【dlib+OpenCV实战:人脸68关键点定位+5种表情(哭/怒/笑)检测】
一、环境准备
在计算机视觉领域,人脸关键点检测是人脸识别、表情分析、美颜滤镜等功能的核心基础。dlib 库提供了预训练的 68 点人脸关键点检测模型,搭配 OpenCV 即可快速实现关键点定位与面部轮廓绘制,无需复杂训练,开箱即用。
本文将手把手带你实现:
1. 人脸 68 关键点精准定位(标注关键点序号)
2. 面部关键区域轮廓绘制(眼睛、嘴巴、脸部轮廓)
3. 完整可运行代码 + 逐行解析
关键模型下载
dlib 需要预训练的关键点模型:shape_predictor_68_face_landmarks.dat
下载地址:https://github.com/davisking/dlib-models
二、核心原理
- dlib 人脸检测器:检测图像中的人脸区域,返回人脸边框
- 68 关键点预测器:在人脸区域内定位 68 个特征点(对应脸部、眉毛、眼睛、鼻子、嘴巴)
- OpenCV 绘制:通过关键点坐标绘制圆点、文字、连线、轮廓
68 关键点分布说明:
- 0~16:脸部轮廓
- 17~21:右眉毛
- 22~26:左眉毛
- 27~35:鼻子
- 36~41:右眼
- 42~47:左眼
- 48~59:嘴巴外轮廓
- 60~67:嘴巴内轮廓
三、代码实例
功能 1:人脸 68 关键点定位
检测图像中的人脸,标注出 68 个关键点,并显示每个关键点的序号,直观展示关键点分布。
import numpy as np
import cv2
import dlib
# 1. 读取图像(替换为你的图片路径)
img = cv2.imread('hg1.png')
# 2. 初始化dlib人脸检测器(无参数)
detector = dlib.get_frontal_face_detector()
# 检测人脸(第二个参数0表示不进行图像金字塔缩放,提升速度)
faces = detector(img, 0)
# 3. 加载68关键点预测模型
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# 4. 遍历检测到的人脸
for face in faces:
# 获取当前人脸的68个关键点
shape = predictor(img, face)
# 将关键点转换为numpy数组格式(x,y坐标)
landmarks = np.array([[p.x, p.y] for p in shape.parts()])
# 5. 遍历所有关键点,绘制圆点和序号
for idx, point in enumerate(landmarks):
pos = (point[0], point[1]) # 关键点坐标
# 绘制绿色实心圆点
cv2.circle(img, pos, 2, color=(0, 255, 0), thickness=-1)
# 绘制白色关键点序号
cv2.putText(img, str(idx), pos, cv2.FONT_HERSHEY_SIMPLEX,
0.4, (255, 255, 255), 1, cv2.LINE_AA)
# 显示结果
cv2.imshow("人脸68关键点定位", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
运行结果:
功能 2:面部关键区域轮廓绘制
基于 68 关键点,绘制脸部轮廓、眉毛、眼睛、嘴巴的闭合轮廓,实现面部轮廓可视化。
import numpy as np
import dlib
import cv2
# 定义绘制连线函数:绘制两点之间的直线
def drawLine(start, end):
pts = shape[start:end]
for l in range(1, len(pts)):
ptA = tuple(pts[l-1])
ptB = tuple(pts[l])
cv2.line(image, ptA, ptB, (0, 255, 0), 2)
# 定义绘制凸轮廓函数:绘制闭合的凸轮廓
def drawConvexHull(start, end):
Facial = shape[start:end+1]
hull = cv2.convexHull(Facial)
cv2.drawContours(image, [hull], -1, (0, 255, 0), 2)
# 1. 读取图像
image = cv2.imread("hg1.png")
# 2. 初始化检测器和模型
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# 3. 检测人脸
faces = detector(image, 0)
# 4. 遍历人脸并绘制轮廓
for face in faces:
# 获取关键点并转换为数组
shape = predictor(image, face)
shape = np.array([[p.x, p.y] for p in shape.parts()])
# 绘制眼睛、嘴巴轮廓
drawConvexHull(36, 41) # 右眼
drawConvexHull(42, 47) # 左眼
drawConvexHull(48, 59) # 嘴巴外轮廓
drawConvexHull(60, 67) # 嘴巴内轮廓
# 绘制脸部、眉毛、鼻子轮廓线
drawLine(0, 17) # 脸部轮廓
drawLine(17, 22) # 右眉毛
drawLine(22, 27) # 左眉毛
drawLine(27, 36) # 鼻子区域
# 显示结果
cv2.imshow("人脸面部轮廓绘制", image)
cv2.waitKey(0)
cv2.destroyAllWindows()1.检测器与模型分离
◦ dlib.get_frontal_face_detector():无参数,仅用于检测人脸边框
