序列模型的演进:RNN、LSTM与BiLSTM的架构设计与数学原理深度解析
NLP-AHU-221
引言
本博客的诞生是应自然语言处理课程老师写博客学习的要求。
在自然语言处理和时间序列分析等任务中,传统的深度前馈神经网络面临着一个严峻的局限性:它们假设所有的输入样本都是相互独立的。然而,人类在理解语言时,对当前词汇的理解高度依赖于上文的语境。为了使得神经网络具备处理序列数据和捕捉时间依赖的能力,循环神经网络RNN及其变体LSTM、BiLSTM相继被提出。本文将深入探讨这三种算法的设计启发、内部细节以及严格的数学表达。
1. 循环神经网络
1.1 设计启发
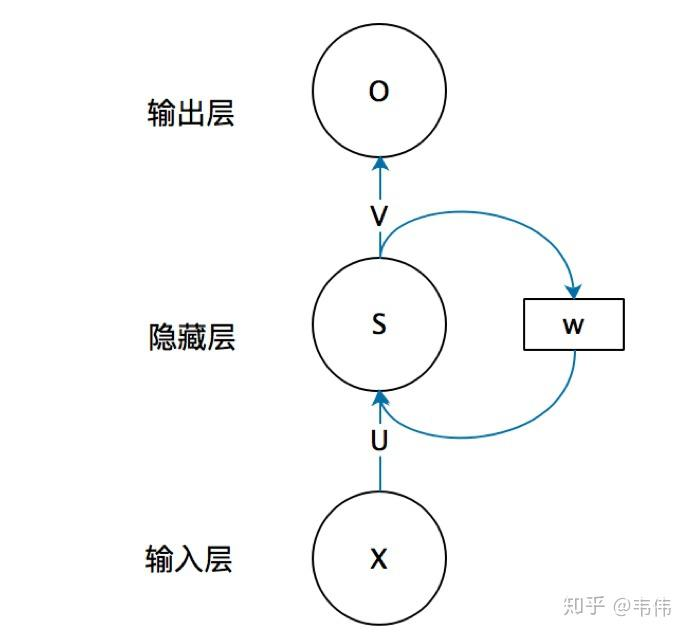
RNN的设计灵感源自于人类认知的“记忆”机制。在处理序列信息时,大脑不仅接收当前的刺激,还会调用之前的记忆状态。因此,RNN的架构核心在于引入了隐藏状态的概念,使得信息可以在时间步之间传递,从而使网络具备对历史信息的记忆能力。
1.2 算法细节
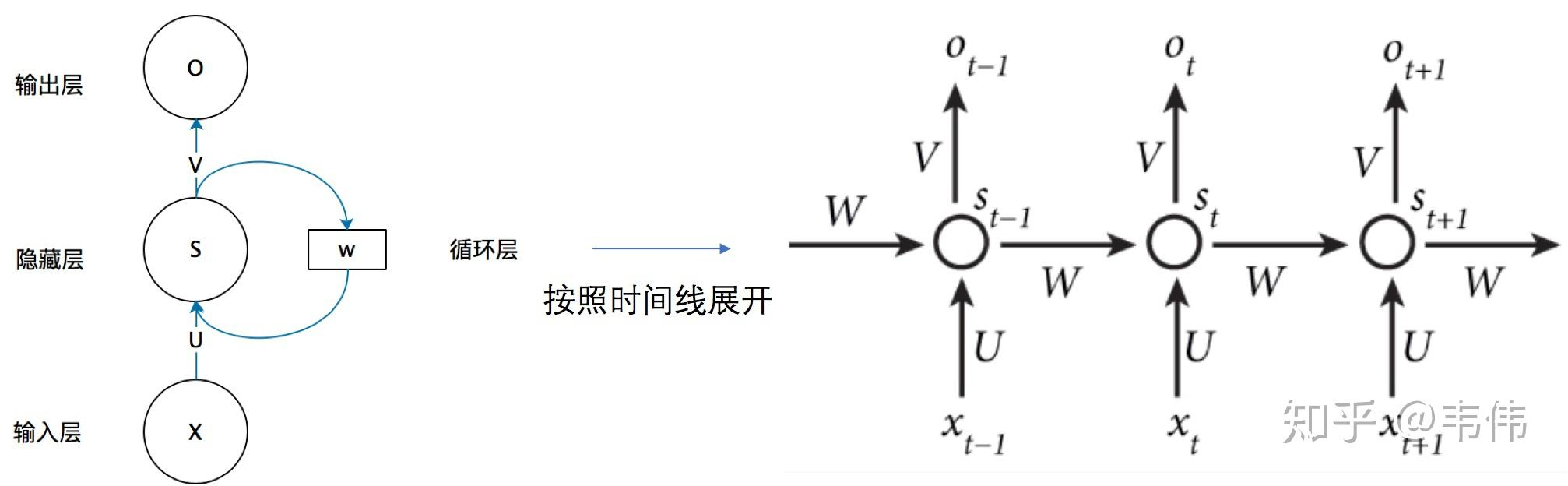
与传统的前馈神经网络不同,RNN在时间维度上引入了自环结构。这意味着隐藏层的输出不仅取决于当前的输入,还取决于上一时刻的隐藏层输出。在序列的推进过程中,RNN在所有的时间步上共享同一套权重参数,这不仅极大地减少了参数量,也使得模型能够处理任意长度的序列。
图1:RNN的循环结构及其在时间维度上的展开
1.3 数学表达
假设在时刻t,序列的输入向量为,前一时刻的隐藏状态为
。RNN的内部计算过程如下:
-
隐藏状态的更新:
