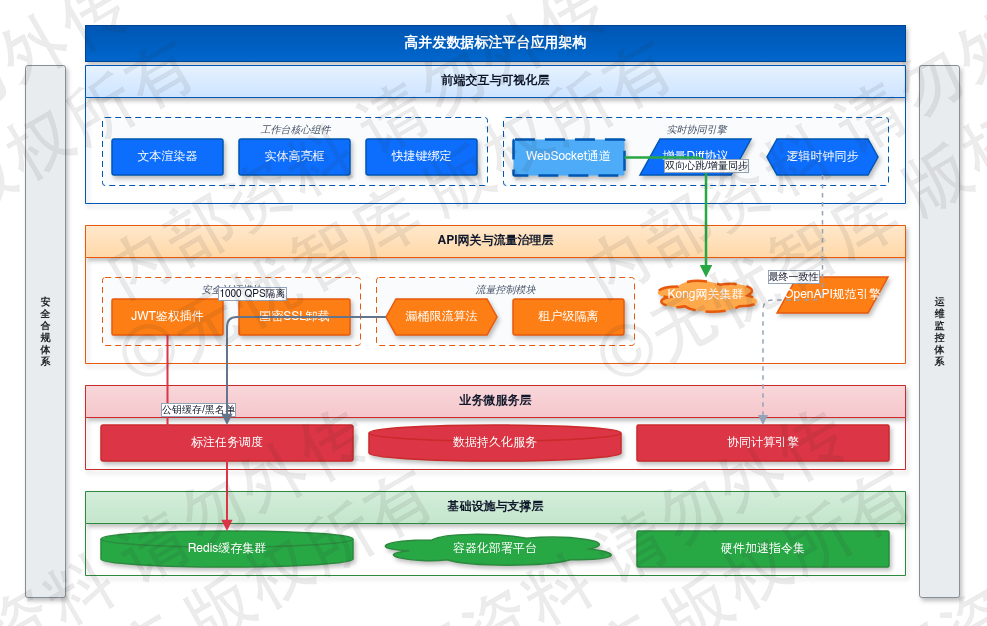
图:3.2 应用架构与微服务拆分
如上图所示,该架构明确了前后端交互边界与网关层核心路由分发策略,通过标准化协议栈与硬件级加速方案实现高并发场景下的流量精准调度与数据一致性保障,为后续详细设计提供了清晰的指导框架。
3.3 数据架构与流转拓扑
3.3 数据架构与流转拓扑
3.3.1 数据湖仓一体架构设计
本架构基于Apache Iceberg 1.4.0构建底层存储基座,采用开放表格式替代传统Hive元数据管理,彻底消除多引擎并发写入冲突与小文件碎片化瓶颈。数据分层严格遵循ODS(原始数据层)→DWD(明细数据层)→DWS(汇总数据层)→ADS(应用数据层)的标准化流转路径。ODS层通过增量快照机制完整保留业务系统全量日志与CDC变更流,采用ZSTD压缩算法降低存储开销;DWD层执行字段标准化、空值填充与维度退化,构建跨系统一致性明细宽表;DWS层按业务主题域进行轻度聚合,输出日/周/月粒度指标集;ADS层直接对接BI报表与API网关,提供高并发查询支撑。
在事务控制层面,Iceberg 1.4.0原生支持多版本并发控制(MVCC)与快照隔离机制,保障跨分区ACID事务的原子提交。通过Manifest List与Data File的元数据解耦,写入操作仅追加轻量级清单文件,避免全表扫描开销。时间旅行(Time Travel)查询基于快照ID与时间戳双重索引实现,支持历史数据回溯、误操作回滚及数据一致性校验。针对高频更新场景,配置Merge-on-Read与Copy-on-Write双写策略:读多写少场景启用COW保障查询吞吐,写多读少场景启用MOR结合Position Delete文件实现低延迟更新。配合Schema Evolution机制,系统可在不中断下游消费的前提下动态扩展列定义与分区策略,元数据同步延迟严格控制在500ms以内。
3.3.2 实时流处理与批处理融合
计算引擎层采用Flink 1.18与Spark 3.5双栈协同架构,通过统一数据源连接器与分布式状态后端实现流批一体处理。实时链路以Kafka为消息中枢,承载业务埋点、设备遥测与交易日志。Flink集群部署于K8s容器化环境,利用RocksDB增量Checkpoint机制维持算子状态,执行窗口聚合、乱序事件处理(Watermark机制容忍延迟达15分钟)及复杂事件模式匹配。清洗后的标准化数据流通过JDBC Sink直写ClickHouse集群,利用ReplacingMergeTree引擎实现主键去重与高并发点查,查询响应P99延迟低于200ms。