◦ dlib.shape_predictor():必须传入.dat模型,用于关键点检测
2. 关键点格式转换dlib 返回的关键点需要转换为numpy数组,才能用 OpenCV 绘制。
3. 轮廓绘制技巧
◦ cv2.line():绘制直线,实现非闭合轮廓
◦ cv2.convexHull() + cv2.drawContours():生成凸包,绘制闭合轮廓
运行结果:
功能3:表情识别
实现方法:人在微笑时,嘴角会上扬,嘴的宽度和与整个脸颊(下颌)的宽度之比变大。即M/J 变大。

判断微笑:M/J > 0.45
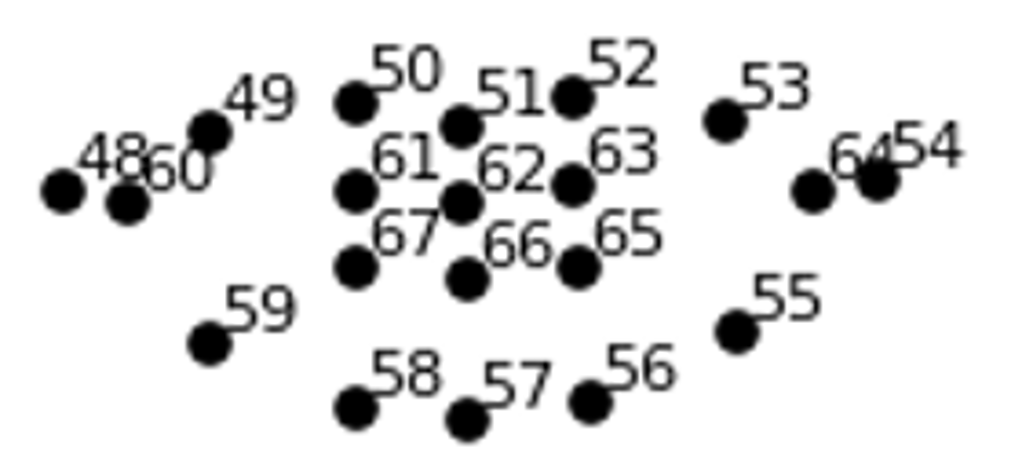
判断大笑:((A+B+C)/3)/M>0.5
人脸表情识别:
import cv2
import numpy as np
import dlib
import cv2
from sklearn.metrics.pairwise import euclidean_distances
from PIL import Image,ImageDraw,ImageFont
def MAR(shape):
# M=euclidean_distance()
A = euclidean_distances(shape[50].reshape(1,2),shape[58].reshape(1,2))
B = euclidean_distances(shape[51].reshape(1,2),shape[57].reshape(1,2))
C = euclidean_distances(shape[52].reshape(1,2),shape[56].reshape(1,2))
D = euclidean_distances(shape[48].reshape(1, 2),shape[54].reshape(1, 2))
return ((A+B+C)/3)/D
def MJR(shape):
M=euclidean_distances(shape[48].reshape(1,2),shape[54].reshape(1,2))
J=euclidean_distances(shape[3].reshape(1,2),shape[13].reshape(1,2))
return M/J
def cv2AddChineseText(img,text,position,textColor=(0,255,0),textSize=30):
img_pil = Image.fromarray(cv2.cvtColor(img,cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
font = ImageFont.truetype("simsun.ttc", textSize)
draw.text(position, text, textColor, font=font)
return cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
# 主程序:摄像头 + 表情识别
def run():
# detector = dlib.get_frontal_face_detector()
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
frame = cv2.imread("img.png")
# cap = cv2.VideoCapture(0)
# while True:
# ret,frame = cap.read()
faces = detector(frame,0)
# faces = detector(frame, 0)
for face in faces:
shape = predictor(frame,face)
shape = np.array([[p.x,p.y] for p in shape.parts()])
mar = MAR(shape)[0][0]
mjr = MJR(shape)[0][0]
result = "正常"
print("mar",mar,"\tmjr",mjr)
if mar > 0.5:
result = "大笑"
elif mjr >0.45:
result="微笑"
mouthHull = cv2.convexHull(shape[48:61])
frame = cv2AddChineseText(frame,result,mouthHull[0,0])
cv2.drawContours(frame,[mouthHull],-1,(0,255,0),1)
cv2.imshow("Frame",frame)
# if cv2.waitKey(1)==27:
# break
cv2.waitKey(0)
cv2.destroyAllWindows()
# cap.release()
if __name__ == "__main__":
run()运行结果:

摄像头表情识别:
import cv2
import numpy as np
import dlib
from sklearn.metrics.pairwise import euclidean_distances
from PIL import Image, ImageDraw, ImageFont
def MAR(shape):
A = euclidean_distances(shape[50].reshape(1, 2), shape[58].reshape(1, 2))
B = euclidean_distances(shape[51].reshape(1, 2), shape[57].reshape(1, 2))
C = euclidean_distances(shape[52].reshape(1, 2), shape[56].reshape(1, 2))
D = euclidean_distances(shape[48].reshape(1, 2), shape[54].reshape(1, 2))