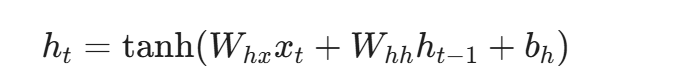
其中,
为输入层到隐藏层的权重矩阵,
为隐藏层状态转移的权重矩阵,
为偏置项。
激活函数用于引入非线性,并将输出值约束在[-1, 1]之间,以防止数值在循环计算中过度膨胀。
-
输出计算:
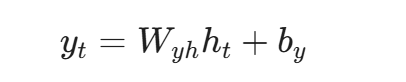
局限性分析:当序列长度增加时,RNN在通过基于时间的反向传播算法进行参数更新时,极易出现梯度消失或梯度爆炸的问题。这导致基础的RNN难以捕捉长距离的依赖关系。随着学习的深入,基础RNN存在一个致命缺陷。当句子很长时,反向传播连乘效应会导致梯度消失。通俗易懂的说,RNN记不住太久远的信息。
2. 长短期记忆网络
2.1 设计启发
为了解决RNN无法长久保存历史信息的技术瓶颈,Hochreiter和Schmidhuber于1997年提出了LSTM。其设计启发来源于人类对信息的选择性处理:大脑会自动过滤掉冗余信息,而将关键信息保留在长期记忆中。LSTM通过引入“门控机制”来实现这种对信息流转的精确控制。
2.2 算法细节
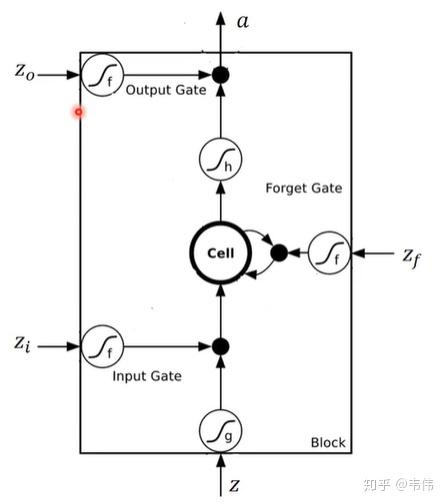
LSTM在RNN的基础上,增加了一个贯穿全生命周期的细胞状态。细胞状态类似于一条主干传送带,信息在其上流动时仅有少量的线性交互,从而保证了梯度能够顺畅地长距离反向传播。
同时,LSTM设计了三个精巧的“门”来保护和控制细胞状态,门结构主要由神经网络层和逐元素乘法操作构成sigmoid输出介于0到1之间,0表示完全阻断,1表示完全通过):
-
遗忘门(Forget Gate):决定细胞状态中哪些历史信息需要被丢弃。