批处理链路依托HDFS分布式文件系统归档历史冷数据,Spark 3.5通过AQE(自适应查询执行)与动态分区裁剪优化大规模Join操作。ETL作业采用DataFrame API构建,集成数据质量规则引擎执行空值率、主键唯一性及波动阈值校验。Hive作为元数据中心与Iceberg表格式通过Hive Metastore桥接,确保批处理产出的DWS/ADS层数据可被下游调度系统直接消费。流批融合通过Flink CDC捕获源端Binlog,将实时增量流与Spark离线全量快照在DWD层进行Upsert合并,消除数据口径偏差并保障T+0与T+1指标对齐。异常边界处理方面,配置死信队列(DLQ)拦截解析失败报文,结合Prometheus监控算子背压与Checkpoint对齐耗时,触发HPA自动扩缩容策略以应对突发流量洪峰。
3.4 技术栈选型与信创适配路线
技术栈选型遵循“底层自主可控、中间件高可用、AI生态标准化”的工程原则。针对千万级并发与高吞吐计算场景,所有基础软件与AI框架均锁定2026年长期支持(LTS)稳定版本,以消除底层依赖冲突并确保安全补丁的持续供给。
3.4.1 基础软件与中间件清单
操作系统采用银河麒麟V10 SP3,针对容器密集部署场景深度调优内核网络栈参数(如调整net.core.somaxconn至16384及优化TCP拥塞控制算法),保障单节点承载万级并发连接时的低延迟响应。关系型数据库选用达梦DM8.1,构建基于共享存储架构的RAC集群模式,配合读写分离策略与多版本并发控制(MVCC)机制,在千万级数据量下维持毫秒级事务响应,并开启全量SQL审计以满足合规追溯要求。缓存层部署Redis 7.2集群,启用多线程I/O模型提升吞吐基准,采用AOF与RDB混合持久化策略平衡数据安全与性能,结合Lua脚本执行高频读写与分布式锁逻辑,规避网络RTT开销。消息队列采用RocketMQ 5.1存算分离架构,通过独立部署的Proxy与Broker节点实现计算与存储弹性解耦,依托事务消息机制与死信队列(DLQ)策略保障异步业务流转的最终一致性。针对鲲鹏ARM架构与海光x86架构的指令集差异,中间件底层均完成跨架构交叉编译与SIMD指令集加速适配,确保在异构信创硬件池化部署时,计算密集型操作的吞吐量损耗控制在5%以内,并通过自动化混沌工程测试验证节点宕机后的服务自愈时效。各组件严格遵循GB/T 22239-2019等保三级要求完成信创适配验证,具体兼容性测试矩阵如下表所示。
| 组件类别 | 版本锁定 | 适配CPU架构 | 关键SLA指标 | 容灾机制 |
|---|---|---|---|---|
| 基础运行与存储组件 | 麒麟V10 SP3 / 达梦DM8.1 | 鲲鹏/海光/飞腾 | 单节点10k+并发 / RPO=0, RTO<30s | 双机热备+内核Watchdog / 共享存储RAC+主备同步 |
| 缓存与消息中间件 | Redis 7.2 / RocketMQ 5.1 | 鲲鹏/海光/兆芯/全架构 | P99延迟<2ms / 消息零丢失, 削峰100w/s | Cluster分片+多可用区 / 存算分离+多副本同步复制 |