return ((A + B + C) / 3) / D
def MJR(shape):
M = euclidean_distances(shape[48].reshape(1, 2), shape[54].reshape(1, 2))
J = euclidean_distances(shape[3].reshape(1, 2), shape[13].reshape(1, 2))
return M / J
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
font = ImageFont.truetype("simsun.ttc", textSize)
draw.text(position, text, textColor, font=font)
return cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
# 主程序:摄像头 + 表情识别
def run():
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
faces = detector(frame, 0)
for face in faces:
shape = predictor(frame, face)
shape = np.array([[p.x, p.y] for p in shape.parts()])
mar = MAR(shape)[0][0]
mjr = MJR(shape)[0][0]
result = "正常"
print("mar", mar, "\tmjr", mjr)
if mar > 0.5:
result = "大笑"
elif mjr > 0.45:
result = "微笑"
mouthHull = cv2.convexHull(shape[48:61])
frame = cv2AddChineseText(frame, result, mouthHull[0, 0])
cv2.drawContours(frame, [mouthHull], -1, (0, 255, 0), 1)
cv2.imshow("Frame", frame)
if cv2.waitKey(1) == 27:
break
cv2.destroyAllWindows()
cap.release()
if __name__ == "__main__":
run()运行结果:摄像头表情识别,正常显示正常,微笑显示微笑,大笑显示大笑
#增加几项表情的检测能力,例如:哭(嘴巴咧开,眼睛闭合),愤怒(眼睛睁圆):
哭泣表情检测:
import cv2
import numpy as np
import dlib
from sklearn.metrics.pairwise import euclidean_distances
from PIL import Image, ImageDraw, ImageFont
# 核心函数定义
def MAR(shape):
A = euclidean_distances(shape[50].reshape(1, 2), shape[58].reshape(1, 2))[0][0]
B = euclidean_distances(shape[51].reshape(1, 2), shape[57].reshape(1, 2))[0][0]
C = euclidean_distances(shape[52].reshape(1, 2), shape[56].reshape(1, 2))[0][0]
D = euclidean_distances(shape[48].reshape(1, 2), shape[54].reshape(1, 2))[0][0]
return ((A + B + C) / 3) / D
def MJR(shape):
M = euclidean_distances(shape[48].reshape(1, 2), shape[54].reshape(1, 2))[0][0]
J = euclidean_distances(shape[3].reshape(1, 2), shape[13].reshape(1, 2))[0][0]
return M / J
def eye_aspect_ratio(eye):
A = np.linalg.norm(eye[1] - eye[5])
B = np.linalg.norm(eye[2] - eye[4])
C = np.linalg.norm(eye[0] - eye[3])
ear = (A + B) / (2.0 * C)
return ear
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=25):
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
font = ImageFont.truetype("simsun.ttc", textSize)
draw.text(position, text, textColor, font=font)
return cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
def judge_expression(shape):
mar = MAR(shape)
mjr = MJR(shape)
left_eye = shape[36:42]
right_eye = shape[42:48]
left_ear = eye_aspect_ratio(left_eye)
right_ear = eye_aspect_ratio(right_eye)
ear_avg = (left_ear + right_ear) / 2.0