-
输入门(Input Gate):决定当前时刻的哪些新信息将被添加到细胞状态中。
-
输出门(Output Gate):基于当前的细胞状态,决定最终输出给下一时刻的隐藏状态内容。
图2:LSTM单元的内部细节
2.3 数学表达
在时刻t,给定输入x_t、上一时刻隐藏状态以及上一时刻细胞状态
,LSTM的计算全过程为:
-
遗忘门计算:
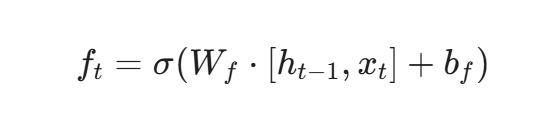
-
输入门与候选状态计算:
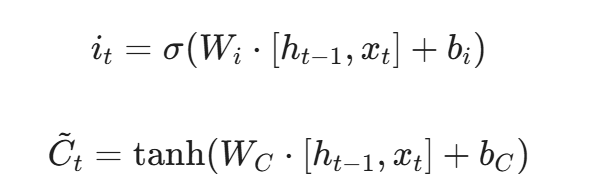
-
细胞状态更新(核心步骤):
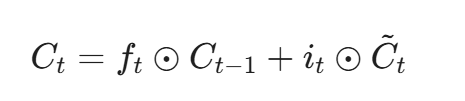
注:
表示Hadamard乘积,即逐元素相乘。该公式完美表达了“遗忘旧信息、吸收新信息”的逻辑。
-
输出门与隐藏状态更新:
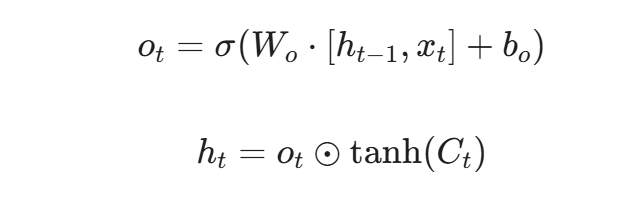
3. 双向长短期记忆网络
3.1 设计启发
标准的LSTM只能按照时间正序(从左至右)处理序列信息,这在许多自然语言场景中是不够的。词汇的语义不仅依赖于上文,同样也受到下文的约束。例如在词性标注中,当前词是名词还是动词,往往需要结合其后面的词汇才能准确判定。BiLSTM的设计初衷便是同时获取当前时刻的过去(上文)与未来(下文)的全局上下文信息。
3.2 算法细节
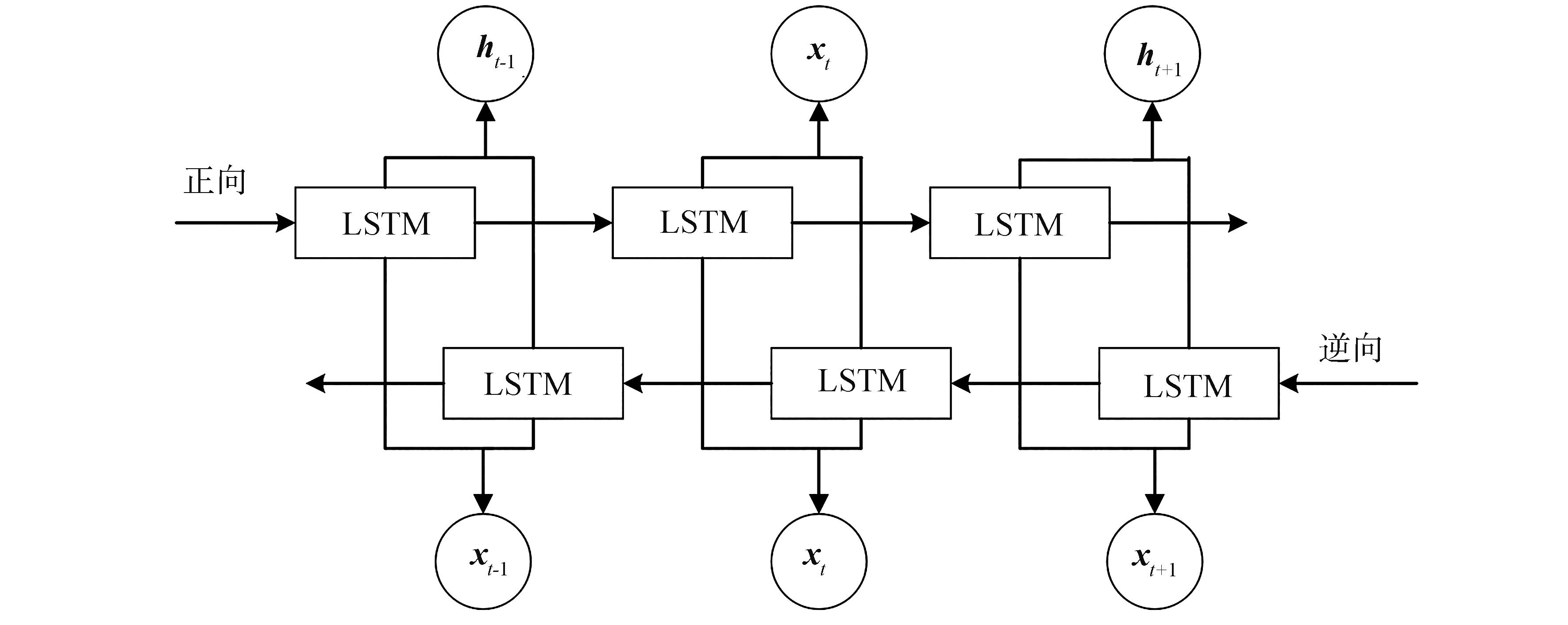
BiLSTM的架构由两个独立的LSTM网络并行构成,它们分别以相反的方向处理输入序列:
-
前向网络(Forward Pass):按照序列的自然顺序(