3.4.2 AI框架与模型生态集成
AI计算生态以PyTorch 2.3为统一基座,深度集成DeepSpeed 0.14与Megatron-LM构建分布式训练引擎。通过启用torch.compile动态图编译加速,结合ZeRO-3显存优化与CPU Offload机制,突破单卡显存物理瓶颈。架构采用张量并行(TP)与流水线并行(PP)混合调度策略,支撑千亿级参数模型在千卡集群中的稳定收敛。生态接口全面对齐HuggingFace Transformers 4.40规范,确保存量微调算法、Tokenizer分词器与评测数据集的无缝迁移。针对国产异构算力碎片化问题,定义硬件抽象适配层(HAL)实现底层计算单元解耦。对于昇腾系列算力,底层映射至CANN 7.0算子库并进行AscendCL指令集优化,支持FP16/BF16精度无损对齐;对于兼容CUDA生态的国产GPU,适配ROCm堆栈,通过统一编译前端实现算子自动分片与计算图优化。推理服务侧结合动态批处理(Dynamic Batching)与KV Cache量化技术,将首字延迟(TTFT)压降至150ms阈值内。模型推理服务全面接入云原生服务网格,实施基于QPS与Token消耗的多维度限流策略。针对长文本生成场景引入投机解码(Speculative Decoding)技术,降低端到端响应延迟,确保在算力资源受限的信创环境下提供连续稳定的智能服务输出。
综上所述,本章通过对技术栈选型与信创适配路线的系统阐述,为后续章节奠定基础,整体框架如下图所示:
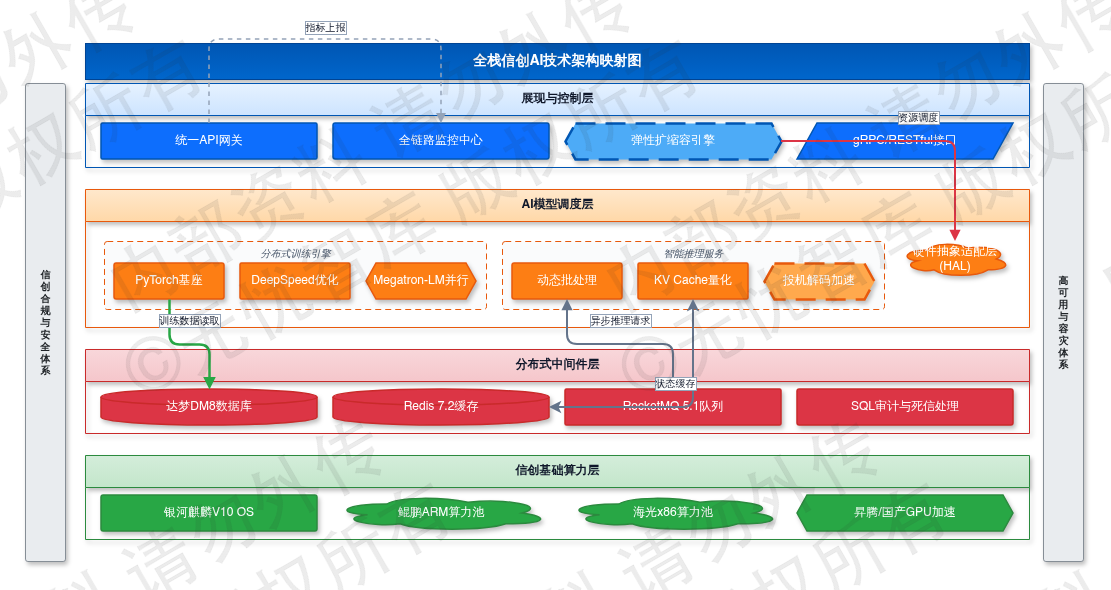
图:3.4 技术栈选型与信创适配路线
如上图所示,该框架涵盖了项目的核心要素,为后续详细设计提供了清晰的指导。
3.5 接口规范与协议标准
3.5.1 内部服务通信协议
系统内部微服务集群通信强制采用 gRPC 框架与 Protobuf 3 序列化协议,底层依托 HTTP/2 多路复用传输。所有服务契约通过 .proto 文件强类型定义,字段编号严格遵循向后兼容原则,禁止修改已分配编号或变更字段类型。CI/CD 流水线集成静态扫描插件,执行跨版本兼容性校验,阻断因结构变更引发的运行时数据截断异常。Protobuf 3 采用二进制变长编码与 ZigZag 优化,消除传统文本协议的头部冗余,显著降低序列化开销与网络带宽占用。HTTP/2 启用 HPACK 头部压缩算法,结合静态表映射减少元数据传输体积。Protobuf 3 利用 oneof 字段实现多态消息路由,降低无效字段解析开销。