# 五种表情判断逻辑(优先级:哭泣 > 愤怒 > 大笑 > 微笑 > 正常)
# 调整哭泣参数:降低门槛,适配小孩哭泣特征(眼睛闭合、嘴巴咧开/张开更宽松)
# 哭泣:眼睛闭合(ear_avg<0.25,放宽闭合判断)+ 嘴巴咧开(mjr>0.40,放宽咧开判断)+ 嘴巴张开(mar>0.25,放宽张开判断)
# 愤怒:眼睛睁圆(ear_avg>0.35)+ 嘴巴闭合(mar<0.2)
# 大哭:嘴巴开合度高(mar>0.5)
# 微笑:嘴巴宽度比例达标(mjr>0.45)且非哭泣
# 正常:无上述特征
if ear_avg < 0.25 and mjr<0.4 and mar > 0.20:
return "哭泣"
elif ear_avg > 0.20 and mjr < 0.50 and mar < 0.35:
return "愤怒"
elif ear_avg > 0.50 and mjr > 0.5 and mar>0.45:
return "大笑"
elif ear_avg > 0.50 and mjr > 0.45 and mar<0.4:
return "微笑"
else:
return "正常"
# def judge_expression(ear_avg,mjr,mar):
# print(f"[DEBUG] ear_avg={ear_avg:.2f},mjr={mjr:.2f},mar={mar:.2f}")
# 初始化模型
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# 主函数(仅保留核心功能,删减冗余文字)
def run():
frame = cv2.imread("cry.jpg")
if frame is None:
print("无法读取图片")
return
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = detector(gray, 0)
face_index = 1
for face in faces:
shape = predictor(gray, face)
shape = np.array([[part.x, part.y] for part in shape.parts()])
expression = judge_expression(shape)
# 绘制轮廓
color_list = [(0, 255, 0), (0, 255, 0)]
current_color = color_list[face_index - 1] if face_index <= len(color_list) else (0, 255, 0)
cv2.polylines(frame, [shape[36:42]], True, current_color, 2)
cv2.polylines(frame, [shape[42:48]], True, current_color, 2)
cv2.polylines(frame, [shape[48:61]], True, (0, 255, 0), 2)
# 显示表情(仅保留人脸序号+表情,无多余指标)
if face_index == 1:
text_x, text_y = 10, 30
elif face_index == 2:
text_x, text_y = frame.shape[1] - 120, 30
else:
text_x, text_y = 10, 30 + (face_index - 1) * 50
frame = cv2AddChineseText(frame, f"{expression}", (text_x, text_y), current_color, 25)
print(f"{expression}")
face_index += 1
cv2.imshow("表情检测", frame)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == "__main__":
run()ear_avg(双眼平均开合度):由 eye_aspect_ratio 函数计算(眼睛上下眼睑距离 ÷ 眼睛宽度),值越小,眼睛闭得越紧(比如哭泣时 ear_avg 极低,愤怒时眼睛睁得大,ear_avg 偏高)
运行结果:

愤怒表情检测:
import cv2
import numpy as np
import dlib
from sklearn.metrics.pairwise import euclidean_distances
from PIL import Image, ImageDraw, ImageFont
# 核心函数定义
def MAR(shape):
A = euclidean_distances(shape[50].reshape(1, 2), shape[58].reshape(1, 2))[0][0]
B = euclidean_distances(shape[51].reshape(1, 2), shape[57].reshape(1, 2))[0][0]
C = euclidean_distances(shape[52].reshape(1, 2), shape[56].reshape(1, 2))[0][0]
D = euclidean_distances(shape[48].reshape(1, 2), shape[54].reshape(1, 2))[0][0]
return ((A + B + C) / 3) / D
def MJR(shape):
M = euclidean_distances(shape[48].reshape(1, 2), shape[54].reshape(1, 2))[0][0]
J = euclidean_distances(shape[3].reshape(1, 2), shape[13].reshape(1, 2))[0][0]