)进行计算,捕捉过去的上下文。
-
后向网络(Backward Pass):按照序列的逆序(
在每一个时间步t,将前向LSTM和后向LSTM输出的隐藏状态进行拼接,作为该时间步最终的输出特征。
图3:双向循环网络结构,展示了前向层与后向层如何并行处理并融合输出。
3.3 数学表达
对于给定的序列,在时间步t,BiLSTM的数学表达为:
-
前向LSTM隐状态:
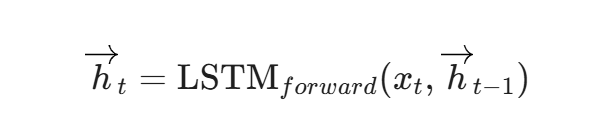
-
后向LSTM隐状态:
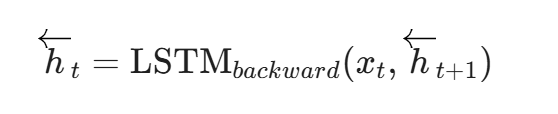
-
全局状态特征融合:
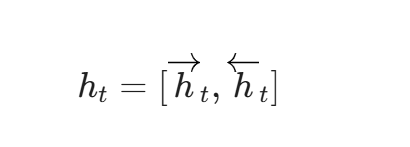
若单向LSTM的隐藏状态维度为d,则经过拼接后,BiLSTM输出的特征向量
维度将扩展为2d。
结语
从RNN的基础时序共享权重,到LSTM通过精妙的门控机制解决长距离依赖,再到BiLSTM引入双向全局视野,序列模型的发展体现了深度学习在模拟语言逻辑与信息流转方面的不断深化。掌握这些基础网络的核心机制与数学原理,是深入学习现代自然语言处理架构不可或缺的基石。总而言之,查完资料后的我的整体认识是:RNN是最基础的,用隐藏状态传信息,但梯度消失让它记不长;LSTM用门和细胞状态解决了这个问题,能学长期依赖;BiLSTM再把正向和反向拼起来,同时利用上下文。这三个是一步步演进过来的,每个新模型都是为了解决前一个的缺点。本次博客作业已完成。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)