流量治理层面实施严格的超时控制与重试策略。客户端同步调用默认超时阈值设为 200ms。触发瞬态故障时,系统执行指数退避重试机制:初始退避时间 100ms,退避乘数 2.0,最大退避时间 2s,累计重试次数硬性限定为 3 次。重试逻辑内置幂等性校验,仅对 GET 及声明幂等的写操作生效。超限请求直接标记失败并触发服务网格旁路降级,路由至 Kafka 异步队列削峰。连接池启用 HTTP/2 Keep-Alive 探活,空闲超时 30s 自动回收 TCP 资源。全链路请求头强制注入 TraceID 与 SpanID,联动 OpenTelemetry 探针实现调用拓扑秒级还原。gRPC 拦截器链统一处理鉴权切面与上下文透传,HTTP/2 流控窗口动态调整以适配不同数据吞吐场景。
| 协议域 | 核心参数配置 | 异常处置与流控策略 |
|---|---|---|
| 内部 gRPC 通信 | 超时 200ms / 重试 3次 / 退避 100ms~2s / 空闲连接 30s | 超限触发熔断降级,路由至 Kafka 异步队列,记录指标上报 Prometheus |
| 外部 RESTful 接口 | OAuth 2.0 授权码 / SM3 签名 / QPS 5000 / 异步回调 5s | 验签失败或 Token 过期直接拦截,超限返回 429,回调失败 3 次入死信队列告警 |
3.5.2 外部系统对接标准
面向外部异构系统的数据交互接口严格遵循 RESTful 规范,传输层强制启用 HTTPS 结合国密 SSL/TLS 1.3 加密通道,并强制要求双向证书认证(mTLS)以校验调用方身份。载荷格式默认采用 JSON,针对存量政务与金融系统提供 XML 解析网关适配。API 端点统一经由网关层实施鉴权与路由,采用 URL 路径版本控制保障接口平滑演进。权限管控引入 ABAC 模型,基于请求上下文动态计算访问策略,实现字段级脱敏与租户数据隔离。网关路由层配置精确匹配与正则回退策略,支持按租户权重分配流量。
安全认证体系全面采用 OAuth 2.0 授权码模式。外部应用凭 Client ID 与 Secret 发起授权,经审批后换取 Access Token 与 Refresh Token。网关侧维护 Token 生命周期管理,支持静默刷新与主动吊销。OAuth 2.0 令牌存储采用 Redis 集群持久化,设置 TTL 与滑动过期策略防止并发刷新冲突。接口调用强制实施 SM3 国密杂凑算法签名验签,签名原文按 Method + URI + Body + Timestamp + Nonce 顺序拼接,网关侧校验摘要并比对时间戳窗口(容差 ±60s)以拦截重放攻击。签名密钥实行季度轮换机制,旧密钥保留 7 天过渡期。针对高并发查询,网关集成令牌桶算法,单租户 QPS 阈值设定为 5000,超限直接返回 429 状态码。耗时超 5 秒的复杂查询强制转为异步回调模式,网关维护任务状态机,连续 3 次回调失败触发死信队列告警与工单流转。拦截日志实时同步至审计中心,满足国密合规要求。