return M / J
def eye_aspect_ratio(eye):
A = np.linalg.norm(eye[1] - eye[5])
B = np.linalg.norm(eye[2] - eye[4])
C = np.linalg.norm(eye[0] - eye[3])
ear = (A + B) / (2.0 * C)
return ear
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=25):
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
font = ImageFont.truetype("simsun.ttc", textSize)
draw.text(position, text, textColor, font=font)
return cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
def judge_expression(shape):
mar = MAR(shape)
mjr = MJR(shape)
left_eye = shape[36:42]
right_eye = shape[42:48]
left_ear = eye_aspect_ratio(left_eye)
right_ear = eye_aspect_ratio(right_eye)
ear_avg = (left_ear + right_ear) / 2.0
# 五种表情判断逻辑(优先级:哭泣 > 愤怒 > 大笑 > 微笑 > 正常)
# 调整哭泣参数:降低门槛,适配小孩哭泣特征(眼睛闭合、嘴巴咧开/张开更宽松)
# 哭泣:眼睛闭合(ear_avg<0.25,放宽闭合判断)+ 嘴巴咧开(mjr>0.40,放宽咧开判断)+ 嘴巴张开(mar>0.25,放宽张开判断)
# 愤怒:眼睛睁圆(ear_avg>0.35)+ 嘴巴闭合(mar<0.2)
# 大哭:嘴巴开合度高(mar>0.5)
# 微笑:嘴巴宽度比例达标(mjr>0.45)且非哭泣
# 正常:无上述特征
if ear_avg < 0.25 and mjr<0.4 and mar > 0.20:
return "哭泣"
elif ear_avg > 0.20 and mjr < 0.50 and mar < 0.35:
return "愤怒"
elif ear_avg > 0.50 and mjr > 0.5 and mar>0.45:
return "大笑"
elif ear_avg > 0.50 and mjr > 0.45 and mar<0.4:
return "微笑"
else:
return "正常"
# def judge_expression(ear_avg,mjr,mar):
# print(f"[DEBUG] ear_avg={ear_avg:.2f},mjr={mjr:.2f},mar={mar:.2f}")
# 初始化模型
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# 主函数(仅保留核心功能,删减冗余文字)
def run():
frame = cv2.imread("angry.jpg")
if frame is None:
print("无法读取图片")
return
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = detector(gray, 0)
face_index = 1
for face in faces:
shape = predictor(gray, face)
shape = np.array([[part.x, part.y] for part in shape.parts()])
expression = judge_expression(shape)
# 绘制轮廓
color_list = [(0, 255, 0), (0, 255, 0)]
current_color = color_list[face_index - 1] if face_index <= len(color_list) else (0, 255, 0)
cv2.polylines(frame, [shape[36:42]], True, current_color, 2)
cv2.polylines(frame, [shape[42:48]], True, current_color, 2)
cv2.polylines(frame, [shape[48:61]], True, (0, 255, 0), 2)
# 显示表情(仅保留人脸序号+表情,无多余指标)
if face_index == 1:
text_x, text_y = 10, 30
elif face_index == 2:
text_x, text_y = frame.shape[1] - 120, 30
else:
text_x, text_y = 10, 30 + (face_index - 1) * 50
frame = cv2AddChineseText(frame, f"{expression}", (text_x, text_y), current_color, 25)
print(f"{expression}")
face_index += 1
cv2.imshow("表情检测", frame)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == "__main__":
run()运行结果:


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 26
26 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)