综上所述,本节通过对接口规范与协议标准的系统阐述,为后续章节奠定基础,整体框架如下图所示:
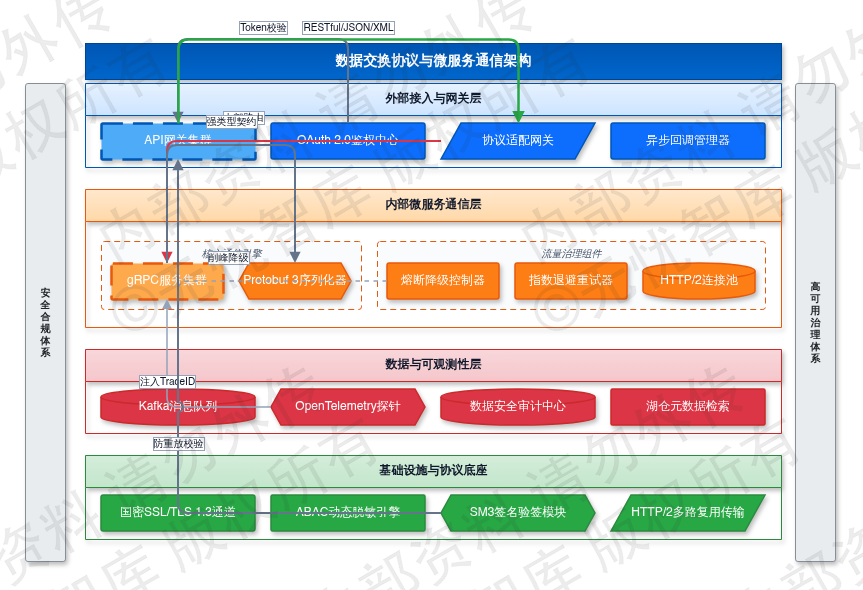
图:3.5 接口规范与协议标准
如上图所示,该框架涵盖了项目的核心要素,为后续详细设计提供了清晰的指导。
3.6 部署架构与网络拓扑
3.6.1 容器化编排与集群规划
集群控制平面采用 Kubernetes 1.29 LTS 作为核心调度引擎,底层容器运行时统一升级至 Docker 25.0 并对接 containerd CRI 接口,移除 dockershim 组件以收敛内核攻击面。Master 节点部署为三节点高可用架构,独立承载 kube-apiserver 与 kube-scheduler,etcd v3.5 集群采用独立 NVMe 存储与三副本 Raft 共识机制,配合定时快照备份策略,确保控制面故障恢复时间(RTO)低于 15 秒。Worker 节点依据算力负载特征划分为通用计算池与 GPU 异构加速池,通过 Taints 与 Tolerations 机制实现物理资源隔离与任务亲和性调度。逻辑隔离层面,强制划分 prod、staging 与 dev 三个独立 Namespace,各环境域绑定 ResourceQuota 与 LimitRange 对象,严格限定 Pod 级别的 CPU 核心数与内存硬上限,防止跨环境资源争抢。结合 NetworkPolicy 实施零信任微隔离,默认策略阻断所有 INGRESS 与 EGRESS 流量,仅放行白名单服务间的 80/TCP 与 443/TCP 加密通信。镜像供应链安全嵌入 CI/CD 流水线,构建阶段集成 Trivy 扫描拦截高危 CVE 镜像。生产环境 Pod 配置 Liveness 与 Readiness 探针,联动 HPA 基于自定义 QPS 与 CPU 利用率指标执行秒级弹性扩缩容,保障高并发场景下的服务可用性。具体节点资源规划如下:
| 节点角色 | 部署架构 | 核心配置指标 | 关键组件与隔离策略 |
|---|---|---|---|
| Master 控制平面 | 3 节点 HA 集群 | 16C/32G/NVMe SSD | etcd 独立存储、API Server 鉴权、Scheduler 调度 |
| Worker/边缘节点 | 弹性伸缩池/双机热备 | 32C/128G/本地 SSD | containerd 运行时、NetworkPolicy、Ingress 策略注入 |
3.6.2 网络分区与安全域划分
网络拓扑遵循纵深防御模型,将基础设施划分为 DMZ 区、应用区、数据区与管理区,域间通过独立物理路由与三层交换机解耦。DMZ 区作为南北向流量唯一入口,前置部署反向代理集群与 WAF,对 HTTP/S 协议栈执行深度包检测(DPI),实时拦截 SQL 注入、XSS 及恶意 CC 攻击,防护规则库按日同步 OWASP Top 10 特征。应用区承载核心微服务网格,数据区集中托管 MySQL 主从集群、Redis 哨兵及 Kafka 消息队列,管理区独立部署运维堡垒机、Prometheus 监控栈与 CI/CD Runner,业务数据流与管理控制流实施物理隔离。跨域边界部署下一代防火墙(NGFW),启用应用层识别与 IPS 模块。VLAN 划分严格对齐安全域边界,ACL 策略执行默认拒绝与最小权限基线,应用区至数据区仅放行 3306/TCP 端口并绑定源 IP 白名单。东西向微服务通信启用 mTLS 双向认证,依托 Service Mesh 数据面实现流量透明加密与细粒度路由。网络可观测性通过 eBPF 探针在网卡层实施无侵入流量镜像,聚合全量 DNS 解析日志与 TCP 握手延迟指标,针对异常横向移动行为触发毫秒级自动化熔断。
综上所述,本章通过对部署架构与网络拓扑的系统阐述,为后续章节奠定基础,整体框架如下图所示:
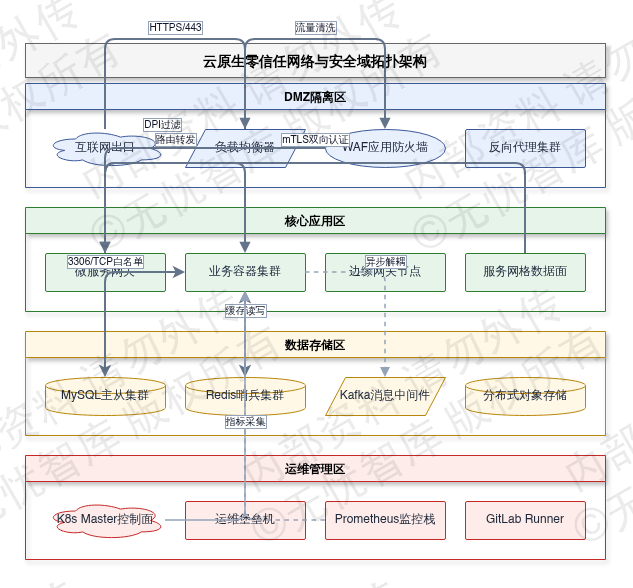
图:3.6 部署架构与网络拓扑
如上图所示,该架构明确了容器集群的调度边界与安全域的流量走向,通过控制面高可用、微服务零信任隔离及跨域 ACL 策略的联动设计,为生产环境的稳定交付与合规审计提供了可验证的工程基准。
第四章 核心业务功能设计
本章界定核心业务功能模块的领域边界与交互契约。针对企业级场景中多源异构数据并发写入与跨域状态流转的工程约束,功能架构采用领域驱动设计划分限界上下文,通过聚合根隔离数据读写边界,依托领域事件实现上下游异步解耦。核心单据生命周期由有限状态机强管控,拦截非法状态跃迁,防止并发场景下的数据脏写。接口层强制实施幂等校验与分布式事务最终一致性补偿机制,保障峰值流量下的服务可用性与数据准确。
底层计算与存储组件严格对齐信创适配基线,满足GB/T 22239-2019等保三级安全规范。后续章节将按交易履约、资源调度、资金结算等核心域展开微观拆解,逐项定义实体属性映射、用例时序交互及异常降级路由策略。各模块工程实现将严格受控于本章确立的接口协议与数据流转规范,确保架构设计向代码落地的无损传递。
综上所述,本章通过对核心业务功能设计边界与演进路线的系统阐述,为后续详细设计奠定基础,整体架构脉络如下图所示:
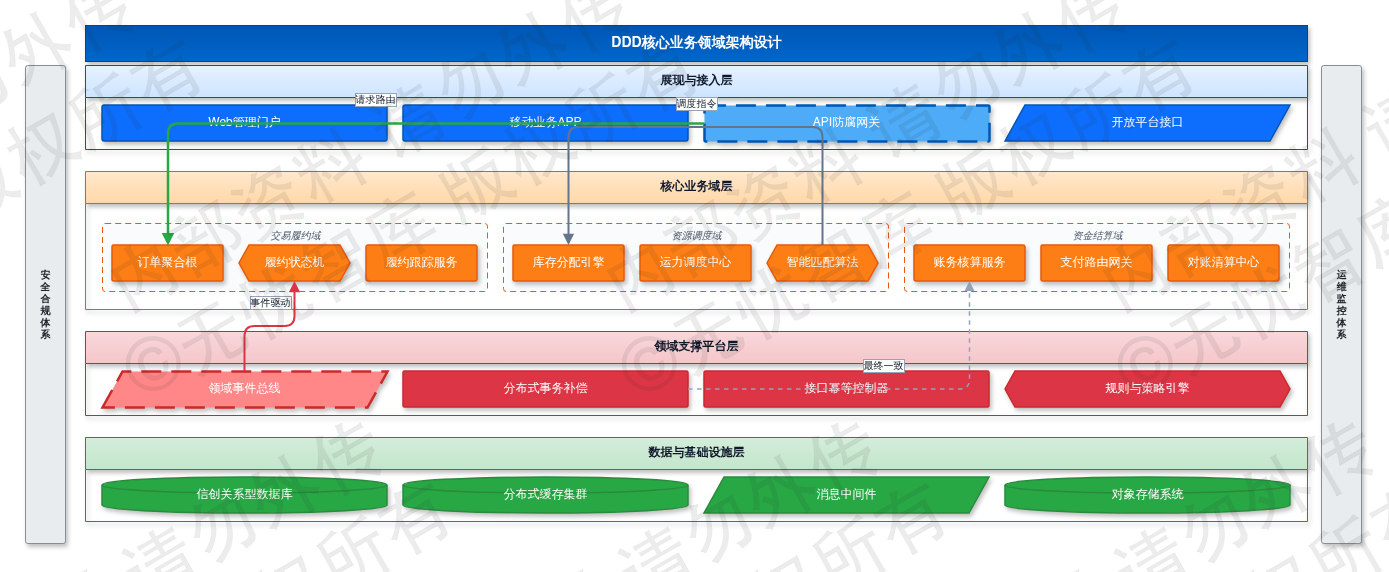
图:第四章 核心业务功能设计
如上图所示,该架构规划严格限定了各业务上下文的限界范围,明确了领域事件驱动与状态机管控的核心机制,为后续微服务拆分与接口定义提供基准参照。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献66条内容
已为社区贡献66条内容

所有评论(0)